
基于AdaBoost方法的近红外光谱建模分析
2022-08-08 03:28:08荣婕妤
吉林师范大学学报(自然科学版) 2022年3期
李 华,荣婕妤
(长春大学 理学院,吉林 长春 130022)
0 引言
近红外光波长范围为780~2 500 nm,是介于可见区与中红外区之间的电磁波,通过与物质中有机分子的含氢基团的作用,形成有机分子的倍频和合频吸收光谱.根据这些近红外吸收频谱出现的位置、吸收强度等信息特征,结合数理统计对成分作定性和定量分析.由于近红外技术具有快速、无损、环保等特点而广泛用于农产品、食品、化学、医药、石油等领域[1].在淀粉加工过程中,利用近红外技术进行定量分析可以达到不破坏样品、不消耗化学试剂、节省材料和时间的目的,很适合对淀粉成分进行监测分析.本文考虑将AdaBoost 回归算法用于淀粉成分的近红外光谱建模分析,以实现对加工过程中淀粉成分含量的监测.
集成学习方法由于可以提高模型系统的泛化能力,近些年来成为了机器学习领域重要的研究方向[2],AdaBoost(自适应增强)属于集成学习方法,个体学习器之间存在强依赖关系.它的自适应性在于:前一个基学习器训练效果差的样本会得到加强,加权后的全体样本集再次被用来训练下一个基学习器.同时,在每一轮训练中加入一个新的弱学习器,直到达到某个预定的足够小的错误率或达到预先指定的最大迭代次数时训练结束.
本文以AdaBoost回归算法为线索,介绍算法设计思想的多样性,并比较不同方法的性能,探讨在实证分析中的效果:AdaBoost回归算法的设计思想;介绍随研究发展而出现的改进AdaBoost回归理论分析模型,以及从这些模型衍生出的各种变种算法,与早期分析理论形成对比,揭示AdaBoost回归算法研究的新思路以及有待解决的问题;基于不同AdaBoost回归算法在近红外光谱建模问题中进行实证分析,对比不同方法的性能;探讨AdaBoost回归算法的发展方向及在近红外光谱建模领域的发展前景.
1 AdaBoost回归算法设计思想
AdaBoost回归算法是从弱学习算法出发,反复学习得到一系列弱学习器,然后组合这些弱学习器,构建一个强学习器.重点在于改变训练数据的概率分布(权值分布),根据不同的训练数据分布调用弱学习算法,再按一定权重集成弱学习器得到强学习器.

图1 AdaBoost回归算法训练过程
具体步骤以AdaBoost R.T算法为例阐述[3]:
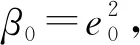
其中Z0为归一化权重,使得弱学习器f0学习相对误差高的训练样本权重变高,在下一步弱学习器f1中得到更多的重视.
然后基于调整权重后的训练集来训练弱学习器f1.
如此重复进行,直到弱学习器误差率数达到事先指定的阈值或迭代次数达到阈值,最终将这T个弱学习器通过集合策略进行整合,得到最终的强学习器输出
其中βt∈[0,1]可看作是对弱学习器的不信任程度,et越小,βt越小,对该弱学习器的信任程度越大,在对样本权重更新时也是利用βt<1的特点,使预测误差大于某一阈值的样本点获得较大权值,使得下一步迭代中更关注此类样本点.这样通过迭代使得最终的强学习器训练误差越来越小.理论上当弱学习器个数趋近于无穷时,最终获得的强学习器误差近似趋于零.
2 AdaBoost回归算法及不同变种算法
AdaBoost变体算法主要有两个方向,一是Boosting家族系列算法,可看作是AdaBoost算法的横向发展;二是AdaBoost算法的纵向发展,是对AdaBoost算法本身的改进和推广,以及结合其他算法而产生的新方法.对AdaBoost算法的改进主要集中在以下三个方面:一是调整权值更新方法,以达到提升弱学习器性能,减缓退化等效果;二是改进AdaBoost的训练方法,使AdaBoost方法能更高效地进行拓展;三是结合其他算法和一些额外信息而产生的新算法,达到提高精确度的目的.
2.1 权值更新方法的改进
H.Drucker[4]考虑的一种Boosting回归算法给每个样本赋了一个权重Dt,i,并对加权后得到样本集合X′拟合一个CART模型ft(X′)→Y.类似于AdaBoost分类算法,计算第t次迭代样本集合上的预测平均损失
其中对于损失函数Li,有三种可选形式分别是
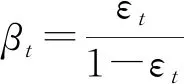
通过这种方法,每次迭代在不同权重的样本集合上构建回归树,最后通过加权中值方法来集成每个回归树的预测结果,即对于一个新的输入x*,在每个弱学习器上都会产生一个预测值ft(x*),t=1,2,…,T,最终的预测结果f(x*)为

2.2 训练方法的改进
2009年H.X.Tian和Z.Z.Mao[5]提出一种自适应解决方法,通过递归调整AdaBoost.RT算法中的阈值φ,具体方法是选择0.2作为默认阈值初始值,计算每次迭代输出预测结果的均方根误差(RMSE)动态调节阈值,再计算每个样本绝对相对误差,并与阈值进行比较.绝对相对误差是预测值相对于真实值的误差百分比绝对值,φ用于对预测值进行正确或不正确的分类.通过阈值比较将回归任务转化为一个分类问题,在下一次迭代中,预测差的样本采样权值会增加.
此方法的代价是引入了一个新的待调节参数.AdaBoost R.T不像Adaboost.R2等回归提升方法有一个设定停止准则,其迭代次数可以根据所需的精度(达到某阈值)来选择.
修正AdaBoost R.T方法具体步骤如下:
初始化 迭代序号t=1,原始分布Dt,i=1/N,i=1,2,…,N,权重向量ωt,i=Dt,i.
(1)令t=1,2,…,T.
(2)根据对应权重抽取样本训练弱学习器建立回归模型:ft(x)→y.
(4)通过前一次迭代和此次迭代的RMSE差值自适应调整下一步迭代中的阈值φ:
其中λ依赖于t的变化:其中r的默认值为0.5,也可以自行设定.
输出 下一步迭代中样本权重更新的阈值.
2006年[6]研究发现在AdaBoost R.T算法中阈值φ设定若大于0.4会导致过拟合及噪声增强,使得学习器不稳定.
2.3 多算法结合的改进
算法结合一般针对传统AdaBoost回归算法中的弱学习器采用的回归树进行改变,如P.Zhang等[7]采用将极限学习机(ELM)与AdaBoost结合形成新的具有鲁棒性的混合算法RAE-ELM,不再像原始AdaBoost算法中人工选择回归的阈值,而是通过训练集样本预测误差的近似分布确定学习器回归阈值,使迭代过程阈值可根据输入的内在特性动态地自行调整.在具有鲁棒性的AdaBoost R.T方法(AdaBoost.ROB)中,近似误差分布的标准差作为其预测好坏的判断依据,因为在概率和统计理论中,标准差衡量的是相对于平均值的变化量或是离散量,即数据点大多趋近于平均值,那么标准差会很低,若数据点分布范围广,则会产生较大的标准偏差.所以标准偏差可以用作一组重复预测的不确定性度量,在用此判断时,如果预测值到真值间的平均距离很大,那么被测回归模型可能需要修改,因为可以合理认为超出预测范围的样本点会出现,所以此时模型预测准确率较低.
AdaBoost.ROB方法具体步骤如下:
初始化 迭代序号t=1,原始分布Dt,i=1/N,i=1,2,…,N,权重向量ωt,i=Dt,i,误差率εt=0.
(1)令t=1,2,…,T;
(3)建立回归模型ft(x)→y;
(4)计算每个样本的误差et,i=ft(xi)-yi;
(6)如果εt>1/2则令T=t-1并终止循环;
(7)令βt=εt/1-εt;
(8)计算弱学习器在最终强学习器中的贡献(权重)αt=-log(βt);
(9)更新样本权重向量:若i∉P,则ωt+1,i=ωt,iβt,否则ωt+1,i=ωt,i;
(10)令t=t+1.
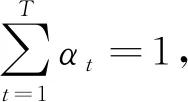
在RAE-ELM算法训练过程中,将极限学习机(ELM)与鲁棒改进AdaBoost相结合,相应地分配一个集成权值,使每个ELM学习器根据前一轮训练输出结果确定下一步训练集样本的相应分布.对于当前ELM模型预测效果较好的样本,将其权重向量乘以错误率βt,否则,其权重向量不变.再训练下一步ELM模型,直到迭代次数达到阈值或者εt高于0.5.因为错误率高于0.5时,AdaBoost算法就不再收敛[8].
方法的优点在于ELM学习速度快,回归性能高,有利于提高最终强学习模型的泛化性能,并且改进后的AdaBoost R.T算法利用近似误差的统计分布动态确定具有鲁棒性的阈值,可以自适应选取更合适样本的阈值.
3 基于AdaBoost回归算法的近红外光谱建模分析
本文通过以粮食加工企业近红外光谱仪对生产产品质量预测的建模分析,目的是贴合实际中质检领域快速在线监测,为企业的实际生产中通过产品质量预测以便对加工流程及时做出调整而提出建议.采用的淀粉数据的数据量为1 898,由12个波长值构成自变量,一种成分(水分M)构成因变量,其中,12个波长值分别为(2.36、2.21、2.16、2.06、1.94、1.84、1.76、1.66、1.55、1.51、1.45、1.31)×103cm-1.
在模型训练和测试阶段通过3∶1划分训练集(数据量1 423)和测试集(数据量475),通过在同一组数据上对比前面提到的4种方法:AdaBoost R2(3种不同损失函数)、AdaBoost R.T、AdaBoost.ROB和AdaBoost 权重调整方法(3种不同损失函数),其中弱学习模型均采用的是决策树回归模型,得到图2和表1.
图2中各个子图的横坐标为样本真实化验值,纵坐标为据建立模型得到的预测值,不同的图例用于区分训练集和测试集样本,通过真实值和预测值散点图可直观上看出不同AdaBoost回归模型效果基本不错,散点大多分布在对角线上,不同AdaBoost回归模型下的预测值较为接近真实值.
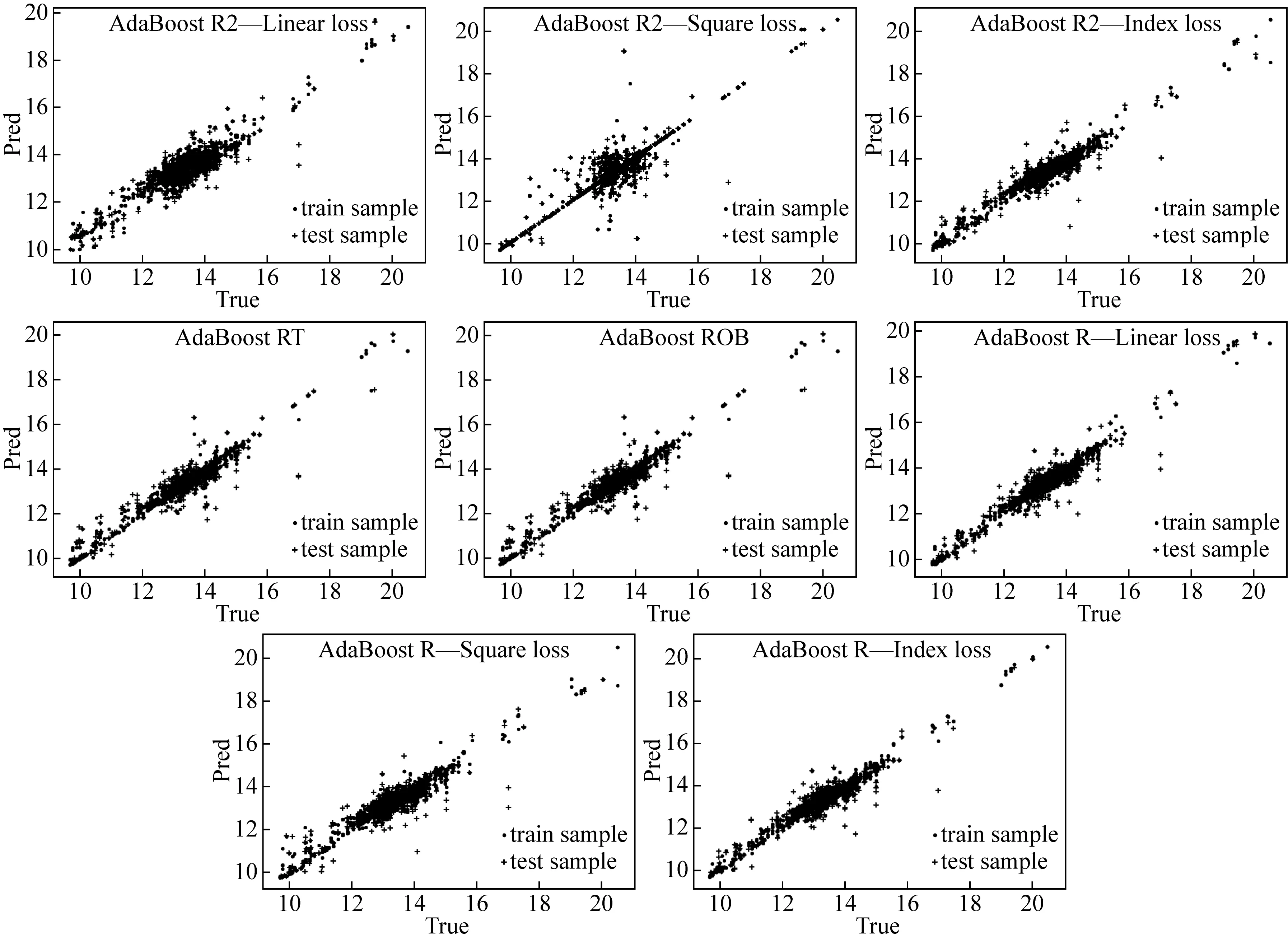
图2 不同AdaBoost回归模型效果对比
具体统计效果还要通过表1的评价准则来看.本文采取的回归评估指标是均方误差(R2).MSE是预测值和真实值误差平方和的均值,其值越小说明拟合效果越好.R2是反映模型拟合优度的统计量,为回归平方和与总平方和之比,取值在0~1之间,且无单位,其数值大小反映了回归贡献的相对程度,即因变量的总变异中回归关系所能解释的百分比,是最常用于评价回归模型优劣程度的指标,R2越接近于1,回归模型拟合效果越优.
由表1可知,以测试集的MSE来看,AdaBoost 权重调整后的回归算法预测模型表现最优,Testing MSE从小到大依次是AdaBoost 权重调整(线性损失函数)、AdaBoost 权重调整(指数损失函数)、AdaBoost R2(指数损失函数)、AdaBoost.ROB、AdaBoost R.T、AdaBoost 权重调整(平方损失函数)、AdaBoost R2(线性损失函数)和AdaBoost R2(平方损失函数).可以看出AdaBoost 权重调整算法的预测效果优于改进前的AdaBoost R.T,鲁棒改进的AdaBoost.ROB方法预测效果也优于固定阈值的AdaBoost R.T方法,后来发展的AdaBoost算法也优于较早提出的AdaBoost R2方法.
以测试集的决定系数来看,也是AdaBoost 权重调整后建立的回归模型拟合效果最好,AdaBoost.ROB与改进前AdaBoost R.T方法的拟合效果差别不大,但因为MSE减小,说明此方法应用于淀粉近红外预测模型在精确度和准确度方面相对较好.
4 结论与展望
通过实验表明将AdaBoost回归算法用于淀粉成分的近红外光谱建模分析是可行的,据此实现对加工过程中淀粉成分含量的监测也比原始化学仪器检测要快速、方便许多.为得到更为符合真实生产工艺的成分含量情况,研究关于AdaBoost算法的改进工作也是必要的.关于改进AdaBoost回归算法主要关注以下几个方面:一是针对AdaBoost算法本身过拟合和鲁棒性不强的问题,对权值更新方式改进;二是针对AdaBoost算法训练过程进行加速的尝试,可以尝试结合多核技术,类似P-AdaBoost的并行算法,也可以考虑减小样本容量,关于如何寻找强代表样本,动态剪裁[9]是一个不错的设想;三是结合某些成熟的算法,或加入前驱步骤,或对学习器结构进行改进.目前在改进AdaBoost算法权值更新方法上,尚没有一个完美的解答,权值抑制是一个基本思想,但存在不同的抑制方法和侧重点,寻找一种能兼顾各方面特点的方法将成为研究的重点.另外,弱学习器数量、精度和结构上的研究也值得关注.但目前大多数研究改进均集中在分类问题的应用,对于回归问题还存在诸多与分类问题不一致的方面有待讨论.
最后,需要指出的是AdaBoost算法的改进工作在第三个方向开放性最强,新算法层出不穷,算法结合点的不同,就会形成不同的算法.目前新算法主要的目的在于获得更快的检测速度和更高的精度,可以在提高训练速度和算法强健性的方向上尝试.总之,新的算法在不断涌现中,各类改进方式具有非常广阔的空间,AdaBoost回归算法必能在近红外光谱建模领域获得更为广泛的应用.
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
当代陕西(2020年17期)2020-10-28 08:18:18
制造技术与机床(2019年9期)2019-09-10 07:36:54
西南交通大学学报(2018年6期)2018-12-18 02:22:28
人大建设(2018年5期)2018-08-16 07:09:00
河北遥感(2017年2期)2017-08-07 14:49:00
电信科学(2017年6期)2017-07-01 15:44:57
自动化学报(2017年7期)2017-04-18 13:41:02
衡阳师范学院学报(2016年3期)2016-07-10 07:16:27
