
基于运营商大数据的信用服务体系探索
2022-08-08 07:09张湛梅张晓川
互联网天地 2022年7期
□ 文 张湛梅 张晓川
0 引言
随着移动互联网和金融创新业务的快速发展,客户信用行为愈加多元化,基于银行领域信贷与消费行为的传统信用评分方式已无法满足当前互联网信贷的需求,与经济发展水平和社会发展阶段存在不匹配、不协调、不适应的矛盾,这直接影响着中国金融市场的交易秩序。为夯实金融行业发展的基础,深化我国市场经济发展,亟需构建更健全的信用服务体系。目前,数据获取及处理方式有了大幅度提高,相对于传统征信如央行通过统计信用卡等信息的征信,大数据征信拥有着更多优势。运营商具备客户身份特征、消费行为、位置信息、社交活动等海量数据,在大数据征信中具有显著的数据优势。
本文阐述了基于运营商大数据打造个人信用评分体系模型,保证了个人信用评分模型在筛选指标的时候保持稳定并体现信令数据的重要作用,进一步减少模型系数的误差,使得评分模型更加合理,并以此为基础打造标准化的信用服务产品,满足信贷身份校验、授信等市场需求,推动征信行业的发展。
1 项目背景
1.1 个人信用发展现状
个人信用系统是一个评估、记录和归档个人信用的系统。贷款人可以根据家庭收入、收到和偿还的贷款、超额信贷、罚款和不良贷款的起诉来决定是否借款或借款金额。
从20世纪20年代当时的中国政府被迫颁布中国最早的个人信用档案——《银行工会章程》到现在,中国的个人信用制度经历了一个世纪的发展,但是从严格意义上来说,我国个人信用体系建设真正始于1999年中国人民银行个人信用信息基础数据库的投入建设。比较于国际上的发达国家,我国个人信用系统的建设起步较晚,但是发展规模却后来居上。早期,个人信用体系主要由央行主导,采集的个人信用信息包含三类:身份识别信息、贷款信息和信用卡信息,但是随着互联网的飞速发展和技术迭代,个人信用体系的大数据时代也随之到来,由芝麻信用管理有限公司、腾讯征信有限公司等为代表的金融、互联网行业巨头建立的个人征信公司,成为央行个人征信业务的有效补充。2019年中国人民银行副行长朱鹤新介绍,中国已经建立全球规模最大的征信系统,累计收录9.9亿自然人、2591万户企业和其他组织的有关信息,在防范金融风险、维护金融稳定、促进金融业发展等方面发挥了不可替代的重要作用。
1.2 运营商潜在优势
互联网技术的进步和电信行业基础设施的不断增强,移动互联网获得了前所未有的空前繁荣。根据中国互联网网络信息中心2022年2月25日发布的《中国互联网发展统计报告》,截至2021年12月,中国移动网络IPv6流量占网络核心资源的35.15%;在信息通信行业,建成投产5G基站142.5万个;在使用互联网设备方面,99.7%的中国网民使用手机上网,手机仍然是上网的主要设备。从报告中可以判断,电信运营商占据着获取用户个人信息和个人信用数据的天然优势。
有相关文章对大数据信用与传统信用的区别进行了比较和总结:第一,大数据征信拓展了征信的理念,通过对大量信息主体数据的分析,可以发现信息主体的历史行为与其信用记录之间的相关性;第二,大数据征信的数据来源更加广泛;第三,大数据征信的数据形式更加多样,包括文本形式的半结构化数据,以图片、视频、音频等形式存在的非结构化数据等;第四,大数据征信的数据规模更大,相较于传统征信数据规模通常以GB为单位,大数据征信数据规模一般以PB计。
基于上述的比较研究,可以清晰地了解在个人信用体系中,相比传统征信,大数据征信在个人信用数据获取和处理上有其独特优势。依据《中国互联网络发展状况统计报告》的统计,我们能够清楚判断,基于海量移动运营商数据的大数据征信,具备其他个人征信渠道难以获取的数据优势。相关如下:
1.2.1 在互联网征信中具有重要数据优势
在目前的互联网专业化征信系统中,排名前4的高质量的数据是:收入、位置、熟人社交、税务等,除去信贷评估能获取的收入、税务以外,熟人社交、位置等信贷机构无法准确获取的数据恰好是运营商的优势数据源。因此,运营商在互联网+征信评估中占据了数据优势地位。
1.2.2 海量的客户数据具有很大的潜在价值
运营商拥有客户身份特征、消费行为、位置信息、社交活动这四维一体的核心大数据,基于大数据高度融合,可清晰描绘出客户全息精准画像,以此为基础可提供征信服务产品,满足信贷身份校验、授信等市场需求。如图1所示。

图1 运营商具有的数据优势
在个人信用体系中,相比传统征信,大数据征信在个人信用数据获取和处理上有其独特优势。
2 构建运营商大数据信用服务体系
2.1 方案概述
本方案依托用户的基本信息、消费能力、信用记录、人脉关系、行为偏好等五大方面指标以及用户的信令数据,通过抽取标准样本数据、指标分箱处理及计算、利用信令数据自适应的个人信用评分模型训练和个人信用评分计算等步骤,自适应选取对信用评分有效的指标和系数,保证了个人信用评分模型在筛选指标的时候保持稳定并体现信令数据的重要作用,减少模型系数的误差,使得评分模型更加合理,最终实现具备运营商特色的全面、综合、多维度的个人信用度评分指标体系建设,为精准高价值用户营销、银行信贷行业等方面应用提供有效支撑。如图2所示。

图2 运营商大数据信用服务体系
2.2 具体实现方案
2.2.1 提取样本数据
利用熵值法并结合欠费方面的指标对用户进行评分,分值由高到低排序,得分越高则用户的欠费程度越高,违约的概率也随之增加,所以取得分前1%的用户作为坏用户,即正样本;在剩下的用户中随机抽取总用户人数的10%作为好用户,即负样本。具体的步骤如下:
(1)选取近三个月停机总次数、近三个月欠费总金额和客户账期类型作为指标,这些指标均衡量了用户的欠费违约情况。由于指标的取值范围不一致,为了避免过于侧重单个指标,需要对指标进行标准化,标准化公式如下:

其中Uij,i=1,2,…,m,j=1,2,3为原始数据中第j个指标的第i个记录,m为总用户人数,vij为标准化后的数据。
(2)通过计算熵值可以用来判断三个月停机总次数、近三个月欠费总金额和客户账期类型三个指标的离散程度,离散程度越大表明该指标对综合评价影响越大。
首先计算指标的熵值,衡量了指标的离散程度,计算公式如下:
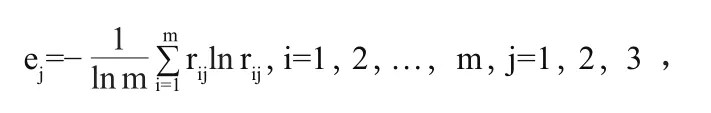
其中rij表示第i个记录下第j个指标的比重

然后计算指标的权重,衡量了三个月停机总次数、近三个月欠费总金额和客户账期类型三个指标在计算总分时理应乘上的系数,计算公式如下:
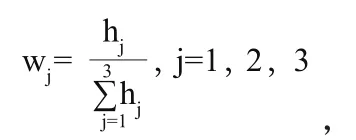
其中hj为第j个指标的差异性系数hj=1_e,j=1,2,3。
最后根据指标的权重和指标值,计算每个用户的熵值法得分

(3)对si分值由高到低排序,分值越高表示在欠费违约方面越严重,取得分前1%的用户作为坏用户,即正样本;在剩下的用户中随机抽取总用户人数的10%作为好用户,即负样本。正负样本的合集即为标准的样本数据,用于后续建立信用评分模型。
用户的基本信息主要包含品牌、在网时长和身份等信息;
2.2.2 选取指标并进行分箱处理
为了全面评估用户的信用情况,除了从传统评分角度提取用户的基本信息、消费能力、信用记录、人脉关系和行为偏好等五大方面指标,同时加入用户的信令数据作为数据依据。
用户的基本信息主要包含品牌、在网时长和身份等信息;消费能力是衡量用户在通信消费的消费层次、消费级别、消费活跃度,主要包含账户余额、主套餐包含的费用、上月总通话次数、上三个自然月平均充值额度等等;信用记录用于衡量用户履约能力,包含上三个自然月欠费总额、上一自然月单停机天数、上一自然月双停机天数等等;人脉关系用于衡量用户社交关系强度,从社交影响力和身边人的信用分来评估人脉关系,包括高频对端号码个数、高频对端号码平均时长、亲密人员个数、亲密人员平均消费水平等等;行为偏好用于衡量用户使用App的活跃度以及应用偏好,包括App类型偏好top1、社区交友使用次数、社区交友使用流量、电商购物使用次数、股票类App使用次数等等。用户的信令数据主要选取工作日10:00至17:00常驻位置为高端写字楼和CBD的次数和22:00至次日6:00常驻位置为高端小区的次数。
为方便后续的评分能形成评分表用于评估信用得分,须对指标进行分箱,对于连续型指标,一个合理的分箱应该使得每个箱内的数据量较为均衡,不宜过多或者过少,同时各个箱内负样本的占比应呈现单调上升或下降的趋势,这里采用WOE值,它既可以衡量各个分箱的趋势情况,也是后续的回归模型的变量输入,其计算公式如下:

对于离散型指标,在指标的取值不多的时候,可直接按其取值作为分箱并求取WOE值;在取值较多的时候,可对某些取值进行合并,再求对应的WOE值。

2.2.3 利用信令数据对评分模型进行自适应训练
逻辑回归在信用评分模型中使用比较广泛,它的结构简单,系数的作用容易在业务上解释。
用户为坏用户的概率可用P表示,则逻辑回归模型可表示为

其中xi=(i=1,2,…,s)为指标,由于P取值在0到1之间,而通过logit变换后,取值范围可变换为任意实数值,需要求解的是β =(β0,β1,…,βs)T。
在使用逻辑回归预测时,可以使用全部指标进入模型,但某些对预测贡献度不高的指标也会进入模型,导致模型预测的偏差变大。针对该情况,通过前进法、后退法、逐步回归等方法筛选变量,剔除作用不明显的指标。
同时基于信令数据自适应的逻辑回归模型,利用信令数据自适应地同时进行变量选择和系数估计,有效减小模型系数估计偏差。
首先,采用Adaptive—Lasso方法求解逻辑回归模型。给定数据(X(i),y(i)),i=1,2,…,n,其中X(i)=(xi1,…,xis),表示样本数据中的第i个数据的WOE值向量,共n个,xi1表示第i个数据的第一个指标对应的WOE值,y(i)表示目标变量,若第i个数据为正样本,则y(i)=1;若第i个数据为负样本,则y(i)=0。则在Adaptive—Lasso方法下β=(β0,β1,…,βs)T的估计量定义为

(2)式的第一部分表示模型拟合的优良度,这是一般逻辑回归模型在求解时的部分,第二部分则表示系数的惩罚项,λn为惩罚参数。而表示公式(1)进行最小二乘估计得到的βj的估计值,当|βj|系数较大的时候,给予较小的惩罚,能得到较小的偏差;而当|βj|系数较小的时候,给予较大的惩罚,该系数则近似为0,实现了变量选择的功能。
同时求解的过程需要利用信令数据方面的指标对其他指标的系数进行自适应地控制,确保信令数据方面的指标贡献较高的权重,所以需要在Adaptive—Lasso方法的基础上增加惩罚项。
记工作日10:00至17:00常驻位置为高端写字楼和CBD的次数和22:00至次日6:00常驻位置为高端小区的次数两个指标在所有指标xi(i=1,2,…,s)中的下标为k1,k2,即xk1表示工作日10:00至17:00常驻位置为高端写字楼和CBD的次数,βk1表示指标xk1对应的系数。
为了保证信令数据方面的指标xk1和xk2贡献较高的权重,需要对βj之间的差异进行控制。考虑添加惩罚项
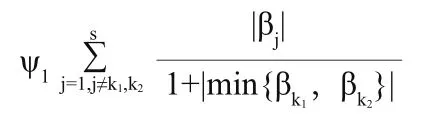
用于控制指标xk1和xk2的系数值,通过限制的大小,保证了指标xk1和xk2的系数必须大于其他指标的系数,即确保了信令数据方面的指标在模型贡献较高的权重,而ψ1为惩罚系数。
综上则有基于信令数据的自适应逻辑回归模型β=(β0,β1,…,βs)T的估计量定义为

2.2.4 将回归模型转化为评分模型
将回归系数转换为信用评分的形式是一个量表编制的过程,为了方便业务人员使用以及评分之间的差异具有业务意义,通常需要满足一下三点要求:
(1)评分控制在一定范围内,如0~900分之间。
1995年9月,我曾介绍《大地上的事情》的作者、生态文学散文家苇岸加入中国作家协会。我的推荐词写道:“苇岸秉承着《瓦尔登湖》作者梭罗、《林中水滴》作者普利什文的传统,倾全力描绘生机蓬勃的大自然的一切。他在中国散文史上首先表达了土地伦理学的思想,因此我乐于介绍他加入中国作家协会。”推荐词里,我虽然使用了“土地伦理学”的提法,但那时我并不知道这一首创性的概念最早是由李奥帕德提出的。这时我才感到,冬林把这本好书送我阅读,使我得到醍醐灌顶般的醒悟,我是多么幸运。
(2)在特定的分数时,好用户和坏用户具有一定的比例关系,这里采用
(3)评分值的增加应该能反映好用户和坏用户比例的变化,如希望评分值每增加50分,odds也增加一倍。
目前业界比较通用的信用评分方程式如下:
score=offest+factor×ln(odds),
为了满足以上3个条件,该方程式需满足以下两个等式
a、score=offest+factor×ln(odds),
其中pdo表示odds增加1倍需要评分值增加的值。则有
factor=pdo/ln(2),offest=score_factor×ln(odds)。
从而得到最终的评分方程式为:


score=offest+factor×ln(odds)
假如评分值在600分的时候好用户与坏用户的比例为50:1,且odds增加一倍的时候,评分增加50分。则有:
factor=50/ln(2)=72.13,
offest=600_72.13×ln(50)=317.83
于是得到最终的评分方程式:
score=317.83+72.13×ln(odds)。
由于逻辑回归方程的左边可知_logit(P)×ln(odds),则将上一步骤中得到β的估计量代入评分方程式,得到:

这里的xi表示第i个变量的值所对应的分箱的WOE值,为(3)式得到的回归模型系数。
故根据评分公式可得到对应每个变量每个分箱的评分值
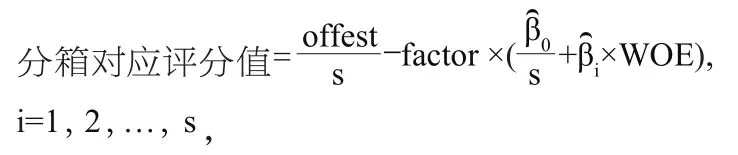
其中WOE表示变量的分箱对应的WOE值。
结合输入参数和待评估用户的指标,将待评估用户的个人信用评分计算出来。如图3所示。

图3 信用报告示例
以数据对接的商务模式为切入点,信用查询服务为载体,探索和信用分对外价值变现的合作方案。
2.3 应用效果
2.3.1 基于信用服务体系,打造标准化的互联网产品
基于信用服务体系及金融行业成功变现经验,通过上网助手/微信公众号/运营商客户端/App等渠道拓展应用辐射,创新前后向服务模式,建立标准化产品体系,储备大数据变现能力。以数据对接的商务模式为切入点,信用查询服务为载体,探索和信用分对外价值变现的合作方案。相关做法如图4所示,如下:

图4 产品服务模式
(1)信息查询定价标准:基于模型指标相关程度排序,划分数据查询价格梯度;
(2)数据脱敏处理方案:通过数据脱敏操作,对数据进行封装,输出泛化的数据形态;
(3)合作方使用查询服务方法:合作方提供一批用户号码及个性化定制的需求,以号码为单位,输出非明细数据的用户画像报告。

2.3.2 开发“个人信用度”微信公众号,进行自媒体推广
开发基于微信公众号的用户界面,为将“个人信用度”推向公众用户,利用全面的线下渠道对公众号进行迅速推广,力争达到让用户感觉好玩、有用、愿意传播分享。同时在用户首次使用时引导关注其他大数据产品,最终实现基于运营商大量的自有资源低成本吸引客户,提高用户黏性。如图5所示。
图5 “个人信用度”微信公众号
2.3.3 开拓在各行业的信用服务应用
在确保数据安全前提下,向个人用户以及政府、金融机构用户提供信用数据查询服务,个人用户可以对历史消费、信用评级等数据进行查询;政府、科研机构用户可以对脱敏处理后的上网行为、地理位置等宏观数据进行查询使用,辅助更好的防范信用性风险,促进征信行业的发展。如图6所示。
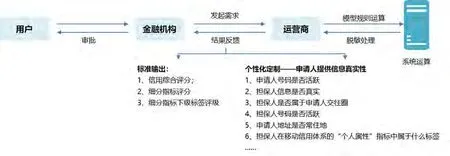
图6 场景应用示例
运营商将持续基于大数据、区块链、人工智能等技术,进一步探索信用服务业务向更全面、更智能、更安全的方向深度融合发展。
3 结束语
金融市场不断扩大,个人信用服务发挥了重要作用,如何提高个人信用识别率,保证多方利益,实现精准的信用评估,建设大数据体系下的信用服务体系具有重大意义。基于运营商大数据的信用服务体系充分利用海量多维度用户数据,相比于传统的个人信用,以运营商的视角信用服务更加多元化、全面地反映了用户信用表现,拓宽了信用可应用的范围,加强了风险防控能力。未来,运营商将持续基于大数据、区块链、人工智能等技术,进一步探索信用服务业务向更全面、更智能、更安全的方向深度融合发展。
猜你喜欢
计算机与网络(2019年8期)2019-09-10
娃娃乐园·3-7岁综合智能(2017年9期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年8期)2018-02-01
娃娃乐园·3-7岁综合智能(2017年7期)2018-02-01
环球市场信息导报(2017年24期)2018-01-24
中国新通信(2017年10期)2017-06-02
当代贵州(2017年10期)2017-05-26
中国新通信(2016年13期)2016-08-12
企业导报(2015年3期)2015-03-11
初中生·作文(2004年11期)2004-11-25
