
企业数字化决策与多维内存分析技术
——基于元年方舟多维数据库(ArkCube)架构
2022-08-04 08:44元年科技高级副总裁李彤
管理会计研究 2022年4期
文 · 元年科技高级副总裁 李彤
一、问题的提出
在数字化转型的大潮推动下,企业信息化架构正在进行互联网化的转型升级。在新一代企业信息化架构下,各种系统产生的数据类型和数据量快速激增,如何利用数据进行科学有效决策、如何充分挖掘数据的价值,成为众多企业的重要诉求。
企业的数据应用主要有两个大的方向。一是面向业务运营的数据支撑。它包括:①通过对消费者数据的洞察,改变销售和交易模式,提高获客和成交效率。目前大多数企业的数据应用聚焦在改变市场销售模式方面。②通过数据模型为供应链管理提供支撑,提高生产经营过程的效率,如排产和计划优化、物流的优化。③大数据+算法成为业务运营的数据赋能主要技术手段。二是面向战略规划和执行的管理决策分析。它包括:①在战略指引下对财务结果进行持续规划和分析是管理过程的核心。②管理会计的预算管理、成本盈利分析、管理报告等工具是战略执行的重要管理工具。③管理会计的核心是基于对企业全方位数据的加工、分析,发现问题,制定战略和相关决策,并对结果进行预测和监控。④规模越大的企业对管理会计的需求越强,支持管理决策的数据模型越复杂。
本文主要探讨在管理决策分析中多维内存分析技术及其计算应用的几个问题,重点阐述元年方舟多维数据库(ArkCube)架构及其主要应用场景。
二、数字化时代决策分析技术的发展历程与全新要求
面向战略规划和执行的管理决策应用,无疑包括了管理会计体系的几项核心内容,如战略规划和测算、全面预算管理、成本管理、管理分析报告体系。这些决策类应用的主要目标是帮助管理者应对企业各种不确定性。这就需要管理会计体系具备敏捷反应,顺应前端业务变化的能力,能够实时获取第一手的业务端信息并及时捕捉到变化中的管理需求,建立业务模型来对可能的变化进行预测、管理和分析。
不同的应用场景对数据技术的需求不同,面向运营支撑的数据应用主要依赖大数据+算法。而面向战略规划和执行的决策场景主要依赖的是利用多维数据技术建立复杂业务财务模型的能力,以及对模型中的数据进行快速、灵活分析的能力。虽然算法在战略决策方面也有重要价值,但是管理决策体系的数据模型中更多的是显式、复杂的计算规则。
数据建模和计算是管理会计应用的关键技术基础。管理会计系统的功能满足度、可扩展性,都依赖系统的建模计算能力。以计划预测和成本分摊模型为例,管理决策数据模型具有以下特点。①数据模型通常具有从业务到财务的转换逻辑,计算规则成链状、网状。②数据来源既包含从业务系统导入的历史数据,又包含人工输入和计算生成的预测和计划数据。③存在大数据量的分摊计算场景,分摊模型需要不断调整,需要较低的时间开销,以保障分析效率。④预测和分摊模型由业务驱动,需要根据业务变化频繁快速调整,业务人员需要独立进行建模和维护。
在这种面向分析的管理系统中,数据是由多个维度(角度)描述的。例如销售收入的数据是由产品、时间、渠道、客户、区域、部门、人员等多个角度进行定义的,在对销售收入的预算或实际发生数据进行分析的时候,分析人员可能会关心按产品、渠道、客户等各维度汇总的销售收入,或者按照不同的维度组合进行数据查询。这些都要求管理会计应用系统建立在一个多维度的数据模型上。
在全球软件市场,企业绩效管理(Enterprise Performance Management,EPM)是指支撑战略执行过程的一系列管理过程与管理软件。类似于Oracle Hyperion、SAP BPC、IBM T M1等领先产品的数据模型,都是构建在OLAP(Online Analytical Processing,联机分析处理)多维数据库之上的。
多维数据库从设计理念上与面向交易的管理信息系统有着本质的区别。基于OLAP的多维数据库技术不同于关系型数据库(OLTP,联机事务处理),主要面向业务分析人员。多维数据库用户的多角度思考模式,预先为用户组建多维的数据模型。维度指的是用户的分析角度,例如对销售数据的分析,会计期间、产品类别、渠道、区域、客户都是维度。多维数据库用维度对数据进行描述和存储,一旦多维数据模型建立完成,用户可以快速地从各个分析角度获取数据,也能动态地在各个角度之间切换或者进行多角度综合分析,具有极大的分析灵活性。
(一)OLAP分析技术在数字化决策领域面临的挑战
从数据库产生以来,数据分析和决策支持的需求就始终存在,为了解决这一需求,IT领域已经为之付出了50余年的努力。OLAP就是这一领域的技术门类的代表。OLAP是关系数据库之父Edgar F.Codd在1993年提出的,作为与OLTP(Online Transactional Processing,联机事务处理)所对应的另一类数据处理能力。这个概念主要用于多维数据分析(MDA)领域,是商业智能(BI)技术的核心。
如前所述,企业决策分析需求长期以来就是由OLAP技术进行支撑的。OLAP按数据存储组织的模式分为MOLAP、ROLAP和HOLAP。其中MOLAP(Multi-dimensional OLAP)是以多维数组存储模型的OLAP,是OLAP发源最初的形态。它的特点是数据需要预计算(Pre-computaion),然后把预计算之后的结果(Cube)存在多维数组里。ROLAP(Relational OLAP)是基于关系模型存放数据,一般以事实表(Fact Table)和维度表(Dimensition Table)的结构来存储数据,不需要预计算,使用标准SQL就可以根据需要即时查询不同维度数据。HOLAP是MOLAP和ROLAP类型的混合运用,细节的数据以ROLAP的形式存放,更加方便灵活。而高度聚合的数据以MOLAP的形式展现,更适合高效的分析处理。HOLAP的目的是根据不同场景来利用不同OLAP的特性。
从发展历程分析,其包括两个大阶段。
(1)独立OLAP数据库阶段。1992年Arbor公司发布Essbase产品。这是一个独立的OLAP数据库产品,在服务器端通过跟业务系统和数据仓库的集成,面向业务人员提供数据建模和决策分析。1998年,Hyperion公司与Arbor公司合并,之后,凭借在管理会计(预算、合并、成本)和BI领域的应用产品与Essbase的集成,一跃成为OLAP市场的领头羊,并持续保持领先位置。2004年Hyperion进入中国市场,成为管理会计和BI领域应用系统的领导者。2007年Hyperion被Oracle收购,借助Oracle的力量在国内大型企业管理会计和BI市场形成了几乎垄断的优势。Essbase作为底层的核心能力,一直延续到今天。
Essbase是一个MOLAP产品,主要优点有:面向业务人员设计,业务人员可以独立完成数据分析建模,实现计算规则,对IT人员依赖较低,Oracle Hyperion基于Essbase的应用产品深受CFO和财务人员的认可;支持数据回写和更新,大并发的查询和数据回写的性能优异;采用预计算的方式来提高查询性能;计算的执行效率远高于关系数据库。但是,Essbase有以下缺点:Cube的维度需要提前规划,增加新的维度需要对数据进行重构;数据规模大的时候,计算的时间开销较大;TB级数据量时,预计算和Cube重构的时间开销巨大。
(2)大数据OLAP阶段。21世纪初,随着互联网的快速发展,非结构化数据大量出现,传统的数据库难以处理。2008年《自然》杂志专刊提出了BigData(大数据)概念。2009年谷歌公开论文提出分布式文件系统GFS、分布式计算系统框架MapReduce、分布式锁Chubby及分布式数据库Big Table,催生了开源的Hadoop平台,成为大数据蓬勃发展的基础。
Hadoop的本质是一个处理非结构化和半结构化数据的分布式系统,要做数据分析需要将数据转换为结构化数据。Hadoop本身并不具备结构化数据处理的能力,于是MPP(Massively Parallel Processing)即大规模并行处理技术开始与Hadoop一起提供大数据量下的新型OLAP能力。简单来说,MPP是将任务并行地分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果。
大数据OLAP阶段的应用主要集中在互联网行业,开源的OLAP产品以其低成本开放性优势占据主流。这类产品以SQL为主要开发语言,主要面向研发技术人员。在应用场景上以PB级海量数据的分布式聚合分析为主,面向互联网行业的业务运营分析场景。对于决策支持和管理会计领域应用场景,这类OLAP产品在数据实时回写、复杂规则计算方面存在较大局限性。
由以上分析可见,传统OL AP技术对大数据环境下的管理决策分析存在一定的计算能力局限性,而新兴的大数据OLAP由于原理和设计场景的差异,主要用于运营分析支持,也不能很好地支持管理决策分析场景。
(二)数字化时代对决策分析技术的全新要求
管理会计系统的应用与实施的成功,不仅要看系统能否成功上线,而且要考虑系统上线后对管理模型变化的适应性和可扩展性。因此优秀的多维数据库产品都把系统用户定义为业务背景的分析人员,可以由分析人员用简单易懂的多维表达式,编写计算公式和计算脚本来完成数据建模和维护。
随着数字化时代来临,企业拥有的数据量在快速增长,数据更精细更全面,对实时性要求越来越高。以某地产企业为例,2008年的经营分析系统的数据量级在GB级,到2017年业务规模增长近10倍,数据精细化程度也有了大幅提升,经营预测和分析的颗粒度由2008年的项目级,细化到了楼栋甚至房间,数据量也增长到了TB级。传统OLAP技术已经开始捉襟见肘,在数据容量、计算时间开销上面无法满足企业日益增长的预测和分析需求。
在全新的数字化时代,企业决策分析对技术方面主要有6个要求。①TB级数据支持:面向决策的数据通常可以在交易级数据基础上进行一定层级的汇总,以减少决策数据的计算量,即便如此,在数字化的趋势下,决策数据的量级也会持续增加,从传统的GB级数据发展到TB级。②亚秒级数据计算:随着企业决策数据量级的逐渐增大,传统数据分析技术在亿级数据量的复杂计算场景下的时间开销通常要以小时甚至天计,无法满足数字化时代快速决策的要求。企业管理者对实时或者准实时的数据分析决策期望越来越高,业界实践表明,亿级数据量实时计算的响应时间应该达到秒级甚至亚秒级。③0代码多维度查询分析:企业决策模型包含组织、区域、渠道、产品、客户、指标、时间、版本等多种业务维度,要支持快速响应多种维度组合的数据的计算、查询和分析要求。业务人员要能够通过Web、Excel等客户端实时访问决策数据,并自助完成多维度的分析和数据查询,无须借助技术人员或者通过SQL等代码语言。④高并发数据回写:数据决策的趋势正在快速地从面向过去的分析向面向未来的预测进行转变。这种转变就要求决策分析技术不能仅仅具备从大量历史数据建立只读的分析模型。而是要具备高并发回写的能力,以预算场景为例,经常有几千甚至上万用户在几天内,并发写入数亿数据;在成本和管理报告分摊计算的场景下,几分钟内要计算并回写数亿条数据,同时用户还会并发地对预测数据进行大量更新操作。这就要求决策平台要具备大并发写入及更新数据的能力,并具备事务机制,保障数据一致性。回写的数据要能够实时参与聚合、公式等分析计算,快速输出分析结果。⑤面向业务的无代码数据建模:分析决策的数据模型是灵活多变的,传统的由管理者和分析人员提出需求,由开发人员通过代码进行模型开发的方式无法满足分析决策的时效性需求。通过无代码、在线的数据建模工具,向业务人员进行赋能,让他们能自助地完成数据模型的设计、计算规则的设计、报表报告的设计。这种设计能力需要是所见即所得,无须编译发布即可生效的。⑥云原生弹性计算:决策分析的场景天然适合云模式,通常会不定期地需要大量的计算资源来完成某些特定的决策计算,通常在几天甚至几小时需要处理亿级乃至TB级的复杂计算,决策完成后计算资源即可释放。因此,基于云原生的微服务化、容器化的弹性计算引擎,是降低决策分析场景的计算资源成本、提高计算效率的重要途径。
可以说,只有能同时满足以上6个技术特性的计算引擎才能支撑未来10年的企业管理决策的要求。
三、升级版的多维内存分析技术:元年方舟多维数据库(ArkCube)架构
元年科技20余年来一直致力于自主可控的企业决策分析平台的研发,通过大量的应用实践和自主创新,推出了自主多维内存OLAP产品元年方舟多维数据库(ArkCube),将ArkCube产品整合到数据中台的整体架构中,并推出了基于元年数据中台的全面预算、报表合并、盈利能力分析、管理报告、数据智能等专业产品。元年管理会计平台产品架构如图1所示。

图1 元年管理会计平台产品架构
为了满足数字化时代对管理决策分析产品的要求,元年将A rkCube产品融入企业数据中台架构,借助互联网、云原生的大数据底座跟多维内存计算引擎的整合,既能发挥大数据平台对海量数据的处理能力,又能延续优秀OLAP产品面向业务分析人员自助维护数据模型的能力。同时,利用数据中台数据驱动业务的思想,让管理会计能更好地将企业管理决策和运营支持进行融合。
(一)企业数据决策平台的总体架构
极具中国特色的“数据中台”概念是企业为了适应不断加剧的竞争环境而不断探索、调适的结果。数据中台的出现为企业数据的有效管理和利用提供了一个全新的思路。数据中台历经2019年的概念普及期,在2020年进入了探索应用阶段。来自CRM、ERP、SRM等各个信息化系统的业务数据、财务数据、大数据,结构化和非结构化数据全部汇入数据中台,实现统一、集中的数据收集、数据治理、数据计算、数据建模,形成服务化的数据应用。
基于数据中台架构的企业管理平台,不仅彻底解决了企业的信息孤岛问题,有力提升了数据采集和数据转换的效率和质量,而且根除了企业IT系统重复建设的现象,为数据存储和数据管理带来便利。基于数据中台,企业可以打通和汇聚多源数据,实现数据资产化和内外部数据的整合,将其实时动态地共享和复用给前端应用系统,实现场景化的数据应用。
图2为元年数据中台总体方案架构,通过主数据、元数据、数据标准、数据质量、数据资产等数据治理功能,有序地管理数据源、数据模型和数据服务。底层采用大数据平台集成来自内外部各类数据源的多种数据。大数据平台支持Hadoop、Greenplum等主流计算引擎,IT技术人员完成从数据源到大数据平台的数据开发。在大数据平台之上的ArkCube多维数据库开放给业务分析人员来进行数据建模,专业的分析模型除了赋能给企业决策者,也能通过数据中台的数据服务,开放给企业的业务端应用来实现数据驱动和赋能。

图2 元年数据中台总体方案架构
将ArkCube融入数据中台体系中,可以更好地支持数据分析以及管理决策工作。
(二)元年ArkCube多维内存分析引擎
元年ArkCube数据库采用自主创新的内存计算技术,具有高性能等优势。为了更好地适应大数据时代的分析需求,元年在高可用部署、基于云原生容器化的动态弹性计算、支持自主可控国产化操作系统、中间件、关系数据库等方面进行优化升级。
元年ArkCube可以满足数字化和大数据时代对管理决策分析的技术要求。元年方舟多维数据库(ArkCube)产品架构见图3。
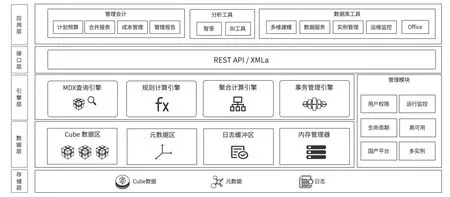
图3 元年方舟内存多维数据库(ArkCube)产品架构
一是TB级数据支持。ArkCube作为内存实时计算引擎,定位为以多维建模和OLAP分析为主的数据集市,可以支持单节点TB级的实时数据分析。测试表明,在单节点服务器中运行800G以上的单一Cube,ArkCube仍有较高的读写和计算性能。由于ArkCube采用了内存实时计算技术,常驻内存的数据仅有输入级别的数据,避免了传统MOLAP采用预计算方法造成的数据爆炸。
二是亚秒级计算。ArkCube采用Tree来存储数据,数据查询和写入的速度优异,Cube数据常驻内存带来了高速的计算能力。在用真实数据进行的测试中,测试数据集包含14个维度,最大维度有13万成员,Cube中有12亿输入数据。不同维度的全量聚合计算耗时如下:按产品维(100+成员)作为行维度进行聚合计算时间,响应时间1s;组织维度作为行维12.7万维度成员进行聚合计算,响应时间2.5s。结果表明,ArkCube可以支持亿级计算量的亚秒级响应。
三是0 代码多维分析。利用Ark Cube的Web客户端,Office、WPS插件,业务人员可以自助连接ArkCube服务进行多维图表的查询分析,不需要使用MDX或者Sql代码。
四是高并发实时回写。利用真实数据集对ArkCube进行单节点压力测试,测试数据集包括14个维度,最大维度有13万成员,Cube中有12亿数据输入数据。测试和实践应用均表明,ArkCube单节点可支持数千至万级的用户规模。
五是业务人员自助建模。业务人员可以在ArkCube客户端完成Cube、维度、图表、计算规则、校验规则的建模工作。对于建模工作中最复杂的计算规则,ArkCube提供成员公式和计算脚本两种模式,业务人员用维度表达式和公式方式(见图4)编写计算规则,无须技术人员协助,也无须像大数据ROLAP技术那样,经常需要进行复杂的性能优化工作。
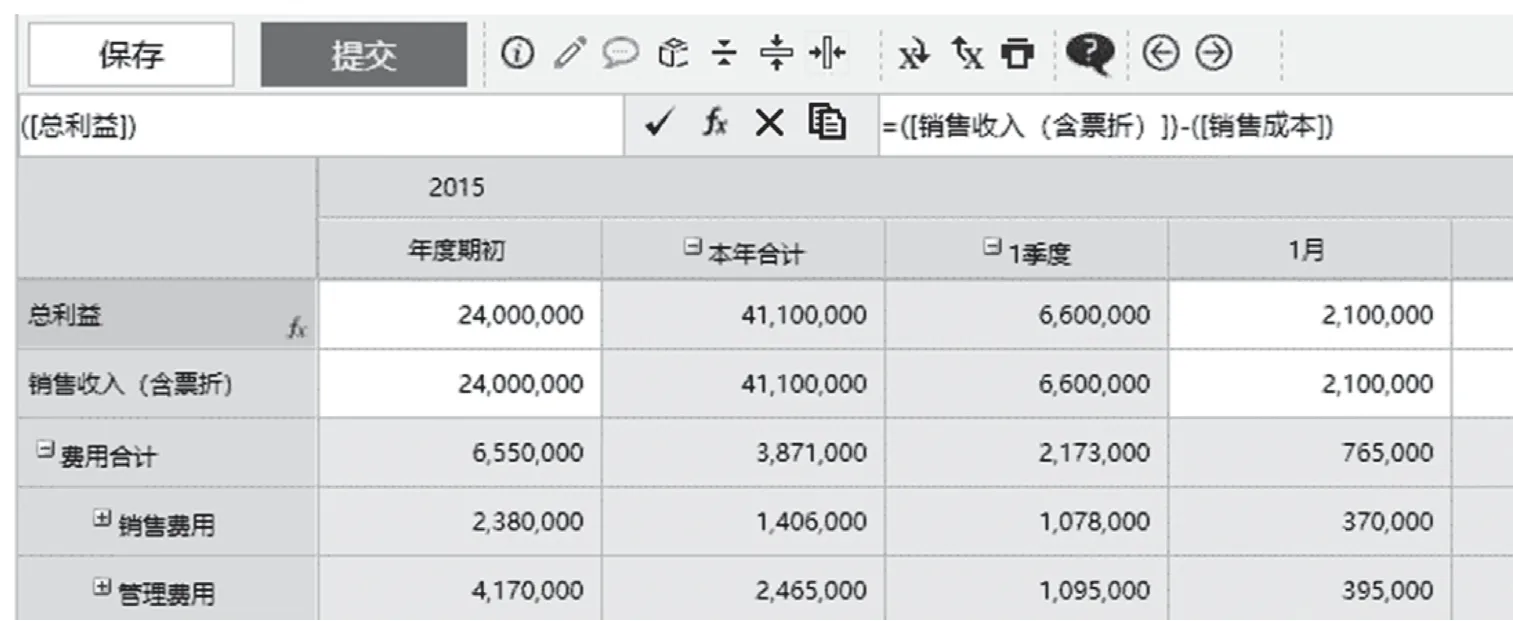
图4 维度成员公式
六是云原生弹性计算。在复杂的TB级,或者百亿量级的数据计算场景下,ArkCube单节点的CPU会成为计算瓶颈。ArkCube基于容器的弹性计算架构可以通过分布式计算来解决单节点的瓶颈问题。
(三)ArkCube的弹性计算架构的应用场景
ArkCube的计算架构存在诸多应用场景。
一是大规模计算任务分解。执行大规模计算任务时,ArkCube可以动态调度带有模型的Docker模板,并按任务分解维度将数据切块以数据文件方式分发给动态的Docker节点,各节点加载数据完成计算后再将结果通过数据文件回传主节点。比如,在保险、银行的费用分摊场景,随着监管和运营决策的精细化的要求,总部、省、市各级机构的费用需要逐级分摊到区域、产品、渠道,最终要分摊到保单或者账户。通常按月进行计算,每次分摊耗时数个小时,过程中还要不断核对、调整,从而造成多次反复分摊计算,采用固定的硬件资源来提高分摊计算的效率投入产出比很低,采用基于容器的弹性计算框架,可以将分摊任务按省分公司进行分解,在动态创建的多个容器中并行计算,计算完成再释放容器资源,可以几十倍提高分摊计算的效率,满足快速出具成本、盈利分析报告的要求,又不会因为计算需求的不均衡造成硬件资源的浪费。
二是用户并发量大且单用户计算量大的负载均衡。例如大型地产集团的项目经常要做项目级的全周期经营预测,根据市场变化,调整产品结构、销售节奏、施工进度、成本支付节奏等变量,设置几百个版本,对项目的全周期内部收益率(IRR)进行敏感性分析,从而选择最佳的经营决策。大型地产集团有几百上千个项目,每个项目要持续做几百个版本的测算,每个用户的计算量在百亿级,当多个用户并发时,单节点计算资源无法支撑,造成用户排队等待。各项目的测算不定期执行,计算资源的需求不平衡,使用固定的计算资源无法匹配不确定的计算需求。利用弹性计算架构,按项目动态生成计算节点并分发数据,响应项目用户的计算请求,用户完成测算后动态节点即被回收。弹性计算架构既可以满足大用户的分布式计算,又可以充分利用云端资源,避免静态的分布式部署模式带来的计算资源浪费。
四、总结
随着数字化时代企业对管理决策和分析需求的快速增长,传统MOLAP技术已经无法支撑大数据环境下的计算需求。而大数据ROLAP又缺乏对管理决策场景的支持,对技术研发依赖过重,业务分析用户很难直接使用。市场急需新型的OLAP产品满足新时代的企业需求。元年方舟ArkCube是一款自主可控的多维内存分析引擎,可以有效地与大数据平台进行整合。作为数据中台的一部分,它可以面向业务分析用户,提供预测、预算、成本分摊和管理报告等复杂计算场景的建模能力,并利用内存实时计算和弹性分布式计算架构,有效地弥补传统OLAP的缺陷,引领企业管理会计应用迈向实时化、动态化和场景化。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
汽车工程(2021年12期)2021-03-08
时代人物(2019年27期)2019-10-23
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
军事运筹与系统工程(2018年4期)2018-03-26
军事运筹与系统工程(2018年2期)2018-02-16
计算机测量与控制(2017年6期)2017-07-01
党政干部学刊(2015年7期)2015-12-24
中南民族大学学报(自然科学版)(2012年4期)2012-11-26
中国土地科学(2011年11期)2011-03-20
