
一种融合生成对抗网络的零样本图像分类方法
2022-08-02 01:44戴晓峰颜金花
计算机技术与发展 2022年7期
刘 帅,黄 刚,戴晓峰,颜金花
(1.南京邮电大学 计算机学院,江苏 南京 210023; 2.南京工业大学 计算机科学与技术学院,江苏 南京 211816)
0 引 言
近年来,随着深度学习的发展,深度学习在自然图像识别领域(如图像识别与分类、图像的文本描述以及图像分割等)都取得了突破性的进展,在对人脸、车牌号等特定的对象识别与分类方面表现的尤为突出。但算法的发展过程中也逐渐暴露出泛化能力差、训练所需数据量大等缺点。尤其是近年来的图像分类数据量都非常大,训练数据过大则导致人工标注难度大,而传统方法分类图像需要大量被标注的标签,因此传统的方法无法满足现有需求。
为了解决上述问题,Larochelle等于2008年提出了零样本学习这一概念[1]。零样本可以将可见类拓展到不可见类而不需要额外的标签[2-8]。零样本图像分类的过程与人类识别未见过的物体很相似,但是人类可以只通过一句话的描述就能识别出物体。例如,如果一个孩子以前见过马,并且知道“斑马”就像一匹黑白条纹的马,那么他/她识别“斑马”就没有问题。零样本分类依赖于一个有标记的可见类,以及一个拥有语义信息描述的不可见类。传统的零样本方法主要是建立视觉空间和语义特征空间之间的映射函数,包括视觉空间到语义空间的映射[2],语义空间到视觉空间的映射[9],视觉空间和语义空间映射到一个共享的隐空间[10]。但是由于视觉和语义之间的差异,相互映射会导致语义信息丢失,最终对图像分类的效果不理想。
同时,由于深度网络的训练缺少注释样本,训练数据生成成为了研究热点[11]。生成对抗网络[12]特别有吸引力,因为它们允许生成真实而清晰的图像,例如,生成以对象类别为条件的图像[13-14]。尽管生成对抗网络已经可以解决多数问题,但是其难以训练和梯度消失等问题仍是一大阻碍。强大的WGAN[15]解决了这些问题。
因此,可以通过融合生成对抗网络来解决零样本存在的问题,利用高斯噪声和不可见类的语义信息生成图像特征,然后利用可见类和生成的图像特征训练分类器。虽然上述方法可以解决零样本存在的问题,但是也引入了新的问题:如何训练出能够生成符合语义信息的图像特征。因此,该文改进了生成器,将生成的图像特征重构回语义信息,从而约束生成器生成高质量图像特征。
主要贡献如下:改进生成对抗网络的生成器网络,在原本生成器网络基础上引入重构网络,将生成的图像特征重构回语义信息,以此来限制生成器,使得生成的图像特征能够更加贴合语义信息,从而确保图像和语义直接的结构相关性。
1 相关工作
本节介绍零样本学习和生成对抗网络,为后面改进融合生成对抗网络的零样本图像分类模型做铺垫。
1.1 零样本学习
在早期的零样本方法中,主要可以分为直接语义预测和模型嵌入两类。其中第一类,直接预测方法,最具代表性的为2013年Lampert提出的两种拓扑结构零样本学习模型,即直接属性预测(DAP)模型以及间接属性预测(IAP)模型。其中DAP,就是对输入的每一个属性训练一个分类器,然后将训练得出的模型用于属性的预测,测试时,对测试样本的属性进行预测,再从属性向量空间里面找到和测试样本最接近的类别。IAP则是利用可见类建立一种关联关系来将测试样本和不可见类相关联,该方法是将测试样本分类到可见类别中,随后根据可见类和不可见类的语义信息建立的语义关系对测试样本进行预测。文献[16]提出利用随机森林算法来训练模型以提高对语义信息的预测准确度,通过对每个类别的属性预测损失来提升预测准确率。基于嵌入的方法则是将可见类和不可见类关联在一个高维向量空间中,即语义嵌入空间,该空间可以是语义属性空间或语义词向量空间。由于视觉和语义的差异,三种语义和视觉空间的映射会导致语义丢失问题。Chen等于2017年提出了SP-AEN模型[17],通过引入一个独立的视觉到语义空间嵌入器来防止语义丢失,该嵌入器将语义空间分解为两个子空间,以实现两个可能冲突的目标:分类和重构。通过两个子空间的对抗学习,SP-AEN可以将语义从重构子空间转移到判别子空间,实现对不可见类的零样本识别。
虽然传统的零样本方法能够在一定程度上实现零样本图像分类,但取得的效果并不理想。于是Xian等[18]提出了利用生成对抗网络体系结构来直接生成图像特征。通过利用可见类训练生成器和鉴别器,以及不可见类的语义信息生成类似不可见类的图像特征来训练分类器,最终使得分类器的效果好于之前的传统方法。
1.2 生成对抗网络
生成对抗网络,最初是由Goodfellow作为一种学习生成模型的方法提出,该模型从一个特定的领域(图像等)捕获任意的数据分布。生成对抗网络由生成器和鉴别器两个部分组成,生成器输入随机噪声试图生成“真实图像”来欺骗鉴别器,鉴别器则区分真假图像,两个网络通过相互对抗的方式进行。在随后的发展中,通过将类别标签,句子描述输入到生成器和鉴别器中,GAN也被扩展为条件GAN。GAN的理论在文献[19]中进行了研究,表明Jenson-Shannon发散会导致不稳定性问题。为了解决GAN的不稳定训练问题,文献[20]提出了Wasserstein-GAN(WGAN),优化了Wasserstein距离的有效逼近。虽然WGAN获得了比原始GAN更好的理论性能,但它仍然受到梯度消失和爆炸问题的困扰。因此,文献[15]提出了一个改进的WGAN版本,通过梯度惩罚对鉴别器进行1-Lipschitz约束来缓解梯度消失和爆炸问题。
2 基于生成对抗网络模型
2.1 问题描述
首先设S={(x,y,c(y))|x∈X,y∈Y,c(y)∈C},其中S代表可见类的训练数据,x∈Rdx为经过CNN处理的图像特征,y表示类别标签Ys={y1,…,yK},由K个离散的可见类组成,c(y)∈Rdc是类别嵌入,例如类y的属性,它模拟类之间的语义关系。另外,还有一个不相交的类标签集Yu={u1,…,uL},包含L个不可见类,其类别嵌入集合U={u,c(u)|u∈Yu,c(u)∈C}可用,但缺少图像特征,以此来训练分类器,最终使得分类器的效果好于之前的传统方法。
2.2 f-CLSWGAN模型
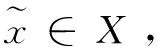
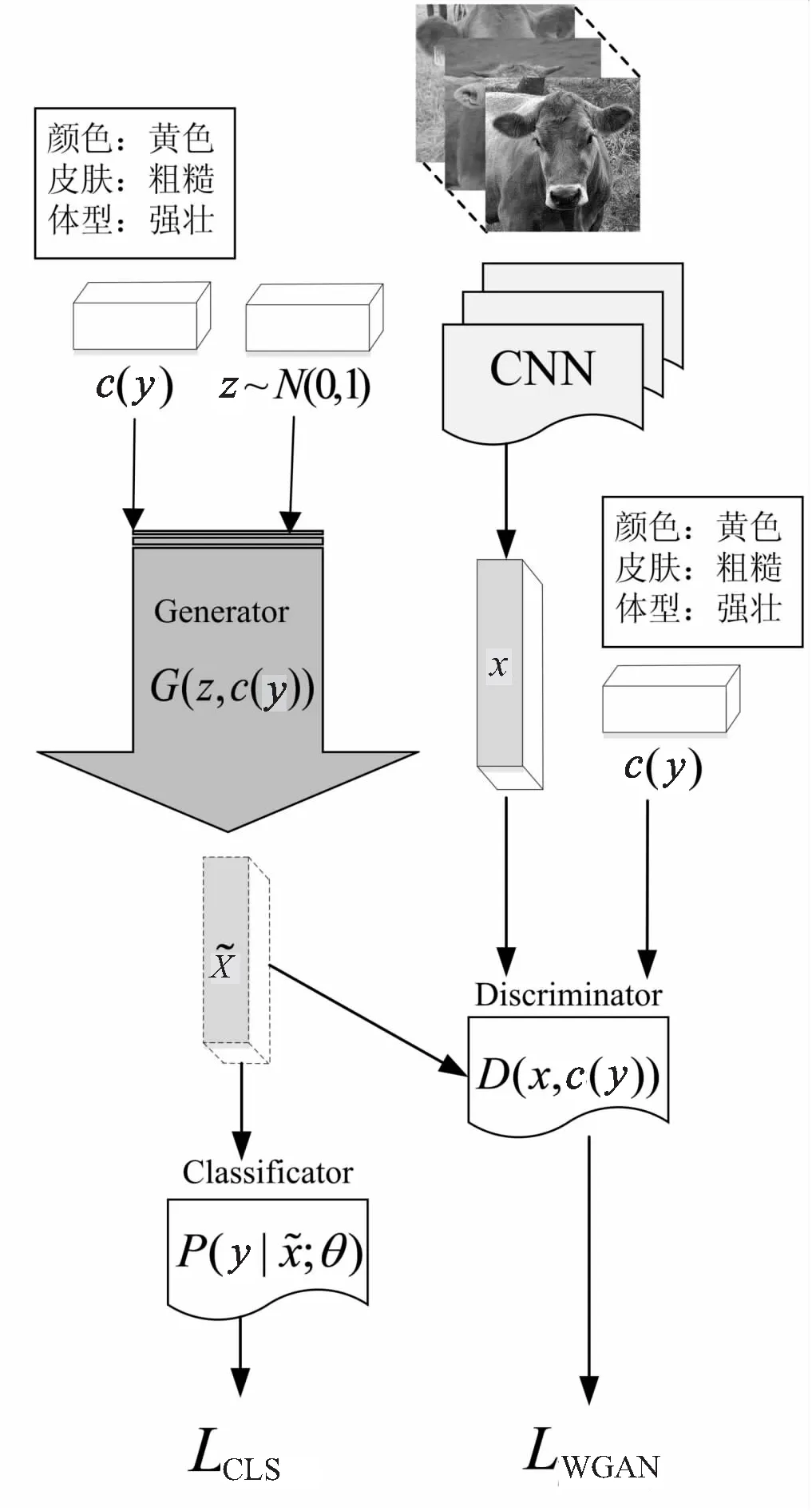
图1 CLSWGAN网络结构
生成对抗网络损失函数LWGAN:
(1)
式中,前两项近似于Wasserstein距离,第三项是梯度惩罚,λ为惩罚系数。
分类器的损失函数LCLS:
(2)
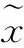
整体的损失函数为:
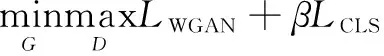
(3)
2.3 改进生成器的模型f-WGRAN
由于生成对抗网络容易产生模式崩溃的问题,仅通过生成器和鉴别器之间相互对抗会使得最终生成的图像特征趋向单一化。计算机视觉的另一种方法─变分自动编码器(VAE)也可以生成图像[21]。VAE由编码器Encoder和解码器Decoder构成。如图2所示,VAE本质上是提取图像的隐性特征,构建从特征生成目标图像的模型。编码器从输入图像中提取均值向量和标准差向量,然后对编码得到的结果向量加上高斯噪声来约束,生成潜在变量,潜在变量服从高斯分布的隐含特征。解码器将潜在变量映射到重新生成的概率分布中。编码之后的分布要与原始的分布越接近越好。

图2 VAE网络结构
VAE的损失函数如下:
L(φ,θ,x)=Eqφ(z|x)[logpθ(x|z)]-
DKL(qφ(z|x)‖pθ(z))
(4)
式中,E为编码器网络,D为解码器网络,qφ(z|x)表示从图像编码成向量的分布,pθ(x|z)表示从向量重构为图像的分布。第一项为解码器D的误差,驱使分布pθ(x|z)接近于输入分布pθ(x),第二项旨在减少KL散度,令qφ(z|x)更接近于先验分布pθ(x)。
VAE本质上就是在对Encoder的均值向量结果加上了高斯噪声,使得Decoder能够对噪声有鲁棒性。而额外的KL损失目的是让均值为0,方差为1,事实上就是相当于对Encoder的一个正则项,希望Encoder出的结果有均值。另外,Encoder的标准差向量用于动态调节噪声的强度。当Decoder还没有训练好即重构误差远大于KL损失时,就会适当降低噪声使得拟合起来容易一些;反之,如果Decoder训练的效果不错,重构误差小于KL损失,这时候噪声就会增加,使得拟合更加困难,这时候Decoder就要提高Decoder生成能力。
基于VAE网络的原理,推理出可以在f-CLSWGAN的基础上引入重构网络来比较生成器生成的图像特征和原始的语义信息之间的差异来约束生成器,以改进f-CLSWGAN模型,提升分类准确度。
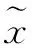
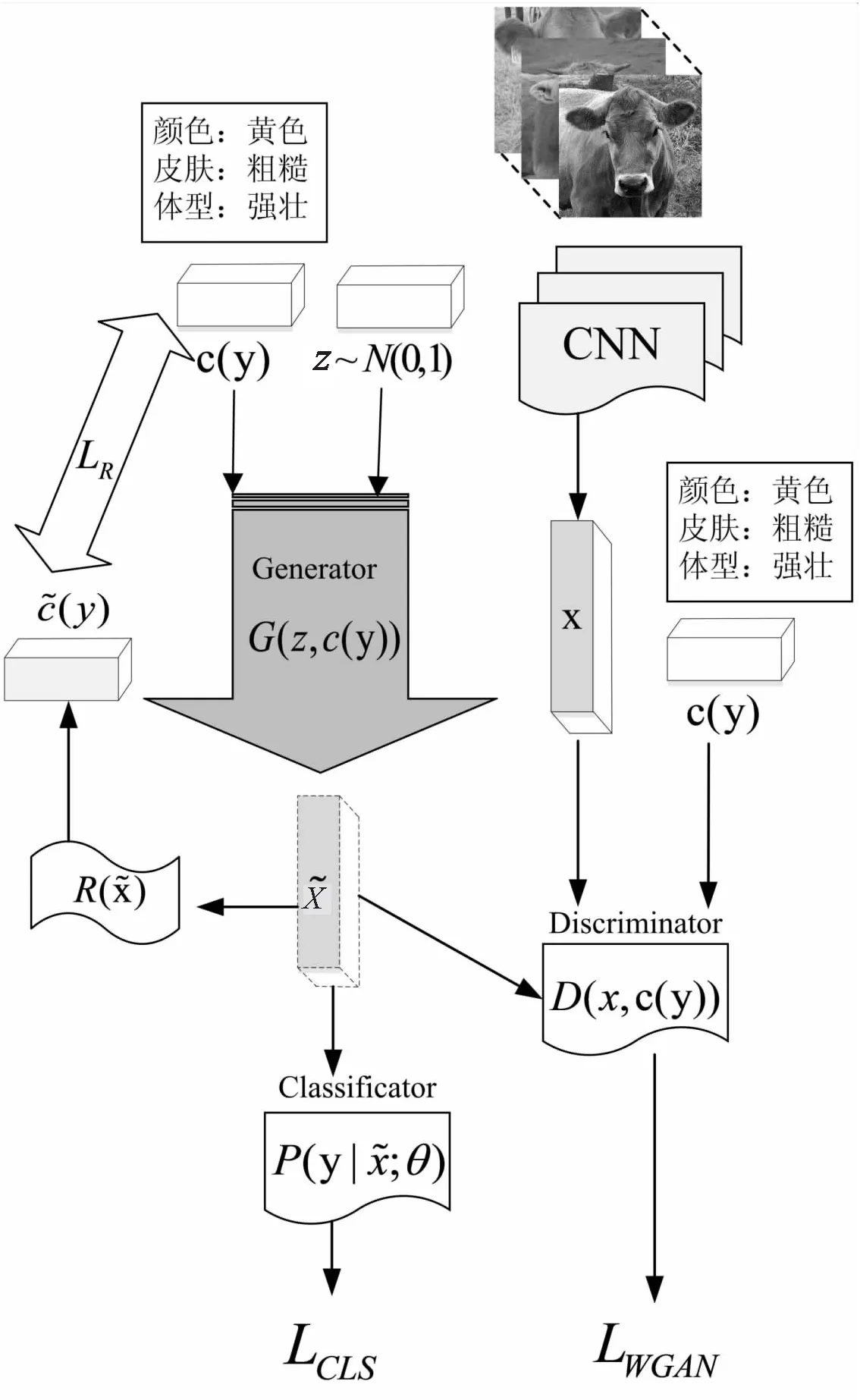
图3 f-WGRN网络结构
重构网络的损失函数如下:
(5)
生成对抗网络损失函数LWGRAN:
(6)
整体的损失函数为:
(7)
3 实 验
3.1 实验数据集
实验采用了4个不同的经典数据集,分别是AWA[4]、CUB[22]、FLO[23]、SUN[24],其中CUB、FLO、SUN都是细粒度数据集,AWA是粗粒度数据集。CUB包含来自200种不同的类型鸟类的11 788张图片,这些图片带有312种属性。FLO有102种不同类型的鲜花图片共8 189张,但是没有属性注释,所以通过视觉描述对FLO进行注释。SUN是一个场景数据集,其包含717个场景的14 340张,且场景标注有102种属性。AWA是一个动物数据集,包含30 475张图片,共用50个类别,包含85种属性。
数据集具体参数如表1所示,同时将数据集分割为两部分,可见类作为训练集,不可见类作为测试集,可见类与不可见类之间没有交集。
表1 AWA、CUB、FLO、SUN数据集
3.2 数据集处理
参考Xian等的对于数据集的操作,采用Res101[25]对整幅图像提取2 048维的图像特征,并在ImageNet上进行了预训练。没有对图像进行预处理,例如裁剪或者其他的数据增强技术。此外,把每个类别的属性AWA(85维),CUB(312维)和SUN(102维)作为语义信息。对于SUN和FLO,从细粒度的视觉描述(每幅图像10句)中提取了1 024维的基于字符的CNN-RNN特征。
3.3 实验结果与分析
该模型在ubuntu16.04、Python2.6、pytorch环境下搭建,在一张Tesla P100显卡上训练并测试。实验在四个不同数据集上分别进行了100轮训练,图4为四个不同数据集的分类准确度。
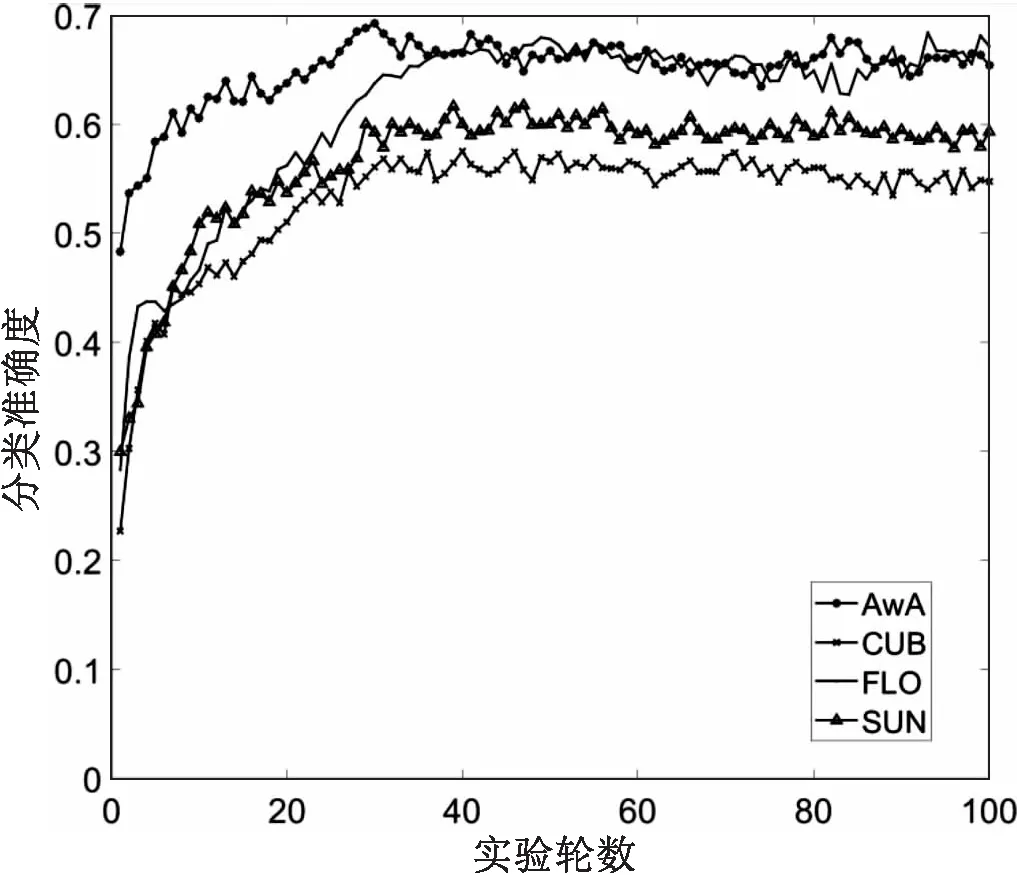
图4 实验结果
可以看出,该模型在训练AWA上只经过了30轮训练便达到了最大值,随之便逐渐下降;在CUB数据集上数据震荡较大,在45轮左右达到最大值;在FLO数据集上经过40轮训练后开始在最大值附件震荡,直到95轮左右达到了最大值;在SUN数据集上,经过30轮训练后,便逐渐趋于稳定。分类准确度的训练轮次能够很快达到稳定,主要原因在于f-WGRAN模型采用了重构网络,可以约束生成器使得生成的图像特征与语义信息的相关性更加紧密。
3.4 与不同方法的比较
与不同方法对比结果如表2所示。观察实验结果可知,f-WGRAN关于四种不同数据集的分类准确度均优于之前的方法。同时,可以看出引入生成对抗网络的模型分类准确度明显高于传统的零样本图像分类方法。原始的f-CLSWGAN网络模型只是利用生成器和鉴别器直接相互对抗,使得生成的图像特征越来越单一。而提出的f-WGRAN模型对生成器进行改进,引入重构网络来限制生成器生成更符合属性的图像特征,从而使得分类准确度有所提升。
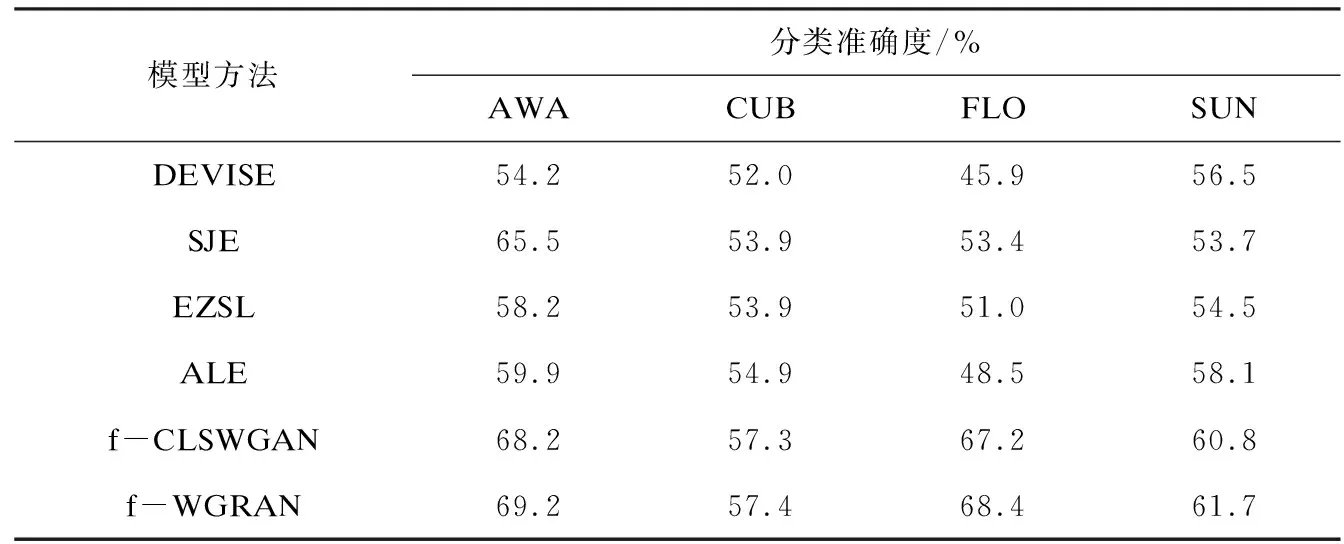
表2 不同模型方法在4个数据集上的分类准确度比较
该模型在AWA数据集取得了69.2%的分类准确度,比f-CLSWGAN模型提升了1.0个百分点,在FLO和SUN模型分别取得了68.4%和61.7%的分类准确度,相比f-CLSWGAN分别提升了1.2和0.9个百分点,在CUB数据集上几乎没有提升。实验证明,f-WGRAN能够取得更高的分类准确度,证明该模型方法是可行的。
4 结束语
零样本图像分类经过十多年的发展仍是深度学习领域的具有挑战性的研究方向[26-27]。该文通过分析以往的零样本分类方法,分析存在的问题,结合生成对抗网络提出了一种利用生成对抗网络生成图像特征来进行判别的模型f-WGRAN,以此来解决零样本图像分类问题。f-WGRAN在生成对抗网络上增加一个重构网络,通过将生成器生成的视觉特征重构回语义信息,以此来限制生成器生成更符合属性的图像特征,加强了生成器的特征生成能力,并且在很少的轮次就可以达到最大分类准确度。经过实验论证,该模型分别在AWA、CUB、FLO、SUN四个数据集提升了1、0.1、1.2和0.9个百分点。该文主要针对生成对抗网络来进行改进,并且此改进可以应用于不同的生成对抗网络上。在后续的工作中将考虑如何提升鉴别器的鉴别能力。
猜你喜欢
中国德育(2022年9期)2022-06-20
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
天津诗人(2017年2期)2017-11-29
数学学习与研究(2017年3期)2017-03-09
长江学术(2015年1期)2015-02-27
计算技术与自动化(2014年1期)2014-12-12
