
安全运营中告警全面性和告警过载的平衡实践
2022-08-01 02:32:08奇安信科技集团股份有限公司黄巍
网信军民融合 2022年1期
◎奇安信科技集团股份有限公司 黄巍
一、告警过载已成为SOC 有效性的最大挑战之一
近日,一项全球调研显示,超过70%的安全运营团队认为,他们的工作及家庭生活受到了告警过载带来的严重影响。受访者表示正在被大量的告警淹没,并承认他们没有信心能够确定告警优先级并及时做出响应。据统计,受访者仅进行误报处理就占据了工作时间的四分之一以上,这揭示了当前安全工具难以解决众多安全系统生成的告警的现实情况。此外,在面对巨大告警过载压力时,部分受访者承认曾选择关闭告警(43%)、离开计算机(43%)、寄希望于团队其他成员介入(50%)、甚至选择忽略(40%)。研究显示,受访者表示由于告警过载引发的疲劳和焦虑,还侵犯了他们的家庭生活,甚至在情感上对其造成了巨大损失:70%的受访者表示,他们在工作之外的时间也感受到巨大压力,以至于他们难以在生活中放松,并且对朋友和家人表现出烦躁情绪。
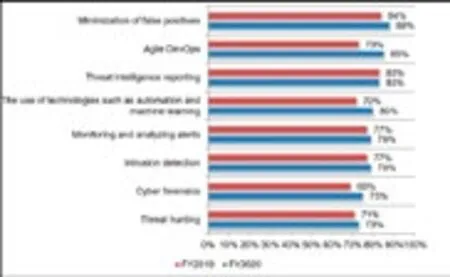
波耐蒙研究所(Ponemon Institute)于2020 年和2021年分别发布了两份题为《SOC 经济学:出效果到底要花多少钱》的系列调研报告。本次调研报告最终有效样本数为682份,调研对象主要为大型企业安全运营中心(SOC)的管理者。报告显示,在受访者心目中,最重要的SOC 活动排序第一的为“降低误报”(88%),而安全厂商更看重和强调的“告警监测”(79%)“威胁检测”(73%)能力,仅仅排在第五位和第八位。这样的调研结果与我们的固有认知存在较大差异,然而这却代表了众多安全运营团队的真实诉求。
二、造成告警过载的原因
原因一:安全设备和产品众多,造成海量数据输入并引发数据重复
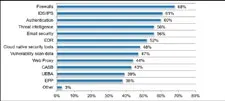
随着国内大型企业和机构安全建设的逐渐成熟,所采购和投入使用的安全设备和产品也越来越多,因此,安全运营中心(SOC)需要监管的海量数据和资产信息正在爆炸式的增长。调研报告显示,SOC 监管最多的安全产品依次是防火墙、IPS/IDS、认证系统、威胁情报、邮件安全、云安全、EDR、漏扫、中间件、终端安全等产品。除了十种典型安全产品,SOC 还需要监管诸如数据库审计、上网行为管理、堡垒机、4A 认证、VPN 认证、零信任认证等众多审计类产品的海量数据和告警等。
但在数据量增长的同时,也会引发严重的数据重复现象。由于单个安全产品能力越来越趋向于多样化、多功能,这势必造成部分安全产品的能力重合,例如NGFW、UTM、IPS、流量探针等网络安全设备可能对同一份网络流量检测出常见的网络攻击事件,其内容大同小异,而这样的重复部署会对SOC 分析师和运营人员的工作量造成数倍的增长。这是造成告警过载的首要原因,且当前呈现出日益加剧的趋势。
原因二:安全运营工具未能对海量告警进行有效降噪、去重、归类合并
作为安全运营的重要工具,安全运营平台类产品正迅速得到普及,此类产品产生的初衷是帮助安全团队管理爆炸式增长的数据和各类信息,以实现一站式的告警监测和多源的日志管理。然而,事实上多数平台并未有效地解决因数据量过大和数据重复引发的告警过载问题。究其原因,主要在于平台难以对各安全产品上报的告警数据进行有效的质量评估、过滤、去重和归类合并,即平台未能自动地对明显无效、质量差、价值低的数据进行筛选过滤,也未能有效地对重复或反复发生的告警进行自动化地去重和归类合并,从而造成了工作的低效。
原因三:人是SOC 运营成功的关键,但人才的发现和培养过程困难
Ponemon 发表的调研结果表示,人(分析师)是SOC成功的关键,也是SOC 成本支出的主要部分。SOC 需要的人才数量多,且分析师的雇佣成本也相对较高,在招人、育人、留人方面也很困难。调查显示,招聘到一名分析师平均耗时3.5 个月,培训时间约为3.8 个月,但分析师在一个企业的供职时间平均只有27.2 月(2 年左右),即人员的流动性也很高。如下图:

从分析师的角度来讲,他们工作的痛苦也在不断加剧。70%受访者承认,由于告警过载、信息过载、7x24x365 全年无休等问题,使他们感到精疲力竭,这直接促使了人员的流失和招聘困难,进而导致更多的告警无人分析和及时响应,又加重了SOC 的失效。这是一个恶性循环的过程,因此如何平衡告警过载带来的压力,缓解运营人员的工作负担,已成为SOC 亟需解决的问题。
三、应对告警过载的案例
本文通过实践案例来分享解决告警过载问题的经验:国内某大型新能源企业下设多家分公司、多个数据中心及海外办公区,且安全基础建设相对成熟,拥有的终端/服务器超过5 万台,拥有的网络安全设备和审计类产品有数百种,其安全运营中心(SOC)每天仅收到的网络威胁告警就数以十万计,安全团队承认,他们最多处理全部告警的十分之一,其压力也可想而知。
(一)理性选择需要监测的数据源
首先,安全团队应理性评估各类安全产品的能力覆盖范围和数据重合度,安全产品并非采购的越多越好,如不合理规划和分配各安全产品的职能,难免会造成不必要的浪费,避免安全能力的重合。对于明显重复的数据,例如捕获相同流量的FW、IPS、流量探针,要对数据质量进行评估,并选择过滤,以保留数据最全、质量最好、检出率最高的设备告警作为告警首要呈现来源和主要分析对象,而其他日志仅用于存储和辅助分析,不作为首要对象去分析。
(二)主动降噪无效告警
该企业拥有众多对外提供服务的网站应用,这些应用暴露在互联网难免遭到无数探查和尝试攻击行为,但DMZ区已部署WAF,绝大多数的探查和攻击行为都可以被阻拦,且WAF 已上报相关的告警事件,但攻击特征却在流量中被防火墙、IDS、流量探针等重重把关的安全设备检测到并重复地报出告警。原则是此类重复告警应被主动过滤,而不作为首要对象进行呈现,更不应该重复呈现。为此,企业制定了数据过滤策略:通过告警中的“响应码”“上下行字节数”“攻击结果”“是否阻断”等关键字段进行过滤,以过滤无效告警,仅做入库存储用于必要时的溯源分析,而不再呈现给分析师,这成功将告警总量从10 万级别降至1 万以内,减少了90%的无效告警。
(三)深度关联资产信息,去除重复告警
因负载均衡、代理服务器、多级DNS 服务器等设备将网络请求进行转发,转发前后的流量同时被捕捉,流量中的攻击事件被网络安全设备(IPS、流量探针、WAF)进行重复检测,从而造成告警数量的翻倍。例如常见的恶意域名请求事件,下级DNS 服务器对上级DNS 服务器的域名请求同样产生告警,且无法定位真实请求源,这是典型的既重复又无效的告警。为解决此问题,企业将告警关联请求源IP 属于客户的下级DNS 服务器的告警进行过滤,这可以减少约50%恶意域名请求的告警数量。此外,通过分析还发现,由于该企业的NGINX 代理服务器转发前后的流量都会被捕获,因此转发后的请求流量存在告警重复且无法定位攻击源的问题,这将难以在第一时间对来自互联网的攻击者进行定位和封禁。基于此,企业也进行了过滤,凡是攻击源来自于NGINX 服务器代理地址的告警,都不作为首要关注目标,而只关注请求转发前的攻击事件。
此类告警优化策略应建立在对企业资产信息充分了解之上,需要掌握企业的部分关键资产信息,尤其是对于容易引起告警重复、误报的资产信息要有清楚的认知,并应通过运营工具将这些信息与告警进行自动关联过滤,例如客户定期漏扫、云监测、资产探查等服务都会周期性的引发告警。若分析师不清楚这些资产信息,势必存在误导和困扰,造成过大工作负担。
(四)告警归类合并
通过上述的降噪和过滤策略,已经可以将告警数量显著下降至每日数千条,这可以减少约94%无效、重复告警,但对于人员有限的SOC 分析师来说,这个数据还是很大,仍存在很多担忧,如因无法一一查看这些告警而被迫忽视真正高危的安全事件。通过继续分析告警类型可以发现,很多告警虽不重复,但却是反复发生,例如常见的弱口令事件、信息泄漏事件、敏感目录访问事件、未授权访问事件等,都并非攻击性质的事件,而是属于脆弱性事件或称之为管理疏忽事件。这类事件因涉及太多主机、用户和服务,因此会引发海量告警,而仅按照IP、用户名、主机名去归并也无法完全解决问题。此类事件应进行合理的归纳总结,而不是面面俱到的一一展示,以避免造成告警的堆积,淹没其他更具分析价值的真实攻击事件。通过积极调整检测规则的“归并策略”,可将此类告警在规定时间窗口内产生的所有告警合并为一个事件,并做好事件分类,使这类脆弱性事件不与其他网络攻击事件混为一谈。客户只需周期性的查看该事件并督促该事件中涉及的所有用户和主机责任人进行整改即可。此外,还需对不同类型事件进行分类和定级,例如威胁情报事件的可信程度极高应该首先被关注,内网攻击事件优先于外部攻击事件,重点资产的安全事件优先于用户终端的安全事件等。通过这些合理的分类和定级可以帮助分析师确立优先级,定向地去查看,以提高工作效率。
至此,通过主动降噪、告警去重、归纳合并等策略可以将告警数量从每天十万条降至每天约800 条,平均每1 亿条日志仅呈现给分析师24 条高度归纳总结后的事件,作为SOC 分析师调查分析的入口。
安全运营平台作为大型企业一站式告警监测与多源日志的管理平台,在优化工作中扮演了重要角色。优秀的运营工具通过加工的日志存储和过滤的告警呈现,更加智能有效地帮助安全团队解决非核心业务,让安全分析师将更多精力和时间专注于告警分析和事件响应这种核心业务上,不被告警过载问题所困扰。
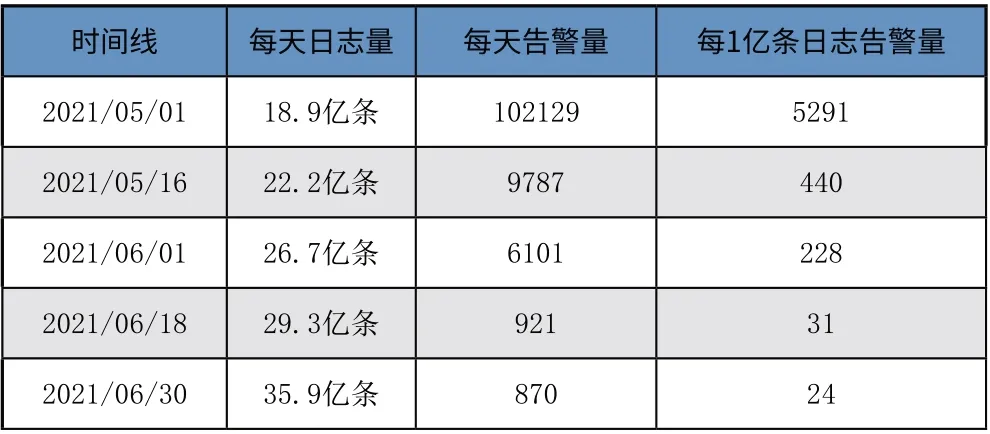
时间线每天日志量每天告警量每1亿条日志告警量2021/05/01 18.9亿条102129 5291 2021/05/16 22.2亿条9787 440 2021/06/01 26.7亿条6101 228 2021/06/18 29.3亿条921 31 2021/06/30 35.9亿条870 24
猜你喜欢
小康(2022年28期)2022-10-21 02:35:38
小康(2022年19期)2022-07-09 10:41:00
小康(2022年16期)2022-06-13 05:05:44
华人时刊(2021年13期)2021-11-27 09:19:02
时代邮刊(2021年8期)2021-07-21 07:52:36
心声歌刊(2020年4期)2020-09-07 06:37:14
小学生(看图说画)(2017年6期)2017-11-06 06:48:08
股市动态分析(2016年24期)2017-01-07 08:59:13
股市动态分析(2016年23期)2016-12-27 19:07:33
股市动态分析(2016年18期)2016-10-11 14:01:07
