
包围圆分割在铁路货车车号字符的应用
2022-07-28 06:19:54靳延伟张晓丽
重庆大学学报 2022年7期
靳延伟,董 昱,张晓丽
(兰州交通大学 自动化与电气工程学院,兰州 730070)
近年来,随着铁路建设信息化的发展,面向图像的铁路货车车号识别问题受到了诸多研究学者的关注。目前,铁路货车车号的定位问题已经发展得比较成熟,但识别准确率还有待提高,在进行调研之后,车号的识别主要分为2种模式:一种是基于整个车号字符的识别,另一种是基于单个字符的识别。前者对定位后的结果进行直接识别,省略了分割的步骤。目前比较成熟的整体识别算法有卷积循环神经网络(CRNN,convolutional recurrent neural network)及系列变种等[1-3]。传统CRNN模型是由基于卷积神经网络组成的特征提取层、由循环神经网络构成的预测层及转录层构成,相比传统网络有诸多优势,但存在训练网络需求数据量巨大、训练时间长且易产生梯度消失等问题。基于单个车号字符识别的分割算法需要预先将车号字符分割成单个字符,对分割后的单个字符进行识别。可以看出,这种方式分割结果的好坏会直接影响到识别准确率的高低。因此,文中针对铁路车号分割的问题展开研究。
货车车号字符分割问题与汽车车牌类似,同属于文本分割问题。现有字符分割方式主要有2种:1)基于投影的方法[4-8]。该方法主要是利用字符间距中没有文本,沿着文本行的垂直方向及水平方向进行投影,仅针对正平行或近似正平行的图像文本,但对于透视变形、倾斜的文本需要预先校正,直接处理效果不理想。2)基于连通域的方法[9-11]。通过聚类算法获取文本连通区域,利用矩形包围框的相邻关系进行区域合并或分裂。但矩形包围框均是正平行的矩形框,应用于曲线排列、倾斜及存在透视变形情况的字符很难精确描述单个字符位置和大小。另外,基于形态学和基于神经网络的方法也被应用到字符的分割问题中。
从现有采集数据来看,定位后的车号区域字符具有以下几点特征:1)铁路货车车号一般漆刷在车身左上角和中间下端边缘处,图像是在车辆运行情况下拍摄采集,字符普遍会出现倾斜问题;2)拍摄装置硬件原因会导致采集图像变形,字符出现扭曲排列现象;3)铁路货车长年在野外行驶,环境恶劣,车号字符局部颜色淡化导致字符部分缺失;4)车号漆刷的样式多变,有单双行2种方式,漆刷位置易受到车号栅栏结构的影响。
基于以上特征的考虑,文中针对货车车号字符的特点,采用自适应游程平滑算法对双行车号进行行分割,重新设置算法参数,对单行的字符进行区域合并,消除或减小字符的断裂程度,再利用文献[12]的思路进行单个字符分割。为验证算法的有效性和鲁棒性,文中收集货车车号数据图像集500张进行算法验证,实验结果表明,文中所提出的算法可以实现铁路货车车号字符的准确分割,具有良好的实际应用价值。
1 双行车号分割
铁路货车车号存在单行车号、双行车号2种类别,在进行车号字符分割之前,预先需要将双行字符分割成2个单行字符。文中采用自适应游程算法(ARLSA,adaptive run length smoothing algorithm)进行铁路货车车号的行间隙判断。自适应游程平滑算法[13]是由Nikolaou等提出,广泛应用于版面分割。利用对二值化图像同一水平行的背景像素点进行距离计算,将位于同一行的单个字符连通域进行合并,不同连通域之间以空白区域隔开,实现文本行分割的目的。此算法对图片质量要求比较低,在图片有阴影、光照不均、低对比度及污损等情况也可以实现文本行的精确分割。
1.1 图像预处理
自适应游程算法本质上是对将背景区域像素点进行前景化处理,所以需要将原始三通道图像转化成二值化图像。因此,文中采用改进最大类间方差算法(OTSU)[14]进行图像处理,处理结果如图1所示。但二值化图像中存在较多由于货车车身栅栏结构引起的长条状、线段等背景干扰信息,可近似看作多条直线段构成,由此,文中采用霍夫直线检测算法[15]进行直线检测经过直线拟合得到图像I2,并与原二值化图像I1作“同或”运算,得到消除背景干扰后的图像I3。相同位置像素点进行“同或”处理,如图1中c列所示,图中红色像素点为经霍夫检测算法计算出的直线区域,与图I1相比,图I2中的直线区域的像素值不同,因此,选择进行“同或”运算,对检测出的直线进行滤除,以此达到消除直线的目的。

图1 预处理结果部分示例图Fig.1 Some examples of preprocessing results
1.2 双车号分割
1.2.1 自适应游程算法原理简介
在列车运行过程中,相机拍摄角度不当、车号字符漆刷方式、铁路货车车身复杂的栅栏结构等原因会导致图像倾斜、字符出现断裂以及出现大量干扰信息等问题,传统的直线分割法已经不能正确将双行车号进行正确分割,自适应游程算法是现有页面布局分析和分割技术中最常用的算法之一,目的是将同一个文本区域重新组合在一起,可以将同一字符的各断裂部分重新连接,根据以上特点分析,文中参照文献[13]的思路建立的双车号分割模型。
在应用之前,需要进行连通分量分析。考虑了2种背景像素(白色)序列。第一种类型涉及发生在属于同一字符的2个前景像素(黑色)之间的序列,在这种情况下,将序列的所有背景像素替换为前景像素。第二种类型的背景像素序列发生在2个不同相邻字符之间,在这种情况下,针对连接字符的几何特性设置约束,并且在满足约束条件时执行前景像素替换。
自适应游程算法中,设定Ci、Cj是图像第i、j个文本连通域,如图2所示。

图2 文本连通域示意图Fig.2 Connected domain of the text
S(i,j)表示文本连通域Ci、Cj之间背景像素的水平序列,相关参数如下所示:
1)L(S)是序列的长度,表示背景像素点的个数。
2)HR(S)表示连通域Ci、Cj包围矩形框的高度比为

式中:hi、hj表示连通域Ci、Cj包围框的高度值。
3)OH(S)表示2个文本连通域Ci、Cj包围框之间的宽度交叠值为
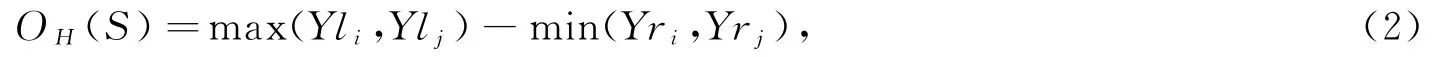
式中:(Xli,Yli)、(Xri,Yri)分别表示连通域Ci的左上角坐标和右下角坐标。当OH(S)<0时,表示两连通域水平方向有背景重叠部分存在。
4)N(S)是一种二值化的输出函数,若文本连通域Ci与Cj之间的背景水平像素序列S(i,j)的3×3邻域的像素均仅介于Ci与Cj之间,没有第三个文本连通域存在,则N(S)的值置为1。否则,N(S)置为0。背景像素平滑示意如图3所示。

图3 背景像素平滑示意图Fig.3 Background pixel smoothing diagram
基于以上指标的分析,背景像素点仅在满足以下条件的情况下才能转换成前景像素点。判断条件为
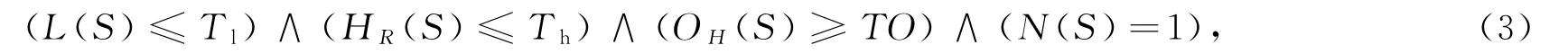
式中:从两文本连通域之间连续背景像素点数目L(S)、文本连通域包围框的高度比、宽度交叠比,Tl、Th、To为预先设定阈值,其中,Tl和To为

式中:阈值Th被设置为1.7是基于铁路标准TB/T1.1对于铁路车列字符漆刷的字体要求,双行漆刷的车号下标字符的高度为120 mm,正常字符高度为200 mm,单行车号的下标字符漆刷高度为120 mm,正常字符漆刷高度为70 mm。从已收集的数据来看,字符高度比集中在1.6~1.7之间,因此,将Th的值设为2,为同一文本行的字符之间的字体大小变化提供了足够的公差。
自适应游程算法实现双行车号分割以及单个字符的分割算法优化,因此,结合货车车号字符特征,对算法参数进行讨论。参照铁道车辆标记规范TB/T1.1文件,规定车号相邻较小字符高度与字符间隔比值为4~10。因此,实现双行车号分割时,应尽可能将同行的所有字符重组成一个连通域,设定α值取最大值10作为初始值讨论;实现单个字符分割时,应将同一字符的各连通域进行组合,不同字符连通域之间避免组合,α值应取小于最小值,因此,文中将α设定为3.5作为初始值进行讨论,c值设定0.4进行讨论。双行车号的分割实验结果如图4所示,可以看出,实现α=12、c=0.4时,双行车号的分割精度最优,重新组合后的连通域具有更光滑的边缘。

图4 参数α对双行车号分割结果的影响Fig.4 Influence of parameterαon segmentation result of double line vehicle number
对于车号字符分割,应用算法的结果如图5所示。可以看出,自适应游程算法可以很好地解决字符断裂问题,当α>3时,下标字符出现了过填充的情况,会将相邻字符重新组合成一个连通域,造成误分割;当α=3时,可以将同一字符组合成一个连通域,避免了将相邻字符组合,实现了字符内部断裂消除,分隔开相邻字符。因此,在实现单个字符分割时,将α设定为3,c设定为0.4作为优化算法的参数。

图5 参数α车号字符分割结果的影响Fig.5 Influence of parameterαon segmentation result of vehicle number character
1.2.2 算法应用
自适应游程算法将同一行的字符重新组合在一起,同时检测出双行字符之间的间隙作为行障碍物。将行障碍物的位置作为双行车号字符的分割点,实现分割目标。在应用游程算法之后,垂直白游程直方图hv(w),对于行障碍物的检测,将值小于Mv=argmaxhv(w)的白色游程序列作为文本行障碍物,其中Mv表示不同车号字符行之间的白色像素游程距离。图6所示为车号障碍物检测结果部分示例。其中,蓝色表示行障碍物,绿色表示不同行之间可能的水平连接。所有连接属于不同车号行的对象都被障碍物隔开。

图6 车号分割结果部分示例Fig.6 Some examples of vehicle number segmentation results
从图6可以看出,文中采用的自适应游程算法可以准确检测出不同行车号字符之间的间隔,实现双行车号的准确分割。
2 基于包围圆几何参数的字符分割
图像采集于货车运行过程中,图像采集设备和货车车号位置不是正对关系,并且由于安装相机不够平稳、车号字符出现断裂等原因造成拍摄车号图像出现非水平排列或有透视变形的问题,考虑到车号字符排布的多样性,会出现透视变形、字符断裂的特征以及包围圆的无向性等问题。笔者参照文献[12],选择圆代替传统矩形框作为字符连通域的外接形状,通过确定包围圆的几何参数作为车号字符的位置,从而达到分割点目的,但以往成果研究结果表明,基于包围圆的方法对相邻字符字体断裂的情况下会出现错分情况。
2.1 包围圆构建
包围圆的构建方式为

式中:(ui,vi)表示第i个文本连通区域的第j个前景像素点的坐标;Ni、(ui,vi)及Ri分别代表第i个连通区域的像素数目、包围圆圆心和半径。并由式(6)得出各连通域的包围圆参数。
2.2 文本连通域的捆绑原则
铁路货车车号字符在漆刷时候有垂直方向的断裂现象,单个字符的各个断裂部分并不是在同一个连通域中,为了准确合并同一字符的各个部分,设立相交比原则、互相交原则进行区域合并。相交比定义为

式中:A(.)表示面积;ci和cj分别表示第i个、第j个文本连通域的包围圆。相交比原则是根据式(7)求出两文本连通域的两相交比,并根据设定阈值s比较是否需要合并。由式(7)确定两圆的相交比,若其大于指定阈值U,则合并对应的连通区域。
不同货车号字符的字符连通域的包围圆的结构如图7所示。其中,p1和p2的相交比接近1,确定为同一字符区域,进行区域绑定;p2和p3包围圆面积交叠比为0,确定为不同字符区域。以上是对相交比原则的绑定结果体现,由于字符本来漆刷特点以及后期处理后出现局部断裂问题,造成车号字符有几块区域构成,所以设定互相交原则进行连通域的绑定。如图7所示,p5与p3相交、p3与p4相交、p4与p5相交,构成一个封闭环,根据互相交原则,将p3、p4、p5绑定位同一区域。

图7 不同连通域的位置关系示意图Fig.7 Schematic diagram of location relationship of different connected domains
经过实验仿真,在相交比原则的阈值设定为0.4、互相交原则阈值设定为0.04时,分割效果精度最优,分割示例如图8所示。可以看出,在出现字符断裂或相邻字符字体差异较大或的情况下,会出现错分情况。因此,文中利用自适应游程算法对字符预先进行连通域重组,将同一字符不同连通域进行合并重组,减小字符断裂及字符差异对分割精度的影响。

图8 货车车号分割过程示例Fig.8 Example of freight train number segmentation process
2.3 算法优化
经过大量实验发现,鉴于包围圆分割方式字符断裂的情况下会出现错误合并,如图8(d)所示。因此,利用1.2.1小节预先采用自适应游程算法进行连通域重组,减小或消除字符断裂,再利用包围圆算法进行字符分割,实验结果如图9所示,图9(a)列为分割算法输入原图像,图9(b)是仅适用包围圆算法进行字符分割结果,图9(c)为在分割前预先使用自适应游程算法进行字符区域重组,将统一字符的断裂部分有效重新拼接在一起后再使用包围圆算法进行分割,可以看出,算法优化后的分割结果明显优于中间侧的分割精度,可以达到铁路货车车号字符的分割要求。

图9 算法应用结果比较Fig.9 Comparison of algorithm application results
3 实验结果分析
为了验证文中方法的有效性和鲁棒性,在Matlab仿真软件中,选取兰州北编组场采集的图像作为算法输入。整个实验是在操作系统为Windows10,编程软件为Matlab R2014b。为使对比效果更为明显,对原始货车图像加入噪声作为实验的测试对象,对文中提出的分割节识别方法进行验证,采用字符分割准确率、车号分割准确率作为评价指标。
3.1 分割效果评价指标
分割准确的评价标准是观察分割之后字符的完整性。若字符轮廓完整,没有出现缺失也没有增加多余部分,则认为是正确分割的字符,字符分割准确率定义为Ac。一个车号的所有字符分割准确,没有多余部分,则认为车号分割准确率,定义为An。

式中:Ncc为正确分割字符的个数;Nc为测试图像中车号字符总数;Npc为正确分割车号图像数;Np为测试图像总数。
3.2 效果评估
为了验证文中提出分割模型的优越性,实验中将对4种分割过程进行效果评估,分别是:投影算法[16]、连通域算法[17]、包围圈分割算法和文中所提的自适应游程处理后的包围圈分割算法。比较结果如图10和图11所示,文中优化组合的分割算法在字符出现轻度断裂、重度断裂及倾斜、变形等情况下分割准确率优于其他3种分割算法,证明文中提出方法具有较好的鲁棒性和更高的实际应用价值。

图10 字符分割效果对比Fig.10 Comparison of character segmentation effect of different methods

图11 车号分割效果对比Fig.11 Comparison of vehicle number segmentation effect of different methods
使用以上3种算法对车号图像进行分割,最终实验结果如图12所示。可以看出,基于投影法的分割算法和基于连通域(矩形包围框)的分割算法对于倾斜图像的分割准确率较低,且均对于断裂字符具有较低的分割准确率,受铁路货车车号的断裂特征影响较大。同时,水平放置的矩形框不能精确表达出字符的位置和大小,相对于包围圆算法,会出现更多的背景像素点,影响字符的识别效率。因此,文中方法具有更高的分割准确率和鲁棒性。
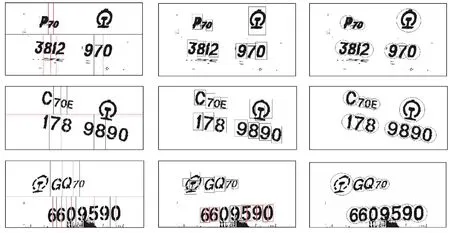

图12 部分车号图像分割结果对比图Fig.12 Comparison of segmentation results of some vehicle number images with different methods
4 结束语
1)文章提出一种基于包围圆的字符分割方法,利用自适应游程算法填充像素,结合货车车号断裂、倾斜、变形等特点进行预处理,实现双行车号的分割和字符断裂消除,并使用包围圆分割方法进行分割。大量实验表明,文中算法相比传统算法具有更优的分割精度和鲁棒性。
2)自适应游程算法可有效解决图像中字符断裂问题,但因铁路货车车号的断裂程度不一,如何选择一个动态参数既能消除轻度断裂和重度断裂又不出现粘连成为下一步研究重点。
猜你喜欢
安庆师范大学学报(自然科学版)(2023年4期)2023-03-11 11:01:38
江苏海洋大学学报(自然科学版)(2022年1期)2022-06-01 08:02:54
电脑爱好者(2022年15期)2022-05-30 01:29:23
文体用品与科技(2021年7期)2021-04-09 01:28:50
哈尔滨铁道科技(2020年1期)2020-07-27 01:45:52
机电工程技术(2020年4期)2020-05-30 01:01:56
小学生学习指导(低年级)(2019年12期)2019-12-04 03:39:42
电子制作(2019年19期)2019-11-23 08:41:50
安庆师范大学学报(自然科学版)(2019年2期)2019-08-26 05:05:52
少儿美术(快乐历史地理)(2018年7期)2018-11-16 05:31:14
