
基于集成极限学习机的电子商务风险预警研究
2022-07-27 10:29:40蒋伟杰
闽南师范大学学报(哲学社会科学版) 2022年2期
陈 艳,叶 翀,蒋伟杰
(1.福州大学至诚学院 经济管理系,福建 福州 350002;2.福州大学经济与管理学院,福建 福州 350108;3.福州大学计算机与大数据学院,福建 福州 350108)
根据2021年9月商务部电子商务和信息化司发布的《中国电子商务报告2020》显示,2020年中国电子商务交易总额37.21万亿元(人民币),同比增长4.5%,电子商务的从业人员达6015.33万人,同比增长17%[1],在疫情常态化背景下国内电子商务呈快速发展态势,在拉动经济、增加就业方面发挥着重要的作用。同时报告也指出,虽然电子商务信用体系建设取得明显成效,但是新型网络营销方式也带来信用治理难题,涉及商品质量、刷单、信用造假、虚假宣传、价格欺诈等问题;报告要求电子商务行业及信用服务行业需要立足行业自身,利用专业优势进一步加强诚信建设,推动信用评价、信用监测以及信用管理等多项信用服务,促进电子商务经济的规范健康发展。
电子商务中交易主体的信用风险评估是电子商务信用体系中的基本环节之一,有效的信用风险评估可以规避电子商务平台中的“柠檬问题”,降低可能发生的交易风险和交易主体的损失。信用风险等级与交易主体的各项指标之间往往存在着复杂的非线性关系,依据人工经验判断难以发现其中的规律,传统基于统计决策的方法仅适用于低维数据的情况,在高维数据下的表现不尽如人意。因此依托现有的机器学习、数据挖掘技术从交易主体的各项指标数据中快速有效的评估信用风险等级对降低信用分析成本,加快电子商务信用体系的建设具有重要的现实意义。
一、文献回顾
国内外已有不少研究利用机器学习技术根据企业数据实现信用评估,按照评估结果为企业信用得分和信用风险等级两种形式分别构建回归模型[2-5]和分类模型[6-13];按照模型的学习过程可以分为“端到端”的一站式学习[2,9,11-13]和两阶段式[3-8,10]的学习。一站式的学习方式中模型从原始数据所有维度的特征中直接进行学习;而两阶段式的学习方式中,首先对原始数据进行特征选择降低数据的维度,其次在降维后的数据中进行学习。在回归模型的构建过程中,余乐安提出了最小二乘近似支持向量回归(LS-PSVR)模型,其构建的企业信用风险预警模型按照企业指标给出风险评估分数,根据分数可以进一步划分风险等级进行预警[2],在此基础上,有些研究结合粗糙集或大数据分析技术进一步提升了模型的风险预警性能;另外有研究使用了基于主成分分析(PCA)的方法,首先使用PCA提取出主要指标后通过核支持向量机回归(KSVR)得到风险评估分数,KSVR中的超参数惩罚因子C和径向基核宽度σ由粒子群优化算法来选择[4];其后,一些研究在此基础上进一步使用核主成分分析(KPCA)来提取主要指标,接下来风险评估分数由改进的粒子群算法(PSO)结合神经网络计算而得[5]。在信用风险预警等级分类模型的学习中,王新辉先是利用PCA等技术从多个调研的企业数据中提取出主要指标,再利用反向传播神经网络(BPNN)从这些指标中学习得到能够对企业信用进行分类的风险预警分类模型[6];其后李兵同样使用了KPCA进行特征选择,然后在高斯先验假设的基础上应用朴素贝叶斯设计了分类模型,模型能够根据主要指标输出风险预警等级[7];还有些研究是以支持向量机(SVM)为基分类器,通过bagging集成方式增强了模型的泛化能力,其中周可滢在自行调研的企业数据集上获得了良好的效果[8],陈云等在UCI机器学习数据库的两组公共信用数据集上得到了验证[9];Xu YZ研究了决策树(DT)分别与逻辑回归(LR)、动态贝叶斯网络(DBN)及神经网络相结合的模型性能,在淘宝卖家信用案例上验证的结果表明,决策树-神经网络的组合达到了最高的准确率[10]。Chang YC提出了一种基于决策树的信用风险评估模型,通过在训练模型的过程中将自助聚合和少数抽样技术相结合,提高了决策树的稳定性和非平衡数据的性能[11];Zhang X基于粒子群优化遗传算法(PSO-GA)的神经网络,研究了跨境电子商务信用风险评估模型,提出了信用风险评估模型构建过程,并验证上述模型能够有效满足跨境电子商务信用风险评估的要求[12];Huang XB则系统地研究了BPNN,径向基函数(RBF),广义回归神经网络(GRNN)及概率神经网络(PNN)等不同类型的神经网络在信用风险预警等级分类上的表现[13],在公开的信用数据集上测试表明,PNN在二分类问题的准确率,ROC曲线下面积(AUROC)等度量上具有最佳的性能和鲁棒性。
现有的信用风险评估模型加快和推动了信用风险评估体系的发展,但在实际使用过程中还存在着不足,主要体现在以下两点。第一点是基于SVM、DT、LR等模型的方法难以直接拟合高维数据,往往需要使用特征选择手段先对数据进行降维操作。在样本数量有限的情况下,数据降维的过程无法判断和选择出真正有效的特征属性,因此会造成有效信息量的丢失,影响模型的性能和效果;第二点是近期越来越多的研究使用神经网络进行模型的回归和分类,神经网络在低维和高维数据上都体现出了优越的性能,但是神经网络的参数量大大超过其它模型,容易出现过拟合的问题。针对以上的问题,本文提出了基于类别平衡校正的集成极限学习机(EELM)企业信用风险预警等级预测模型。该模型通过样本过采样进行类别平衡校正,以解决少样本数据集中的类别不平衡问题;其次模型中的极限学习机(ELM)能够将高维数据进行随机投影后再优化求解,可以增加模型的泛化能力,避免过拟合,然后以ELM为基学习器进行投票集成,进一步降低ELM随机投影过程中造成的预测偏差,为信用风险评估体系提供稳定有效的结果。
根据以上的分析,本文主要的贡献和创新点如下:
一是研究了ELM模型在信用风险等级预警分类中的应用,并通过集成进一步提升了模型的效果。
二是提出了通过样本过采样来解决企业指标数据集上的样本类别不平衡问题。
三是在实际数据集上进行了验证,与基于BPNN、SVM的集成学习算法相比较,本文所提出的模型展示出更好的性能和效果。
二、研究方法与模型构建
(一)极限学习机模型
假设要学习的任务为分类任务,训练数据集(X,Y)={(xi,yi)|i={1,…,N}},其 中xi∈Rd,yi∈ {0,1}k,,即yi为k分类任务的one-hot编码。ELM为黄广斌[14]提出的属于单隐层的前馈神经网络,结构如图1所示。

图1 极限学习机网络结构
输入层为d个结点,对应输入数据x的d维数据;隐藏层共h个结点,h为极限学习的超参,根据具体的应用进行设置,g(·)为激活函数,为极限学习机提供非线性映射的能力;输出层共k个结点,对应于k分类。模型中的共有三组参数,W[d,h]和B[h]是输入层到隐藏层的线性映射权重及其偏置;β[h,k]是隐藏层的输出到最终输出的线性映射权重。模型中输入数据X和输出预测值之间关系如公式1所示。

在极限学习机中,学习的目标函数为min||Y-||,这里的参数W[d,h]和B[h]在随机初始化便不再改变,要学习的参数仅有β[h,k],即要求解的问题如公式2所示:

这里根据公式2可以得到β的解析表达式:

其中,g(WTX+B)-1可以使用矩阵广义逆来近似求解。
(二)基于相对多数投票的集成学习模型
ELM将样本X以非线性的方式随机投影到不同的特征空间,然后在新的特征空间中进行学习。由于投影的参数W,B在初始化的过程中随机生成并不再改变,投影的过程在样本数量有限的情况下不可避免地造成原始信息偏歧,最终得到的模型效果容易受到初始投影参数的影响。集成学习要求基分类器具备“好而不同”的特点,使用ELM作为基分类器,其随机投影保证了基分类器之间的差异性,而其后的近似解析表达可以为效果提供保障。使用集成学习结合多个ELM基分类器,相当于以不同的方式对原始数据进行投影后再学习,可以通过不同的“角度”充分地利用原始数据信息,有效的降低偏差,获得更准确和稳定的预测结果。对多个基分类器的结果使用相对多数投票法的结合策略,即预测为得票最多的类别,若同时有类别票数相同,则随机选取一个。
(三)基于过采样的类别平衡校正
在现实的电子商务过程中,需要预警的企业远少于正常的企业数量,这将在数据集中造成类别不平衡问题,会降低模型的性能和预测效果。为了使数据集中的类别达到平衡状态,一般可以通过少数类样本的过采样技术和多数类样本的欠采样来缓解类别不平衡的问题。在企业信用风险预警数据样本量有限的情况,使用对多数类的欠采样会进一步减少样本的数量,往往比基于少数类的过采样造成更严重的分类器过拟合问题。因此在本文中采用对少数类的样本随机过采样的方法来使数据集的类别达到平衡状态。
(四)基于类别平衡校正的EELM模型算法框架
根据上述的步骤,基于类别平衡校正的EELM模型的训练过程如算法1所示:

算法1基于类别平衡校正的集成极限学习机模型训练算法输入:训练数据集D={X,Y),模型集成的数量M,ELM的激活函数g(·),隐藏结点数h过程:1:i=0 2:repeat 3:对D中的少数类样本进行随机过采样以达到类别平衡4:随机初始化ELM的分类器Fi权重W和B 5:根据公式3计算出分类器Fi的权重β 6:i=i+1 7:util i==M输出:M个ELM分类器{F1,F2,…,FM}
基于类别平衡校正的EELM模型算法的推断过程如算法2所示:

算法2基于类别平衡校正的集成极限学习机模型推断算法输入:测试数据X,M个ELM分类器{F1,F2,…,FM}过程:1:i=0 2:foreach Fi 3:根据公式1计算 Ŷi=Fi(X)4:根据{ ⌒Y1,⌒Y2,… ,⌒YM}的结果使用相对多数投票法计算得到最终预测结果 Ŷ输出:最终预测结果Ŷ
三、实证分析与检验
(一)电子商务企业信用风险预警指标体系及数据来源
电子商务信用风险数据样本的采集首先要建立其对应的指标体系,本文采用王新辉的指标体系及其调研的18家企业数据[6]。由于电子商务信用风险的复杂性,因此使用指标体系中全部的19个指标,指标及其计算方法如表1所示。
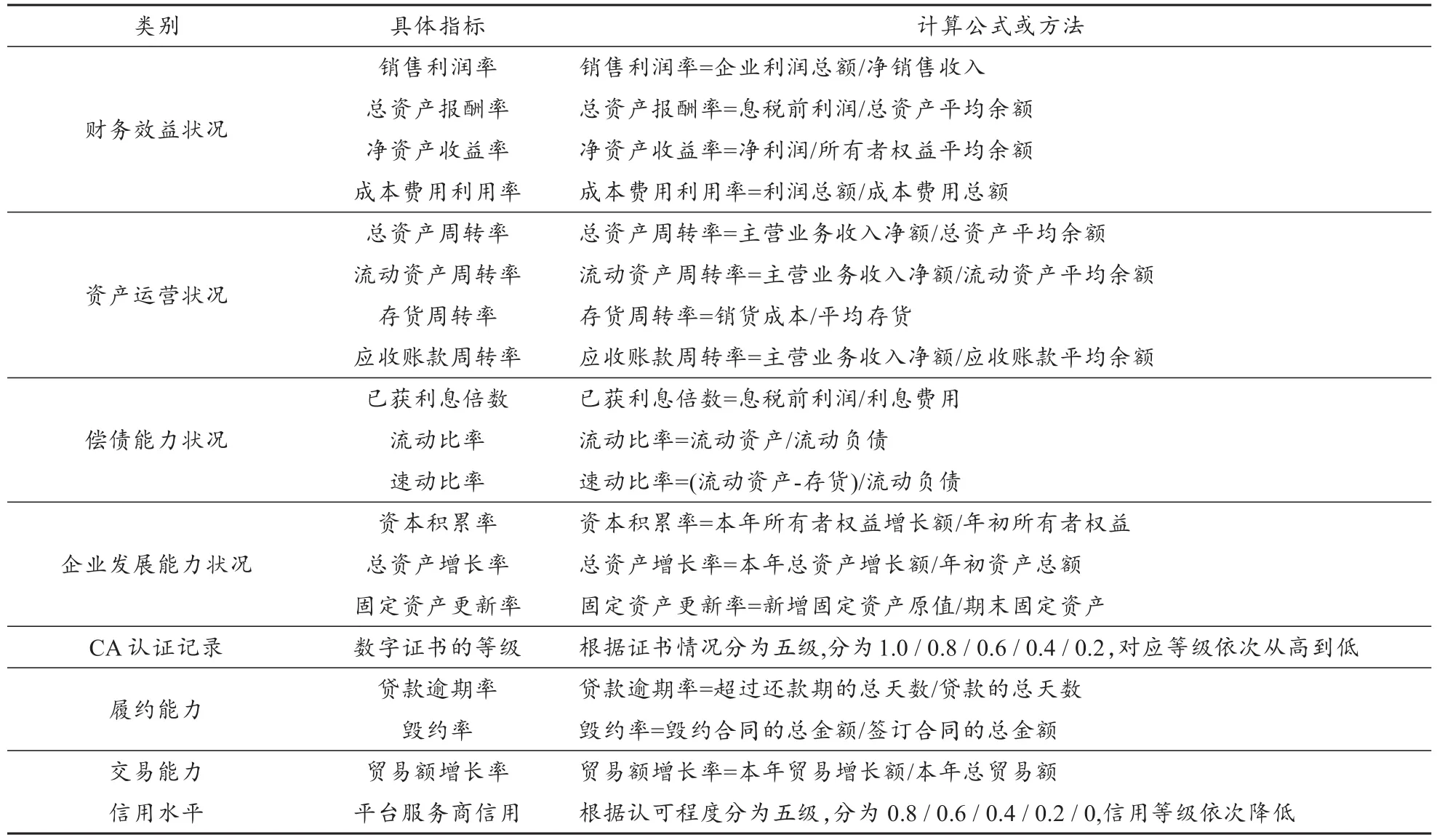
表1 电子商务企业信用风险预警指标体系
王新辉在论文中对18家企业的信用风险等级评定由不同岗位的专家组对企业进行综合评定打分后,再由不同的分数确定其风险等级[6]。本文根据其论文中提供的分值范围、综合得分分布以及信用风险的经验等级划分,按照得分情况将风险等级划分为三类,对应的预警等级和分值范围为:无风险预警A(70-100)、低风险预警B(40-69)、高风险预警C(0-39)。原始数据中的18家企业信用风险分值和风险预警等级如表2所示。

表2 18家企业信用风险分值及其风险预警等级
根据表2,本文实验取前13家企业为训练样本,后5家为测试样本。在训练样本中,共有5个A类样本,5个B类样本,3个C类样本。在实验中,本文将对C类样本进行过采样以达到和其它类别一致的5个样本。为了对比其实验效果,过采样后的训练数据集记为校正数据集,未校正的数据集记为原始数据集。
(二)EELM超参选择
在ELM中最重要的和需要设置的参数为隐层结点的数量,隐层结点的数量决定随机投影的维度,合适的维度可以有效的缓解ELM在学习过程中过拟合和欠拟合的情况。在实验中使用ELM最常用的Sigmoid激活函数,在基分类器数量为100个的情况下,隐层结点数量从3个到10个模型的各运行10次的平均准确率如图4所示。
准确率包括在原始数据集上的训练准确率和测试准确率,校正后的数据集上的训练准确率和测试准确率。可以发现,随着隐层结点数量的增加,原始训练准确率和校正训练准确率都在上升,但是在原始测试准确率和校正测试准确率先上升再下降,这个现象说明当隐层结点数量超过一定数量时造成了模型的过拟合现象。根据图4所显示的结果,ELM的隐层结点数量选择为7个结点。
在EELM中的参数还涉及到基分类器数量选择。如图5所示,可以观测到两个现象:一是随着基分类器数量的增加,无论是训练准确率还是测试准确率校正后的数据集都明显高于原始数据集,说明校正后的类别平衡有助于提高模型的性能;二是随着基分类器数量增加,校正测试准确率先呈上升趋势,随后在一定水平线上波动,说明在当前基分类器参数下模型性能具有较小的偏差。根据图5所显示的结果,将EELM的基分类器数量设置为1000。
(三)对比算法结果及分析
首先验证集成学习对应单个基分类器的效果,在7个隐层结点,1000个基分类器的情况下,运行模型10次取准确率均值,与所有基分类器的准确率均值比较如图6所示。

图6 集成模型与基分类器准确率对比
根据图6展示的结果,可以发现集成模型的准确率明显高于基分类器的准确率,在测试数据集上体现得更加显著。
为了验证ELM相对于其它分类器的有效性,本文选取在信用风险评估中常用的BPNN、SVM模型作为比较算法,对BPNN和SVM同样使用相对多数的投票法进行集成。这三个算法基分类器的数量都设置为1000,其它两个算法具体的参数如下:为方便比较,BPNN使用和ELM相同的单隐层结构,使用10个隐层结点,激活函数采用同ELM一样的Sigmoid函数,使用基于L-BFGS的梯度下降优化算法,迭代至200次或误差小于0.001时停止;SVM选择核支持向量机,核函数选择为RBF函数,为了进一步增大SVM基分类器之间的差异性,惩罚因子C以及RBF函数的核宽度参数从(0,1)的高斯分布中采样,迭代至误差小于0.001时停止。另外为了比较模型的计算效率,还将给出模型在相同环境下的运行时间,运行环境为:windows10操作系统,Intel Xeon E5型号的CPU,32G内存。在不同的基分类器下的准确率和运行时间如表3所示。

表3 不同基分类器性能对比
根据表3所展示的结果,基于ELM的集成模型在测试准确率上明显优于基于BPNN和SVM的集成模型,同时可以看出基于解析求解的SVM和ELM在计算速度上远远超过基于迭代优化的BPNN模型。在校正的数据集上所有模型的训练准确率都高于原始数据集,说明类别平衡校正有助于模型更容易地寻找分类边界;在校正的数据集上ELM和BPNN的测试准确率高于原始数据集,说明类别平衡校正能够进一步提高模型的泛化能力,值得注意的是BPNN的训练准确率达到了100%,远超测试准确率,说明基于梯度下降的BPNN容易在少样本数据集上造成过拟合现象;但是SVM在校正的测试数据集上取出现了性能下滑,造成这个现象的原因过采样的样本干扰了SVM支持向量的选择,导致SVM模型产生了过拟合现象。
四、结论与建议
在电子商务活动中,有效准确的企业信用风险预警等级评估是健全电子商务信用体系的重要环节,能够积极推动电子商务的进一步发展,本文根据当前电子商务企业数据样本数量少且类别不平衡的特点,提出了基于过采样的类别平衡校正集成极限学习(EELM)模型,与现有的研究相比较具有泛化能力强、求解速度快,适用于高维的少样本数据集。EELM模型在18家电子商务企业数据的全部19个指标上进行了实证分析,EELM能够有效的预测企业信用风险预警等级,且在性能和效果上优于基于BPNN和SVM的集成模型,较好解决了电子商务企业信用评价数据样本少且类别不平衡的问题。由于企业信用数据采集存在一定的困难性,本文所提出来的模型有效性还有待在更多的企业信用数据上进行验证。
针对三类风险等级界定,建议如下:
第一,处于A级无风险预警的企业,信用风险较小,有较好的抗风险能力,可继续深度合作,加强信用评级信息收集,优化风险调控结构,提升企业信用。
第二,处于B级低风险预警的企业,有一定的信用风险发生的可能性,要加强对企业产生信用风险的潜在因素进行分析,加强沟通和管理,改进工作,督促提高信用,防止信用风险的发生。
第三,处于C级高风险预警的企业,处于预警状态,有较大信用风险发生的可能性,建议进入风险预案程序,暂停合作,督促加强各项工作,提升信用风险防范意识,避免出现惨重损失。
猜你喜欢
电子测试(2018年1期)2018-04-18 11:52:35
辽宁经济(2017年6期)2017-07-12 09:27:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
当代经济(2016年26期)2016-06-15 20:27:18
新校长(2016年8期)2016-01-10 06:43:59
新疆财经大学学报(2015年3期)2015-12-10 03:49:13
特区实践与理论(2014年5期)2014-07-24 14:02:08
商事法论集(2014年1期)2014-06-27 01:20:42
电测与仪表(2014年15期)2014-04-04 12:05:20
