
基于改进的EfficientDet 的军用手势检测算法*
2022-07-25 06:44:24王智博刘梦洁
火力与指挥控制 2022年6期
刘 杰,王智博,刘梦洁
(1.太原工业学院,太原 030008;2.韩国全州大学,韩国 全州 55069;3.太原师范学院,太原 030000)
0 引言
手势是人与人交流的一种方式。经过长期实践与发展,利用手指、手掌和手臂形成一定的形态,并对其赋予特定的含义便构成了手势。手势以直接、明了的特点广泛应用在裁判的执法、警察的执法和军事行动等不需要反馈交流的指挥和控制场景中。尽管语音、视频技术已经广泛开始应用,但在军事作战现场,由于外部嘈杂的环境语言无法正常沟通或某些需要在无声静默情况下执行任务时,手势无疑是最简单、最直接的沟通方式,它可以快速完成行动的指挥和部署。利用计算机技术对军用手势图像或者视频进行识别,不仅可以更规范和准确地使用军用手势进行交流,而且可以对战场上越来越广泛使用的自动化设备进行人机交互实现手势控制提供了更多的可能。
手势检测任务是指在图像或者视频中识别出手势的类别并标记出该手势所在的位置,该问题一直是科学研究的热点。目前研究主要集中在利用统计和知识方法,依靠人工设计目标特征的传统目标检测方法。随着深度学习技术在计算机视觉中的突出表现,利用深度神经网络自动提取特征并对目标进行检测成为研究热点。
传统的目标检测通过滑窗确定候选区后进行特征提取,然后利用传统分类器确定目标类别和位置。LBP(local binary pattern)即局部二值模式算法,它可以提取到对象更丰富的纹理特征,较好地适应光照的均匀变化;HOG(histogram of oriented gradients)算法通过计算和统计局部区域的梯度方向直方图来构成特征,特征表达能力更强,在物体检测、跟踪、识别中有广泛的应用;DPM(deformable parts models)算法,对输入图像中的目标制作激励模板,对原始图像进行卷积得到激励图,根据该效果图来对目标进行检测。传统的目标检测算法计算量大,运算速度慢,而且受人工设定特征的数量和质量影响较大,性能较低。
基于深度学习的目标检测算法,是将大量的图像送入神经网络,利用深层神经网络超强的学习能力和强大的逻辑抽象能力,对目标特征进行自动提取,极大地避免了人工设定特征的不足。当前大多数基于深度学习的目标检测技术研究都是基于Achor-based 方法的,主要有单阶段目标检测和双阶段目标检测。双阶段目标检测首先对图像提出候选区,然后再对候选区中的特征进行提取,一般效率较低,但精度较高。SPP Net算法将特征金字塔思想加入CNN 中实现多尺度投特征的输入。Fast rcnn是RCNN 和SPP Net 的改进,并引入共享卷积层提高检测速度;Faster R-CNN利用Region Proposal Network 提取候选区域,提高检测速度。单阶段目标检测中不生成候选区,直接对目标的分类概率和位置进行预测,因此,效率更高,可以满足实时检测任务的要求。YOLO算法将分类问题转化为了回归问题,获得了较高的检测效率;SSD提出了不同尺度特征进行检测大小不同目标的想法,克服了小目标难检测的问题;Yolov3算法使用FPN 对特征进行融合后,在3 个不同尺度上对目标进行检测,获得了更好的检测效果;EfficientDet算法在目标检测精度、效率上都取得优秀的成绩,同时实现了模型在宽度、深度和分辨率的缩放可以满足不同设备和不同任务的要求。军用手势的检测,要求算法有较高的检测效率和精度,因此,本文以高效的单阶段目标检测算法EfficientDet 为基础,结合军用手势数据的特点,提出了一种基于改进的EfficientDet 的手势检测算法。
1 EfficientDet 介绍
EfficientDet网络是2020 年提出的一系列可扩展的、高效的单阶段目标检测算法,优化了准确率和效率,以满足不同设备不同任务的需求。Efficient Det 网络的FLOPs 是Yolov3 的1/28,RetinaNet的1/30;EfficientDet-D7 在COCO 数据集上AP=55.1,获得当时多项任务中的最好成绩。EfficientDet 目标检测网络在完全保留EfficientNet网络的P~P层的基础上可以得到更全面的特征,对P层进行下采样得到P和P特征层;同时为了得到更有效的特征信息,对传入的P~P的特征层使用了高效双向跨尺度连接和加权特征融合(BiFPN)网络对不同尺度的特征进行融合;最后将融合后的特征送入检测网络,对目标的分类和预测框位置进行检测。EfficientDet 网络在推理过程中,对输入的图像(512* 512) 经过下采样后,将P~P特征层(64*64,32*32,16*16,8*8,4*4)送入BiFPN 网络进行特征融合,最后使用检测网络得到目标的预测分类和位置,并使用预测框标记出目标位置。EfficientDet 网络结构如图1 所示。
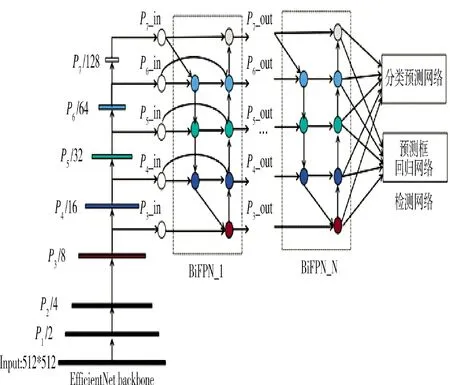
图1 EfficientDet 网络结构
EfficientDet 网络其实是D~D系列模型的组合,D模型是使用MobileNetV2+SE神经网络搜索出的最优模型,再以D模型为基础对模型的宽度、深度和图像分辨率进行综合考量,提出了模型扩张的具体方法,如式(1)所示:
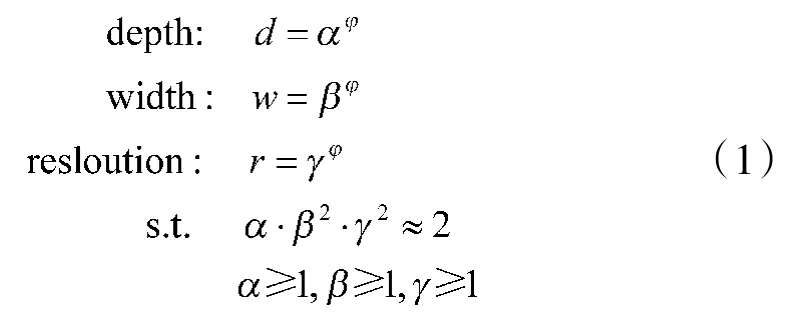
式(1)中,α 代表网络深度常数;β 代表网络宽度常数;γ 代表分辨率常数。常数α,β,γ 通过网格搜索得到的最优值α=1.2,β=1.1,γ=1.5,其中,φ 是复合系数,通过人工调节可以得到D~D不同大小、不同复杂度的网络结构,从而满足不同设备和不同任务的需要。
2 网络的改进
本文在EfficientDet 基础上针对图像中的军事手势检测问题作出改进,受限于实验环境,本文主要研究针对EfficientDet 网络的基础网络EfficientDet-D0 进行优化。首先在模型训练前通过K-means聚类得到先验框的尺寸;在特征融合时引入了更多的中间特征层信息,使各特征层包含了更加丰富的手势特征信息;最后在预测阶段,使用不仅考虑交并比,还考虑了相对位置的DIoU(distance intersection over union)代替了原算法中的IoU(intersection over union)作为标准,通过设定不同置信度阈值以去除多余的预测框,然后使用非极大值抑制(non-maximum suppression,NMS)算法得到手势的预测结果。
2.1 调整先验框尺寸
与其他单阶段目标检测网络的目标检测原理类似,EfficientDet 网络将输入的512*512 图像经过下采样和特征融合后得到5 种尺度(64*64,32*32,16*16,8*8,4*4)的特征层。每个特征层上的特征点都对应着不同的感受野,即相当于将原图按照5 种尺度划分成了不同大小的网格,再以每个特征点对应原图位置为中心生成3 个正方形,3 个水平长方形和3 个垂直长方形,共9 个锚框,通过这些生成的锚框(Anchor)对目标进行检测。在网络训练过程中,通过计算每个Anchor 与Ground Truth(真实框)的损失,得到目标的预测结果。因此,Anchor 选择的好坏将直接影响网络的收敛速度和目标的识别率。原始EfficientDet 先验框是通过ImageNet 数据集预训练后使用迁移学习后在COCO 数据集得到的,本文军用手势数据集与COCO 数据目标的先验框不同,如果使用原先验框尺寸将会增加训练成本。因此,本文在训练网络前,通过对数据集进行K-means聚类调整了先验框尺寸。K-means 算法一般使用欧氏距离计算样本点到聚类中心点的距离,而先验框的距离需要通过计算两个框的IoU(交并比)来进行聚类。EfficientDet 每个特征点产生有9 个Anchors,因此,设定了9 个聚类中心,使用处理过的IoU(交并比)构造距离公式进行聚类,如式(2)所示:
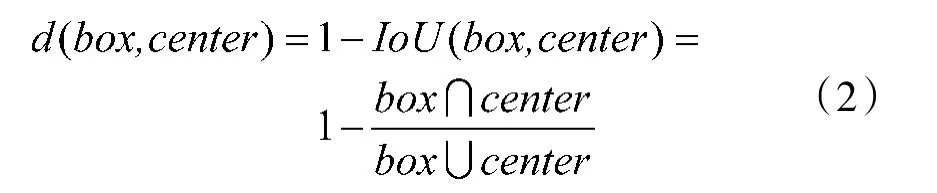
式(2)表示Anchors 与Ground truth 之间的距离。IoU(box,center)表示两个框的重合程度,重合度越高表示两个两框距离越近。使用K-means 算法对本文手势数据集进行聚类得到先验框的宽高比为(1.0,0.8),(0.8,1.4),(0.8,2.5),缩放比例为(1,1.26,1.59)。经过聚类得到的锚框更好地满足了手势目标识别的要求,大大提高了目标检测的精度和速度。
2.2 优化特征融合
特征融合技术被认为是深度学习目标检测和图像分割任务中提高性能的有效手段。图像经过下采样技术得到不同分辨率的特征层,随着网络的加深,特征图分辨率变小,对应特征的感受野变大,得到了更高级的全局语义,同时也丢失了更多的局部细节,这样对小目标的检测非常不利。为此,FPN(feature pyramid networks)提出特征金字塔结构如图2(a)所示,采用自顶向下对深层特征进行上采样后与浅层特征进行融合,生成新的特征层,提高网络对小目标的检测能力。PANet在FPN 基础上增加了自底向上网络结构,构成了双向特征融合结构如图2(b)所示。EfficientDet 采用的BiFPN(双向特征融合)结构不仅对PANet 网络中存在的冗余进行去除,还对融合前后相同维度的特征进行了跳接,多次利用原始特征进行融合;同时考虑在检测大小不同的目标时,为每个特征层设置了可用于学习的权重,使特征层在检测不同尺度的目标时有所侧重,提高了检测效果,如图2(c)所示。

图2 3 种特征融合网络
文献[19]中,对BiFPN 特征融合网络结构进行优化,在每个输出特征层前增加了中间特征层进行融合,以增强小目标的检测能力,通过实验证明网络性能所有提升。本文提出的BiFPNx 结构如图3 所示。
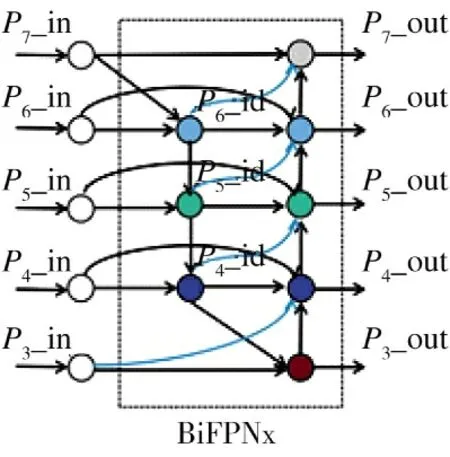
图3 BiFPNx 特征融合网络
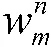

2.3 以DIoU 为准则对预测框进行NMS
目标检测网络对图像进行预测时,会产生很多预测框,即使是一个目标也会因为置信度阈值设置的大小产生数量不等的预测框。而目标检测的理想效果是目标与预测框一一对应,只保留与真实框最接近的框,去除掉多余的框。常用的算法是NMS(非极大值抑制),具体算法步骤如下:


目标检测中的NMS 算法常使用IoU 对预测框进行评价,但是当图像某个区域中存在密集目标时,使用IoU 进行非极大值抑制会将其他目标的准确预测框删除,导致检测效果不好。本文采用DIoU代替传统NMS 中的IoU 作为评价准则,该方法不仅考虑了两个框的重合程度IoU,而且通过计算两个框中心点距离评估两个框的相对位置,这使得模型能更加稳健,对有遮挡的情况可以有更好的检测效果。DIoU 计算方法如式(4)所示:
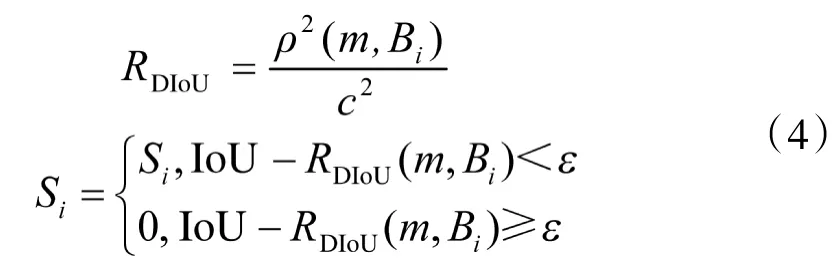
式(4)中,S表示预测框的分数;ρ(·)表示两个框中心点的欧氏距离;c 表示两个框的最小临接矩形(覆盖两个框的最小封闭框)的对角线长度;ε 表示NMS的阈值;m 表示最高置信度候选框;B为每个框与M 候选框重合的程度。
3 实验及结果分析
本文实验在Windows10 系统下进行,CPU 为Gen Intel(R)Core(TM)i7-11800H,GPU 为NVIDIA RTX3060,CUDA 版本为CUDA 11.2,深度学习框架采用Pytorch。
3.1 数据集
本文选择10 种常用军事手势,包括数字0~5和表示明白(fist)、停止(stop)、手枪(gun),自定义手势(9)类别;通过选择Handpose_x_gesture_v1和Sign-Language-Digits-Dataset-master公开数据集的部分图像,并自行采集手势图像共5 090 张图像构成军用手势数据集。
Handpose_x_gesture_v1 是静态手势识别数据集,它是由kinect_leap_dataset 数据集、网络数据和自己拍摄图像数据经过整合后构成,主要包括了one、fist、OK、nine 等在内的14 类静态手势,共有2 850 张数字图像。该数据集中图像采用不同背景进行拍摄,数据集网址:https://codechina.csdn.net/EricLee/classification。本文军用手势数据集选择了该数据集中表示数字1、2、4、5 以及fist、gun、stop 和nine 等部分手势图像数据。
Sign-Language-Digits-Dataset-master 是土耳其安卡拉Ayranci Anadolu 高中采集了10 个班级的218 位学生的手语图像数据集。该数据集对每位学生的10 种手势(0~9)进行采样,每张图像为100*100 像素,颜色空间采用RGB,均采用灰度背景,网址:https://github.com/ardamavi/Sign-Language-Digits-Dataset。本文军用手势数据集选择了该数据集中表示数字0~5 的部分手势图像数据。
自制数据集通过手机对12 个不同个体的10种军用手势进行拍摄得到。图像的拍摄是在不同距离、不同背景、不同光照下进行的。图像是由手机进行拍摄,图像中exif 信息保留了方位信息,可能会导致读入的图片发生旋转和大小变化,需要对图像进行校正,没有对图像的色彩、亮度和大小等信息进行改变。
针对本文使用的军事手势数据集,选择了Handpose(Handpose_x_gesture_v1)数据集的1 602 张手势图片和Sign(Sign-Language-Digits-Dataset-master)数据集中的1 237 张手势图片以及自行采集的具有复杂背景的2 253 张手势图片构成,手势数据集具体来源如表1 所示。
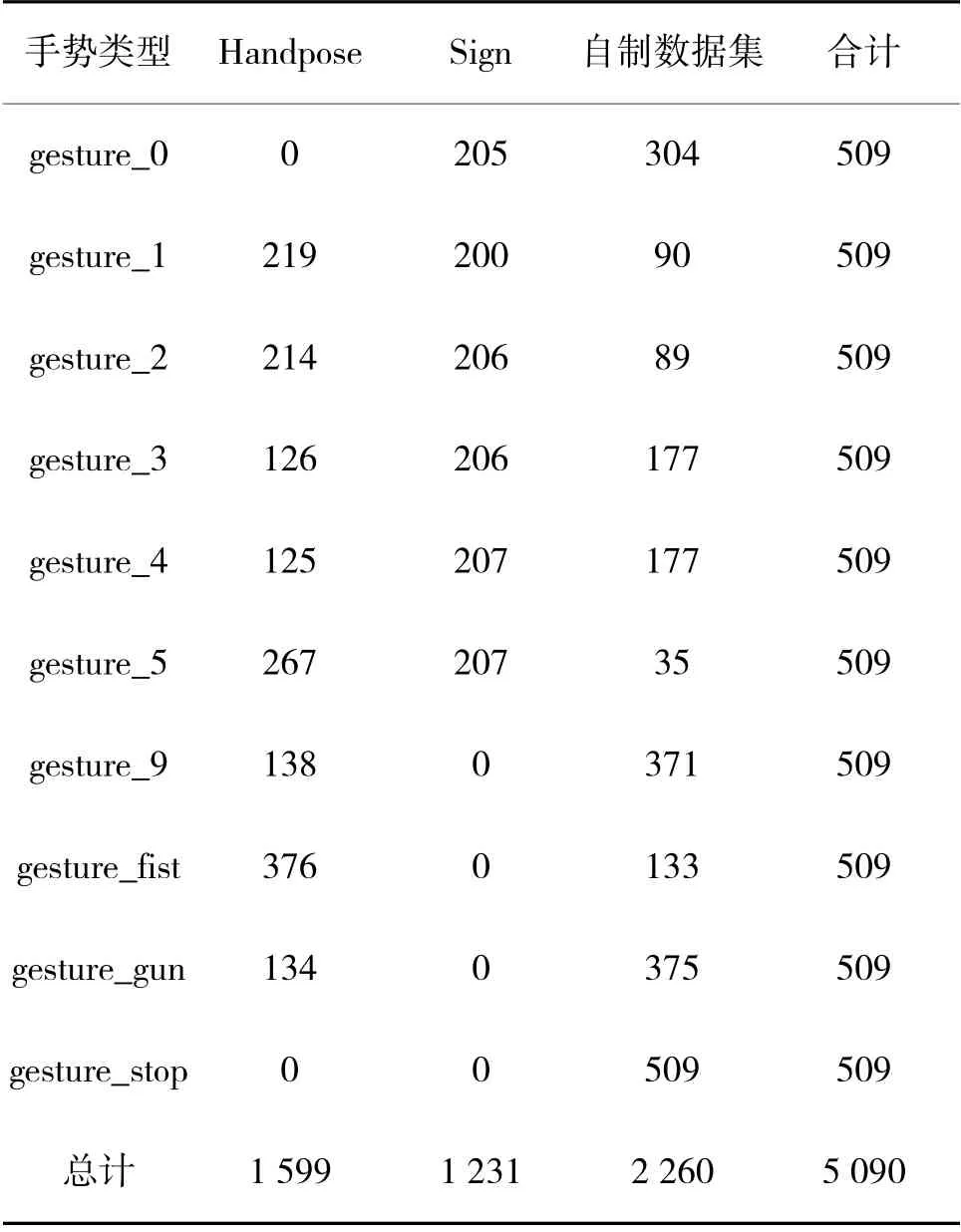
表1 军事手势数据集10 种类别的分布
表1 中,军事手势数据集中涉及常用的10 种类别的军用手势,每种类别的手势均包含有509 张图像,数据集图像示例如图4 所示。其中,Sign 数据集的图片分辨率为100*100,被检测目标是整张图的主体,真实框尺寸均在80*80 以上,利用检测网络的P7 特征层将原图划分为4*4 的网格,以每个像素点为中心绘制9 个Anchors,可以抽象得到更高的语义信息,一般利于较大目标的检测。自建数据集中图像分辨率为1 024*1 365,被检测手势目标仅占图片的一小部分,利用检测网络的P特征层将原图划分为64*64 网格,利用每个像素为中心绘制的9 个Anchors,可以得到手势的轮廓、边缘、纹理等细节信息,一般利于较小目标的检测。本文算法将下采样得到的P~P5 种尺度的特征进行融合,即将更多的细节特征和更高语义的全局特征进行融合,提高了目标在不同尺度下的检测能力和识别率。

图4 军事手势数据集图像示例
本文采用LabelImg 软件对数据集中5 090 张图像进行人工标注,对每张图像中出现的手势采用最小外接矩形作为真实框(ground truth),并对该框中的手势指定分类信息,完成标注后,导出XML 文件与VOC2007 数据集标注的格式一致。模型训练前,随机选取数据集图像中80%作为训练集,10%作为测试集,10%作为验证集,模型进行训练时完成一次训练后进行一次验证,使用验证集loss 进行评估。同时使用online augmentation方式对训练集中的图像数据进行随机数据增强,主要包括水平翻转,裁剪、缩放比例、灰度处理等方法增加了模型的鲁棒性和降低了过拟合。训练网络使用迁移学习和微调的方法加快网络的收敛速度,减少了训练时间。
3.2 评价指标:
目标检测网络用于检测图像中目标的分类即目标的位置,检测结果使用矩形框将检测目标框出,并给出该目标的置信度。通常使用精确率Precision 和召回率Recall 对模型性能进行评估,Precision 和Recall 的计算如式(5)所示:
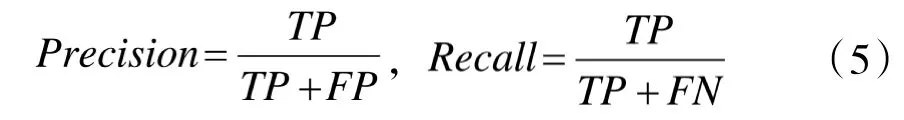
式(5)中,Precision 表示预测为正例在所有被预测为正例中的比例;Recall 表示正例中被预测对的比例。其中,TP 表示被正确预测为正例的个数;FP 表示被错误预测为正例的个数;FN 表示被错误预测为负例的个数。
在目标检测问题中,通过对预测框与真实框的目标类别及它们的交并比(IoU)来评估检测的效果。如果预测框中的目标类别与真实框中目标类别一致则分类预测正确,反之分类预测错误。在分类预测正确的预测框中还需要通过将其置信度与设定的阈值进行比较来确定正例还是负例,如果预测框置信度大于预设阈值则为TP,反之则为FP。置信度阈值设定的越大,表示要求预测为TP 的条件越严格。置信度阈值设定范围一般在0.5 到1 之间,本文选择0.5和0.75 两种阈值计算某一类手势在测试集中预测的TP 和FP 值,从而计算得到对应的Precision 和Recall。Recall 和Precision 值越高代表预测该类手势效果越好,但是实际上,往往Precision 提高会使得Recall 降低,因此,通常选择Precision=Recall 时的值作为评价指标,即AP(average precision)。在置信度阈值为0.5 时得到AP 记作AP50,置信度阈值为0.75 时得到的AP 记作AP75。本文使用军用手势数据集有10 种类别的手势,因此,使用每种类别AP的均值mAP 即平均检测精度(mean average precision)作为综合度量指标。该指标是采用PASCAL VOC mAP 标准,具体如式(6)所示:

式(6)中,AP 代表某种类别的平均精度,mAP 即为所有类别AP 的平均值;Q 表示分类目标的类别数。本文通过在0.5 和0.75 两个置信度阈值下评估模型,在阈值为0.5 时计算所有类别的平均mAP 记为mAP;在阈值为0.75 时计算得到所有类别的平均mAP 记为mAP。
3.3 实验结果分析
3.3.1 本文算法实验
本文提出算法在训练时,喂入模型的图像大小为512*512,batch_size=8,初始学习率为0.01,采用3次loss 不变即将学习率衰减10%的学习策略,在将图像送入网络前对其进行数据增强,损失函数使用Focal loss 分别计算分类损失和预测框的回归损失。
本文算法在手势数据集训练100 个epoch,网络基本收敛,此时在测试集上得到各类平均精确度为98.94%。为有效考察网络损失的衰减趋势,继续进行50 个epoch,发现该过程loss 无明显下降,在测试集中的mAP 表现也有没有较大提升,如图5 所示。
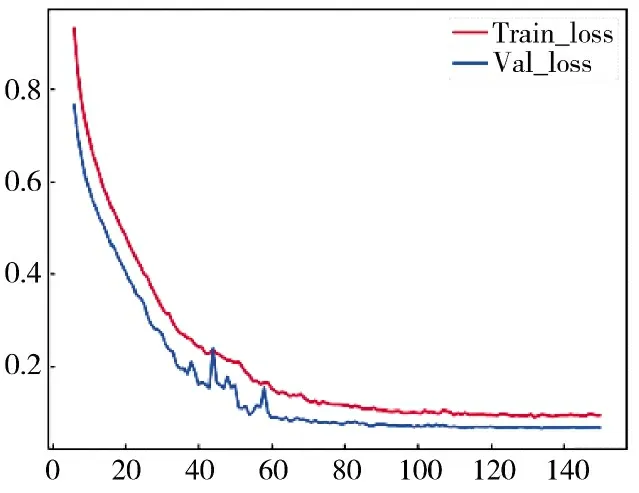
图5 训练集和验证集上损失的衰减情况
在图5 中,训练集和验证集的损失急剧衰减,在60 个epoch 开始趋于平稳,在100 个epoch 时收敛,100 epoch 到150 epoch 损失在变化小于0.001。
在手势数据集的测试集的510 张图像上进行测试,分别设定置信度阈值为0.5 和0.75,得到10 种类别的预测平均精度分别为mAP=98.94%和mAP=95.40%,详细检测结果如表2 所示。

表2 10 种手势在两种阈值下的检测精度
表2 中,当阈值为0.5 时,10 种类别精度均达到了95%以上,其中,gesture_2 手势的检测精度最高,达到了100%,gesture_fist 手势的检测精度最低为95.33%;在置信度阈值为0.75 时,10 种手势的检测精度基本在90%以上,gesture_5 手势的检测精度最高达到99.89%。在两种阈值条件下,本文算法对10 种常用军用手势检测得到了较高的平均检测精度,分别为98.94%和95.40%,证明了本文算法可以较好地对手势进行识别。在阈值为0.75 和0.5 两种情况下,gesture_stop 和gesture_5 两种手势的检测精度在阈值为0.75 时有一定提升,分别提升了0.09%和0.15%,其他类型的手势有不同程度下降,但都基本达到90%以上,说明算法对手势目标的检测有着较高的有效性和鲁棒性。
3.3.2 消融实验
本文提出的算法基于EfficientDet,首先使用k-means 算法对手势数据集先验框进行聚类;在特征融合网路中融合了更多的中间层特征,并在预测阶段使用DIoU 作为NMS 指标抑制预测框,得到最好的预测效果。为了验证3 种改进方案的必要性和性能,对其在不同置信度阈值下进行了消融实验,实验效果如表3 所示。

表3 优化方案对网络性能的影响
由表3 可以看出,在两种阈值下,每种单一优化均对模型性能有较好提升,其中,BiFPNx 对模型预测性能提升较大,分别为1%和1.6%。多种优化的组合措施在两种阈值下的性能均高于单一优化性能。当采用本文提出的优化算法,对手势的识别率有了较大提升,在两种阈值下达到了98.94%和95.4%,分别提升了1.59%和2.48%,证明本文算法的改进方案的可行性和必要性。
3.3.3 本文算法与其他算法对比
为进一步验证本文算法的有效性,将其与已经广泛应用的单阶段目标检测算法Yolov3、双阶段检测算法Faster R-CNN(在本文中用FR 代替)以及原始的EfficientDet 算法在本文手势数据集上进行对比实验,从输入图像大小(Input)、特征提取主干网络、特征融合网络、参数量(Params),计算量(FLOPs)、检测速度(FPS)和平均精确率(mAP,mAP)等几个方面进行对比,同时为了保证实验的公平性,均采用相同的训练集、验证集和测试集,设置epoch=100,测试集进行预测时分别计算阈值为0.5 和0.75 两种条件下的10 类手势的平均精确率,实验对比结果如表4所示。
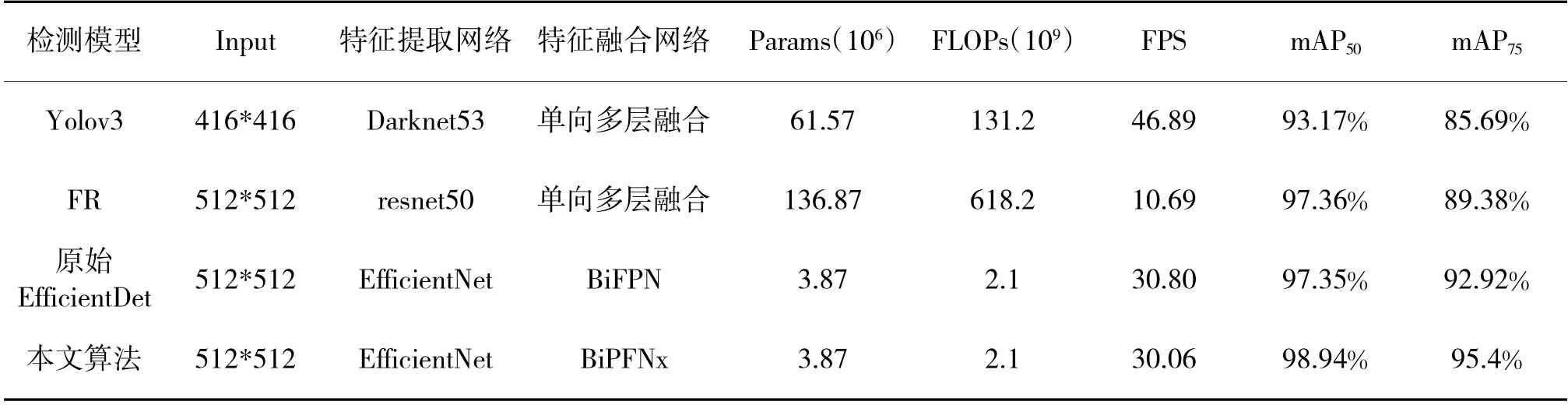
表4 4 种算法的对比结果
从表4 中可知,4 种模型的复杂度和计算量对比:双阶段检测模型FR 的参数量(Params=136.87 m)和每秒钟运行浮点运算的次数(FLOPs=618.2 G)比其他3 种模型的复杂度和计算量更高,需要更高算力及硬件环境才能保证正常运行,不适合部署在移动终端或者硬件配置不高的项目中。单阶段检测模型Yolov3 的参数量(Params=61.57 m)只有FR 模型参数量的0.45 倍,每秒运行浮点运算的次数(FLOPs=131.2 G)只有FR 模型的1/5。本文算法改进了EfficientDet 模型,增加了更多的浅层特征进行融合,参数量和FLOPs 比原始的EfficientDet 模型略有增加。与FR 和YOLO 模型相比,本文算法参数量仅为3.87 m 是FR 模型的3%,Yolov3 模型参数量的6%;FLOPs 为2.1 G 仅为FR 模型的0.3%,Yolov3 模型的0.016%。
从模型检测速度方面进行对比,FR 模型平均每秒钟检测图像数量(FPS)为10.69,Yolov3 模型平均每秒钟可以检测图像数为46.89。本文提出的算法在参数量和复杂度上比EfficientDet 模型略大,每秒可以检测的图像数量略少,但是每秒钟也可以检测30.06 张图像,完全可以满足视频(24 frame/s)图像实时检测的要求。
在检测精确度方面,当设置置信度阈值为0.5时,FR 模型各类别平均精确度(mAP)为97.36%,比原始EfficientDet 模型的mAP(97.35%)略高。当设定阈值设置为0.75 时,EfficientDet 模型的mAP(92.92%)高于FR 模型的mAP(89.38%)。对测试集进行预测中,本文算法对10 类军用手势的平均精确度(mAP)为98.94%,在4 种算法中最高,比双阶段检测算法FR 高出1.58 个百分点,比单阶段检测算法Yolov3 高出5.7 个百分点,比原始的Efficient-Det 算法高出1.59 个百分点;当把置信度阈值设置为0.75 时,检测的精度(mAP)为95.40%,比原始EfficientDet 算法高出2.48%,更远高于其他模型的精度。
通过表4 对比实验的数据可以看出,本文提出的算法在10 种军用手势的检测中,可以使用较小的模型,更少的计算量和更高的检测效率得到更高的平均检测精确率。
在表5 中列出了置信度阈值为0.5 时,本文提出的算法、Yolov3、Faster CNN 和原始EfficientDet 4种算法对每种手势的检测精度(AP)。

表5 4 种算法对每种手势的检测效果
从表5 中可以看出,本文所提算法对每种手势的识别率整体优于FR 和Yolov3 两种算法的识别精确率,仅对gesture_gun 和gesture_3 两个手势的检测略低于Yolov3 的识别率。本文算法比原始EfficientDet 算法在各种手势的识别效果更加稳定,尤其对gesture_gun 手势的识别,本文识别率为99%,而原始EfficientDet 算法识别率仅为85.08%。本文所提算法,对gesture_2 手势的识别率最高为100%,对gesture_fist 手势的识别率最低为95.33%。4种算法对手势gesture_1、gesture_2、gesture_3、gesture_4 和ge-sture_stop 5 种手势均有较高的识别率,达到95%以上,对其他手势的识别效果有较大差异。为了更好地展现对比检测效果,选择gesture_0、gesture_5、gesture_9、gesture_fist 和gesture_gun 5 种检测精度差别较大的手势检测效果进行对比分析。5 种手势在不同算法中检测效果的表现如图6 所示。
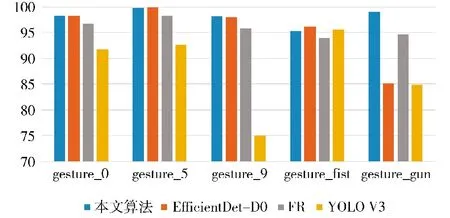
图6 5 种手势在不同算法中mAP50 值
通过图6 可以看出,4 种模型对gesture_fist 手势的检测中表现都不佳。本文算法的检测结果比原始EfficientDet 模型的结果低0.88%,比Yolov3 模型低了0.25%,除此以外在其他手势的检测中均取得了较好的效果。对gesture_gun 手势的检测出现了比较大分歧,只有FR 和本文算法取得了95%以上的检测精度;对于gesture_9 手势的检测中,Yolov3 取得了最低成绩,仅为74.98%的检测精度。
通过实验表明,本文提出的算法大大缩减了模型的计算量和复杂度,检测速度满足实时检测的需要,有更高的检测精度,模型各项性能较改进前均有较大提升,证明了本算法的优越性。
4 结论
本文提出了一种改进的EfficientDet 军用手势识别算法,主要从3 个方面进行改进:1)在模型训练前,使用k-means 算法对手势数据集先验框进行聚类,得到最适合检测手势目标的先验框宽高比例,加快了网络的识别精度和识别速度;2)优化了特征融合网络。在BiFPN 双向特征融合网络中利用更多的中间层特征得到5 个不同尺度的输出特征层,以确保输出的特征可以包含更丰富的语义信息,提高了手势的识别率;3)使用DIoU 为标准对预测框进行非极大值抑制(NMS)选出最佳预测框,得到了更加准确的预测框。通过本文构建的军用手势数据集进行实验,采用数据增强降低了过拟合;采用迁移学习和微调的方法加快网络的收敛速度,减少了训练时间,最终在测试集上选定的0.5 和0.75两种置信度阈值下得到的识别率分别达到了98.94%和95.40%。通过对本文算法的改进方案进行了消融实验,验证改进方案的有效性,并在相同环境下,与Yolov3、Faster R-CNN 以及原始EfficientDet 算法进行对比实验。实验结果表明,本文提出的算法对军用手势预测的识别率和检测效率更高,模型复杂度和计算量更小,从而验证了本文算法对不同尺寸军用手势的识别更有效,为更进一步的军事作战和自动化设备的人机交互应用提供了可能。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
制造技术与机床(2019年9期)2019-09-10 07:36:54
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
西南交通大学学报(2018年6期)2018-12-18 02:22:28
河北遥感(2017年2期)2017-08-07 14:49:00
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
