
一种基于功耗分析的深度卷积神经网络识别方法
2022-07-21 09:20方泽彬吴小笛杨帆何杰逊
声学与电子工程 2022年2期
方泽彬 吴小笛 杨帆 何杰逊
(第七一五研究所,杭州,310023)
当前,DCNN 相对传统机器学习算法的优势不断扩大,传统学习方法在多个领域无法与深度学习抗衡,比如手写体识别、图像分类、图像语义理解、语音识别和自然语言理解等技术领域[1]。近年来,CNN 在越来越多的领域超越传统模式识别与机器学习算法,取得顶级的性能与精度。这些成果主要是通过增加神经网络层数、加大训练样本的数量、改进训练学习算法这三方面的技术手段来实现的。不同结构的CNN 在运行过程中的运行效率和工作功耗都是存在差异的,而这种差异会反应到识别效率和设备功耗上,目前国内外对此的研究文献都相对较少,但是这方面的分析和讨论是非常有意义和必要的。
1 实验可行性介绍与分析
1.1 实验原理介绍
侧信道攻击(Side Channel Attack,SCA)的主要方法有功耗攻击、电磁场攻击和时间攻击。通过类比侧信道攻击加密电子设备的方法,我们设计了可以运行多种DCNN 并进行实时功率采集的硬件平台。
我们通过运行搭载在人工智能(Artificial Intelligence,AI)设备的CNN,并连续采集电压和电流数据,形成电源功耗的数据集。对于每个CNN,我们多次重复之前的采样和数据处理过程,最终形成n组功耗特征数据。我们设计分类器D 并将数据集进行训练,为了进一步评估参数,增加设置了几个不常用的稀疏度变化的新模型,因此最终标签包括结构参数y和稀疏度参数λ,侧信道算法详见表1。
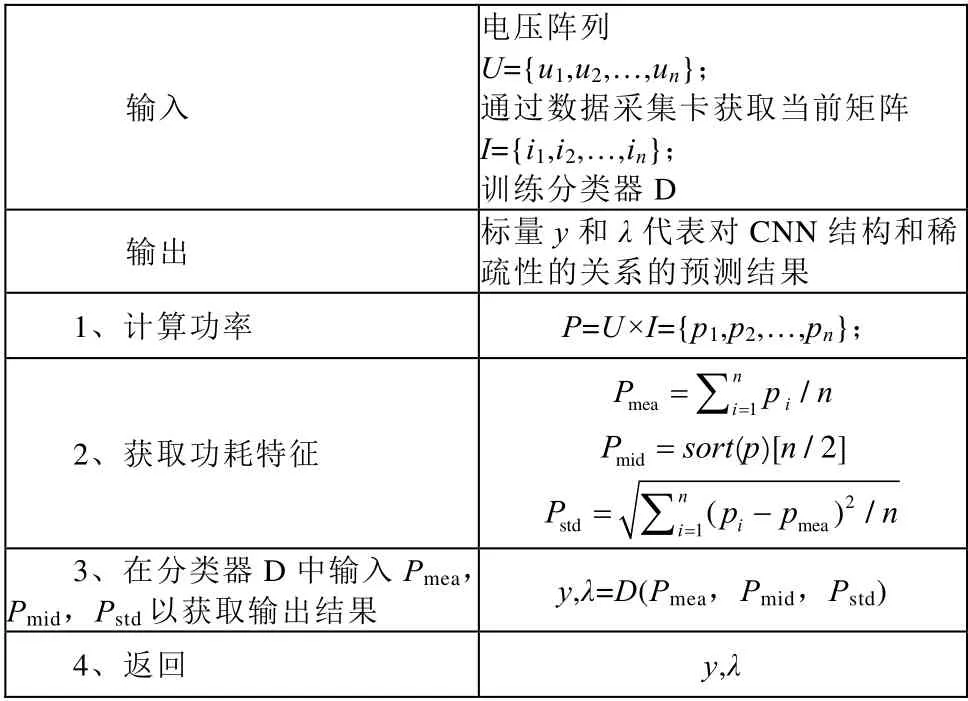
表1 侧信道攻击算法
1.2 平台组成说明
为了能采集到不同CNN 运行过程中的功耗数据,首先我们需要一个能运行多种CNN 的AI设备,它能长时间同时稳定运行多个卷积神经网络,并支持实时切换。功耗数据通过示波器进行实时观察,相关数据通过采集卡进行长期连续采集。
此次实验我们选用的嵌入式AI 设备为树莓派3B+,其采用了BCM2837B0 型号CPU 构建,在2.4 GHz 和5 GHz 的频带都有优异的性能,有线和无线网络吞吐量大约是上一版本的3 倍,并且能够在更长的时间内保持高性能运行。
1.3 测试实验结果分析
测试实验我们使用Alex Krizhevsky[2]设计的AlexNet(Alex Neural Network)对图1 的图像集进行图像分类。图2 为图像分类期间的功耗图。可以观察到图像中有24 个峰,对应图像集中的24 个图像。设备运行CNN 的整个过程,存在开始阶段和结束阶段,我们去除了那些低功率阶段数据,仅取CNN 运行阶段的数据,作为后续数据处理的数据集。

图1 CNN 训练用图像集
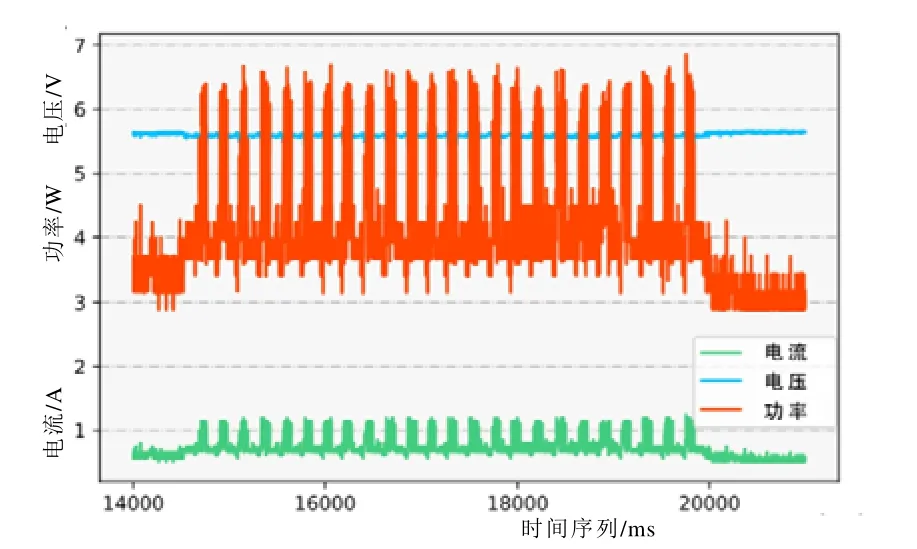
图2 使用AlexNet 对图像进行分类的效果图
由于功耗的瞬时性,在实验设计过程中,我们将每五张图片分为一组,整理所有功耗数据。实验阶段,我们在AI 设备上依次运行了六种常见的CNN,并使用相同的图像集对其进行测试。数据采集和处理后,我们获得功能强大的数据集,具体如图3 所示。
图3 功率特征数据集的可视化
在本次实验中,我们使用机器学习技术来识别CNN。首先,我们扩大了功耗数据的量,每个网络模型的功耗数据的量约有20 000 组,将功率特征数据集随机分为训练集和测试集,其比率为4∶1。首先仅使用SVM 分类器来进行分类。测试集的结果如图4 所示,其中红色部分表示的是架构识别的准确率,平均分类准确率达到96.50%。可以看出不同CNN 的功耗特征具有很高的区分度,因此开展后续实验是很有意义的。

图4 不同CNN 的识别结果
2 试验设计与分析
为了保证实验对象的丰富性和代表性,我们在之前实验的基础上,选取了9 种常用深度卷积神经网络来进行后续实验,分别是Inception-v1、Inception-v2、Inception-v3、Inception-v4、ResNet-v1、ResNet-v2、MobileNet-v1、MobileNet-v2、AlexNet等9 种网络。不同的机器学习算法具有不同的适用范围。由于网络种类的不同,为了避免单一机器学习方法得到的混淆矩阵的效果过好或是过差,所以在数据处理阶段使用随机森林、支持向量机(Support Vector Machines,SVM)、K 近邻分类算法(K-Nearest Neighbor,KNN)、朴素贝叶斯这4 种算法,以保证结果的科学性、严谨性。
2.1 改变卷积神经网络卷积层层数的实验
2.1.1 实验设计
CNN 是一种具有多层网络结构的深层前馈模型,其模型基本结构如图5 所示,CNN 的主要结构包括卷积层、池化层、全连接层、输出层四类。将图像数据输入到CNN 模型之中,多个不同的卷积核就会与输入到模型之中的图像数据进行卷积运算,然后把运算结果再加上一个偏置就可以提取出图像数据的局部特征图,之后再将卷积运算的输出结果通过一个非线性激活函数处理之后,对激活函数的输出结果进行池化操作,就可保留图像数据中最显著的特征。将获取的显著特征通过全连接层,并利用分类器输出相应的结果。
图5 深度卷积神经网络结构
ResNet(Residual Neural Network)[3]的基本网络结构如表2 所示,不同深度的网络结构由不同的子模块搭建,一种基于基本块(BasicBlock),浅层网络ResNet18、ResNet34 都由BasicBlock搭成,另一种基于瓶颈层(Bottleneck),深层网络ResNet50、ResNet101、ResNet152 乃至更深的网络都由Bottleneck 搭成。我们选择了ResNet101作为实验对象,并设置了5 组对照组,分别修改5 组超参数中卷积层的层数,反映到代码上只需要修改ResNet_utild.Block 中卷积层的层数。5 组数据分别记作block1~block5,其Bottleneck 中的层数依次为为3163、3263、3264、3363、4263。
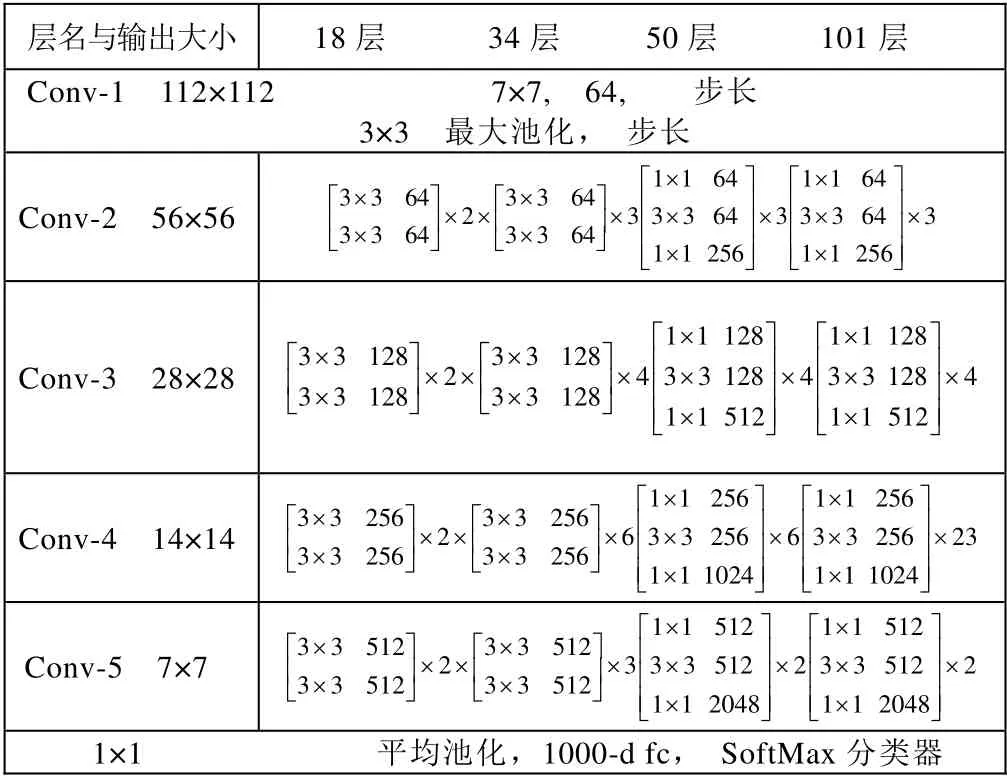
表2 ResNet 基本的网络结构
2.1.2 实验数据分析
通过改变ResNet_utild.Block 里的参数,得到了5 组不同卷积层数的深度卷积神经网络,我们记作3163、3263、3264、3363、4263,后续用四种机器学习得到的混淆矩阵如图6 所示。
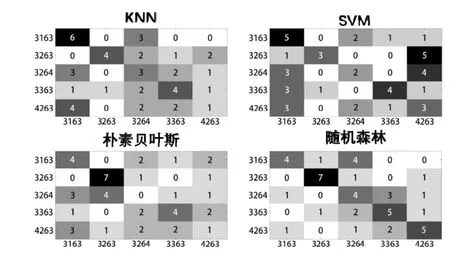
图6 改变超参数机器学习的混淆矩阵
四种混淆矩阵的识别成功率分别为:KNN 算法的40.00%、SVN 算法的37.78%、朴素贝叶斯算法的35.56%、随机森林算法的55.56%,从四组混淆矩阵可以看出,改变卷积层的层数量对平台运行CNN 产生的功耗影响较小。
2.2 改变卷积神经网络网络稀疏度的实验
2.2.1 实验设计
研究发现,任何图像的像素之间局部的相关性较强。CNN 模型通过模拟人的神经网络,使用稀疏连接构建图像的局部感知野,利用网络每层之间的局部空间相关性,只把每层的神经元节点和相近的上层神经元节点连接起来,最大限度地减小了神经网络的参数规模[3]。2012 年,Hinton[4]提出了Dropout,当一个复杂的前馈神经网络被训练在小的数据集时,容易造成过拟合,为了防止过拟合,可以通过阻止特征检测器的共同作用来提高神经网络的性能。同一年,Alex、Hinton[5]用Dropout 算法防止过拟合。Dropout 在实际工作中,能很好地在训练阶段阻止神经元的共适应,让某个神经元以一定概率停止工作,如图7 所示。

图7 Dropout 前后的网络结构示意图
图7 中左边是原来的神经网络,右边是采用Dropout 后的网络。原网络的计算公式是:

通过上述公式中的Bernoulli函数,随机生成一个0~1 的变量ρ,即网络稀疏度实验的可调整变量。我们分别取ρ为0.2、0.4、0.6、0.8、1.0,针对Inception-v3 和MobileNet-v1 这两个网络进行功耗采集以及数据分析。
2.2.2 实验数据分析
Inception-v3 和MobileNet-v1 这两个深度卷积神经网络实验数据生成的混淆矩阵如图8~9。由图中混淆矩阵可知,ρ=0.2 时的识别成功率已经非常理想,新增的实验组主要考察的稀疏度范围是0.4~1.0。通过混合架构和参数稀疏度变量,我们共得到16 个不同网络的功耗数据,对其进行分析,结果如图10 所示。
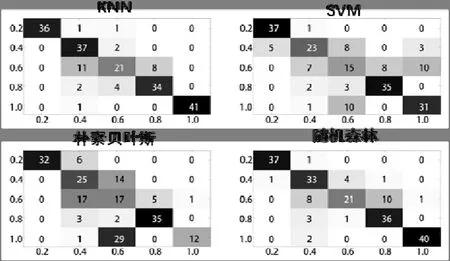
图8 Inception-v3 网络稀疏度机器学习的混淆矩阵

图9 MobileNet-v1 网络稀疏度机器学习的混淆矩阵
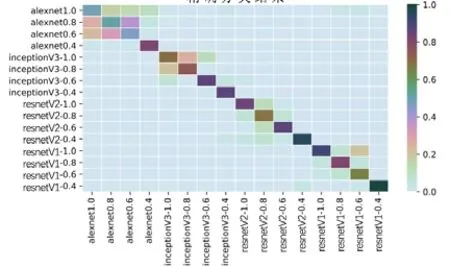
图10 CNN 精细分类的混淆矩阵
具体实验结果数据如表3 所示。表中的准确率是基于上文提到的4 种机器学习算法得到的准确率的平均值。由表中实验数据可知,除了AlexNet 的识别成功率偏低以外,另外五种网络的平均识别准确率都超过75%。混淆矩阵表明,即使稀疏度参数变化,我们仍然以相对较高的准确度获得CNN 的结构。精细分类任务下的参数稀疏度识别成功率虽然略有降低,但结果仍然是可以接受的。
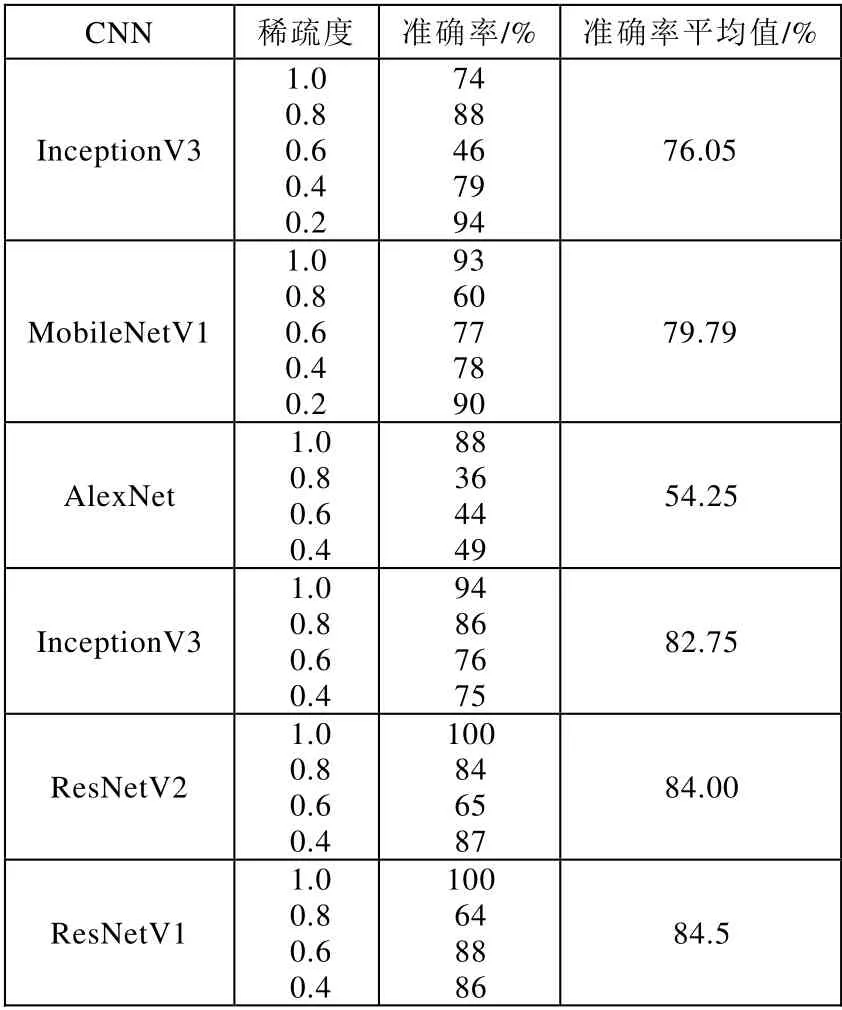
表3 实验结果
2.3 改变卷积神经网络检查点文件的实验
2.3.1 实验设计
我们经常在训练完一个模型之后希望保存训练的结果,以便下次数据迭代或者用作测试,TensorFlow 针对这一需求提供了Estimator 类[6]。Estimator 类提供了向检查点文件Checkpoint 保存和从Checkpoint 文件中恢复变量的相关方法。Checkpoint 文件是一个二进制文件,它把变量名映射到对应的tensor 值,只在train()进行的时候保存数据,如图11 所示。Checkpoint 可以直接使用,也可以作为从它停止的地方重新运行的起点。我们分别对ResNet-v1 和ResNet-v2 这两个深度卷积神经网络设置了2 组对照组,其中Checkpoint分别取两个不同的文件ckpt0 和ckpt1。
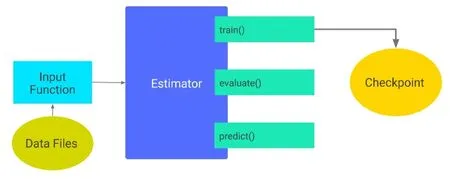
图11 生成Checkpoint 流程图
2.3.2 实验数据分析
四种不同机器学习方法所得的混淆矩阵如图12 所示,我们都能得到比较理想的识别结果,四种机器学习方法得出的混淆矩阵的识别成功率分别为KNN 算法的96.67%、SVN 算法的96.67%、朴素贝叶斯算法的 97.78%、随机森林算法的96.67%,识别成功率均在96%以上,识别效果非常好。
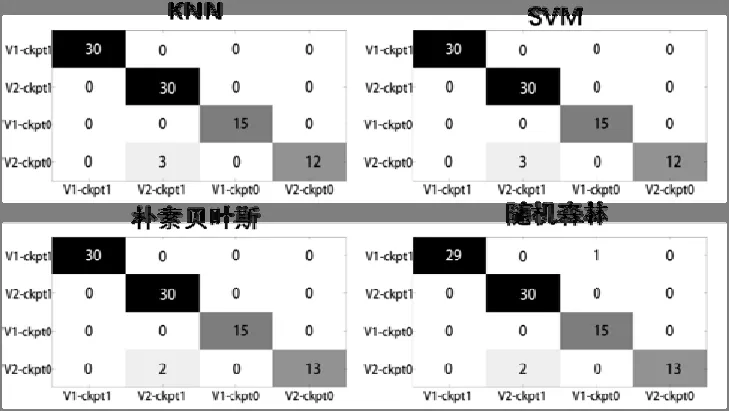
图12 ResNet-v1 和ResNet-v2 初始化状态改变的混淆矩阵
由此可见,通过改变同一CNN 的Checkpoint,对其运行阶段功耗的影响是显著的,这点可以通过混淆矩阵非常直观的反映出来。同样,使用相同Checkpoint 的不同CNN 也能够通过这种方式被高精度的识别出来。
3 总结与展望
本文通过对常见DCNN 设置对照实验,证实了类比侧信道攻击的功耗分析法能够高精度识别CNN。不同卷积结构、不同检查点文件、不同网络稀疏度的CNN 都能通过功耗分析的方式进行识别。这种识别方式有一定的普遍性,后续可拓展的实验方向很多。受制于实验设备的局限性,本实验存在许多不足,接下来需要改进完善的内容主要有以下几点:
(1)本文的研究方向对于一般的CNN 有一定的普遍性,由于实验受限,所涉及到的网络种类以及对照实验次数均有不足。未来可以拓展实验的CNN 种类,增大数据采集量;
(2)实验使用的均为DCNN,后续可以增加除卷积层外的对照实验,例如全连接层、池化层等;
(3)选用的四种机器学习分类方式也各自存在算法缺陷,后续可以考虑增加决策树(Decision Tree,DT)分类算法、逻辑回归(Logistic regression,LR)分类算法;
(4)由于设备限制,实验所用采集卡的采集速率为1000 kS/s。后续实验中,采集卡的性能还可以得到提升,现在每个网络的功耗数据组约为20 000 组,未来可以增加数据组的量,进一步提升实验的科学性和严谨性。
猜你喜欢
北京航空航天大学学报(2022年7期)2022-08-06
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
电影(2018年8期)2018-09-21
北京航空航天大学学报(2018年1期)2018-04-20
个人电脑(2016年12期)2017-02-13
电子制作(2016年19期)2016-08-24
