
一种改进感知哈希算法的2DPCANet人脸识别方法
2022-07-18 06:49王莎莎刘道华
信阳师范学院学报(自然科学版) 2022年3期
赵 莉,王莎莎,刘道华*,张 建
(1. 信阳农林学院 信息工程学院, 河南 信阳 464000; 2. 信阳师范学院 计算机与信息技术学院, 河南 信阳 464000)
0 引言
在计算机视觉领域和模式识别中,图像分类一直成为困扰很多学者的难题,因为基于视觉内容的图像分类容易受光照、遮挡、聚焦等多种因素的影响。虽然过去人们在图像识别系统中研究出了很多特征提取方法,但因这些方法大多都需要通过手工设计算法来实现,新的神经网络[1]在各种识别任务上的表现,引起了人们的高度关注,但由于神经网络的数据量过于庞大,使得参数调整的专业性成为网络取得成功的关键。为了解决这一难题,CHAN等[2]提出了一种较为简单的主成分分析网络(PCANet)模型,该模型在训练网络框架之前便固定了网络的参数,实验结果证明了PCANet在图像分类任务中取得了很好的表现;FENG等[3]在场景分类的过程中也运用了其他网络代替PCA,并获得了很好的分类效果;JIA等[4]提出了一种基于二维主成分分析的网络图像分类方法,并将其应用于极光分类中,虽然提升了分类的速度,但分类精度受到一定程度的影响。总之,这些基于PCANet的变体方法在各类场景分类任务中取得了一定的成效。
目前,利用PCANet方法进行人脸图像分类的方法很多,但既能快速地提取出人脸特征又能保存图像的结构信息的研究方法还比较少。基于此,笔者提出了一种基于改进感知哈希算法的2DPCANet人脸识别方法,在PCANet的基础上采用二维主成分分析代替原先PCA的计算过程以减少分类的耗时。实验表明,改进的PCANet算法在人脸图像分类任务中能有效地提高计算速度,且该方法能较好地保存了图像的结构信息。
1 二维主成分分析
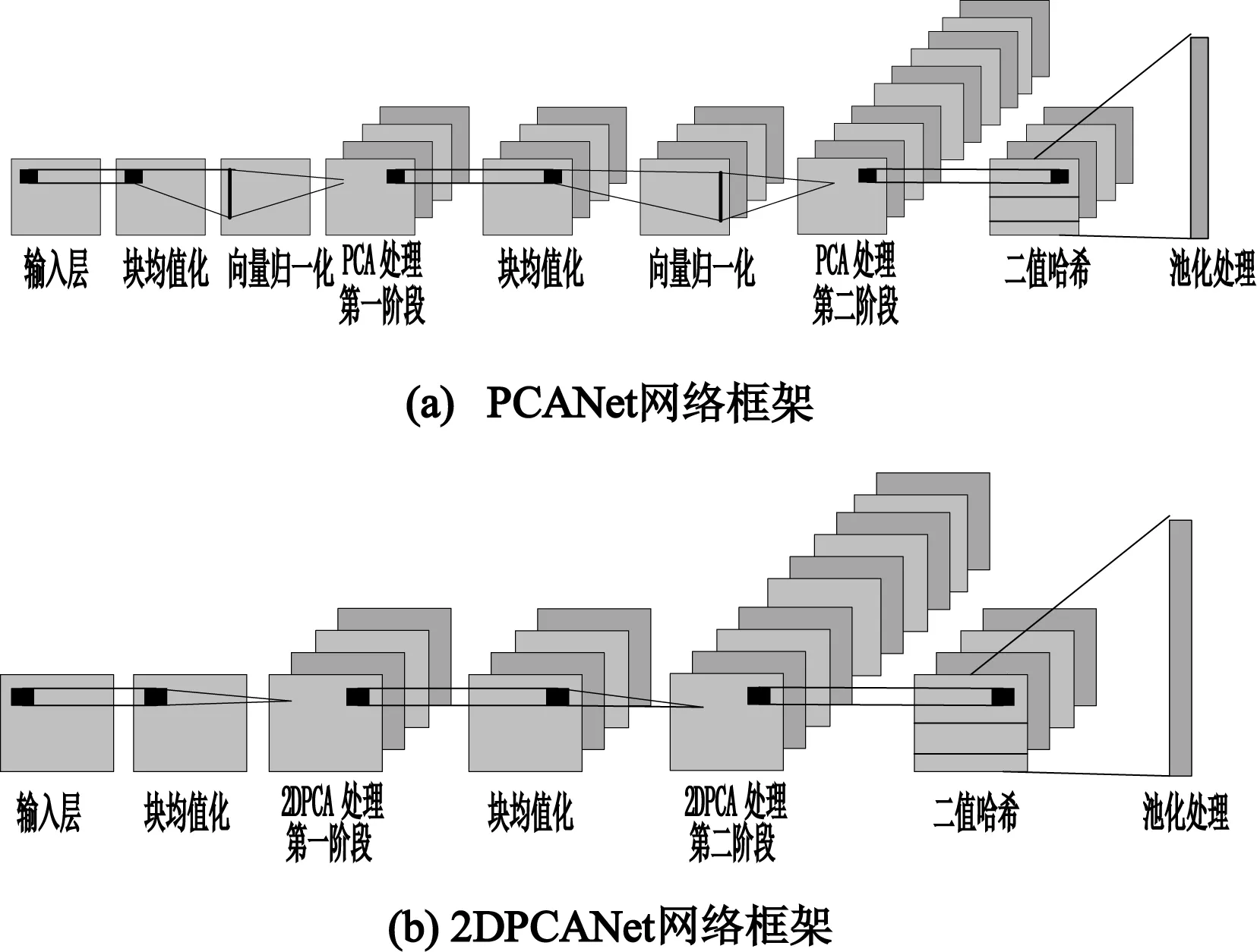
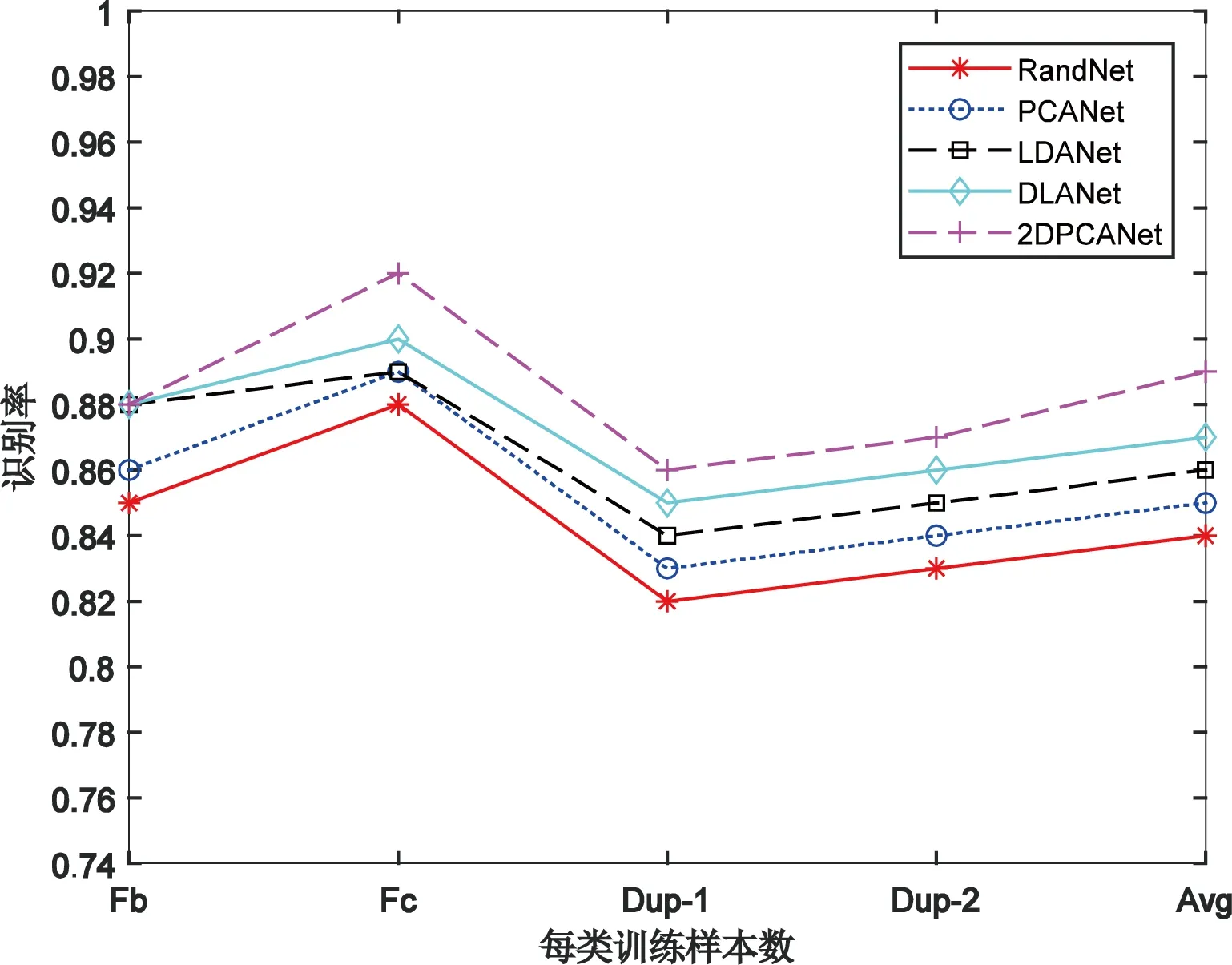
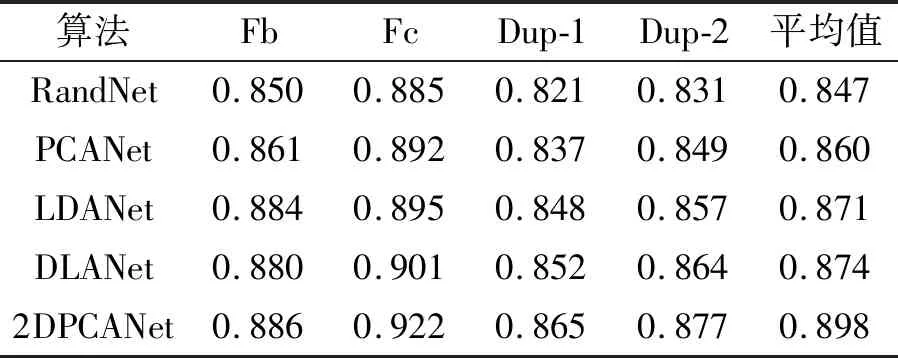
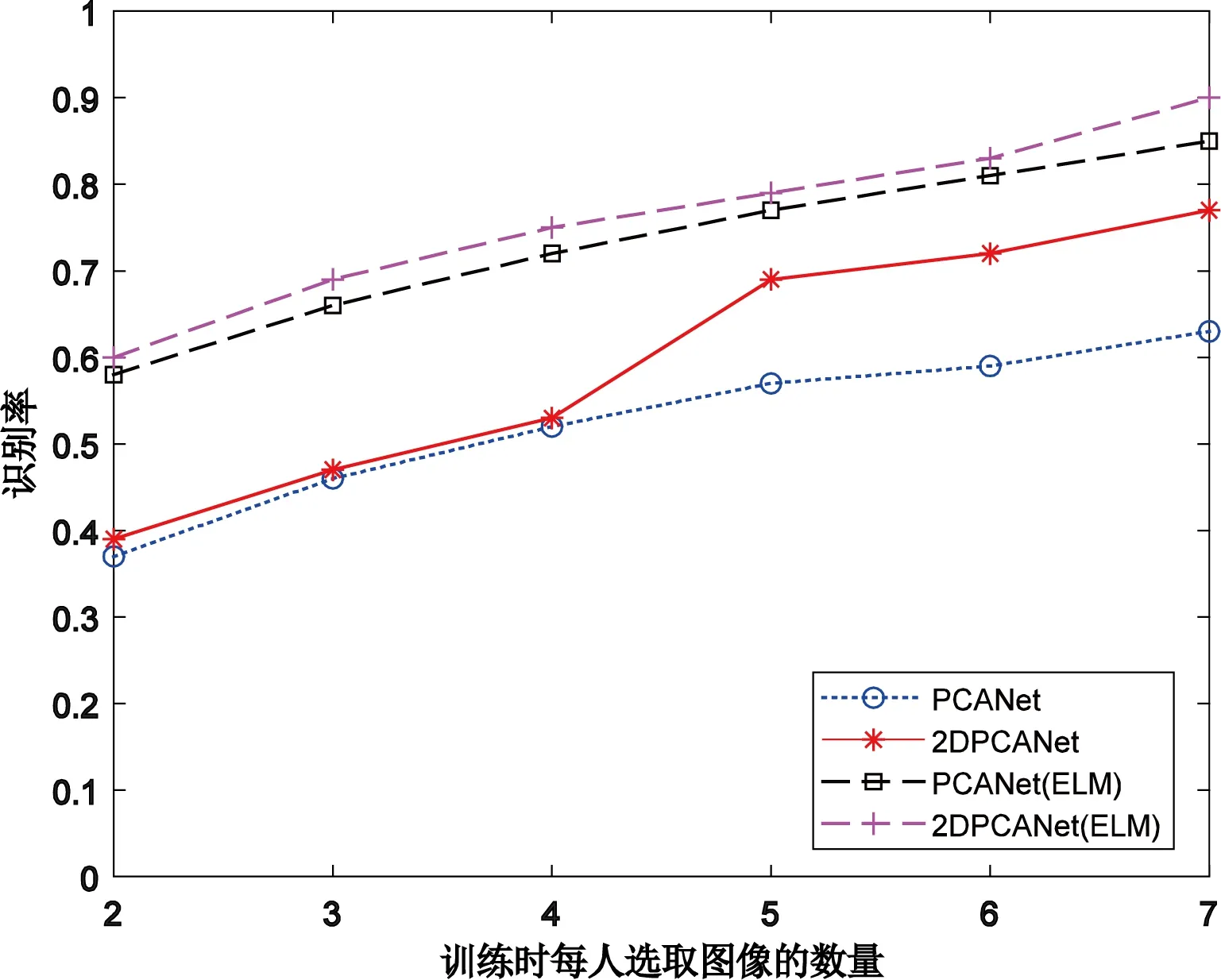
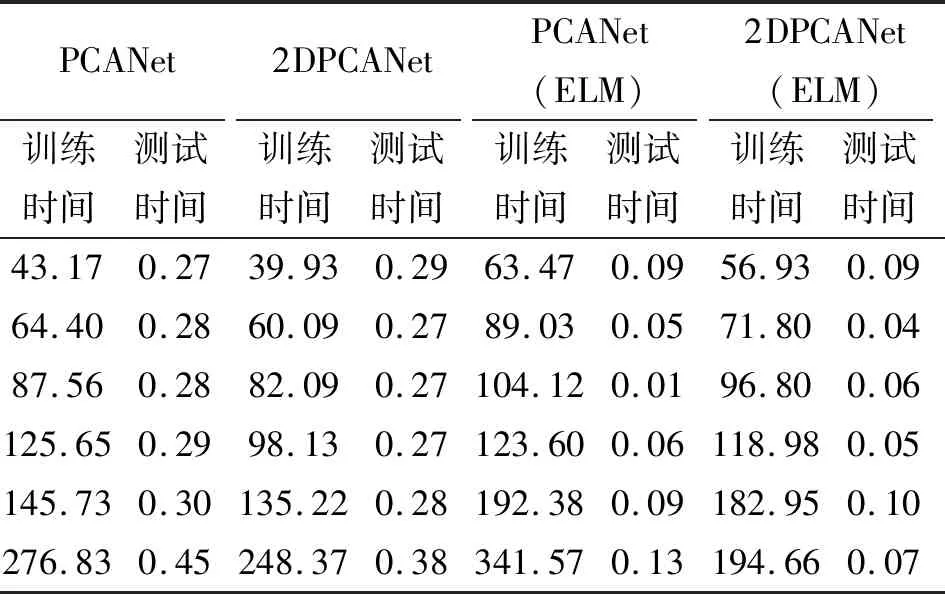
二维主成分分析计算的过程不需将原始数据向量化,可直接对二维矩阵进行计算,其思想为:假设X∈Rn×d为一正交矩阵,其中d (1) 则G可以写成: (2) 在这个过程中,可以根据整体样本的散度去判断正交向量的效果,也即是求出最大特征值所对应的最佳投影矩阵。最优投影矩阵用Xopt=[X1,X2,…,Xd]表示,其即为所求的特征值对应的特征向量。 因2DPCA在处理图像矩阵时只在行向量上进行,所以会造成系数增多的现象。受文献[5]的启发,可以同时对两个方向的向量进行计算,以减轻计算的复杂性。其过程如下:设Z∈Rm×q为正交矩阵,那么A投影Z上得到矩阵B=ZTA后,通过两个方向的计算便可得到最终的投影矩阵: C=ZTAX。 (3) 在网络多次特征提取的过程中,会在一定程度上,减少人脸数据的低频信息。为了更好地保留原始人脸图像的详细轮廓,受文献[6]的启发,采用感知的哈希算法去提取人脸的低频信息。采用离散余弦变换(DCT)的方式将图像的像素域转换到频率域,从而更好地保留图像的低频信息。 利用的变换核是余弦函数,具体的离散余弦变换正变换核如下: (4) 式中:x=0,1,…,M-1;u=0,1,…,M-1;y=0,1,…,N-1;v=0,1,…,N-1。 设f(x,y)为图像矩阵,其大小为M×N,则二维DCT变换方式如下: (5) 将上述调整角度后的人脸图像进行尺寸上的处理,再对处理后的人脸图像进行DCT变换,得到DCT变换的系数矩阵,再对与图像最低频率对应的矩阵进行整合比较,最后综合主成分分析结果,便可得到人脸的识别效果。 考虑到传统的主成分分析网络在图像处理时需将原始数据向量化的缺点,在原始的PCANet网络基础上进行优化,从而提出改进的2DPCANet网络结构。该结构在保留原始的数据处理过程二值哈希以及分块直方图的基础上,分别选取了极限学习机与支持向量机对网络最后提取的特征进行分类,并将最后的结果进行了对比。图 1 为2DPCANet网络结构和PCANet网络结构两者之间的对比图。 图1 PCANet与2DPCANet网络框架对比图Fig. 1 Comparison diagram of PCANet and 2DPCANet network framework 输入训练的人脸图像后,第一层的2DPCA是为了计算出输入人脸图像的输出特征向量,其主要步骤如下: (6) (2)对输入的人脸图像分别进行归一化操作,选取第i图像Ai,经过归一化后可得: (7) 其中,Pi=(pi,1,pi,2,…,pi,mn),pi,j∈Rk×k表示第i幅人脸图像Ai去均值后的块,提取的块大小为k×k。 (3)将所有经过归一化的人脸图像组合成一阶全局均匀阵: (8) 设X∈Rk×D1为一个正交矩阵,Di表示第i阶段卷积核的个数,经过第1层的2DPCA处理后可得到一阶半正定矩阵:Y=piX,其中X为P中的一个矩阵pi经过投影得到的矩阵,那么式(2)可以写为 则所求的特征值对应的特征向量为Xopt=[X1,X2,…,XD1]。 (4)利用上述求得的正交矩阵,同理另设Z∈Rk×D1也为正交矩阵,经过投影后可得B=ZTpi,则生成人脸图像的协方差矩阵为: (9) (10) (11) 在二维主成分分析网络第二阶段得到了D1D2个特征映射图,然后在基于2DPCANet的输出层利用二进制哈希算法和分块直方图对其进行处理进而组合成最后的输出特征。 具体的步骤:首先对第二个阶段输出的特征映射图利用哈希算法进行二值化,利用Heaviside函数H(·)将其转化成二进制矩阵,输入正数则输出1,其他情况输出为0。 (12) 其中,每一个像素为[0,2D2-1]。 再对第一阶段获得的图像Fi,d1(d1=1,2,…,D1)划分为B块,再将每个块的分块直方图进行整合统计处理,处理后用向量hist(Fi,d1)表示,进行编码后生成对应特征: (13) 实验基于Windows系统,电脑配置为IntelCore i7-6700,内存为8 G,CPU主频为3.41 GHz。在实验过程中,利用2DPCANet算法对人脸图像进行处理后,分别选取了SVM和ELM两种分类器进行人脸图像的分类。 实验选用AR数据集和FERET数据集评估所提方法的有效性。文中提到的LDANet[2]方法是一种从数据整体提取人脸特征的线性判别分析算法;RandNet[2]是为了摆脱预训练的困扰在PCANet基础上进行改进的一种网络模型;DLANet方法是一种考虑到人脸鉴别信息的特征学习方法。在实验过程中因选取了SVM作为分类器,所以其参数选取的好坏决定了特征分析方法的性能。实验采用了十折交叉验证的方式进行参数选取,结果如图 2 所示。在实验过程中最终选取参数c的值为0.176,b的值为0.615。另外实验以识别率为人脸图像分类的评价指标。 图2 2DPCANet模型中SVM分类器参数选取三维示意图Fig. 2 Three dimensional schematic diagram of SVM classifier parameter selection in 2DPCANet model 实验将FERET[7]人脸数据集的1196个人的照片分为训练集与验证集。对于人脸图像识别,将验证集的人脸图像分为四种:Fb是在时间与光照变化均相同条件下拍摄的图像;Fc图像是在不同光照的条件下拍摄的;Dup-1所包含的是在不同时间内由不同相机拍摄的图像;Dup-2则是实验对象在间隔一年以后由不同相机拍摄的图像。图 3 为FERET的部分人脸图像,实验SVM采用的是liblinear工具箱,极限学习机隐层神经元的个数设置为5000,图4为文中所提的2DPCANet方法与人脸识别对比方法LDANet[8]、RandNet[9]和DLANet[10]的识别率对比图。 图3 FERET的部分人脸图像Fig. 3 Partial face images of FERET 图4 FERET数据集图像识别率Fig. 4 Image recognition rate of FERET dataset 表1为不同方法在FERET数据集上的识别率。从表中可以看出,在每类训练样本数中2DPCANet方法的识别率始终优于其他方法,尤其是在Fc训练部分,2DPCANet的识别率更是达到了0.922,要比RandNet方法的识别率高了约4%。而在Fc后面其他类的训练样本部分,识别率会出现下降趋势,但最终仍呈现上升趋势,这表明所提出的2DPCANet方法对表情和光照变化有一定的鲁棒性。 表1 不同方法在FERET数据集上的识别率Tab. 1 Recognition rate of different methods on FERET data set 对于LFW人脸数据库,实验选取个人图像大于或等于10幅的人脸作为实验对象,实验从LFW的对齐版本LFW-a中选取158个人的照片作为训练集,实验训练时每人随机选取f(f=2,3,4,5,6,7)幅人脸图像作为训练样本,剩下部分作为测试集。SVM使用liblinear工具箱,将ELM的隐层神经元的个数设为5000,实验重复10次取平均识别率作为评价指标。实验结果如图 5 所示。 图5 FERET数据集图像识别率Fig. 5 Image recognition rate of FERET dataset 图5为2DPCANet和PCANet方法使用SVM作为分类器以及两种网络采用ELM作为分类器在LFW数据集上所获得的识别率对比图。从图中可以看出使用SVM作为分类器的准确识别率效果不如使用ELM,而且随着训练时选取图像数量的增多,整体的识别率呈现上升的趋势,当个人选取图像的数量达到7时,所提出的2DPCANet(ELM)识别率比原始的PCANet高了0.27。从图中可以看出整个过程中,改进方法的识别率均高于其他几种对比方法。 经过实验验证得到了不同方法在LFW数据库上的性能表现,实验结果如表2所示。从表2中的对比数据可以看出,文中所提出的改进方法在训练时间上明显比PCANet提升了很多,因为2DPCANet方法不需要对原始数据进行向量化处理,而直接可以在二维图像上进行操作。另外,从表中可以看出训练时随着图片的增多,ELM的训练速度明显比SVM有优势。 表2 在LFW数据库上不同方法的性能Tab. 2 Performance of different methods on LFW database 提出了一种用于人脸识别的二维主成分分析网络模型,利用2DPCA代替PCANet中的PCA计算过程,同时在输出阶段采用感知的哈希算法去提取人脸的低频信息,从而提高了整个分类模型的识别率。文中所提的2DPCANet方法即使测试环境出现光照变化或者遮挡时,也能表现出很好的识别效果,实验结果表明,其在减少分类耗时的同时更好地保存了图像原本的结构信息。但该方法仍有待改进的地方,当数据库的数量增多时,采用SVM方法进行分类时其准确识别率会逐渐下降,而且其速度也没有ELM快,因此在今后的工作中可以继续改善模型,进一步提升2DPCANet算法在人脸识别中的效果。2 改进的感知哈希算法
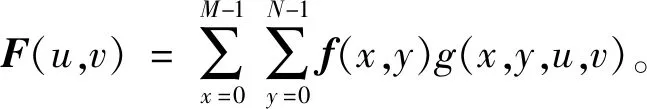
3 基于二维主成分分析网络的人脸图像分类
3.1 第一层的2DPCA
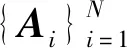
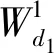
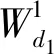
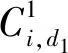
3.2 第二层的2DPCA
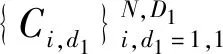
3.3 基于2DPCANet的输出阶段
4 实验结果


5 结论
猜你喜欢
大数据(2021年6期)2021-11-22
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
计算机工程(2020年3期)2020-03-19
中国听力语言康复科学杂志(2019年3期)2019-06-24
动漫星空(2018年9期)2018-10-26
中国交通信息化(2018年3期)2018-06-13
中国交通信息化(2016年2期)2016-06-06
