
基于改进YOLOv3的安全帽检测方法研究
2022-07-18 02:36:26丁文龙费树珉
电子测试 2022年11期
丁文龙,费树珉
(东南大学自动化学院,江苏南京,210096)
0 引言
近年来,建筑工地作业人员因为未佩戴安全帽而导致安全问题的现象频频发生。施工场景中,由于施工人员安全意识不足,人员监管不力都是导致该类安全事故发生的原因。因此,对工人安全帽佩戴的实时检测十分重要。当前主要是人为监管施工工人的安全帽佩戴情况,检测效率低下。
目前,一些学者对安全帽检测已有一些研究。文献[1]利用Vibe背景建模算法,并基于运动对象分割的结果快速定位行人,并通过头部位置、颜色空间变换来实现安全帽检测。文献[2]以梯度直方图(histogram of oriented gradient,HOG)和圆环霍夫变换提取特征,再通过分类器进行安全帽检测。文献[3]利用运动物体提取K-Nearest-Neighbor(KNN)分类器开发了一个可以自动检测自然环境中人员是否带上安全帽的系统。传统的安全帽检测方法依赖于人工设计特征,基于此设计分类器。检测效果受人员先验知识影响大,该方法在应用上有局限性。当前采用深度学习方法通过CNN提取特征方式的方式可以避免人员主观知识偏差的影响,被许多学者采用。利用现有模型训练,能够得到检测效果良好的目标检测模型。近年来,目标检测模型不断涌现的过程中,出现不同性能和适用场景的算法模型。在这一系列模型中,YOLO模型凭借其结构精简,检测速度快,适用于多种场合等优点,受到了大量相关研究人员的关注和具体应用。
本文基于图像处理方法,针对YOLOv3[4]进行改进,提出一种施工场景中准确高效的安全帽检测算法。
1 基于YOLOv3改进算法的安全帽检
1.1 YOLOv3目标检测算法原理
YOLOv3使用Darknet-53作为特征提取网络。Darknet-53包括53个卷积层和5个最大池化层。YOLOv3网络把图片分为大小相同的网格,每个网格有3个用于预测的anchor框。每个框的预测信息包含框的宽度,高度,框的起始位置,物体预测置信度以及N维分类物体类别数。YOLOv3在特征提取之后采取特征金字塔(Feature Pyramid Networks)[5]的思想,将不同大小的特征图用于预测不同尺寸的物体。共有三个不同大小的特征图,越大的特征图预测越小的物体。通过将浅层特征和深层特征融合,有效利用了低层网络的位置特征以及高层网络的语义信息,使得YOLOv3网络能够准确识别物体的类别,同时将物体进行精准定位。
1.2 K-means++锚框生成优化
YOLOv3文中对COCO数据集采用K-means[6]算法获取用于目标检测的初始先验框。不同于COCO数据集的目标尺寸大小和类别数量,本文制作的数据集仅有两个类别,且安全帽在图像中的尺寸偏小。因此,需要采用K-means算法重新获取用于当前检测任务的初始先验框。由于K-means算法需要人为确定初始聚类中心,不同的聚类中心会导致不同的聚类结果。K-means++算法随机选择初始聚类中心,并选择距离最近聚类中心较远的点作为新的聚类中心,并重复此过程,直到选取完K个聚类中心。从而避免人为选取聚类中心的缺点。
本文针对自制数据集,采用K-means++算法进行聚类,得到9个先验框尺寸,并分配到不同尺寸的预测分支上,小尺度锚框为(5,11),(7,16),(11,22)。中尺度锚框为(17,30),(26,44),(39,66)。大尺度锚框为(58,102),(93,157),(182,255)。
1.3 scSE注意力模块融合设计
在目标检测任务中,当网络层级加深。可采集的目标信息特征逐渐减弱。从而导致检测目标的漏检和误检等问题。scSE(Concurrent Spatial and Channel Squeeze and Channel Excitation)是一种更加轻量化的SE-NET变体。scSE模块由在输入通过sSE(Channel Squeeze and Spatial Excitation)和cSE(Spatial Squeeze and Channel Excitation)两个模块之后相加。其中,cSE将特征图通过全局平均池化改变输入的尺寸,然后使用了两个卷积进行信息的处理,最终得到C维的向量,接着使用sigmoid函数进行归一化,得到对应的掩码。最后通过通道纬度融合,得到信息校准后的特征图。sSE直接对特征图使用卷积,将输入特征图的通道变为1维,然后使用sigmoid进行激活得到空间注意力图,接着施加到原始的特征图中,完成空间的信息校准。scSE整体结构如图1所示。该注意力模块同时根据通道和空间的重要性来校准采样。这种重新校准使得网络学习更有意义的特征图。本文将scSE注意力模块添加至YOLOv3模型特征提取网络之后的三个检测支路的多个卷积模块之间进行网络优化。

图1 Concurrent Spatial and Channel Squeeze and Channel Excitation(scSE)
1.4 引入残差模块
随着网络的加深,在靠近检测输出端的深层网络中,含有图像小目标的特征信息较少,而本任务所检测的安全帽以及人体头部都属于这样的小目标。为了让检测层能够检测到目标信息,在输出端的卷积操作之前,将卷积模块替换为残差模块。通过跳跃连接,将网络中层级间的信息的得以传递。实现在网络较深的背景下,能够加强模型对深层特征的检测能力。图2为本文引入的残差模块结构图。本文残差模块前通道数为512,分为残差部分和快捷连接部分。残差连接先经过一个1×1的卷积,通道数变为128。然后经过3×3的卷积层,通道数保持不变,再经过一个1×1的卷积层,通道数变为1024。快速连接部分通过一个1×1的卷积将输入通道512转换为1024。最后将两个分支进行相加,得到残差模块的输出。改进后模型如图3所示。
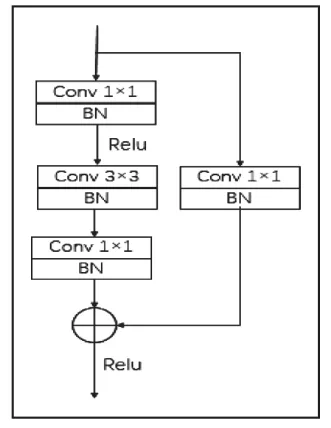
图2 残差模块结构图

图3 改进后模型结构
2 实验结果分析
2.1 数据收集
当前开源的安全帽数据集有SHWD数据集,共包含7581张图片,分为person(未佩戴)和hat(佩戴)两类。数据集包含9044个正类样本以及111514个负类样本。由于该数据集场景单一,缺乏更多施工现场的场景,缺乏佩戴非安全帽的场景。因此本文针对以上缺点,另外从多个工地监控视频中采集了另外828张工地监控视频图片。
2.2 数据标记及处理
从工地监控视频中采集的数据用labelImg软件进行标记。本文按照Pascal VOC格式对监控视频数据进行标注。标定后生成的xml文件标注了图片中安全帽和未佩戴安全帽头部的类别和位置信息。数据标注界面如图4所示。

图4 数据标注界面
标注后的数据量较少,为增强数据的多样性,提升模型的泛化性和鲁棒性,本文对工地监控视频做了翻转,加噪,HSV变换等方式进行数据增强,最终得到3312张工地视频图像。本文将自制后增强的图片融合至SHWD数据集,得到本文实验所用的数据集SHWD-NW,共10893张图片。并采用留出法按照8:1:1划分训练集,验证集,测试集。
2.3 实验平台
本文实验基于GPU进行运算,在实验室服务器上搭建包括Windows10,Python,OpenCV等环境。深度学习框架采用Pytorch。实验平台配置如表1所示。

表1 平台配置
2.4 网络训练
使用深度学习模型YOLOv3进行模型训练过程中,损失函数在训练迭代的过程中会逐渐降低。本次实验中,训练批次为100。模型迭代次数共55100次。在0到50个批次时,学习率初始设置为0.001,在50到100批次时,学习率初始设置为0.0001。每经过一个训练批次,学习率减少为上一个训练批次学习率的0.94倍。权重衰减系数为0.0005。模型在0到44080次时损失函数迅速降低,在44080次之后损失逐渐收敛于3.27,得到一个训练完毕的模型。图5为模型训练过程中模型损失变化图。
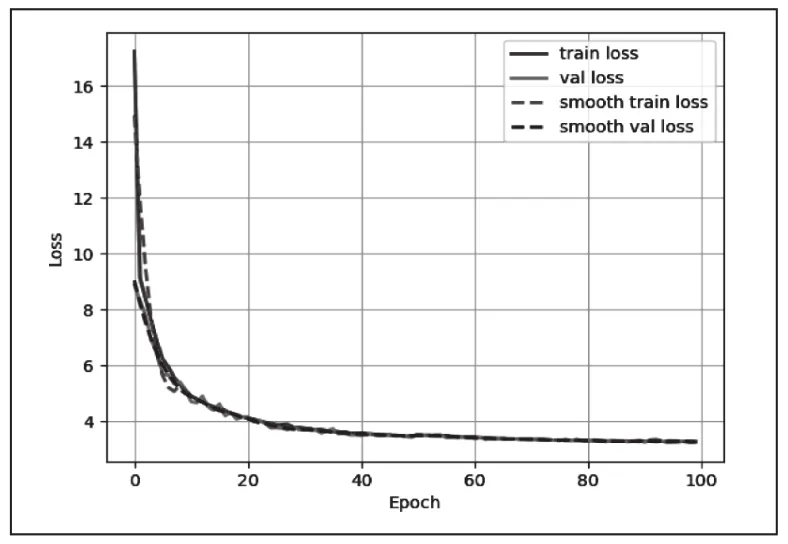
图5 训练过程损失曲线
2.5 评价指标
准确率(Precision),召回率(Recall)以及平均准确率均值(mean average precision)是衡量目标检测模型性能的一般性指标。本文采取平均准确率均值(mAP)作为模型性能评价的指标。
准确率是模型预测的正类样本数和预测总样本数的比值。召回率是预测样本中正类样本和预测样本的比值。通过对本文分类类别的helmet以及head两种类别,针对准确率,召回率曲线的图像使用积分计算该曲线与坐标轴的面积,来计算两种类别的准确率(AP),两个类别的准确率求和再除以分类的类别,得到本文所使用的评价指标之一:平均准确率均值。平均准确率均值越高,表明模型对检测任务的目标识别效果越好。
此外,本文使用识别帧率(f/s)来衡量模型的检测速度。该数值越高,代表模型的检测速度越快。用训练好的模型针对图片进行检测得到。
2.6 实验结果
本文采用改进YOLOv3模型在自制的数据集中SHWDNW上进行实验。并对比目标检测的其他常见方法:YOLOv3,Faster R-CNN算法等。实验结果如表2所示。
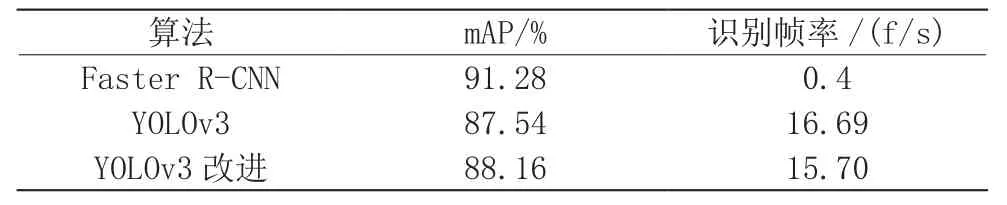
表2 实验结果
实验结果表明,在416×416的图片输入尺寸下,在检测准确率方面,Faster R-CNN的平均准确率最高,达到了91.28%。本文所采用的算法改进型YOLOv3相比Faster R-CNN,准确率稍有不及,但是改进型YOLOv3算法的检测速度比Faster R-CNN有显著优势。另一方面,改进型YOLOv3相较于YOLOv3,在检测速度下降不大的情况下,检测准确率有相应的提升。能够较好的满足工地场景安全帽检测任务的准确性和实时性要求。
3 结束语
本文基于开源数据集以及自制工地现场监控视频数据集进行了安全帽佩戴检测实验。采用K-means++优化YOLOv3算法所需的anchor尺寸,在网络模型中加入scSE注意力模块,使网络学习重要的特征图,用残差模块替换卷积模块等方法改进YOLOv3网络,使网络获得较好的前后特征信息传递。经过本文改进后的安全帽检测模型同时获得了较高的检测准确率和检测速度。可以较好地满足施工现场安全帽检测任务的需要。
猜你喜欢
星星·诗歌原创(2023年12期)2024-01-06 08:24:53
机电安全(2022年4期)2022-08-27 01:59:42
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电视技术(2014年19期)2014-03-11 15:38:20
