
共享后处理边缘信息的实例分割算法
2022-07-11 01:12张宁
电子技术与软件工程 2022年7期
张宁
(厦门航空有限公司数字委员会 福建省厦门市 361006)
1 引言
随着时代的变化和人类科技的提升,人脸识别、目标检测和图像分割等领域的研究成果已开始服务于人们生活中的方方面面。因此,人们对于计算机视觉及相关问题的研究也越来越深入,图像分割(image segmentation)是计算机视觉领域中尤为重要的一个研究和应用方向。它是一种利用计算机来对图像中的信息进行加工处理、计算分析并理解,从而识别各种各样不同类别的目标和对象的技术,是神经网络、深度学习算法的一种实践应用,为其他视觉处理任务提供了一个可靠的基础支持。图像分割的研究成果在各个领域都起到了非常重要的作用,其分割结果有助于后续的场景分析与理解。但是由于图像中实例的复杂性、重叠性、不确定性等问题,使得图像分割这一任务仍面临着极大的挑战,尤其是在对目标区域进行较细粒度的分割时,大部分算法得到的结果往往较为粗糙。
针对此问题,本文提出了一种共享后处理边缘信息的实例分割算法。该算法将边缘信息进行预处理,并在Mask R-CNN[1]网络中引入含有待分割目标边缘信息的并行分支,加强深层次网络学习中的边缘信息,并利用经过回归的边界框信息可以在后续RoIAlign 中得到效果更好的特征层,从而优化掩码分割结果。
2 相关工作
图像分割是图像处理中的关键技术。自1970 年代以来,这项研究已经进行了数十年,并取得了很大进步。迄今为止,无数学者已经借助各种不同的理论提出了数千个分割算法,并且这一领域的算法研究现在也依旧十分活跃。
图像分割算法的研究主要分为两种类型。一种是使用传统的图像处理方法对图像的颜色,纹理和亮度等特征进行加工,从中选择出待检测目标的轮廓信息,从而完成图像分割任务。例如:基于阈值的分割方法,基于区域的分割方法,基于边缘的分割方法。但是,早期的图像分割算法依赖图像中低级的视觉信息,当检测图片中存在光照不均,成像模糊和噪声较多等问题时,这些传统的分割技术常常会得到错误的分割结果。
随着深度学习的逐渐发展,学者们进一步研究了一些基于深度学习的图像分割方法来代替传统的分割方法。Bharath Hariharan等人于2014 年提出的SDS 算法称得上是最早的实例分割算法,也可以说是现有实例分割算法的基础。该算法将检测和分割两个任务结合在了一起:首先由目标检测来提供实例的模糊位置,然后利用语义分割对每个像素点进行分类。虽然SDS 算法的准确性与现有的高级算法相比起来有较大差距,但是它作为实例分割算法的开端,给后续的研究提供了一个有效且精妙的思路,在此基础上,Bharath 等人基于SDS 算法进行了改进,提出了HyperColumns 算法,对图像的底层特征和高层特征进行了深度组合,使得该算法可以得到更加精准的细节信息,从而提高了分割的精度。
Dai 等人于2015 年提出了CFM(卷积特征掩码,Convolutional Feature Masking)算法,该算法第一次将掩码(Mask)这一概念引入到实例分割中。图像掩码是指使用图像块覆盖住图像中的部分特定区域,从而更改图像处理的范围。CFM 算法使用矩形框来为特征图生成掩码,并且可以把任意区域生成固定规模的特征,这种统一的形式方便了后续的处理。此后,Dai 等人提出了一种新的实例分割方法MNC(多任务网络级联,Multitask Network Cascade),MNC 算法通过共享特征实现了多任务的级联,该算法把对于实例的边界框预测、类别分类和掩码分割这三个任务通过级联而集成到一个端到端的实例分割网络框架中,以进行高质量的实例分割。
全卷积实例语义分割也是一种端到端处理的实例分割算法。该算法使用CNN(卷积神经网络,Convolutional Neural Networks)来提取特征,用区域建议算法来生成感兴趣的区域(RoI,Region of Interest)并给这些感兴趣区域计算出相关评分,然后确定实例所属的最终区域和分割结果,从而获取实例分割的结果。
Mask R-CNN是目前最常用的且最有效的实例分割算法。该算法在目标检测算法Faster R-CNN中添加了一个用于预测分割掩码的分支。该算法不仅可以得到一个高质量的实例分割结果,而且还有强大的可扩展性,可以进一步应用于人体关键点检测等领域。但该算法虽然在实例分割领域处于领先地位,其分割结果的准确性却不如语义分割的结果。
3 本文方法
本文提出了一种共享后处理边缘信息的实例分割方法,改善了图像实例分割的结果。在分析Mask R-CNN 的实例分割结果时,很容易发现大部分掩码的边缘细节与对象的实际边缘具有一定的误差,严重一点的甚至损失了一部分目标。其原因是在执行实例分割的过程中,该算法并不是对图像中的像素点直接进行分类,而是先识别要分割对象的边缘,然后再对由边缘信息确定的封闭区域进行掩码填充。为了提高算法对实例边缘的分割准确率,在已有的网络框架基础上,本文提出了一种共享后处理边缘信息的实例分割算法,用以提高掩码分割的精度。本文算法框架如图1 所示。
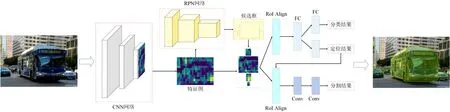
图1:共享后处理边缘信息的实例分割算法
3.1 Mask R-CNN网络结构
Mask R-CNN 网络结构由骨干网络,头结构和掩码分支这三个模块组合而成。其中,骨干网络被用来进行特征提取,头结构用于进行边界框回归和类别分类,而掩码分支被用于为每个RoI 进行像素级别的分割。这种网络结构使得Mask R-CNN 算法可以同时完成对实例对象的分类,回归和分割任务。
如图2 所示,Mask R-CNN 共有三个分支,分别起到对象分类、对象定位和对象掩码分割的作用。其中,分类分支和定位分支都是Faster R-CNN 中原本就具有的分支。与Faster R-CNN 不同的地方在于,Mask R-CNN 算法使用RoIAlign 对每个感兴趣区域进行校正。RoIAlign 是一种为了矫正偏差而提出的一个量化的、简单的自由层,已保留精确的空间位置。Faster R-CNN 使用RoI Pooling 将感兴趣的区域从原始图像区域映射到了卷积区域,并且通过池化操作将其调整到一个固定大小,最后将输入区域的规模归一化为卷积网络所需要的输入大小。但是在规范化的过程中,RoI 和提取到的特征不匹配的现象时有发生,且不可避免,而直接将RoI 和特征的尺寸缩放到统一大小则会导致部分特征的丢失。为了解决这个问题,Mask R-CNN 提出了RoIAlign 的概念,使用RoIAlign层将提取的特征与输入的感兴趣区域对齐,使用双线性插值的方法来计算RoI 中的四个固定采样位置得到的输入特征值值并合并结果。

图2:Mask R-CNN 中三个分支的结构示意图
增加的用于预测分割掩码的分支本质上是一个小的FCN(Fully Convolutional Networks, 全卷积网络)网络,用于实现对图像像素级别的分割。分类,回归和分割三部分共同构成了Mask R-CNN 网络。因此,Mask R-CNN 网络损失函数L 可以表示为:

其中,L是分类误差、L是边界框回归误差、L是分割掩码误差。其中,掩码分割分支会为每一个RoI 定义一个 维度的矩阵,用来表示每个n×n 区域中的C 个不同的分类,然后使用sigmod 函数计算相对每一个像素求取相对熵,最后得到平均相对熵误差L。对于每一个RoI 来说,仅会将该RoI 所属的类别分支的相对熵误差计算为误差值。
3.2 共享后处理边缘信息
Mask R-CNN 中对象分类与对象定位两个分支的输入是完全相同的,这使得这两个分支之间的信息高度共享,在经过了同一个RoIAlign 层和全连接层之后,其接收的边界框输入信息都是相同的。但是相对而言,用于进行对象掩码分割的分支则与上述两个分支处于一个完全不相同的,与原有分支平行运行的分支中。在经过了RPN 网络,获得了经过不完全的处理后的建议框之后,掩码分割分支将进入一个网络层次和处理操作完全不同的分支中。这样的并行结构决定了在后续网络被执行的时候,网络计算得到的边界框和分割掩码分别位于各自的处理分支上,其信息不能互通、不能共享,这意味着掩码分支既不能参与后续对边界框进行的一些优化、调整操作,也无法得到经过回归等操作最终处理后的边界框信息。
为解决此问题,本文通过使用边界框定位分支中经过后置处理的、更加精准的边界框信息作为掩码分割分支的候选框来作为输入,经过掩码分割分支中的RoIAlign层操作之后,网络从骨干网络提供的特征层中映射出的局部特征图也会更加接近实例对象在原始图像中的真实位置,从而可以使算法进一步得到边缘细节处理更精确的掩码分割结果。
如图3 所示,本文将经过回归操作之后的边界框信息返回给分割掩码分支,由于增加了边界框信息的预判性,将进一步提高实例分割的准确性。在获取后处理边缘信息的过程中,主要涵盖了两个重要操作:首先是利用在之前的网络结构中就已经得到的建议框的调整参数来对边框进行回归;其次是通过非极大值抑制(NMS,non maximum suppression)来获取最优结果来确定最终的边界框位置信息。

图3:共享定位分支的边界框信息
边框回归旨在将候选框坐标映射为真实图片中的坐标。假设当前候选框坐标为(x, y, w, h),通过公式(2)可得到真实图片中的坐标(x, y, w, h):
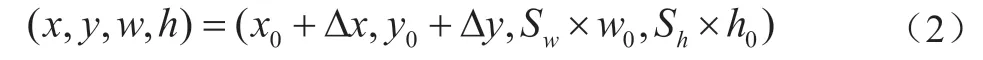
式中Δx 为沿x 轴的平移变换量,Δy 为沿y 轴的平移变换量,S为边框宽度的缩放倍数,S为边框高度的缩放倍数。
由于Mask R-CNN 网络在候选框生成阶段对于同一个检测目标会生成多个候选框,因此需要对这多个候选框进行非极大值抑制,选择最优的候选框进行后处理边缘信息的共享。非极大值抑制的过程如算法1 所示。

算法1 非极大值抑制算法输入:回归后的候选框Pboxs={Pbox0, Pbox1, …, Pboxn}输出:最优边界框Mbox 1. 根据置信度得分对Pboxs 进行排序2. 选择置信度最高的边界框作为Mbox,并将其从Pboxs 列表中删除3. 计算Mbox 与Pboxs 中其它候选框的IoU 4. 在Pboxs 中删除IoU 大于阈值的边界框5.重复上述过程,直至Pboxs 为空
将最终得到的最优边界框作为后处理的边缘信息,共享到分割分支,提高分割分支的定位精度。获得边缘细节更加饱满的分割结果。
4 实验
4.1 实验环境与数据集
为了验证本文提出的共享后处理边缘信息的实例分割算法的有效性,在Ubuntu 16.04 LTS 系统下采用Pytorch 进行模型搭建及训练,并使用MS COCO 2017 数据集进行实验验证。本文所有实验均在NVIDIA GeForce RTX 2080 的硬件环境中运行。
本文选择的MS COCO 数据集是Microsoft 于2014年开始资助标注的数据集。该数据集被认为是计算机视觉领域中最受关注并且最权威的竞赛之一。该数据集主要侧重于解决三个问题:目标检测,目标之间的上下文关系以及目标在二维空间中的精准位置。
4.2 量化指标
实验选择IoU 阈值为0.5 时,不同置信度下的真正例TP(True Positives)、假正例FP(False Positives)、真负例TN(True Negatives)和假负例FN(False Negatives)作为计算模型检测精确率P 的参考值:

式中,c 为模型检测时采取的置信度,TP,FP,FN表示置信度为c 时模型检测得到的TP, FP, FN。
当检测时设置的置信度不同时,精确率P 会发生变化,因此通过采取10 个等距置信度c={0.50, 0.55, … , 0.95}下的平均精确率AP(Average Precision)作为衡量模型检测性能的评价指标:

对于多分类模型,不同检测类别拥有不同的AP,所有类别的平均AP 称为MAP(Mean Average Precision)。

式中,n 表示模型可以检测的类别总数,j 为不同的检测类别。
4.3 实验结果
图4 所示为本文算法在MS COCO 数据集上的部分检测结果。从图中可以看出,本文算法可以精确的将目标进行分割,并可以较为完整的找出分割对象的边缘位置,极大的改善了Mask R-CNN 分割过程中边缘丢失的问题。

图4:本文算法的实例分割结果
为了进一步验证本文算法的有效性,分别使用Mask R-CNN 网络与本文所提网络在MS COCO 数据集上进行训练及验证。表1 和表2 分别展示了两种方法的目标检测结果和实例分割结果。从表中可以看出,本文方法在目标检测和实例分割上的效果均优于Mask R-CNN 模型。其中,在目标检测分支上,本文方法的AP 相比于MaskR-CNN 提高了0.56%,在实例分割分支上,本文方法的AP 相比于MaskRCNN 提高了0.87%。

表1:在COCO2017 数据上测试的bbox 分支的结果

表2:在COCO2017 数据上测试的segm 分支的结果
5 结论
本文简要回顾了图像处理技术的发展历程,分析比较了目前流行的几种基于Mask R-CNN 的图像实例分割算法,并针对Mask R-CNN 分割精度较差,分割速度缓慢的缺陷,提出了一种共享后处理边缘信息的实例分割算法。该算法在Mask R-CNN 网络中添加了含有待分割目标边缘信息的并行分支,加强深层次网络学习中的边缘信息,并利用经过回归的边界框信息在后续池化过程中得到效果更好的特征层,从而优化掩码分割结果。通过与Mask R-CNN 的对比实验,验证了本文算法的有效性。
猜你喜欢
学生天地(2019年28期)2019-08-25
通信学报(2019年5期)2019-06-11
数学物理学报(2018年1期)2018-03-26
通信技术(2018年3期)2018-03-21
浙江大学学报(工学版)(2015年4期)2015-03-01
电子设计工程(2015年20期)2015-01-29
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
山西大同大学学报(自然科学版)(2014年3期)2014-01-23
疯狂英语·口语版(2013年1期)2013-01-31
