
一种基于有限时间与或过滤器的浏览器缓存设计
2022-07-07 12:42孙亮
电子技术与软件工程 2022年5期
孙亮
(广东省深圳市创梦天地有限公司 广东省深圳市 518000)
1 引言
随着互联网技术的发展,互联网中越来越多的网站出现在网络世界里。在浏览器中的缓存设计可以极大提升用户体验,更快的网站响应速度。但是浏览器中的缓存大小是有限的,怎么在有限的缓存空间中存入足够大的URL,提升用户体验是我们需要思考的问题。
浏览器缓存是将一个曾经请求过的网页文件(如HTML文件,图片数据,JavaScript 文件,数据文件)拷贝成一个副本数据放到浏览器中。进而将WEB请求进来的数据内容保存为输入内容到缓存中,可能是内存缓存或者磁盘缓存数据。当浏览器再次请求数据的时候,如果是请求相同的URL数据,浏览器就会通过自动缓存策略,根据缓存规则判断、识别是直接通过浏览器的副本响应。如果不存在缓存中需要从源服务器再一次发出WEB资源请求以获取网络资源数据。随着URL的增长,缓存所占据的内存会越来越大,而响应的速率也会越来越缓慢。因此讲到浏览器缓存,我们必须首先介绍浏览器中缓存的种类和其工作的原理。而了解浏览器的缓存原理,也就是了解在什么地方对缓存做优化可以最大限度的提高缓存的效能,从而提高网页的反应速度和工作效果,进而改善使用者的体验。
(1)Memory Cache。内存中的缓存。按照操作系统原理知识可以知道。操作系统默认优先从读内存读取数据,如内存缓存没有缓存记录,再读硬盘读取数据。Memory Cache也是所有缓存中速度最快也是占用存储空间最小的,同时对存储效率要求也是最高的缓存类型,大部分的浏览器的资源请求都会被浏览器根据缓存规则缓存到 Memory Cache 中,用来高效的浏览WEB资源。从网络中请求越多的资源,因为浏览器的访问请求的数量越大,缓存在内存空间占用也就有越来越高,正因为操作系统的是内存有限的原因,浏览器占用的内存不能无限扩大,否则会被系统提示内存不足,需要收到杀掉进程,以减少内存的使用,Memory Cache 一般情况下只是个“短期有效存储”,通常是有一定的有效期限,这样提升缓存的效率。一般使用浏览器的情况下,浏览器的页签关闭后,此次浏览的 Memory Cache 会自动释放 (为了给其他 Web图页面腾出更多的内存空)。在内存使用量大的情况下 (若果一个页面的Memory Cache就占用大量的Memory),那可能在 浏览器页签没关闭之前,排在前面的浏览器缓存就会失效。所以在Memory Cache设置有效期很有必要,这样既能提升用户体验和浏览器的访问速度也能节省不必要的内存空间的浪费。
(2)Disk Cache也叫 HTTP cache,顾名思义是存储在操作系统硬盘上的缓存,通常是也是存在于操作系的文件系统中的,因此它是长久性存储在操作系统的磁盘的资源数据。而且它允许在相同的资源下跨会话请求数据,甚至跨WEB站点的情况下使用相同的资源数据,例如两个站点都使用了同一张图片。Disk Cache 会指定的根据浏览器的缓存规则以及根据 HTTP头信息中的各类字段来判定哪些资源不可以缓存到磁盘中,哪些资源可以缓存到磁盘中,这样做好区分,但是也能做好存储空间的共用,提升存储的效率;根据缓存有效率策略,哪些资源是在有效期限内仍然可用的,哪些资源是超过有效期需要重新请求服务器的。当浏览器的请求命中缓存之后,浏览器先做判断,是否存在与硬盘中,如果是Disk Cache便会更具浏览器策略从硬盘中读取Disk Cache资源,虽然比起从内存中读取资源数据的速度是慢了一些,但比起网络请求获取资源数据,在大部分情况下还是快了很多的。相当大部的一部分的缓存都是存储在Disk Cache。虽然对比Memory Cache 速度慢,但是优势在于可以存储更多的内容。
(3)Service Worker,在上述的缓存策略以及读取缓存,失效策略,缓存有效性等动作都是由浏览器内部通过其缓存策略自动判断进行的一种缓存策略,我们一般通过设置web请求头的部分字段来强制通知浏览器,需要使用哪种策略,不使用哪种策略,而不是自己手动操作浏览器使用哪种策略。它具有在浏览器也服务器之间的转发请求功能。判断哪些请求需要转发给浏览器,如果需要向服务器发起请求的按照浏览器的缓存策略就自动转发请求到服务器端,就直接使用浏览器的内存缓存或者磁盘数据缓存的数据直接返回缓存数据,不需要再次转发给服务器请求资源数据。从而极大提高浏览器的浏览使用体验。
一个URL的数据经过多个Hash 函数生成的 哈希值映射到槽位的一个二进制位,并且是一个固定长度的槽位占有多个二进制位。映射过程就是这个哈希值和一个槽位上多个元素按位LXOR(按位异或)的计算规则(相同的取0否则取1)。然后多个哈希函数产生的多个哈希值会映射到多个槽位上,LXOR过滤器会维护这些槽位。通过将这些槽位中的二进制数据做整体计算生成一个唯一的哈希函数的值。最后用户查找URL地址时会将多个函数映射的槽位LXOR(按位与)计算。假设通过哈希函数运算的结果是T1,同时将URL输入到上面构造的唯一的一个函数中,计算结果是T2。如果T1等于T2,则确认URL是存在与LXOR过滤器中,否则不存在。即判断指纹函数的元素值和3个哈希函数对应的K-Bites的值按位异或之后的值是否相等,如果相等则表示元素可能是在LXOR过滤器中否则不存在。
LXOR过滤器类似于集合数据结构,添加元素并检查给定的元素是否存在于集合中。有小概率的错误判断,这种误报事件为假阳性事件False-Positive Probability。由于LXOR过滤器可以使用比原始集少的内存。因此,LXOR过滤器接受一个小概率的错误减少内存使用。查询元素是否在集合中的过滤器有很多应用:例如,使用浏览器URL缓存。在这样的存储中,内存数据结构避免了磁盘访问同时使用简单数据结构并且使用更少的内存。这样可以在有限的内存中,存入足够多的URL地址。因此我们提出了基于有限时间与或过滤器的浏览器缓存LXOR。
2 相关工作
对于静态数据集合,使用哈希函数的指纹可以从根本上实现减少的内存使用。但是哈希函数可能计算需要花费时间,然而Dietzfelbinger 和 Pagh提出了一种新过滤器,我们称之为异或过滤器。它的建立是基于过滤器,如 Bloom过滤器。我们基于有限时间的异或过滤器作为一种实用的数据结构具有优势。
我们发现许多Bloom 过滤器先关的数据结构是基于数据库系统设计,避免内磁盘直接访问。当前主流的数据库引擎必须支持频繁更新,是一种合并LSM数据结构。在高层次LSM 树内存中保持快速批量合并到持久存储中的数据的组件中,内存组件累积数据库更新,从而将更新成本分摊到本地存储中。加速查找,许多 LSM 树实现(例如 LevelDB)使用Bloom 过滤器。合并组件时,通常会构建一个新的过滤器。我们可以更新现有的过滤器支持快速合并的数据结构(例如 Bloom 过滤器)需要原始过滤器有额外的容量,合并的结果有更高的假阳性的可能性。
通常,每当过滤器必须通过与其他计算机的网络连接(例如,缓存和网络查询),通常缓存是可变的。随着时间变化,访问不同URL,通过过滤器的缓存会发生变化。基于时间的变化策略设置过滤器的缓存策略,记录URL访问的时间和次数,为URL设置访问的等级和Token。
3 理论基础
给定一个元素URL,我们使用随机选择的密钥生成它的 k 位指纹哈希函数,我们假设一个理想化的完全独立的散列函数;我们在表1总结了我们的符号。我们想要构造一个从所有可能元素到k位整数的映射 F,这样它就可以映射所有密钥y从集合S到他们的k位指纹(x)。因此,如果我们选择集合中的任何元素,那么它会得到通过设计映射到其指纹 F(y)=fingerprint(y)。我们的目标是拥有数组 B 中三个哈希函数给出的位置处的值与指纹一致(B[h0(x)]xor B[h1 (x)]xor B[h2(x)]=fingerprint(x)) 对于所有元素 x∈S。哈希函数h0,h1,h2 被假定为独立于用于指纹的哈希函数。检测成员函数计算哈希函数 h0,h1,h2,然后从表 B 中的这些条目构造预期指纹,并将其与给定密钥的指纹进行比较。如果密钥在集合中,则该表包含指纹是匹配的。处理时间包括三个哈希函数的计算以及三个随机内存访问。尽管其他相关的数据结构可能需更少的内存访问,但大多数由于内存级并行性,可以同时并发访问三个以上的内存。因此,可以减少内存访问的时间。
对于生成的哈希函数值,按照访问URL次数做记录,根据频率设置等级,浏览器根据等级进行概率性选择存储在内存中。在指定时间内删除访问频率低的URL产生的哈希函数值。保证LXOR过滤器缓存中存储的是高频率访问的URL,本算法将低频率访问量的URL设置为较低的缓存等级来增大R,从而使高频率的访问的URL以更高概率缓存在LXOR过滤器中,我们可以给出R变化的公式:
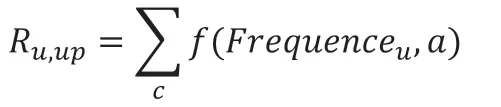
其中Frequence是URL访问频率等级,a是令牌权值。f(Frequence,a)代表令牌生成量/消耗量关于内容流行度等级与令牌权值的变化函数,是一个随URL等级单调递减的函数,设置二次函数,例如:
f(Frequence,a)=-a×Frequence+1
对不同的函数进行实验来选取其中性能更好作为最后的参数。a控制了R增加的速率,如果a设置的过大,令牌将难以获取,高频率访问URL不容易被加入到缓存中,对缓存的变化并不敏感,会导致缓存的效率下降。同样的,如果a设置的过小,令牌将失去意义,因为大部分内容都会被进入缓存环节,算法会演变为概率性缓存算法,从而导致缓存命中率进一步的降低。a值过大或过小都会降低浏览器LXOR过滤器缓存的命中率,因此我们会监测一段时间内缓存命中率的变化趋势,动态地调整a值,调整算法如算法1所示。
4 算法框架及描述分析
从缓存的角度分析,一定是希望能在缓存中存入经可能多的URL地址数据,但是为了保证浏览器缓存有效的运行,使用ρ控制URL等级的大小。
Hot=ρ×f(c)
其中f(c)是浏览器对URL请求对热度预测函数。为了实现一段时间内的URL热度的预测,在浏览器中控制Token 的数量大小。在一段时间内的Token的中位数,根据Token大小变化动态调整ρ 的值。动态调整算法如算法2所示。

算法1 数据标记处理变量:ε←a 的偏移量1: function offsetAlpha()2: count←0 3: for every Δt do 4: h←url access times 5: m←url miss times 6: if h⁄((m+h))>Hr then 7: count←count+1 8: else 9: count←0 10: ε=‐1·ε 11: end if 12: a=a+ε 13: Hr=h⁄((m+h))14: end for 15: end function
带有时间戳和次数标记的算法LRUF,是在LRU算法基础设计上,记录每一个URL在浏览器缓存中的停留时间,减少计算量和存储空间,使用访问次数替换为在缓存中存留的时间。每间隔一点时间统计在浏览缓存中的存活的时间周期。可以依次判断URL访问的热度和URL的等级之间的差异,据此计算出浏览器缓存的概率偏移量。

算法2 ρ的调整算法变量:ε←ρ的偏移量T←上一个时间段的Tmin的中位数1: function offsetCache()2: count←0 3: for every Δt do 4: s←sum of Tmin 5: count←number of access 6:7: ϵ=-1×ϵ 8: end if 9: ρ=ρ+ϵ 10:11: end for 12: end function
5 实验
我们在配备 MacBook Pro M1 Pro处理器上运行基准测试:M1 Pro 处理器以 2.5 GHz 运行,具有 24 MB L2 缓存。基于一组 1M 或 10M 的原始数据构建过滤器。我们建造由10M 个随机查询键组成的集合。这组查询过滤器的空间使用率和查询过滤器器的元素多对比。发现在LXOR过滤器中使用较少的使用空间使用率以及较快的查询速度。在一定时间范围内,LXOR组成过滤器缓存在假阳性率较低。一定时间范围内的URL请求数据热度较高,在查询数据和内存使用率方面有一定的优势。
在内存利用率,在不同的数量URL访问的场景下的假阳性FPP比对。LXOR过滤器占用内存比要低,同时在假阳性率也是低于XOR过滤器,在数据量增加的场景下,优势是更加明显。
在空间内存空间使用率方面,如图1和图2,LXOR过滤器是低于Bloom过滤器、Cuckoo过滤器、XOR过滤器,随这个数据量增加,LXOR过滤器在假阳性率方面依旧占有优势,在内存使用率方面依旧如此。由此可见,在使用时间维度的与或过滤器在缓存的效率和内存空间方面的具有优势。
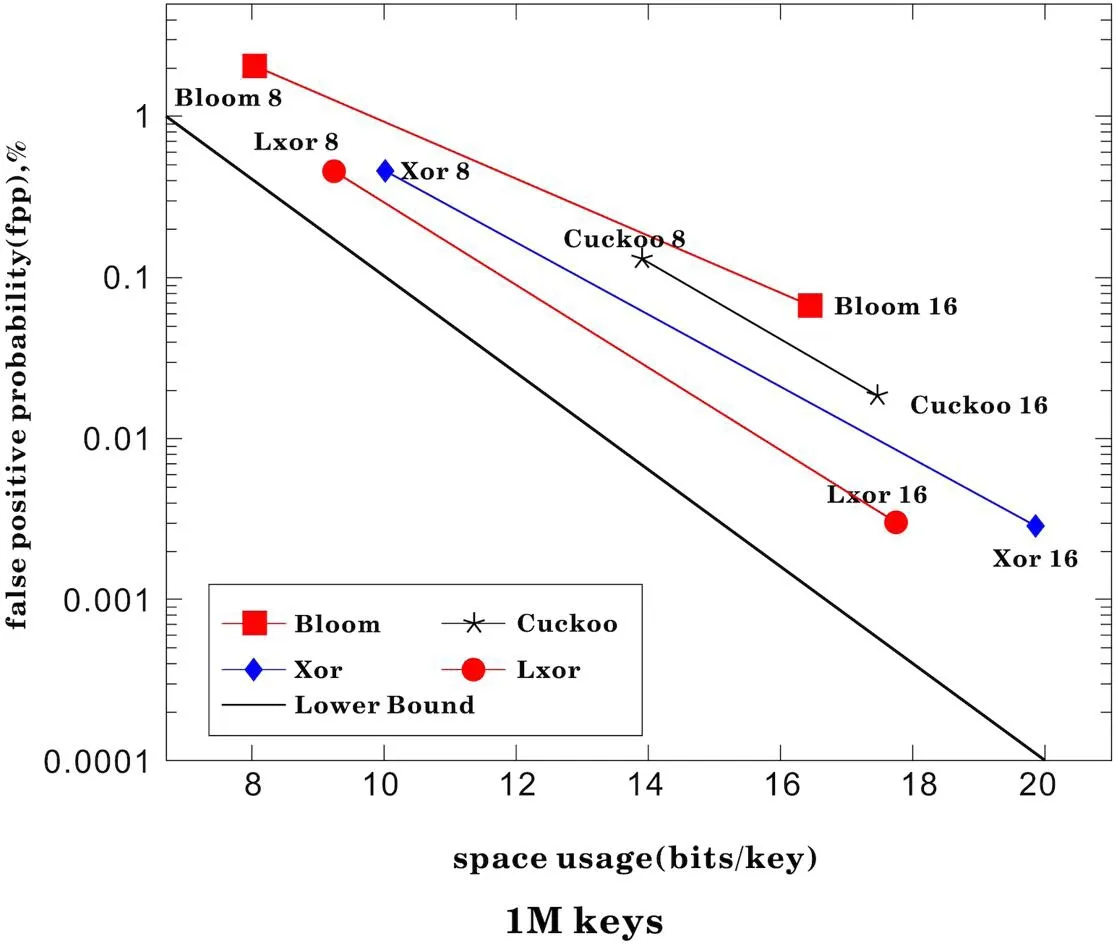
图1:1M keys场景下的内存使用量对比
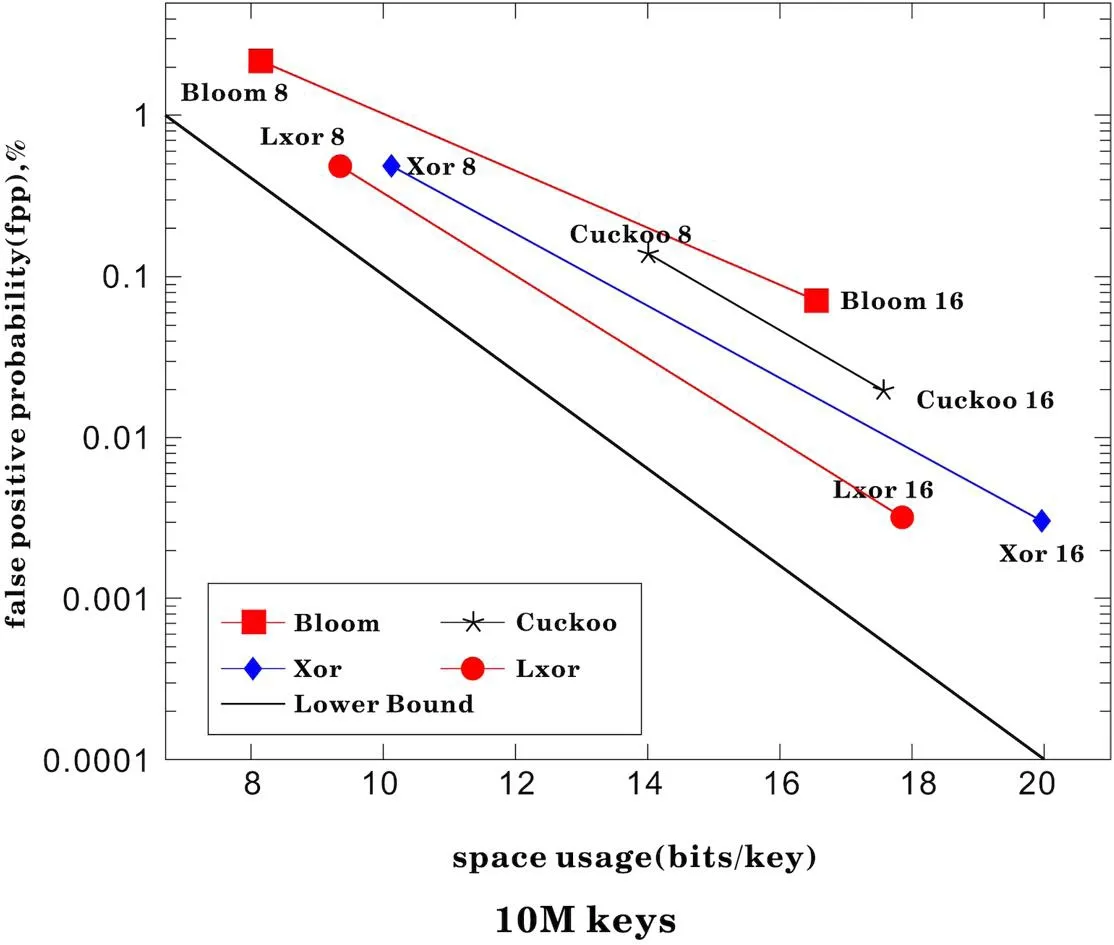
图2:10M keys场景下内存使用量对比
在基于一定热点的URL作为key值,在查询效率方面有优势,查询效率更高。在增加查询的URL的场景下优势是更加明显。在查询URL查询方面,由于使用较少内存,令URL的查询更快,超越了XOR过滤器、Cuckoo 过滤器以及Bloom过滤器。虽然在XOR 过滤器在查询效率有一定的优势,但是在LXOR过滤器加入了时间和次数的维度,使得空间占有优势,在查询效率方面亦是如此。如图3和图4所示。
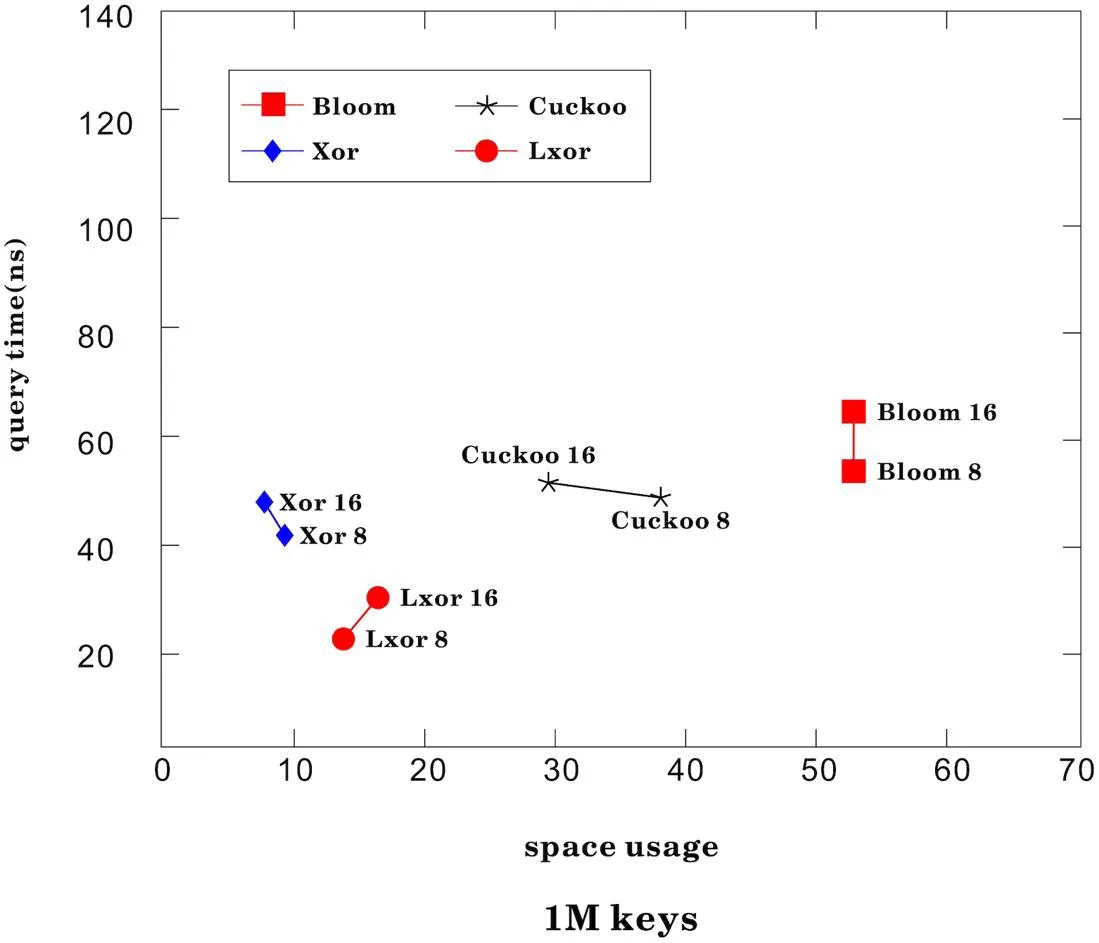
图3:在1M Keys空间使用率下,查询效率对比
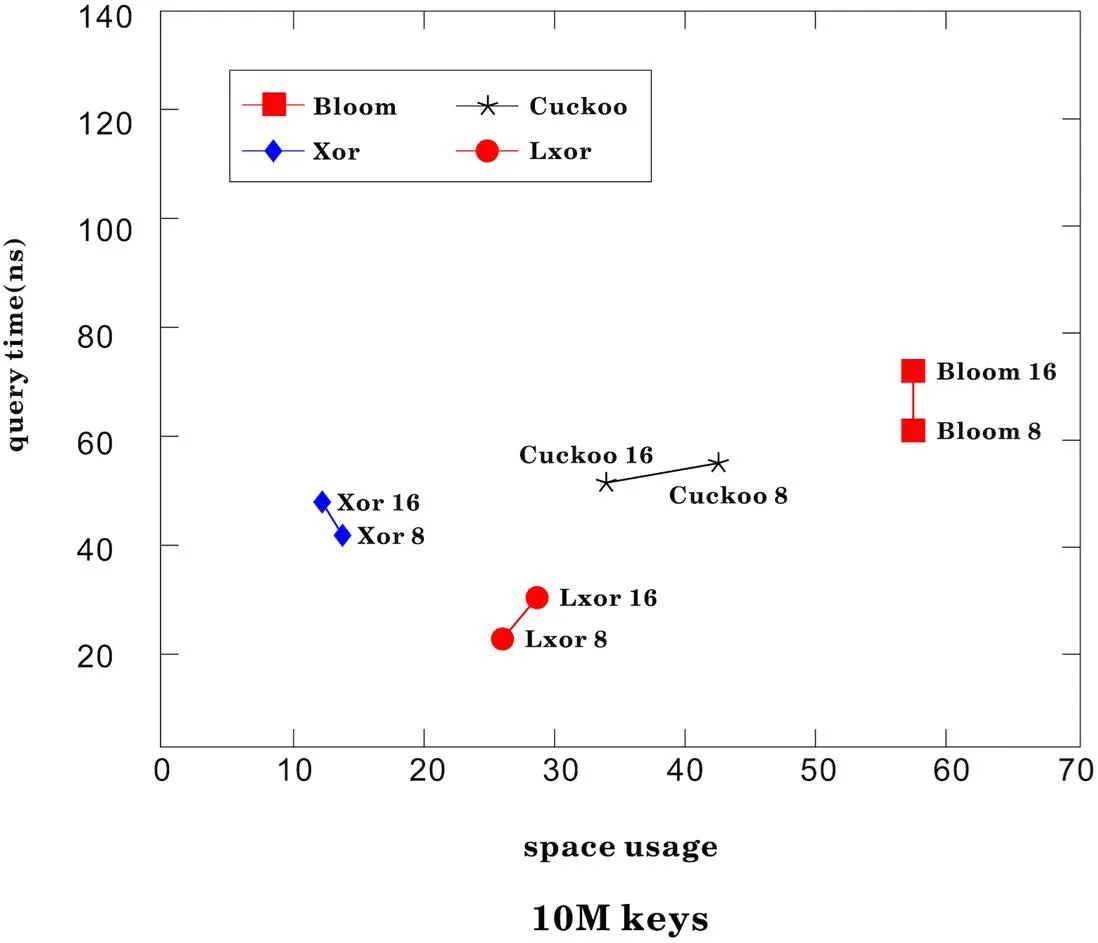
图4:在10M keys空间使用率下查询下查询效率对比
6 结语
本文提出的基于有时间与或过滤器的浏览器缓存设计,目的是为了提高浏览器的缓存性能。本文的算法通过有限与或过滤器的方式减少内存使用量和提升查询效率方式。与有效时间内的缓存结合的方式对比,新的方法效率更高,进一步提升了缓存的效率,下一步工作计划是增加更多应用场景的缓存使用,提升LXOR过滤器缓存的普适性。同时增加URL的模拟数据,进一步提升缓存的利用率,在缓存时间和缓存效率之间做平衡,做到最大化利用缓存,存储更多URL信息。
猜你喜欢
电子制作(2019年10期)2019-06-17
电子测试(2018年9期)2018-06-26
趣味(语文)(2018年2期)2018-05-26
环境与生活(2016年6期)2016-02-27
计算机工程(2015年8期)2015-07-03
自动化博览(2014年6期)2014-02-28
计算机工程(2014年6期)2014-02-28
中国氯碱(2014年11期)2014-02-28
电子设计工程(2014年12期)2014-02-27
