
基于改进的tiny-YOLOv3网络的表面缺陷检测研究
2022-07-07 06:46:12李屹魏建国刘贯伟
现代信息科技 2022年4期
李屹 魏建国 刘贯伟



摘 要:表面缺陷自动化检测在社会各个行业有广泛应用前景,可以大幅度提升效率。基于卷积神经网络架构的目标检测模型是自动化表面缺陷检测与识别的重要方法。折中检测速度与精确度,选择tiny-YOLOv3网络作为表面缺陷检测的模型。将视觉注意力机制引入tiny-YOLOv3网络结构并比较不同类别注意力机制在网络不同位置对于模型表现的影响,从而提出一种对于原网络改进的方法。改进的tiny-YOLOv3网络结构在表面缺陷数据集上测试结果较原始tiny-YOLOv3网络在mAP值上提升2.3%。
关键词:缺陷检测;注意力机制;神经网络
中图分类号:TP391.4 文献标识码:A文章编号:2096-4706(2022)04-0095-05
Research on Surface Defect Detection Based on Improved tiny-YOLOv3 Network
LI Yi1, WEI Jianguo2, LIU Guanwei1
(1.Cashway Fintech Co., Ltd., Tianjin 300308, China; 2.College of Intelligence and Computing, Tianjin University, Tianjin 300072, China)
Abstract: Automatic detection of surface defects has a wide application prospect in various industries of society, which can greatly improve the efficiency. The target detection model based on convolutional neural network architecture is an important method for automatic surface defect detection and recognition. To compromise the detection speed and accuracy, choose tiny-YOLOv3 network as the model for surface defect detection. The visual attention mechanism is introduced into the tiny-YOLOv3 network structure and the influence of different types of attention mechanisms in different network positions on the performance of the model are compared, then a method to improve the original network is proposed. The testing results of the improved tiny-YOLOv3 network structure in the surface defect dataset show that the mAP value is 2.3% higher than that of the original tiny-YOLOv3 network.
Keywords: defect detection; attention mechanism; neural network
0 引 言
在工業品质量检测过程中,表面缺陷的检测与分类是质量检测的一个重要步骤。人工对于上述方面的质检存在人力成本高,效率低,在某些场景准确率低,危险性大等问题,因此对于物体表面缺陷的自动化和智能化检测与分类成为目标检测的一个重要应用领域[1,2]。目标检测算法通常包括对于物体边界框的界定与对目标物体的分类。目标检测算法包括传统检测算法与基于深度学习的检测算法。传统目标检测算法主要步骤包括对输入图像进行候选框的提取,对候选区域进行特征提取,再利用分类器进行分类等几个步骤。在特征提取过程中,传统方法主要使用的特征包括HOG[3],LBP[4],Haar[5]等特征。分类器可以选为SVM[6],BP神经网络等。例如文献[3]中使用HOG+SVM方式进行人体检测。近年来基于深度学习的检测算法发展迅速,在各类数据集上的结果不断突破,逐渐在目标检测领域成为主流算法。基于深度学习的目标检测算法主要包括两类。一类为两步检测算法,即先对检测目标生成候选区域,再对检测目标进行分类和边界框回归。两步检测算法代表算法为R-CNN[7]、Fast-Rcnn[8]、Faster-Rcnn[9]等。2014年Girshick提出利用选择性搜索方法获取ROI区域,再将不同ROI区域送入巻积神经网络,用SVM和回归算法分别得到检测目标的分类与边界框信息。Fast-RCNN算法提出先使用巻积神经网络对图像提取特征,再在特征图像上定位出ROI区域所对应特征图块后将特征图块送入全连接层进行回归与分类。由于不需要重复提取特征,从而加快速度。Faster-RCNN算法在网络结构上与Fast-RCNN相同,但使用区域生成网络代替了通过选择性搜索生成候选区域方法,从而大大提高效率。另一类算法不单独生成候选区域,通过巻积神经网络提取图像特征后将边界框的回归任务与目标的分类任务同时完成。此类方法代表算法为YOLO系列算法与SSD算法。YOLO[10]系列算法将图像划分为S×S个网格,每个网络预测K个边界框的位置与置信度。YOLOv2[11]在神经网络中加入BN层,并使用archor box。YOLOv3[12]则使用Darknet53的网络结构并使用多尺度特征进行检测。SSD[13]使用VGG19作为特征提取器,直接在多个特征尺度的巻积层上进行预测,而非在全连接层上进行预测。
目标检测算法在很多场景下对实时性要求较高,并且算法需要部署在移动端或是边缘设备上。由于此种情况下计算资源有限,上述算法在某些情况下难以满足速度要求,而tiny-YOLOv3网络可以在一定程度上解决此类问题。tiny-YOLOv3将YOLOv3网络特征提取部分的层数大幅度减少,并只在两个特征尺度上进行预测。由于网络层数大幅度减小,检测精度有所降低。本文提出一种改进的tiny-YOLOv3网络结构,将不同类型注意力模块加入网络的特征提取部分并对不同加入位置进行比较,使检测精度有所提高。并在表面缺陷检测数据集上进行了测试。
1 理论基础
1.1 YOLO系列算法检测原理
YOLO系列目标检测算法将待检测目标图像分为S×S个网格,S代表图像在某一方向所分割的区间数。如果一个目标落入了这个网格单元之中,则这个网格负责预测此目标。网格单元会对该目标的边界框的位置与置信度进行预测。边界框的置信度定义为是否包含目标物体的概率,即:否则为1。代表预测框与真实框面积的交并比。
(1)
式中c代表置信度,P(object)代表物体是否落在边界框中,如果边界框不包含预测目标,则P(object)值为0,否则为1。代表预测框与真实框面积的交并比。每个边界框的维度为4+1,4代表边界框的中心位置坐标(x,y)以及边界框的宽和高(w,h)。而1代表预测置信度c。每个单元格含有B个边界框,如在YOLOv3中每个单元格使用B=3种不同宽高比的边界框进行预测。
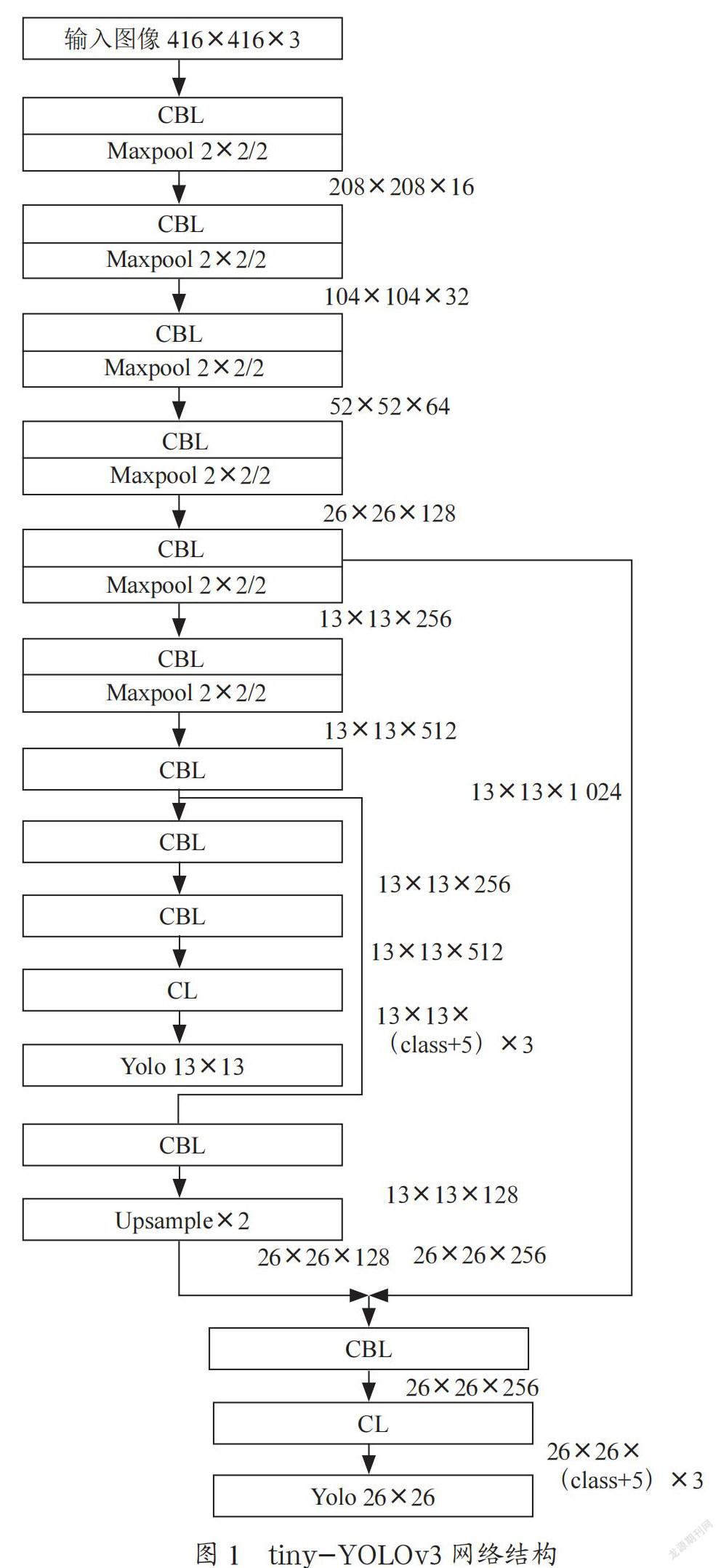
1.2 tiny-YOLOv3网络结构
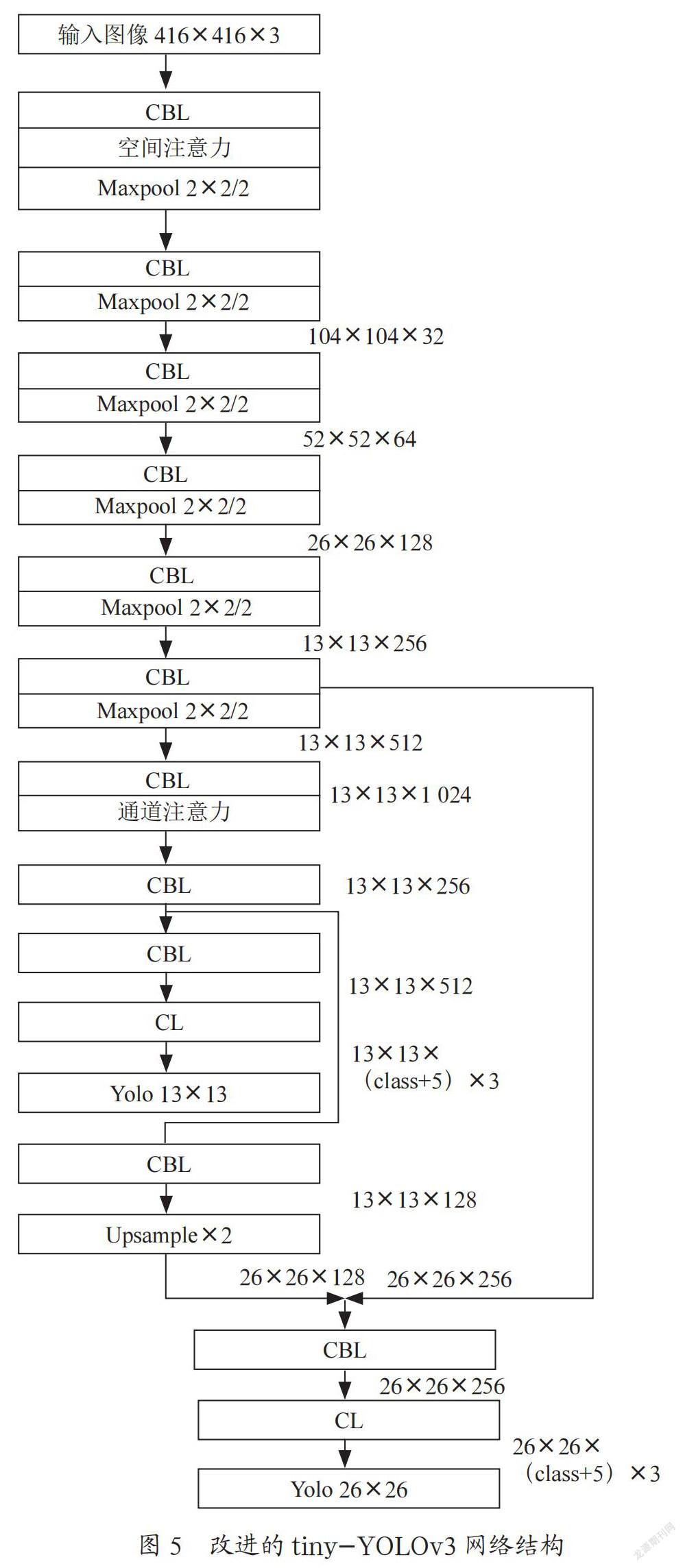
YOLOv3在YOLOv2的darknet-19模块上引入残差并增加了网络深度,加深后的网络含53个巻积层,命名为darknet53。tiny-YOLOv3是YOLOv3的轻量化网络,网络结构如图1所示:tiny-YOLOv3网络可以在两个特征尺度上进行检测,相比于YOLOv3网络减少了一个特征尺度。特征提取网络相较于YOLOv3大大化简,取消了残差连接部分。图1中CBL代表空间维度为3×3的卷积层+批归一化层+激活函数,此网络激活函数使用leaky relu函数。CBL层后接2×2单元格上的最大池化层,将特征图在空间方向缩减2倍或保持不变。CL层中不包含批归一化函数,激活函数使用linear relu函数。每次卷积之后所得的特征维度在图1中右侧标注。其中class代表目标类别数。
1.3 注意力机制
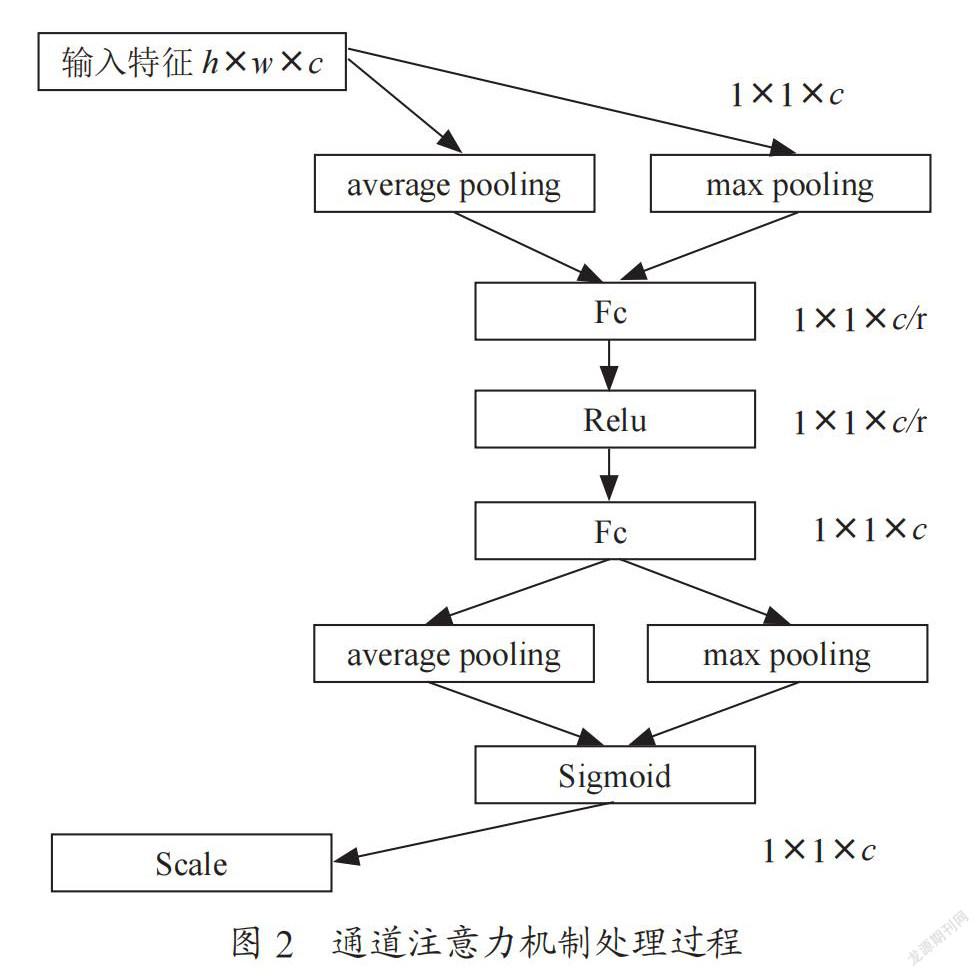
注意力机制最初被应用于机器翻译,现在已经成为神经网络中的一个重要概念,在图像识别,语音识别与自然语言处理等领域已有广泛应用。注意力机制可以利用人类视觉注意力机制进行解释,例如人类视觉系统倾向于关注辅助判断的部分信息,并忽略掉不相关的信息。在图像处理领域,注意力机制主要包括通道注意力与空间注意力[14,15]。通道注意力的提出主要是为解决特征图中不同通道的重要性不同而带来的损失。通道注意力机制处理过程如图2所示,输入特征图的维度为h×w×c,h,w,c分别代表高,宽与通道数。特征图在空间方向分别经过平均池化与最大池化后得到1×1×c的特征图,两特征经过相同的全连接层将通道数压缩为c/r,r为压缩率,通常选为16。再经过第二个全连接层后将通道数扩张为c,将两特征图相加后经过sigmoid函数后得到各个通道的权重系数,再与池化之前的特征图相乘后得到通道注意力模块的输出。
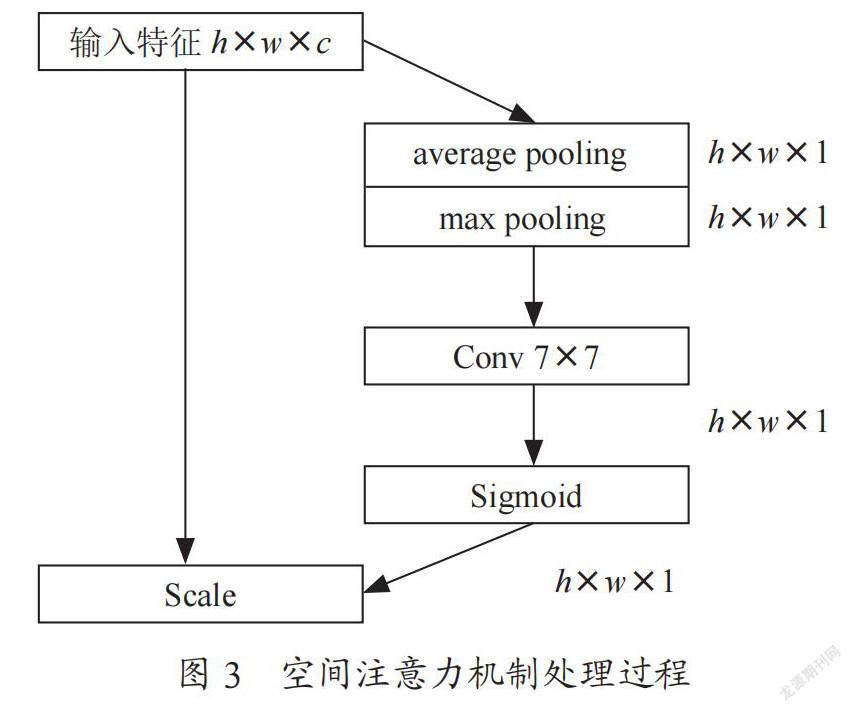
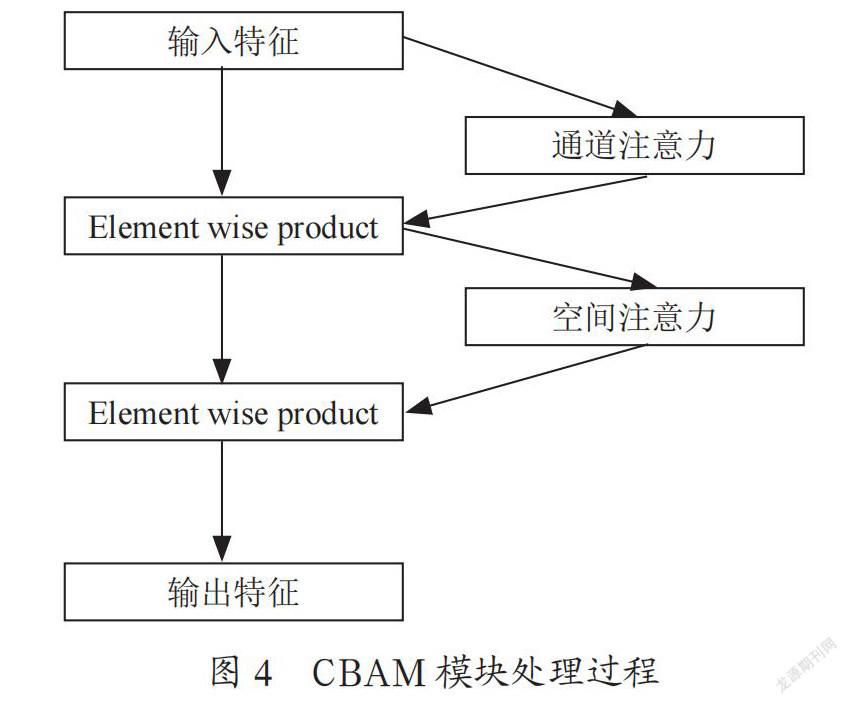
空间注意力模块主要关注图像之中哪部分特征更加重要,处理过程如图3所示。给定空间维度为h×w×c的特征图,空间注意力模块首先在通道方向进行最大池化与平均池化,分别得到h×w×1的特征,將两组特征在通道方向上拼接后经过7×7卷积层与sigmoid函数得到特征在空间方向的权重系数,再与输入的特征相乘即可得到新的特征。CBAM模块则将通道注意力与空间注意力的特点相结合,将特征图先送入通道注意力模块后再送入空间注意力模块。CBAM模块的处理过程如图4所示。
2 目标检测算法设计
2.1 网络模型架构
卷积神经网络中浅层网络可以学习到图像的局部特征,具有较小的感受野,而深层网络可以学习到更抽象的特征,具有更大的感受野与更多的通道数。由于通道注意力模块关注神经网络某层的不同通道对于学习结果的贡献,因此通道注意力模块应添加在神经网络中具有最大通道数的卷积层后。空间注意力模块关注空间中哪部分特征对网络学习能获得更好的效果,浅层特征为图像局部特征,深层特征为图像更抽象,更全局的特征,不同于CBAM模块将空间注意力添加在通道注意力模块之后,本文认为空间注意力模块添加在浅层特征后较添加在深层特征后对于学习效果可能更有提升。经过添加注意力模块改进的tiny-YOLOv3网络结构如图5所示。
2.2 损失函数
算法中所使用的损失函数包括三部分,分别为边界框回归损失,边界框置信度损失与目标分类损失。本实验采用的边界框回归损失为CIOU损失,目标检测中所使用边界框损失函数包括L1,L2损失与IOU损失两类。由于在相同的L1,L2损失下边界框仍可以产生不同的交并比,文献[16]中首次提出使用IOU作为边界框损失函数。之后GIOU,DIOU,CIOU[17,18]损失又相即提出。GIOU[17]考虑到了IOU损失中两边界框不相交而无法度量的问题,DIOU[18]将中心点距离因素加入损失函数,CIOU[18]则将边界框重叠面积,中心点距离,边界框长宽比三个因素同时加入损失函数中。CIOU损失函数表达式为式(2)~(5):
式(2)中第二项为IOU损失,计算方法见式(3),其中B与Bt分别代表预测边界框与真实边界框。式(2)中第三项为对于边界框中心点的惩罚,其中p(c,ct)代表预测框与真实框之间的欧式距离,而d代表预测边界框与真实边界框最小外接矩形对角线的长度。第四项为对于边界框长宽比的惩罚,其中a,v的计算方式分别见式(4)与式(5)。式(5)中ht,wt,h,w 分别代表真实边界框与预测边界框的长与宽。
目标检测任务的总损失函数表达式为式(6),其中i,j分别为图像单元格与边界框的索引。式(6)中第一项为边界框与真实框之间交并比损失函数,其中表示某个边界框是否为正样本,正样本值为1,否则为0。第二项是正样本的置信度损失函数,其中为第i个单元格中第j个边界框的预测置信度值,而为真实值。第三项是负样本的边界框置信度损失,第四项是正样本的分类损失,其中为预测物体属于某个类别的概率,为真实概率。因为正负样本数量差别较大,因此在训练中令系数λnoobj=0.5可均衡正负样本使损失函数不趋于零。
3 实验
实验使用DAGM2007数据集。DAGM2007数据集是物体表面缺陷的数据集,数据集包含十类表面缺陷,为人工合成,但类似于现实世界中的问题。从此数据集中选出1 046副含有缺陷的图像,利用图像翻转90,180,270度与沿图像水平竖直轴镜像对称方式对数据集增扩至6 276副图像,并以9比1的比例划分为训练集与测试集。
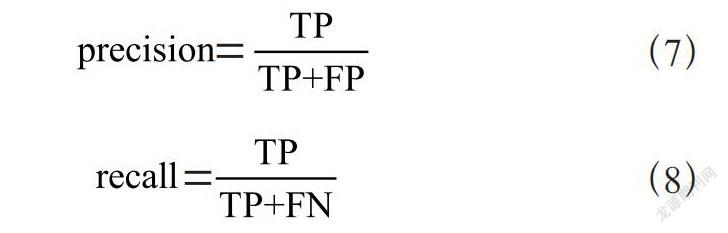
实验中所用显卡为RTX-3090。初始学习率为0.01,最终学习率为0.000 5。学习率使用cos函数进行衰减。选用Adam[19]作为优化算法。在目标检测任务中使用mAP值作为衡量检测算法优劣的主要标准。mAP值为mean average precision,即AP值在数据集中所有类别上的平均值。AP值则为每一类中precision-recall值曲線下的面积。而precision与recall值的定义则见式(7),(8)。式(7),(8)中TP,FP,FN分别代表真阳性,伪阳性,伪阴性的样本数目。
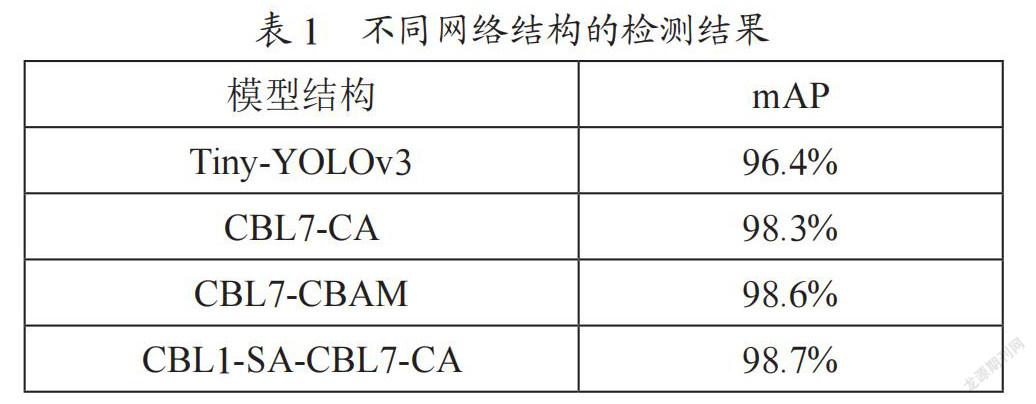
本文在数据集上测试了在特征提取网络中几种不同的注意力模块添加方式的目标检测结果,分别为原始tiny-YOLOv3网络,在第7个CBL结构后加入cbam模块的网络,在第7个CBL结构后加入通道注意力模块的网络,在第1个CBL结构后加入空间注意力和在第7个CBL结构后加入通道注意力的网络,在特征提取网络后只加入通道注意力,并将不同方法经过训练后所得到的检测结果进行对比,结果如表1所示。
从表1中实验结果可以看出,通道注意力对于模型效果提升较大,加入通道注意力后再加入空间注意力能使模型性能有所提升。空间注意力加入在浅层后检测效果相对于在深层加入使检测结果略有提升。
4 结 论
为了使tiny-YOLOv3网络能在缺陷检测数据集中取得更好的性能,本文通过对于注意力模块在网络不同位置的研究,提出一种改进的tiny-YOLOv3网络从而提升检测效果。并从实验结果中分析了不同注意力机制对于对网络性能的影响,相较于空间注意力机制,通道注意力机制对于检测效果提升更大。空间注意力机制将不同权重赋予图像不同部分,而样本中待检测目标空间分布未必一致,因此改进空间注意力机制使所赋权重能更好匹配待检测目标可成为未来的研究方向。
参考文献:
[1] 黄凤荣,李杨,郭兰申,等.基于Faster R-CNN的零件表面缺陷检测算法 [J].计算机辅助设计与图形学学报,2020,32(6):883-893.
[2] 李维刚,叶欣,赵云涛,等.基于改进YOLOv3算法的带钢表面缺陷检测 [J].电子学报,2020,48(7):1284-1292.
[3] DALAL N,TRIGGS B.Histograms of Oriented Gradients for Human Detection [C]//2005 IEEE Computer Society Conference on Computer Vision & Pattern Recognition.San Diego:IEEE,2005(1):886-893.
[4] OJALA T,PIETIKAINEN M,MAENPAA T.Multiresolution Gray-Scale and Rotation Invariant Texture Classification with Local Binary Patterns [J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(7):971-987.
[5] LIENHART R,MAYDT J.An Extended Set of Haar-Like Features for Rapid Object Detection [C]//Proceedings.International Conference on Image Processing.Rochester:IEEE,2002(1):I-I.
[6] SUYKENS J,VANDEWALLE J.Least Squares Support Vector Machine Classifiers [J].Neural Processing Letters,1999,9(3):293-300.
[7] GIRSHICK R,DONAHUE J,DARRELL T,et al.Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation [C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.Columbus:IEEE,2014,580-587.
[8] GIRSHICK R.Fast R-CNN [C]//2015 IEEE International Conference on Computer Vision(ICCV).Santiago:IEEE,2015:1440-1448.
[9] REN S,HE K,GIRSHICK R,et al.Faster R-CNN:Towards Real-Time Object Detection with Region Proposal Networks [J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2017,39(6):1137-1149.
[10] REDMON J,DIVVALA S,GIRSHICK R,et al.You Only Look Once:Unified,Real-Time Object Detection [C]//2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Las Vegas:IEEE,2016,779-788.
[11] REDMON J,FARHADI A.YOLO9000:Better,Faster,Stronger [C]//2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR).Honolulu:IEEE,2017:6517-6525.
[12] REDMON J,FARHADI A.YOLOv3:An Incremental Improvement [J/OL].arXiv:1804.02767 [cs.CV].[2021-12-03].https://arxiv.org/abs/1804.02767.
[13] LIU W,ANGUELOV D,ERHAN D,et al.SSD:Single Shot MultiBox Detector [C]//Computer Vision – ECCV 2016.Cham:Springer,2016:21–37.
[14] JIE H,LI S,GANG S.Squeeze-and-Excitation Networks [C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City:IEEE,2018:7132-7141.
[15] WOO S,PARK J,LEE J Y,et al.CBAM:Convolutional Block Attention Module [J/OL].arXiv:1807.06521 [cs.CV].[2021-11-03].https://arxiv.org/abs/1807.06521.
[16] YU J,JIANG Y,WANG Z,et al.UnitBox:An Advanced Object Detection Network [C]//MM’16:Proceedings of the 24th ACM international conference on Multimedia.Amsterdam:Association for Computing Machinery,2016:516–520.
[17] REZATOFIGHI H,TSOI N,GWAK J Y,et al.Generalized Intersection Over Union:A Metric and a Loss for Bounding Box Regression [C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).Long Beach:IEEE,2019:658-666.
[18] ZHENG Z,WANG P,LIU W,et al.Distance-IoU Loss:Faster and Better Learning for Bounding Box Regression [J/OL].arXiv:1911.08287 [cs.CV].[2021-11-13].https://arxiv.org/abs/1911.08287.
[19] KINGMA D,BA J.ADAM:A Method for Stochastic Optimization [J/OL].arXiv:1412.6980 [cs.LG].[2021-11-23].https://arxiv.org/abs/1412.6980.
作者簡介:李屹(1984—),男,汉族,山东滨州人,工程师,博士研究生,研究方向:图像处理、计算机视觉。
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
中国高新技术企业(2016年34期)2017-02-10 16:40:20
计算技术与自动化(2016年4期)2017-01-11 14:19:49
重型机械(2016年1期)2016-03-01 03:42:04
科技视界(2016年3期)2016-02-26 11:42:37
大连工业大学学报(2015年4期)2015-12-11 04:06:52
