
5G开源软件平台中LDPC加速的实现与优化
2022-07-05 21:21:27高震宇赵静雅苏晨陈梅
电脑知识与技术 2022年14期
高震宇 赵静雅 苏晨 陈梅
摘要:為解决开源的软件定义通信系统平台OAI存在接口速度慢、功能模块化不清晰、处理速度慢等问题。通过分析物理层LDPC编解码的功能,找出目前OAI平台的性能瓶颈。为提高整体性能,选择采用GPU加速方法,替换性能较差模块,最终通过实验仿真结果分析,显示出了方法的可行性和可靠性。
关键词:5G;通用处理器;物理层;开源
中图分类号:TP311 文献标识码:A
文章编号:1009-3044(2022)14-0031-03
1 引言
随着第五代移动通信技术(5G)的商业化应用,基于5G的应用以及学术研究需求逐渐增大。由于系统庞大和专用设备昂贵,研究机构如果要建立一套完整的通信系统非常困难。近年来,随着SDN、NFV等技术的成熟,科研机构可使用通用处理器(GPU)代替各种专用处理器,以建立小型的通信系统[1]。与此同时,大量的开源社区逐渐发展壮大,为实现5G通信系统的小型化提供了软件支持。欧洲Eurecom组织发起建立了OpenAirInterface(OAI)项目,该平台能够提供3GPP蜂窝系统EPC和E-UTRAN协议的开源硬件和软件平台[2],包括:LTE系统的从物理层到网络协议层协议,以及R10标准版本的LTE接入侧和核心网侧的UE、eNB、MME、HSS、SGW和PGW等模块[3]。OAI是3GPP堆栈的开源实现。它涵盖3GPP栈的不同部分(eNodeB、UE、MME、HSS、S-GW、P-GW)。该软件运行在通用计算平台(例如因特尔/ARM)上,并与各种SDR平台(EXMIMO、USRP、BladeRF、LimeSDR)连接。OAI目前为eNB/UE/EPC实现Rel 8/10栈。它运行在标准的ubuntu linux 14.04 LTS上,具有eNB/UE的低延迟内核。OAI需要支持(SSE3/SSE4)的因特尔处理器,但是支持AVX2是可选的。在与SDR平台(USRP、BladeRF、EXMIMO和LimeSDR)接口的PC上安装USB3/PCIe也是一项要求。该代码使用Linux附带的标准GNU工具链进行编译。OAI也可以在模拟模式(OAISIM)下运行。用于部署运营商核心网络的OAI软件包,即增强包核心(Enhanced Packet core)或EPC,统称为openairCN,而用于基站和终端的接入网软件则以openair5G的名称命名[4]。
2 LDPC模块加速
LDPC码由于可以达到更高的译码吞吐量和更低的译码时延,可以更好地适应高数据速率业务的传输,从而替代LTE的Turbo码,被采纳为5G NR数据的编码方案[5]。
在OAI中,LDPC的实现主要分为三大板块,分别为LDPC的编码,LDPC的解码和编解码函数的调用。
LDPC编码函数:
在OAI中,LDPC编码函数的定义代码如下所示:
1 int nrLDPC_encod(unsigned char **test_input,unsigned char **channel_input,
2 int Zc,int Kb,short block_length, short BG, encoder_implemparams_t *impp)
其中二级指针testinput指向编码输入数组。值得注意的是,在编码函数看来,输入数据中1比特代表1个信息位,即每比特代表输入数据(0或1);二级指针channel_input指向编码输出数组。此时输出数据8比特表示1个信息位,即每字节代表输出数据(0或1);OAI中采用了QC-LDPC编码方式,Zc、Kb以及BG均是QC-LDPC编码矩阵所需的参数;block_length表示输入码块长度;immp结构体用作编码函数的指示。其定义的结构体代码如下所示:
1 typedef struct {
2 int n_segments;
3 unsigned int macro_num;
4 unsigned char gen_code;
5 time_stats_t *tinput;
6 time_stats_t *tprep;
7 time_stats_t *tparity;
8 time_stats_t *toutput;
9 }encoder_implemparams_t;
总结而言,OAI提供了原始的编码函数、AVX2优化后的编码函数以及AVX2优化下最高8个码块一起编码的编码函数。immp结构体为编码函数提供了码块数以及时间测量,以适应不同的编码函数。
LDPC解码函数:
在OAI中,LDPC解码函数的定义代码如下所示:
1 int32_t nrLDPC_decod(t_nrLDPC_dec_params* p_decParams, int8_t* p_llr,
2 int8_t* p_out, t_nrLDPC_procBuf* p_procBuf, t_nrLDPC_time_stats* p_pr3529DBB4-0592-409E-B621-2A611E9124B9
3 ofiler)
p_decParams結构体为解码函数提供解码所需的指示参数。其中BG指示了QC-LDPC解码方式的矩阵块,Z代表移位因子,R代表解码率,numMaxIter代表最大迭代次数,而outMode则代表输出数据的格式,OAI中支持三种格式的输出,分别为32个比特每一个32位无符号输出,1比特每8位符号输出,一个LLR数值每8位符号输出。p_llr与p_out则分别代表编码输入与编码输出,均是每字节代表每个信息位;p_procBuf是解码函数所需的缓存空间结构体;p_profiler是为编码函数所提供的时间状态指示,用于指示各个步骤所耗费时间。
函数调用:
OAI中LDPC相关函数均是先编译成动态链接库(.so文件)的形式,再对库进行调用。通过调用函数int load_nrLDPClib(void)实现对nrLDPC_decoder以及nrLDPC_encoder的调用。该函数需要提供loader_shlibfunc_t结构作为加载函数的接收对象,同时传递给最终编解码函数的中间容器。在load_nrLDPClib函数中会调用load_module_shlib函数,实现对指定目录下共享库文件的加载以及函数加载。以LDPC解码为例,其调用函数的过程代码如下所示:
1 shlib_fdesc[0].fname = "nrLDPC_decod";
2 int ret=load_module_shlib("ldpc",shlib_fdesc,sizeof(shlib_fdesc)/sizeof(loa der
3 _shlibfunc_t),NULL);
4 AssertFatal( (ret >= 0),"Error loading ldpc decoder");
5 nrLDPC_decoder = (nrLDPC_decoderfunc_t)shlib_fdesc[0].fptr;
3 GPU加速
3.1 GPU加速原理
目前OAI仿真软件功能的实现都是基于CPU的,整个程序运行在CPU上。而LDPC编解码过程涉及大量数据的处理,并且其数据码块可以支持同时进行处理而不影响最终数据的正确性,正是基于这两点的考虑,本文提出了利用GPU对LDPC编解码进行加速的解决方案。
3.2 加速实现
本文采用了英伟达的Tesla V100显卡,其算力能力评估分值高达7.0,可以满足本文设想需要。除此之外,英特尔的各种软件开发工具包也为本文GPU加速的实现提供了支持。在本文中需要用到的软件开发工具包是指物理层组件,其能够提供部分基于GPU的物理层实现。接下来所有的安装操作均在Ubuntu18.04系统下进行的,首先需要对相关的依赖库文件进行安装,值得注意的是,因为DPDK组件需要在GCC特定版本的环境下进行编译,需要满足GCC的版本是8.5与7.5;CMake的版本需要在3.12以上。在安装好库文件依赖后,需要对英伟达的驱动和CUDA进行安装。在安装的软件开发工具包中,许多组件都提供基于H5文件的测试。通过将数据按照规定的格式写入H5测试向量文件中,供给加速组件读写测试,所以需要对HDF5库进行安装,最后在设置好环境变量之后,便可以对物理层软件开发工具进行安装了。
一个完整的CUDA程序包括以下步骤:1)设置显卡设备(单GPU不用);2)分配显存空间;3)从内存拷贝数据到显存;4)执行并行函数;5)从显存拷回数据到内存;6)释放显存空间;7)设备重置(单GPU不用)。在LDPC的编解码中也不例外。在英伟达的CUDA给出的物理层程序中,有LDPC编解码的实现,但其实现的方法和OAI中不尽相同。首先,其定义了一个LDPC类ldpc_tv,其中设置了LDPC编解码所需要的各种参数,例如编码块的数量、码字的比特数、基准码块等;其次,还定义了各种获取编解码前后的数据的函数,以及一些其他辅助函数。
在LDPC编码的示例程序中,首先需要获取一个HDF5文件,文件中的数据即为待编码数据,也可以通过类中的生成函数完成,但需要传入基本图样的类型BG,偏移位置Z和分段数量C,根据3GPP的38.212协议生成每个代码块的比特数K,当偏移位置小于64时,填充比特数F,以及编码后输出序列长度N,值得注意的是,GPU中只支持32位的LDPC计算,故K和N必须要为32的倍数。然后将原有或生成的数据拷贝到指定位置,做好数据的准备工作。需要通过cuphyLDPCEncodeLaunchConfig完成编码运行的参数配置工作,分配描述符并设置LDPC编码工作,接下来,再通过make_unique_device申请特有的GPU设备,将指示符与GPU相关联,最后,通过输入相关参数,启动cuphySetupLDPCEncode函数完成LDPC的编码工作。在此过程中,可以通过CUDA特有的event_timer函数,对程序完成的时间进行统计。
在LDPC解码的示例程序中,其为了验证编解码的正确性,采用了先生成数据再编码数据、再通过信道加扰,接着解码数据,最后将解码数据与生成数据对比,计算误比特率的方式,验证了其编解码的正确性。虽然这种既做裁判又做运动员的方式,有一定的不可靠性,但是若其编解码中的一个函数正确,那么两个函数的正确性就都得到了验证。接下来,本文将目标转到其示例程序的具体实现上。在得到经过加扰的数据后,第一步仍是获取相关参数,但需要的参数更多,增加的参数有解码率R和最大迭代次数numIterations等。随后,根据输入设置输出格式,创建cuPHY上下文,并创建LDPC解码器实例,分配工作区缓冲区,以供LDPC实现使用。接着,初始化LDPC解码描述符结构,准备工作完成后,便可进行解码工作。3529DBB4-0592-409E-B621-2A611E9124B9
从上面的描述可以看出,OAI中的LDPC编解码和CUDA有很大不同,虽然编解码的最终实现都采用了封装好的函数,但其数据接口大相径庭。所以需要对接口进行统一化编排。考虑到OAI程序的主体地位,数据格式的转化都会在CUDA中的程序实现。除了数据接口的统一,还有外部文件的调用问题。OAI的代码采用C语言,而CUDA采用的是C++,两者并不相同,无法直接调用。在OAI中对外部程序的调用都是采用先寻找外部库文件的位置和相应函数名,再将其赋给内部定义的一个空壳函数的方法,具体操作代码如下所示。
1 char fname[] = "_Z15ldpc_encode_gpuPPhS0_iiii";
2 void *handle = dlopen("/home/ubuntu/cuBB/build/cuPHY/examples/error_
3 correction/libgpuldpc.so", RTLD_LAZY|RTLD_NODELETE|RTLD_GLOBA
4 L);ldpc_encode_gpu = (gpuldpc_encode_t) dlsym(handle, fname);
其中RTLD_LAZY:代表在dlopen返回前,對于动态库中存在的未定义的变量(如外部变量extern,也可以是函数)不执行解析,就是不解析这个变量的地址。RTLD_NODELETE代表在dlclose()期间不卸载库,并且在以后使用dlopen()重新加载库时,不初始化库中的静态变量。RTLD_GLOBAL:代表使得库中解析的定义变量在随后其他链接库中可以使用。因为此处为一个初始化定义,并且本文希望在初始化后一直保持使用相关函数的状态,故采用如上参数。
本文先将CUDA中的相关程序采用-fPIC -shared -o libgpuldpc.so编译命令,将所需文件编译为动态链接库,有时候函数被封装进.so后名称会变化,比如在前后加点字符,例如上面示例中的函数名_Z15ldpc_encode_gpuPPhS0_iiii在CUDA的程序中名称为ldpc_encode_gpu。这时想查看生成的.so文件中的函数名称只需运用nm命令即可查看。
值得注意的是,在正式运行编解码程序前,都需要对进行GPU预热,预热的方式和编解码相同,系统在每一次编解码或者说预热时消耗的时间都比较长,所用时间会达到秒这一数量级,故建议在整个OAI程序初始化时便对GPU进行预热,利用其自带数据完成一次编解码,其中函数的各种定义和.so库函数的引用不再赘述。如此便完成了整个LDPC函数的GPU加速。
4优化结果仿真分析
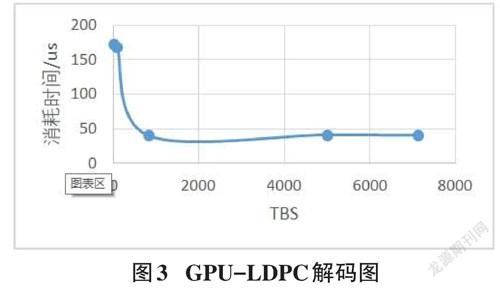
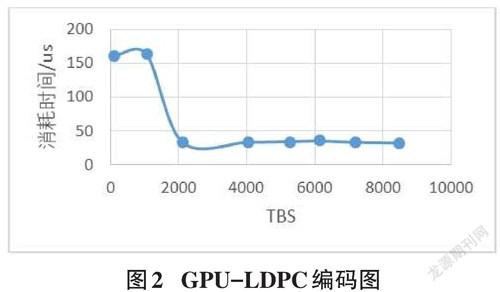
为了验证本文论述的GPU对LDPC编解码的正确性,本文在保证初始条件不变的情况下,用GPU代码替换了CPU的代码,并进行了实验仿真,实验仿真结果如图2、图3所示:
利用GPU加速后,从LDPC编码的时间消耗与TBS的关系,可以看出当TBS较大时,LDPC编码完成的时间皆在35微秒左右,而当TBS较小时其所用时间反而较长。可以看出相较于CPU,当数据量较大时GPU加速的效果明显。
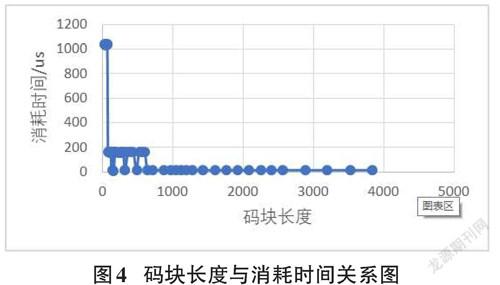
为了明确当TBS较小时,所用时间反而较长这种情况的原因,本文单独对GPU的LDPC模块进行了测试,实验结果如图4所示:
图4是当BG=2时,码块长度与编码消耗时间的关系图(码块长度与TBS呈线性关系),经过数据查看可以发现,这些消耗时间较长的码块长度都是32的整倍数,联系到上一章所描述的初始定义数据长度时必须是32的整倍数才能完成数据定义,故猜测这可能和GPU自身数据处理的方式相关。
5结论
开源项目OAI基本实现了5G NR中的物理层,但仍有很多功能未完善。本文通过仿真实验,找出了系统瓶颈在于LDPC编解码的时间过长,提出了一种基于GPU代替CPU完成编解码功能的方案,即统一化了OAI与GPU的接口,实现了OAI对外部代码的调用,完成了对OAI的优化。仿真实验表明,该方案降低了系统处理数据的时间。
参考文献:
[1] 王子凡,温向明,陈亚文,等.面向5G无缝连接的云无线接入网系统及实现[J].北京邮电大学学报,2018,41(5):143-148,158.
[2] Liu Y F,Olmos P M,Mitchell D GM.Generalized LDPC codes for ultra reliable low latency communication in 5G and beyond[J].IEEE Access,2018,6:72002-72014.
[3] Chen Y,Guo Z,Yang X Q,et al.Optimization of coverage in 5G self-organizing small cell networks[J].Mobile Networks and Applications,2018,23(6):1502-1512.
[4] Salhab N,Langar R,Rahim R.5G network slices resource orchestration using Machine Learning techniques[J].Computer Networks,2021,188:107829.
[5] Chen Y,Liu Y,Zhao J Y,et al.Mobile edge cache strategy based on neural collaborative filtering[J].IEEE Access,2020,8:18475-18482.
收稿日期:2021-12-30
基金项目:北京电子科技职业学院科技一般项目(基金号:2021Z029-KXY)
作者简介:高震宇(1969—),女,吉林省吉林市人,讲师,学士,主要研究方向为电子信息工程技术、无线通信等。3529DBB4-0592-409E-B621-2A611E9124B9
猜你喜欢
湘潭大学自然科学学报(2022年2期)2022-07-28 05:26:28
中国石油石化(2022年12期)2022-07-16 08:28:28
空间科学学报(2020年4期)2020-04-22 01:17:38
中国外汇(2019年19期)2019-11-26 00:57:32
中国交通信息化(2019年10期)2019-11-16 09:24:14
民用飞机设计与研究(2019年2期)2019-08-05 01:33:26
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
电子测试(2018年18期)2018-11-14 02:30:54
信息安全与通信保密(2016年5期)2016-02-28 17:04:14
