
Prediction of Intrinsically Disordered Proteins Based on Deep Neural Network-ResNet18
2022-07-04 05:42JieZhangJiaxiangZhaoandPengchangXu
Jie Zhang,Jiaxiang Zhaoand Pengchang Xu
School of Electronic Information and Optical Engineering,Nankai University,Tianjin Key Laboratory of Optoelectronic Sensor and Sensing Network Technology,Tianjin,300350,China
ABSTRACT Accurately,reliably and rapidly identifying intrinsically disordered(IDPs)proteins is essential as they often play important roles in various human diseases;moreover,they are related to numerous important biological activities.However,current computational methods have yet to develop a network that is sufficiently deep to make predictions about IDPs and demonstrate an improvement in performance.During this study,we constructed a deep neural network that consisted of five identical variant models,ResNet18,combined with an MLP network,for classification.Resnet18 was applied for the first time as a deep model for predicting IDPs,which allowed the extraction of information from IDP residues in greater detail and depth,and this information was then passed through the MLP network for the final identification process.Two well-known datasets,MXD494 and R80,were used as the blind independent datasets to compare their performance with that of our method.The simulation results showed that Matthew’s correlation coefficient obtained using our deep network model was 0.517 on the blind R80 dataset and 0.450 on the MXD494 dataset;thus,our method outperformed existing methods.
KEYWORDS ResNet18;MLP;intrinsically disordered protein
1 Introduction
Intrinsically disordered proteins(IDPs)(i.e.,proteins that contain disordered regions[1,2])have been confirmed to be related to many important biological activities and involved in several important cell functions,such as nucleic acid folding[3]and cell signaling and regulation[4,5].Moreover,various human diseases,such as certain types of cancers[6],genetic diseases,and Alzheimer’s disease[7,8]are associated with IDPs.Furthermore,IDPs are more easily blocked by small molecules,and are therefore potential targets for drug design,providing a good basis for drug treatment[9,10].However,accurately,reliably,and rapidly identifying IDPs remains a challenging problem.
Numerous schemes for detecting IDPs have been proffered over the past several decades and can be categorized into two types:those based on physical and chemical properties of amino acids and those based on computational methods.(i)examples based on physicochemical properties include FoldIndex[11],GlobPlot[12],FoldUnfold[13],and IsUnstruct[14].FoldIndex[11]predicts disordered proteins by calculating the ratio of the average hydrophobicity to the average net charge of the residues.GlobPlot[12]predicts the disordered region by analyzing the tendency of all amino acids in the protein sequence to disordered residues and ordered residues.FoldUnfold[13]treats areas with a weaker density as unnecessary areas by predicting the average packing density of residues.IsUnstruct[14]is a prediction method based on statistical physics and uses the Ising model for disorder-order transformations in protein sequences and replaces the interactions of adjacent terms with penalties for changes between boundary energy states.These methods promote the field of IDPs,yet ignore the overall structure of the protein,which leads to inaccurate prediction results.(ii)More recently,the use of machine learning has increased in the field of bioinformatics,especially to solve problems that are closely related to human life and health[15,16].Methods to identify IDPs through machine learning,especially deep learning techniques,such as PONDR[17],DISOPRED2[18],RONN[19],DISKNN[20],IDP-Seq2Seq[21],NetSurfP-2.0[22],SPOT-Disorder2[23],and RFPR-IDP[24],have also been developed.The PONDR[17]series is the first publicly available and established method for predicting IDPs internationally,which distinguishes disordered proteins from ordered proteins based primarily on differences in their amino acid composition.DISOPRED2[18]is a dynamic prediction method for disordered proteins,and the output of the support vector machine is used as the prediction results.RONN[19]is a function-based array and neural network prediction algorithm.Its main idea is that if two proteins have similar biological functions and similar tendencies toward being disordered or ordered,then their sequences are also similar.DISKNN[20]applies KNN with several protein features to predict the disordered regions of proteins.However,the performance comparison in this article was unconvincing because it was only regarding one protein.IDPSeq2Seq[21]draws on sequence-to-sequence learning in natural language processing to map protein sequences and use associations between residues as features for prediction.NetSurfP-2.0[22]applies convergence strategies with the convolutional neural network(CNN)and long and short-term memory networks(LSTM)based on protein structural features.SPOT-Disorder2[23]is an improvement of the SPOT-Disorder by Hanson et al.[25](a profile-based method),which mainly uses the LSTM model to predict intrinsically disordered proteins.RFPR-IDP[24]is based on a combination of the CNN and the bidirectional LSTM.In addition,there are also various meta-methods to predict IDPs,such as IDP-FSP[26],MFDp[27],Spark-IDPP[28],and Meta-Disorder[29],which run multiple independent prediction schemes and merge their results to obtain final prediction results.Mishra et al.used a deep learning-integrated method combining 9890 features for protein function prediction;the large number of features used was novel[30].These schemes based on computational methods do not sufficiently capture details between protein residues and only capture those at the sequence level,which leads to inaccurate predictions.
Thus,in the field of predicting IDPs,several problems remain:(i)Predictions using physical and chemical methods is not only a complex and time-consuming process but also have poor prediction performance;(ii)Previous studies based on computational methods did not employ a sufficiently deep network to capture more accurate characteristics among residues,and consequently,did not demonstrate a significant improvement in performance;(iii)Although some previous methods have advantages in predicting IDPs,Matthew’s correlation coefficient(MCC)[31],which directly indicates the quality of the prediction result,remain relatively low on blind independent test datasets.
Motivation:Because IDPs are essential given their important roles in various human diseases and their association with many important biological activities,addressing the above three problems in an accurate,reliable,and rapid manner is of great significance and research value.Therefore,using simple computational methods,rather than complex physicochemical methods,is crucial,and constructing a neural network with deep layers for predicting IDPs and demonstrating an improvement in prediction performance is essential.ResNet18[32]has sufficiently deep layers and has been used in myriad domains owing to its excellent performance;however,it is the first application of ResNet18 for predicting IDPs.It would be constructive to apply the ResNet18 deep neural network and achieve good results,with a high as possible MCC value,for predicting IDPs.
Contribution:During this study,we proposed a novel method for predicting IDPs using deep neural networks,which outperformed existing methods.The innovative value of our contributions are as follows:
·We constructed a sufficiently deep structure,which consisted of five identical ResNet18 networks,and combined it with a constructed multilayer perceptron(MLP)network.This constructure differed from all previous methods and was a completely new architecture.Fig.1 depicts the paradigm of our deep neural structure.
·Resnet18 was applied for the first time as a deep network model for predicting IDPs.The study did not simply use the ResNet18 network directly but replaced the output layer with a dense layer,and the output was then input into the MLP network.
·The simulation results showed that the MCC value obtained using our deep network model was a significant improvement on other existing methods,which has important implications for more precise investigations of IDPs.
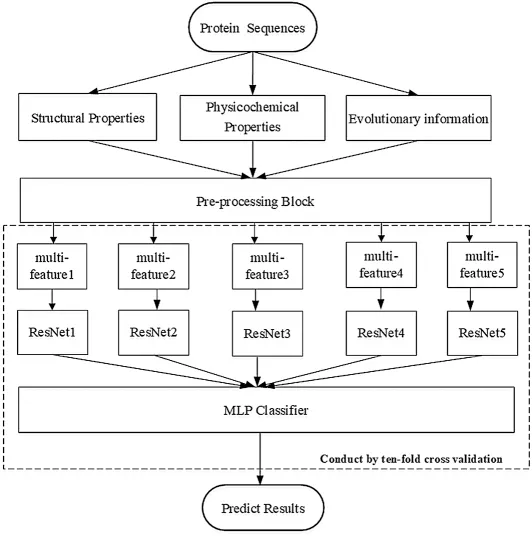
Figure 1:Paradigm of our deep neural structure
The following steps illustrate the specific performing process of our proposed method in detail:
Step 1.Data preparation:A total of 1616 pieces of the latest protein sequences were downloaded from the DisProt database as a training dataset for our deep network model.
Step 2.Feature selection:For the features of each amino acid of the IDP sequence,we calculated five structural properties,seven physicochemical properties,and 20 protein evolution information of the sequence with a total of 32 features;the five structural properties included Shannon entropy[33],topological entropy[33,34],and three amino-acid propensity scales;the seven physicochemical properties were obtained from Meiler et al.[35],and the position-specific scoring matrices(PSSMs)were generated from the PSI-BLAST software using the latest NCBI non-redundant database[36](updated in June 2020).
Step 3.Feature pre-processing:An important step after selecting features is preprocessing features using the sliding window approach.With the sliding calculation of the window over each protein sequence,we obtained the feature matrix X,which was fed into our constructed deep neural network model.
Step 4.Model processing:We constructed a sufficiently deep structure,which consisted of five identical ResNet18 networks,and combined it with a constructed MLP network.For the original ResNet18 model,we replaced the fully connected(FC)layer with a dense layer,and the output was then input into the MLP network for the final identification process.
Step 5.Analyze the blind dataset performance:In contrast to other well-known methods,the R80 and MXD494 datasets were used as our blind datasets to analyze the performance of our deep network model.
The different sections of this article describe the contents of the proposed method in a step-by-step manner and are organized according to the above steps as follows:Section 2 describes above Steps 1 to 4 and the materials and methods proposed in this article,which include the preparation of our method,the architecture of the network,and how the method works.Section 3 compares other well-known methods that predict IDPs using five recognized performance measures.Section 4 provides our conclusions and the future scope of our research.
2 Materials and Methods
We have listed all datasets used for training and blind testing,and we introduce the architecture of our deep network model depicted in Fig.1.The model is comprised of a pre-processing block,five copies of the ResNet18,and a self-constructed MLP network.
2.1 Datasets
We employed DIS1616 from the latest version of the DisProt database as our training dataset.The DIS1616 dataset consists of 1616 protein sequences,which comprise 888678 residues.Of these 888678 residues,182316 are disordered residues and 706362 are ordered residues.Here,we randomly shuffled and divided the dataset into 10 separate subsets,with the test dataset containing 166 sequences.Then,10-fold cross-validation was performed.To analyze the performance of our deep network,the R80[19]and MXD494 datasets[21,37]were used as our blind datasets.The R80 dataset consisted of 80 protein sequences with 3566 disordered residues and 29243 ordered residues.The MXD494 dataset contained 494 protein sequences with 44087 disordered residues and 152474 ordered residues.Fig.2 illustrates two completely ordered proteins(2FG1 and 3BBB)with stable three-dimensional structures from the MXD494 dataset.
Figure 2:Two protein pictures from the MXD494 dataset
2.2 Protein Feature Selection and Pre-Processing Procedure
Three types of features were selected:five features associated with the structural properties,seven features corresponding to the physicochemical properties,and the remaining features related to the evolutionary information.Structural features were Shannon entropy[33],topological entropy[33,34],and three amino acid propensity scales provided in the GlobPlot NAR paper[12].The physicochemical features were obtained from Meiler et al.[35].The PSSMs were used to describe the protein evolution information generated from the PSI-BLAST software using the latest NCBI non-redundant database[36](updated in June 2020).
As shown in Fig.1,our deep neural network contained a pre-processing block that computed the input feature matrix X as below:
1)For each residue in a given protein sequence of length L,a window of size M centered around this residue was chosen.We addedzeros to each end of the protein sequence.We then computed the features associated with the structural properties,the physicochemical properties,and the evolutionary information described above for each residue within this window.The characteristic values of these calculated residues were averaged over this specific window and assigned to residues in the center of the window as their characteristic values.Therefore,each sequence was associated with a 32×Lcharacteristic matrix

where xiwith 1 ≤i≤Ldenotes the 32 characteristic values(five structural properties,seven physicochemical properties,and 20 evolutionary information)associated with thei-th residue.The entry xiwith 1 ≤i≤Lin Eq.(1)is a 32×1 vector that can be expressed as

wheremi,kdenotes thek-th characteristic value with 1 ≤k≤32 of thei-th residue(1 ≤i≤L)assigned over the associated window.In Eq.(2),mi,1andmi,2represent Shannon entropy and topological entropy associated with thei-th residue,respectively.Their computations follow the process presented in Eqs.(1)and(14)of He et al.[33].
2)For thei-th residue(1 ≤i≤L)in the protein sequence of length L,we varied the size of the sliding window centered around this residue to yield a feature matrix:

Fig.1 shows that the output of the pre-processing block yielded the feature matrix in Eq.(3)of thei-th(1 ≤i≤L)residue.If we usewith 1 ≤k≤32 to represent thek-th row of matrix Xi,then we can rewrite.Therefore,a set of Mi,l,Mi,l+1,Mi,l+2withl=1,4,7,10(i.e.,the output of multi-feature1 to multi-feature4 in Fig.1)was chosen as the input dataset,which was fed into ResNet1 to ResNet4.In addition,a set of Mi,l,···,Mi,32withl=13 was chosen as the input dataset,which was fed into ResNet5.
2.3 Designing and Training the ResNet18 and MLP Models
We constructed a sufficiently deep structure,which consisted of five variant ResNet18 networks,and combined it with a constructed MLP network.Fig.3 shows each of the five identical variant deep neural structures that replaced the FC layer with a dense layer containing 16 perceptrons.The outputs of the five variant networks were then concatenated and input into the MLP network that we constructed for the prediction.

Figure 3:Frame diagram of the variant ResNet18 model
The MLP network we constructed had two hidden layers,where the binary cross-entropy cost function was employed:
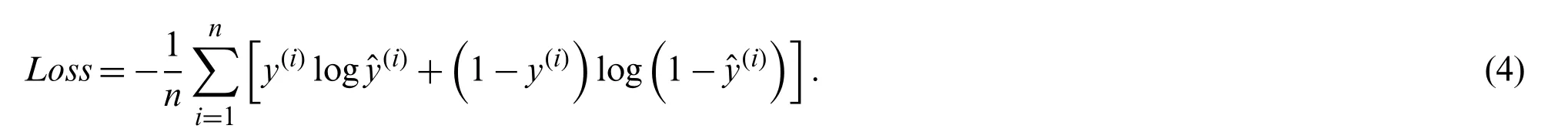
In Eq.(4),y(i)∈{0,1}is the label;0 indicates that thei-th residue is ordered,and 1 indicates that the residue is disordered.is the obtained probability of thei-th residue using our constructed MLP network.
The output of each of our variant ResNet18 models in Fig.1 was a 1×16 matrix,and therefore,the outputs of these five matrices were concatenated to yield a 1×80 matrix.This was then used as the input for our MLP network.The MLP network was comprised of two hidden layers,which included 75 and 15 perceptrons,respectively,and a rectified linear unit was used as the activation function.Moreover,in the two hidden layers,we adopted the dropout mechanism,which randomly drops 60% perceptrons during each iteration.One perceptron was contained in the output layer,which utilizes a sigmoid as the activation function.The structure of the MLP network is depicted in Fig.4,where the sigmoid function is used in the perceptron of the output layer.
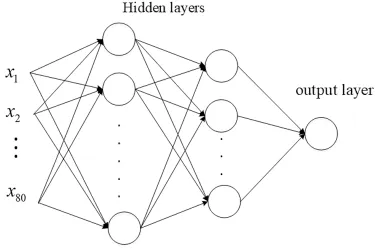
Figure 4:Structure of the MLP network
We randomly initialized the parameters of the MLP model and employed an stochastic gradient descent(SGD)optimizer to perform back-propagation to update the parameters during the training process.The output of the sigmoid function was thus used as the predicted probability,defined in Eq.(5)of thei-th residue.

wherea(i)denotes the output through the network of thei-th residue.
The training process with our constructed model was as follows:first,we randomly shuffled and split the training dataset into multiple batches and calculated the probabilities of all residues in each batch through the constructed network using Eq.(5).Subsequently,the binary crossentropy loss function was employed to compute the loss of the given batch,to optimize the network parameters through the SGD optimization mechanism for the back-propagation process,where the learning rate was set to 0.001.The above procedure was repeated for every batch of residues until one epoch was completed(i.e.,all residues were trained by the network,and probabilities were calculated).After one epoch was completed,we then randomly shuffled and split the training dataset into multiple batches again and repeated the whole procedure until the loss stopped converging or the training epoch reached the setting number.The main parameters of our algorithm are summarized in Table 1.

Table 1:Experimental parameters used in our algorithm
After the training process was complete and our network parameters were determined,we used the test dataset to test our network.The predicted probabilities obtained using Eq.(5)were used to determine whether the residue was disordered or ordered.Finally,we conducted the performance evaluation.
2.4 Performance Measures
To evaluate the accuracy of our model for predicting IDPs,we mainly used five authoritative and universal evaluation criteria in the IDP prediction field:sensitivity(Sen),specificity(Spe),binary accuracy(BAcc),weight score(Sw),and MCC.TP,FP,TN,and FN were also used to respectively denote the numbers of true disordered,false disordered,true ordered,and false ordered samples.The following formulae were used to calculate these five evaluation criteria:
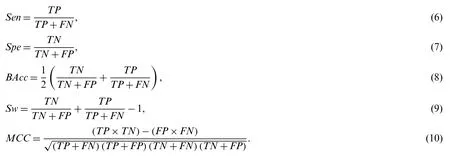
Among these,the MCC value was the most important and effective criterion to measure the performance of the prediction of IDPs,which varies from -1 to 1.A high MCC value indicates outstanding classification performance.
3 Results and Discussion
3.1 Comparison of Performance with Other Well-known Methods
For ease of description,DISRES was employed as the acronym of our deep network model.To analyze the performance of our deep network model and highlight the advantages of our method,DISRES was compared with seven other state-of-the-art methods used for predicting IDPs,using the five performance measures described above using two blind datasets:MXD494 and R80.The MCC value obtained by our trained model was 0.450 for the blind MXD494 dataset and 0.517 for the R80 dataset.Therefore,the MCC values obtained using our network model showed that our model outperformed the existing methods of DISpre,SPOT-Disorder2,RFPRIDP,DISOPRED2,DISpro,RONN,PONDR,and FoldIndex.All relevant evaluation criteria for comparing the performance of the models using the two blind datasets,MXD494 and R80,are shown in Tables 2 and 3.To visualize the comparison results,Figs.5 and 6 show the comparisons of performance between different methods using the two blind datasets,respectively,where the red line represents MCC,the most important evaluation criteria,for prediction performance.
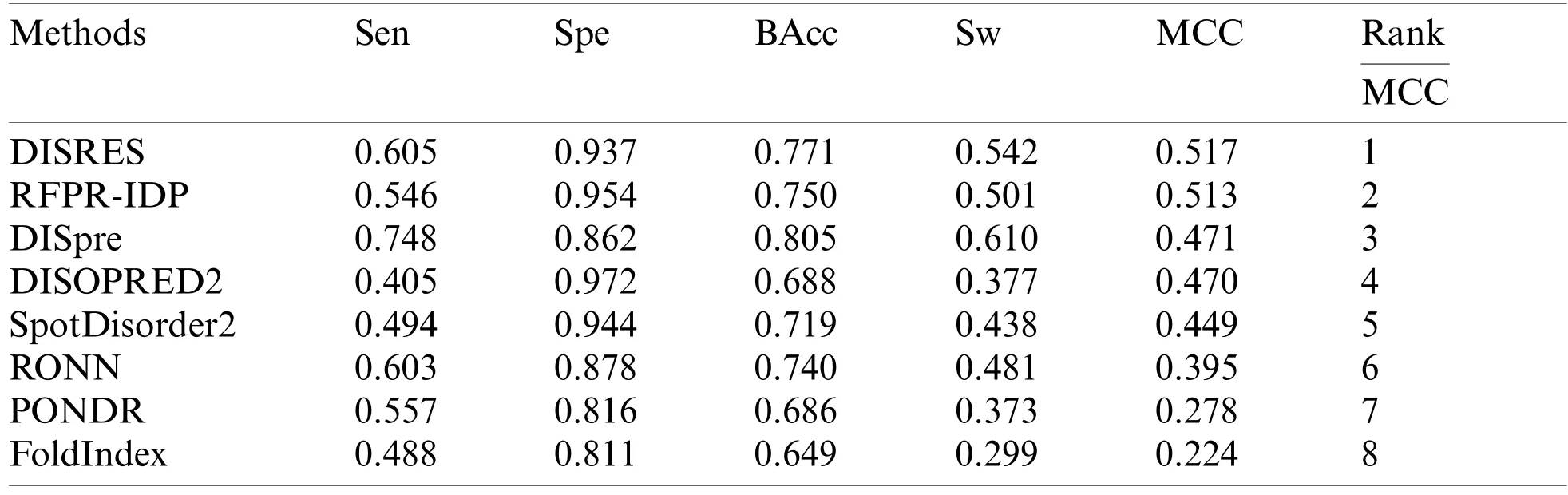
Table 2:Performance comparison of the various methods using the blind R80 dataset
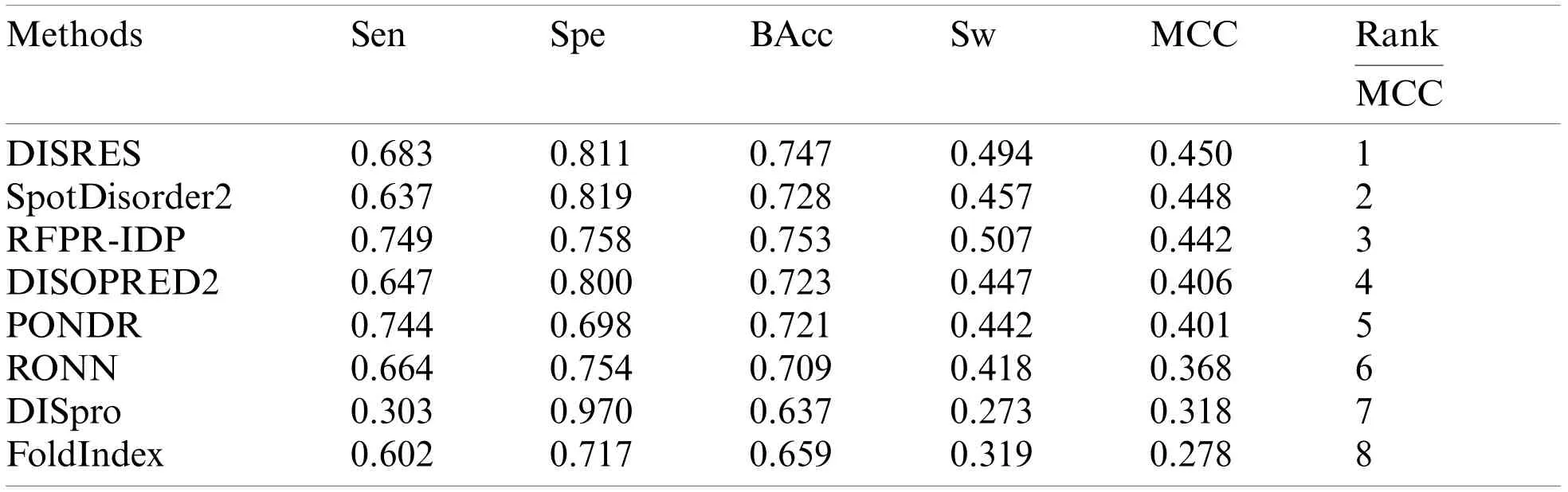
Table 3:Performance comparison of the various methods using the blind MXD494 dataset
As shown in Table 2,for the blind R80 test dataset,DISRES showed superiority over the other seven well-known methods for predicting IDPs,with an MCC value of 0.517,and ranking first among all methods.DISpre is a method we developed previously in relation to MCC using the MLP network alone.Fig.5 shows that DISpre achieved the highest sensitivity value but obtained lower specificity and MCC value,which resulted in poor predictive performance.The MCC value significantly improved with the addition of the ResNet18 deep neural network,and the value obtained by DISRES was on the highest point of the red line,which demonstrated that our method yielded the best performance in predicting IDPs.
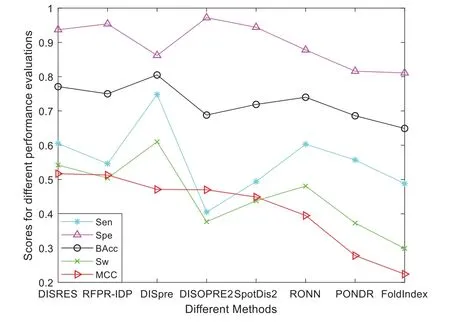
Figure 5:Comparisons of the different methods using the blind R80 dataset
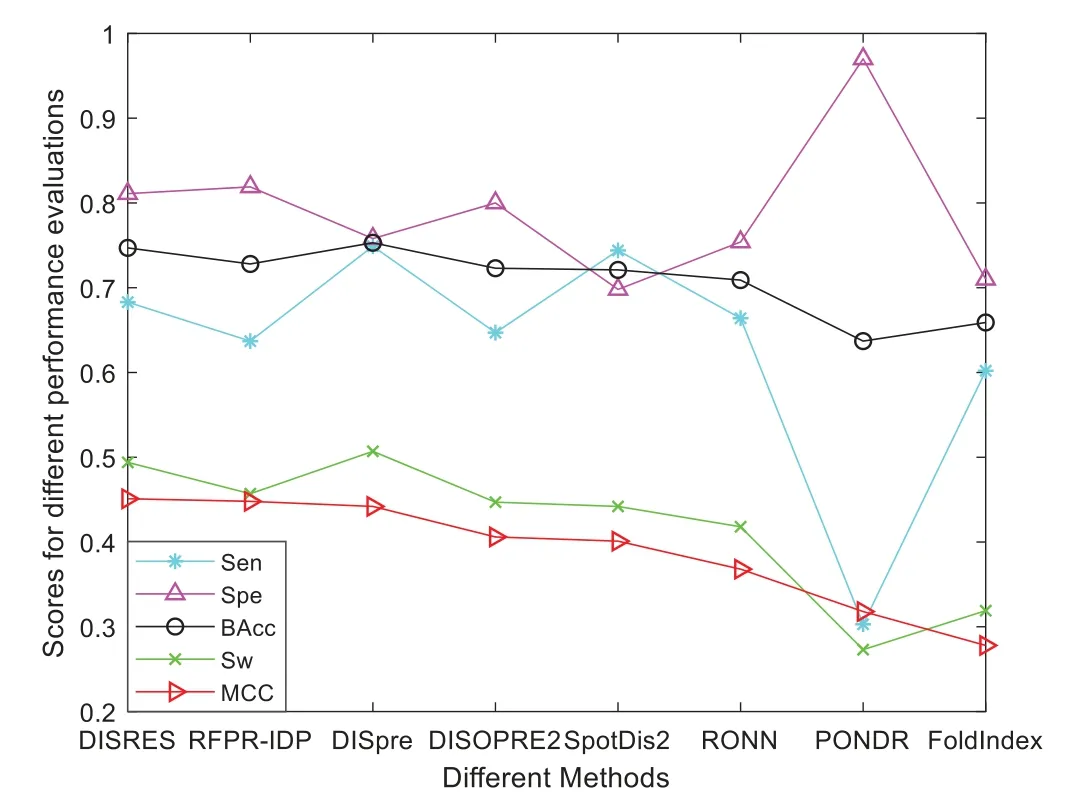
Figure 6:Comparisons of the different methods using the blind MXD494 dataset
To make the results more convincing,we used another widely used blind test dataset,the MXD494,which contains more data than R80.As shown in Table 3,DISRES achieved an MCC of 0.450,which was higher than that of several other prediction methods;moreover,it still ranked first among all methods,which can largely be attributed to the deep neural network ResNet18 applied in DISRES.Although the PONDR obtained the best specificity,as shown in Fig.6,its sensitivity and MCC value were low,which indicated that the PONDR did not perform well in predicting IDPs.DISRES still achieved the highest point on the red line of MCC,which showed that it outperformed the other methods.
3.2 Limitations of the Current Study
For the first time,we used the deep neural network model,ResNet18,and combined it with an MLP network to predict disordered regions of IDPs with good performance.However,it is well known that the size of the training dataset in a neural network affects the final prediction results.Although the dataset we obtained from the authoritative DisProt database is the most recent data available,there were still only 1616 protein sequences,which limits the potential of improving the performance of our model.
4 Conclusions
IDPs are of great importance as they play essential roles in numerous human diseases,such as certain types of cancers,genetic diseases,and Alzheimer’s disease;moreover,they are related to many important biological activities,such as nucleic acid folding and cell signaling and regulation.Thus,developing a method that can accurately,reliably,and rapidly identify IDPs is important to understand the mechanisms underlying biological activities and study the role of IDPs in major diseases.Therefore,our proposed method for efficiently detecting IDPs has important practical implications for research on biological activities.
In contrast to other previously proposed methods,our model has the following advantages:(i)fewer features were selected to achieve better results than other methods;(ii)a sufficiently deep neural network,ResNet18,was introduced for the prediction and achieved the most accurate predictions;(iii)most convincingly,the MCC values obtained using our method were the highest.
The outperforming of our constructed model over other methods was mainly attributed to the following points:(i)the construction of a sufficiently deep structure,which consisted of five identical ResNet18 networks,and its combination with a constructed MLP network.This constructure differed from all previous methods and was a completely new architecture;(ii)Resnet18 was applied for the first time as a deep network model for predicting IDPs,which enabled the extraction of information from IDP residues in greater detail and depth than those of other methods;(iii)using two well-known datasets,MXD494 and R80,as blind test datasets,simulation results showed that the MCC values obtained using our method were 0.517 for the blind R80 dataset and 0.450 from the MXD494 dataset,which demonstrated that our method outperformed existing methods.
In the future,we will approach subsequent research from two perspectives:(i)the extraction of protein features;exploring additional properties of amino acids may improve prediction performance;(ii)models developed based on other deep learning methods to further improve prediction performance.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2022年5期
Computer Modeling In Engineering&Sciences2022年5期
- Computer Modeling In Engineering&Sciences的其它文章
- Computational Investigation of Cell Migration Behavior in a Confluent Epithelial Monolayer
- The Hidden-Layers Topology Analysis of Deep Learning Models in Survey for Forecasting and Generation of the Wind Power and Photovoltaic Energy
- Conceptual Design Process for LEO Satellite Constellations Based on System Engineering Disciplines
- Deep Learning-Based Automatic Detection and Evaluation on Concrete Surface Bugholes
- Efficient Numerical Scheme for the Solution of HIV Infection CD4+T-Cells Using Haar Wavelet Technique
- Prototypical Network Based on Manhattan Distance