
基于集成学习的用户信用卡违约预测模型研究
2022-07-04 12:29周芄,王勇
井冈山大学学报(自然科学版) 2022年4期
周 芄,王 勇
基于集成学习的用户信用卡违约预测模型研究
*周芄,王勇
(安徽工程大学计算机与信息学院,安徽,芜湖 241000)
用户信用卡违约预测任务有助于银行等金融机构平衡经济风险与经济利益,对于银行信用卡业务的风险管控具有重要作用。针对用户信用卡违约预测问题,提出了一种基于集成学习的预测模型,有异于传统集成学习中的弱学习器。该模型采用集成模型和神经网络模型作为基学习器,从而提升模型整体的预测效果。首先通过预处理提取用户信用卡数据集的相关特征,然后分别采用优化后的决策树、随机森林、GBDT、XGBoost、CatBoost和SPE六种机器学习模型与神经网络模型进行并行训练和预测,最后通过加权软投票法集成基学习器结果并输出最终预测结果。结果表明,相对于基学习器,该模型在各项评估指标上均有所提升,且拥有更好的模型泛化能力。
违约预测;集成学习;机器学习;神经网络
信用卡因其方便、利息低等特点已经被普及到人们的日常生活中。随着信用卡用户数量的增加,信用卡的风险管控对于银行等金融机构来说成为了一项具有挑战性的任务,银行等金融机构需要权衡信用卡业务所带来的利益与风险,而用户的信用卡违约、消费、还款等预测任务已然成为监控信用卡风险的有效途径之一。
用户信用卡违约预测任务包含信用卡消费预测、信用卡还款预测等任务。本质上来说,用户信用卡违约预测属于分类任务。用户信用卡历史相关的各项数据作为数据集特征,例如在不同月份的消费金额、还款金额等,经过监督学习或无监督学习的方式预测在未来一段时期内用户是否会发生违约行为。目前,针对用户信用卡违约预测的方法可大体分为三类:基于规则的方法、基于机器学习的方法和基于深度学习的方法[1]。
基于规则的违约预测方法基本思想是通过人工预先定义相关规则,进而直接对数据进行分类预测,其优势在于其简洁性和较强的解释性。然而此类方法存在如下缺陷:一是需要大量专家领域知识,人力资源成本消耗高,且极度依赖领域知识的正确性,主观性强。二是泛化能力弱,由于规则都是针对特定领域的,不同领域之间的规则一般无法相互适用。
基于机器学习的违约预测基本思想是利用统计学习方法学习不同模型的相关参数,进而提升模型的预测效果和泛化能力。此类方法克服了规则方法对人工的强依赖性缺陷,同时具有更强的泛化能力,因此近些年来广泛受到国内外研究学者的关注。Florentin Butare[2]等人基于对数机率回归(Logistic Regression)、决策树(Decision Tree)和随机森林(Random Forest)对不同银行的用户信用卡数据进行预测,得出了不同的机器学习模型适用于不同银行的信用卡违约预测任务的结论。Jianping Cai[3]等人提出了一种基于差分隐私的加权SVM算法用于预测信用卡的还款和违约情况,同时该算法能够充分保护用户的隐私。国内方面,章宁[4]等人提出基于TF-IDF的机器学习模型,包含Logistic回归、SVM等,并将这些模型应用于P2P贷款预测任务,在真实的贷款数据集上取得了80%以上的AUC评价分数。马晓君[5]等人提出了基于CatBoost的贷款违约预测模型,在真实银行相关借款数据集上取得了96%的准确率。
随着计算机硬件性能的提升,基于深度学习模型的违约预测方法逐渐受到研究学者的关注。Ying Chen[6]等人提出了基于k-means与BP神经网络集成算法的违约预测模型,该模型首先利用k-means算法改变数据分布,然后利用随机森林计算数据特征的,利用BP神经网络进行模型训练和预测。笔者等人将该模型与KNN等五种常见的机器学习模型进行对比,取得了较高的AUC评价分数。杨磊[7]等人提出了基于Transformer编码器的违约预测模型,在有标签的小规模数据集上,该模型通过Transformer编码器能够较好地缓解训练样本类别不均衡的影响。
集成学习(Ensemble Learning)的思想被广泛用于用户信用卡违约预测中[8],研究学者关注使用多种机器学习算法或深度学习算法作为基学习器,集成基学习器的预测结果或者将集成结果作为辅助特征用于新的学习器进行训练。多数研究使用的基学习器学习能力较弱,通过集成学习思想聚合基学习器性能以提升模型整体学习能力。本研究关注将机器学习模型、集成模型和神经网络模型作为基学习器,通过结合策略生成一种学习能力更强的集成模型(Ensemble model)。通过强化基学习器的学习能力以达到提升模型整体学习能力的目的。具体来说,首先对用户信用卡数据集进行预处理以提取模型需要并能够计算的特征。然后构建基学习器,包含决策树、集成学习模型(随机森林、GBDT、XGBoost、CatBoost、SPE)和深度学习模型(BP神经网络)七种模型,通过加权软投票融合策略集成各基学习器的学习结果作为模型的最终预测结果。
本研究的创新点在于提出的强化了集成模型中的基学习器,采用包含集成学习模型和神经网络模型等学习能力较强的模型作为基学习器。此外,将基学习器中的决策树和集成学习模型所学习到的样本特征权重传入神经网络,进一步强化基学习器的学习能力。
1 基于集成学习的用户信用卡违约预测模型
基于集成学习的违约预测模型主要分为三个步骤:第一步是对训练数据和预测数据进行预处理,将数据转化为模型可接受、可计算的形式。第二步构建集成学习模型。本文参考文献[9],统一规范命名各模型的缩写,即DTC(决策树,Decision Tree)、RF(随机森林,Random Forest)、GBDT(Gradient Boosting Decision Tree)、XGBoost(eXtreme Gradient Boosting)、CatBoost、SPE(Self Paced Ensemble)、BP(Back Propagation neural network)。第三步是模型训练与预测。通过训练优化模型参数,再对预测数据集进行预测,得出模型的输出结果。图1展示了本文提出的模型的概要图。
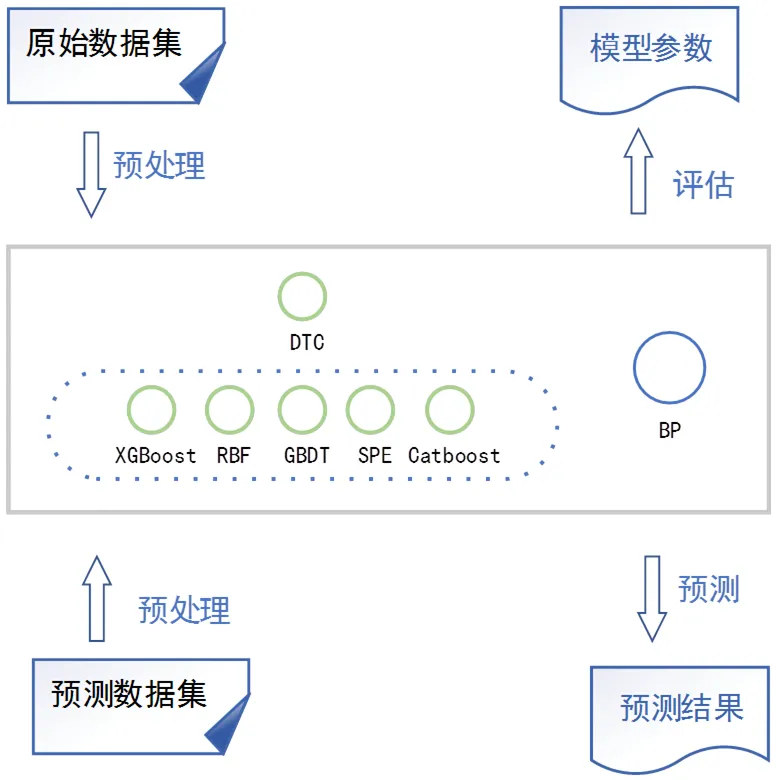
图1 基于集成学习的用户信用卡违约预测模型
1.1 数据预处理
数据预处理的目的主要是剔除原始数据集(包含训练集和测试集)中的缺失值、异常值,筛选出与学习任务相关的特征,并将其转换为模型能够接收和计算的输入形式。具体来说,我们的数据预处理主要包含以下步骤:
● 剔除数据集中缺失值比例达到60%的数据。采用均值、方差填充法处理数据集中剩余的缺失值。
● 采用one-hot编码将离散特征连续化,以便模型能够计算离散特征。
● 采用z-score标准化将数据压缩至同一维度以减少数据量纲差异带来的影响。
1.2 集成学习模型
集成学习是指通过构建并结合多个学习器来完成学习任务[10]。其中,每个学习器被称为基学习器。通常情况下,集成学习模型的性能显著优于单一基学习器。现有研究也有将集成学习所学习的知识(例如数据特征、特征权重)辅助用于新的学习器中[11]。集成学习模型的构建主要围绕两个方面,即基学习器和结合策略。
本文选取的基学习器包含DTC、RF、GBDT、XGBoost、CatBoost、SPE和BP。其中DTC属于基本机器学习算法,在集成学习领域中,也称为弱学习器;RF、GBDT、XGBoost、CatBoost和SPE属于集成学习模型,其基学习器主要为DTC;BP属于深度学习模型。各模型的数学原理可参考文献[12-14]。本文对上诉基学习器的损失函数作简单介绍:
1)DTC
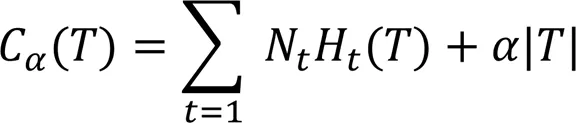
2)RF
RF针对回归和分类任务提出了不同的损失函数。本文只介绍具体涉及的RF分类任务的损失函数:
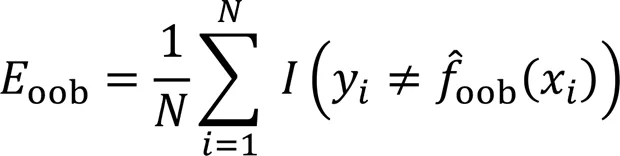
3)GBDT
针对二分类问题,GBDT可采用对数损失函数和指数损失函数。类似RF损失函数,本文只介绍GBDT二分类的对数损失函数:
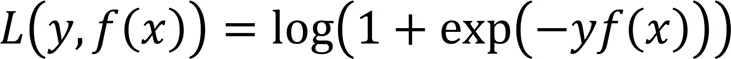
4)XGBoost
针对二分类问题,XGBoost可采用概率损失函数(binary: logistic)和类别损失函数(binary: logitraw)。类似RF损失函数,本文只介绍XGBoost二分类的概率损失函数:
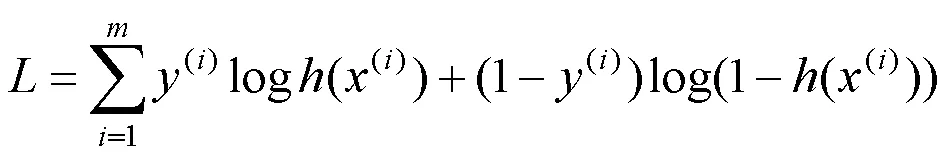
5)CatBoost
针对二分类问题,CatBoost可采用Logloss 、CrossEntropy、MAE等函数作为损失函数。本文介绍CatBoost二分类的Logloss损失函数,其计算方式同式(3)。
6)SPE
针对二分类问题,SPE存在三种常用损失函数,即Absoulte Error、Squared Error和Cross-Entropy。
本文介绍SPE二分类的Cross-Entropy损失函数,计算方式如下:
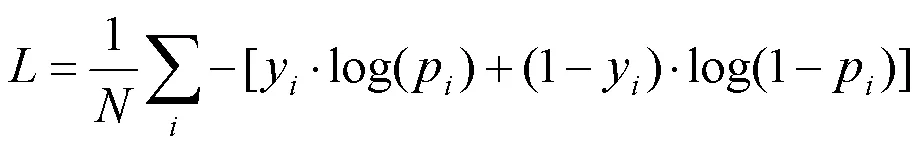
7)BP
1.3 结合策略
集成学习模型的结合策略是指集成模型融合各基学习器预测结果的方式。在分类任务中,集成学习常用的结合策略是投票法。
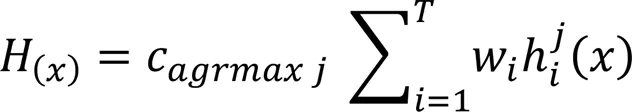
投票法依据基学习器的学习结果分为硬投票和软投票。硬投票是指在集成基学习器学习结果时,基学习器的学习结果是具体的类别标签。软投票是指在集成基学习器学习结果时,基学习器的学习结果是所有类别标签的预测概率。软投票、硬投票也可分别分为多数投票法和加权投票法。我们的结合策略采用软投票结合加权投票法。
2 实验
2.1 实验数据及环境
本文所使用的实验数据为UCI数据库中的数据集“default of credit card clients”。本简称为DCCC数据集。该数据集描述了台湾用户信用卡的违约情况,共有30000例样本,23个数据特征(包含标签),数据特征的类型统一为浮点型。表1展示了部分数据,其中特征“default payment next month”为类别预测标签,取值集合为{1,0},0代表不违约,1代表违约。
本文的编程语言为Python3,操作系统为macOS,深度学习框架为paddlepaddle。
2.2 评价指标
二分类预测任务中常用的评价指标包含精准率(Precision)、召回率(Recall)、F1分数(F1-Score)和准确率(Accuracy)[17]。
表2展示了各个评价指标的计算方法,其中TP、TN、FP、FN分别指分类结果混淆矩阵中的真正例、真反例、假正例,假反例。
表1 部分DCCC数据
Table 1 Partial DCCC data
LIMIT_BALEDUCATIONMARRIAGEAGEPAY_0…default payment next month 02000021242…1 11200002226-1…1 29000022340…0 35000021370…0 4500002157-1…0
表2 二分类评价指标计算方法
Table 2 The calculation methods of binary classification evaluation indexes
评价指标计算方法 Precision Recall F1-Score Accuracy
2.3 对比模型
本文的对比模型为集成模型的7个基学习器。在构建基学习器的时候,通过网格搜索方法(Grid Search)确定各个基学习器中的重要参数,并通过交叉验证(cross validation)的方式训练数据,以提升各基学习器的性能和泛化能力此外,BP神经网络模型不参与网格搜索,因为该模型采用随机梯度下降方法自适应更新参数,我们通过不断增加全链接隐层数目从而寻找最优网络结构的方式达到优化BP神经网络的目的。
为了验证网格搜索和交叉验证优化的有效性,分别采用初始7个基学习器和优化后的7个基学习器对DCCC数据进行训练和预测,并记录F1分数。图2展示了预测结果。从中可以看出,网格搜索和交叉验证对于各基学习器能够带来一定的性能提升,其中以DTC的性能提升最为明显。
2.4 实验结果
表3展示了本文提出的集成模型与各基学习器在DCCC数据集上,进行10次违约预测任务的Precision、Recall、F1-Score和Accuracy评价指标平均得分,其中Ensemble是集成模型。多次实验的目的是缓解基学习器在训练过程中随机性的影响。
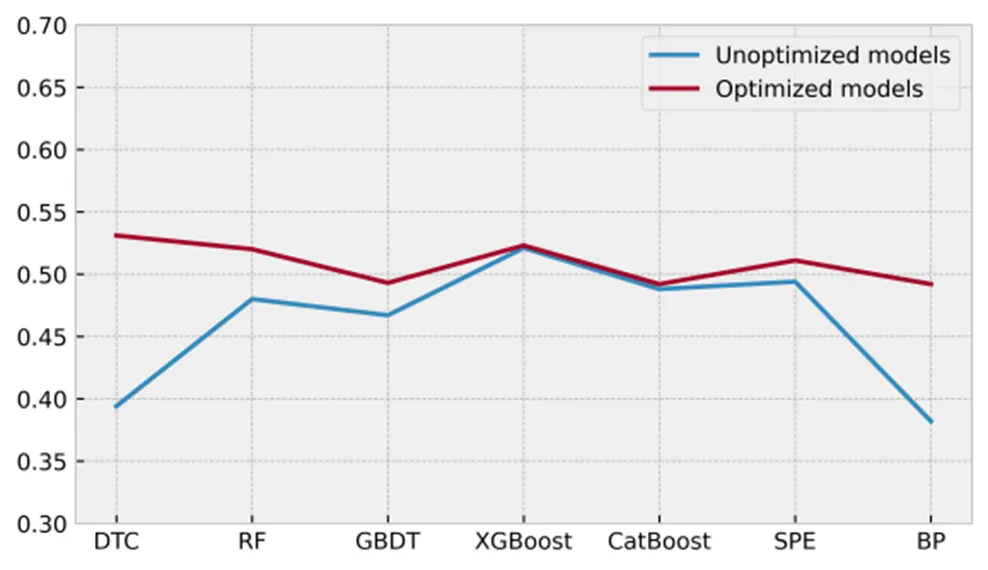
图 2 基学习器优化前后的F1得分
表3 各模型Precision、Recall、F1-Score、Accuracy指标得分
Table 3 Precision, Recall, F1-score and Accuracy scores of each model
模型名称PrecisionRecallF1ScoreAccuracy DTC0.556 0.507 0.531 0.803 RF0.434 0.649 0.520 0.737 GBDT0.678 0.374 0.482 0.824 XGBoost0.591 0.469 0.523 0.812 CatBoost0.692 0.364 0.477 0.825 SPE0.407 0.647 0.500 0.716 BP0.656 0.402 0.499 0.823 Ensemble0.676 0.536 0.598 0.843
2.5 实验结果分析
从表3中可以看出,集成模型虽然在精确率和召回率上的表现不如其某个基学习器,但在F1分数上能取得更好的性能。针对实际场景中用户信用卡的违约预测,F1分数更能体现一个模型的预测效果,更高的F1值意味着模型能够更精确的预测用户是否发生违约,同时模型有着更低的错误率。此外,相较于基学习器,集成模型取得了更高的准确率,直观上来说,这意味着集成模型能够正确预测样本类别的概率更大。
更为重要的是,基学习器由于随机性等不确定因素,在面对不同质量数据集时会有不同的模型性能。我们通过重新随机分配训练集和验证集,从而获得不同的数据集并对各个模型进行评估。图3展示了实验结果,X轴表示不同的训练集和测试集。从图3中可以看出,集成模型的F1值不仅优于各基学习器,同时还更加稳定。这意味着,针对用户信用卡违约预测任务,集成模型不仅能够取得更好的预测效果,而且在面对训练数据波动时,集成模型的性能受影响较小。相比于基学习器F1值的波动,集成模型较为稳定的F1值也能反映模型具有更强的泛化能力。
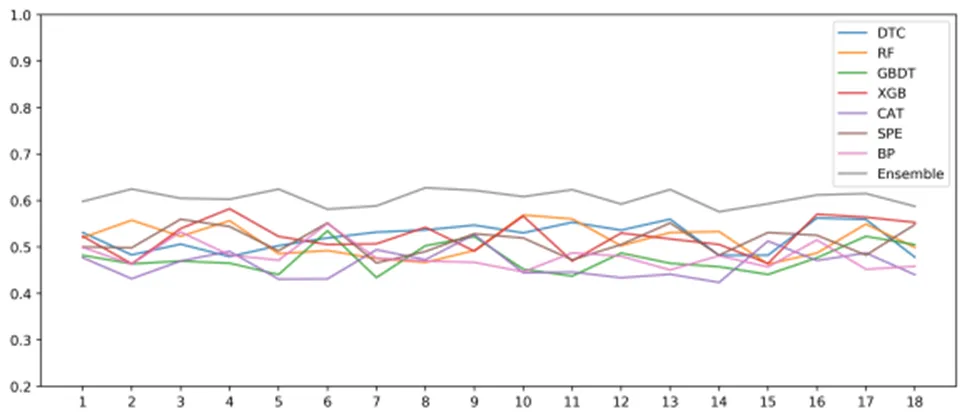
图 3 基学习器和集成模型在不同数据集上的F1得分
3 不足之处和未来展望
3.1 不足之处
基学习器在训练过程中具有一定随机性,在不同的数据上或相同的数据上的性能不一致。我们通过多次实验取得模型性能的平均值来缓解模型随机性的影响,并通过并行计算的方式来减小模型多次训练的时间开销。此外,无论是基学习器还是深度学习模型,模型的解释性较弱。本文采用基于决策树的基学习器和BP神经网络,其优势在于决策树在进行训练时,能够计算数据特征重要程度,进而加强模型的可解释性。
3.2 未来展望
用户信用卡违约预测是信用卡预测的子任务之一,信用卡预测还包含于消费预测、还款预测等任务。本文将在后续的研究中探索信用卡预测多任务学习,通过联合模型针对各项子任务提出一个综合模型,尝试解决信用卡预测多任务学习中的多任务度量和结合问题。
4 结论
用户信用卡违约预测任务是银行监控信用卡风险的有效途径之一。本文提出了一种基于集成学习的用户信用卡违约预测模型,该模型采用集成模型和神经网络作为基学习器,从而达到强化模型整体性能的目的。通过在真实用户信用卡数据集上进行违约预测,相较于基学习器,该集成模型能够取得较高的F1值和准确率,且具有更强的稳定性和泛化能力。此外,我们分析了模型的威胁因素,即模型的随机性和可解释性。
[1] 林国强,赵毅鸣,况青作,等. 基于复杂网络和机器学习的P2P用户违约预测[J]. 北京师范大学学报:自然科学版,2017,53(1): 24-27,2.
[2] Butaru F, Chen Q, Clark B, et al. Risk and risk management in the credit card industry [J]. Journal of Banking & Finance, 2016,72:218-239.
[3] Cai J, Liu X, Wu Y. SVM Learning for default prediction of credit card under differential Privacy [C]. PPML, 2020: 51-53.
[4] 章宁,陈钦.基于TF-IDF算法的P2P贷款违约预测模型[J].计算机应用, 2018, 38(10): 3042-3047.
[5] 马晓君,宋嫣琦,常百舒,等. 基于CatBoost算法的P2P违约预测模型应用研究[J].统计与信息论坛, 2020, 35(7): 9-17.
[6] Chen Y, Zhang R. Research on credit card default prediction based on k-Means SMOTE and BP neural network [J]. Complex, 6618841:1-13.
[7] 杨磊,姚汝婧.基于Transformer的信用卡违约预测模型研究[J].计算机仿真, 2021, 38(8): 440-444.
[8] Kim E, Lee J, Shin H, et al. Champion-challenger analysis for credit card fraud detection: Hybrid ensemble and deep learning [J]. Expert Syst Appl, 2019, 128: 214-224.
[9] Brumen B, Cernezel A, Bosnjak L. Overview of machine learning process modelling [J]. Entropy, 2021, 23(9): 1123.
[10] Wang G, Song Q, Zhu X. Ensemble learning based classification algorithm recommendation [C]. CoRR, 2021, abs/2101.05993.
[11] Zhao C,Wu D,Huang J,et al. Boost tree and boost forest for ensemble learning [J].CoRR,2020,abs/2003.09737.
[12] 陈凯,朱钰. 机器学习及其相关算法综述[J].统计与信息论坛,2007(5): 105-112.
[13] Wang H, Hong M, Hong Z. Research on BP neural network recommendation model fusing user reviews and ratings [J]. IEEE Access, 2021, 9: 86728-86738.
[14] Liu Z, Cao W, Gao Z, et al. Self-paced ensemble for highly imbalanced massive data classification[C]. CoRR,2019, abs/1909.03500.
[15] 周志华.机器学习[M].北京:清华大学出版社,2016.
[16] Breiman L. Random forests[J]. Mach Learn, 2001, 45(1):5-32.
[17] Ben-Yishai A, Ordentlich O. Constructing multiclass classifiers using binary classifiers under log-loss[C]. CoRR,2021, abs/2102.08184.
A CREDIT CARD DEFAULT PREDICTION MODEL BASED ON ENSEMBLE LEARNING
*ZHOU Wan, WANG Yong
(School of Computer and Information, Anhui University of Technology, Wuhu, Anhui 241000, China)
The user credit card default prediction can help banks and other financial institutions to balance economic risks and interests, and play an important role in risk control of bank credit card business. Aiming at the problem of credit card default prediction, a credit card default prediction model based on ensemble learning was proposed. Being different from the weak learner in the traditional ensemble learning, the ensemble model and the neural network were adopted as the base learners in this model, so as to improve the prediction effect of the ensemble model. Specifically, the relevant features of the user credit card data by pre-processing were extracted. Then the optimized decision tree, random forest, GBDT, XGBoost, CatBoost and SPE and neural network models were adopted to train data and predict results. Finally, the combined strategy (i.e., the weighted soft voting) was used to integrate the results of the base learners and output the final prediction results. It showed that compared with the base learners, the prediction model had improved in all evaluation indicators and had better model generalization ability.
default prediction; ensemble learning; machine learning; neural network
1674-8085(2022)04-0051-06
TP311.05
A
10.3969/j.issn.1674-8085.2022.04.008
2021-12-13;
2022-01-28
国家自然科学基金面上项目(61976005);安徽自然科学基金面上项目(1908085MF183);计算机软件新技术国家重点实验室(南京大学)开放基金项目(KFKT2019B23)
*周 芄(1997-),男,安徽池州人,硕士生,主要从事机器学习、NLP研究(E-mail:wanzi_hyl@icloud.com).
猜你喜欢
黄河之声(2022年10期)2022-09-27
舰船科学技术(2022年11期)2022-07-15
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化·高二版(2022年4期)2022-05-09
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
时代金融(2018年22期)2018-10-09
软件(2017年6期)2017-09-23
瞭望东方周刊(2017年35期)2017-09-22
