
Modelling an Efficient Clinical Decision Support System for Heart Disease Prediction Using Learning and Optimization Approaches
2022-07-04 05:41SridharanKannan
Sridharan Kannan
Department of Computer Science and Engineering,J K K Munirajah College of Technology,Erode,638506,India
ABSTRACT With the worldwide analysis,heart disease is considered a significant threat and extensively increases the mortality rate.Thus,the investigators mitigate to predict the occurrence of heart disease in an earlier stage using the design of a better Clinical Decision Support System(CDSS).Generally,CDSS is used to predict the individuals’heart disease and periodically update the condition of the patients.This research proposes a novel heart disease prediction system with CDSS composed of a clustering model for noise removal to predict and eliminate outliers.Here,the Synthetic Over-sampling prediction model is integrated with the cluster concept to balance the training data and the Adaboost classifier model is used to predict heart disease.Then,the optimization is achieved using the Adam Optimizer(AO)model with the publicly available dataset known as the Stalog dataset.This flow is used to construct the model,and the evaluation is done with various prevailing approaches like Decision tree,Random Forest,Logistic Regression,Naive Bayes and so on.The statistical analysis is done with the Wilcoxon rank-sum method for extracting the p-value of the model.The observed results show that the proposed model outperforms the various existing approaches and attains efficient prediction accuracy.This model helps physicians make better decisions during complex conditions and diagnose the disease at an earlier stage.Thus,the earlier treatment process helps to eliminate the death rate.Here,simulation is done with MATLAB 2016b,and metrics like accuracy,precision-recall,F-measure,p-value,ROC are analyzed to show the significance of the model.
KEYWORDS Heart disease;clinical decision support system;over-sampling;AdaBoost classifier;adam optimizer;Wilcoxon ranking model
1 Introduction
Globally,42 million premature deaths are encountered annually due to non-communicable diseases reported by World Health Organization(WHO),i.e.,roughly 72%.The total count of the non-communicable disease-based death reaches 52.1 million annually by 2030[1–3]when these diseases are un-mitigated.Some general non-communicable conditions are hypertension and diabetes,about 46% of the total death rate.Type II diabetes occurs due to constant metabolic disorder that shows variation in blood glucose levels.It is generally a significant cause of the human’s ineffectiveness to adopt its own produced insulin.Likely,individuals are supposed to have diabetes with higher chances and risk of mortality and stroke[4].However,constant monitoring of blood glucose levels can appropriately mitigate or prevent the complications of diabetes.In most developing countries,huge people have diabetes,and the diabetic rate will increase gradually from 84 to 229 million approximately by 2030 and burden the healthcare system significantly.Moreover,hypertension is a harmful condition where blood flows through blood vessels like arteries and veins at raised pressure.Globally,it is noted that one in three adults show increased blood pressure,and it is depicted as the root cause of mortality rate[5].Roughly 640 million adults suffer from hypertension in developing countries and reach about 1 billion adults in 2025.
Various recent researches have adopted Machine Learning(ML)models as a decision-support system as the growing awareness of hypertension and diabetes risks for earlier prediction of the disease[6].It produces higher accuracy in predicting hypertension and diabetes based on patients’present situation and therefore helps them take necessary actions earlier.Alam et al.[7]demonstrated ensemble model is a common ML approach that merges the outcomes from various classification models and proves that the anticipated model shows superior performance compared to various standard approaches[8].Various other approaches have successfully adopted ensemble models to assist medical-based medical decision-based support systems and predict diabetes.In the ML field,various confronting issues arise,like imbalanced datasets and outlier data that cause the reduction of models’prediction accuracy[9,10].Some approaches demonstrate adopting an isolated forest model to avoid outlier data and using the Synthetic Minority Over-sampling Technique(SMOTE)to balance the Not-A-Number(NaN)value and imbalanced data computation performance the ML approach is improved substantially.
However,none of the previous research works has integrated the characteristics of SMOTE with ML classifier and optimizer models to enhance the prediction accuracy of the model,specifically over hypertension and Type II diabetes datasets.Thus,this research concentrates on modelling and efficient decision-support systems using ML classification and optimization for predicting hypertension and Type II diabetes using individual risk factor data[11,12].Here,Statlog UCI ML-based heart dataset is used for predicting(hypertension and Type-II diabetes)to measure the performance of the anticipated model.Some researchers concentrate on modelling IoT-based mobile applications for the healthcare system to offer superior proficiency over disease prediction and their suitable way for validating the present health condition via the mobile applications[13,14].But,this work does not perform any form of mobile-based analysis to reduce the preliminary complexity[15].The reason behind the avoidance of the mobile application is to eliminate the computational complexity and improve cost-efficiency.However,future research intends to include this idea to take necessary and immediate action to diminish and eliminate the individual risk during the unexpected worsening condition of health,i.e.,higher BP and triggered diabetes level.
·The proposed decision support system model includes four major parts:1)statlog dataset acquisition;2)pre-processing with SMOTE;3)classification with Adaboost classifier model;and 4)Adam Optimizer to attain a global solution.These methods adapt their way to predict the disease in the earlier stage to help the individual.The significant research contributions are given below.
·Generally,SMOTE technique is applied in the ML algorithm as the newly constructed instances are not the actual copies.Therefore,it softens the decision-support boundaries and helps the algorithm for hypothesis approximation more accurately.Also,it reduces the Mean Absolute Error(MAE)and gives better prediction accuracy.
·Here,the Adaboost Classifier model is adopted as it is a best-suited boosting algorithm.The AdaBoost model’s significant benefits are reducing the generalization error,more straightforward implementation of the algorithm,and a broader range of classifier adaptability with no parameter adjustment.However,the classifier model needs to be provided with massive care as the algorithm is more sensitive to data outliers.
·Finally,the Adam Optimizer(AO)is used for this research as the model works well with the sparse gradients,noisy data,significant dataset parameters,and it needs lesser memory space.This optimizer model is well-known for its computational efficiency and more straightforward implementation.
·The simulation is done in the MATLAB 2018a environment.Various performance metrics like prediction accuracy,sensitivity,specificity,and execution time are evaluated to show the model’s significance and improve prediction accuracy.
The proposed decision support system model includes four major parts:1)statlog dataset acquisition;2)pre-processing with SMOTE;3)classification with Adaboost classifier model;and 4)Adam Optimizer to attain a global solution.These methods adapt their way to predict the disease in the earlier stage to help the individual.Generally,SMOTE technique is applied in the ML algorithm as the newly constructed instances are not the actual copies.Therefore,it softens the decision-support boundaries and helps the algorithm for hypothesis approximation more accurately.Also,it reduces the Mean Absolute Error(MAE)and gives better prediction accuracy.Here,the Adaboost Classifier model is adopted as it is a best-suited boosting algorithm.The AdaBoost model’s significant benefits are reducing the generalization error,more straightforward implementation of the algorithm,and a broader range of classifier adaptability with no parameter adjustment.However,the classifier model needs to be provided with massive care as the algorithm is more sensitive to data outliers.Finally,the Adam Optimizer(AO)is used for this research as the model works well with the sparse gradients,noisy data,significant dataset parameters,and it needs lesser memory space.This optimizer model is well-known for its computational efficiency and more straightforward implementation.The simulation is done in the MATLAB 2018a environment.Various performance metrics like prediction accuracy,sensitivity,specificity,and execution time are evaluated to show the model’s significance and improve prediction accuracy.
The work is structured as Section 2 summarises various existing approaches used to predict the disease and its pros and cons.Section 3 gives the ideology of the anticipated model that includes dataset acquisition,SMOTE technique,Adaboost classifier and Adam optimizer for enhancing the prediction rate.Section 4 discusses the performance evaluation outcomes with the analysis of various metrics to balance the data.Section 5 gives the summarization of the research work with research constraints and ideas for future research improvements.
2 Related Works
Generally,medical data is composed of various relevant features and categorized based on its usefulness,i.e.,less practical and not useful features(redundant features)based on its progression and formulation of diverse practice measurements.The predictions of these attributes are essential for representing the proximity of the domain appropriately[16].The labelling process is a nontrivial task as the specification of the prediction column is not influenced by the irrelevant features.The appropriate evaluation of maximal influencing elements affects the classification process,and the dataset size is reduced by eliminating redundant features.Some specific features are chosen to extract the sub-group of the most influencing features from all these clustered features.This section discusses two sub-sections of the recent research works.The first section discusses the feature selection techniques and discusses heart disease prediction techniques.Usually,feature selection approaches are employed to predict heart disease risk,and the prediction models on the same dataset without feature selection approaches are laid out.Various datasets are involved in the heart disease prediction process like statlog,Hungarian,and Cleveland that are accessible in the repository of the UCI ML.Some investigators consider the Switzerland heart dataset from those available repositories and include it with the aforementioned datasets.
2.1 Reviews on Feature Selection Techniques
In this review section,some notable researches are performed for predicting the disease risk using the Cleveland heart dataset from the UCI ML repository.Avci[17]adopted an improved decision tree with four diverse features and attained 76% prediction accuracy.Also,the author uses the C4.5 tree model and attained 79% accuracy with five influencing features.Bakar et al.[18]used a Fuzzy-based decision support system(FDSS)with rule-based weighted fuzzy models from adaptive GN.The author retrieved eight significant features and attained 82% accuracy.Sujatha et al.[19]established the PI-sigma model and designed a multi-layer Pi-sigma neuron model for predicting heart disease.The proposed idea is provided for the k-fold validation method where‘k’is set as 5.The author selects four diverse attributes adjacent to the hyperplane of the SVM and Linear Discriminant Analysis approach and attains 89% accuracy.However,Taser et al.[20]noticed that adopting the DM voting technique and selecting nine diverse features are considered and merged with logistic regression and the naïve Bayes method.Also,the author adopts SVM,k-NN,NN and decision tree classifiers for the same dataset model.
With Tun et al.[21]perspective,two variants of modern algorithms are employed for feature selection like uni-variate and relief model are used for key feature sorting.The author uses SVM,DT,RF,MLP,and LR algorithms without feature selection.Here,hyper-parameters and crossvalidation are tuned and validated to improve disease risk prediction accuracy.The author attains roughly 89% prediction accuracy with seven diverse features achieved using the univariate and LR feature selection approach.Also,he attained 90% accuracy with LR and the same number of features with the Relief-based feature selection approach.Rubino[22]adopted ensemble-based classification and integrate manifold classifier model with classifier models like Bayesian network,NB,MLP,and RF and later uses feature selection approach to improve the prediction accuracy.The outcomes are reformatory by adopting a majority voting model with MLP,RF,BN,and NB and attain the highest accuracy of about 86%.Heo et al.[23]discusses a modern ML intelligence framework and perform mixed data factor analysis for extracting and deriving features from the heart disease dataset for training the ML prediction model.The framework attains 92% and an AUC of 92.61% for ten various features and the proposed classifier model.
2.2 Reviews on Heart Disease Prediction Techniques
Singh et al.[24]performed arrhythmia data classification using the least-square twin SVM model,structural twin SVM model,structural least-square twin SVM model,and various structural data proofs and attain 88% prediction accuracy without performing feature selection over the online available Cleveland heart disease UCI ML dataset.Domingues et al.[25]anticipated a novel CDSS employing C5.0 and RF classifier model.Using C5.0,various rules are generated,and 91% prediction accuracy is attained with this system.Alfian et al.[26]used a bi-model Fuzzybased analytic hierarchical process to legitimize the risky elements over the dataset using statistical data and provide the Bayesian formula’s fuzzy rules.The anticipated model attains 87% accuracy.Yousefian et al.[27]used a clustering-based hybrid sampling technique and requires minimal sampling time.A confidence measurement-based approach is used to evaluate the testing set and attain 78% prediction accuracy.Harliman et al.[28]anticipated a novel hybridization approach using ANN and DT model to achieve 78% and 79% prediction accuracy.Here,a 10-fold CV is used to substantiate the outcomes,and the experimental analysis is performed using WEKA.Also,the author noticed the functionality of the hybrid DT model,which outperforms the ANN algorithm during the prediction of heart ailment risk.Goel et al.[29]evaluated a novel nested ensemble model using a support vector classification approach for heart disease prediction.The proposed model relies on the conventional ML and ensemble classification approach.Prediction accuracy of 85% is attained with the sigmoid support vectors and conventional ML approaches.Calheiros et al.[30]employed a hybrid RF with a linearity model and achieve a prediction accuracy of 89% using the ML classifier model to predict heart disease risk.The author uses GA algorithm,re-sampling and class-balancer methods are used for balancing the dataset[31].Then,sigmoid,linear,polynomial,and radial basis kernel functions are integrated with some base algorithms.However,the model fails to work effectually in heart disease prediction Freund et al.[32]commenced χ2statistical model for addressing the feature refinement and problem eradication issues during the heart disease prediction model,i.e.,problems of over-fitting and under-fitting.Here,a novel DNN is used for the specific search purpose and attains a[33]prediction accuracy of 92%,respectively.Atiqur et al.[34]discussed performance analysis using PCA algorithm for heart disease prediction and attains a prediction accuracy of 91.11%.The author adopts various feature extraction algorithms to perform heart failure classification.Liaqat et al.[35]discussed a linear SVM model for heart disease prediction and attains a prediction accuracy of 92.22%.The model intends to eliminate irrelevant features by reducing the coefficients to zero.Liaqat et al.[36]anticipated an automated diagnostic system for heart disease prediction using theχ2 model.The author acquires 93.33% prediction accuracy compared to various other approaches.Ali et al.[37]gave an approach based on mutually informed NN to optimize the generalization capabilities of DSS for heart disease prediction and attain a prediction accuracy of 93.33%.Table 1 depicts the comparison of prediction accuracy of various prevailing approaches using the statlog dataset.
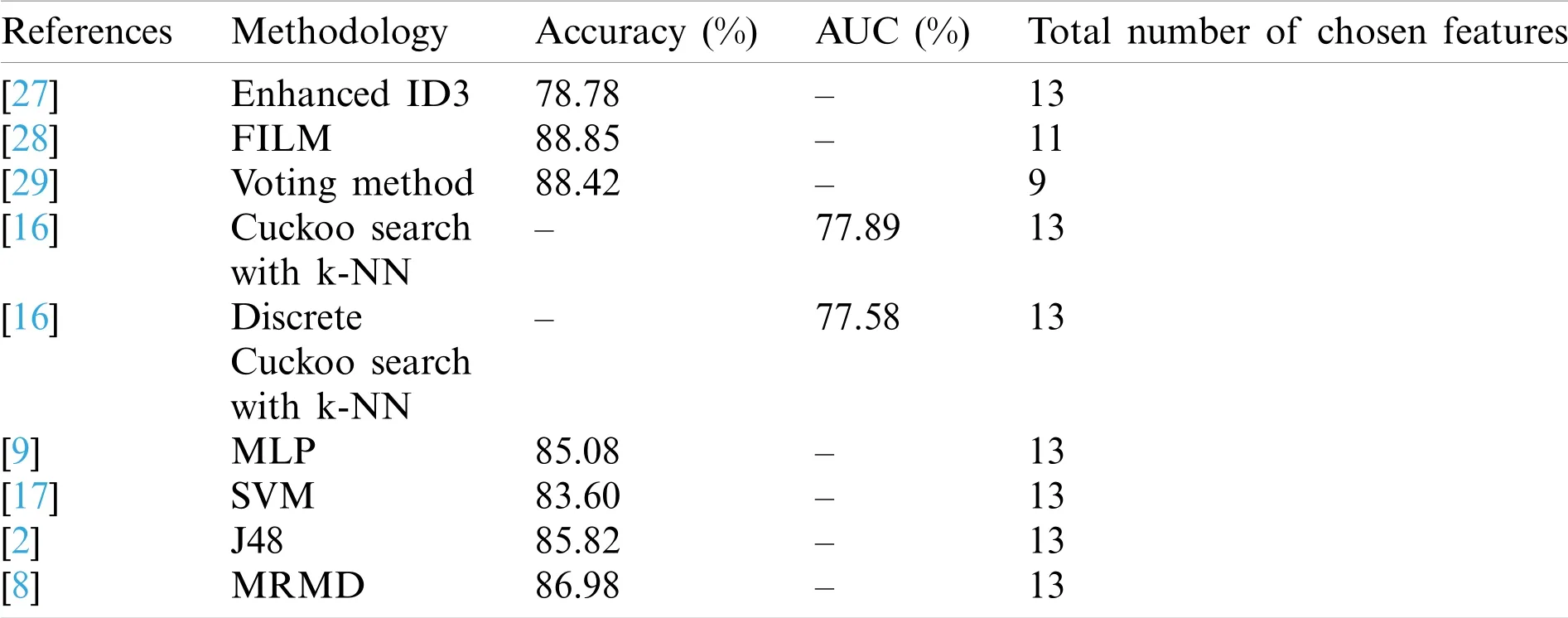
Table 1:Comparison of various existing approaches using statlog dataset
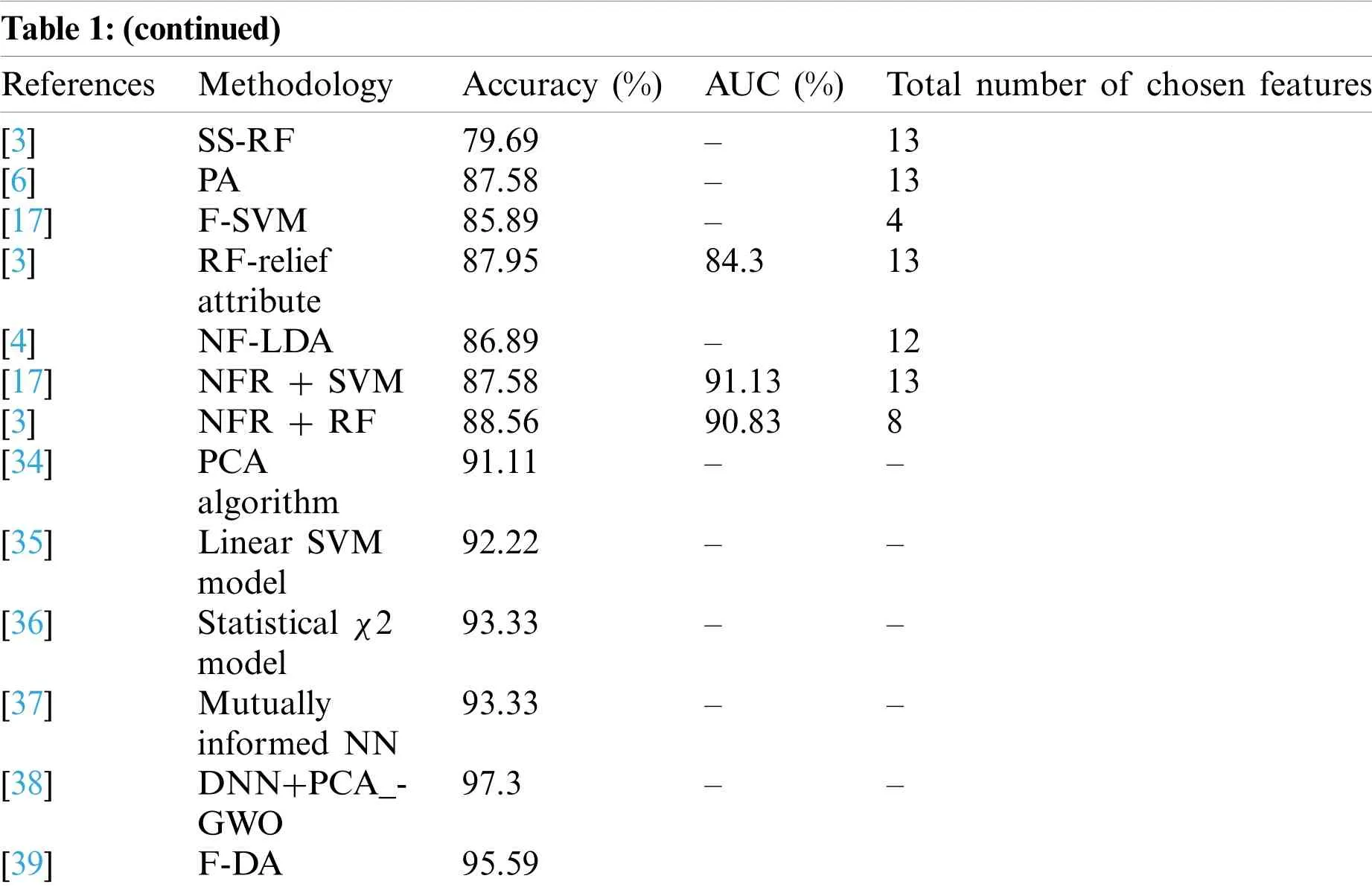
Table 1:(continued)References MethodologyAccuracy(%)AUC(%)Total number of chosen features[3]SS-RF79.69–13[6]PA87.58–13[17]F-SVM85.89–4[3]RF-relief attribute 87.9584.313[4]NF-LDA86.89–12[17]NFR + SVM87.5891.1313[3]NFR + RF88.5690.838[34]PCA algorithm 91.11––[35]Linear SVM model 92.22––[36]Statistical χ2 model 93.33––[37]Mutually informed NN 93.33––[38]DNN+PCA_-GWO 97.3––[39]F-DA95.59
3 Methodology
This section discusses three phases of the proposed flow:data pre-processing,classification,and optimization.Here,the SMOTE technique pre-processes the missing data and handles the imbalanced data problem encountered in the statlog dataset.Moreover,the Adaboost-based classifier model is adopted to perform disease classification and evaluate the model’s outcome.This work aims to classify the class labels and optimize the values to attain better results.
3.1 In Dataset Description
Starlog dataset is a heart disease dataset like another dataset available in the UCI Machine Learning(ML)repository but shows some slight difference in its form.Table 2 depicts the statlog dataset attributes.

Table 2:Starlog dataset attributes
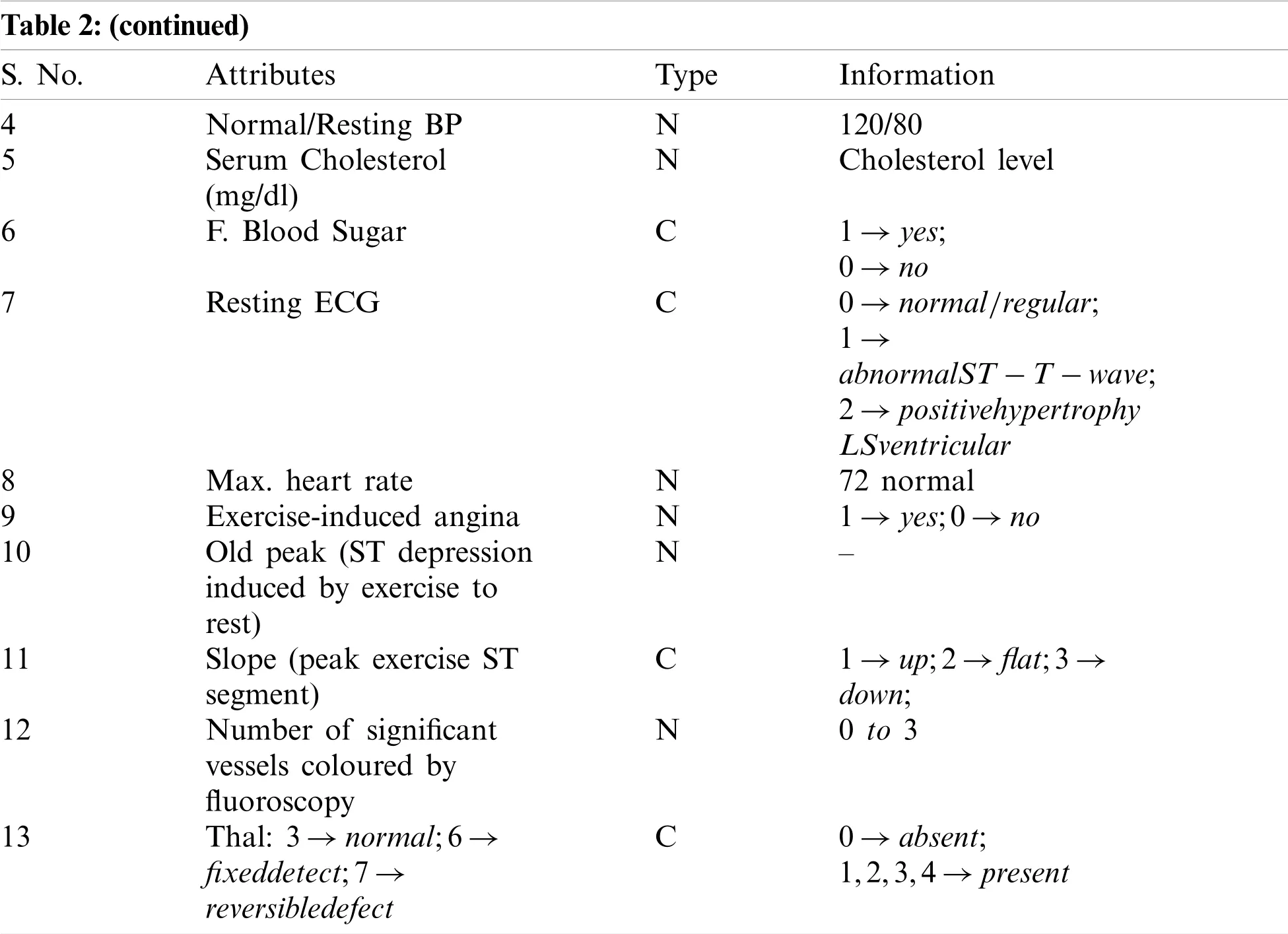
Note:Here,‘N’is numeric,and‘C’is categorical.
3.2 SMOTE Technique
The provided statlog dataset comprises various positive and negative classes where positive is specified as 1,and negative class is defined as 0.However,there is an uneven distribution of classes over the dataset,and these uneven distributions are depicted as the foremost cause of the reducing prediction accuracy in the classifier model.The significant cause is that most ML algorithms do not drastically learn about the pattern for all the positive and negative classes due to the imbalanced dataset.However,negative classes are considered as the minority class with a smaller amount of instances.Therefore,the outcomes generated using the proposed classifier model for a class definition is often more inefficient.Various existing approaches do not consider this minority class as the major flaw in attaining classification outcomes.The key contribution of this pre-processing step is to deal with the imbalanced instances of the provided statlog dataset and handle this issue efficiently using SMOTE approach.Moreover,the outcomes for the minority and majority classes are separately documented to compute the class performance in generating overall classification outcomes.
The author describes that SMOTE is a prominent approach adopted for the classifier construction with the imbalance dataset.This imbalanced dataset is composed of uneven distribution of underlying output classes.It is most commonly used in classification issues of the imbalanced dataset.The handling of uneven instances is a pre-processing technique and a reliable approach.With the origin of the SMOTE approach,there are diverse SMOTE variants deployed and proposed to improve the general SMOTE approach with efficient adaptability and reliability under various situations.It is depicted as the most innovative pre-processing approach in information mining and the ML domain.This approach aims to adopt interpolation with data of minor class instances,and therefore the numbers are improved.It is essential to attain classifier generalization and most extensively adopted to cater to the problems raised due to the imbalanced classification instances over the statlog dataset.Generally,the minority classes are oversamples with the production of various artificial models.The minority class-based feature space is adopted for the construction of these samples.Based on the classification and sampling requirements,the number of neighbours is selected.Lines are constructed with the minority class data points utilizing the neighbours and most efficiently used while handling the imbalanced datasets.It pretends to equalize the minority and majority class instances during the sample training process.A novel imblearn library is utilized for the SMOTE implementation to handle the imbalanced dataset.
Fig.1 depicts the generic flow of the experimentation where the provided statlog dataset is processed to eradicate the null values.However,SMOTE approaches are provided to the statlog dataset in this research.Therefore,an equal amount of negative and positive samples are attained.However,the final phase provides diverse ML approaches over the given dataset,achieving the corresponding outcomes.Generally,k-fold CV is applied to the dataset to fulfil the reliability of the results.Fig.1 depicts the workflow of the anticipated experiment.
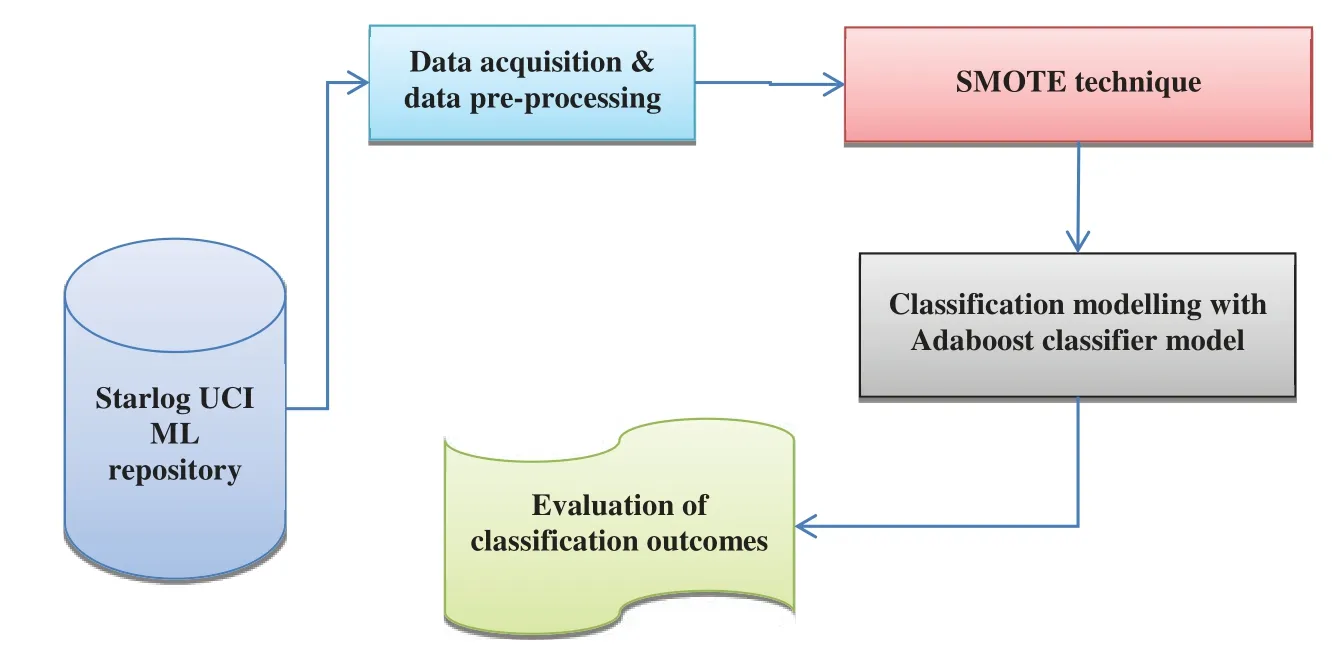
Figure 1:Workflow of the proposed experiment
3.3 Adaboost Classifier(AB)
Adaboosting helps in boosting the performance of the weak learner and improves the learning performance.Adaboosting is connected with the bagging and bootstrap model,and it is conceptually diverse from others.Generally,bagging is aggregation and bootstrapping,while bootstrap performs a specific sample-based statistical approach where the samples are randomly drawn with replacement.Here,three diverse methods are constructed with random sampling,and others are sampling with replacements.The general factors between these two approaches are depicted as a practical voting approach and the classifier model is more popular with the most satisfactory performance.It is experimentally proven that these model gains superior performance and are determined as the best classifier model.The classification process of this classifier is based on the combination of learning outputs of the provided weak classifiers,and it is mathematically expressed as in Eq.(1):

Here,H(x)is the output of the weak classifier,∝nis classifier weight.The preliminary idea behind this algorithm is to sequentially train all the classifiers and update weight vectors based on training set pattern accuracy among the present and previous classifiers.The weighted vectors are decreased or increased based on the decreasing or improving misclassified patterns among the iterations.The weight quality in increment and decrement Δ(x)is based on the error percentage among the present and previous patterns.This research adopts modest Adaptive boosting with lower generalization error compared to other forms of adaptive boosting algorithms.The algorithm for this classifier model is shown in Algorithm 1:

Algorithm 1:Modest Adaptive Boosting Algorithm Input: Z={z1,z2,...,zN} with zk=(xk,yk) where k=1,2,...,N as training set,M=no.ofclassifiers.Output:prediction accuracy based on H(x)1.Initialize weighted values as wi →1N for all i∈{1,2,..,N}where wi is determined as weighted value.2.For all m=1 →M;Hm/=0;3.begin the process 4.Train the classifiers Hm(x) using wi;5.Perform inverse distribution using Eq.(2):wi=(1-wi);normalize∑i wi=1;(2)6.Compute probability values using Eqs.(3)–(6):P+1 m=Pw(y=+1,H(x));(3)P+1 m=Pw(y=+1,H(x));(4)P-1 m=Pw(y=-1,H(x));(5)P-1 m=Pw(y=-1,H(x));(6)7.Update classifier Hm(x)=(P+1m(1-P+1m -P-1m(1-P-1m ));8.Update the weighted value wi=wi exp(-yiHm(xi)) and normalize ∑i wi=1;9.End process;10.Evaluate the classifier output using Eq.(7):H(x)=images/BZ_133_677_2533_708_2579.pngsgn(∑Mm=1 Hm(x))=images/BZ_133_1141_2533_1172_2579.png+1 for∑Mm=1 Hm(x)≥0-1 for∑Mm=1 Hm(x)<0images/BZ_133_1678_2533_1709_2579.png(7)
3.4 Adam Optimizer(AO)
Adam Optimizer is used to handle the noisy problem and used to optimize the classifier model.Adam optimizer is known as a replacement optimization algorithm for training deep learning models.It merges the best properties of RMSprop and AdaGrad algorithms to enhance the optimization algorithm that handles sparse gradients over noisy problems.The main objective of integrating Adam Optimizer with AdaBoost is that Adaboost has some drawbacks,i.e.,vulnerable to a constant noise(empirical evidence).Some weak classifiers turn to be weaker because of low margins and over-fitting issues.Thus,it helps to boost the weak classifier performance and works effectually over the large dataset and is computationally efficient.Adam is a well-known algorithm used in the Deep Learning(DL)field as it acquires better outcomes faster.Adam optimizer outcomes work well in real-time applications,and also it is one of the finest techniques among other stochastic optimization techniques.Adam optimization is an alternative to commonly used Stochastic Gradient Descent(SGD)for iteratively updating NN weights based on training data.The optimizer functionality of stochastic Gradient is different from conventional optimizer because it applies the learning rate of alpha for the overall weight updation.This updation is performed during the learning process.The learning rate is preserved for all network weights and adapted during the learning process separately.It integrates the benefit of two stochastic gradient descents as:
Adaptive Gradient:Learning rate is preserved for all attribute values with improved gradient descent performance.
Root Mean Square(RMS)propagation:The learning rate is maintained for all attributes;however,it is based on the average magnitudes of gradients for weight.The algorithm for Adam Optimizer is clearly described in Algorithm 2.
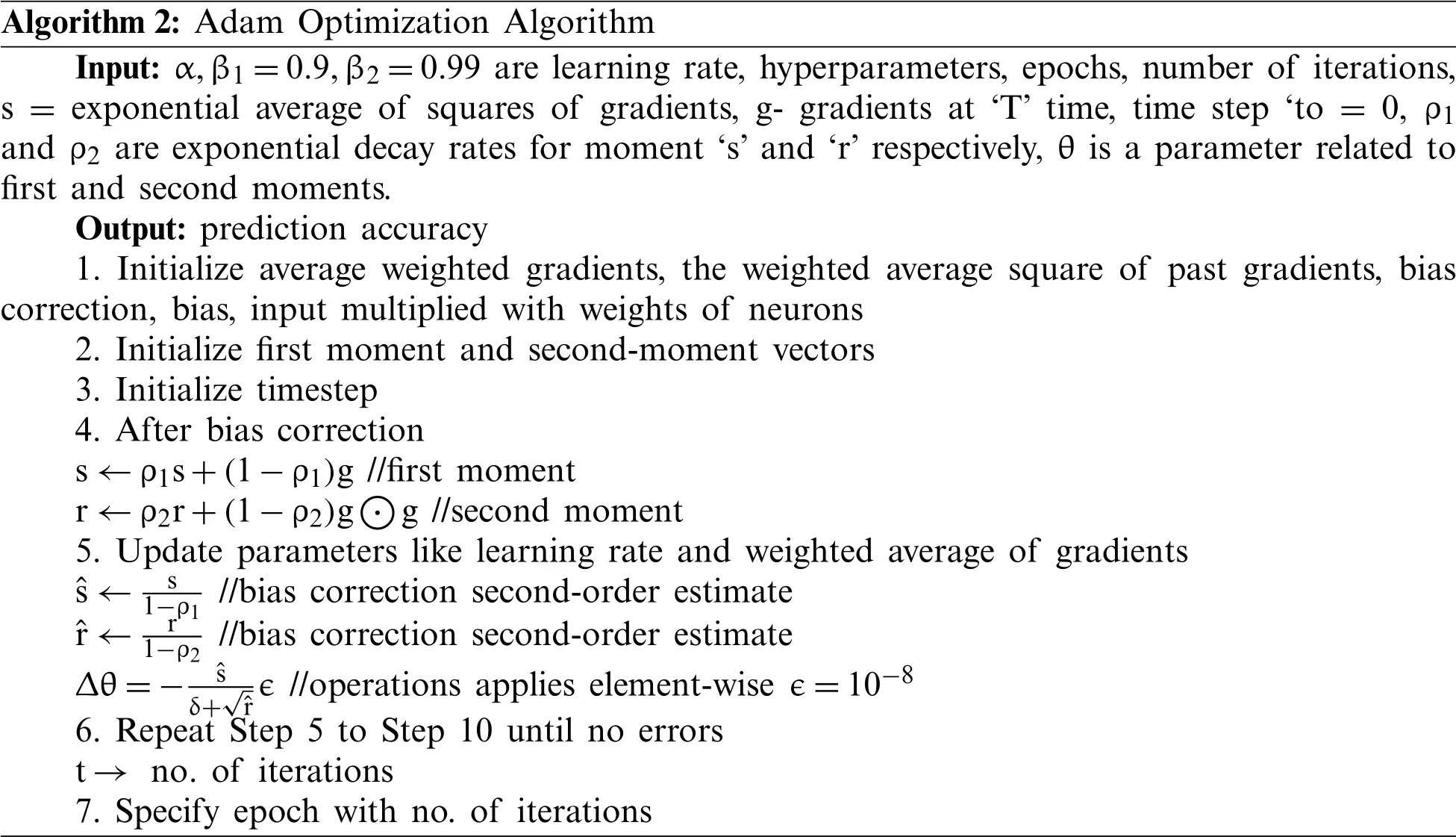
Algorithm 2:Adam Optimization Algorithm Input:α,β1=0.9,β2=0.99 are learning rate,hyperparameters,epochs,number of iterations,s=exponential average of squares of gradients,g- gradients at ‘T’time,time step ‘to=0,ρ1 and ρ2 are exponential decay rates for moment ‘s’and ‘r’respectively,θ is a parameter related to first and second moments.Output:prediction accuracy 1.Initialize average weighted gradients,the weighted average square of past gradients,bias correction,bias,input multiplied with weights of neurons 2.Initialize first moment and second-moment vectors 3.Initialize timestep 4.After bias correction s ←ρ1s+(1-ρ1)g //first moment r ←ρ2r+(1-ρ2)gimages/BZ_134_743_2358_794_2404.pngg //second moment 5.Update parameters like learning rate and weighted average of gradients ˆs ← s 1-ρ1 //bias correction second-order estimate ˆr ← r 1-ρ2 //bias correction second-order estimate Δθ=- ˆs δ+ˆr∈//operations applies element-wise ∈=10-8 6.Repeat Step 5 to Step 10 until no errors t →no.of iterations 7.Specify epoch with no.of iterations
The optimized Adam output is expressed by Eq.(8):

where ‘x’-input parameters,i.e.,input parameters needed for predicting brain tumour(tumour or non-tumour class).‘w′-weights that are varied for iterations.To improve the accuracy,‘b’-bias is added to nodes of NN where the learning rate is unique for all weights.Therefore,bias and weights are updated with the use of AO.It is utilized for updating the bias and weights of the network model used.Updated values are multiplied with given input parameters and classifier functions like ReLU,used for performing classification.The bias and weights are iteratively updated until the model acquires better classification accuracy.
4 Result and Discussion
The experimentation is done over the provided statlog dataset,and the associated outcomes are attained.The simulation is done in MATLAB 2018b environment and intends to free the results from biases.Classification needs to be achieved efficiently by balancing the instances with SMOTE technique.Pre-processing is performed over the raw data and later fed into the ML approaches,and the outcomes are evaluated and compared with various existing approaches.The major constraint with the evaluation of the ML approach is that the dataset needs to validate the same evaluation metrics like prediction accuracy,which leads to misleading outcomes due to the uneven distribution of the samples.The system weakness is measured with the uneven sample distribution.The predicted values are not measured as the true value with the missing samples.Most of the general approaches concentrate on the UCI ML dataset for accuracy evaluation.Standard evaluation metrics like accuracy,specificity,sensitivity,AUROC,F1-score and execution time compute the anticipated model.Generally,accuracy is measured as the ratio of proper predictions to the total amount of inputs.The confusion matrices are modelled with the evaluation of True Positive(TP),False Positive(FP),True Negative(TN)and False Negative(FN),respectively.
Similarly,specificity and sensitivity are computed with FP/(FP+TN)and TP/(FN+TP),respectively.AUROC is another metric used for the evaluation of the classification accuracy of the provided model.Some special constraints are given for the evaluation of minor dataset samples.It is performed with the validation of accuracy measures.The experimentation is done with the Adaboost classifier model and SMOTE technique,outperforming the existing approaches.The methods include Linear Regression(LR),Random Forest(RF),Lightweight Gradient Boosting Machine approach(L-GBM),Support Vector Machine(SVM),Boosted Regression Tree and ensemble model,respectively.The evaluation is done with other datasets like Cleveland and the UCI Machine Learning repository(see Figs.2–12).The accuracy of the AB-AO model is 90.15%without feature selection which is 3.9%,9.17%,5.43%,9.17%,10.28%,and 2.59% higher than LR,RF,L-GBM,SVM,BRT,and an ensemble model.The prediction accuracy after feature selection is 95.87% which is 3.33%,8%,88.98%,86.76%,8%,and 2.73% higher than other models.The sensitivity is 91% which is 17%,14%,20%,17%,6%,and 1% higher than other models.The specificity of AB-AO is 94% which is 24%,26%,23%,22%,5%,and 2% higher than other approaches.The F1-score is 20% which is 6%,7%,6%,6%,5% and 4% higher than other models.The Cleveland dataset consists of 13 features where LR selects 10 features,RF selects 9 features,L-GBM selects 11 features,SVM selects 7 features,BRT selects 12 features,and an ensemble model selects 8 features.The execution time(min)of all these models are 0.10,0.10,0.78,6.80,1.100,0.06 and 0.04 for Linear Regression(LR),Random Forest(RF),Lightweight Gradient Boosting Machine approach(L-GBM),Support Vector Machine(SVM),Boosted Regression Tree,ensemble model and AB-AO model,respectively.The AUROC of AB-AO is 96.78% which is 3.92%,4.42%,2.92%,5.38%,4.46% and 0.89% higher than other approaches.
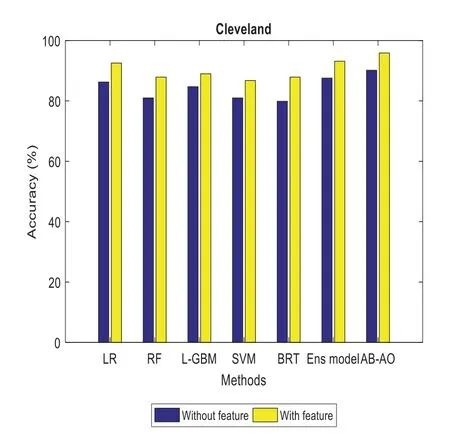
Figure 2:Accuracy computation in cleveland dataset
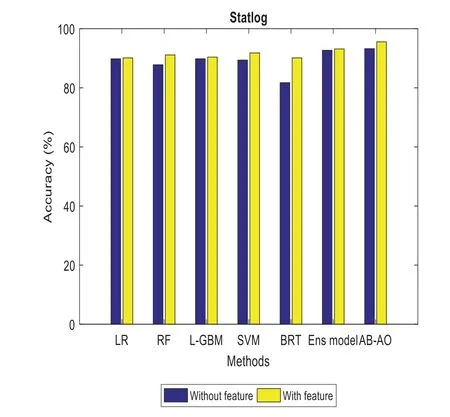
Figure 3:Accuracy computation in statlog dataset
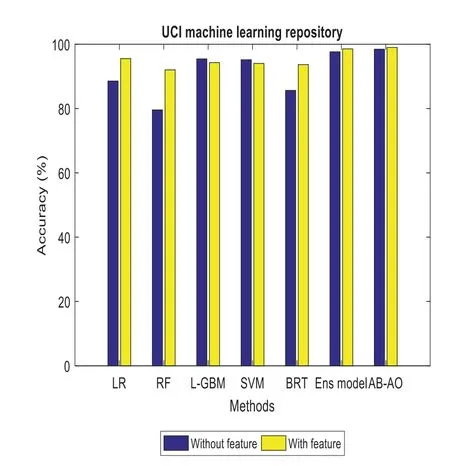
Figure 4:Accuracy computation in UCI ML dataset
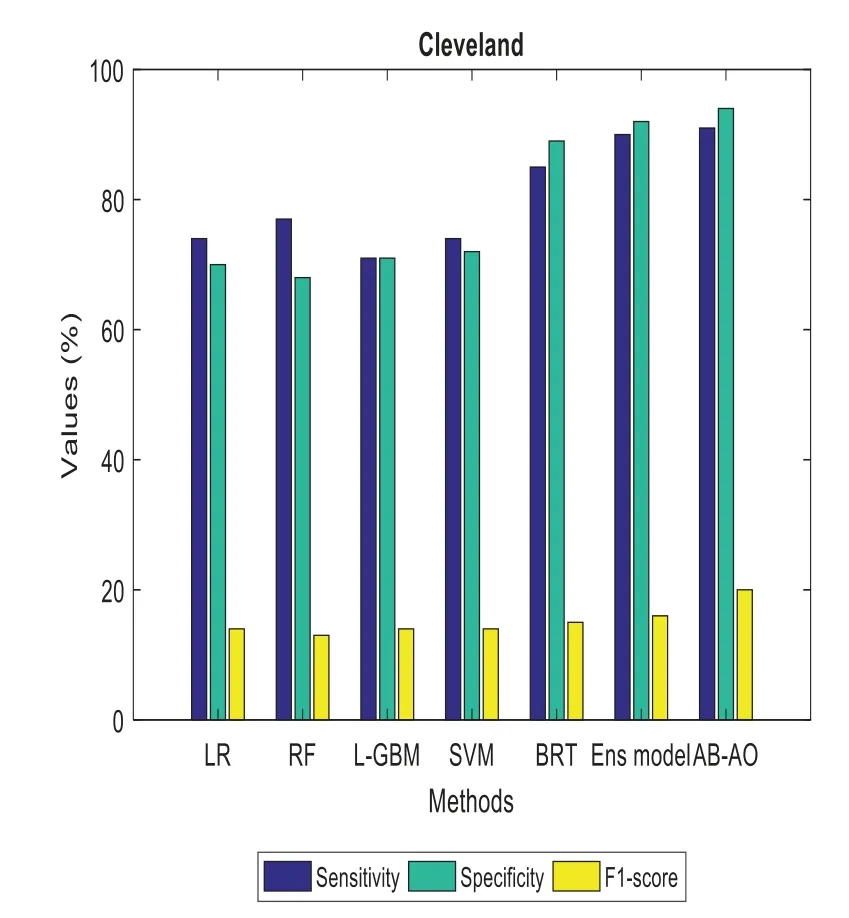
Figure 5:Sensitivity,specificity and F1-score computation in cleveland dataset
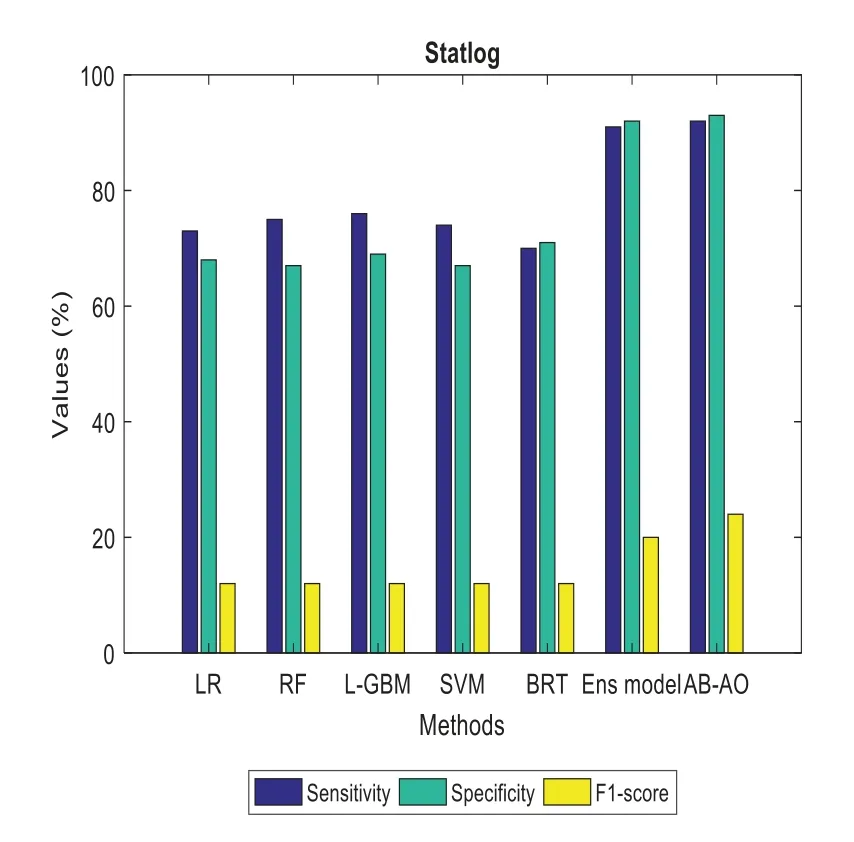
Figure 6:Sensitivity,specificity and F1-score computation in statlog dataset
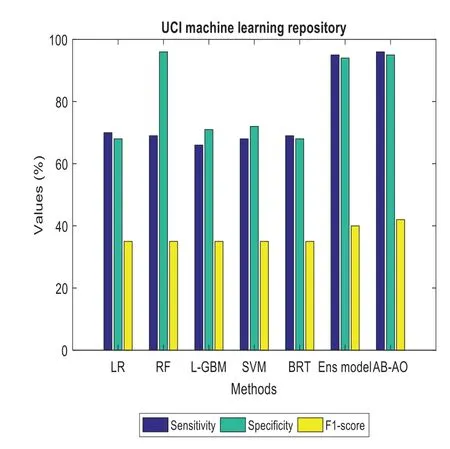
Figure 7:Sensitivity,specificity and F1-score analysis in UCI ML dataset
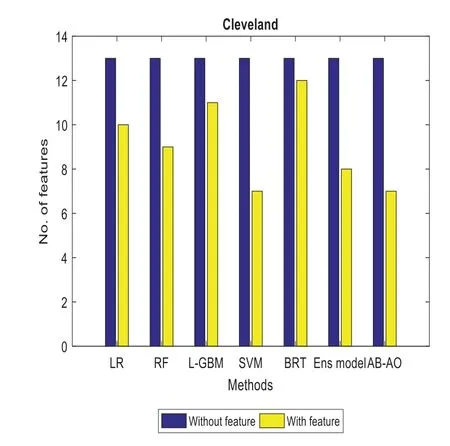
Figure 8:Feature specification in cleveland dataset
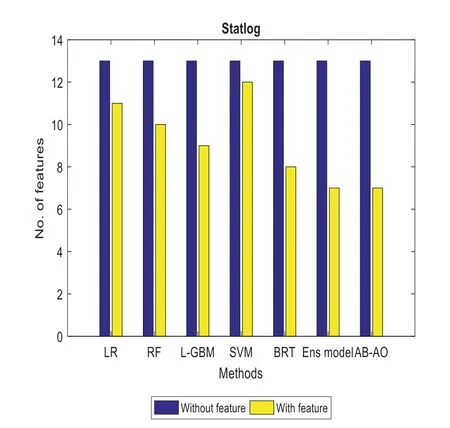
Figure 9:Feature specification in catalogue dataset
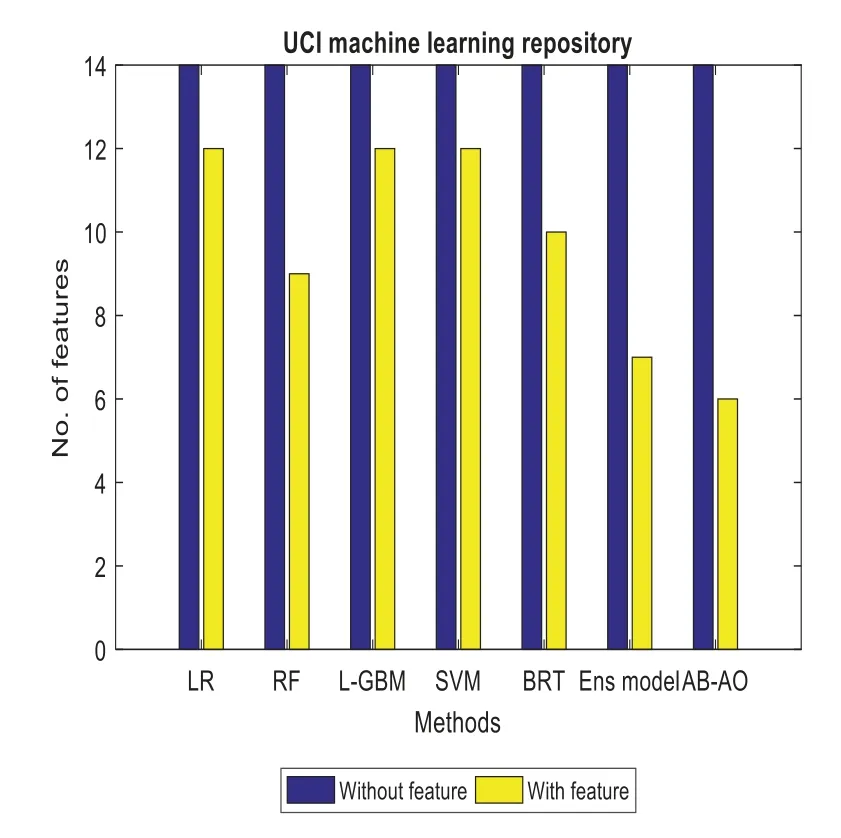
Figure 10:Feature specification in UCI ML dataset
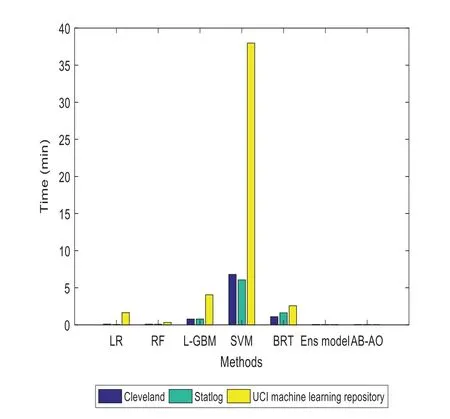
Figure 11:Execution time(min)computation
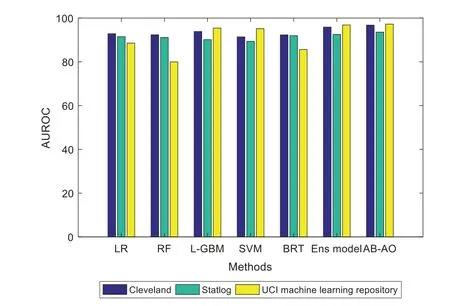
Figure 12:AUROC computation in all the three datasets
The performance metrics of the anticipated AB-AO model w.r.t.statlog dataset is evaluated.The accuracy without feature selection is 93.25% which is 3.43%,5.45%,3.43%,3.86%,11.5% and 0.54% higher than other approaches.The prediction accuracy of the AB-AO model with feature selection is 95.56% which is 5.43%,4.44%,5.17%,3.76%,5.43%,and 2.41% higher than other models.The sensitivity of AB-AO is 91% which is 18%,16%,15%,17%,21% and 1% higher than other models.The specificity of AB-AO is 92% which is 24%,25%,23%,25%,21%,and 1% higher than other models.The F1-score of AB-AO is 24% which is 12% higher than Linear Regression(LR),Random Forest(RF),Lightweight Gradient Boosting Machine approach(LGBM),Support Vector Machine(SVM)and Boosted Regression Tree model and 4% lower than ensemble model.Here,the model considers 13 features where LR selects 11 features,RF chooses 10 features,L-GBM selects 9 features,SVM selects 12 features,BRT selects 8 features,ensemble and AB-AO selects least 7 features.The execution times of all these models are 0.05 min,0.08 min,0.78 min,6.06 min,1.62 min,and 0.04 min,respectively.The AUROC of AB-AO is 93.58%which is 2.08%,2.44%,3.44%,4.2%,1.61%,and 1.02%.
Now,the evaluation is done for the AB-AO model with all three datasets.The prediction accuracy without feature selection of AB-AO with statlog dataset is 93.25% which is 3.1% higher than Cleveland and 5.22% lower than UCI dataset.The prediction accuracy with feature selection is 95.56% which is 0.91% and 3.44% lower than another dataset.The sensitivity is 92% which is 2% higher for Cleveland and 4% lower than the UCI dataset.The specificity of AB-AO with statlog and Cleveland dataset is 92% which is 3% lower than the UCI dataset.The F1-score of statlog is 24% which is 4% higher than Cleveland and 18% lower than the UCI dataset.The Cleveland dataset and statlog dataset considers 13 features,while UCI considers 14 features.But,the average feature selection ratio of Cleveland is 8,statlog and UCI is 7 features.The average execution time for the Cleveland dataset and statlog dataset validation is 0.04 min,while for the UCI dataset,the execution time is 0.03 min,respectively.The AUROC value of statlog is 93.58%which is 3.2% and 3.67% lesser than other models.Table 3 depicts the comparison of various performance metrics.
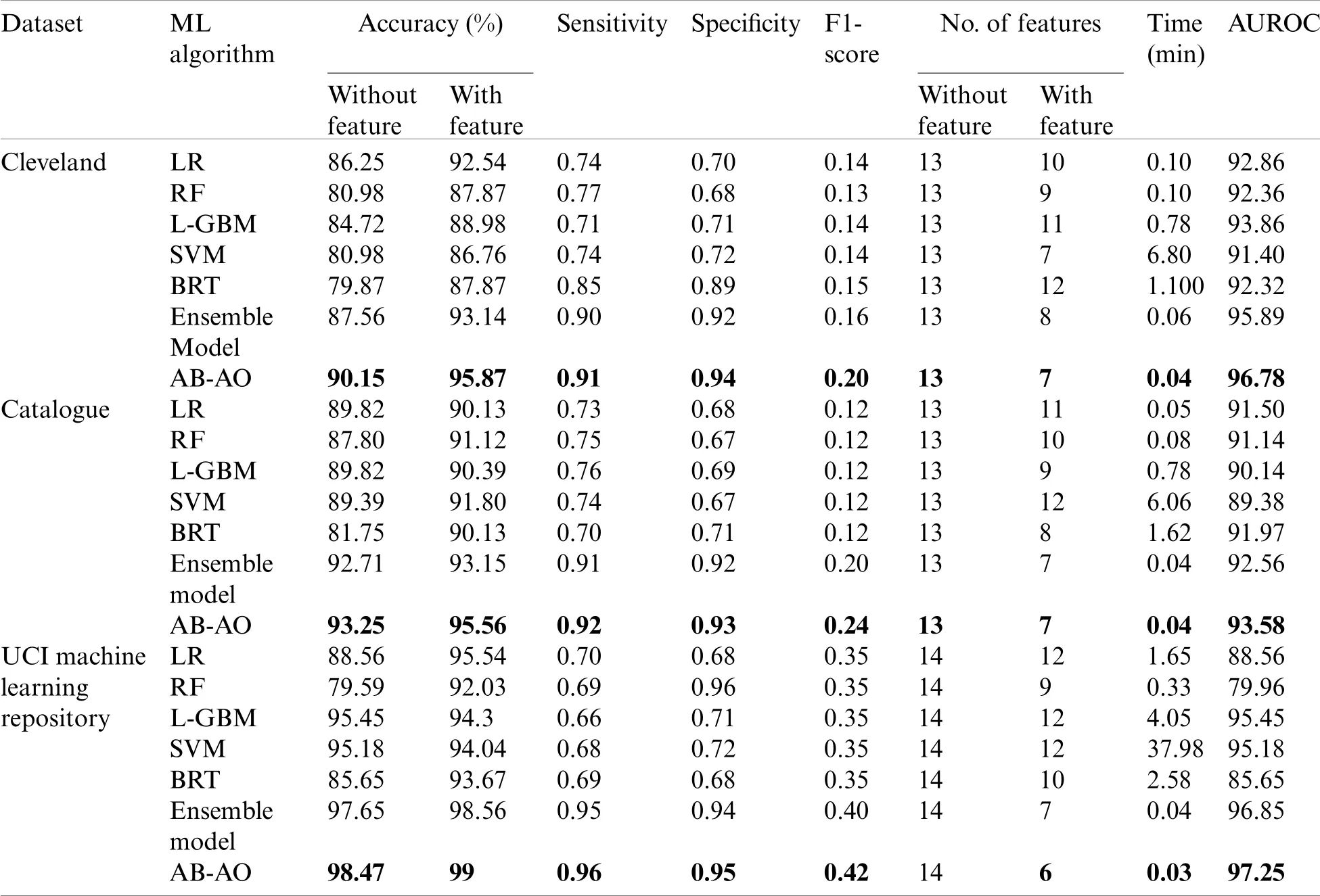
Table 3:Comparison of various performance metrics
The performance metrics of the anticipated AB-AO model w.r.t.UCI ML dataset is evaluated.The accuracy without feature selection is 98.47% which is 9.91%,18.88%,3.02%,3.29%,12.82%and 0.82% higher than other approaches.The prediction accuracy of the AB-AO model with feature selection is 99% which is 3.46%,6.97%,4.7%,4.96%,5.33%,and 0.44% higher than other models.The sensitivity of AB-AO is 96% which is 26%,17%,30%,28%,17% and 1% higher than other models.The specificity of AB-AO is 95% which is 27%,1% lower than RF,24%,25%,27%,and 1% higher than other models.The F1-score of AB-AO is 42% which is 7% higher than Linear Regression(LR),Random Forest(RF),Lightweight Gradient Boosting Machine approach(L-GBM),Support Vector Machine(SVM)and Boosted Regression Tree model and 2% higher than ensemble model.Here,the model considers 14 features where LR selects 12 features,RF chooses 9 features,L-GBM selects 12 features,SVM selects 12 features,BRT selects 10 features,ensemble selects 7,and AB-AO selects the least 6 features.The execution times of all these models are 1.65 min,0.33 min,4.05 min,37.98 min,2.58 min,0.04 min and 0.03 min,respectively.The AUROC of AB-AO is 97.25% which is 8.69%,17.29%,1.8%,2.07%,11.6%,and 0.4%.The performance of the AB-AO over the statlog dataset is optimal as it eradicates uneven distribution of samples using SMOTE technique.However,the Cleveland and UCI ML repository approaches do not adopt SMOTE or other methods to handle these issues.However,it is noted that the performance metrics can be misleading results compared to the proposed model.Thus,it is proven that the anticipated model outperforms the existing approaches efficiently by adopting essential pre-processing steps.
5 Conclusion
This research work has provided a clinical decision support system for predicting heart diseases by evaluating the provided statlog UCI ML dataset.The anticipated Adaboost classifier and Adam optimizer work as a superior prediction approach to classify the imbalance dataset efficiently with the well-known SMOTE technique.Moreover,the execution time is considered a remarkable metrics with lesser computation time to show the reliability of the anticipated model.The classifier’s performance entirely relies on parameter tuning with a ‘1’learning rate and a ‘30’estimator.The prediction accuracy of the AdaBoost classifier is 90.15% and 95.87% for without and with feature selection.The model’s sensitivity is 91%,specificity is 94%,F1-score is 0.20,time for execution is 0.04 seconds,and 96.78% AUROC.The major constraint with this research work is the lesser number of available samples(statlog)for the evaluation process.However,the prediction accuracy achieved by this model is 95.87% and acts as a superior CDSS during the time of emergency.In the future,deep learning approaches are adopted to enhance the heart disease prediction rate,and statistical analysis withp-value computation is highly solicited to acquire higher validation accuracy.The statistical analysis will be given more importance in future research works.
Funding Statement:The author received no specific funding for this study.
Conflicts of Interest:The author declares that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2022年5期
Computer Modeling In Engineering&Sciences2022年5期
- Computer Modeling In Engineering&Sciences的其它文章
- Computational Investigation of Cell Migration Behavior in a Confluent Epithelial Monolayer
- The Hidden-Layers Topology Analysis of Deep Learning Models in Survey for Forecasting and Generation of the Wind Power and Photovoltaic Energy
- Conceptual Design Process for LEO Satellite Constellations Based on System Engineering Disciplines
- Deep Learning-Based Automatic Detection and Evaluation on Concrete Surface Bugholes
- Efficient Numerical Scheme for the Solution of HIV Infection CD4+T-Cells Using Haar Wavelet Technique
- Prototypical Network Based on Manhattan Distance