
The Hidden-Layers Topology Analysis of Deep Learning Models in Survey for Forecasting and Generation of the Wind Power and Photovoltaic Energy
2022-07-04 05:40DandanXuHaijianShaoXingDengandXiaWang
Dandan Xu,Haijian Shao,★,Xing Deng,2 and Xia Wang
1School of Computer,Jiangsu University of Science and Technology,Zhenjiang,212003,China
2School of Automation,Key Laboratory of Measurement and Control for CSE,Ministry of Education,Southeast University,Nanjing,210096,China
3School of Information Science and Technology,Nantong University,Nantong,226019,China
ABSTRACT As wind and photovoltaic energy become more prevalent,the optimization of power systems is becoming increasingly crucial.The current state of research in renewable generation and power forecasting technology,such as wind and photovoltaic power(PV),is described in this paper,with a focus on the ensemble sequential LSTMs approach with optimized hidden-layers topology for short-term multivariable wind power forecasting.The methods for forecasting wind power and PV production.The physical model,statistical learning method,and machine learning approaches based on historical data are all evaluated for the forecasting of wind power and PV production.Moreover,the experiments demonstrated that cloud map identification has a significant impact on PV generation.With a focus on the impact of photovoltaic and wind power generation systems on power grid operation and its causes,this paper summarizes the classification of wind power and PV generation systems,as well as the benefits and drawbacks of PV systems and wind power forecasting methods based on various typologies and analysis methods.
KEYWORDS Deep learning;wind power forecasting;PV generation and forecasting;hidden-layer information analysis;topology optimization
1 Introduction
As the energy crisis,environmental degradation,and climate change worsen,the usage of clean energy is becoming increasingly important.Furthermore,the proportion of wind and photovoltaic energy is growing[1,2].Wind and photovoltaic power generation are examples of new energy power generating technologies that are clean,low-carbon,and renewable,which have been widely used in power generation technology.China’s installed power generating capacity reached 2.26 billion kilowatts in June,gaining 9.5 percent year on year,according to statistics issued by the National Energy Administration.The installed solar power capacity was about 270 million kW,up 23.7 percent year on year.Two basic patterns in wind speed are discussed due to the low density of wind energy,atmospheric pressure,humidity,and temperature:on the other hand,wind speed distribution is volatile and has a non-stable random trend.The stability of the output power will be detrimental to power grid dependability,economics,and reduce the uncertainty of wind power due to the randomness of wind and solar power and volatility features[3–5].Wind power forecasting with high precision is particularly important,and we must successfully carry out power system operation optimization.
To calculate the value of wind power,modeling and mathematical analyses of historical data may be employed.As a consequence,when comparing different forecasting methods,wind speed and wind power may be included in their entirety.Short-term forecasting,or utilizing physical models based on numerical weather predictions and statistical models based on wind speed and wind power data for predicting,is the current trend in wind power forecasting.Artificial intelligence-based wind power forecasting technology has grown in prominence in recent years.
The rest of this paper is organized as follows:The physical model,statistical learning technique,and machine learning method based on historical data are investigated for forecasting wind and solar photovoltaic generation,and the ensemble sequential LSTM approach with optimized Hidden-layers topology for short-term multivariable wind power forecasting is introduced in Section 2;In Section 3,STL(Seasonal-Trend decomposition procedure based on Loess)and the method of SOM cluster is successively applied to decompose the wind power time series into the seasonal and trend component with significant information and optimize the hidden-layer topology of forecasting method.VGG,ResNet and other transfer learning models are used for cloud image classification and the hidden layer feature information of cloud images are used for classification analysis.
2 The Forecasting and Generation Methods of the Wind and Photovoltaic Energy
Large-scale grid-connected power generation is the most effective approach to completely use wind and solar energy due to exposure to sun radiation.The shooting strength,temperature,humidity,cloud volume,and a variety of other parameters,as well as scenic power generation,reveal an inherent follow-up machine and volatility.With the growth of the number of scenic power stations,the demand for real-time monitoring of scenery data has developed.As a result,there is a greater demand for enhanced and safe operation,as well as the ability to evaluate meteorological and landscape data.The survey’s general framework is depicted in Fig.1.This paper examines the experimental principle,experimental process,experimental results,and sample analysis from the perspective of different classification models in order to find a reliable method to improve the forecasting effect by combining and analyzing the current wind power forecasting system and photovoltaic forecasting system.
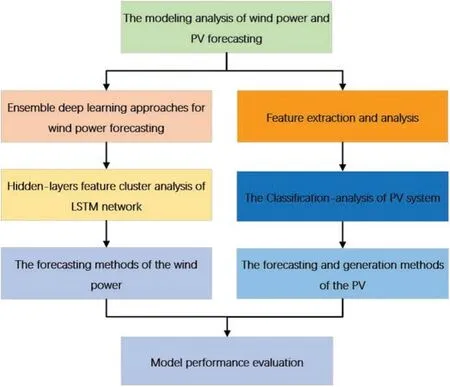
Figure 1:The overall framework of this paper
2.1 The Modeling Analysis of Wind Power Forecasting
In recent years,the research on wind power forecasting model is very extensive all over the world,and the forecasting methods are also innovating constantly.There are several literatures to summarize the forecasting technology in different development periods of wind power as indicated in Table 1,in order to better apply the existing research results of wind power forecasting technology and improve the forecasting accuracy of wind power forecasting systems.Pinson[6]studied and evaluates various uncertain factors of wind power forecasting accuracy from the aspects of reliability,accuracy and resolution.Zhang et al.[7]highlighted the requirements and overall framework of uncertainty forecasting evaluation by categorizing forecasting approaches into three categories:probabilistic forecasting(parametric and non-parametric),risk index forecasting,and spatiotemporal scenario forecasting.Aggarwal et al.[8],based on NWP,statistical methods,ARIMA models and mixed technologies on different time scales,discussed wind power and important forecasting technologies related to wind speed,and divides the forecasting technologies into statistical models,physical models and mixed models.Foley et al.[9]went into great length about statistical and machine learning methodologies.Benchmarking and uncertainty analysis techniques used for forecasting are outlined and the performance of various methods over different forecast time horizons is examined.The preceding literatures are useful for researching and using wind power forecasting methodologies,as well as improving wind power forecasting accuracy.
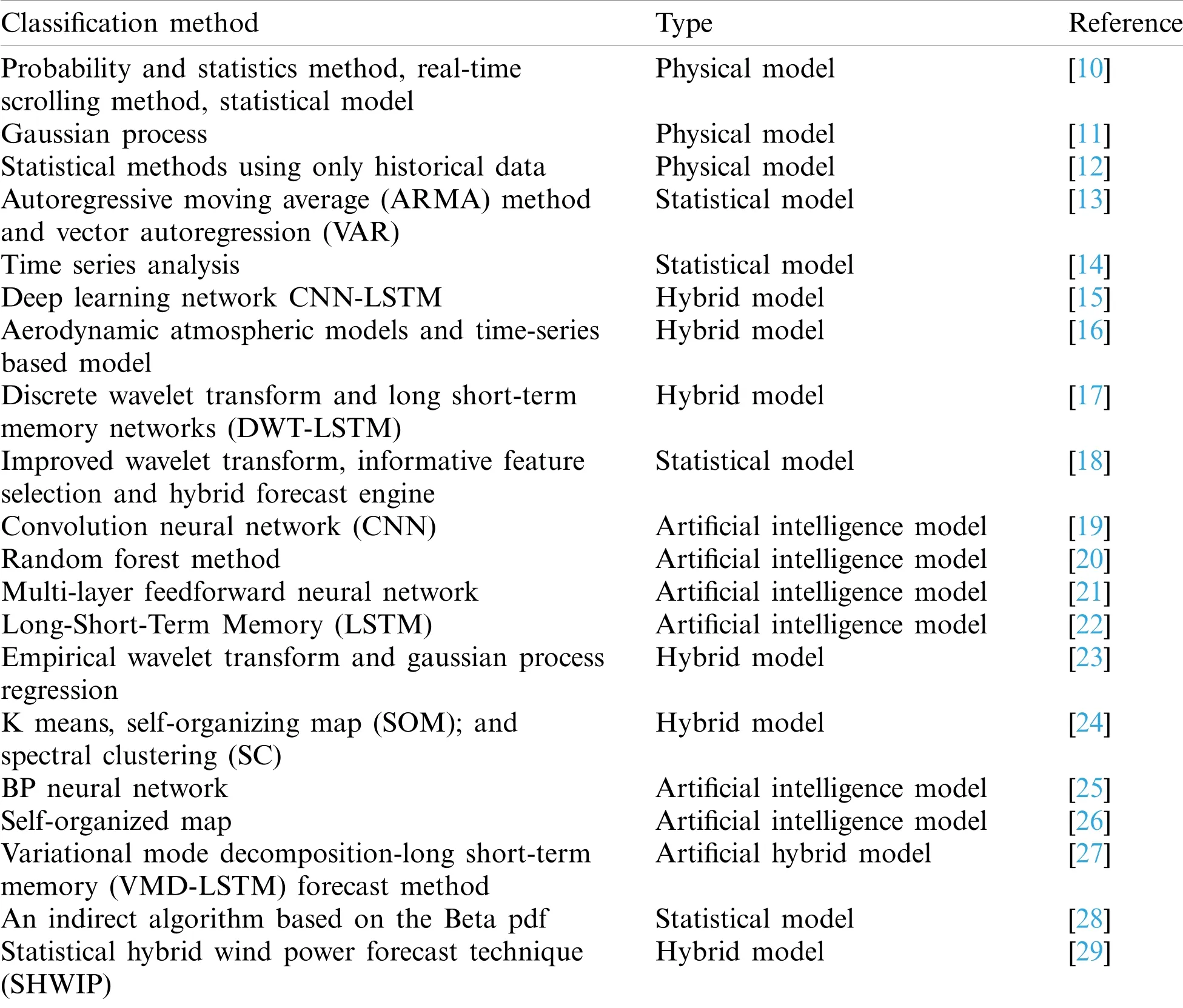
Table 1:The summary of wind power forecasting models
In order to establish a more accurate wind power forecasting model,a classification research on wind power forecasting is constructed,which can be summarized as shown in the Fig.2.According to different forecasting models,wind power forecasting is mainly classified into four categories based on distinct forecasting models:physical model,statistical model,artificial intelligence model,and hybrid model[30–32],and it is classified into ultra-short-term forecast,short-term forecast,medium-term forecast and long-term forecast[33–35]according to different time scales.The wind power forecasting at different time scales:
i)Ultra-short-term forecasting:to forecast the wind power of the next few minutes to a few hours,using the historical data of the wind tower to predict the wind power by continuous method or statistical method,mainly used for the control of wind turbines[36–39].
ii)Short-term forecasting:to forecast the power output in the next few days,often using the method of weather forecast based on data,or using historical data for forecasting,used for reasonable dispatch of the power grid,to ensure the quality of power supply[40–46].
iii)Mid-term forecasting:to forecast the power output in the next few months or weeks,generally using numerical weather forecast methods,mainly used for arranging maintenance of wind farms[47–50].
iv)Long-term forecast:the forecast unit is month or year,which usually requires decades of wind power data to calculate the annual power generation of wind farms,mainly used for feasibility study and site selection of wind farm design[51–55].
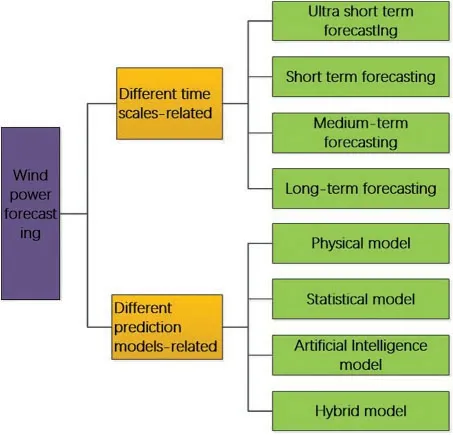
Figure 2:Different classifications of wind power forecasting
2.2 Physical and Statistical Models Related Approaches
The physical model obtains wind speed,wind direction,temperature,and other meteorological data primarily through a numerical weather forecast system(NWP),and then the power curve of a wind turbine is determined by estimating wind speed,yielding the expected power of a wind turbine[10–12].NWP is often implemented on supercomputers because it uses high-dimensional and complicated mathematical equations,resulting in significant computational and manpower expenses.As a result,this method’s capacity to foresee in the near term is more broad,and its output is better suited as a long-term reference standard.When observed data is scarce,statistical models must rely on historical wind data,which reduces predicting accuracy.Because actual data is typically random for a variety of reasons,the statistical characteristics of time series change over time.The corresponding mathematical expectation and variance factors will change with time,which will surely make it more difficult to forecast trends based on historical data.Statistical models such as the moving average method[13,14,16]and wavelet decomposition[17,18]have limited ability to predict data with strong nonlinearity due to the random,intermittent,and seasonal changes in wind speed,and statistical models are usually only suitable for short-term forecasting.
2.3 Hybrid Forecasting Modeling Based on Neural Network-Related Approaches
Artificial intelligence models are commonly used in short-term wind power forecasting because of the benefits in dependency analysis and pattern detection[25–27,56–60].Ozkan et al.[61]suggested a multi-feature convolutional neural network-based wind power forecasting approach.To begin,wind power is classed based on the waveform’s changing characteristic.Then,the convolution neural network extracts the feature of the wind power waveform(CNN).The results show that this method can effectively improve the reliability of wind forecasting.Quan et al.[62]put forward the random forest method to construct the wind power predictor before hours,the results show that the proposed model can significantly improve the forecasting accuracy,compared with the classical neural network forecasting.Haque et al.[63]adopted a new recurrent neural network called Long-Short-Term Memory(LSTM),the test results on real data sets show that the performance of LSTM model is better than typical RNN models such as Elman,exogenous nonlinear autoregressive model and other benchmark models.
Despite the stated artificial intelligence models can forecast the short-term wind power[64],the forecasting accuracy is still insufficient.Long-term and short-term memory(LSTM)networks have been widely employed in wind power forecasting because to their capacity to understand the long-distance dependency of time series.The back propagation information may not be extracted in RNN because of the multivariable with long temporal dependency,and the vanish gradient and vanish explosion issues are typically caused in the learning processing of the deep neural networks.By controlling the information updating,the LSTM network can avoid the information exponentially decaying,and effectively overcome the outlined disadvantages of the RNN,as well as improve the forecasting accuracy and robustness of the deep learning[65].
By calculating the vibrational energy distribution for each period,the time series can be viewed of a reconstruction of several periodic disturbances,which is important for identifying the periodic components of the time series[66].High-accuracy multivariate forecasting modeling remains a challenge due to the varied distributions of time series in different areas.Periodic features may be obtained by decomposing the original time series sequence using a filtering strategy,which can help enhance multivariate time series forecasting and modeling accuracy.Spectral decomposition,wavelet transformation[23,67],and time series decomposition models are the most extensively used the approaches of multivariate decomposition.The raw data can be decomposed into trend component,seasonal component,and remaining component using the LOESS-based method of time series decomposition,as illustrated in Fig.3[68].As a result,the forecasting models properly capture the long-term steady trend in timing across time,periodic duration and amplitude fluctuations,as well as irregular changes caused by random factors.
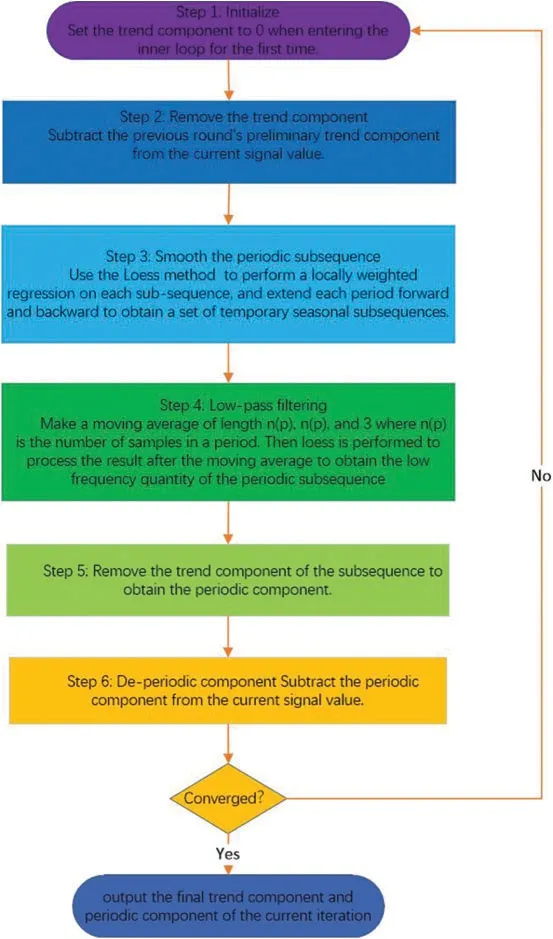
Figure 3:The STL decompresses flow chart
2.4 The Ensemble Deep Learning Approaches for Wind Power Forecasting
The Fourier series principle indicates that any continuous time series or signals can be represented as the superimposing of sine wave signals with different frequencies.Similarly,STL(Seasonal-Trend decomposition procedure based on Loess)can also use the idea of overlays to decompose the time series into complex trends terms,periodic terms and remaining terms[78],which is usually defined by Eq.(1):
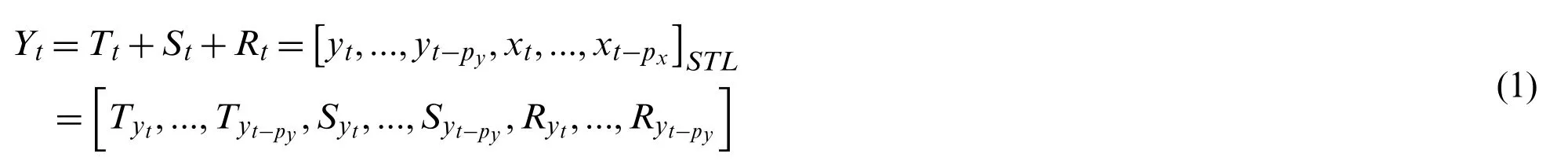
whereYtis the input time series,and has three variablesTt,St,andRtafter decomposition.Ttis a trending weight at t-moment,representing the long-term characteristics of the sequence.Stis the corresponding periodic variable that represents the periodic characteristics of the sequence.Rtis the remaining item ofYt,which represents the jitter and interference factors that the sequence is subjected to,and is usually considered miscellaneous.One of the most extensively used methods for smoothing discrete data is the Loess(locally weighted scatterplot smoothing)approach.When estimating the value of a response variable,a subset of data is first taken from the region of the target variable,and then linear or quadratic regression is used to this subset.For regression,the weighted least square approach is used,with the weight increasing as it comes closer to the estimation data.Finally,the local regression model is used to estimate the response variable[79,80].STL consists of inner loop and outer loop,and the former is mainly used for trend component fitting and periodic component calculation.Through multi-round iteration,the convergence value is utilized to estimate the real value of the probability distribution of the trend and periodic component.In the outer loop,the remainder can be calculated based on the trend component and periodic component obtained in the inner loop.The remainder will not be defined where the input data is missing.Once an outlier is detected,it will produce an abnormality.The outer loop is mainly used to adjust the robustness weight and reduce the size of the remainder for generated outliers[81,82].
The ensemble deep learning approaches for wind power forecasting is described in Fig.4.which is generally made up of four parts:Firstly,the dataset is divided into three groups based on the STL decomposition,trend component,seasonal component and residuals.Usually,the trend and seasonal parts can still show the significant influences to reflect the most the effective information,and the residuals is not a simply white noise,which still has some valid information.However,it has a far smaller impact on sequence predictions than the first two components.This is due to the fact that the render and seasonal components contain the majority of the original sequence’s valid information.Secondly,the data processed by the STL decomposition methods are divided as training sample,validation sample as well as testing sample which are used to train and test the performance of the forecasting models.Thirdly,by the SOM cluster,the hidden-layer information is mapped into the feature space with well sample separation to optimize the hidden topology of LSTM.The precise analysis of the hidden-layers information can reduce the risk caused by over-fitting and improve the robustness of the proposed approaches.Fourthly,the forecasting error is analyzed in mathematical analysis,and the output is constructed by the ensemble LSTM networks.Finally,the benchmarks methods,such as persistence model,multi-SVR,convnets,basic LSTM,cluster LSTM are performed to compare the performance of the proposed approaches,and the forecasting errors are mainly analyzed.
2.5 Hidden-Layer Topology Analysis of the LSTM Network
When RNN(Recurrent Neural Network)dealing with ling a long sequence,LSTM network are designed to solve the problem of gradient descent and gradient,as well as overcome short-term dependence.LSTM network can remember the cell state basing on the cell state,and reasonably forget the old state,then add new state and outputting new state[83].Therefore,the final outputftis given by Eqs.(2)–(4):
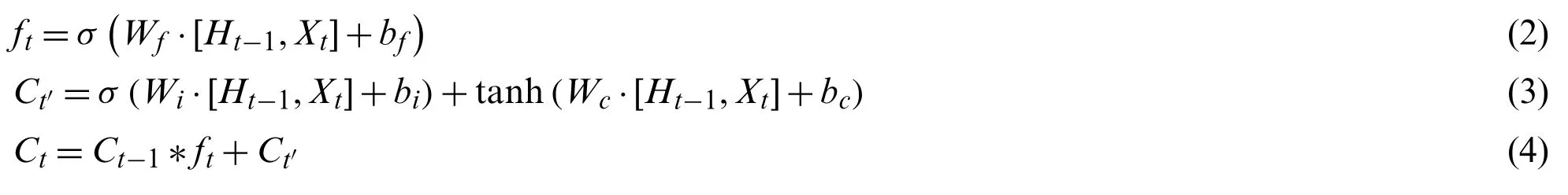
The input gate determines that the number of inputXtis retained,and the input is processed by the weight matrixWc,biasbc,and tanh function.The cell stateCtis given in Eq.(2),and it can be easily seen that a new cell state can be obtained by forgetting part of the past state and adding the existing state based on Eqs.(3)and(4).After multiplying by the cell stateCt,the output gate gets the outputHtof the next stage similar to the forget gate.Eq.(5)is theHtexpression.

Then,the partial derivative between the hidden-states at different times is calculated by Eq.(6):
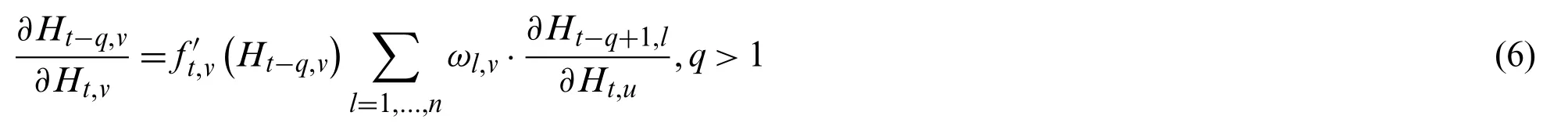
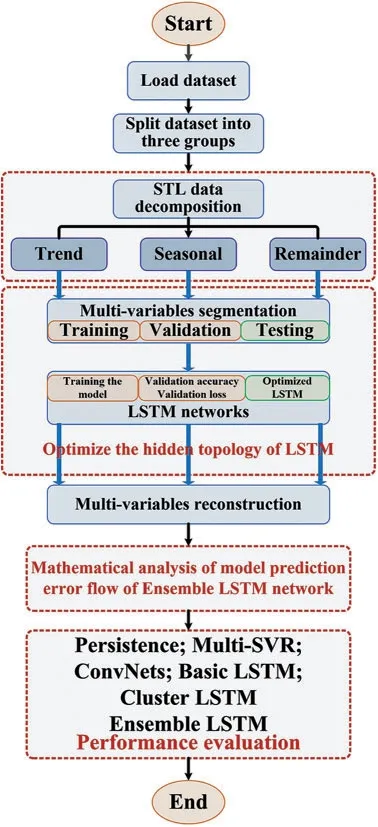
Figure 4:The framework of the multivariable wind power forecasting approaches
More precisely,the corresponding gradient is estimated by Eq.(7):
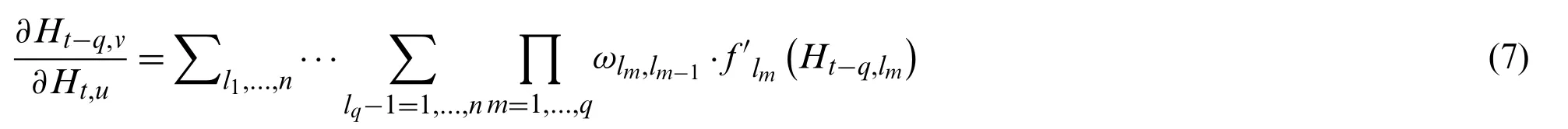
Furthermore,estimating the approximate value ofderived by Eq.(8):
Anne Lisbeth went forth from the castle into the public road,feeling mournful and sad; he whom she had nursed day and night, andeven now carried about in her dreams, had been cold and strange, and had not a word or thought respecting her. A great black raven darted down in front of her on the high road, and croaked dismally. Ah, said she, what bird of ill omen art thou? Presently shepassed the laborer s hut; his wife stood at the door, and the twowomen spoke to each other.
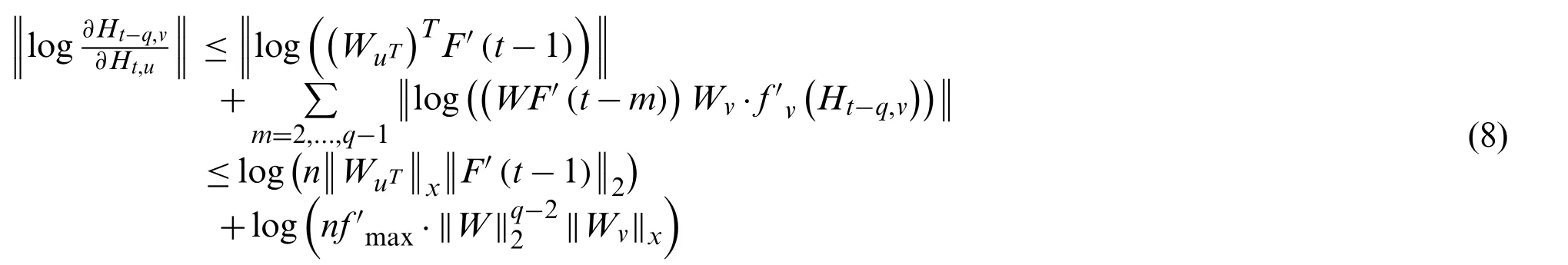
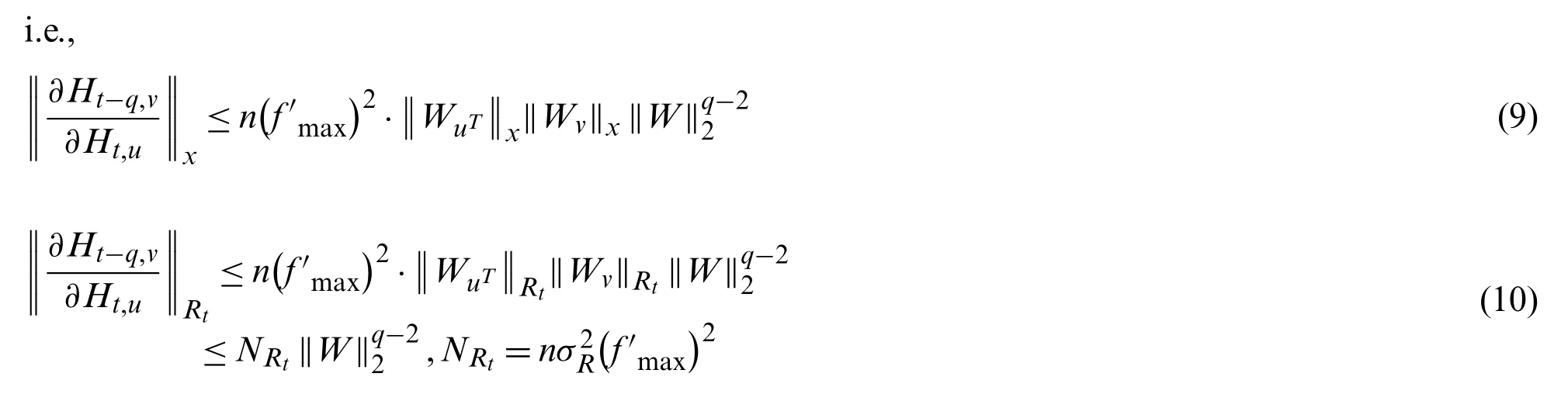
For multipliers in Eq.(10)at any moment,the results can be weighted to be greater than 1 or less than 1.More precisely,the vanishing gradient may be happened when united results became much more smaller.The total product may be larger if the mold of the multiplier at the later moment is greater than 1 through the adjustment of the weight coefficient(i.e.,the door).Thus,the long-term memory of time series is preserved.It can be seen from the above thaththas an effect on all errors at the time oft∈(0,+∞),so all subsequent errors will be transmitted back during back propagation.The calculation process of error propagation termcan be studied by a way of recurring moment by moment from back to front.
2.6 Hidden-Layers Feature Analysis of LSTM Network
To avoid the infiltration of external information and achieve long-term memory of sequence information,the LSTM network employs a complete structure including forget gates,input gates,and output gates[84,85].The LSTM network is commonly used to forecast the future time series output of a single time step in time series.With numerous time steps,an LSTM network can also anticipate the future time sequence output.Multiple variable sequences influence the value of the final variable sequence in a multivariate sequence group.The LSTM model,on the other hand,usually only learns information from a small amount of the time step.Because an interception sequence with a lengthy time step produces low attention value output,the final LSTM network’s predicting impact will be harmed[86,87].
The SOM neural network is an unsupervised network that can do unsupervised data grouping[88,89].The approach assumes that the input data has certain topological connections or sequences that allow for the realization of the dimensionality reduction mapping from the input n-dimensional space to the output 2-dimensional plane.A typical topological distribution of the input data is then produced on a one-dimensional or two-dimensional processing unit array.The preservation of topological properties resembles the nature of actual brain work.SOM network training adopts the method of “competitive learning”[90,91].Each input sample finds a node with the shortest distance from it in the output layer,that is,the most matching node,which is called activation node or winning unit.Then,the node’s parameters are then updated using the stochastic gradient descent approach.At the same time,the points adjacent to the activated node also update their parameters appropriately according to their distance from the activated node[92–94].
When designing the SOM network,we must take into account the number of neurons in the output layer[95–97].The number of neurons in the out-put layer is related to the final number of clusters.More neurons can be set to better map the topological structure of the sample in the case of unknowing the number of clusters.If the number of clusters is too large,the output nodes can be appropriately reduced.Therefore,when dividing and selecting ‘regions’in the clustering plane,the “distance” between samples can be calculated and then the potential categories of different hidden-layer features can be analyzed basing on the similarity measurement between different hidden-layer information.The corresponding distance formula is obtained according to Eq.(11):

wherea,bis two arbitrary information points on a two-dimensional plane,the above formula indicates that the closer the hidden layer information is,the more similar the two sample patterns are.In particularly,the patterns of the two samples are the same if the distance obtained by Eq.(11)between the information patterns is zero.In the cluster analysis of the hidden-layer information,the presented threshold is usually used to judge whether the hidden-layer information between different samples is considered as the same,or will be treated in different categories[98,99].
2.7 The Forecasting and Generation Methods of the PV System
As indicated in Table 2,there are two types of photovoltaic power forecasting methods:direct forecasting based on a physical model and indirect forecasting based on historical data[100–103].The direct forecasting methods relies heavily on weather values or weather cloud maps,as well as other data,to predict energy generation[104–111],Ground cloud map model[112],a forecasting model integrating weather values with cloud cover pictures[21],and so on.The direct forecasting approach necessitates precise weather prediction information,power station geography information,and a considerable amount of sky picture information,as well as stringent gathering equipment and methods,resulting in the forecasting method’s weak resilience.Simultaneously,the model utilized in the direct forecasting technique is unable to gather time correlation information and is incapable of recalling past data.Indirect forecasting methods include time series method[113–116],Regression analysis[117]and artificial intelligence methods such as artificial neural network[118–125].The indirect forecasting method can overcome the difficulties such as the lack of physical mechanism of the direct forecasting method,which is suitable for short-term and ultra-short-term photovoltaic power forecasting,as well as long-term and short-term memory[126–128].
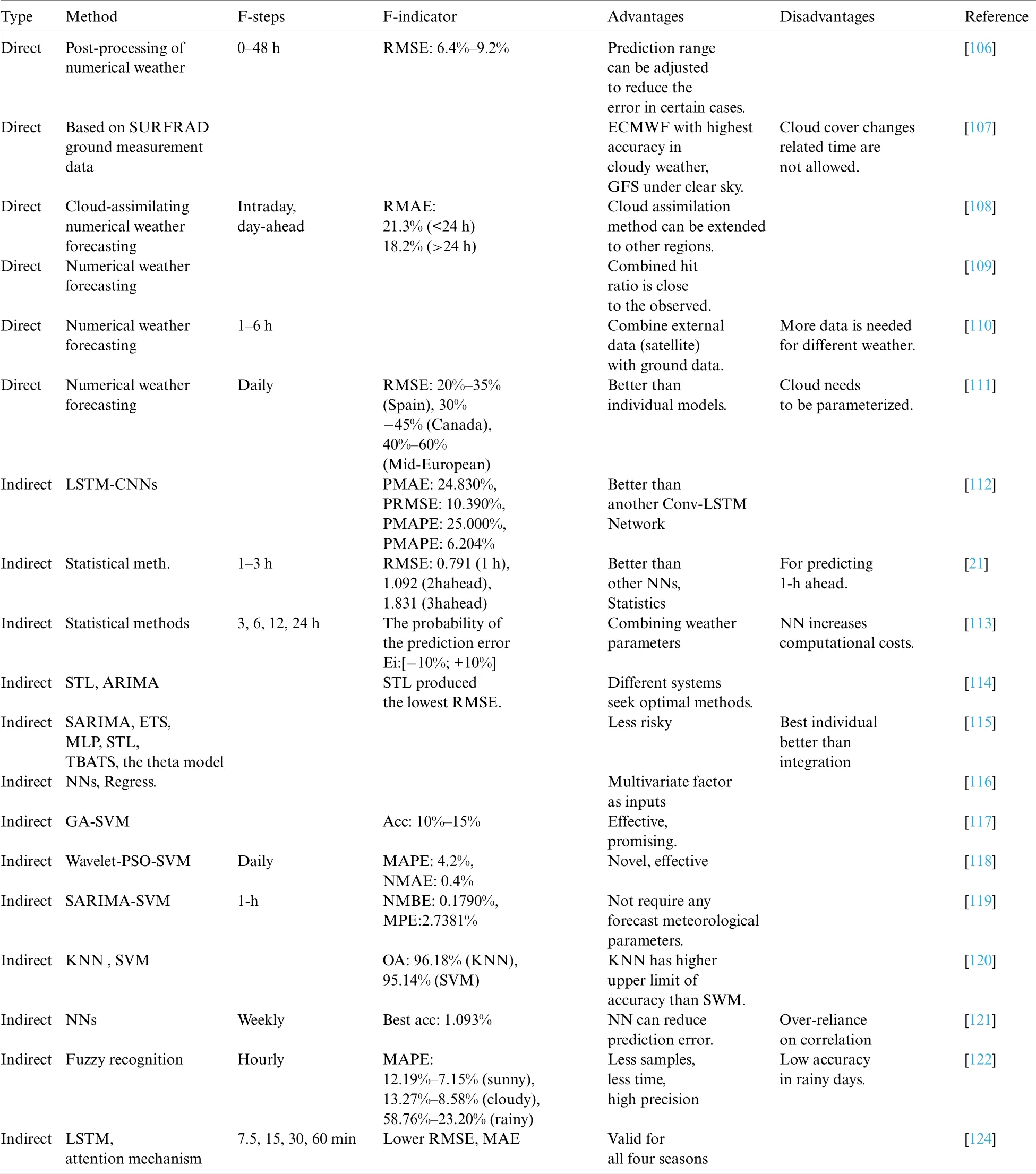
Table 2:Continued

Table 2:The summary of PV forecasting models
Due to the blocking of solar radiation by moving clouds,the photovoltaic power fluctuates rapidly and dramatically in minutes,posing a significant threat to the power grid’s reliability[129–132].The traditional photovoltaic power forecasting model based on the historical power data of photovoltaic power stations and numerical weather forecast is restricted by the algorithm principle and data accuracy,and it is difficult to precisely predict the minute power fluctuation caused by cloud movement[133–136].However,under certain weather conditions such as overcast,the surface irradiance fluctuates dramatically in minute time scale because of the influence of moving clouds[137–141].At this time,there is almost no correlation between the irradiance fluctuation and the historical irradiance data[142,143].Therefore,the above phenomena pose a challenge to the extraction and forecasting of minute level meteorological features.
Zhen et al.[144]took pictures of clouds in the sky with the all-sky imager to obtain the visual cloud features,and on this basis,predicts the ultra-short-term photovoltaic power[145].Zhen et al.[146]proposed a computing method for cloud motion velocity of solar photovoltaic power forecasting(PCPOW)sky image based on pattern classification and particle swarm optimization weight,and simulates it using real data recorded by Yunnan Electric Power Research Institute.The results confirme that PCPOW can improve the accuracy of displacement calculation.Cros et al.[147]proposed a forecasting method based on phase correlation algorithm for motion estimation between subsequent nebula-images derived from Meteosat-9 images.The forecasting of this method is 21% better than the relative RMSE persistence of the cloud index.It is found that sky images are widely used to improve weather forecast performance[148,149],and cloud identification is one of the challenges faced by photovoltaic forecasting.
3 Experiments
The neural network is an artificial intelligence system model that models and links the basic unit neurons of the human brain to replicate the activities of the human brain neuron system selection,pattern recognition,correlation analysis,and learning.The network learning algorithm performs network training by constantly altering the learning rate and weight of the network neuron nodes,and the model can design the learning environment using the input data samples or patterns.The training results will be dispersed across the neuron nodes that were first built.After repeated training analysis,the weight of network neuron nodes will approach a predefined value.Finally,the network can classify data samples autonomously and select the obvious qualities after learning and training.
3.1 The Short-Term Wind Power Forecasting Based on the Hidden-Layers Topology Analysis
The Kohonen neural network is a common unsupervised learning technique,whose network structure and learning algorithms have a better feature selection ability than other neural networks.In the learning or training stage,the Kohonen network structure-based clustering algorithm can adapt to the learning environment,adjust and optimize the learning rate and neuron weight,receive external data samples and environmental characteristics as input,as well as divide different categories of regions autonomously.In Fig.6,SOM analyzes the hidden layer information of the deep neural network,reduces the dimension and maps the read hidden layer information into the two-dimensional space.The first line of Fig.6 delicate,before the STL data decomposition,the number of clusters is not obvious,that is,the geometric relationship between clusters or the nodes that can be used as clusters in the topology are not obvious.The corresponding error trend fluctuates sharply around the peak value,which indicats that the convergence speed of the algorithm at this time will be affected by the local area of the data.
The second row to the fourth row of Fig.5,and display the data trend,cycle,and residual items into low dimensional discrete data,the network nodes are mapped to the local area and the active point in the network.After Competitive Process,Cooperation Process and Adaptation Process,the low dimensional data clustering center of the respectively show about 1 2.The attenuation of vector corresponding with the time of learning,as well as the convergence speed of SOM have the effect of reducing,and the corresponding error is reduced gradually.
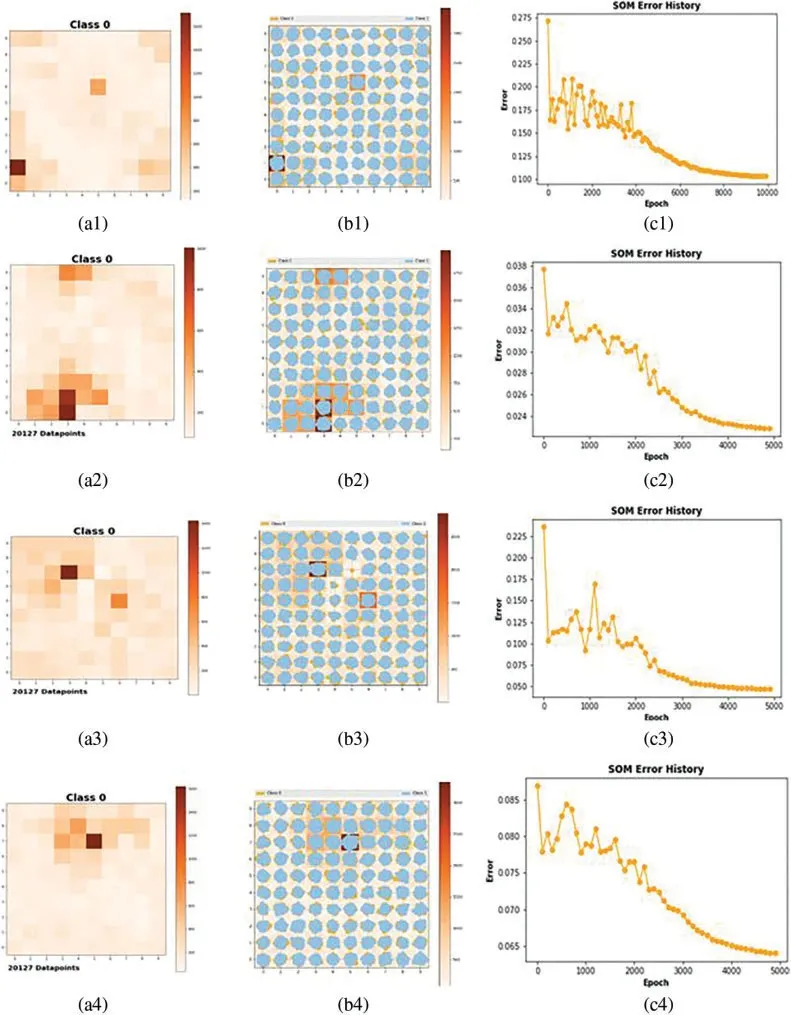
Figure 5:The hidden layer information of the deep neural network:cluster visualization and som error history
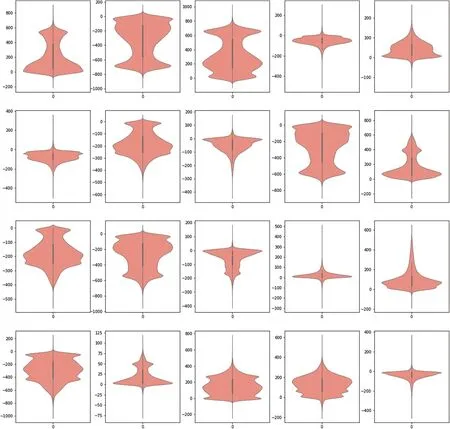
Figure 6:The hidden layer information of the deep neural network in different neurons
Designing the number of hidden nodes requires to read the information of the hidden layer.There are 40,254 pieces of output dable by LSTM,and the feature value dimension of the sample data at each time point is 20.The following Fig.6 shows the violin chart of the data feature value,which shows the distribution and probability density of the data.The thick black bar in the middle of the violin chart is used to show the quartile,the white dot in the middle of the black thick bar represents the median.The top and bottom edges of the thick bar represent the upper quartile and the lower quartile,respectively.The value of the quartile can be seen from the value of the y-axis corresponding to the position of the edge can see the value of the quartile.The two sides of the graph reflect the density information of the data.The data density at any position can be seen from the shape of the violin graph,the feature distribution of the time series more intuitively is estimated.From the previous analysis of the hidden layer information,it can be seen that the closer the hidden layer information is,the more similar the two sample patterns are,and they can be classified into the same category.Therefore,the 20 hidden layer nodes can be reduced to 6.
For the proportion of places inhabited by a given sample of the cluster,the associated accuracy can be shown as a percentage of the map’s logarithmic sample response,or computed as a percentage of the data sample’s response on the map.BMU is the closest representation of the data sample to the above percentages,estimating accuracy through relative quantization errors and fuzzy responses(quantitative nonlinear functions and percentages of all map units).The quantitative results were analyzed by displaying a histogram(or aggregate response).In fact,if treating the data result as a table shape,a cylinder or ring graph can be visualized,and the map shapes containing flat visualization percentages also will be visualized by using self-organizing grid graphics.The statistical results show that the average algorithm quantization error of trend term,period term and residual term after original data,and STL data decomposition is 0.175,0.032,0.125 and 0.080.Comparing with the hidden layer characteristic analysis of the original data,the average fluctuation degree of the data characteristic after STL decomposition is reduced by about 54.85%.According to the above analysis,the number of hidden layer nodes is reduced from the original artificial experience of 20(related to the number of inputs,which are determined by the order of the model)to 68.Thus,the preliminary optimization of hidden layer topology structure of deep LSTM network is designed.
When evaluating the prediction capacity of time series models,it is critical to use the baseline model.In general,the baseline model is easy to implement forecasting modeling and naive of problems-specific details.For example,the persistence model can quickly,simply and repeatable calculate the corresponding expected output based on the current input,so as to effectively measure the reliability and effectiveness of the forecasting model currently established[150–157].Multiple vector regression analysis(Multi-SVR)is a common kind of time-series forecasting model,which can use statistical methods to determine the quantitative relationship of the interdependence between multiple variables[158–160].Especially the modeling of causal forecasting in the big data,Multi-SVR is used to establish the forecasting model with high accuracy,and mainly used in the model to determine the development regularity of time series data[161–164].CNN has the analysis ability of using the convolution kernel feature analysis,especially the hidden layer’s awareness of the deep network information[165–169].Through the establishment of a strong expression ability of nonlinear mapping,it can effectively and accurately analyze data and on the basis of the law of the development trend of the current data,and speculated the data law of development in the future[170–172].
The LSTM network works well for evaluating and forecasting important events in time series with long gaps and delays,which have a improved classification accuracy and parallel processing power,as well as the ability to properly discern the trend development between historical data and anticipated variables.However,several factors in this model must be tweaked,particularly the calculation of topology structure,weight,and hidden-layer threshold.If the hidden-layer data cannot be adequately comprehended.In other words,accurate analysis of the deep neural network’s hidden-layer information is beneficial to the model’s generalization capacity.Furthermore,ensemble LSTM approaches can combine many trained LSTM models and increase each LSTM model’s learning ability,resulting in better and more reliable outputs.
Table 3 shows that the ensemble LSTM model has a greater forecasting accuracy than Persistence,Multi-SVR,ConvNets,Basic LSTM and Cluster LSTM,in every step in the next hour.The improvement of model accuracy also shows that memory gate and forgetting gate in LSTM network structure have significant advantages in dealing with long history dependence.More ever,When the method of SOM cluster is applied to wind power forecasting,it can provide guidance for wind power operation and dispatch.Compared with the traditional LSTM network,the forecasting accuracy of the Ensemble LSTM has been respectively improved by 44.51%,41.90%,41.89%,41.39%,38.83% and 9.42%.The detailed forecasting results are given in Table 4.
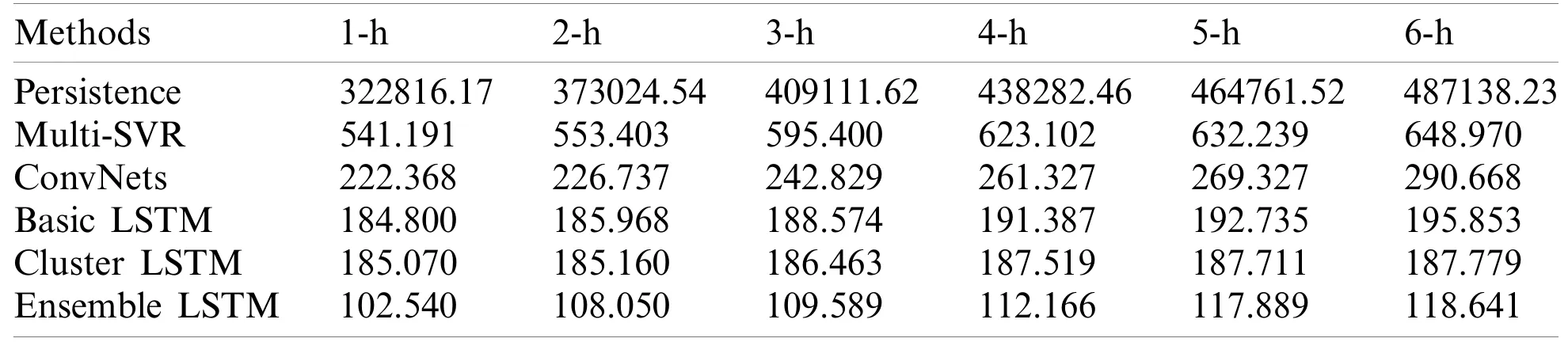
Table 3:Experiments evaluation

Table 4:The improvement of ensemble LSTM compared with other models(%)
Comparing with the benchmark model such as Persistence,Multi-SVR,ConvNets,Basic LSTM and Cluster LSTM,the forecasting accuracy has been improved by(1-h ahead)99.97%,81.05%,53.89%,44.51% and 44.59%,(2-h ahead)99.97%,80.39%,52.15%,41.66% and 41.40%,(3-h ahead)99.97%,81.59%,54.87%,41.89% and 41.23%,(4-h ahead)99.97%,82.00%,57.08%,41.39% and 40.18%,(5-h ahead)99.97%,81.35%,56.23%,38.83% and 37.20%,(6-h ahead)99.98%,81.72%,59.18%,39.42% and 36.82%.Compared to the traditional LSTM network,the forecasting accuracy of the Ensemble LSTM has been respectively improved by 44.51%,41.90%,41.89%,41.39%,38.83% and 9.42%.The detailed forecasting results are given in Tables 3 and 4.It can be seen that,no matter what dataset it is,CNNs based on the new topology gets the highest accuracy.On the MNIST dataset,CNNs based on the improved topology has no obvious advantages and achieves an average accuracy improvement of 7%.However,the accuracy in other datasets has improved by 30% and 7%,which achieves a great advance of the topology-optimized network.
3.2 The PV Classification and Forecasting Based on the Hidden-Layers Topology Analysis
Although the bulk of cloud identification depends on visual observation by meteorological observers,the majority of manual identification conclusions are likely to be incorrect depending on the observers’competence and physical state[173–175].Furthermore,continuous long-term observation is not practicable owing to the diversity of cloud morphologies and the difficulties of manual observation,affecting cloud identification accuracy and consistency[176–178].Intelligent cloud categorization and recognition technology has become a prominent study area in meteorology in recent years,thanks to the rapid growth of digital image processing technology.Satellite cloud image research has a wide range and span,but the description accuracy of high resolution and local cloud information is not very good,whereas ground-based cloud image classification has the advantages of ease of operation and strong local guidance,which is something that researchers are concerned about[179,180].The multi-category support vector machine(MSVM)is employed in the literature[181]for cloud classification of satellite radiation data,demonstrating MSVM’s promise as a cloud detection and classification system.A classification technique based on extreme learning machines and K nearest neighbors is suggested in the literature[182].Simulation results show that the proposed model is more suitable for cloud classification than extreme learning machine(ELM)model and artificial neural network(ANN)model.Reference[183]develops a novel time update method for a probabilistic neural network(PNN)classifier to track time changes in image sequences.The results on satellite cloud image data show that the classification accuracy of this method is improved.In literature[184],the fuzzy set algorithm is used for cloud classification of satellite data.Through careful analysis of the fuzzy set,spectral channels are most suitable for the information of specific feature classification are determined.The feature extraction network architecture of nephogram is shown in Fig.7.
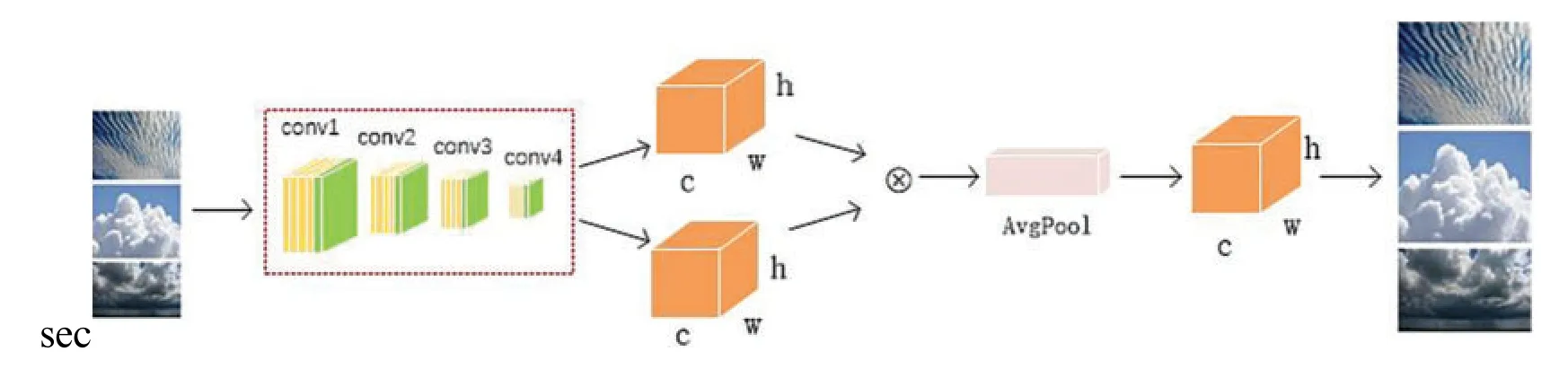
Figure 7:The model structure for feature extraction
CNN has a great capacity to extract visual features and has been used in the categorization of cloud images[133].At present,in the field of deep learning,such as VGG16[185–187],ResNet[188–191]and InceptionResnet-v2[192–195].CNN have achieved good results in classification,so these mature research results can be used as a reference cloud classification model can be built[196,197].In order to guarantee higher accuracy,shown in the following Table 5,this paper tests the five classical model:VGG16,ResNet18,ResNet34,ResNet50,InceptionResnnetv2 migration learning accuracy,and compared with ordinary CNN,found that ordinary CNN has the highest accuracy,at 0.8.This is because,while deeper hidden layers in deep neural networks may extract characteristics with better resolution,the model is also easier to overfit[198–201].Fig.8 shows the information of the first four hidden layers of the cloud image data set.It can be seen that the texture features of the cloud image in the first three layers are well retained.The fourth layer begins to learn invalid features.In order to further the cloud,a rich hierarchy of objects for feature extraction,a kind of attention mechanism making the model more focus on the characteristics of effective figure is designed.In the structure,two tensors of extended channel dimensions are firstly used to obtain features,and average pooling and max pooling are performed respectively.The former for spatial information aggregation,which can extract the texture information of the object,be able to infer updated channel information.Then,the output feature vectors are multiplied to connect the two channels,and finally the overall feature extraction of the connected channels is carried out through the two fully connected layers.The accuracy rate was finally reached 92%.

Table 5:The acc of different models
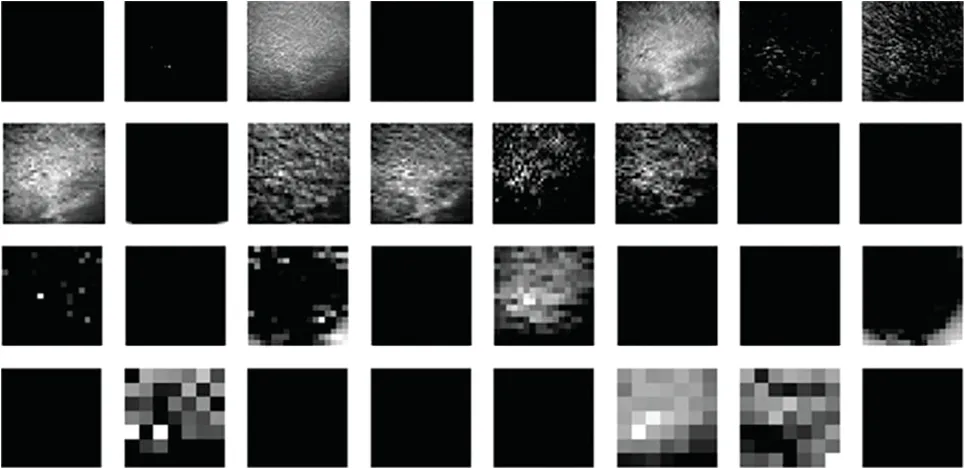
Figure 8:The hidden layer information of CNN for cloud cover
4 Conclusions and Discussions
Wind power and solar power generation are widely employed in the power grid,and power system optimization is becoming increasingly important.In this paper,Firstly,the physical model,statistical model,and machine learning model for wind power forecasting are fully detailed,and the hybrid machine learning method is universal and effective,especially in short-term wind power forecasting.Secondly,the set order LSTMs method based on optimized hidden layer topology is emphatically introduced,which is utilized for short-term multivariable wind power forecasting.The STL is used to obtain the trend component,seasonal component and residuals,to reflect the most effective information for short-term wind power forecasting.And the hidden-layer information is mapped into a higher-dimensional feature space,so that the similar information of hiddenlayer are well separated via the SOM clusters.The forecasting error of the ensemble LSTM network is analyzed in mathematical analysis.Thirdly,we summarizes the direct method based on physical model and the indirect method based on historical data in photovoltaic power generation forecasting,emphasiz the importance of cloud map identification photovoltaic power generation forecasting.Finally,the performance of the ensemble deep learning approaches is compared to benchmark methods such as persistent model,multi-support vector machine,convolution,basic LSTM and cluster LSTM,and the forecasting error is thoroughly examined.The accuracy of cloud image classification is compared to VGG16,ResNet18,ResNet34,ResNet50,InceptionRes-Netv2,CNN and other benchmark methods,and the hidden layer feature information of the model is emphatically analyzed.Through our research,it is found that wind power prediction and photovoltaic prediction have similar characteristics.Solar radiation,wind speed and cloud change are all important factors affecting the two kinds of power generation.Therefore,in order to improve the accuracy of prediction,it is the trend for future power generation prediction to extract predicted time characteristics from multiple factors.
Acknowledgement:Thanks the editors of this journal and the anonymous reviewer.
Funding Statement:This project is supported by the National Natural Science Foundation of China(NSFC)(Nos.61806087,61902158).
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2022年5期
Computer Modeling In Engineering&Sciences2022年5期
- Computer Modeling In Engineering&Sciences的其它文章
- Computational Investigation of Cell Migration Behavior in a Confluent Epithelial Monolayer
- Conceptual Design Process for LEO Satellite Constellations Based on System Engineering Disciplines
- Deep Learning-Based Automatic Detection and Evaluation on Concrete Surface Bugholes
- Efficient Numerical Scheme for the Solution of HIV Infection CD4+T-Cells Using Haar Wavelet Technique
- Prototypical Network Based on Manhattan Distance
- Modelling an Efficient Clinical Decision Support System for Heart Disease Prediction Using Learning and Optimization Approaches