
表格识别技术研究进展
2022-07-04 01:53高良才李一博都林张新鹏朱子仪卢宁金连文黄永帅汤帜
中国图象图形学报 2022年6期
高良才,李一博,都林,张新鹏,朱子仪,卢宁,金连文,黄永帅,汤帜*
1. 北京大学王选计算机研究所,北京 100871; 2. 华为技术有限公司 AI 应用研究中心,北京 100085;3. 华南理工大学电子与信息学院,广州 510640
0 引 言
在大数据时代,高效地存取数据,以及从海量数据中提取有效信息是各行各业都亟需利用的重要技术。表格作为数据的一种重要载体,具有信息精炼集中、方便体现数据关系等特点,已经在各个行业得到了广泛应用。在教育领域中,表格常常会出现在各类试卷、题目中;在金融领域,表格用来展示和分析数据;在科学领域,表格用来记录各类实验配置以及结果;在现实生活中也常常在幻灯片、车站时刻牌上看到表格。因此对表格进行区域检测、结构识别乃至对其中信息进行识别理解都有着广阔的应用前景。
表格在生成或存储过程中往往以图片或PDF(portable document format)文件的形式存在,会丢失易于计算机理解的原有结构信息。若是采用人工手段对表格进行重新处理录入,会面临效率低下、数据量大导致出错等问题。因此,如何让计算机从文档或图像中自动识别表格、提取信息,成为文档识别领域一个重要的研究问题。
早期对于表格的识别大多是针对较为简单或模板化的表格。从表格的布局结构出发,抽取表格线条或抽取文本块,然后使用规则方法进行分析,但这些方法往往泛化能力较差,且难以处理复杂表格。随着深度学习的发展,无论是机器视觉方面还是自然语言处理方面都获得了巨大的进展,各种表格识别的方案相继提出,并有研究者开始尝试对自然场景下的表格进行处理。
本文将围绕表格的区域检测、表格结构识别和表格内容识别3个表格识别子任务,从传统方法、深度学习方法等方面,综述该领域国内国外的发展历史和最新进展,同时对国内国外的研究进行对比,对未来的趋势和技术发展目标进行展望。
1 国内外研究现状
1.1 表格识别相关数据集及评测标准
针对表格识别的不同子任务、表格格式、数据量和文档类型等,本文对该领域的相关数据集总结如表1所示。
表格区域检测目前通常采用给定IoU (intersection over union)的F1进行评测,IoU表示的是预测框和真实框的交并比。对于图像中的表格,会选择IoU值超过阈值且具有最大IoU值的预测框作为正确预测。据此可以计算出正确预测、错误预测和未被召回的表格的数量,从而计算召回率和准确率,得到F1值。
表格结构识别的评测标准从早期到现在出现了多种形式,分别有单元格对的F1值、行列的预测准确性、序列化标注出现之后的BLEU(bilingual evaulation understudy)和TEDS (tree edition distance similiarity)等。单元格对的F1值的评测标准首先在ICDAR2013(International Conference on Document Analysis and Recognition)比赛中提出,这种方法将在结构上处于同一行或同一列的单元格组成一个单元格对,从而将表格分解成多个单元格对,之后计算这些单元格对的准确率、召回率和F1值。ICDAR2019比赛采取了相类似的方法,但是使用了IoU来确认单元格是否被检测到,将超过阈值的单元格组成单元格对计算F1值。行列预测准确性的评测标准由Shahab等人(2010)提出, 其将检测的结果分为正确检测、部分检测、过分割、分割不完全、丢失以及错误检测等6类来评估检测的效果。Li等人(2019)在使用序列标注表格结构的同时借鉴了自然语言处理中的BLEU来评测表格结构识别的效果。Zhong等人(2020)认为基于单元格对的评测标准无法评估由于空白单元格和非直接邻接的单元格未对齐对表格识别结果的影响,同时单元格对的评测标准是精准匹配,因此无法衡量每个单元格的识别效果。据此,其提出了TEDS(树编辑距离相似度),将表格的HTML代码看成一棵树,HTML代码的每个标签即为树中的节点,计算树之间的编辑距离和树长度的比值作为错误的比例。即
(1)
式中,Ta代表预测的HTML代码,Tb代表真实的HTML代码,Edit(Ta,Tb)代表两种代码序列的标记距离,|T*|代表的是代码的长度。
Smock 等人(2021)提出了GriTS(grid table similarity),GriTS将表格的拓扑结构表示为2维网格或矩阵,并分为单元格内容相似度、单元格位置相似度和单元格拓扑结构相似度3类来计算。对于单元格内容相似度,使用最长子串来计算;对于单元格位置相似度,使用IoU来计算;对于单元格的拓扑结构相似度,则使用跨行跨列来计算开始行开始列,并使用类似IoU的方式来计算。
1.2 表格区域检测相关研究
表格区域检测指的是从页面中框出对应的表格区域位置。在早期的研究中,检测目标多集中于扫描文档图片和PDF文档。随着图像采集技术水平的提升,以及表格应用领域的扩展,还出现了自然场景表格的检测任务。
1.2.1 传统的表格区域检测方法
国外的表格区域检测研究起步较早,这些早期方法大多数基于启发式规则或者简单的机器学习算法,依赖于图像预处理和文档分析获得的线条、文本块等视觉信息,或者依赖于PDF编码中自带的一些文字信息。
Watanabe等人(1993a)、Hirayama(1995)通过对扫描文档进行图像处理,获取文档中的文本块以及水平线和垂直线来定位表格。Ramel等人(2003)只尝试寻找表格区域顶部的第1条水平线,该表格的其他区域则通过匹配9种框线相交情况中的4种“T”字形模板来寻找;Watanabe等人(1993b)使用水平垂直线等特征的同时,在具体的检测策略上更注重用单元格的左上角作为基准点来确定表格位置(Watanabe和Luo,1996);Wang等人(2001)提出在初步定位表格时不用表格本身的特征,而是利用表格上下在水平方向上贯穿文档的空白区域得到待定表格区域,再计算该区域内的空白比例、单元格坐标差异等信息进行二次确认;Kieninger和Dengel(2001)认为空白、框线等都不是表格必须具备的特征,而表格中的文本区域具有和其他普通文本区域不一样的特性——不同列上的文本区域在x轴上投影基本不相交,并以此检测表格区域。
国内的表格区域检测研究起步较晚,启发式方法较少。其中,具有代表性的是Fang等人(2011)提出的基于表格结构特征和视觉分隔符的方法。该方法以PDF文档为输入,分4步进行表格检测:PDF解析、页面布局分析、线条检测和页面分隔符检测以及表格检测。在最后的表格检测部分中,通过对上一步检测出的线条和页面分隔符进行分析得到表格位置。
1.2.2 基于深度学习的表格区域检测方法
随着计算机硬件水平的提高,深度学习在计算机视觉的语义分割和目标检测等任务上取得了优异表现。作为语义分割或目标检测领域的一个具体应用,国际上提出了诸多方法来解决表格区域检测问题。一些具有代表性的方法在ICDAR2013和ICDAR2017竞赛上的结果如表2和表3所示。
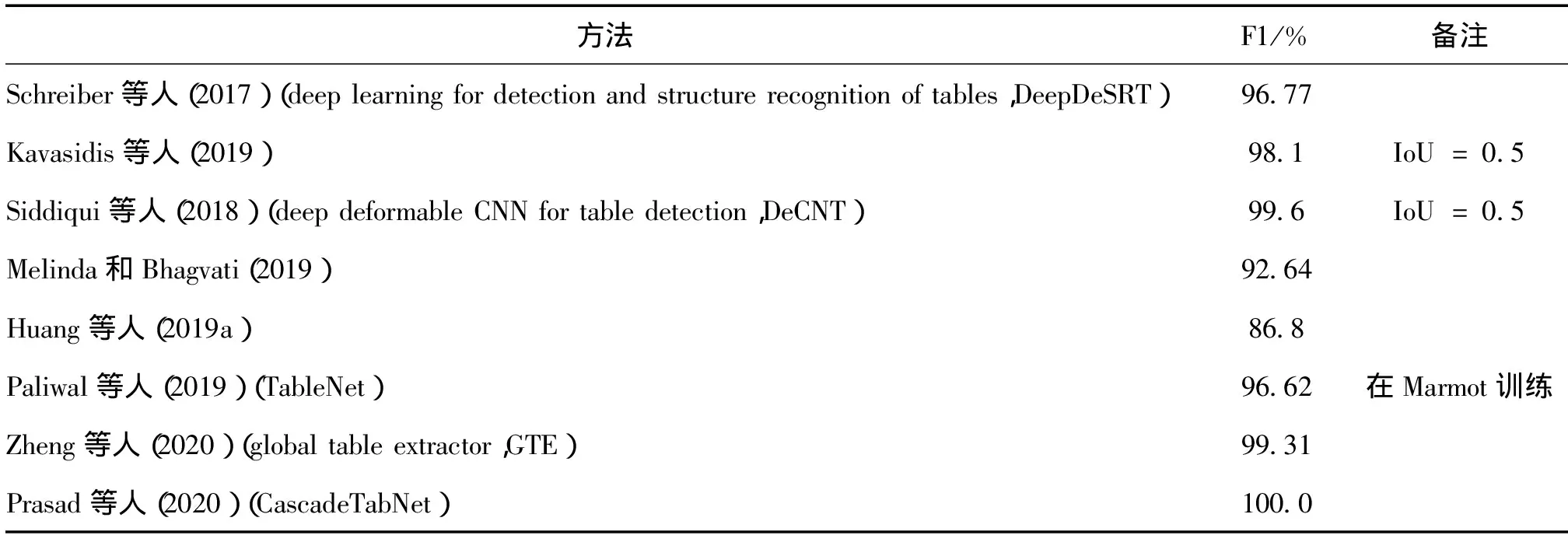
表2 ICDAR2013表格检测结果比较Table 2 Comparison results of table detection on ICDAR2013

表3 ICDAR2017表格检测结果比较Table 3 Comparison results of table detection on ICDAR2017
Schreiber等人(2017)采用了Faster R-CNN(region convolutional neural network)(Ren等,2015)作为表格检测的模型网络,来获取每个表格的区域。Gilani等人(2017)在采用相同的目标检测网络的同时,还使用了3种距离变换来增强页面图像特征。He等人(2017a)将表格检测作为文档分割的子任务,使用FCN(fully convolutional networks)(Long等,2015)作为基础模型,考虑了多尺度特征,同时进行表格、段落以及图像的边缘检测和分类,最后通过连通体分析、条件随机场等获得表格区域。Kavasidis等人(2019)同样使用了一个典型的语义分割架构,使用VGG(Visual Geometry Group)(Simonyan和Zisserman,2014)作为骨干网络,同时使用了空洞卷积(Yu和Koltun,2015)来扩大感受野, 之后再通过上采样和反卷积将特征放缩为原图尺寸,以获得每个像素的分类。使用条件随机场来平滑表格边缘,得到更加准确的候选区域,并对每个区域使用Inception(Szegedy等,2015)网络来进行最终的表格分类。Siddiqui等人(2018)提出的DeCNT(deep deformable CNN for table detection)网络将形变卷积(Dai等,2017)应用在目标检测网络中,使用了ResNet-101(He等,2016)作为特征提取网络,使用了特征金字塔(Lin等,2017)来抽取更全面的特征。Saha等人(2019)将表格检测作为文档检测中图形类目标检测的子任务,尝试了Faster R-CNN和Mask R-CNN(He等,2017b)网络, 并证明了预训练模型在表格检测中的效果。Riba等人(2019)将图神经网络(graph neural network,GNN)(Scarselli等,2009)应用到了表格检测中, 他们先检测出文档的文本区域和图像区域,以这些区域为顶点构建一个图,然后送入图网络进行特征交互,对点和边进行分类,判断每个区域是否属于表格,以及相邻的两个区域是否需要合并,从而获得最终的表格区域。Melinda和Bhagvati(2019)将表格分为封闭表格和开放表格。其中封闭表包含表格线条,可以直接得到表格区域。对于开放表则通过使用混合高斯模型和EM(expectation maximization)算法对所有文本块进行分类,判断其是否属于表格区域,然后将属于表格区域的单元格进行合并得到表格的区域。Zheng等人(2020)将单元格检测和表格检测放在同一个检测网络中,使用单元格的位置来调整表格检测的结果。此外,还有一些同时对表格进行检测和结构识别的研究,将在表格结构识别算法中进行介绍。
近年来,国内也涌现出了许多基于深度学习的表格区域检测算法。Huang等人(2019a)对Yolov3(you only look once)网络的锚进行了适应性调整,同时在后处理时去除了检测框的空白区域,过滤掉了噪声对象,使得检测的表格更加准确。Sun等人(2019)提出,基于锚的表格检测方法比较依赖于锚的设置,而锚的设置很难包含所有情况,因此借鉴CornerNet(Law和Deng,2018)的思想,在检测表格的同时回归表格的4个角的点的位置,最后再用4个点来矫正表格检测的结果,提高了检测的精度。Li等人(2019)则关注了少线表和无线表,使用对抗生成网络来使生成器重点抽取到表格的布局特征,并将此特征和检测网络的骨干网络抽取的特征进行融合,在无线表检测上取得了更好的效果。Zhang等人(2021)提出了VSR(vision, semantics and relations)网络,融合了文档的视觉和语义信息。文档以图像(视觉)和文本嵌入映射(字符级和句子级语义)的形式输入VSR。然后,通过一个双流网络提取对应模态的视觉和语义特征,这些特征随后被有效地组合到一个多尺度自适应聚合模块中。最后,结合基于GNN的关系模块,对候选组件之间的关系进行建模,并生成最终结果。
1.3 表格结构识别相关研究
表格结构识别是表格区域检测之后的任务,其目标是识别出表格的布局结构、层次结构等,将表格视觉信息转换成可重建表格的结构描述信息。这些表格结构描述信息包括:单元格的具体位置、单元格之间的关系和单元格的行列位置等。在当前的研究中,表格结构信息主要包括以下两类描述形式:1)单元格的列表(包含每个单元格的位置、单元格的行列信息和单元格的内容);2)HTML代码或Latex代码(包含单元格的位置信息,有些也会包含单元格的内容)。
1.3.1 传统的表格结构识别方法
与表格区域检测任务类似,在早期的表格结构识别方法中,研究者们通常会根据数据集特点,设计启发式算法或者使用机器学习方法来完成表格结构识别任务。
Itonori(1993)根据表格中单元格的2维布局的规律性,使用连通体分析抽取其中的文本块,然后对每个文本块进行扩展对齐形成单元格,从而得到每个单元格的物理坐标和行列位置。Rahgozar等人(1994)则根据行列来进行表格结构的识别,其先识别出图片中的文本块,然后按照文本块的位置以及两个单元格中间的空白区域做行的聚类和列的聚类,之后通过行和列的交叉得到每个单元格的位置和表格的结构。Hirayama(1995)则从表格线出发,通过平行、垂直等几何分析得到表格的行和列,并使用动态规划匹配的方法对各个内容块进行逻辑关系识别,来恢复表格的结构。Zuyev(1997)使用视觉特征进行表格的识别,使用行线和列线以及空白区域进行单元格分割。该算法已经应用到FineReader OCR产品之中。Kieninger(1998)提出了T-Recs(table recognition system)系统,以词语区域的框作为输入,并通过聚类和列分解等启发式方法,输出各个文本框对应的信息,恢复表格的结构。随后,其又在此基础上提出了T-Recs++系统(Kieninger和Dengel,2001),进一步提升了识别效果。Amano等人(2001)创新性地引入了文本的语义信息,首先将文档分解为一组框,并将它们半自动地分为4种类型:空白、插入、指示和解释。然后根据文档结构语法中定义的语义和几何知识,分析表示框与其关联条目之间的框关系。Wang等人(2004)将表格结构定义为一棵树,提出了一种基于优化方法设计的表结构理解算法。该算法通过对训练集中的几何分布进行学习来优化参数,得到表格的结构。同样使用树结构定义表格结构的还有Ishitani等人(2005), 其使用了DOM (document object model)树来表示表格,从表格的输入图像中提取单元格特征。然后对每个单元格进行分类,识别出不规则的表格,并对其进行修改以形成规则的单元格排布。Hassan和Baumgartner(2007)、Shigarov等人(2016)则以PDF文档为表格识别的载体,从PDF文档中反解出表格视觉信息。后者还提出了一种可配置的启发式方法框架。
国内的表格结构识别研究起步较晚,因此传统的启发式方法和机器学习方法较少。在早期,Liu等人(1995)提出了表格框线模板方法,使用表格的框架线构成框架模板,可以从拓扑上或几何上反映表格的结构。然后提出相应的项遍历算法来定位和标记表格中的项。之后Li等人(2012)使用OCR(optical character recognition)引擎抽取表单中的文本内容和文本位置,使用关键词来定位表头,然后将表头信息和表的投影信息结合起来,得到列分隔符和行分隔符,从而得到表格结构。
总体来说,表格结构识别的传统方法可以归纳为以下4种:基于行和列的分割与后处理,基于文本的检测、扩展与后处理,基于文本块的分类和后处理,以及几类方法的融合。
1.3.2 基于深度学习的表格结构识别方法
在传统的表格结构识别算法基础之上,基于深度学习的表格结构识别算法可以分为:自底向上的方法、自顶向下的方法和图像文本生成的方法。其中,自底向上的方法主要特点是先进行表格单元格和文本块的检测,再进行单元格关系的分类;自顶向下的方法则先进行表格行列的分割,之后对单元格进行合并等操作;图像文本生成方法是指基于表格图像直接生成表格结构所对应的序列文本(HTML、Latex等)。
针对近年来的一些具有代表性的方法及代表性数据集(ICDAR2013, PubTabNet),其效果总结如表4和表5所示。由于此类方法所采用的评测标准各有不同,因此在备注一栏进行具体阐述。

表4 ICDAR2013表格结构识别结果比较Table 4 Comparison results of table structure recognition on ICDAR2013

表5 PubTabNet表格结构识别结果比较Table 5 Comparison results of table structure recognition on PubTabNet
自底向上的基于单元格检测和单元格关系分类的深度学习算法的基本框架如图1所示(Qasim等,2019),图中前半部分为单元格检测阶段,后半部分为单元格关系判断阶段。

图1 自底向上的表格结构识别深度学习算法框架(Qasim等,2019)Fig.1 The framework of bottom-up algorithm for table structure recognition(Qasim et al., 2019)
Prasad等人(2020)主要在前半部分的单元格检测阶段进行研究,提出了CascadeTabNet,一种基于级联掩膜区域的CNN高分辨率网络,同时检测单元格和表格。在检测表格位置的同时,将表格分类为有线的表格和无线的表格。对于有线的表格直接使用常规的行列检测算法,并使用行列交点来确定单元格;对于无线的表格则使用检测到的单元格来预估缺失的线,进而恢复表格结构。Siddiqui等人(2019)提出的DeepTabStR网络将可变型卷积应用于目标检测网络中,同时对行、列和单元格进行检测,并根据单元格的位置特点恢复表格。还有一些研究是专注于后半部分的表格关系判断阶段,即给出单元格或文本区域,使用深度网络模型来判断单元格之间的关系。Clinchant等人(2018)在历史文档的表格识别中尝试了条件随机场和图卷积网络的作用。Qasim等人(2019)提出使用图网络来解决单元格之间的关系判断问题,首先使用OCR引擎获取图片中文本的位置和内容,之后使用卷积神经网络获取单元格的视觉特征,并以单元格位置作为位置特征,以文本的长度作为文本特征,3种特征相融合为每个文本块的特征。随后将这些文本块作为顶点构建全连接的无向图,并进行图卷积,卷积得到的特征送入DenseNet,然后判断两个文本块是否处于同一行或同一列,以及是否需要合并,最后通过启发式方法获得表格结构。另外,在训练中使用基于蒙特卡洛的采样方法,解决正负样本不均衡和单元格对内存占用过大的问题。
自顶向下的行列分割和单元格合并的基本流程如图2所示(Tensmeyer等,2019)。其基本思路是先检测单元格的行和列分隔符,将表格划分为最基本的单元,然后再使用规则类方法或深度学习方法将这些基本单元进行合并,以避开难度较大的单元格检测环节。最早期的行列分割方法忽略了单元格的跨行跨列问题,直接进行行和列的检测,而不进行后续的行列合并等操作。

图2 自顶向下的表格结构识别深度学习方法流程(Tensmeyer等,2019)Fig.2 The framework of top-down algorithm for table structure recognition(Tensmeyer et al., 2019)
Siddiqui等人(2019)将表格识别定义为一个语义分割问题,并使用了类似于编码器—解码器的架构, 编码阶段通过卷积和池化来获取表格特征,解码阶段则通过反卷积和上采样还原出和原图相同大小的特征图,并对每个像素进行分类,再通过后处理获得表格结构识别结果。Schreiber等人(2017)在其提出的DeepDeSRT系统中,以FCN(Long等,2015)为基础架构,进行行和列的语义分割。此外,由于行与行之间的间隔相对较小,在进行行检测时,此方法还会对图片的高度进行拉伸。Paliwal等人(2019)提出了TableNet, 同样使用语义分割框架,将表格检测和结构识别放在一个框架下进行处理,同时进行表格检测和行列检测。此方法针对表格检测和行列检测的不同,分别提取骨干网络中不同尺度的特征进行融合。之后又制定启发式规则对表格的行进行分割,得到表格的结构。Khan等人(2019)则认为,卷积网络受限于感受野无法获取更广的特征,同时忽略了行列(行—空白或线—行)的排布规律,会降低行列检测的准确率。因此使用了两个双向的循环神经网络进行像素级别的行列分隔符的识别。Tensmeyer等人(2019)对表格的行列分割和分割后的合并都进行了详细的讨论,提出了一个合并网络,将表格分割为最细粒度的基本单元,然后进行合并得到真正的表格结构。
Raja等人(2020)把自顶向下和自底向上的处理流程进行了融合,一方面使用检测网络来检测单元格,另一方面对检测出来的单元格进行特征抽取,对文本块对进行同行和同列的判断,从而获得表格的完整结构。
得益于Table2Latex(Deng等,2019)、TableBank(Li等,2019)等给定HTML或Latex代码的表格数据集,图片文本生成的方法逐渐兴起。其基本架构如图3所示。

图3 基于图片文本生成的表格结构识别方法框架Fig.3 The framework of image to text algorithm for table structure recognition
Deng等人(2019)使用了经典的IM2LATEX模型(Deng等,2017), 此方法使用CNN抽取特征,并使用带有注意力机制的长短期记忆网络(long short term memory, LSTM)(Hochreiter和Schmidhuber,1997)来生成对应的Latex代码。Zhong等人(2020)提出的PubTabNet数据集不仅提供了表格结构的HTML代码,同时也提供了每个单元格的文本内容。因此,他们提出了一种编码器—双解码器的模型EDD,在编码阶段单独使用了一个卷积神经网络,而在解码阶段则使用两个循环神经网络,其中一个负责解码出表格结构标签,另一个负责解码出具体的文本结果。值得注意的是,该网络设置只有结构解码器解码出“〈td〉”标签时,文本解码器才会被激活。在训练时,需要先对结构解码器单独进行训练,之后再将两个解码器联合训练。
随着深度学习的发展,以及工业界对表格识别需求的日益增长,国内的表格结构识别研究迅速发展,并产生了一批有影响力的研究成果。
在自底向上的表格结构识别研究中,Chi等人(2019)提出了GraphTSR模型,通过对PDF文档的解析,得到单元格内容以及相应的边界框。将每个单元格视做一个顶点,构建出全连接图,并根据单元格大小、位置设计了相应的特征。对于每个边,通过点与点的距离计算权重,得到一个完整的图。之后使用基于注意力机制的图网络来对每条边进行分类,判断K邻近的单元格对是否在同一行或同一列。Xue等人(2019)提出了Res2TIM系统,在使用检测网络获得各个文本区域后,将区域原图特征和经过卷积网络的特征相融合,并构建单元格对来判断两个单元格的上下左右关系,最终达到重建表格的目的。Qiao等人(2021)则将重心放在单元格检测上,提出了LGPMA网络。该网络从局部和全局角度考虑了视觉特征,充分利用了局部和全局特征的信息,通过提出的掩码重评分策略,获得更可靠的对齐单元格区域,并使用软标签的方式,巧妙解决了空白单元格对检测模型的干扰。Li等人(2021a)使用多任务的语义分割网络同时进行前景单元格和背景的表格线分割。为了消除表格尺度不一致的影响,设计了一种基于每个文档图像中平均单元格大小和划线密度的自适应图像缩放方法。Long等人(2021)在提出一个自然场景的表格识别数据集WTW的同时,还提出了Cycle-CenterNet的表格结构识别方法。他们认为过去的文档表格识别针对的都是非常规整的表格图片,而在自然场景中由于表格存在扭曲,行和列之间没有非常完备的对齐关系。他们以CenterNet(Duan等,2019)为基础,同时检测单元格的中心以及4个单元格的交汇点,这样在单元格检测完成之后就可以直接对表格结构进行恢复。
在自顶向下的行列分割方法中,Li等人(2021b)考虑到表格行和列的分类结果遵从“行—分隔符—行—分隔符—行”的规律,将行列检测视为一个逐像素的序列标注问题。先用卷积神经网络获取图像特征并视做一个行或者列的序列,随后使用序列标注网络对行和列的每个像素进行分类,得到行和列的检测效果,从而识别表格。
在图片到文本序列的方法中,He等人(2021)提出的TableMaster模型以文字识别模型Master(Lu等,2021)为基础,先对表格HTML代码进行划分,之后在解码器部分增加了一个单元格检测分支,使得单元格检测和HTML代码的生成一一对应,同步进行。同时为了解决此模型单元格检测效果相对较差的问题,该方法又使用了PSENet(Wang等,2019b)对文本块进行检测,对TableMaster的单元格检测进行矫正。
在实际场景应用中,表格结构识别的流程比以上的研究领域复杂,需要同时进行表格检测和结构识别,还需要对每个单元格的文本进行识别和信息抽取。为了提高最终效果,会采用多模型的融合,其对表格识别的研究也有重要的借鉴意义。
好未来于2021年6月—9月举办了一个表格识别技术挑战赛。本次比赛提供了2万幅包含表格的图像。这些图像来源于教育场景下学生的作业、试卷以及部分的扫描合同表。其中16 000幅图像作为训练集,提供了详细的HTML代码、单元格框以及单元格内容标注;2 000幅含有内容标注的图像作为验证集,完全没有标注的2 000幅作为测试集。比赛以TEDS作为评测指标对各个队伍的结果进行打分。
总体而言,前3名的技术方案基本思路相同,都包含表格检测、表格结构识别、文本识别和HTML代码恢复等阶段,但在各个阶段采用的模型存在差异。第1名的方法采用了Cascade R-CNN(Cai和Vasconcelos,2018)对表格进行检测,并使用了后处理以提高表格检测的准确率;随后其使用TableMaster模型(He等,2021)来预测HTML序列和单元格区域;之后使用BDN(barcode detection network)(Jia等,2020)来检测文本行,并使用CRNN(convalutional recurrent neural network)和CTC(connectionist temporal classification)(Shi等,2017)来进行文本行的识别,最后将所有结果合并起来得到最终结果。第2名采用了CDeC-Net(Agarwal等,2020)来进行表格和单元格的检测;考虑到自然场景下表格会出现的扭曲、褶皱问题,在表格检测结束之后,采用了TPS(thin plate spline)变换和仿射变换来对图像进行矫正,矫正结果保证了每个单元格行和列的对齐,之后根据坐标来直接还原出表格结构,最后采用DBNet(Liao等,2020)检测文本行,并使用CRNN和CTC的方法来识别文字。第3名在表格结构检测上使用多任务的方式,同时分割单元格和表格线并检测单元格;之后在文本识别过程中对任务进行了细化,对单元格内容进行分类,判断手写单元格、空单元格以及插图单元格。
1.4 表格内容识别相关研究
表格内容识别的研究包含两个方面,一方面是对于单元格内的文本进行识别,一般在获得单元格区域之后,使用较为鲁棒的光学字符识别方法(OCR)进行解决,这方面不属于表格识别的研究范畴,不做详细介绍;另一方面是根据整个表格内容进行的表格分类、单元格分类以及表格信息抽取等任务,这是当前表格识别研究的热点之一。
1.4.1 表格分类与单元格分类相关研究
表格分类指的是根据表格的结构或内容,对表格进行分类。Wang和Hu(2002)根据表格包含的内容将表格分为正品表(genuine table)和非正品表(non-genuine table)。其中非正品表是指仅仅使用HTML表格标签来进行网页布局的内容,并不是用来展示表格数据。他们对 HTML 中包含〈table〉标签的部分抽取了一系列特征,提出了一个可训练的机器学习方法对表格进行分类。Crestan和Pantel(2011)将表格分为两大类别:关系型知识表格以及不包含知识仅仅用于布局的表格。其中前者又细分为列表型、属性/值、矩阵型、枚举型和填空型;后者细分为导航型、格式化型。他们从表格中抽取了表格的布局特征和内容特征,进而使用有监督机器学习算法对表格进行分类。
单元格分类指的是将单元格分成表头、数据单元格等类别。Fang等人(2012a)比较了简单的启发式算法和基于机器学习的分类算法之间的效果。其中启发式算法假设表格的行列表头分别存在于表格的左边和上边,计算表格中连续的两行/列的相似性,并以从上到下/从左到右出现的第1个局部最小值当做表头和数据的分隔,从而得到表头;基于机器学习的分类算法利用了一系列能够区分表头的特征,并使用支持向量机分类器、逻辑回归和随机森林来将单元格行或列分类为表头或数据单元格。Seth和Nagy(2013)将单元格分成 5 种不同类型:行表头、列表头、数据、存根表头(stub head)和额外信息,利用表格中“每个数据单元格可以被行列表头路径的文本序列唯一确定”这一特性,来识别表格中的每个单元格的类型。Koci等人(2016)将表格中的单元格分为5个类别:元数据、表头、属性、数据和派生数据,抽取表格单元格的内容特征、单元格风格特征、字体特征、引用特征和空间特征,然后将这些特征以及标注结果输入到常用的机器学习分类器中进行学习,得到单元格类别。Gol等人(2019)综合考虑了单元格中的文本和风格特征,通过一个表格预训练模型得到每个单元格的向量,利用单元格向量将其归类到6个类别中。
国内在表格分类和单元格分类领域的研究相对较少。其中具有代表性的是北京航空航天大学和微软亚洲研究院的Dong等人(2019)的研究,他们利用 BERT(bidirectional encoder representation from Transformers)(Devlin等,2018)提取表格中的文本语义特征,并与其他手工特征一同输入到 FCNN(fully CNN) 骨干网络中,然后以3个分支网络将表格信息抽取任务、表格区域检测和单元格分类3个任务融入到这一多任务提取框架中。
1.4.2 表格信息抽取相关研究
基于表格的信息抽取任务是从表格或者包含表格的文档中提取给定的关键信息字段,并对其进行归纳、分析。从实际应用的角度来看,自动地从表格、票据和合同等文档中收集个人信息、重要日期、地址和金额等关键字段具有很高的应用价值。
其中具有代表性的ICDAR2019举办的表格信息提取竞赛的SROIE数据集的一些代表性结果如表6所示。
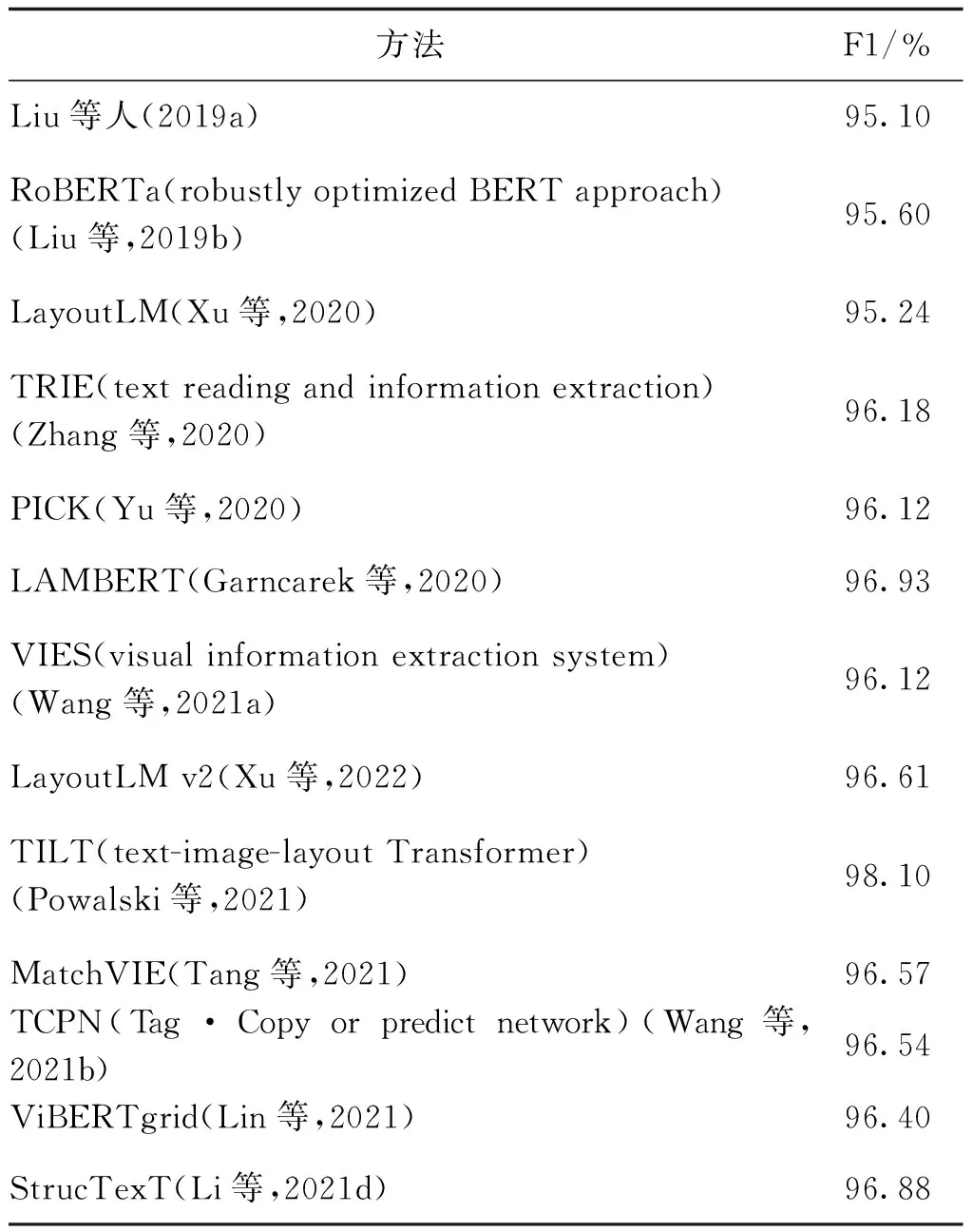
表6 SROIE数据集信息抽取结果比较Table 6 Comparison results of table information extraction on SROIE
近年来,随着自然语言处理技术的发展,一部分研究者的研究兴趣从传统的序列文本逐渐转向表格等(半)结构化文档上来,并将序列文本上先进的语言模型,例如LSTM(Hochreiter和Schmidhuber,1997),Transformer(Vaswani等,2017),GPT(generative pre-training)(Radford和Narasimhan,2018),BERT(Devlin等,2018)及LayoutLM(Xu等,2020)等应用于表格等(半)结构化文档上,取得了良好的效果,说明这些模型在自然语言处理任务中具有良好的普适性和可迁移性。其中BERT及其变体RoBERTa(Liu等,2019b)、LayoutLM及其变体LayoutLMv2(Xu等,2022)在表格信息抽取理解的各类任务中都取得了较为稳定且高效的性能,成为该领域中的基线方法。
目前常用的表格等(半)结构化文档信息抽取的公开数据集有SROIE(Huang等,2019b),FUNSD(Jaume等,2019),CORD(consolidated receipt dataset)(Park等,2019),Kleister(Graliński等,2020)等。另外,近年来的研究中很多研究者在提出信息抽取方法时,也会建立一套特定应用场景的数据集,例如中文增值税发票(Liu等,2019a)、火车票、医学处方(Yu等,2020)、出租车收据(Zhang等,2020)和试卷标题(Wang等,2021a)等。
表格信息抽取是表格内容识别中的一项基础任务,根据对表格文档表示形式的不同,可以分为基于序列、基于图和基于2维特征网格等信息抽取方法。
基于序列的方法与典型的自然语言处理方法类似,需要将表格文档首先序列化为1维文本序列,然后使用现有的序列标记模型(如LSTM-CNN(Chiu和Nichols,2016)、Bi-LSTM-CRF(Ma和Hovy,2016)、BERT(Devlin等,2018)、RoBERTa(Liu等,2019b)等)提取字段值。较为新颖的方法(如LayoutLM,LAMBERT(Garncarek等,2020)等)则会在序列文本信息之外加入表格的布局信息和结构信息,通过融合不同模态的信息、联合训练不同模态特征等方式来提高精度。
基于图的方法将每个文档页面建模为一个图,其中文本片段(单词或文本行)表示为节点。每个节点的初始表示可以结合其对应文本段的视觉、文本和位置特征。然后利用图神经网络或自注意力机制(Vaswani等,2017)在图中相邻节点之间传播信息,得到每个节点的更丰富的表示,随后将这些图节点的特征输入到分类器模型(如PICK(Yu等,2020)),或与文本特征共同输入到序列标记模型中获得所需的字段(如GraphIE(Qian等,2019)、Liu等人(2019a)、Wei等人(2020)、TRIE(Zhang等,2020)和VIES(Wang等,2021a)等)。
基于2维特征网格(2D grid)的方法将文档表示为一个包含字符特征的2D网格,然后使用标准实例分割模型从2D网格中提取字段值。这一类方法首先由Katti等人(2018)在Chargrid中提出。Chargrid引入了2D网格作为新的文本表示类型,通过将每个文档页面编码为2维字符网格,可以保留文档的2维布局,并提出一个用于结构化文档的通用文档理解处理流程,利用完全卷积的编码器—解码器网络来预测分割掩码和边界框。2D网格表示保留了文档的文本和布局信息,但忽略了图像信息,为此,VisualWordGrid(Kerroumi等,2021)将这些网格表示与文档图像的2D特征图相结合,生成更强大的多模态2D文档表示,它可以同时保存文档的视觉、文本和布局信息。BERTgrid(Denk和Reisswig,2019)对Chargrid进行了改良,将文档表示为上下文词块特征向量的网格,在网络结构中加入了BERT网络,对来自目标领域的大量未标记文档进行预训练,为文档中的每个词块计算上下文特征向量。与其他基于2维网格的方法相比,虽然BERTgrid在网格表示中加入了语言模型BERT,但在模型训练时,预训练的BERT参数是固定的,没有充分发挥语言模型的作用。
此外,在框架构建方面,Clova AI的Hwang等人(2021)提出了一个信息抽取框架SPADE(spatial dependency parser),将信息抽取任务表述为一个空间依赖解析问题。它以端到端方式在文档中建模高度复杂的空间关系和任意数量的信息层。BROS(BERT relying on spatiality)(Hong等,2021)通过提出一种新的位置编码方法和基于区域掩蔽的训练,进一步改进了SPADE,在大规模半结构化文档上使用新的区域掩蔽策略进行预训练,同时有效地包含了输入文档的空间布局信息。Applica.ai的Powalski等人(2021)提出了一种同时学习布局信息、视觉特征和文本语义的神经网络架构TILT,以预训练的Transformer为骨干网络,将布局信息表示为注意力机制中的偏差项,并使用U-Net(Ronneberger等,2015)提取上下文的视觉特征加入到模型的输入中。
国内的研究者近年来在表格信息抽取领域取得了丰硕的成果,尤其是在基于图的信息抽取方法研究中取得了领先地位,在基础模型的构建方面也颇有建树。
在基于序列的表格信息抽取方法中,由于顺序文本上的语言模型(如Transformer、BERT等)难以捕捉表格文档的结构信息,哈尔滨工业大学和北京航空航天大学的Xu等人(2020)提出了LayoutLM模型,现在已经成为表格内容理解领域中众多研究方向的基线模型。LayoutLM模型相对于传统的序列语言模型有了明显的革新,将文档的结构信息也输入到了模型中,丰富了结构化文档的特征表示。哈尔滨工业大学和微软亚洲研究院的Xu等人(2022)随后对LayoutLM进行了优化,提出了性能更强的LayoutLMv2。阿里巴巴公司的Wang等人(2020)提出了StructBERT,将语言结构融入到预训练中,结合词结构目标和句子结构目标,利用语境表征中的语言结构来扩展BERT。这使得StructBERT能够通过强制重建单词和句子的正确顺序进行预测,从而显式地对语言结构进行建模。
在基于图的方法方面,阿里巴巴集团的Liu等人(2019a)提出了一种基于图卷积的模型,以结合富信息视觉文档中呈现的文本和视觉信息。将表格数据转化为图特征,经过训练以总结文档中文本段的上下文,并进一步与文本特征相结合以进行实体提取。徐州医科大学和平安科技(深圳)有限公司的Yu等人(2020)提出了PICK,充分而有效地利用文档的特性(包括文本、位置、布局和图像)来获得更丰富的语义表示,并结合图学习与图卷积,将图学习模块引入到现有的图架构中,没有人为预先定义图的边缘类型,而是学习一个软邻接矩阵,表示任务节点之间的关系。利用图卷积的方法,在输入信息中加入了文档的文本、图像、位置等特征,提供了更加丰富的表格表示。学习到更丰富的表示,并用于解码器,以辅助进行字符级别的序列标记。华南理工大学的Tang等人(2021)提出的MatchVIE,首次将键值匹配模型用于视觉信息抽取任务中,集成了实体的语义、位置和视觉信息,通过图网络中边的关系来评价实体的相关性,证明了对键值关系进行建模可以有效地提取视觉信息,为表格信息抽取任务提供了一个新的视角。
在基于2维特征网格的方法中,Lin等人(2021)提出了ViBERTgrid方法,拼接BERTGrid特征图到CNN中间层得到的多模态主干网络,并对参数进行联合训练,显著提高了模型的语言标识能力,将基于2维特征网格的方法与多模态融合、联合训练以及大规模预训练等方法相结合,相较于之前的同类方法有了大幅提升。
针对当下普遍流行的基于OCR结果进行表格文档信息提取所带来的高标注成本和标签歧义等弊端,华南理工大学的Wang等人(2021b)还提出了一种统一的弱监督学习框架TCPN,在编码阶段引入了一种高效的2D文档表示方法,对2维OCR结果中的语义和布局信息进行建模,在解码阶段进行OCR纠错和快速推理,同时仅使用关键信息序列作为监督,极大地节省了标注成本并避免了标签歧义。这一方法对于如何缓解对完整标注的过度依赖,以及如何减轻OCR错误带来的负面影响具有启发性。
2 国内外研究进展比较
2.1 表格检测
从总体上看,早期在表格检测识别研究上投入比较大的是美国、德国和日本等;后来随着深度学习的发展,表格检测和结构识别研究呈现了百花齐放的状态。其中比较突出的有印度的研究,在IBM公司支持下的澳大利亚、美国的一些研究,以及国内大学和互联网公司的一系列研究。目前,工业界也涌现了一大批表格检测和识别的服务。国外的一些大型云服务商已经在他们的平台上提供了表格检测和识别的功能,比如亚马逊的Textact服务、微软的Azure服务等。而在国内,既有一些提供表格检测和识别等云端基础服务的互联网公司,例如百度、阿里巴巴、腾讯、华为和网易等,也有一些深耕于相关领域多年的专业服务提供商,例如庖丁科技、好未来等。
2.2 表格结构识别
从表格结构识别的效果上看,国内目前已经处于世界较为领先的水平。2020年末和2021年初由IBM公司发起举办了ICDAR2021科学文档解析比赛(Jimeno-Yepes等,2021),其中的任务二——表格识别任务,吸引了来自国内外的多个公司、学校参加。国内许多公司都参与了这场比赛,其中海康威视提出的LGPMA模型和平安科技提出的TableMaster模型分别取得了比赛的第1、2名。由此可见,在表格检测和结构识别的研究领域,尤其是在应用方面,国内的研究者已经取得了国际领先的地位。
从数据集上看,国外的数据集主要为类PDF文档,其中的表格结构比较规整,不存在扭曲、阴影等问题,例如SciTSR、PubTabNet等。而国内除了规整文档的表格数据集Tablebank之外,已经开始出现自然场景表格的数据集,例如WTW、NTable、TAL_OCR_TABLE比赛等数据集,这些数据集中应用场景更丰富,也对表格识别方法提出了进一步的挑战。
2.3 表格内容识别
在表格内容识别的各个领域,国内外研究者研究方向和方法选择上呈现出了不同的偏好。在语言模型构建方面,由于目前表格内容识别领域常用的模型仍以序列语言模型的改进为主,国外起步较早,技术积累更为丰富,LSTM、Transformer、BERT等一系列经典模型在表格内容识别任务中均取得了较好的效果。但国内近年来出现了LayoutLM、StructBERT等先进的文档表征模型,这些模型专门针对表格等(半)结构化文档进行设计,并成为相关领域常用的基线模型之一,在基础模型构建的方面呈现出了较好的发展势头。
具体而言,在表格信息抽取方面,国内的研究者在基于图和基于2维特征网格的方法上居于世界领先地位,PICK、MatchVIE和ViBERTGrid等方法在各类信息抽取任务榜单中居于前列;国外的研究者在基于序列的方法上较为突出,提出了LAMBERT、TILT等一系列表现优异的模型,这与国外积累已久的语言模型发展经验密不可分,在基于2维特征网格的方法上国外起步更早,提出了Chargrid和BERTgrid等经典模型,而对于基于图的方法研究较少。总体而言,近年来国内外研究者对表格内容识别均有很高的研究热情,这一领域的方法也呈现出多样化发展的趋势。
3 发展趋势与展望
对于表格区域检测,其准确率已经达到了比较高的水平。而检测作为识别的一部分,两者逐渐一体化,单独的检测逐渐弱化。如何让检测和结构识别的结果相互促进将是以后研究的方向和重点。
由于表格应用场景较为广泛,表格形式多种多样,文档图像质量参差不齐,表格结构识别仍存在着较大的挑战。具体表现为:1)跨页表格对结构识别带来的识别困难;2)表格线未对齐带来的行列判定困难;3)表格嵌套(某些小表格是大表格的单元格)带来的识别困难;4)一些非常规的表格线标注形式;5)现实场景带来的扭曲、褶皱和光照等问题。
对于表格结构识别,现阶段主流的方案包括两种:1)单元格检测+单元格关系判断;2)编码解码器同时生成HTML或Latex代码以及相对应的单元格位置。方案1)主要关注如何检测出更准确的单元格,在后续研究中可尝试使用表格文本的语义信息来提高;方案2)主要关注生成的代码过长时,准确率的降低以及回归的单元格框漂移等问题,可尝试由目标检测网络提出单元格候选框来改善。未来随着表格应用场景的增加,表格数据集的丰富,现实场景的表格识别以及表格识别的预训练模型都是值得深入挖掘的方向。
对于表格内容识别与理解,总体来说,随着自然语言模型的成熟和发展,自然语言处理的方法所能处理的信息形式已经不仅仅局限于1维的顺序文本,研究者们对于表格、票据等(半)结构化文档信息提取的研究热情日益增长。然而,由于表格形式复杂多样,并涉及各个行业的专业知识,目前研究者们面临着两大挑战:一方面是表格信息的表示方式难以统一,不同形式的表格有着不同形式的结构关系,很难构建出从表格信息到机器表征的通用识别框架,目前的大部分研究还处于针对某类特定的表格数据进行性能优化的阶段;另一方面,对于表格的查询、问答和文本生成等以内容为主导的任务,由于表格数据通常具有一定的专业性且表格中表达的语义不唯一,数据的标注难度很大且成本高昂,训练出的模型迁移能力较差。
随着深度学习技术的发展,大规模预训练模型已经成为自然语言处理领域中广泛认可的有效方法,表格内容的识别及理解在近年来快速发展,但在这一领域中目前并没有出现具有关键影响力的大规模预训练表格理解和表格生成模型。目前常用的方案大多都是对已有的语言模型进行改进,尽管这类方法针对某类具体问题可能是行之有效的,但往往不能很好地应用于其他表格内容识别相关的任务中。因此,寻找并构建出针对表格结构的大规模预训练模型,或是构建出在顺序文本、结构化文本和场景文本等多种形式的文档结构中都有良好表现的预训练语言模型,也是该领域目前面临的一大挑战和重要研究方向。
就整体趋势而言,一方面表格内容识别的任务具有具象化的特征,新的任务和新的应用场景纷纷出现,体现出了很高的应用价值,相关的任务类型和涵盖的领域也趋于具体,出现了很多专门针对具体问题的方法和模型;另一方面,表格内容识别也具有理论意义,研究者们对于基础模型的构建具有很高的研究兴趣,一些与表格内容识别相关的方法已经体现出了很高的泛化能力,能适用于序列文本、结构化文本和场景文本等不同类型的对象。在抽象层次,力图构建泛化性更好的基于文档的表征模型,寻找更加具有普适性的方法来描述、理解和处理表格信息,也是未来的研究热点之一。
致 谢本文由中国图象图形学学会文档图像分析与识别专业委员会组织撰写,该专委会更多详情请见链接:http://www.csig.org.cn/detail/2551。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
电脑爱好者(2021年12期)2021-06-22
电脑爱好者(2021年9期)2021-05-12
电脑爱好者(2021年8期)2021-04-21
小天使·三年级语数英综合(2020年4期)2020-12-23
数学大王·趣味逻辑(2020年6期)2020-06-22
数学大王·趣味逻辑(2020年5期)2020-06-19
高中时代(2017年7期)2018-02-24
小天使·六年级语数英综合(2017年10期)2017-10-20
