
藏汉跨语言文本剽窃检测数据集
2022-07-03 14:05:12鲍薇董建徐洋申影利戚肖克
中国科学数据(中英文网络版) 2022年2期
鲍薇,董建,2,徐洋,申影利,戚肖克
1.中国电子技术标准化研究院,北京 100007
2.北京航空航天大学,北京 100191
3.中央民族大学,北京 100081
4.中国政法大学,北京 102249
引 言
跨语言文本剽窃检测可以检测出从一种语言翻译抄袭形成文章的现象,可用于论文、著作等的检测,在知识产权保护方面具有重要应用价值。但当前的跨语言文本剽窃检测研究多为中英,英法等[1],对藏文等低资源语言的研究较少,主要包括基于语法的文本剽窃检测方法、基于词典的方法、基于平行/可比语料的方法、基于机器翻译的方法。SemEval是ACL举办的针对文本语义相似度计算研究的评测任务,连续多年开展单语言、多语言语义相似度计算评测任务。在SemEval2016英语-西班牙语跨语言文本相似度计算评测任务中,CNRC[2]抽取句子的词法语义特征,结合句对的浅层语义结构,在英语-西班牙语任务上的皮尔森相关系数达到了0.567。FBK[3]使用机器翻译中的质量评估特征和双语词向量特征,结合回归模型,在该任务上的皮尔森相关系数达到了0.3953。
目前,可用于跨语言文本剽窃检测的公开语料资源较少,多是使用信息检索、句子相似度计算任务的语料资源。Ferrero等人建立的包含35篇英语-法语自然科学研究论文的可比语料库,其中,法语文章来源于1997-2014 TALN和2006-2011 RNTI,英语文章来源于谷歌学术。CLEF-PAN 2011年文本剽窃评测任务[4]中提供了 388篇英语-海地语的跨语言文档,标注人员对 5031篇英文文章进行机器或人工翻译,生成388篇“剽窃”的海地语文档。SemEval 2016年和2017年评测任务中也提供了少量用于跨语言文本相似度计算的语料,涉及的语言包括英语-西班牙语、英语-阿拉伯语、英语-土耳其语,语料格式为“[英文句子,西班牙语句子,相似度值]”。
为了缓解低资源语言的数据缺少问题,在机器翻译任务中,多位学者使用数据增强方法生成语料。Sennrich[5]最早提出使用数据增强方法,基于单语语料构造伪平行句对,扩充机器学习模型训练语料。Fadaee[6]在训练语料中将部分低频词替换为高频词,减少低频词在训练语料中出现的频次,降低了低频词对机器翻译模型的负面影响。蔡子龙等人[7]在藏汉机器翻译训练语料中,对句子块中相似的模块进行位置调换,使训练语料扩充了一倍,丰富了句子的结构,实验获得了4个双语评估基础值(Bilingual evaluation understudy,BLEU)的提高。李家宁等人[8]梳理总结了文本分类任务中的数据增强方法,如在文本数据中将性别相关词语替换成相反性别的对应词语,并在西班牙语等某些性别与语法关联紧密的语言中,对性别词语进行替换后,对文本的词形、句法标签进行调整;在情感分类任务中,匹配含义相近标签相反的文本寻找因果词,并替换为反义词。
本研究采用数据增强(Data Augment)的数据扩充方法,构建了藏汉跨语言文本剽窃检测数据集。该数据集包含标注相似度值标签的15万藏汉句对,为研究藏汉文本剽窃检测提供数据基础。
1 数据采集和处理方法
1.1 数据采集方法
本研究所建立的跨语言文本剽窃检测数据集,使用的原始数据包括单语语义相似度评测语料和跨语言机器翻译平行语料。单语语义相似度评测语料为SemEval 2014年英语评测语料SICK,共包括10,000个英文单语句对,每句带有人工标注的句子相似度值标签,相似度值范围为[0,5]。其中,0表示两个句子无任何内容相似,5表示两个句子的内容完全相同,语料标注内容如表1所示。标注标签包括句对ID、句子A、句子B、蕴含标签(neutral-中性、entailment-蕴涵、contradiction-矛盾,用于判断文本蕴含关系)、相关度值、蕴含_AB、蕴含_BA、句子A的来源、句子B的来源、句子A所属的数据集、句子B所属的数据集、集合(开发集、训练集、测试集)。跨语言机器翻译平行语料为CWMT评测中提供的14.6万句对藏汉平行语料。

表1 SICK语料标注内容Table 1 Annotations of SICK corpus
由于汉文、藏文缺少人工标注相似度值标签的语料,对新语料进行人工标注需要耗费大量人力和物力。所以本研究首先使用将 SICK语料中的英文句对翻译成相对应的汉文句对和藏文句对,最终形成英文、汉文、藏文三种单语语料库以及英-汉、英-藏、汉-藏三种跨语言语料库,分别用SICK_en、SICK_cn、SICK_tib、SICK_en-cn、SICK_en-tib、SICK_cn-tib进行表示。本研究所使用的藏文实验语料SICK_tib和藏汉语料SICK_cn-tib均为机器翻译产生的语料,因藏汉翻译系统本身存在一定的误差,导致藏文句子可能存在翻译不准确的问题。本研究针对藏汉文本的剽窃检测,不针对藏汉机器翻译研究,本研究未对机器翻译的藏文语料进行修改。
1.2 数据预处理
在低资源语言场景下,如何利用丰富的单语资源和其他领域资源来扩充数据集尤为重要。近几年,数据增强方法被成功应用在机器翻译、语言模型训练以及文本分类中,尤其在低资源语言机器翻译研究中,用于增加深度学习所需的大规模训练语料,缓解数据稀疏问题。
本研究建立的藏汉跨语言文本剽窃检测数据集,使用数据增强方法扩充语料。具体的处理步骤为:
第一步,将SICK语料中的英文句对翻译成相对应的汉文句对、藏文句对,最终形成英文SICK_en、汉文SICK_cn、藏文SICK_tib三种单语语料库,以及英-汉SICK_en-cn、英-藏SICK_en-tib、汉-藏SICK_cn-tib三种跨语言语料库。其中,SICK语料中英文句对均有人工标注的相似度值,相似度值范围为[0,5]。其中,0表示两个句子意义不相同,5表示两个句子意义相同。因此,对应翻译的汉文句对、藏文句对的相似度值与英文句对相同。表2给出了以上语料库的句子样例。

表2 语料库中的句子样例Table 2 Sentence samples in the corpus
第二步,使用 SCIK_cn语料库中的 10,000个汉语句对训练汉语单语孪生长短时记忆网络模型[9],网络模型的输入为两个汉语句子,输出为这两个句子的相似度值。其中,训练集中的相似度值同SICK语料中人工标注的相似度值。调整参数使模型性能达到最优。
第三步,利用训练好的汉语单语孪生长短时记忆网络模型对藏汉平行语料SICK_cn-tib中的汉语句对计算其相似度值,即输入SICK_cn-tib中的任意两个汉语句子到网络中计算,输出为这两个句子的相似度值,该过程如式(1)所示。例如,对表3所示的cn1和cn2两个汉语句子,即“他全神注视着这片金黄色的景色。”和“他以勇气赢得大家的尊敬。”,网络模型输出得到的相似度值为 1.6,即表示cn1和cn2的相似度值sim1为1.6。
其中,similarity()表示已训练的单语孪生长短时记忆网络模型。cn1、cn2代表输入到模型中的两个汉语句子,sim1表示模型输出的相似度值。
第四步,计算藏汉平行语料SICK_cn-tib中任意组合的藏汉句对的相似度值。具体操作如下:由于藏汉平行句对中平行的句子语义完全相同,即如表3所示的cn1与tib1两个藏汉平行句对的相似度值为5,cn2与tib2两个藏汉平行句对的相似度值为5,因此,表3中tib1和tib2的相似度值等于cn1和cn2的相似度值,也是sim1,即获得了包含相似度值标签的句对。以此类推,对cn1-tib1、cn2-tib2两个藏汉句对的相似度值等于 cn1和 cn2的相似度值,也是 sim1,最终可得出 cn1-tib1、cn2-tib2、cn1-tib2、cn2-tib1四个带有相似度值标签的藏汉跨语言句对。计算流程如下:
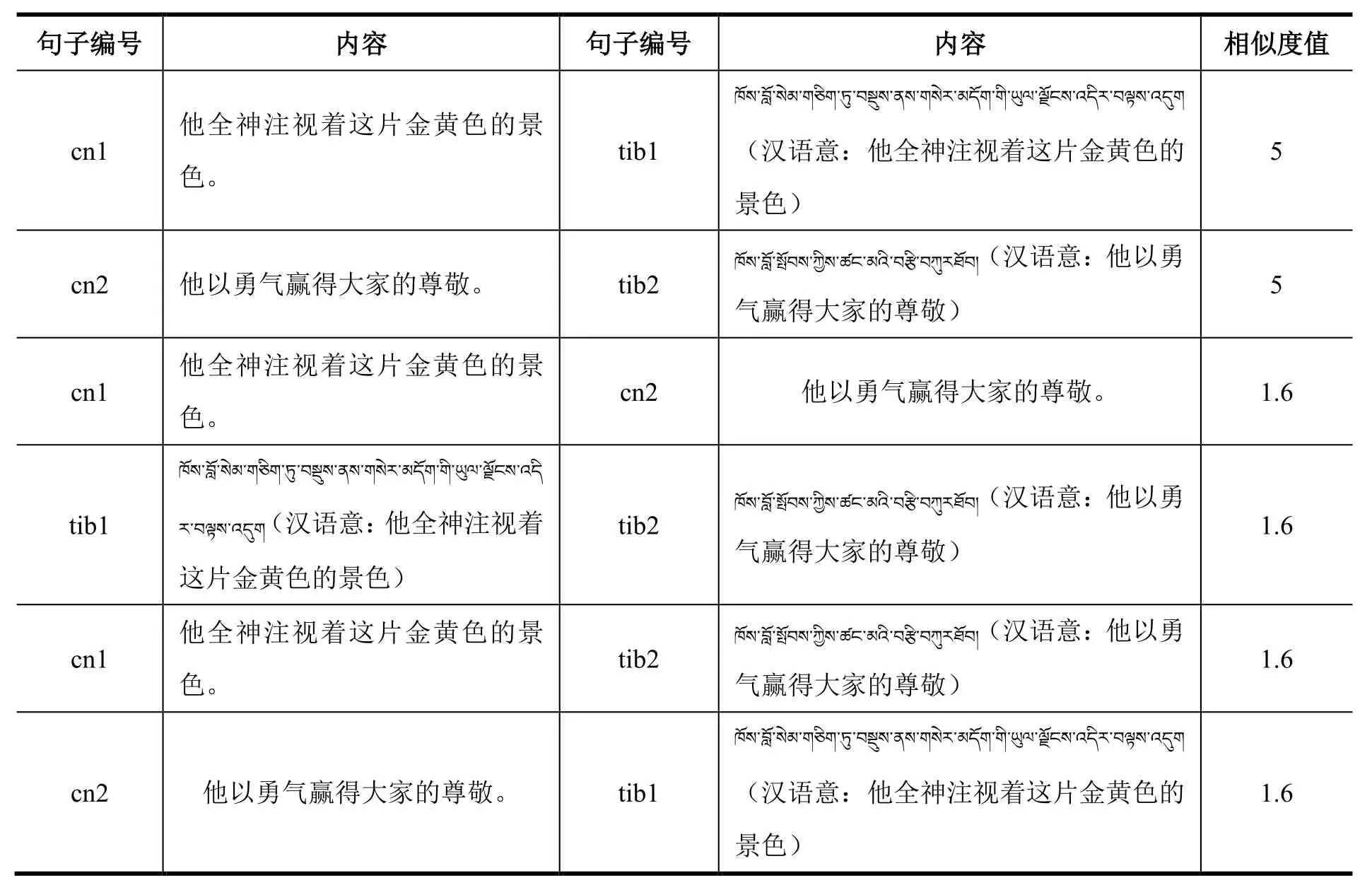
表3 基于数据增强方法生成的藏汉句对样例Table 3 Samples of Tibetan-Chinese sentence pairs based on data augmentation
其中,cn1、cn2代表两个汉语句子,tib1、tib2代表两个藏文句子,sim1是两个句子的相似度值。
2 数据样本描述
2.1 数据结构
本数据集中包含一张数据表。表中有3个字段,包括汉文句子、藏文句子、句子相似度值。数据集共包括15万个藏汉句对。
2.2 数据样本展示
基于数据增强方法生成的藏汉句对示例如表4所示。

表4 藏汉跨语言文本剽窃检测数据集示例Table 4 Samples of Tibetan-Chinese cross-language text plagiarism detection dataset
3 数据质量控制和评估
本研究使用基于数据增强方法生成的藏汉语料,在文献[9]中的藏汉跨语言文本剽窃检测模型中进行实验验证,实验结果表明,生成语料大幅提升了模型性能。实验中使用皮尔森相关系数ρ(Pearson correlation coefficients)、平均平方误差MSE(Mean-square error)和斯皮尔曼相关性系数ρs(Spearman correlation coefficient)衡量系统预测句对的相似度值与人工标注的相似度值之间的差异。
从表5中实验结果对比可以看出,使用原始语料SICK_tib中10,000藏文句对训练的模型,藏汉跨语言剽窃检测模型的皮尔森相关系数为0.1505,表明模型结果与人工标注结果只达到弱相关程度。实验中不断增加生成语料,皮尔森相关系数不断提升。语料量增加至15万句对时,皮尔森相关系数达到0.4746,较基线结果提升了0.25,平均平方误差降低了1.6,斯皮尔曼相关性系数提升了0.38,模型输出的句对相似度值与人工标注的相似度值达到了中等程度相关。可以看出,本数据集中的数据对藏汉跨语言文本剽窃检测研究起到积极作用。实验结果表明,本研究中基于数据增强方法扩充的藏汉语料可以显著提升藏汉跨语言文本剽窃检测实验结果。
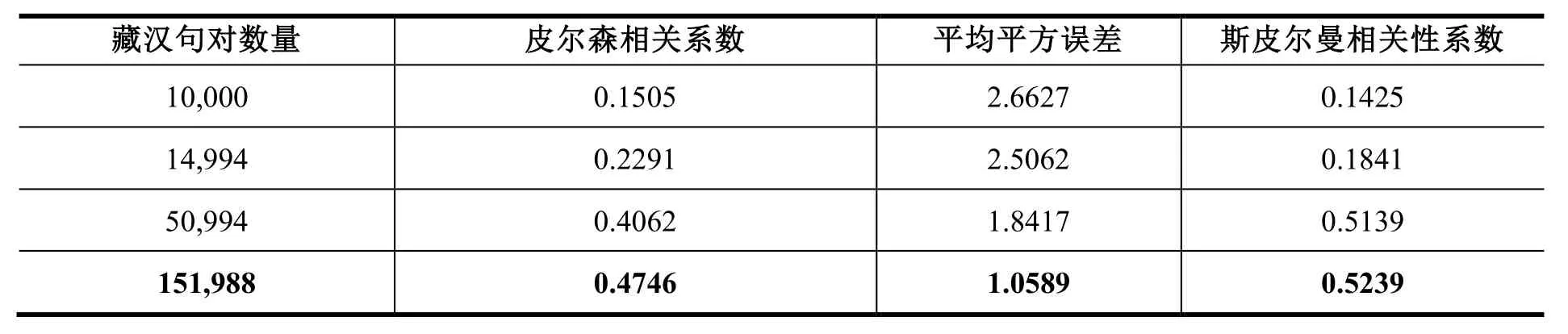
表5 基于数据增强的藏汉跨语言剽窃检测实验结果Table 5 Experimental results of Tibetan-Chinese cross-language plagiarism detection based on data augmentation
4 数据价值
本研究从少数民族语言信息处理的实际需要出发,建立的数据集不仅可用于藏汉跨语言文本剽窃检测,也可用于藏汉句子相似度计算、语义计算等其他任务中,为低资源语言自然语言处理做出贡献。另一方面,本研究在建立数据集中所使用的数据增强方法,扩充了藏汉实验语料,有效地解决了语料稀缺问题,为训练大规模神经网络模型奠定基础,也对其他低资源语言相关研究提供了研究方法。
数据作者分工职责
鲍薇(1990—),女,江苏徐州人,博士,工程师,研究方向为人工智能标准化、自然语言处理、语音信号处理。主要承担工作:基于数据增强方法计算数据相似度、论文撰写。
董建(1985—),男,山东单县人,博士在读,高级工程师,研究方向为人工智能、大数据、基础软件。主要承担工作:修改论文。
徐洋(1983—),女,辽宁沈阳人,硕士,高级工程师,研究方向为人工智能标准化、语音信号处理。主要承担工作:数据集预处理。
申影利(1994—),女,安徽亳州人,博士在读,研究方向为机器翻译。主要承担工作:数据校对。
戚肖克(1985—),女,山东菏泽人,博士,副教授,研究方向为语音信号处理、自然语言处理。主要承担工作:数据集整合。
猜你喜欢
交通科技与管理(2022年19期)2022-10-12 03:57:30
客联(2022年4期)2022-07-06 05:46:23
黄河之声(2022年4期)2022-06-21 06:54:52
布达拉(2020年3期)2020-04-13 10:00:07
西夏学(2019年1期)2019-02-10 06:22:34
西藏大学学报(自然科学版)(2016年1期)2016-11-15 05:23:31
电讯技术(2016年8期)2016-11-02 05:40:50
科技传播(2016年17期)2016-10-10 01:46:58
新闻传播(2016年17期)2016-07-19 10:12:05
西藏科技(2015年12期)2015-09-26 12:13:51
