
适用于电力场景的人工智能中台技术研究与探索
2022-07-02 08:54张凌浩潘文分吴凯军
四川电力技术 2022年3期
张凌浩,潘文分,庞 博,吴凯军,张 颉
(1.国网四川省电力公司电力科学研究院,四川 成都 610041;2.国网四川省电力公司凉山供电公司,四川 凉山 615000)
0 引 言
随着人工智能技术的飞速发展,越来越多的行业引进人工智能技术以解决行业中繁杂、耗时、强度大的工作,电力行业也不例外[1]。在电力系统中,输电、变电环节发挥着重要作用。变电站巡检、输电线路巡检有很多繁杂、重复的工作,线路、设备运行维护检修工作量大。一个基层线路班组每日的巡检工作会产生上千张巡检图片,而在上线了通道可视化系统之后,国网四川省电力公司平均每小时就会采集到5万余张现场照片。这些照片如果通过人工判别将会消耗大量时间精力。因此,国网四川省电力公司近年来利用人工智能算法对采集数据图像进行设备缺陷异常智能检测,逐步实现输变电的智能巡检运行维护。
人工智能在电力行业的应用包括计算机视觉、语音处理、光学字符识别(optical character recognition,OCR)、自然语言处理及知识图谱等方向。其中计算机视觉应用主要用以实现图像识别、目标检测和实例分割等目标。以目标检测算法YOLOv3[2]为例,其核心思想是将图像划分成多个网格,若某个待检测物体的中心落在图像中所划分的一个网格内,该网格负责预测该目标位置和类别,每个网格要预测多个边界框并给出相应概率;最后,根据概率判断哪个边框是物体所在完整边框。
基于深度学习技术,越来越多的智能模型应用到电力行业实现基层减负、工作效率提升。文献[3]采用主动学习和半监督自训练交替迭代训练的方式,有效提升了图像标注效率。文献[4]基于迁移学习的思想,利用模型微调法对预训练模型VGG_CNN_M_1024和Faster R-CNN进行训练,实现推土机和挖掘机造成的输电线路外力破坏检测。文献[5]提出基于迁移学习的预训练方法,训练YOLOv3模型,实现在少量数据下,对防震锤与线夹检测识别,降低模型训练成本,提高模型准确性。文献[6]提出云-端协同的变电站机器人智能巡检新模式,以人工智能为核心技术,实现变电站巡检机器人实时巡检分析。文献[7]基于深度神经网络,实现变电站仪表类型识别及表计自动读数。文献[8]基于图像识别技术和移动边缘计算技术,将视频图像分析能力分散在边端,快速定位输电线路设备故障,提高运检效率。
近年来,人工智能中台技术被广泛提出,提供云化人工智能平台级解决方案。文献[9]提出了一种适用于调控领域的人工智能平台,主要用于支撑知识图谱和调度分析计算方面的人工智能应用。文献[10]主要解决传统人工智能平台人机交互之间的问题。文献[11]重点提出了一种资源调度方法。
上述技术在电力特定场景中的应用具有一定成效,但仍存在以下问题:
1)模型开发通常和业务系统具有紧耦合关系,部署效率低,资源浪费较大,且很难实现共建共享;
2)人工智能算法普遍需要大量样本进行模型训练,且需要大量人工进行标注,各单位样本少且分散,样本收集不方便,数据标注困难;
3)由于模型训练框架与推理框架不同,不同架构下,模型不能直接使用,需要在新框架下再开发,导致模型迁移不方便,造成成本浪费;
4)在实时性要求较高场景下,需要模型部署到边端设备,由于边端设备分布广,与云端架构差异大,将模型迁移到边端设备上运行时,需针对每台设备架构进行单独适配,模型部署困难,导致模型迁移成本高。
为解决上述问题,下面提出一套适用于电力场景的人工智能中台技术架构,以容器和容器编排引擎kubernetes(K8s)为底层架构实现资源灵活调度,同时包括数据回流、图像智能标注、模型预训练、模型转换等关键技术,提升了电力人工智能技术的易用性。首先,通过数据回流实现在调用模型服务预测时同步收集样本,同时通过主动学习方法,实现样本自动标注;然后,考虑到电力场景的相似性,引入迁移学习技术,对预训练模型进行网络参数二次优化实现知识迁移;最后,通过模型转换,实现云端架构模型自动转换,部署至边端设备。通过人工智能中台技术,可以降低人工智能模型开发和适配难度,其易用性显著提升。
1 电力人工智能中台技术架构
人工智能应用全流程包括样本收集、样本标注、模型生产和推理应用,针对引言中提到的几个问题,给出相应解决办法,总体设计框图如图1所示。

图1 电力人工智能中台技术架构
在该架构下,模型的开发、训练、推理环境全部采用应用容器引擎(Docker)的方式独立运行,其中需要图形处理器(graphics processing unit,GPU)的环境采用Nvidia-Docker方式,使得容器内部可以直接访问到底层物理GPU资源。通过虚拟化技术,可以将GPU分成逻辑上的多个分片,进一步提升了资源利用率。存储资源统一采用GlusterFS架构管理,GlusterFS是一种分布式文件系统,具有强大的横向扩展能力,通常采用3副本的方式,提供数据可靠性保障。而中台整个容器调度采用K8s架构,可以实现负载均衡、弹性扩容等灵活调度和扩展功能,使得整个人工智能中台更加高效可靠。
样本收集方面,通常都是在线下从不同渠道进行收集,再上传至人工智能中台,现引入数据回流的思想,实现样本自动收集。电力人工智能应用通常以容器服务的形式部署在中台,客户端(业务系统端)与云端服务之间的通信通过应用程序接口(application programming interface,API)调用实现。以图像目标检测为例,客户端通过服务接口传输待识别的图片和相关请求参数,云端模型识别后输出目标位置、类别、置信度等信息。考虑到样本自动收集,采用样本回流的方式,模型输出常规信息的同时输出图片至样本库中,并根据模型返回的类别和可信度值进行分类保存,实现数据筛选、收集自动化。
数据标注方面,基于已标注信息,可以通过人工智能(artificial intelligence,AI)模型对数据进行智能标注,标注人员在此基础上进行审核纠正。采用目标检测模型对图像进行物体检测,并将结果输出为标注文件,实现样本自动标注;同时,引入主动学习方法,优先挑选出标注较难或比较有代表性的图像进行标注展示,若不符合预期,则将无法识别的图片进行人工修正,继续训练标注模型,直到标注达到预期,再将模型用于全局化标注。
模型训练方面,针对某些实际场景样本数据较少、模型训练效果不好的情况,引入迁移学习的思想,将其他相近任务的已有模型作为预训练模型,使用预训练模型权重参数并使用微调法进行训练,在目标数据量少的情况下也能得到很好的效果。
模型推理方面,对于硬件架构、模型框架不同导致模型无法运行的情况,基于开放神经网络交换(open neural network exchange,ONNX)格式将模型转换为适配边端设备的模型再进行下发,提高模型部署智能化水平,减少模型部署时间,提升模型的适配性。
2 基于主动学习的样本标注
2.1 主动学习
样本质量往往影响训练模型的效果,选取一部分最有价值的样本数据进行标注、训练,得到同样效果甚至更好的模型是热点方法。其核心任务是筛选出最具有代表性的样本,主动学习正好可以实现这一任务。主动学习[12]是机器学习的一个分支,其思想是从未标注样本中选择对模型有价值的数据从而提高模型效果。基于数据池的主动学习可以通过使用尽可能少的标注样本,训练出较好的分类器模型,实现大量未标注样本的自动标注。
基于数据池的主动学习循环如图2所示,其过程大致是:标注少量数据进行模型训练;再从大量未标注样本池中筛选出关键图片数据,提交标注请求,由标注人员进行人工标注;再将新标注的样本加入训练集,重新训练模型;依次迭代循环。
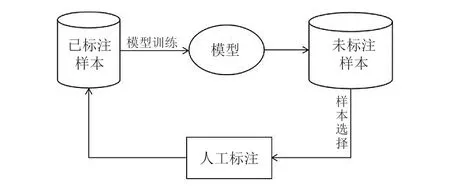
图2 基于池的主动学习循环
主动学习是通过查询函数选择出最有用的样本,查询函数常用策略是不确定性准则和差异性准则[13]。不确定性策略就是找出不确定性高的样本。不确定性越高的样本,包含的信息量越丰富,对模型训练越有用。差异性指的是选择样本之间应有差异,避免选择样本信息重复,有效避免数据冗余。部分主动学习查询函数是基于信息熵进行设计。
2.2 智能标注
数据标注是对原始数据打标签,输送到人工智能模型进行训练学习。而模型训练数据越多,模型准确率越高,由此,大量训练数据使数据标注的工作量变大。数据标注通常是专业标注人员借助标注工具进行手工标注,重复地拉框、标点,标注强度大,整体标注效率底下。随着人工智能技术的发展,数据标注朝着自动标注方向发展,目前数据标注还不能实现完全自动化,但可以在机器标注+人工标注的前提下,尽量减少人工,将机器标注比例逐步提升。这里采用一种基于主动学习的智能标注方法,实现数据标注半自动化,提升标注速率和标注质量。
下面主要研究目标检测中的图像标注,结合主动学习的思想,实现图像智能标注,实现流程如图3所示。该方法中,工作人员不再需要从头开始标注,只需要判断标注是否正确并进行调整,极大地降低人力成本并使标注速度大幅提升。智能标注算法步骤如下:
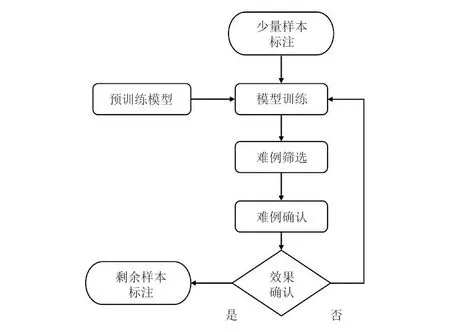
图3 基于主动学习的智能标注流程
1)数据准备:从待标注样本中随机挑选不低于50张照片进行手动标注。
2)模型训练:采用基于电力场景下预训练目标检测模型YOLOv3作为预训练模型进行训练。
3)难例筛选:基于主动学习,从未标注样本中筛选出最具价值性的难例样本进行标注,将标注结果输出成标注文件。
4)难例确认:人工审核模型标注照片,若不满足标注要求,人工修正标注,将新标注数据加入到训练数据,重复循环步骤2至步骤4,直到满足要求;若满足标注要求,即启动模型标注剩余所有照片。
3 基于预训练模型的迁移学习技术
3.1 迁移学习
迁移学习是将一任务中获得的知识应用到另一目标任务中[14],其定义如下:
域(Domain):D={χ,P(X)},式中χ为特征空间,P(X)为边缘概率分布。
任务(Task):T={y,f(·)},式中y为标签空间,f(·)为目标函数。
迁移学习(transfer learning):给定一个源域DS和学习任务TS,一个目标域DT和学习任务TT,迁移学习利用DS和TS中的知识来帮助学习在目标域DT的目标函数fT(·),其中DS不等于DT,TS不等于TT。
传统的机器学习通常是从零开始学习每一个任务,从迁移学习流程(见图4)可以看出,迁移学习是在以前任务的基础上,将以前的一些任务中的知识转移到目标任务中。
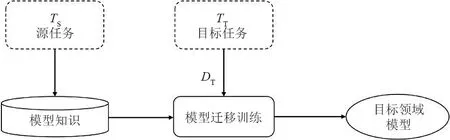
图4 迁移学习流程
以图像识别中卷积神经网络为例,深度神经网络前几层是提取线条、轮廓等通用特征,对该网络的前几层进行迁移,可以减少深度神经网络的训练时间。迁移学习在深度学习中通常有2类用法:1)冻结与训练,将相近任务模型的大部分参数直接应用到新任务训练中,重新训练部分网络层。以神经网络为例,冻结提取特征的卷积层网络,仅对全连接层进行训练。2)微调,将原始训练模型的权重参数作为初始值,在目标数据集中训练所有层,通过固定N-1层的参数,对剩下一层进行训练,实现参数微调[15-16]。
3.2 预置模型训练
在机器学习中,训练数据量较少时,训练模型效果不好,且训练过程需要大量时间完成模型参数调整选出最优参数,训练时间长。当无法收集到大量高质量数据时,可以结合迁移学习的思想,采用微调法进行预置模型训练,进一步地可以通过域对抗网络(domain-adversarial neural network,DANN)[17],提升迁移学习效果。如图5所示,基于DANN的迁移学习训练将网络模型分为特诊提取、领域分类和标签分类3个部分,共同训练,优化迁移学习的效果。
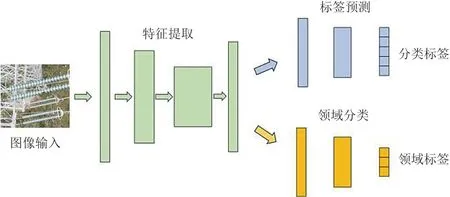
图5 基于DANN的迁移学习训练
由于在电力应用中,部分场景具有一定的相似性,可将迁移学习技术应用于输电线路的输电通道可视化模型,应用于变电站隔离开关、仪表等设备状态识别的变电站仪表开关识别模型,以及应用于生产环境人员穿戴、行为的安全生产监控模型。基于输电、变电、安监三大典型电力场景,所开发的人工智能训练和推理平台已实现了三大场景10类预训练模型,采用了SSD-MobileNetV1、YOLOv3-MobileNetV1、YOLOv3-DarkNet、Faster R-CNN-ResNet50vd-FPN等网络模型,将不同单位收集到的缺陷样本进行二次调优训练,得到针对不同生产环境下的输变电设备缺陷异常检测和现场作业安全行为分析模型,基准模型识别率在70%~90%之间。
4 基于智能转换的云边协同框架
4.1 模型转换
对于实时性要求较高的业务场景,通常优先选择边缘计算的方式,在边端侧安装智能终端设备,部署人工智能模型进行就地及时处理。尽管目前在云端训练模型、部署服务、运行已经比较成熟,但云端的X86架构和边端以ARM为主的各类异构芯片架构的差异,使得模型迁移仍然需要考虑硬件兼容、能耗与性能等问题,仍有很多困难。
由于模型训练过程和推理服务侧重点不同,大部分主流训练框架和推理框架也有所不同,为此,实现模型在不同框架之间的转换,是避免模型重复开发、浪费资源较好的办法。目前主流模型转换技术是ONNX技术,是针对深度学习设计的一种开放式的文件规范,主流深度学习框架都支持这种规范标准。而ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型,ONNX使得不同的人工智能框架可以采用相同格式存储模型数据并交互,使模型在不同框架之间进行转换。
模型转换实现过程如下:
1)计算图生成:在模型推理过程中,框架会记录执行算子的类型、输入输出、超参数、参数等算子信息;最后,把算子节点信息和模型信息结合得到符合ONNX 标准的静态计算图。
2) 计算图转换:解析静态计算图,根据计算图和目标格式的定义,转换出目标框架模型。
4.2 云边协同
结合云边协同的理念,在边缘侧部署AI模型,实现人工智能在电力场景中的边缘智能应用。边缘计算需要在边缘端部署边缘物理代理及模型。由于边端设备各式各样,这里采用容器化、模块化的方式,部署边缘本地运行包,赋能边缘计算节点,让本地设备具备本地计算、AI推断等能力。同时,采用ONNX技术,生成适配边端设备的计算模型,已支持X86、ARM等多种硬件以及Linux、MacOS和Windows等各类操作系统。智能边缘实现流程如图6所示,图6(a)是云端模型与边端设备架构相同时的流程;图6(b)是与云端模型不适配的边端设备,需要先进行模型转换的流程。

图6 智能边缘实现流程
传统云边协同下发模型推理到边缘设备,以容器形式下发,占用带宽,且不同处理器架构下容器不能通用。对此,使用ONNX进行模型转换,将模型转换为适配边端设备的模型,再将模型文件下发至边端设备,在边端采用Docker+K3s的方式部署模型,提升模型资源管控能力。
5 应用成效
基于以上提出的技术,开发了统一开放的四川电力人工智能中台,中台架构如图7所示,包括两库(“样本库”和“模型库”)、一平台(人工智能训练和推理平台)。中台在硬件上由13台服务器组成,配置56张Nvidia T4 GPU加速卡,采用Docker+K8s的方式实现资源调度,内置深度学习和机器学习预训练模型,为模型生产提供便利。中台上人工智能模型以容器方式提供在线服务,通过规范化的服务接口,可以方便各业务系统直接进行集成调用,且通过数据回流技术实现了在进行预测服务的同时,在线收集到各类样本。中台搭建了服务门户页面,对目前已上线AI算法模型的调用接口、功能描述进行展示和试用。

图7 人工智能中台应用架构
目前,人工智能中台已收集典型电力缺陷样本6.5万张;基于智能标注算法,完成4万张样本标注;采用预训练模型,开发部署输、变电场景中设备异常缺陷识别、现场作业安全行为分析、文字识别算法模型共119个,并投入生产一线使用。截至2021年年底算法模型累积服务次数超过100万次,主要应用成效如下:
1)助力现场安全作业管控。开发现场作业60余种违章算法模型,在140个基层班组进行试运行,识别正确率达到 90% ,截至2021年年底,累计辅助完成管控各类作业场所共计3806场,涉及作业人员17 593人次,分析视频共计214 000 h,成功发现违章2797次,作业现场违章率下降91.58%。
2)实现森林火灾监测预警。输电线路森林防火面临点多线长面广特点,一线班组人员巡视压力巨大,国网四川省电力公司在220 kV周格一线、永理二线、山越二线等13条森林火灾易发线路部署887个摄像头,开发山火、烟雾检测模型,对采集图像进行山火智能识别,算法模型已提供算法服务413 965次,成功预警山火137次,有效提升森林草原防山火工作效率。
3)实现了对智能运检管控平台(无人机管控平台)的全面智能服务。国网四川省电力公司绝大部分输电线路处于山区、无人区,一线班组人员巡线压力巨大。依据预训练模型开发部署鸟巢、异物、绝缘子、均压环异常检测等75个算法模型,采用云边协同方式和模型转换技术,将模型下发至边缘物联代理,提高图像识别实时性,累计收集输电线路缺陷样本11 838张,算法模型累计服务超过12 275次,巡检效率提升超过2倍。
4)提升变电站巡检质效。国网四川省电力公司在110 kV峨山变电站开展变电站智能巡检试点,开发部署表计读数、油温油位、压板投退、绝缘子、呼吸器等90类图像识别算法模型,对变电站内各类设备的状态进行实时监控,及时预警,缺陷诊断预警准确率达到90%,减少人工巡视的80%工作量。
5)提升智能审计效率。国网四川省电力公司利用电力人工智能平台开发部署的OCR模型,将传统人工费结算纸质材料快速转换为结构化数据条目,对人员的出勤记录和结算数据进行智能识别与比对。截至目前,已实现对208个劳务分包项目、2 248.79万元民工费的稽核,共挽回经济损失20余万元,审计覆盖面由之前的20%提升至50%,抽样比例由之前的30%提升至90%,现场审计时间压缩近50%。
6 结 论
上面主要针对人工智能在电力企业所面临的样本收集、标注困难、训练样本少、模型边缘部署困难等问题,建设了集样本收集和标注、模型训练、模型转换、云边协同等为一体的统一开放平台,清扫电力行业中人工智能应用的阻碍,助力人工智能在电力行业广泛化、自动化应用。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
中学生数理化·高一版(2021年2期)2021-03-19
汽车工程(2021年12期)2021-03-08
当代陕西(2019年16期)2019-09-25
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
领导决策信息(2018年16期)2018-09-27
小康(2017年16期)2017-06-07
数学学习与研究(2017年3期)2017-03-09
南风窗(2016年19期)2016-09-21
