
一种多特征融合的说话人辨认算法
2022-07-02 12:23孙佳宁于玲
电脑知识与技术 2022年15期
孙佳宁 于玲



摘要:针对在智能音箱中容易出现误唤醒情况,即设备被环境音错误激活的问题,该文提出了一种多特征融合的说话人辨认算法。该算法在特征提取部分通过将短时能量、线性预测倒谱系数(LPCC)、梅尔频率倒谱系数(MFCC)及其一阶动态特征差分系数进行有机结合来提高说话人辨认算法的识别率。使用自建语音库进行仿真测试,仿真实验结果表明,与采用传统特征提取的GMM说话人辨认相比,采用改进的特征提取方法能显著提高说话人辨认的识别正确率。
关键词:说话人辨认;MFCC;LPCC;短时能量
中图分类号:TP18 文献标识码:A
文章编号:1009-3044(2022)15-0082-03
在實际生活中,智能音箱容易出现误唤醒的情况,比如电视里提到唤醒词,或者外面小朋友贪玩喊出唤醒词,都会导致误唤醒的发生。在进行唤醒词识别前,加入对说话人的辨认[1]可以有效减少这种情况的发生。
说话人辨认的性能主要取决于特征提取和模式识别部分。目前常用的特征有梅尔频率倒谱、感知线性预测、线性预测倒谱[2]。采用单一的线性预测倒谱特征(LPCC)对语音的清音识别来说并不准确;采用单一的短时能量可以准确区分清浊音,但抗噪性很差;采用单一的梅尔频率倒谱特征(MFCC)抗噪性比较强,但其各维分量对识别性能的贡献是不同的,如第一维、第二维特征分量会使说话人辨认的识别效果更差[3]。
故本文考虑通过多特征融合来提高说话人辨认的识别准确率,进而降低智能音箱的误唤醒率。本文在特征提取部分,将LPCC、MFCC及其一阶动态特征差分系数进行有机结合,并将MFCC中第一维特征分量舍弃并替换为短时能量,获取说话人特征的更多信息,从而有效提高说话人辨认系统的识别性能。与采用单一特征进行说话人辨认相比,多特征融合的说话人辨认算法抗噪声性能更强,在环境适应性方面更有优势。
1说话人辨认的特征提取
本文所采用的特征包括:线性预测倒谱系数(LPCC)、短时能量、梅尔频率倒谱系数(MFCC)及其一阶动态特征。其中,线性预测倒谱系数(LPCC)可以更好识别合成语音;梅尔频率倒谱系数MFCC可以降低噪声的影响;再加入反映语音瞬时变化的动态特征,用短时能量来取代MFCC第一维的特征分量,能有效提高系统识别性能。下面分别对这几种特征的提取进行简要介绍。
1.1线性预测倒谱系数(LPCC)特性
线性预测倒谱系数(LPCC)是依据全极点模型对线性预测系数(LPC)[4]进行递推得到的。目前已经有多种线性预测分析方法,本文选用的是自相关法中的杜宾算法,先计算出预测系数a1~ap,然后将预测系数带入公式进行计算得出LPCC系数。
当线性预测倒谱系数n的阶数为1的时候,使用式(1)进行计算。
[clp(1)=a1] (1)
当n的阶数不超过线性预测系数p时,使用式(2)中第一个算式进行计算,进而得到语音信号线性预测倒谱系数clp(n),当n的阶数大于线性预测系数p时,则使用式(2)中第二个算式进行计算,进而得到语音信号线性预测倒谱系数clp(n)。
[clp(n)=k=1n-1knan-kclp(k)+an(1<n≤p)clp(n)=k=1n-1knan-kclp(k)(n>p)] (2)
线性预测倒谱系数LPCC相对别的特征参数计算方法来说计算运算量并不大,与其他特征进行有机结合可以有效提高说话人辨认的准确率。
1.2短时能量特性
短时能量在说话人辨认中大致有两种作用:一是用来区分清浊音;二是用来判断语音起始段[5]。本文用到短时能量主要是用于区分清音和浊音。
对于信号{x(n)},其短时能量En的定义如下:
[En=m=-∞∞[xmwn-m]2=m=-∞∞x2mhn-m=x2n∗hn] (3)
其中h(n)=w(n)2, w(n)为汉明窗,公式如下:
[wn=0.54-0.46cos2πnN-1,0≤n≤N-10,其他] (4)
其中N为汉明窗的长度。
然后对En进行归一化处理和取对数处理。
[En^=log(En/max(En)0≤n≤L-1)] (5)
其中L为帧的数量,最后将得到的[En^]加入特征向量中。
1.3梅尔倒谱系数MFCC及其一阶差分特性
MFCC是在梅尔标度频率域提取出来的,它是说话人辨认中常用的语音特征参数[6]。其中梅尔标度计算公式如下:
[fMel=2595log10(1+f/700)] (6)
其中f为频率,单位为Hz。
梅尔倒谱系数MFCC的提取过程如图1所示。
第一步:将语音信号进行预加重后再进行快速傅里叶变换,然后取模的平方进而得到离散功率谱S(n)。
第二步:将S(n)通过N个三角滤波器进行滤波处理,得到N个系数Pn(n=0,1,…,N-1)。
第三步:计算滤波器组输出参数Pn的自然对数,得到Ln(n=0,1,…,N-1)。
第四步:对Ln进行离散余弦变换:
[Cn=2Nj=0N-1fjcos[πnN(j+0.5)],n=0,1,...,N-1] (7)
得到Cn(n=0,1,…,N-1)。舍去代表直流成分的C0,将C0特征分量替换为式(5)中的短时能量[En^],之后取[En^],C1,C2,…,Cn作为新的MFCC参数。
最后对MFCC进行一阶差分处理[7]:
[dm=Cm+1-Cm,m<Kk=1Kk(Cm+k-Cm-k)2k=1Kk2,其他Cm-Cm-1,m≥N-K] (8)
其中dm表示第m个一阶差分,Cm表示第m个倒谱系数,K表示一阶导数的时间差。
本文首先取12维梅尔倒谱系数Cn,之后把梅尔倒谱系数(MFCC)的第一维特征分量替换为一维短时能量[En^],然后对新得到的12维梅尔倒谱系数MFCC进行一阶差分处理得到dm。将新得到的梅尔倒谱系数与线性倒谱系数clp(n)进行线性加权,得到一组新的特征向量,记为Y。最后将Y与dm进行有机结合得到最后的特征参数向量,记为X。
2基于GMM的说话人识别模型
说话人辨认就其本质来讲是对个性特征的识别,在使用前述方法将所需的特征提取出来之后,使用说话人识别模型将所提取的特征送入识别部分进行与文本相关的说话人辨认。目前主要模型有动态时间规整[8]、隐马尔科夫[9]、矢量量化[10]、高斯混合[11],本文采用的是高斯混合模型。
建立高斯混合GMM模型首先要计算单个高斯分布函数:
[piX=exp-X-wiT∑i-1X-wi22πN2∑i12] (9)
其中X为第一章中进行多特征融合后的特征参数向量,N为多特征融合的特征向量维数,∑i为协方差矩阵,wi为均值向量,T为某个说话人的某段语音经过预处理后的分帧数。
然后将多个单高斯概率密度进行加权线性组合:
[gXλ=i=1Mμipix,i=1Mμi=1] (10)
其中,µi为第i个分量的混合权值。通常情况下高斯混合模型的阶数M越大,计算量和训练样本越多,误差率越小;M越小,计算量和训练样本越少,但误差率会增大。通过式(10)可得出GMM参数集[λ]由各均值向量、协方差矩阵及混合分量的权值组成[12]:
[λ={wi,i,μi(i=1,2,...M)}] (11)
對GMM训练实际上就是对参数集[λ]进行估计的过程,GMM的似然度可表示为:
[G(Xλ)=i=1TgXiλ] (12)
因为式(12)是参数[λ]的非线性函数,很难直接求GMM似然度的最大值。因此,用最大期望算法(EM)反复重估参数[λ],直至模型收敛[13]。
3 仿真及结果分析
在语音库部分,本文采用的是自建语音库。语音录制分别在以下两种环境下进行:(1)录制环境无噪声;(2)室内有较少人群,录制环境非静音。第二种环境模拟了智能音箱在家居环境中的使用,可以测试出采用多特征融合的说话人辨认是否能提高智能音箱的抗噪性。本实验参与语音录制的共63人,分别在两种环境下朗读内容为“小度小度”的声控语音6遍。随机选取在环境(1)下录制的语音信号中的4句作为训练语音,称为训练集一,剩余语句作为测试语音,称为测试集一。随机选取在环境(2)下录制的语音信号中的4句作为训练语音,称为训练集二,剩余语句作为测试语音,称为测试集二。在特征提取部分本文预加重系数选取为0.95,分帧部分取256点为一帧,帧移为128点,加窗部分为汉明窗。所有特征提取方法均使用GMM模型进行训练识别,GMM阶数设置为16阶。
3.1不同特征提取方式说话人辨认的比较
首先本实验将传统方法和本文所使用的多特征融合特征提取方法进行比较。
LPCC[14]、MFCC[15]、MFCC+其一阶动态差分特征[16],梅尔倒谱系数MFCC+其一阶动态差分特征+短时能量为传统特征提取。LPCC+MFCC+其一阶动态差分特征+短时能量为本文提出的改进特征提取方法。所用语音库为安静环境下所录制的训练集一、测试集一。参数设置以及说话人识别结果如表1所示。
从表1中可以得出结论,当只使用8维LPCC参数进行说话人辨认时识别效果并不好,识别率只有39.68%;当只使用12维MFCC参数进行说话人辨认时,比起使用LPCC参数进行说话人辨认时识别效果有显著提升,由39.68%变为82.54%;比起单一的MFCC来说加入一阶动态差分特征的说话人辨认识别率有所上升,由82.54%变为84.92%;因为对说话人辨认来说最有用的信息包含在MFCC分量C2~C16之间,所以本文将C0分量丢弃后加入1维的短时能量,表1表明将C0分量舍弃并加入短时能量后说话人辨认识别成功率变为87.30%;当将25维LPCC、1维短时能量与12维MFCC及其一阶动态差分特征进行结合时,识别率达到了98.41%。仿真结果表明,将短时能量、LPCC、MFCC及其一阶动态特征差分系数进行有机结合的方法识别成功率最高。
3.2 LPCC、MFCC阶数对说话人辨认的影响
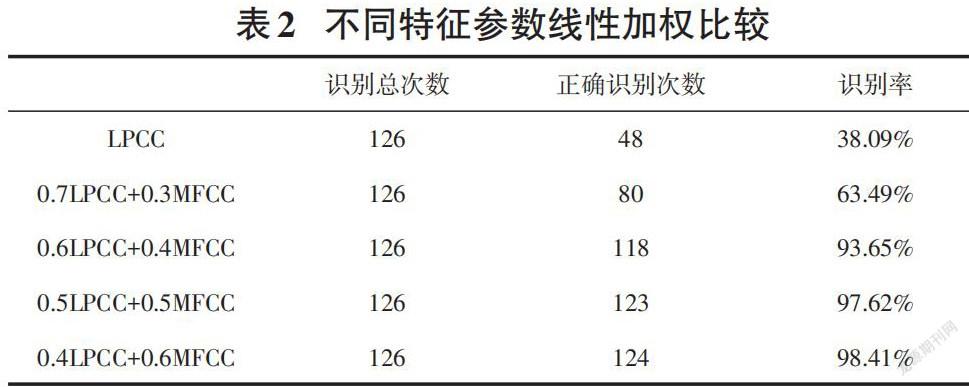
本实验将MFCC、LPCC进行了线性加权处理。LPCC参数选取为25维;MFCC中MFCC参数选取为12维,短时能量参数选取为1维,△MFCC参数选取为12維。所用语音库为安静环境下所录制的训练集一、测试集一。说话人识别结果如表2所示。
从表2可以看出,单独使用LPCC特征参数进行说话人辨认时识别正确率只有38.09%;将0.7LPCC与0.3MFCC进行线性加权时说话人辨认识别正确率为63.49%;将0.6LPCC与0.4MFCC进行线性加权时说话人辨认识别正确率由63.49%变为了93.65%;将0.5LPCC与0.5MFCC进行线性加权时说话人辨认识别正确率为97.62%,比起0.6LPCC+0.4MFCC识别率又有所提高;将0.4LPCC与0.6MFCC进行线性加权时说话人辨认识别正确率达到了98.41%。仿真结果表明,经过线性加权运算后构成的组合特征参数涵盖了语音的声道及听觉特性,提高了说话人辨认系统的识别率,其中将0.4LPCC与0.6MFCC进行线性加权时说话人辨认识别率最高。
3.3 不同环境下特征提取方法对识别的影响
本实验使用三种特征提取方法,对两种环境下录制的语音进行识别。三种特征提取方法为LPCC、MFCC、LPCC+MFCC+其一阶动态差分特征+短时能量。其参数设置分别为:8维LPCC、12维MFCC、25维LPCC +12维MFCC +其一阶动态差分特征+1维短时能量。两种录制环境分别为:安静环境下录制的测试集一、录制环境非静音情况下的测试集二。说话人识别结果如表3所示。
由表3可知,当在安静环境下时LPCC识别率为39.68%,MFCC识别率为85.54%,LPCC+MFCC+△MFCC+短时能量识别率为98.41%。当在录制环境非静音情况下LPCC识别率为23.81%,识别性能受到较大影响;MFCC识别率为71.43%,比起在安静环境下识别性能也有所下降;LPCC+MFCC+△MFCC+短时能量识别率为95.24%,识别效果比起单一使用LPCC与MFCC来说依旧更好。仿真结果表明,无论是在安静环境下还是噪声环境下,多融合特征提取方法识别性能都要优于普通特征提取方法。
4结语
本文通过将线性预测倒谱系数、短时能量、梅尔倒谱系数及其一阶动态差分特征进行有机结合,提高了说话人辨认算法的识别正确率。仿真结果表明在进行说话人辨认时,本文所提出的多特征融合算法比采用传统特征提取算法抗噪性更好,识别性能大大提高。
参考文献:
[1] 欧国振,孙林慧,薛海双.基于重组超矢量的GMM-SVM说话人辨认系统[J].计算机技术与发展,2017,27(7):51-56.
[2] 杨瑞田,周萍,杨青.TEO能量与Mel倒谱混合参数应用于说话人识别[J].计算机仿真,2017,34(8):215-219,264.
[3] 甄斌,吴玺宏,刘志敏,等.语音识别和说话人识别中各倒谱分量的相对重要性[J].北京大学学报(自然科学版),2001,37(3):371-378.
[4] 吕治国,范文.基于DSP的身份确认双系统设计[J].通信电源技术,2013,30(3):33-35.
[5] 刘玉珍,田金波.基于语音增强的双门限语音端点检测算法[J].测控技术,2016,35(11):33-35.
[6] 唐铠,陆鹏.SOM-LSTM递归神经网络语音端点检测系统[J].信息通信,2019,32(5):50-53.
[7] Revathi A,Ravichandran C,Saisiddarth P,et al.Isolated command recognition using MFCC and clustering algorithm[J].SN Computer Science,2020,1(2):1-7.
[8] Liu J W,Cheng Q S,Zheng Z G,et al.A DTW-based probability model for speaker feature analysis and data mining[J].Pattern Recognition Letters,2002,23(11):1271-1276.
[9] Liu H,Wang W,Wang C W.A novel research in low altitude acoustic target recognition based on HMM[J].International Journal of Multimedia Data Engineering and Management,2021,12(2):19-30.
[10] Ouisaadane A,Safi S,Frikuil M.Arabic digits speech recognition and speaker identification in noisy environment using a hybrid model of VQ and GMM[J].TELKOMNIKA (Telecommunication Computing Electronics and Control),2020,18(4):2193.
[11] Gupta M,Bharti S S,Agarwal S.Gender-based speaker recognition from speech signals using GMM model[J].Modern Physics Letters B,2019,33(35):1950438.
[12] 姚青俊.歌曲风格与歌手音质自动分析研究[D].哈尔滨:哈尔滨工业大学,2010.
[13] 成新民,沈律,赵力,等.基于修正EM算法的说话人识别的研究[J].电声技术,2004,28(12):51-53.
[14] 于明,袁玉倩,董浩,等.一种基于MFCC和LPCC的文本相关说话人识别方法[J].计算机应用,2006,26(4):883-885.
[15] 韩旭.噪声环境下基于RNN的说话人识别方法研究[D].哈尔滨:哈尔滨理工大学,2019.
[16] 周玥媛,孔钦.基于GMM-UBM的声纹识别技术的特征参数研究[J].计算机技术与发展,2020,30(5):76-83.
【通联编辑:唐一东】
