
海量日志环境下的电力业务信息系统健康性动态评价方法
2022-07-01 07:31:06吴树霖毛舒乐吴小华郑青如
合肥工业大学学报(自然科学版) 2022年6期
吴树霖, 伍 刚, 毛舒乐, 邵 臻, 吴小华, 郑青如
(1.国网福建省电力有限公司,福建 福州 350003; 2.国网福建省电力有限公司 信息通信分公司,福建 福州 350003; 3.安徽继远软件有限公司,安徽 合肥 230088; 4.合肥工业大学 管理学院,安徽 合肥 230009)
当前,我国进一步深化电力体制改革和完善电力市场化交易机制的工作正稳步推进,随着电力市场的逐步开放,电力企业想要在日益激烈的竞争市场中取得优势,实时有效地检测其业务信息系统的运行状况并确保系统稳定运行变得尤为重要。电力业务信息系统主要包括营销系统、物资管理系统、人力资源系统、生产管理系统等[1],各业务系统的健康运营有利于电力公司更好地适应市场变化。与此同时,随着电力系统信息化、智能化进程的加快,信息技术已经融入到电力系统发、输、变、配、用等各个环节,电力业务信息系统在运行过程中会产生大量的日志数据。因此在电力业务信息系统运维过程中,需要在海量日志环境下对电力业务信息系统的健康运行情况进行实时有效的评价。
目前,对于信息系统健康评价的研究已取得了一些研究成果。信息系统健康度需要从数据的视角客观反映企业信息系统、互联网技术的综合运营能力和水平[2]。对系统健康性的研究主要从功能性、安全性和性能性等多个层面展开,采用层次分析法、模糊理论等方法,构建系统健康性评价体系[2-4]。文献[3]利用功能特性、性能特性和安全特性3个方面的数据,采用层次分析法评估信息系统的运行状态;文献[5]利用模糊综合评价模型研究服务器工作状态、服务区域内用户的使用状态以及DNS非常规使用状态等方面对系统健康性的影响;文献[6]提出一种新的基于粗糙集的容器云系统健康评价模型,实时、动态地对整个云平台资源的运行状况进行直观反映。
除了直接对健康性进行研究,还有部分学者从系统的风险评估、安全评价体系等方面展开研究,相应的评价方法主要有层次分析法、模糊评价法和神经网络等方法。文献[1,7]运用层次分析法,并对指标进行分析,确定指标权重数值,构建信息系统评价体系,对系统的成熟度进行综合评价;文献[8]基于层次分析法和熵权法对配电网调度评价,提高配电网调度管理水平。对于模糊评价法,文献[9-10]将模糊评价方法应用于信息系统的风险评估、等级保护和安全检查3项测评工作中,对信息系统风险进行评估,得出其安全级别,直观地为信息系统安全等级定级提供可量化的标准。但层次分析法和模糊评价法构建层次结构或模糊一致矩阵时,需要依靠专家打分确定相应的权重,这就导致评价过程具有随机性和主观性。为了解决这一问题,文献[11]运用熵权法对安全指标体系进行处理,确定评价指标的权重,尽管该模型属于一种客观赋权方法,但由于系统评价指标较多,导致实际分析时计算量较大,容易出现残缺判断矩阵且标度工作量过大等问题。为此有学者采用神经网络模型进行评价,克服了层次分析法等评价方法中的主观因素影响,提高了综合评价的客观性和合理性。文献[12]基于改进的ELMAN神经网络构建了协同创新伙伴评价模型;文献[13]提出一种深度神经网络的风险评价方法,实验表明该模型具有更高的有效性;文献[14]提出了基于量子门线路神经网络的信息安全风险评估方法,该方法能够实现信息系统的风险评估,使评价结果更准确;文献[15]利用BP神经网络构建了评估模型,来提高生态风险管理;文献[16]结合模糊理论和神经网络方法,提出T-S模糊神经网络模型,实现对系统的评价,但基于神经网络的评价方法同样需要考虑权重赋值问题。
电力系统健康性评价研究主要侧重于电网安全和电网运行状态等领域,关于电力业务信息系统健康性评价的研究工作较少。传统的电力信息系统运行状况评价对于日志信息的利用不足,缺乏对电力信息系统实时监测的多元信息的综合判别与分析。此外,基于传统的AHP、模糊综合评价法等数据评价方法难以克服评价指标权重赋值的主观性等问题,严重影响了系统健康度评价的实时性和客观性。针对上述问题,本文提出了基于数据包络分析的典型业务信息系统,即人力资源系统评价方法,该方法通过关联规则技术中的Apriori算法对信息系统的运行数据指标进行提取,将所发现的指标间的联系用频繁项集的形式进行表示,进而选取出能表达电力业务信息系统健康性的重要关联规则。结合提取到的核心关联规则,运用数据包络分析(data envelopment analysis,DEA)模型进行确定系统健康度的投入与产出指标,进而根据得到的不同时间点的综合评价效率指数来判断电力业务信息系统资源配置的合理性,据此来衡量系统的健康性。
1 电力业务信息系统评价
1.1 关联规则
Apriori关联规则算法是经典的关联规则算法[17]。Apriori算法主要是先对预处理过的数据进行分析,找出比设定的最小置信度大或者相等的频繁项集,再从中找到比设定的最小置信度大的强关联规则。Apriori算法的优点是对数据的要求不高,算法易操作。本文将Apriori算法应用于日志文件的数据挖掘与处理中,在没有直接联系的指标之间找到联系,形成一定的规则。
支持度和置信度是关联规则的2个重要指标。支持度表示项集(X,Y)在总项集中的概率,即number(I)。最小支持度记为smin,用于衡量规则需要满足的最低重要性。频繁项集就是支持度大于或等于最小支持度的集合。置信度表示在X发生的情况下,由关联规则(X→Y)推出Y发生的概率,即confident(X→Y)=P(X|Y)=P(X,Y)/P(X)。最小置信度记为cmin,表示关联规则需要满足的最低可靠性,是人为设定的。若关联规则R:X→Y满足support(X→Y)≥smin且confident(X→Y)≥cmin,则称此规则为强关联规则。关联规则的目的就是找到符合条件的强关联规则。
1.2 DEA评价模型
DEA[18]是常用于运筹学和研究经济生产边界的一种方法。该模型只需要研究输入输出数据,不对数据进行其他处理,不需要了解数据之间的某些关系,并且对于权重无任何要求,只从决策单元的实际输入输出数据求出最优权重。
DEA是通过线性规划方法将多个投入和产出指标进行效益评价的方法。DEA的优点主要是权重由实际数据求得,没有主观因素的影响,不用对输入和输出之间的表达式加以明确。在DEA方法中,CCR模型和BCC模型是典型的模型。在DEA方法中,每一个评价单元为一个决策单元(decision making unit,DMU)。假设有n个决策单元,简称DDMUj(j=1,2,…,n),每个决策单元有m项投入xij(i=1,2,…,m)和s个产出yrj(r=1,…,s),相应的投入和产出向量分别记作Xj=(x1j,x2j,…,xmj)和Yj=(y1j,y2j,…,ymj)。
CCR模型是基于规模报酬不变的假设提出来的经典DEA模型[19]。为方便模型求解和产能分析,引入松弛变量si-、sr+。其中:si-表示该决策单元为达到DEA有效应减少的投入量,称为超额变数;sr+表示达到DEA 有效应增加的产出量,称为差额变数。CCR模型得到的是综合技术效率,表示决策单元在最优规模时投入要素的生产效率,反映了决策单元的资源配置的合理程度。
评价决策单元效益的CCR模式线性规划模型为:

λj≥0,
ε=10-6
(1)
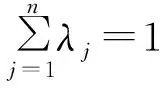
ε=10-6
(2)
该模型将综合效率分解为纯技术效率和规模效率,通过BCC模型得到纯技术效率(technical efficiency,TE),即因管理和技术等因素影响的生产效率。规模效率(scale efficiency,SE)即由企业规模影响的生产因素。
SE=OE/TE
(3)
对于本文电力业务信息系统而言,其DEA效率的意义如下:综合效率值等于1,该系统为DEA有效,即在当前投入的情况下,所获得的产出达到相对最优,同时技术和规模有效。也就是说在该状态下电力业务信息系统是处于非常健康状态的。若综合效率值小于1,则该系统DEA非有效,即该决策单元相对于其他决策单元综合效率低,可根据纯技术效率和规模效率分析造成该情况的原因。若纯技术效率=1,表示在目前的技术水平上,其投入资源的使用是有效率的,未能达到综合有效的根本原因在于其规模无效。
1.3 模型框架
电力业务信息系统健康性评价模型框架如图1所示,步骤如下:① 选择数据。对电力业务信息系统进行健康性评价合适的系统运行数据,对数据进行预处理。② 确定DEA评价模型的投入产出。根据日志信息数据进行关联规则分析,得到关联规则模式,进一步将得到的关联规则进行筛选,筛选后的关联规则的先导作为投入,后继作为产出。③ 利用 DEA 模型进行系统评价,得出DEA分析评价结果并提出决策建议。

图1 电力业务信息系统健康性评价模型框架
2 案例实验与结果分析
2.1 数据描述及预处理
某省电力公司人力资源系统的日志信息,主要包括人力资源数据库、人力资源数据库宿主机、人力资源中间件和人力资源应用服务器等日志信息。考虑数据的可获取性、一致性和完备性,本文选取了人力资源数据库宿主机的日志信息进行实验。进一步利用正则表达式提取日志信息得到人力资源数据库宿主机的运行数据,数据包括ID、Guideline-ID、Monitor-Date、Monitor-Value 等4个不同类型的属性,其中:ID表示每个数据存储的ID,作为主键;Guideline-ID包含18个指标,表示日志信息数据,见表1所列;Monitor-Date表示检测日期;Monitor-Value表示不同时间点各指标对应的值(2019年5月31日 11:00—2019年6月1日 11:00)。

表1 人力资源数据库宿主机数据总指标
为进一步分析人力资源数据库宿主机在不同时间(Monitor-Date)范围内的健康运行状况,首先对运行数据进行清洗,筛选信息完整的指标进行系统评价分析,删除Monitor-Value值均为空值的指标。利用相关性分析,删除与各指标之间相关系数为空值的指标(空值表示该指标的Monitor-Value值均相等),最终得到Guideline-ID包含7个指标。所选取的指标见表2所列,分别为CPU平均使用率、内存剩余量、内存分配率、内存利用率、内存占用量、连续运行时间和存储介质利用率。其中内存剩余量、内存分配率、内存利用率和内存占用量4个指标衡量了人力资源数据库宿主机子系统中内存的使用情况,连续运行时间即系统截止目前时间点的运行时间,存储介质利用率表示存储数据载体的利用率,如硬盘的利用率。
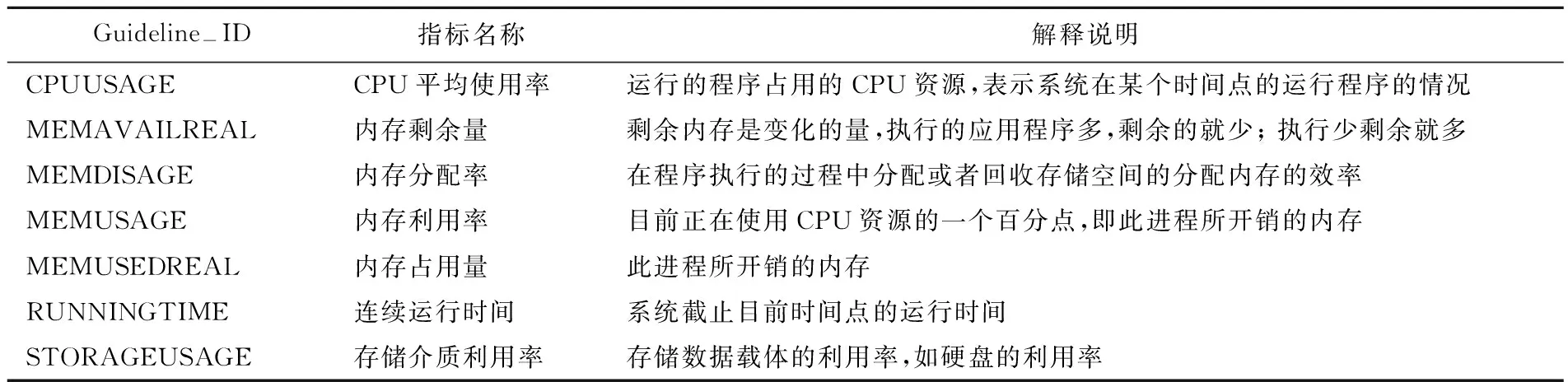
表2 人力资源数据库宿主机评价指标
2.2 实验结果与讨论
2.2.1 评价指标的确定
本文利用Apriori关联规则算法所提取的频繁项集,综合考虑指标的数据质量问题[21],从而确定了DEA评价模型的投入与产出变量。关联规则分析设置的最小支持度为0.5,最小置信度为0.7,由此产生关联规则模式。从模式中选择适当的关联规则,其前项作为投入,后项作为产出,所确定的指标体系见表3所列。
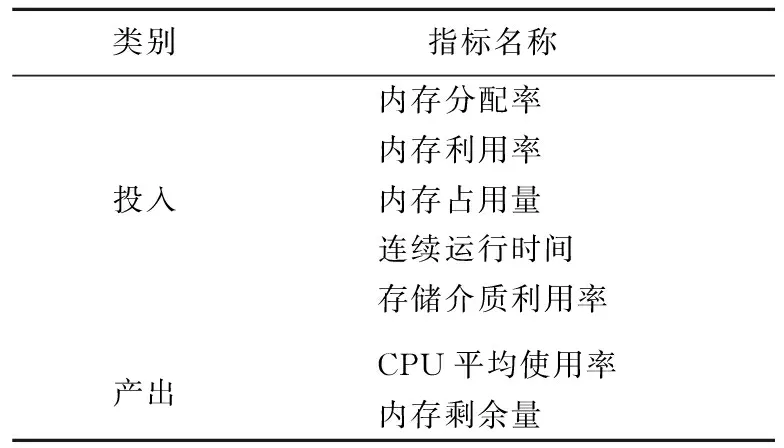
表3 DEA评价模型的投入、产出指标
2.2.2 基于DEA评价模型的系统健康性评价
在得到相应的信息系统健康评价指标后,本文将得到的投入产出指标代入DEA模型中,得到系统的综合效率、纯技术效率、规模效率等,结果如图2所示。
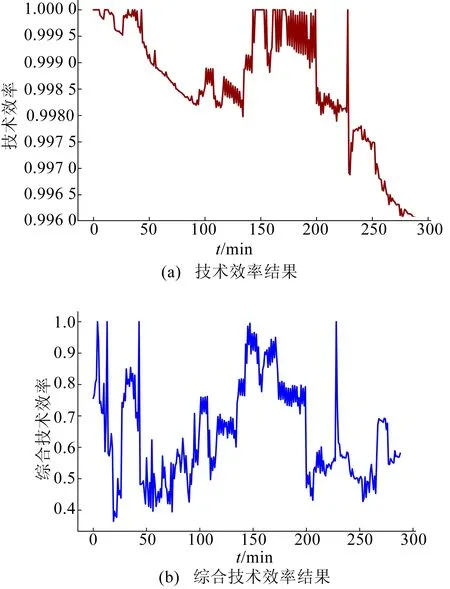
图2 人力资源数据库宿主机健康性评价结果
图2中,时间段为2019年5月31日 11:00—2019年6月1日 11:00。因为样本数量较多,直接列出每一个样本对应的效率不具有十分显著的意义,所以以小时划分数据对人力资源数据库宿主机健康性评价结果进行统计和分析。首先从总体的效率得分进行分析,其次统计非 DEA 有效的各时间段数据投入冗余和产出不足的情况,进一步分析影响系统综合效率的指标。
在不同时间段内,系统健康性评价得分均值的计算结果见表4所列。从表4中可以看出,人力资源数据库宿主机的综合技术效益(OE)得分偏低,均值为0.642。造成得分偏低主要原因是规模效益(SE)偏低,即内存、CPU容量过小或利用不足等原因。由图2、表4可知,人力资源数据库宿主机的综合技术效率在23:00—次日02:00时间段内健康得分较高,在11:30—12:00和次日05:30—06:30健康性评价得分波动较大。

表4 人力资源数据库宿主机各时间段健康性评价结果
根据综合效率高低将系统评价结果进行分类,结果见表5所列。综合效率为1.0,即DEA有效的时间点有4个,综合效率在0.8以上的有50个,综合效率一般的时间点有93个,综合效率介于0.4~0.6之间的结果数占比最高,占总数的48.44%。人力资源数据库宿主机系统在24 h中约有12 h的综合效率低于0.6,存在较大的改进空间。
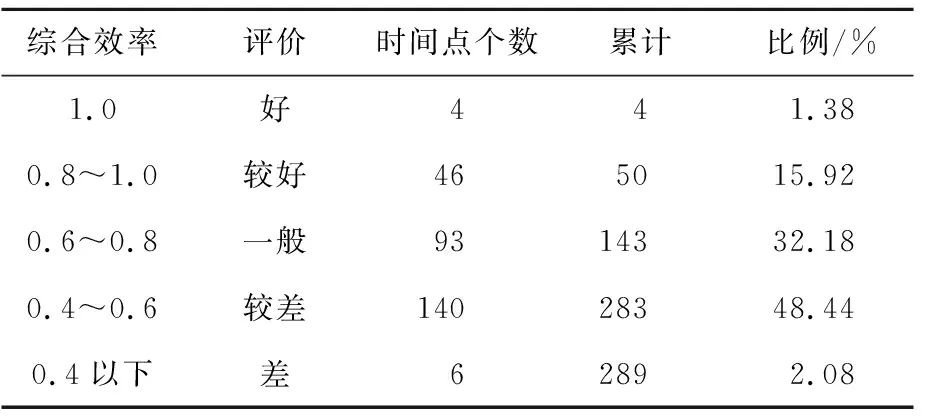
表5 综合效率分类结果
为进一步探究在非DEA有效情形下各投入指标的冗余情况,找出导致系统非DEA有效和综合健康性效率偏低的根本原因,本文进一步分析了各时间段非 DEA 有效数据的投入冗余和产出不足的情况,见表6所列。由表6可知,有285个非DEA有效的时间点,其中内存利用率、连续运行时间、存储介质利用率、内存占用量、内存分配率投入冗余的数据量分别达到了34、238、262、284、284。整体来看,非DEA有效主要由存储介质利用率、内存占用量和内存分配率导致,其中存储介质利用率的投入冗余的数据在13:00—17:00和19:00—次日11:00较多,应该合理提高三者的利用率。

表6 各时间段非DEA有效数据的投入冗余和产出不足情况
3 结论
本文结合某省电力公司人力资源数据库宿主机日志信息历史数据,对CPU平均使用率、内存剩余量、内存分配率、内存利用率、内存占用量、连续运行时间和存储介质利用率等指标进行了统计与分析,利用Apriori关联规则提取算法提取了信息系统的日志数据指标的频繁项集,进而选取出能够表达系统健康性的重要规则和信息。结合提取到的核心关联规则,运用DEA模型进行确定系统健康度的投入与产出指标,根据提取出来的指标对系统进行了健康性评价。
研究发现,从整体效率来看,人力资源数据库宿主机的综合技术效益得分偏低,主要是由于规模效益偏低造成的。对投入冗余的分析表明,存储介质利用率、内存占用量和内存分配率3个指标导致人力资源数据库宿主机的健康性效率偏低。
本文针对电力业务信息系统的运行健康状况开展了客观性评价分析,提出的基于Apriori-DEA的评价方法能够有效提取日志关联信息,为系统运行健康状况的核心指标选取及评价提供了理论依据。结果表明,基于Apriori的日志信息关联规则提取可以通过合理的投入与产出分析,达到客观、科学有效地评价电力业务信息系统的实时运行状况。需要指出的是,本文所建模型主要基于同一信息系统的连续时段历史运行数据,未能考虑不同子系统之间的相互影响及其对比分析,忽略了子系统之间的动态关联关系,因而需要在将来的研究中进一步拓展和完善。
猜你喜欢
当代陕西(2019年15期)2019-09-02 01:52:00
当代陕西(2019年13期)2019-08-20 03:54:22
学苑创造·A版(2018年11期)2018-02-01 06:29:20
广西教育·B版(2017年10期)2018-01-16 08:30:56
中国科技博览(2017年45期)2017-11-28 21:55:58
读者(2017年5期)2017-02-15 18:04:18
电脑知识与技术(2015年13期)2015-07-13 12:31:29
测绘科学与工程(2014年5期)2014-02-27 07:06:14
计算机与网络(2013年12期)2013-04-18 03:30:36
当代修辞学(2011年2期)2011-01-23 06:39:12
