
Transferable Features from 1D-Convolutional Network for Industrial Malware Classification
2022-06-30 09:30LiweiWangJiankunSunXiongLuoandXiYang
Liwei Wang,Jiankun Sun,Xiong Luo,★and Xi Yang
1School of Computer and Communication Engineering,University of Science and Technology Beijing,Beijing,100083,China
2Beijing Key Laboratory of Knowledge Engineering for Materials Science,Beijing,100083,China
3Shunde Graduate School,University of Science and Technology Beijing,Foshan,528399,China
4Beijing Intelligent Logistics System Collaborative Innovation Center,Beijing,101149,China
ABSTRACT With the development of information technology,malware threats to the industrial system have become an emergent issue,since various industrial infrastructures have been deeply integrated into our modern works and lives.To identify and classify new malware variants,different types of deep learning models have been widely explored recently.Generally,sufficient data is usually required to achieve a well-trained deep learning classifier with satisfactory generalization ability.However,in current practical applications,an ample supply of data is absent in most specific industrial malware detection scenarios.Transfer learning as an effective approach can be used to alleviate the influence of the small sample size problem.In addition,it can also reuse the knowledge from pretrained models,which is beneficial to the real-time requirement in industrial malware detection.In this paper,we investigate the transferable features learned by a 1D-convolutional network and evaluate our proposed methods on 6 transfer learning tasks.The experiment results show that 1D-convolutional architecture is effective to learn transferable features for malware classification,and indicate that transferring the first 2 layers of our proposed 1D-convolutional network is the most efficient way to reuse the learned features.
KEYWORDS Transfer learning; malware classification; sequence data modeling; convolutional network
1 Introduction
In the era of digitalization and intelligence,an increasing number of industrial devices are connected to the Internet and the generated data can be collected and analyzed more efficiently for personalized service and industrial production.Meanwhile,those devices suffer from various cyber-attacks [1].Malicious attackers can spread malware,such as viruses,Trojan horses,or ransomware,to compromise industrial systems.To avoid the damages from the malware,an extensive exploration about deep neural networks,recurrent neural network (RNN),and convolutional neural network (CNN)for the industrial Internet of Things (IoT)and cyber-physical system security suggests that deep learning is a powerful tool to detect and classify malware [2-6].
Towards the deep learning solutions for the malware detection and classification tasks,the general idea is to train a deep learning model from scratch following the classical supervised training paradigm.However,the small sample size problem in practical applications degrades the performance severely in deep learning.Due to different kinds of heterogeneous devices in industrial systems and the specificity of malware,the small sample size problem often arises when applying deep learning techniques.Following that,transfer learning is a sophisticated paradigm to alleviate such an issue.In recent researches,transfer learning is widely applied to image-based malware analysis [7-10].The general procedures in such a scenario include:1)converting every malware instance into a gray-scale or RGB image; 2)pre-training a CNN on a large source dataset,e.g.,a ResNet-50 based on ImageNet; 3)transferring the convolutional layers in the pretrained CNN to a new randomly initialized network,freezing the parameters in the convolutional layers,and fine-tuning the parameters in the fully connected layers on target dataset.Here,the key assumption is that the learned color blobs and Gabor filters from the CNN are also applicable to identify the texture of malware images.It is noted that the differences between natural images and malware images are obvious,which means a semantic gap exists.
To overcome issue of the semantic gap,we select opcode and application programming interface (API)sequence for malware behavior representation.Here,the functionality of various programs in different platforms is a process of executing commands sequentially,which means the opcode or API sequence is a more general and precise behavior representation for malware than image-based representation.Among the data-driven malicious sequence modeling architectures,RNN is a common network structure for modeling sequence data due to its weights sharing mechanism on the time dimension.In the era of big data,processing massive amounts of data has become the norm,and parallel computing is now an essential method to handle it.However,RNN is unable to gain benefit from the graphics processing unit (GPU)with parallel computing ability because of its sequential computation process.Hence,in order to make full use of the parallel computing ability of GPU,a new 1D-convolutional-based sequence data modeling scheme was developed and its excellent performance was validated in language modeling [11,12] and timeseries classification subsequently [13].Based on the discussions above,a transfer learning-enhanced 1D-convolutional network architecture is explored for the specific sequence modeling task in this paper,i.e.,malware sequence classification.The contributions of this paper are summarized as follows:
• We propose a 1D-convolutional architecture to perform transfer learning and evaluate 3 convolutional strategies on 6 transfer learning tasks.The experiment results show that the 1D-convolutional network can effectively learn transferable features for malware classification.
• We conduct several experiments to identify the practical way to transfer the parameters of convolutional layer.Moreover,the experiment results show that transfer learning is an effective approach to reduce the training time.
The remainder of this paper is organized as follows.Section 2 overviews some recent works on sequence data modeling.The proposed network architecture is described in Section 3.Our experimental results are presented in Section 4.The conclusion of this paper is stated in Section 5.
2 Related Work
Deep learning and transfer learning are widely explored in sequence data modeling.In this section,for sequence data modeling task,the developed deep learning models,especially the 1Dconvolutional networks on malicious sequence data,are overviewed firstly.Then,the transfer learning models on sequence data are analyzed.
2.1 Deep Learning for Sequence Data Modeling
For malware classification,opcode and API sequences are usually used for malware behavior representation.HaddadPajouh et al.[14] adopted long short-term memory (LSTM)for ARMbased IoT malware detection based on opcode sequence.Kang et al.[15] and Jha et al.[16] used LSTM to classify different malware families based on API sequence and opcode.To benefit from the parallel computing ability of GPU,the 1D-convolutional network is proposed for sequence data modeling.Shelhamer et al.[17] proposed a fully convolutional network (FCN)architecture for semantic segmentation.Wang et al.[13] modified the original FCN with one-dimensional kernels and replaced the last layer of FCN with fully connected layers and a softmax layer for time series classification.After that,some researchers explored the potential of 1D-convolutional networks for malware detection.Hasegawa et al.[18] used a 1D-convolutional network to detect Android malware.Then,to prevent information leakage from the future into the past,a specific temporal convolutional network (TCN)[19] was utilized to categorize malware into different families in the field of IoT malware classification [20].
2.2 Transfer Learning for Sequence Data Modeling
The major assumption from the classical supervised learning scheme is that training and future data follow the same distribution.However,this assumption fails in some industrial malware detection cases,since malicious training instances from heterogeneous devices may not satisfy the same feature distribution.In addition,the training dataset may easily get out of date in the era of big data [21].Hence,knowledge transfer will be a useful technique to improve the performance of deep learning models.Fawaz et al.[22] extensively explored the transferable ability of 1DFCN for time series classification,and their experiment results showed that knowledge transfer is beneficial to performance enhancement.Subsequently,Gao et al.[23] explored a semi-supervised transfer learning technique to alleviate the influence of the small sample size problem.
Meanwhile,there are also some problems in the use of transfer learning.They can be summarized as follows:1)what to transfer? 2)where to transfer? and 3)how to transfer? Currently,the mainstream transfer learning paradigm is based on pre-training and fine-tuning strategies,as illustrated in Fig.1,including 1)pre-training a deep learning model on source domain; 2)transferring the learned weights of the first few layers (i.e.,what to transfer); 3)freezing the weights of transferred layers and retraining the parameters of the rest on target domain (i.e.,how to transfer).In this paper,we follow the general strategy mentioned above,and determine where to transfer the layers pre-trained on the source domain in accordance with the experiment strategy developed in [24].

Figure 1:The general transfer learning paradigm using pre-training and fine-tuning strategies
3 Methodology
In this section,we give a formal definition of the transfer learning task and descriptions of data preprocessing steps firstly.Then,the proposed 1D-convolutional network architecture is introduced.
Here,the schematic diagram of our proposed method is illustrated in Fig.2.

Figure 2:The schematic diagram of our proposed method
3.1 Problem Statement
Domain and task are basic conceptions in transfer learning.A domainDis defined asD={X,P(X)},whereXis the feature space andP(X)is the marginal distribution of data points.Here,Xdenotes the sample set.A taskTis defined asT={Y,g},whereY={1,2,···,C}is the label space,Cdenotes the number of categories,andgis the discriminant function that needs to be learned.Here,gis usually a conditional distributionP(y|x),where x ∈Xandy∈Y.Hence,a supervised learning task can be denoted as a tuple
Based on the definition above,the transfer learning can be defined as:given a source supervised learning task
3.2 Feature Space Alignment
To ensure the feature space of different datasets has the same mathematic representation,we utilize the GloVe word embedding algorithm [25] to align the feature space.Here,we treat each API or opcode as a word.The procedure of data preprocessing is illustrated in Fig.3.The extraction of opcode and API can be implemented through the use of reverse engineering tools or the monitor for the dynamic execution process of malware in a sandbox.
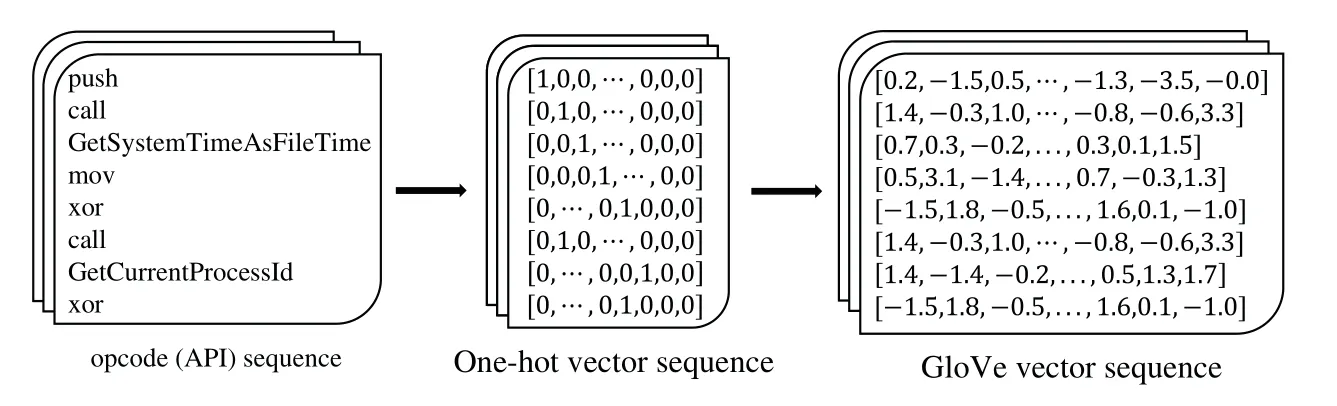
Figure 3:The procedure of data preprocessing
GloVe is a word embedding algorithm that takes advantage of both global statistical information and local context.Before training the word vectors,we need to use a sliding window to compute the word-word co-occurrence matrix M ∈Rn×n,wherendenotes the number of API(opcode)and Mijrepresents occurrence frequency of wordiaround the wordj.Then,the final optimization objective is shown in (1),wheref(·)is a weight assignment function in (2),and it is defined in accordance with the similar setting in [25].

Here,vi∈Rdand wj∈Rdrepresent thei-th row of V ∈Rn×dand thej-th row of W ∈Rn×d,respectively,whereddenotes the embedding size and {V,W}are both word embedding matrices,i.e.,each row of V and W are all word vectors that need to be trained.In addition,bvi(1 ≤i≤n)andbwj(1 ≤j≤n)are both bias terms that need to be updated during training.In practice,the optimization of the loss function (1)is based on the samples with batches,and therefore the word vectors in V and W are updated iteratively.
After the convergence of the training process,(V+W)will be used as the final GloVe word embedding matrix for malware classification.With the assistance of GloVe,all the datasets used in this paper are embedded into the same feature space.
3.3 Network Architecture
In this paper,we redesign the 1D-FCN architecture proposed in [13].To stabilize the training process,we replace the batch normalization with layer normalization and add shortcut connections to 1D-FCN,which is illustrated in Fig.4.In this figure,‘ReLU’means the rectified liner unit(ReLU)activation function widely used in neural networks,and it will set negative output to zero and keep non-negative output unchanged.Meanwhile,for multiclass classification task,‘Softmax’is an activation widely used as the last layer to output possibility distribution.
The functionality of basic 1D-convolutional operation is shown in Fig.5a,and the illustration of 1D-convolution with dilation is shown in Fig.5b.In Fig.5,each blue column represents a word vector obtained from GloVe word embedding algorithm,and green columns denote the 1D-kernel.A 1D-kernel acts like a sliding window and travels from left to right to perform convolutional operation.Compared to conventional 1D-kernel,1D-kernel with dilation can compute larger receptive field,as shown in Fig.5b.To prevent information leakage from the future into the past,padding zeros withL−1 length will be applied before convolution.Here,Ldenotes the length of 1D-kernel,and such operations are called causal convolution.
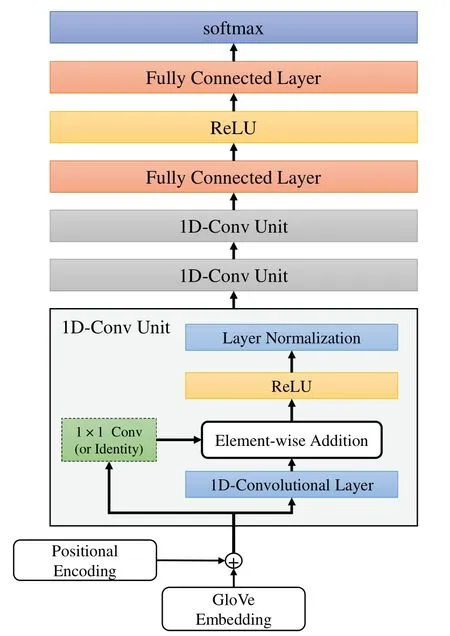
Figure 4:The architecture of our proposed 1D-convolutional network
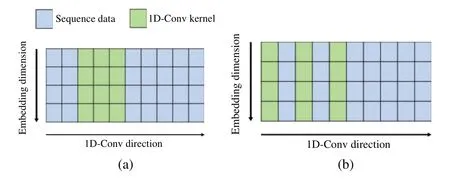
Figure 5:Illustration of 1D-convolution.(a)1D-Conv without dilation (b)1D-Conv with dilation
With the architecture we proposed,we evaluate 3 different convolutional strategies:1)FCN[13] (conventional 1D-convolution as shown in Fig.5a; 2)TCN [19] (1D-convolution with dilation as shown in Fig.5b,where the dilation is not a constant but expansion with the exponential rate,i.e.,the dilation factors of the convolutional layers are 20,21,22,...,sequentially; 3)gated convolutional network (GCN)(gated 1D-convolution which was first proposed in [11]).
Since different convolutional strategies share the same network architecture in our experiment settings,we select the gated convolutional layer (GCL)as our baseline convolutional strategy to tune the hyper-parameters.The GCL can be expressed by (3):

whereXis the input sequence data,KandMare two different 1D-convolutional kernels with the same shape,‘∗’is the convolution operator,and ‘⊙’denotes the element-wise multiplication.
Shortcut ConnectionDuring the training process of a deep learning model,to solve the gradient vanishing problem,the shortcut connection was proposed in [26].It is effective and concise shown in (4):

where x denotes the input data,F(·)represents a layer in a deep learning model,Activate(·)denotes the activation function,and z denotes the output of the shortcut connection.According to the shortcut connection,the low-level feature can pass into inner layers,and the fusion of low-level and high-level features is implemented implicitly.In our experiment settings,the number of input channels in the first convolutional layer may be inconsistent with the number of output channels.Hence,a 1×1 convolutional kernel is applied to adjust the shape of input sequence data to make sure element-wise addition operation is feasible.
Layer NormalizationCompared with batch normalization,the layer normalization (LN)is helpful to stabilize the training process,and it is more suitable for sequence data and independent of batch size [27],since its computation is limited to one single instance.The computation of LN is defined in (5):

where x is the input data that needs to be normalized,E[·] represents the operation of calculating average value of x,Var[·] denotes the operation of computing variance of x,εis a small constant that is used to avoid zero division error,and it is usually set to 10−5.Meanwhile,γandβare the affine coefficients to be learned during training,and they are usually initialized to 1 and 0,respectively.
Positional EncodingTo enrich the input sequence representation,positional encoding,which can provide the current positional information for the 1D convolution,is introduced in the proposed model.The utilized positional encoding can be formalized by (6)[28]:
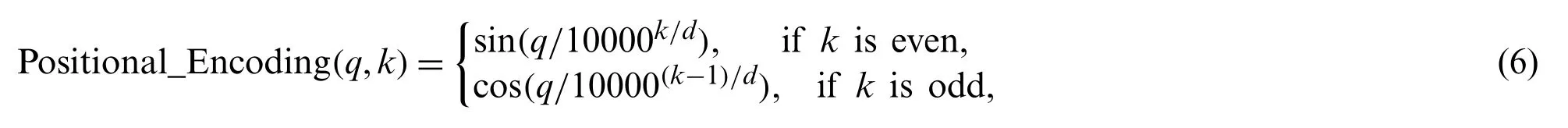
whereqdenotes theq-position in the sequence,dis the positional embedding size,kdenotes thekth entry of the positional vector.In addition,its visualization is illustrated in Fig.6.Each row in Fig.6 represents a position vector,and as time step increases,the changes in the high-dimensional component of the position vector become more significant.In this paper,the addition operation between the GloVe vector and positional vector is applied before the 1D-convolutional network.

Figure 6:Visualization of positional encoding
4 Experimental Results and Discussion
In our experiments,we choose Python 3.8,PyTorch 1.7 and CUDA 11.0 to build the convolutional network architecture.The proposed model is tested in a computer that runs Ubuntu and consists of NVIDIA 1080Ti,Intel(R)Xeon(R)CPU E5-2673 v3 and 64 GB memory.
4.1 Dataset
There are two Windows platform datasets,including a bigger one,i.e.,the Microsoft Malware Classification Challenge (BIG 2015)dataset from Kaggle competition [29],and a smaller one,i.e.,the Windows portable executable (PE)dataset from Allan et al.[30].To make full use of the diversity of the samples and the different malware families in the original datasets,we construct different transfer learning tasks to evaluate our proposed models more comprehensively.Hence,these two datasets are reorganized to conduct the experiments.After the data reorganization,the former bigger dataset is comprised of sequential opcode and API function names,and the latter one is comprised of API sequences.To extensively explore the performance of our proposed architecture,the former Kaggle dataset is split into 3 sub-datasets {A,B,C},and the latter PE dataset is split into 2 sub-datasets {D,E}.The statistical information about the sub-datasets{A,B,C,D,E}is presented in Table 1.In the second column of Table 1,each malware family in each dataset is assigned an index.The number of instances in different malware families is listed in Table 1,and their corresponding categories are also listed in the bracket.Additionally,the number of opcodes (APIs)in each dataset is listed in the third column.In addition,each sub-dataset is split into training set and test set according to the proportion 80% and 20%,respectively.

Table 1:Statistical information about the sub-datasets
(Continued)

Table 1(Continued)DatasetCategories and the corresponding indicesOpcode (API)0 1 2 B2936 (Kelihos_ver3)1168 (Obfuscator.ACY)1012 (Gatak)680 C446 (Vundo)294 (Tracur)387 (Kelihos_ver1)439 D100 (benign)100 (Backdoor)80 (Virus)179 E80 (Virus)100 (Worm)172 (Trojan)225
4.2 Parameters Selection
Here,GloVe word embedding algorithm is applied before the training process of the proposed architecture,and the hyper-parameters for the GloVe algorithm are listed in Table 2.Towards the proposed architecture,the key hyper-parameters,including output channels,kernel size in the convolutional layers,and the hidden dimension in the fully connected layer are determined by cross-validation.In addition,other hyper-parameters listed in Table 3 are selected by our engineering experience motivated by [13-15].

Table 2:Hyper-parameters for GloVe algorithm

Table 3:Hyper-parameters for transfer learning
The cross-validation results,i.e.,accuracy (mean ± std)on training set ofA,are shown in Fig.7.Firstly,the key hyper-parameters in the 1D-convolutional layer,i.e.,kernel size and the number of output channels,are tuned via grid search strategy.In Fig.7a,the horizontal axis denotes the kernel size and the vertical axis denotes the output channels.By observing the cross-validation performance,we select the best combination of output channel and kernel size,then 7 and 64 are chosen as kernel size and output channels,respectively.Moreover,in the fully connected layer,the hyper-parameter,i.e.,hidden dimension,is tuned with fixed kernel size and output channels from the previous results.In addition,according to the cross-validation results,as shown in Fig.7b,we select the hidden dimension value that achieves the highest accuracy,then 64 is selected as the hidden dimension.It should be noted that different convolutional networks used here have the same architecture.Therefore,the same hyper-parameter settings can be applied for all different networks on the same dataset.Here,we select GCN as our baseline model to tune hyper-parameters.When all the hyper-parameters are determined,the parameters of 1D-convolution network are initialized to random values,and then they are updated by Adam optimizer.
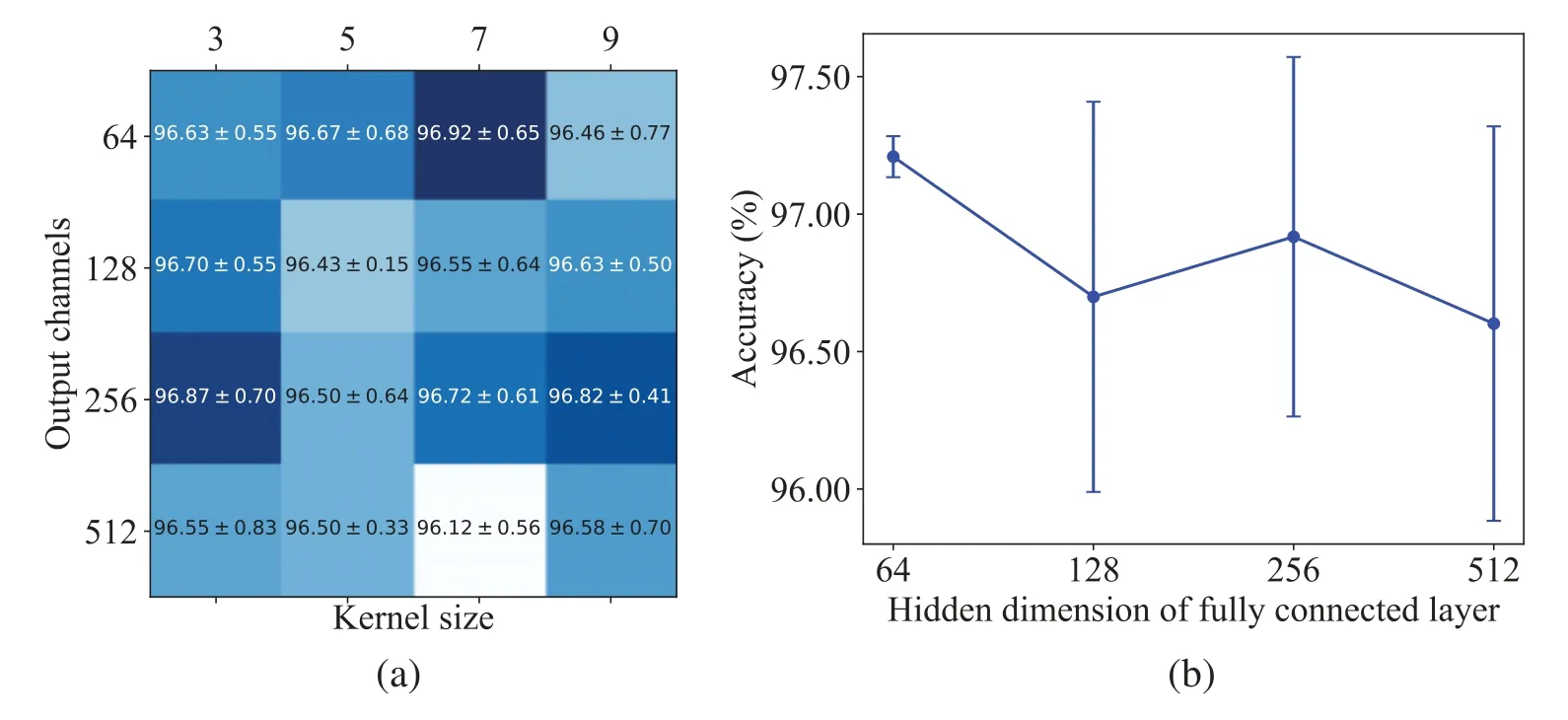
Figure 7:Cross-validation results (mean ± std%)for hyper-parameters tuning
4.3 Results and Discussion
To evaluate the performance ofour proposed 1D-convolutional architecture comprehensively,GCN,TCN and FCN are selected as comparative algorithms due to their validated excellent performance in many other tasks [11,19,22].To identify where to transfer the learned weights of the 1D-convolution network,we evaluate GCN on 4 transfer learning tasks:A→A,A→B,B→B,andB→A.In Figs.8a and 8d,we show the accuracy (mean ± std)changes on the test set with the increase of the transferred layers for the GCN structure.The baselineAandBrepresent the accuracy on test set ofAandBfrom the GCN without transferred layers.Meanwhile,AnBmeans the firstnlayers of a pre-trained GCN on datasetAare transferred to the corresponding firstnlayers in an untrained model and the remaining layers are fine-tuned onB.According to Fig.8a,the fine-tuning is able to recover the accuracy no matter how many layers are transferred forAnAtask,which means fragile co-adaptation phenomenon does not exist in this transfer learning task.In addition,the performance of transfer learning is dropped with the increase of the transferred layers forAnBtask,which is caused by task-specific features learned by the model.Similarly,BnBandBnAhold the same conclusion,as shown in Fig.8d.Furthermore,as shown in Figs.8b,8c,8e,and 8f,the experimental results of TCN and FCN also hold the same conclusion.Additionally,in order to find out how much time can be reduced by transfer learning,the training time of the fine-tuned model and the pre-trained one is recorded,and then the ratio between them is calculated,as illustrated in Fig.9.The results demonstrate that transferring one convolutional layer is able to reduce the training time by over 10% and transferring all 3 convolutional layers can reduce over 30% of the time.Moreover,the GCN is the most effective model to reduce training time.

Figure 8:Accuracy with different transferred layers.(a) AnX tasks using GCN.(b) AnX tasks using TCN.(c) AnX tasks using FCN.(d) BnX tasks using GCN.(e) BnX tasks using TCN.(f) BnX tasks using FCN

Figure 9:Ratio with different transferred layers.(a)GCN.(b)TCN.(c)FCN
We evaluate 3 different 1D-convolutional strategies on 6 transfer learning tasks,as shown in Table 4.Here,‘XCN-n’means transferring the firstnlayers of XCN,and each row in Table 4 demonstrates experimental results of XCN-non different transfer tasks.For a fair comparison,TCN and FCN have the same hyper-parameters as GCN.From Table 4,in most cases,transferring the first 2 convolutional layers is better than transferring the first 3 layers directly,since the top convolutional layer is more task-specific than previous layers.However,the improvement is slight or even negative when the number of training instances in the target domain is small (i.e.,DandE).
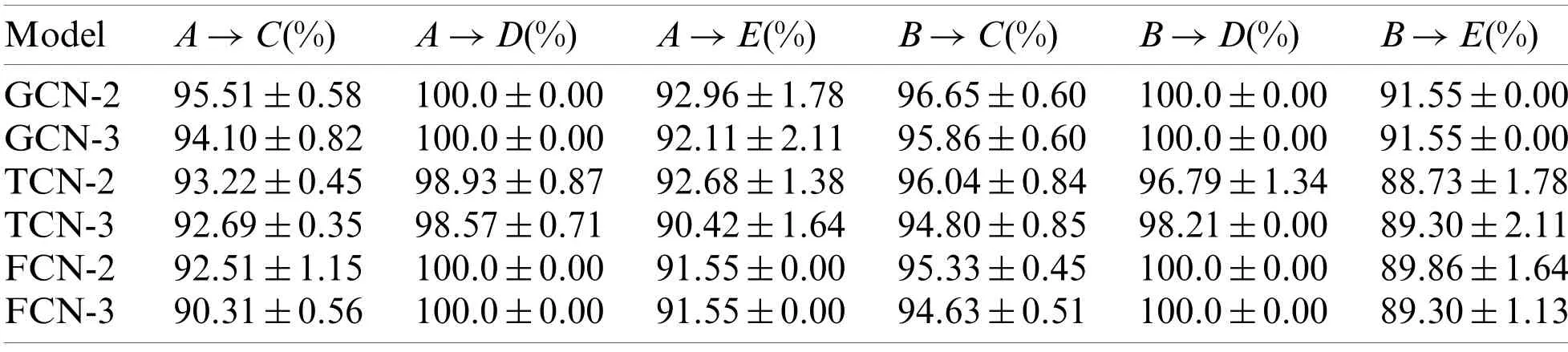
Table 4:Accuracy (mean ± std)with different transfer tasks on test set
The other conclusion revealed by Table 4 is that the source domain,which contains more behavior representation,is more capable of improving the performance of transfer learning tasks.For example,the source domainAcontains 1070 opcodes (APIs)andBcontains 680 opcodes(APIs).Hence,the performance ofA→DandA→Eis better than (or equal to)the performance ofB→DandB→E.In addition,the accuracy ofA→Cis less than that ofB→C,sinceBandCboth contain Kelihos malware as shown in Table 1,which meansBandCare more similar.
5 Conclusion
In this paper,we propose a 1D-convolutional architecture for malware classification,and then evaluate the architecture via 3 convolutional strategies on 6 transfer learning tasks.Our experimental results verify that the transfer learning technique is an effective approach to reuse the learned knowledge from other datasets,and transferring the first 2 convolutional layers is a better choice for this malware classification task.Moreover,the experimental results also demonstrate the time reduction in the training process.For future work,our proposed method is expected to be evaluated on other extensive tasks,and domain adaption techniques will be further investigated for performance improvement.
Funding Statement:This work was supported in part by the National Natural Science Foundation of China under Grants U1836106 and 81961138010,in part by the Beijing Natural Science Foundation under Grants 19L2029 and M21032,in part by the Scientific and Technological Innovation Foundation of Foshan under Grants BK20BF010 and BK21BF001,in part by the Scientific and Technological Innovation Foundation of Shunde Graduate School,USTB,under Grant BK19BF006,and in part by the Fundamental Research Funds for the University of Science and Technology Beijing under Grant FRF-BD-19-012A.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2022年2期
Computer Modeling In Engineering&Sciences2022年2期
- Computer Modeling In Engineering&Sciences的其它文章
- A Chopper Negative-R Delta-Sigma ADC for Audio MEMS Sensors
- Human Stress Recognition from Facial Thermal-Based Signature:A Literature Survey
- The Material Deformation and Internal Structure Development of Granular Materials under Different Cyclic Loadings
- Estimating Daily Dew Point Temperature Based on Local and Cross-Station Meteorological Data Using CatBoost Algorithm
- CFD-Based Evaluation of Flow and Temperature Characteristics of Airflow in an Aircraft Cockpit
- Performance Analysis of Magnetic Nanoparticles during Targeted Drug Delivery:Application of OHAM