
COVID-19 Detection via a 6-Layer Deep Convolutional Neural Network
2022-06-30 09:29ShoumingHouandJiHan
Shouming Hou and Ji Han
School of Computer Science and Technology,Henan Polytechnic University,Jiaozuo,454000,China
ABSTRACT Many people around the world have lost their lives due to COVID-19.The symptoms of most COVID-19 patients are fever,tiredness and dry cough,and the disease can easily spread to those around them.If the infected people can be detected early,this will help local authorities control the speed of the virus,and the infected can also be treated in time.We proposed a six-layer convolutional neural network combined with max pooling,batch normalization and Adam algorithm to improve the detection effect of COVID-19 patients.In the 10-fold cross-validation methods,our method is superior to several state-of-the-art methods.In addition,we use Grad-CAM technology to realize heat map visualization to observe the process of model training and detection.
KEYWORDS COVID-19; deep learning; convolutional neural network; max pooling; batch normalization; Adam;Grad-CAM
1 Introduction
COVID-19 is a disease that easily spreads among people.It originated from the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2)[1].The spread of this disease includes humanto-human contact,or contact with polluted air,as well as respiratory droplets and feces [2].Therefore,the authorities have adopted a series of measures,including wearing masks in public places,quarantining people entering the country from abroad,and reminding people of the country not to travel to high-risk areas [3].
Early detection of COVID-19 helps various departments to take preventive and control measures in advance to protect the safety of local residents.The most commonly used testing methods are real-time reverse transcription polymerase chain reaction (RT-PCR)and point-of-care (POC)methods [4].POC can be used to detect genes encoding viral proteins in respiratory samples,and this method test takes less than an hour to get the result.POC can be used to detect genes encoding viral proteins in respiratory samples.This method only takes a few minutes to get the test results.However,the sensitivity of these two methods may not be sufficient to detect early infections caused by low virus concentrations.
Traditional artificial intelligence (AI)methods [5] may not work well on handling complicated image processing tasks [6].Now,many researchers use deep learning (DL)methods to optimize the detection of certain diseases based on medical images.For example,Guo et al.[7] employed ResNet-18 to detect Thyroid Ultrasound Standard Plane images.Wu [8] chose to combine wavelet Renyi entropy with their proposed three-segment biogeography-based optimization.Ni et al.[9]proposed a deep learning approach (DPA)for COVID-19 detection.Wang [10] combined graph convolutional network (GCN)with convolutional neural network (CNN)using deep feature fusion method.Wang [11] proposed a novel CCSH network to detect COVID-19.There are many other successful applications of deep learning cases [12-14],which all prove the powerfulness of DL.
In addition,more and more researchers also use transfer learning.Transfer learning is suitable for situations where a large number of source data features in the training model are similar to a small number of target data features in the detection model,so it is not suitable for our experiments.In this paper,we collected CT images of COVID-19 and proposed a 6-layer convolutional neural network method to detect COVID-19.Max pooling proved to perform better than other traditional pooling methods.Batch normalization effectively improves the training speed of convolutional neural networks.Adam algorithm is better than other algorithms in terms of model training effect.
The remaining chapters of this paper are as follows.Section 2 introduces the collection of datasets and the characteristics of the datasets.Section 3 describes the various modules of the convolutional neural network.Section 4 introduces the model we built and analyzes the experimental results.In the last section,we made a summary of our experiments and results.
2 Dataset
The image dataset was from [15].In the experiment,Philips Ingenuity 64-line spiral CT machines were used to collect lung pictures.During the CT scan,keep the patient supine and breathe deeply back,which helps scan from the lung tip to the rib diaphragm angle.
The image slices we collected came from 142 COVID-19 patients and 142 healthy people.From the CT images of each subject,1-4 slices were selected as experimental data,and the resolution rate of all images was 1,024×1,024.Table 1 shows the characteristic data of the collected objects.In Fig.1,we can find that the lung biopsy samples of COVID-19 patients have obvious white lesions.

Table 1:The characteristic data of the collected objects
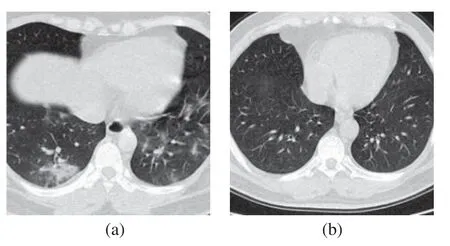
Figure 1:The sample of lung slices from patient with COVID-19 and healthy person.(a)COVID-19 (b)Normal
3 Methodology-CNN
Convolutional neural network is a classifier,this method can identify normal images and abnormal images from medical images [16].A classic neural network consists of an input layer,a convolutional layer,a pooling layer,a fully connected layer and an output layer [17,18].The convolutional layer and the pooling layer are used to extract image features,and the fully connected layer is used for image classification.Fig.2 shows the flowchart of CNN.
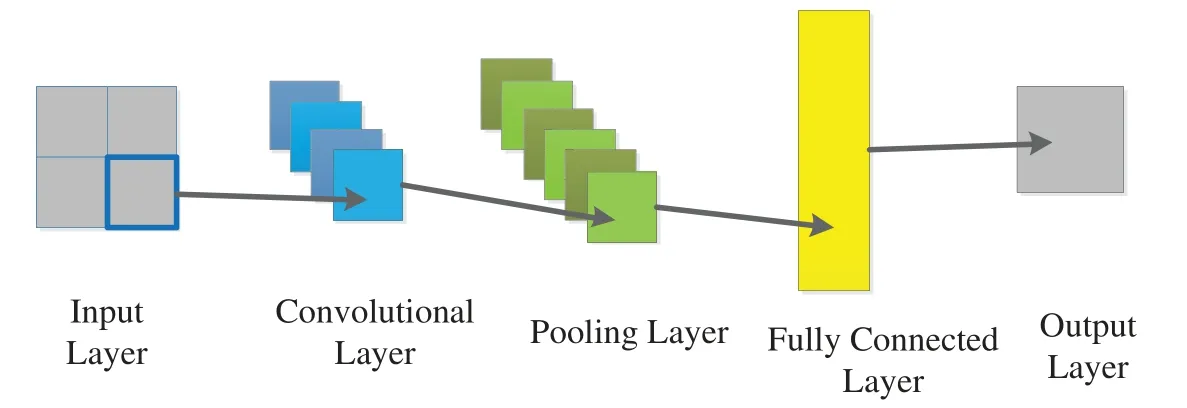
Figure 2:The flowchart of CNN
3.1 Convolution Layer
In the convolutional layer,the input image data and the kernel are convolved to output the feature map.The operation of the convolutional layer contains three hyperparameters [19],which are kernel size,filter depth,and stride.The kernel size represents the pixel size of the convolution filter.The filter depth controls the number of output feature maps,representing the number of filters in the convolutional layer.The stride determines how many pixels the filter will skip in each convolution [20].The case of convolution operation is shown in Fig.3.And the convolution operation is as follows:


Figure 3:The case of convolution operation
3.2 ReLU Function
The convolutional layer will be followed by an activation function,such as Sigmoid and Relu,their activation curve is shown in Fig.4.Sigmoid is a traditional non-linear activation function,and its output is bounded,and the output value ranges from 0 to 1 [21].The activation formula is as follows:

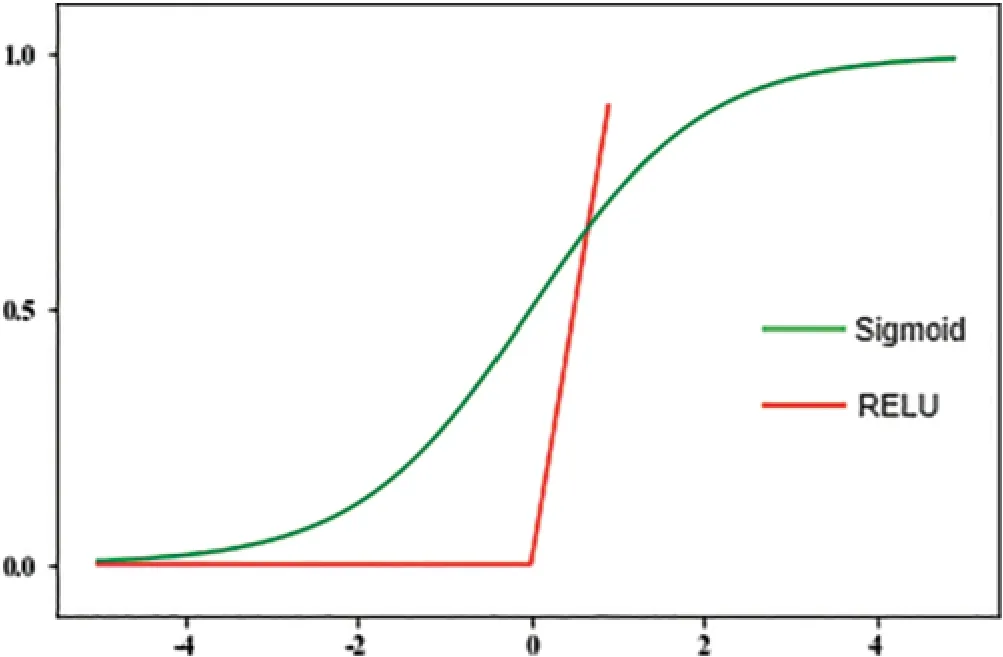
Figure 4:The activation curve of Sigmoid and ReLU
Since the Sigmoid function encounters an input value that is too large or too small,its curve slope will tend to zero,which is likely to cause the gradient descent of the neural network.However,some of the output values of the ReLU function are 0,which avoids the problems existing in Sigmoid,which can reduce overfitting and solve the gradient descent problem.Therefore,compared with Sigmoid,the ReLU function can speed up model training.The calculation formula of Relu is as follows:

3.3 Batch Normalization
In the experiment,we used batch normalization technology [22] to solve the problem of internal covariate shift.This technology ensures that the data set distribution after convolution is more uniform,thereby increasing the learning rate of the training model and speeding up the training process [23].The calculation steps for batch normalization are as follow.First,calculate the average of the minibatchφbased on the input valuewi.

Second,calculate the variance of the minibatch

Third,in order to prevent abnormal operations,we added a constantτto the denominator

Finally,multiply Fiby the scaleαand add the shiftθ.

3.4 Pooling
The pooling layer is used to reduce the dimensionality of the feature vector output after the convolution operation,which can prevent overfitting.The most common pooling methods are max pooling (Mp),average pooling (Ap)andl2norm pooling (l2p)[24].Mp calculates the max value of the pooling area,and Ap outputs the average value of the pooling area.The value obtained byl2pis the arithmetic square root of the sum of the squares of the elements in the pooling area.The three pooling operations are shown in Fig.5.
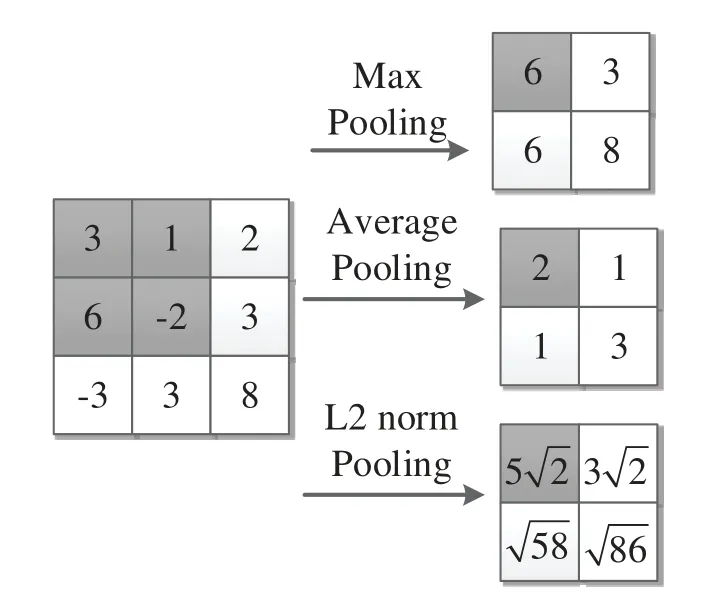
Figure 5:The three pooling operations
Suppose the pooling area is G,and the dataset to be activated in G is D.The definition of D is as follows:

The Mp was defined as

The Ap was defined as

Thel2pwas defined as

3.5 Fully Connected Layer and Softmax
Fully connected layer (FCL)[25] is used to classify feature images after pooling [26].And the neurons in the fully connected layer are fully connected to the neurons in the adjacent layer.The flowchart of the FCL is shown in Fig.6.The calculation formula of the FCL is as follows:

where i represents the value input to the FCL,and w~and b~are the weight matrix and bias respectively [27].I~is the output of the FCL.

Figure 6:The flowchart of the FCL
When the FCL is used for linear feature extraction,an activation function will follow.The most commonly used is the softmax activation function [28].Its calculation formula is as follows:

where∂is the input value and j represents the jth cluster.S(∂|yj)is the conditional probability of∂belonging to the jth cluster,andS(yj)is the prior probability of the cluster.The result ofβj(∂)is between 0 and 1.
3.6 Training Algorithms
In the experiment,for the complexity of the deep learning training model,we chose a suitable optimization algorithm to optimize the model.Adam (Adaptive momentum)[29,30] is a gradient descent optimization technique that calculates the learning rate of each step by controlling the first and second moments of the gradient.And it can also correct the deviation and keep the parameters stable [31].The formula for Adam is as follows:

where c represents the calculated gradient,kzis the first moment of the gradient c,and Lzrepresents the second moment of the gradient c.μ1represents the first moment attenuation coefficient,andμ2represents the second moment attenuation coefficient.ϑrepresents the parameter to be updated,and K−zand L−zare the offset correction of Kzand Lz,respectively.
3.7 Cross Validation
In the experiment,we need to train and test the data set to verify the detection effect of the model.In order to analyze the performance of the constructed model,we adopted the cross-validation technology,which is a widely used method for optimizing and evaluating model performance [32,33].
We chose the K-fold cross-validation method to divide the collected data set into K equal subsets.K-1 equal subsets are trained in the experiment,and the one that is not trained is used for testing.This process is iterated k times,and each subset will be used for testing.In this paper,we used 10-fold cross validation,which has very little error in evaluating model performance.The operation of 10-fold cross validation is shown in Fig.7.
3.8 Measures and Heatmap
In order to evaluate the performance of the built CNN model in training and testing the data set in the experiment,we selected some ideal indicators,including Sensitivity (E1),Specificity(E2),Precision (E3),Accuracy (E4),F1-Score (E5),Matthews correlation coefficient (E6),Fowlkes Mallows index (E7)[34].The calculation formulas for these indicators are as follows:


Figure 7:The operation of 10-fold cross validation
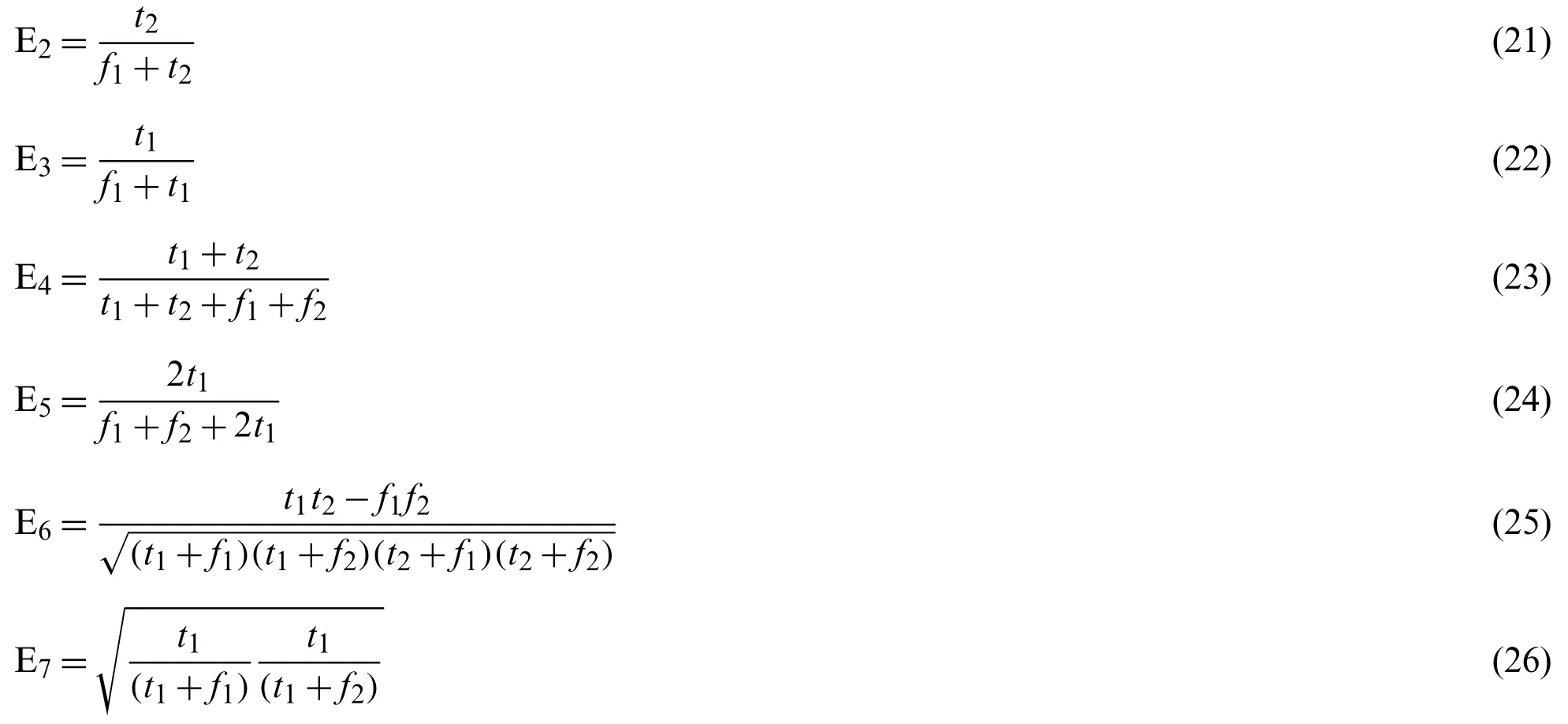
where t1,t2,f1,and f2represent true positive (TP),true negative (TN),false positive (FP),and false negative (FN),respectively.t1and t2indicate the correct classification of COVID-19 patients and healthy people.f1and f2indicate the misclassification of COVID-19 patients and healthy people,respectively.
In the deep learning model,the entire training process cannot be visualized intuitively,so it is easy for radiologists to be confused whether the model can accurately detect abnormal areas in the CT image.We applied Grad-CAM technology to our model so that image features can be colored to easily distinguish between normal and abnormal regions in CT images [35].Grad-CAM technology helps the model to accurately focus on key areas.
4 Experiment Results and Discussions
4.1 Structure of Proposed CNN
In the paper,we built a six-layer CNN.The architecture of the CNN is shown in Fig.8.This CNN includes three convolutional layers,three max pooling layers and three FCLs.The parameters in the activation map are marked on each layer.

Figure 8:The architecture diagram of the 6-layer CNN
4.2 Statistical Results
Table 2 shows the 7 evaluation index results of the 6-layer CNN we built under 10-fold cross-validation.The results of Sensitivity,Specificity,Precision,Accuracy,F1-Score,Matthews correlation coefficient,and Fowlkes Mallows index are 90.97%,89.58%,89.51%,89.52%,89.58%,79.07%,and 89.59,respectively.

Table 2:Evaluation results of 6-layer CNN
4.3 Pooling Comparison
In the experiment,we applie d the Mp layer to the six-layer CNN model,and compared withl2player and Ap layer.Table 3 shows the comparison of the results of the 3 pooling methods based on 7 indicators under the 10-fold cross validation.In Fig.9,we can see the performance comparison of different pooling more intuitively,and the results show that using the Mp method can obtain better results than the other two pooling methods.

Figure 9:Comparison of three pooling techniques
4.4 Training Algorithm Comparison
In the experiment,we used Adam algorithm to optimize the 6-layer convolutional neural network and compared it with the SGDM and RMSProp optimization algorithms.SGDM is based on first-order momentum to reduce the oscillation in the best direction along the steepest path during the gradient descent process.RMSProp is an adaptive learning rate method that normalizes the gradient by using the exponential moving average of the gradient magnitude of each parameter.The experimental results are shown in Table 4 and Fig.10.From the perspective of sensitivity (E1),the results of SGDM and RMSProp algorithms are 83.99% and 88.29%,respectively,but ADAM algorithm reaches 90.97%,so ADAM algorithm performs better than SGDM and RMSProp algorithms.At the same time,the result of ADAM algorithm based on index Matthews correlation coefficient (E6)is 79.17%,which is obviously better than the results 65.98% and 72.92% obtained by SGDM and RMSProp algorithms.Therefore,the performance of the ADAM algorithm in the model we built is significantly better than the other two algorithms.

Table 4:Comparison of three training algorithm

Figure 10:Comparison of three training algorithm
4.5 Comparison of Different Number of Conv Layers
When using CNN to detect CT images,increasing the number of convolutional layers is beneficial to improve the detection effect.But this does not mean that the more layers of convolutional layers,the better the result of the CNN.In order to select an appropriate number of convolutional layers,we compared the performance of convolutional neural networks with different convolutional layers in our experiments.The experimental results are shown in Table 5.We found that when the number of convolutional layers increased from 1 to 3,the performance became better and better,but when the number of layers continued to increase,the effect began to decrease.Therefore,our model works best when the number of convolutional layers is 3.At the same time,we made a clearer comparison in Fig.11.

Table 5:Comparison of different conv layers

Figure 11:Comparison of different conv layers (conv lyers = CL)
4.6 Comparison of Different Number of FCLs
Most convolutional neural network models contain 2 fully connected layers,which can already achieve good results.But in our experiment,comparing the performance of models containing different numbers of FCLs,the experimental results are shown in Table 6,and Fig.12 clearly shows their performance differences under various indicators.We found that when the number of FCLs in the model is 3,the performance is best.

Table 6:Comparison of different FCL layers
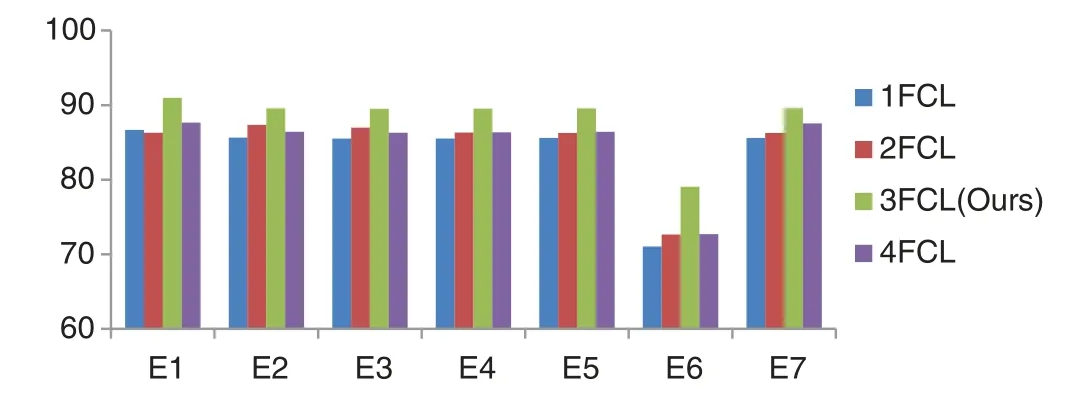
Figure 12:Comparison of different FCL layers
4.7 Comparison to State-of-the-Art Approaches
In the experiment,we compared our proposed method with several advanced methods,including ResNet-18 [7],WRE+ 3SBBO [8],and DPA [9].Guo et al.[7].proposed an 18-layer CNN model ResNet for image classification.Wu [8].proposed a method based on a feedforward neural network and combining wavelet Renyi entropy and a proposed three-segment biogeography-based optimization (3SBBO)algorithm to detect COVID-19.Ni et al.[9].used a deep learning method to accurately identify and quantitatively evaluate chest CT image features of patients with COVID-19.The comparison results based on 7 indicators are shown in Table 7,and the difference in the comparison results is clearly shown in Fig.13.Although ResNet-18 [7] performs a little better on indicators E2and E3than our method,the results of our proposed method are better than it under the other five indicators.The result of DPA [9] under indicator E1is superior than our proposed method,but the performance under the other six indicators is not as good as our proposed method.Therefore,our method performs best in a combination of 7 indicators.

Table 7:Comparison of state-of-the-art approaches
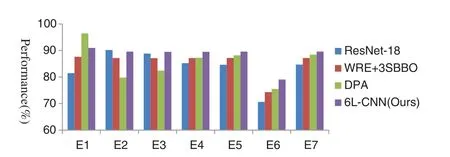
Figure 13:Comparison of state-of-the-art approaches
4.8 Heatmap
Fig.14 shows the heatmap effect produced by using Grad-CAM technology to manipulate the image.Images b and d are heatmaps of the lung CT images of COVID-19 patients and healthy people,respectively.In Fig.14b,the lung lesion area with COVID-19 is marked in red,while the healthy lung in Fig.14d is not marked.It is found that the heatmap can clearly and accurately visualize the model detection area,which is beneficial to the guarantee of the model training process.
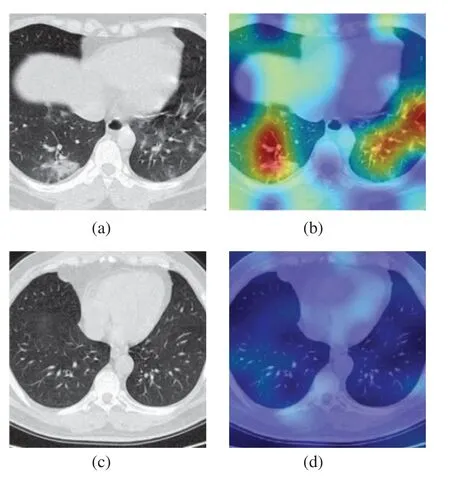
Figure 14:Heatmap of lungs of patients with COVID-19 and healthy people (a)COVID,(b)Heatmap of (a),(c)Healthy,(d)Heatmap of (c)
5 Conclusions
In this paper,we proposed a 6-layer CNN for the detection of COVID-19 and combined the Mp,batch normalization and Adam optimization algorithms.The effect of our proposed method is better than other state-of-the-art methods.The accuracy (E4)of our method reached 89.52%.Grad-CAM technology makes our models to be displayed more intuitively.
However,there is also a flaw in our research that the dataset is not very large,which will have little impact on the effect of model training.So,in future research,we will collect more data to ensure the adequacy of our proposed method in the training process.At the same time,we will build a more superior model based on DL methods to improve the result of COVID-19 detection.We will also share our methods so that other researchers can conduct research on our basis and accelerate the research speed of COVID-19 detection.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
 Computer Modeling In Engineering&Sciences2022年2期
Computer Modeling In Engineering&Sciences2022年2期
- Computer Modeling In Engineering&Sciences的其它文章
- A Chopper Negative-R Delta-Sigma ADC for Audio MEMS Sensors
- Human Stress Recognition from Facial Thermal-Based Signature:A Literature Survey
- The Material Deformation and Internal Structure Development of Granular Materials under Different Cyclic Loadings
- Estimating Daily Dew Point Temperature Based on Local and Cross-Station Meteorological Data Using CatBoost Algorithm
- CFD-Based Evaluation of Flow and Temperature Characteristics of Airflow in an Aircraft Cockpit
- Performance Analysis of Magnetic Nanoparticles during Targeted Drug Delivery:Application of OHAM