
基于图像增强与样本平衡优化的行人属性识别①
2022-06-29 07:48韦学艳吴春雷王雷全
计算机系统应用 2022年6期
韦学艳, 吴春雷, 王雷全, 吴 杰, 李 阳
(中国石油大学(华东) 计算机科学与技术学院, 青岛 266580)
1 引言
行人属性识别, 其任务的主要目的是挖掘给定图像中行人的属性特征, 进而对属性进行分类, 最终能够预测测试集中行人的属性标签, 比如性别、年龄、衣服颜色、衣服样式等. 属性识别一直是计算机视觉中比较热门的领域, 在许多方向都有着广泛的应用, 比如基于属性的人脸相关技术[1–3]已经相当成熟, 应用于日常生活中的各个领域. 随着近几十年监控设备在全世界普及, 监控场景下的行人属性识别[4–6]任务也越来越受到重视, 但是由于监控设备和普通设备所拍摄的图像的差异, 往往存在以下几个问题: (1)图像尺寸较小,分辨率低; (2)行人图像为抓拍图像, 可能存在姿态变换、遮挡、模糊等情况; (3)摄像头为固定摄像头, 受天气、光线、角度等外界因素影响; (4)数据集往往从某一区域某一时间段内获取, 通常存在严重的特殊性.
深度学习出现以后, 大量的行人属性识别模型针对上述问题做出了贡献. Fabbri 等人[7]基于对抗生成网络的模型对遮挡图片进行生成补充, 扩充行人的特征信息; Li 等人[8]基于图来建模区域和属性间的空间关系和语义关系. 这些方法有效地改进了遮挡以及分辨率较低情况下的属性识别, 但是处理方式仅仅针对图像特征提取方式进行改进处理, 忽视了数据集本身存在的问题, 比如行人主体区域不突出、背景噪音干扰严重以及现实生活中季节性以及习俗性导致的属性正负样本分布不平衡的问题.
从数据集角度来说, 虽然图像都为单行人图像, 但是由于监控拍摄的随机性, 图像的分辨率通常比较低并且仍然存在着许多无用的背景噪音信息, 如图1, 背景中的汽车、自行车等信息往往会对属性识别造成不利影响. 另外, 随着跨任务模型[9,10]的出现, 许多其他任务的数据集尝试被标注上属性信息, 应用于行人属性识别, 比如基于传统行人重识别数据集改进的Market-1501-attribute 数据集, 把属性信息与行人身份编号信息相结合, 将其应用于行人属性识别和行人重识别任务. 然而, 由于数据集的提出并不是以属性识别作为基础解决任务, 因此数据集通常包含着严重的正负样本不平衡的问题, 如图2, 由于社会习俗原因, 下衣为黑色的样本占比较多.

图1 背景中的汽车、自行车对行人特征造成影响

图2 下衣为黑色的正样本数量远大于负样本数量
因此, 基于上述观察, 本文提出了一种图像增强与样本平衡优化模型IEBO (image enhancement and sample balance optimization), 在图像特征提取之前, 先进行色彩增强并通过提取行人主体区域的方式减少背景噪音对行人信息的干扰, 再经过深层神经网络提取行人核心特征, 然后基于身份信息针对不平衡属性进行样本平衡优化, 最终达到提高属性识别性能的目的.
综上所述, 本文的贡献是:
(1)提出基于色彩增强与噪音抑制的图像增强方法, 突出行人核心特征并挖掘行人整体图像, 抑制背景噪音信息防止其对属性识别造成干扰.
(2)提出基于身份信息融合的行人属性样本平衡优化算法, 调节跨任务数据集正负样本不平衡的缺陷,提升模型的识别能力.
(3)在跨任务Market-1501-attribute 数据集的样本不平衡属性中取得了较好的结果.
2 相关工作
行人属性识别主要是将给定图像中行人的属性特征挖掘出来, 进而对各个属性进行分类, 最终生成的识别模型能够预测图像中行人的属性标签, 比如性别、年龄、衣服颜色、衣服样式等. 其中头发、衣服、鞋子等属性, 可以具体定位到图像中的某一区域, 被称为是低级属性, 而像性别、年龄等属性是较为抽象的概念, 并不针对某一区域, 则被称为是高级属性. 与传统手工提取的特征相比, 神经网络提取出的属性特征可以看作高级语义信息, 从而能够判断出更深层次的语义含义. 因此, 计算机视觉领域中许多的任务通过结合属性识别技术来辅助其执行从而获得更好的性能, 如行人重识别、人脸检测等. 但是由于视角变换、遮挡、低分辨率、数据集样本不平衡等原因, 行人属性识别的进一步应用仍是一个亟待解决的难题.
2.1 属性识别
近些年深度学习的稳步发展, 使基于神经网络的深度学习算法逐渐广泛应用于行人属性识别任务当中[11,12].与传统的手工特征方法相比, 基于卷积神经网络的深度学习方法在行人属性识别精度上获得了更好的结果.Li 等人[9]考虑到属性任务的统一性, 基于深度学习方法提出了针对单属性和多属性分类的模型DeepSAR、DeepMAR, 单属性分类一次只预测一个属性, 而多属性分类一次可以预测多个属性, 并同时提出了数据集样本不平衡的问题, 但是该模型只考虑了正样本过少的情况, 忽略了正样本过多以及不同类别的属性分布不一致的情况. Fabbri 等人[7]针对行人遮挡以及分辨率低等问题, 提出了基于对抗生成网络的模型GAM,利用生成网络对遮挡图像进行生成补充, 扩充图像特征信息; Li 等人[8]考虑到属性之间的相关性, 提出了基于推理框架的模型VSGR, 针对区域到区域, 属性到属性, 区域到属性的空间关系和语义关系进行建模并预测属性信息, 在一定程度上减小了行人遮挡以及分辨率低带来的影响. 但是这些方法大多针对图像特征提取的方式进行改进处理, 并没有考虑到原始图像本身存在的问题, 比如行人核心特征不突出、背景噪音信息干扰严重以及正负样本不平衡等.
2.2 跨任务模型
随着深度学习的崛起, 跨任务研究也开辟了新的热点方向, 行人属性识别任务与行人重识别任务的结合, 使各自性能都有了很大的提升. 行人属性识别的通用数据集一般以PETA[13]为主, 后来由于多任务融合的出现, 传统的数据集已不能满足需求. Lin 等人[14]在行人重识别任务的传统数据集Market- 1501[15]上标注了行人属性, 并提出了以行人属性辅助行人重识别的方法; Sun 等人[10]也同样将行人属性集成到行人重识别模型当中, 辅助行人的辨识任务; 腾讯优图实验室的Liu 等人[16]提出了一个新的模型JCM, 将属性和图像映射为一个序列统一进行学习, 并使用行人身份信息辅助行人属性识别; Yang 等人[17]根据属性层次和身份层次异同, 提出层次特征模型HFE, 通过行人身份信息聚合同一行人的图像, 以此提高属性识别任务的性能.但是以行人身份信息辅助行人属性识别, 其任务核心是属性识别, 如果不合理利用行人身份信息, 将会导致模型忽略掉属性识别任务的最初目标, 给模型带来不利的影响. 虽然跨任务研究进一步提升了行人属性识别的效果, 然而在自然场景下, 行人属性识别仍然面临着多重挑战.
3 图像增强与样本平衡优化网络
本文提出一个新的深度学习网络图像增强与样本平衡优化模型IEBO, 如图3, 该模型包含IE、SBO 两部分, 给定1 张输入图像, 经过IE 模块对图像进行优化处理, 使行人特征更加突出, 之后经过传统卷积网络ResNet50 提取行人特征, 最后经过SBO 模块, 对不平衡属性进行优化处理, 最终预测行人的整体属性值. 本节分别从图像增强模块、样本平衡优化模块分别对模型进行展开讨论.
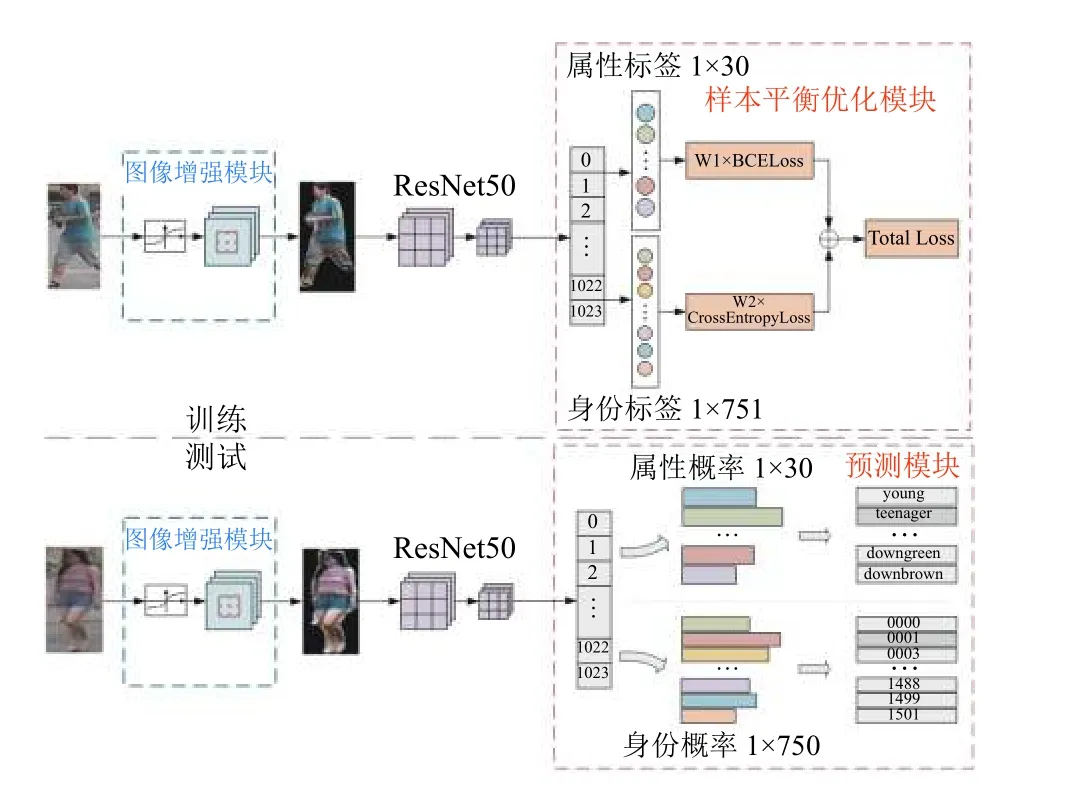
图3 IEBO 模型整体结构图
3.1 图像增强模块
基于监控系统的行人属性识别, 由于数据集图像尺寸较小、分辨率低, 在进行特征提取时往往存在主体区域不突出、背景噪音存在等问题, 这通常会导致行人核心特征提取不充分, 识别结果不理想. 因此, 特征提取前的图像处理至关重要. 输入行人图像之后, 首先通过色彩增强[18]对图像进行处理, 目的是使行人核心特征更加突出, 色彩更加饱和, 有利于行人特征信息的提取.
第一阶段适应局部图像对比度, 首先将像素值映射到[0, 1]范围, 然后分别对彩色图像的RGB 通道单独进行处理, 计算每个像素点的F(X)值. 公式如下:

第二阶段对图像进行调整以获得全局白平衡, 首先通过最大最小归一化将F(x)拉伸到[0, 1]范围, 然后恢复到RGB 像素值. 公式如下:
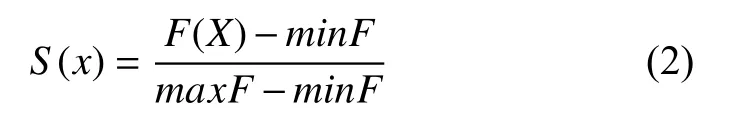
其中,minF为F(x)函数的最小值,maxF为F(x)函数的最大值. 通过色彩增强算法, 提高了行人图像的动态范围和色彩饱和度, 使核心特征更加明显, 有利于更充分的提取行人特征信息.
然而, 图像中仍然包含一些无用的背景信息, 这些信息有可能会对特征提取造成干扰. 因此, 需要对图像进行噪音抑制处理. 图像色彩增强之后, 使用谷歌Chen 等人[19]提出的基于ResNet101 的DeepLabv3 模型对行人背景进行分割, 模型尝试通过级联与并行的空洞卷积的方式对图片进行处理, 如图4, 前边卷积模块采用传统的ResNet101 网络结构, 之后通过一层rate=2的空洞卷积, 并且经过金字塔池化ASPP 模型, 同时对特征进行rate=1, 6, 12, 18 四个空洞卷积和一个全局池化的并行处理, 其中,rate=1 为普通卷积, 最后将并行特征图进行连接, 并输入到传统的卷积神经网络中进行上采样恢复到原图.
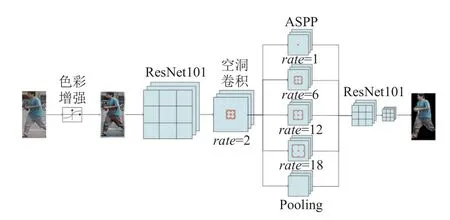
图4 图像增强模块
在进行行人分割的同时, 将检测出的实例框以外的背景区域置0. 通过背景置0 的方式, 将无用的信息去掉, 可以有效防止背景噪音在特征提取过程中对行人核心特征造成干扰.
3.2 样本平衡优化模块
近几年, 由于深度学习的发展, 跨任务研究逐渐进入大众视野, 研究人员将行人重识别领域的传统数据集Market-1501 数据集标注上行人属性信息, 作为可以结合行人身份信息与行人属性信息的数据集进行使用. 因此, 模型利用身份信息进行辅助属性识别,如图5.
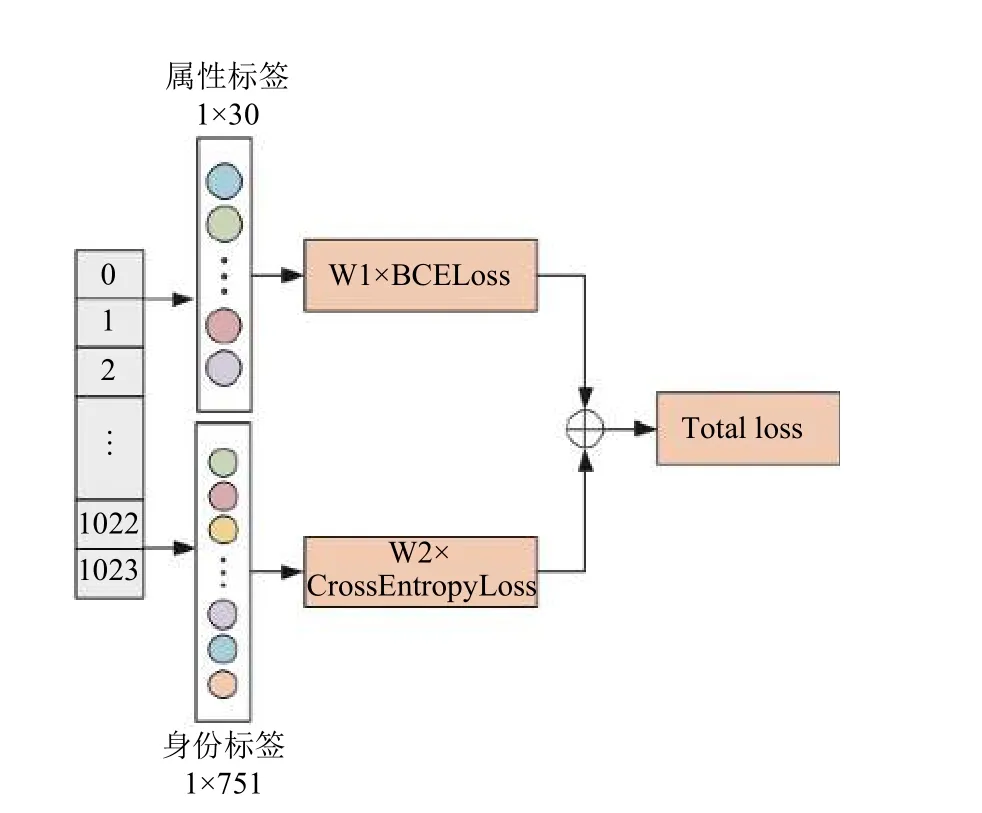
图5 样本平衡优化模块
然而, 由于数据集不是以属性识别任务进行创建的, 所以在属性方面, 数据集存在正负样本不平衡的问题. 比如在“上衣类型”这一属性中, 正样本“上衣为短袖”远比负样本“上衣为长袖”的样本数量要多; “下衣颜色为红色”这一属性的负样本“颜色不为红色”远比正样本“颜色为红色”的样本数量要多. 所以在进行训练时, 模型往往会出现由于正负样本不平衡而造成的训练不充分、准确率不高等问题. 因此, 我们针对正负样本不平衡属性进行了权重优化处理. 由于行人属性在Market-1501-attribute 数据集被转换为30 个二分类问题, 因此属性标签采用二分类交叉熵损失函数进行计算, 公式如下:
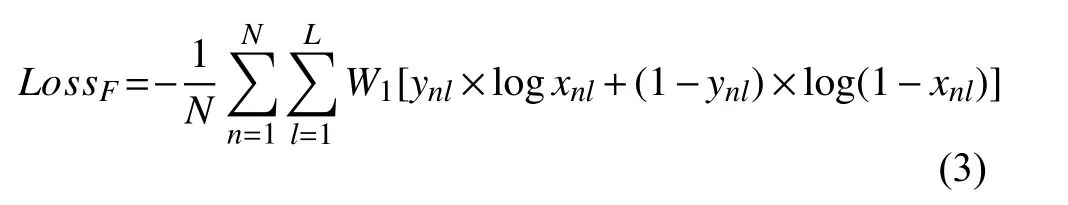

其中,n∈1, 2, …,N,N表示训练集图像个数,l∈1, 2, …,L,L表示属性个数,xnl表示第n张图像第l个属性的预测值,ynl表示真实值,LM表示各属性样本合理比例, 具体如下:
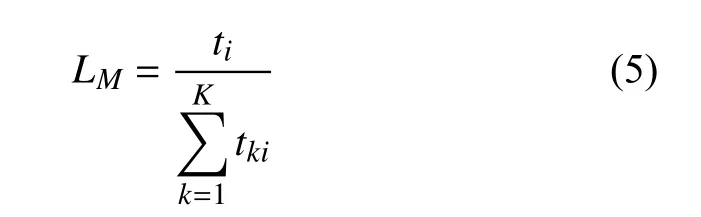
其中,i∈1, 2, …,I,I表示属性种类个数, 例如普遍的二分类以及多分类中的四分类、八分类,k∈1, 2, …,K,K表示各种分类属性中的属性值个数. 本文计算了数据集中各属性正负样本的数量以及每类属性的正样本合理占比. 所谓正样本合理占比, 即该类属性正样本的合理概率值, 例如“性别”属性为二分类属性, 包含“男性”和“女性”, 正样本合理占比为50%, 而“年龄”属性为多分类属性, 包含“儿童”“青少年”“成年人”“老年人”4 种选项, 为了计算方便, 将多分类属性分为4 个二分类属性, 即“是否为儿童”“是否为青少年”“是否为成年人”“是否为老年人”, 因此正样本合理占比为25%. 具体值如下:
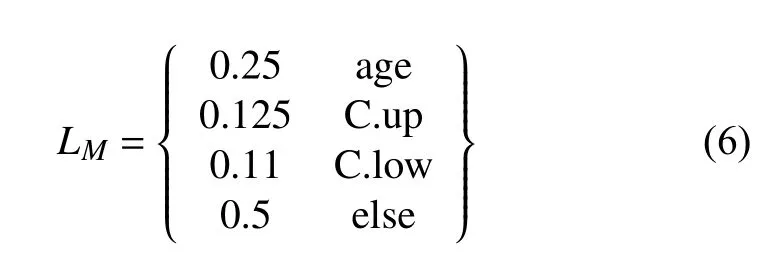
训练过程中, 提高正负样本不平衡且偏离合理占比属性的权重, 力求此类属性可以进行更多的训练, 以此来达到更好的识别效果.
另外, 传统的属性识别可能会由于光线、遮挡、分辨率低等因素造成某些图像的属性识别率较低, 但是对于基于监控的行人属性数据集来说, 行人图像是从不同监控视频的不同序列片段所截取的不同帧, 每一组序列片段, 都有着行人身份信息相同, 行人属性信息相同, 行人图像不相同的特点. 因此, 利用行人身份信息辅助样本平衡优化可以进一步提高行人属性识别能力. 数据集包含多个行人身份信息, 所以身份标签采用多分类交叉熵损失函数. 公式如下:
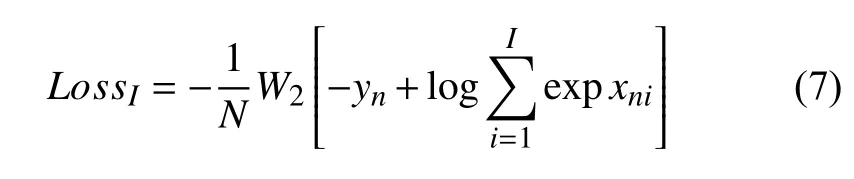
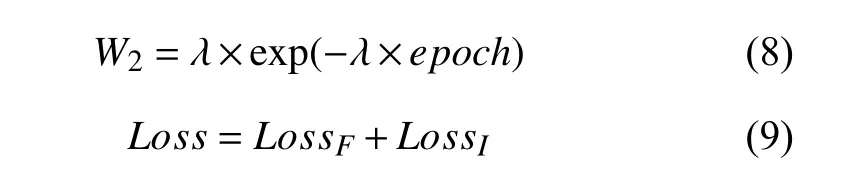
其中,i∈1, 2, …,I,I表示训练集行人身份个数,xni表示第n张图像第i个行人身份的预测值,yn表示第n张图像行人身份的真实值, λ取0.3.
样本平衡损失与身份损失融合作为模块总损失.基于身份信息融合的行人属性样本平衡优化方法, 可以弥补跨任务数据集正负样本不平衡的缺陷, 提升模型的识别能力.
4 实验
本文在大规模跨任务数据集Market-1501-attribute数据集上进行了实验.
4.1 数据集
Market-1501-attribute 数据集的图像来自清华大学, 是在传统的行人重识别Market-1501 数据集[18]的基础上标注行人属性信息所得, 以此用于行人属性识别任务. 该数据集的训练集包含19732 张图像和751个行人身份信息, 测试集包含13328 张图像和750 个行人身份信息. 其中每一张图像, 都注释了27 个属性,包含9 个二分类属性、1 个多分类属性和2 个组合二分类属性, 最终转换为30 个二分类属性.
4.2 实验细节
本文提出的模型使用SGD 优化算法, 批度尺寸为16, 权重衰减系数为5E–4, 特征提取层的基本学习率为0.01, 分类层的基本学习率为0.1, 使用StepLR 学习率调整策略, 学习率衰减为0.1, 每5 个循环衰减一次,总共训练了20 个循环.
该模型在Market-1501-attribute 数据集上进行实验, DeepMAR[9]是基于深度学习的行人属性识别的经典模型, APR[15]是Lin 等人提出的行人重识别任务中的属性识别框架, UF[10], JCM[11]都是使用行人身份信息辅助行人属性识别的跨任务模型. 表1 表示了基于类的评估, 表2 表示了基于实例的评估, 可以发现, 本文提出的模型在最新的Market-1501-attribute 数据集中取得了较好的性能.

表1 Market-1501-attribute 数据集基于类评估实验
Market-1501-attribute 数据集中, “L.slv”“L.low”“S.clth”“B.pack”“H.bag”“C.up”“C.low”分别表示的是length of sleeve, length of lower-body clothing, style of clothing, backpack, handbag, color of upper-body clothing and color of lower-body clothing. 其中, “C.up”和“C.low”为两组单分类属性, “C.up”包含up black , up white , up red , up purple , up yellow , up gray , up blue ,up green 八个单分类属性, 几乎涵盖了日常上衣所有颜色, 合理的属性分布应各为1/8 约12.5%, 但是数据集中分布为up white 占比30%, up purple 占比4%, up yellow 占比6%, up blue 占比6%, up green 占比8%, 均属于正负样本不平衡属性, “C.low”包含down black,down white, down pink, down purple, down yellow,down gray, down blue, down green , down brown 九个单分类属性, 几乎涵盖了日常下衣所有颜色, 合理的属性分布应各为1/9 约11.1%, 但是数据集中分布为down black 占比38%, down pink 占比4%, down purple占比1%, down yellow 占比1%, down green 占比20%,均属于正负样本不平衡属性. 另外, 普通的单分类属性中, 合理的属性分布应各为1/2 约50%, 但是数据集中分布为style of clothing 占比63%, hat 占比2%, 同样属于正负样本不平衡属性. 通过实验发现, 该论文提出的模型在正负样本不平衡的属性中取得了较好的结果.
本文在Market-1501-attribute 数据集上进行了基于实例的评估, 其中,prec表示精确率, 意味着预测为正的样本中有多少是真正的正样本,recall表示召回率, 意味着有多少正样本被正确预测. 理想状态下, 本文力求prec和recall都尽可能获得较高的值, 但事实上这两者在很多情况下是相互矛盾的,prec升高会导致recall降低, 反之亦然. 因此本文考虑使用一个中间数F1=2×prec×recall/(prec+recall)来平衡两个值, 尽可能使prec和recall都获得较优解, 如表2, 可以发现,本文提出的模型在F1 上仍然保持了较好的结果.
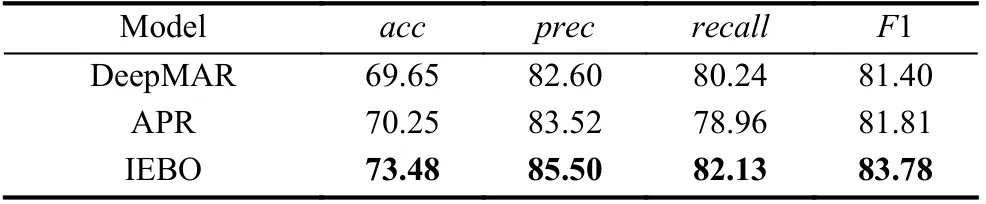
表2 Market-1501-attribute 数据集基于实例评估实验
4.3 消融实验
IEBO 模型包括图像增强模块IE、样本平衡优化模块SBO, 表3 表示了这些模块分别在Market-1501-attribute 数据集上进行的消融实验.
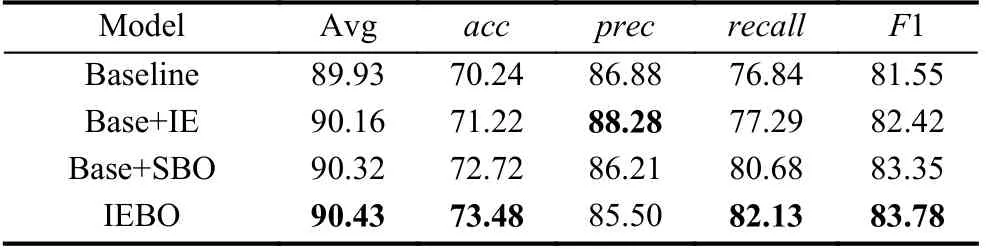
表3 Market-1501-attribute 数据集消融实验
baseline 使用最基本的ResNet50 网络结构作为特征提取方式, SBO 基于身份信息与样本平衡添加了W1与W2 权重参数, 可以发现, 对比baseline, 每一个模块都使模型的准确率有所提升, 综合所有模块, 可以使模型准确率达到最大值.
4.4 参数调优实验
在样本平衡优化中, W2 公式使用λ作为参数进行计算, 我们测试了λ从0.1 到1 时模型的运算结果, 如图6, 可以发现, 当λ取0.3 时, 模型拥有最优解.
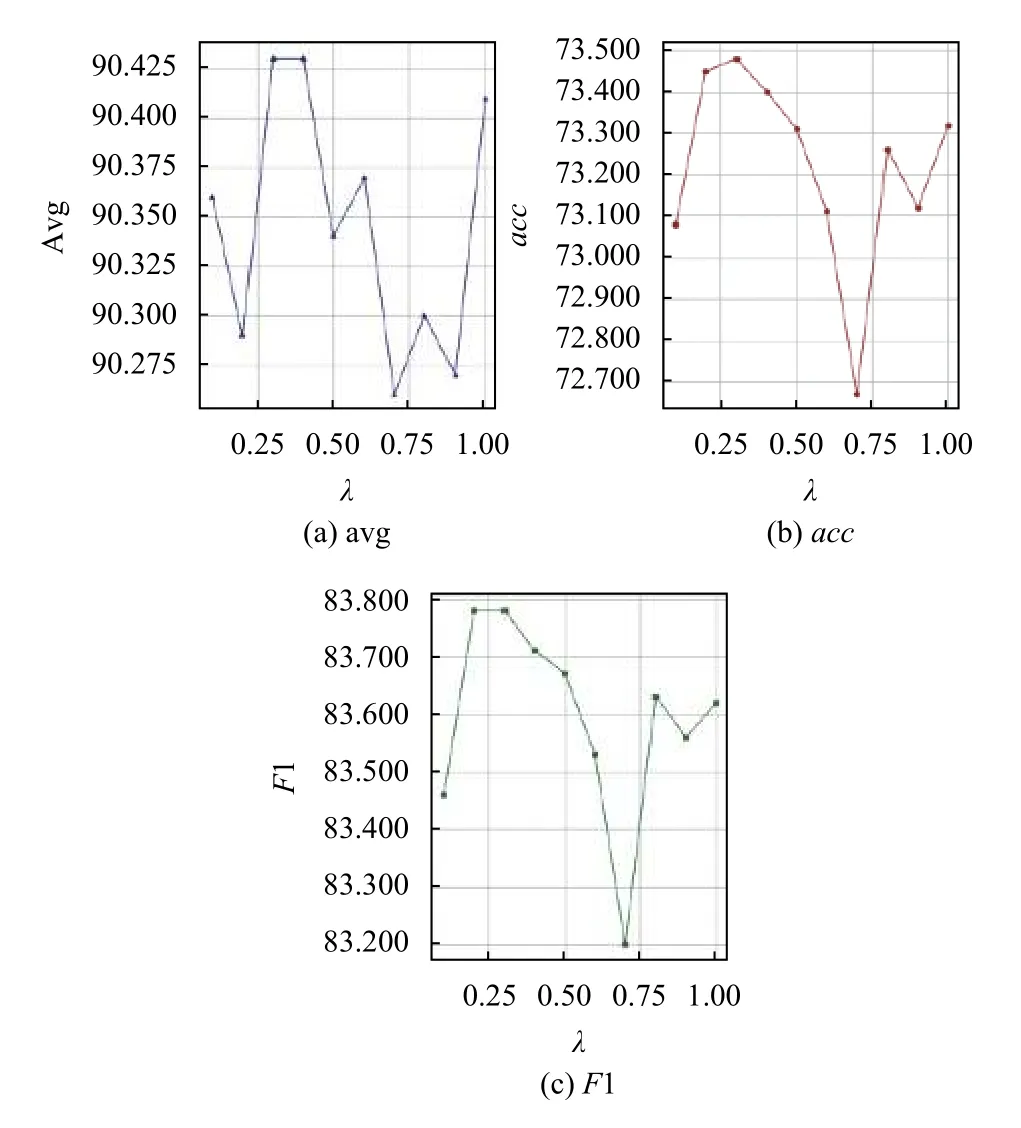
图6 λ 的参数调优实验图
5 结论
本文主要介绍了行人属性识别任务的背景知识,以及新型跨任务数据集的信息, 并且针对新提出的模型讨论了图像增强, 样本平衡等方面的改进. 通过实验比较, 可以发现, 新提出的模型在Market-1501-attribute数据集上取得了较好的性能.
行人属性识别任务一直是计算机视觉中热门的研究方向, 从实践应用角度来讲, 行人属性识别在行人检测[20]、视觉跟踪[21]、行人重识别[14,22–24]等领域等都有着重要的作用, 同时这些任务共同在智能监控系统、智能机器人、广告营销、商业零售等领域也拥有着广泛的应用前景. 但是由于基于监控的图像数据集本身获取方式受到限制, 行人属性识别任务的进一步发展仍然是一个巨大的挑战, 模型性能的提高也有待进一步深入研究.
6Tan ZC, Yang Y, Wan J,et al. Relation-aware pedestrian attribute recognition with graph convolutional networks.Proceedings of the 34th AAAI Conference on Artificial Intelligence. New York: AAAI, 2020. 12055–12062.
7Fabbri M, Calderara S, Cucchiara R. Generative adversarial models for people attribute recognition in surveillance. 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS). Lecce: IEEE, 2017. 1–6.
8Li QZ, Zhao X, He R,et al. Visual-semantic graph reasoning for pedestrian attribute recognition. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1):8634–8641.
9Li DW, Chen XT, Huang KQ. Multi-attribute learning for pedestrian attribute recognition in surveillance scenarios.2015 3rd IAPR Asian Conference on Pattern Recognition(ACPR). Kuala Lumpur: IEEE, 2015. 111–115.
10Sun CX, Jiang N, Zhang L,et al. Unified framework for joint attribute classification and person re-identification.Proceedings of the 27th International Conference on Artificial Neural Networks. Rhodes: Springer, 2018.637–647.
11Zhao X, Sang LF, Ding GG,et al. Recurrent attention model for pedestrian attribute recognition. Proceedings of the 33rd AAAI Conference on Artificial Intelligence. Honolulu:AAAI, 2019. 9275–9282.
12Zeng HT, Ai HZ, Zhuang ZJ,et al. Multi-task learning via co-attentive sharing for pedestrian attribute recognition. 2020 IEEE International Conference on Multimedia and Expo(ICME). London: IEEE, 2020. 1–6.
13Deng YB, Luo P, Loy CC,et al. Pedestrian attribute recognition at far distance. Proceedings of the 22nd ACM International Conference on Multimedia. Lisboa: ACM,2014. 789–792.
14Lin YT, Zheng L, Zheng ZD,et al. Improving person reidentification by attribute and identity learning. Pattern Recognition, 2019, 95: 151–161. [doi: 10.1016/j.patcog.2019.06.006]
15Zheng L, Shen LY, Tian L,et al. Scalable person reidentification: A benchmark. 2015 IEEE International Conference on Computer Vision (ICCV). Santiago: IEEE,2015. 1116–1124.
16Liu H, Wu J, Jiang J,et al. Sequence-based person attribute recognition with joint ctc-attention model. arXiv:1811.08115, 2018.
17Yang J, Fan JR, Wang YR,et al. Hierarchical feature embedding for attribute recognition. Proceedings of the 2020
猜你喜欢
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
时代英语·高二(2017年4期)2017-08-11
学生天地·小学中高年级(2017年5期)2017-06-09
小天使·一年级语数英综合(2017年6期)2017-06-07
红领巾·成长(2016年10期)2017-05-10
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
中学生数理化·七年级数学人教版(2014年6期)2014-09-18
