
用于失配隐写分析的对抗子领域自适应网络
2022-06-24 02:34:36章蕾王宏霞
网络与信息安全学报 2022年3期
章蕾,王宏霞
(四川大学网络空间安全学院,四川 成都 610065)
0 引言
图像隐写是一种利用数字图像的视觉冗余来嵌入秘密信息的隐蔽通信手段,隐写的安全性是进行隐蔽通信的双方需要考虑的问题,即不能被第三方发现隐写行为的存在。最近几年兴起的基于最小化失真的隐写技术通过设计嵌入失真函数,以此衡量图像每个元素的修改对隐写安全性的影响,并通过最小化总嵌入失真实现隐写的高安全性。这种根据图像的内容自适应地将秘密信息嵌入图像纹理丰富或边缘区域的隐写算法又被称为自适应隐写算法,具有代表性的自适应隐写算法有S-UNIWARD[1]、WOW[2]和HUGO[3]。
图像隐写分析的目的是检测隐写信号,以区分载体图像与载密图像。传统的隐写分析方法根据统计矩、图像校准、邻域相关性等来构造隐写分析特征进而进行分类。然而,随着自适应隐写算法的出现,秘密信息被嵌入难以建模的纹理复杂区域,给隐写分析带来了很大的挑战。为了提高隐写分析的准确率,设计算法时需要考虑越来越复杂的图像统计特性,甚至所设计的隐写分析特征需要达到几万维[4-6]。卷积神经网络在图像隐写分析中表现出色,基于深度学习的隐写分析技术得到广泛关注[7-12]。这些基于深度学习的隐写分析器往往能够达到比传统的基于手工设计特征的隐写分析方法更高的检测准确率。
然而,基于深度学习的方法十分依赖训练集的数据和标签,如果训练集的图像内容不够丰富、数量不够大则模型很容易过拟合,且在模型训练时需要将载体图像和对应的载密图像成对地送入模型中,这为训练集的收集增加了难度。为了提升模型的泛化性能,研究者在训练模型的时候往往会通过随机裁剪、旋转等操作进行数据增强[7-10]来扩充数据集。以往的深度学习隐写分析研究假设训练数据和测试数据服从相同的概率分布。然而测试集的图像与训练集的图像差距较大时,模型在测试集上的表现往往不如在训练集上的表现。训练集和测试集存在差异的因素有很多,如图像来自不同的数据集,经过不同的图像处理过程,不同的隐写算法以及不同的嵌入率等。以上所述就是隐写分析中的载体源失配(CSM,cover source mismatch)问题。现实的应用场景中有各种各样的载体源失配问题,因为测试集的图像与训练集的图像总会有差别,研究者很难获取数据集、隐写算法、嵌入率等重要信息。这也是基于深度学习的隐写分析模型很难在实际应用场景中部署的原因。为了提升隐写分析模型在载体源失配情况下的检测准确率,本文提出了一种对抗子领域自适应网络(ASAN,adversarial subdomain adaptation network)以减小训练集和测试集之间的差异。
1 相关工作
近年来,已经有一些工作研究如何减轻载体源失配现象对隐写分析器的负面影响,总体上分为两类。一类是子空间迁移学习方法,这类方法试图寻找一个投影将特征投影到一个公共子空间来减小两个领域之间的分布差异。Jia等[13]试图找到一个投影矩阵将源领域和目标领域数据投影到一个公共的特征子空间,在重构矩阵上联合低秩约束和稀疏表示来保留局部和全局数据结构。Xue等[14]提出了一种基于子空间学习的无监督隐写分析方法,该方法通过对重构系数矩阵的低秩和稀疏约束来保持数据的全局和局部结构以获得新的特征表示,使训练数据和测试数据的特征分布接近。针对JPEG重压缩,Yang等[15]构造多分类器来检测测试图像的重压缩马尔可夫特性,然后将隐写分析特征转移到一个新的特征子空间。Feng等[16]提出了一种基于贡献的特征迁移算法,试图通过评估样本特征和维度特征的贡献来学习两种变换以迁移训练集特征。另一类方法是通过构造领域自适应分类器,直接将领域自适应准则作为正则化项整合到损失函数中。Yang等[17]改进了ARTL(adaptation regularization transfer learning)[18]算法,在图拉普拉斯正则化中加入了条件分布,将联合分布自适应和几何结构作为正则化项整合到一个标准监督分类器中,以构建领域自适应分类器。在空域中,针对数据集载体源失配问题,Zhang等[19]同时考虑了输入图像和预测标签的联合分布。当一个在纹理复杂度低的数据集上训练的模型检测纹理复杂度高的测试集时,隐写分析器的准确率会大幅下降,Zhang等[19]提出的J-Net可以在一定限度上有效地缓解这种下降。
除上述两类方法,Hu等[20]提出了一种解决CSM问题的新思路,通过度量图像的纹理复杂度,然后在一幅图像中寻找最接近有效范围的块来代替整幅图像进而提高隐写分析器的准确率。Zhang等[21]通过研究特征距离与特征运动模式的相似度,为每个测试样本选择了专用的训练集训练分类器来解决CSM。对于嵌入率失配,一个通用的思路[12,22-23]是先在高嵌入率下训练模型,然后通过渐近地用低嵌入率的数据对模型进行微调,最后得到一个可以检测低嵌入率隐写信号的模型。现在的隐写分析器很多是基于深度学习的,然而以往很多研究[13-17,20-21]针对的隐写分析特征是基于手工设计的,如PEV[24]、Rich Model[4]、DCTR[25]、CC-PEV[26]等,很少对深度隐写分析网络的载体源失配问题进行研究。因此,本文以基于深度学习的隐写分析模型为研究对象,探究缓解载体源失配问题的方法。
隐写分析中的CSM问题与迁移学习中的领域自适应问题相似。领域自适应关注于解决特征空间和类别空间一致仅特征分布不一致的问题[27],CSM问题也是如此。一些领域自适应方法会设计并最小化一个度量准则来减小域间差异。最大均值差异(MMD,maximum mean discrepancy)[28]是领域自适应中应用最为广泛的度量,它将两个变量映射到再生核希尔伯特空间(RKHS,reproducing Kernel Hilbert space),然后测量两种分布在RKHS中的距离。在MMD的基础上,研究者提出了许多领域自适应方法。单核方法,如深度领域混淆[29];多核方法,如深度自适应网络[30]、联合自适应网络[31]、深度子领域自适应网络[32]等。Zhu等[32]提出的非对抗的深度子领域自适应网络通过最小化局部最大均值差异(LMMD, local maximum mean discrepancy)以对齐相关子领域的分布。而另一些领域自适应方法则采用对抗的方式学习一种既能用来进行分类又不能使判别器区分是哪个领域的表示。领域对抗神经网络(DANN,domain-adversarial neural network)[33]最先在领域自适应中加入了对抗机制,通过与领域判别器进行对抗,得到域间通用的特征。动态对抗自适应网络(DAAN,dynamic adversarial adaption network)[34]分别为边缘分布和条件分布设计判别器,并动态和定量地评估了这两种分布对对抗学习的相对重要性。
这两类领域自适应方法是从两个不同的角度进行考虑的,仅使用对抗学习的领域自适应方法不足以将域间特征分布的距离最小化,而仅使用最小化度量的方法又缺失了对域无关特征的学习。因此,针对这些局限性,本文提出了用于失配隐写分析的对抗子领域自适应网络。一方面,从减小域间差异的角度出发,对齐相关子领域的特征分布,扩大类间距离,缩小类内距离;另一方面,通过构造一个领域判别器与隐写分析模型进行对抗学习,使模型在两个领域上生成的特征更为相近。
2 对抗子领域自适应网络
2.1 符号表示
2.2 网络结构
本文提出的对抗子领域自适应网络结构如图1所示。蓝色的数据流代表源领域图像,黄色的数据流代表目标领域图像。同时包含源领域图像和目标领域图像的批数据作为模型输入,预训练隐写分析模型共有L层。图像经过模型的第l(l∈L)层后提取到的特征fl会同时进入分类分支(绿色部分)和判别分支(橙色部分)。在分类分支中,分类器给出对一批源领域图像的预测值,通过计算与真实标签Ys之间的交叉熵损失得到分类损失。分类器给出对一批目标领域数据的预测值,与源领域特征fsl、目标领域特征ftl、真实标签Ys一起用于计算局部最大均值差异损失。在判别分支中,特征会首先经过一个梯度反转层(GRL,gradient reversal layer)[33]以简化对抗训练过程。紧接着,领域判别器会对特征的领域标签进行预测,将预测值与真实领域标签值Yd计算交叉熵损失作为对抗损失。通过同时最小化这3项损失进行对抗训练,特征提取器提取的特征会更加相似,特征的分布差异也会更小,从而缓解了载体源失配问题对隐写分析器的负面影响。

图1 对抗子领域自适应网络结构Figure 1 Structure of adversarial subdomain adaptation network
2.3 对抗学习
本文提出的对抗子领域自适应网络主要由特征提取器Gf、子领域自适应分类器Gy和领域判别器Gd组成,主要是为了提高预训练隐写分析模型在失配情况下的检测准确率。将现有隐写分析模型去掉分类层即可作为特征提取器Gf,Gf对输入的图像进行特征提取,提取到的特征是由子领域自适应分类器Gy和领域判别器Gd共享的。Gf学习的目标是:提取后的特征尽可能使分类器对样本进行正确分类,同时使判别器无法区分样本是来自源领域还是目标领域。子领域自适应分类器Gy的网络结构与原隐写分析模型的分类层相同,根据源领域特征fsl和目标领域特征ftl分别给出分类结果。在分类的同时进行子领域自适应,通过最小化LMMD损失来减小域间相关子领域特征分布的差异。领域判别器Gd根据输入的特征给出预测领域的标签,即判断该特征来自哪一个领域。而Gf作为与Gd对抗的另一方,则希望其生成的特征足够相似以欺骗领域判别器Gd,这就使Gf寻找源领域和目标领域共有的特征。Gy和Gd的双重约束,可使Gf生成的特征尽可能相似,同时特征分布的差异尽可能地小。
本文的领域分类网络是由梯度反转层和领域判别器组成的。采用梯度反转层可以简化对抗训练过程。梯度反转层实现的原理是:在前向传播过程中保持输入特征fl不变,在反向传播过程中将梯度乘以一个负的定值μ,实现梯度自动取反以达到对抗训练的目的。采用两个伪函数来分别表示梯度反转层在正向传播和反向传播中的作用。
前向传播:

反向传播:

其中,I是一个单位矩阵。
2.4 子领域自适应
主流的领域自适应方法主要学习全局领域偏移,即对齐全局源和目标分布,这种全局对齐的方法会使分类器忽略很多细节,如同一个领域内属于不同类数据之间的关系,不同领域间属于相同类数据之间的关系,导致分类器并不能够很好地描述两个不同类之间的界限。本文根据标签类别将源领域和目标领域分别划分为两个子领域。源领域使用真实标签进行划分,而目标领域数据使用网络预测的概率分布。本文通过计算局部最大均值差异[32]来衡量属于同一类的两个子领域之间的特征分布差异。LMMD的计算如下。
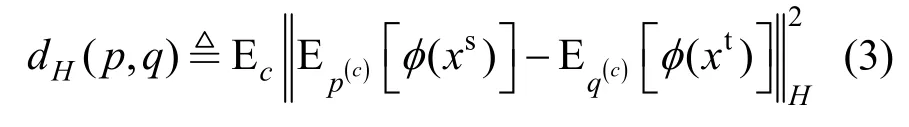
其中,H是被赋予特征核k的再生核希尔伯特空间,E[⋅]为数学期望。p(c)和q(c)分别是源领域和目标领域中属于类别c的子领域特征分布。φ(xs)和φ(xt)分别表示将源领域和目标领域中的样本映射到再生核希尔伯特空间的特征映射,核是映射φ(xs)和φ(xt)的内积。通过最小化局部最大均值差异,同一类别的相关子领域的特征分布更相近。具体地,LMMD损失的计算方式为
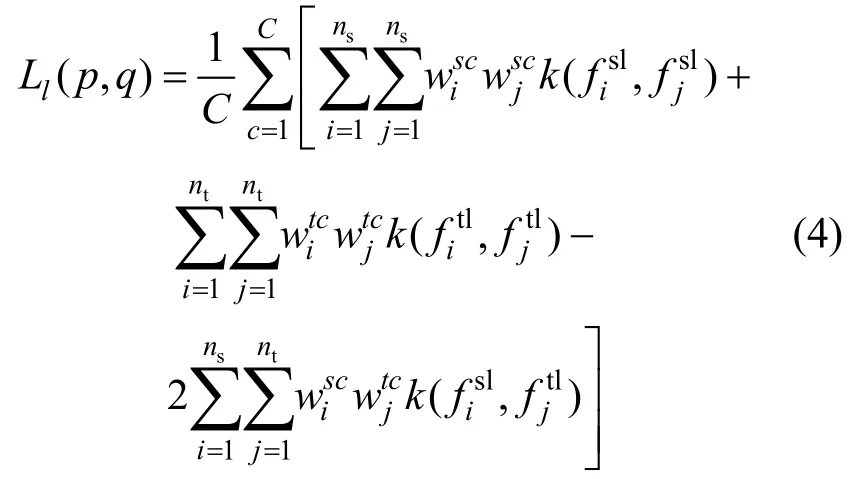
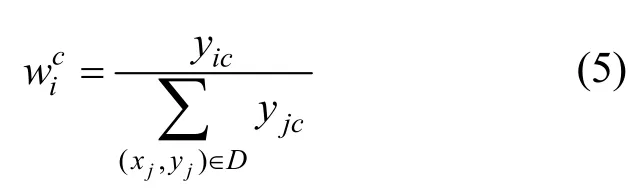
其中,yic是标签向量yi的第c个值。
2.5 损失函数
在本文的训练过程中一共有3个目标:一是实现源领域图像分类误差的最小化;二是减小相关子领域特征分布之间的差异;三是使领域分类误差的最大化,寻找域无关特征。因此可以将总的损失函数写为

其中,λ和ω是权衡参数,Ly,Ll,Ld则分别代表分类损失、LMMD损失和对抗损失。θf,θy,θd分别代表Gf、Gy和Gd的参数。代表源领域图像的标签,di则代表图像的领域标签(源领域的图像di=0,目标领域的图像di=1)。训练收敛后,参数将得到式(6)的一个鞍点。
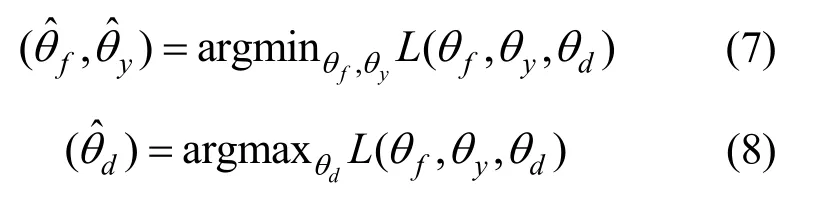
通过采用GRL简化对抗训练过程,损失函数可以改写为
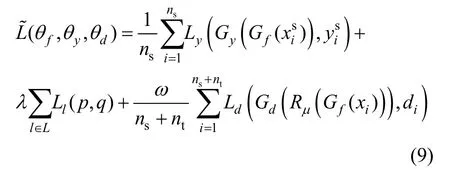
3 实验结果及分析
3.1 实验设置
本实验首先使用3种隐写算法S-UNIWARD、WOW、HUGO在BOSSbase 1.01数据集[35]训练SRNet模型[9];然后将训练好的SRNet模型作为本文载体源失配的研究对象。因为SRNet是一个端到端的深度学习网络,没有引入过多的手工设计成分,并且其检测效果在空域中达到前沿水平,所以选择该模型。本文探究了数据集失配和隐写算法失配这两种载体源失配问题。将本文方法与SRM[4]、SRNet[9]、J-Net[19]进行比较。J-Net也用于解决基于深度学习的隐写分析模型面临的载体源失配问题,其使用联合最大均值差异(JMMD,joint maximum mean discrepancy)[31]来最小化数据集之间的差异。本实验的评价指标为平均总精度PA,,文献[17]也采用了平均总精度作为评价指标。其中pc是载体图像的分类准确率,ps是载密图像的分类准确率。在失配实验中,在训练集随机选取500对图像(一幅载体图像和对应的载密图像为一对)作为源领域数据,在测试集上随机选取500对图像作为目标领域图像来完成迁移任务。与需要大量标签数据进行有监督训练的隐写分析方法不同,本文将待测图像加以利用,对预训练隐写分析模型进行领域自适应。其他失配隐写分析的工作[13-14,17,20]也使用了500对图像参与训练。
本文的整体隐写分析过程包括3个阶段,分别是预训练阶段、领域自适应阶段和测试阶段。在预训练阶段,隐写分析模型在源领域所属数据集上进行有监督的训练。预训练完成后,将预训练隐写分析模型去掉分类层作为本文的特征提取器Gf。通过构造领域判别器来实现对抗子领域自适应,减小特征分布的差异。在本文实验中,领域判别器Gd由3个网络层组成以对特征的领域标签进行预测。SRNet的特征维数为512,隐藏层维数设置为512,Gd的网络结构如表1所示,其中Linear表示线性层,BNld表示一维批标准化层,ReLU和Sigmoid为激活函数。子领域自适应分类器Gy的网络结构与原隐写分析模型的分类层相同。在测试阶段,将目标领域图像送入自适应后的网络中,标签预测器从而给出图像的预测结果。

表1 领域判别器Gd的网络结构Table 1 Network structure of the domain discriminator Gd
在预训练阶段,本文采用256×256大小的BOSSbase 1.01图像进行训练。本文使用PIL库中的resize函数对原512×512大小的图像进行下采样调整其大小为256×256;接着采用S-UNIWARD、WOW、HUGO 3种隐写算法对原始载体图像嵌入秘密信息生成载密图像。数据集的划分为:5 000对训练集,1 000对验证集和4 000对测试集。在预训练过程中没有使用数据增强。本文0.2 bit/pixel的SRNet模型是通过对0.4 bit/pixel的SRNet模型进行100个epoch的再训练得到的。对于SRM,使用BOSSbase1.01数据集前5 000对图像的特征训练分类器。在进行失配实验时,提取目标领域500对图像的空域富模型(SRM,spatial rich model)特征,利用训练好的分类器对其进行分类。
模型的预训练以及自适应过程均是在Pytorch框架下进行的。对于所有任务,本文使用动量为0.9的小批量随机梯度下降(SGD,stochastic gradient descent)和文献[32]中的学习速率衰减策略。学习率初始化为0.01,并按照ηε=η0/(1+ε)β更新,ε是训练过程中取值范围为0到1的线性变化,η0=0.01,α=10,β=0.75。通过这种策略,在经过200个epoch后,学习率会降为0.001 7。本文没有固定权衡因子λ,而是通过一个渐进的过程逐步将它从0改变到1,即λε=2/exp(−10ε)−1,这样做是为了抑制在训练初期模型不稳定的输出。对抗损失权衡参数ω(ω=10)在整个实验中是固定的。训练批大小设为16。
3.2 数据集失配实验
数据集失配实验从BOSSbase 1.01数据集中随机选取500幅并嵌入秘密信息得到500对大小为256×256的图像作为源领域数据,分别从数据集UCID[36]、DIV 2K[37]、Flickr25k[38]上随机选取500对图像作为目标领域数据。
表2和表3分别给出了嵌入率为0.4 bit/pixel和0.2 bit/pixel时数据集失配的实验结果。当在BOSSbase1.01数据集上训练的模型检测来自UCID.v2、DIV2K和Flickr 25K的数据时,即数据集失配时,基于手工特征的传统隐写分析方法SRM受数据集失配的影响比SRNet更大,其检测准确率下降更多。SRM的特征提取过程不是特定于训练集数据的,但分类器的训练却是特定于训练集的。载体源之间的失配也会导致这种传统隐写分析方法的检测准确率下降。对于SRNet,大部分情况下模型的准确率会下降,准确率上升的特例来自Flickr 25K数据集,这可能是对其进行的图像处理使其纹理复杂度较低导致的。
从表2和表3的实验结果可以看出,无论是在纹理复杂度高还是低的数据集上,本文提出的ASAN方法都可以有效地减轻数据集失配对基于深度学习的隐写分析器的影响。在嵌入率为0.4 bit/pixel的情况下,本文方法将隐写分析器的准确率提高3.8%~11.5%,平均提高8.3%;嵌入率为0.2 bit/pixel时,本文方法将隐写分析器的准确率提高10.1%~17.2%,平均提高12.8%。嵌入率为0.2 bit/pixel时的提升效果优于0.4 bit/pixel,两种嵌入率下的检测准确率均高于SRM、SRNet、J-Net。
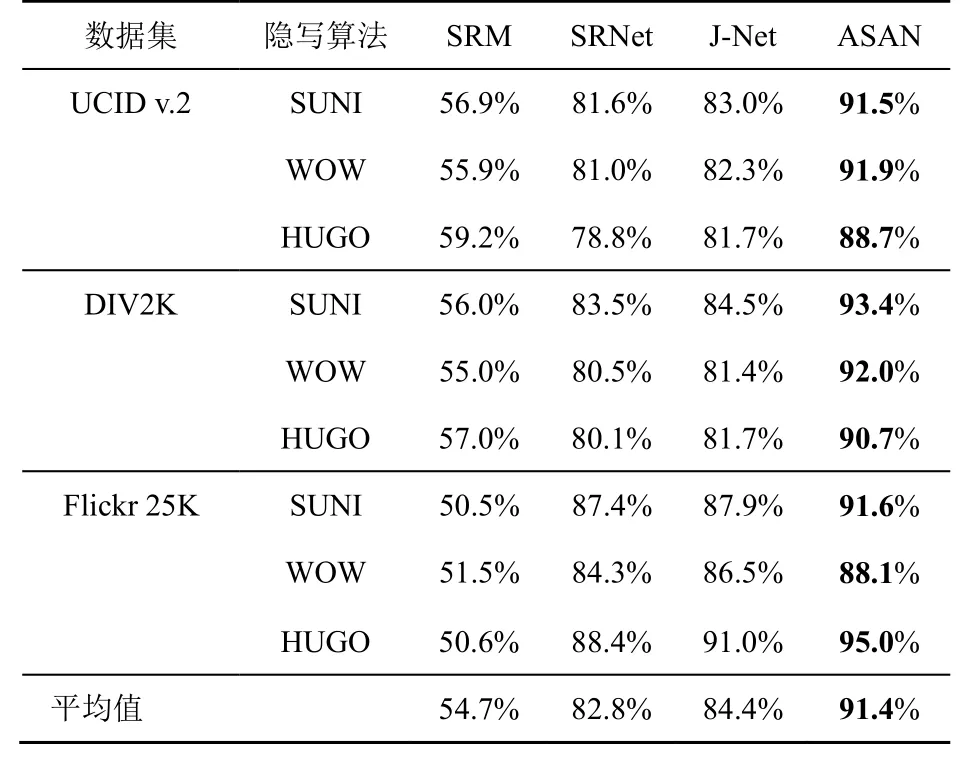
表2 数据集失配时准确率对比(嵌入率为0.4 bit/pixel)Table 2 Detection accuracy comparison in dataset mismatch(0.4 bit/pixel)
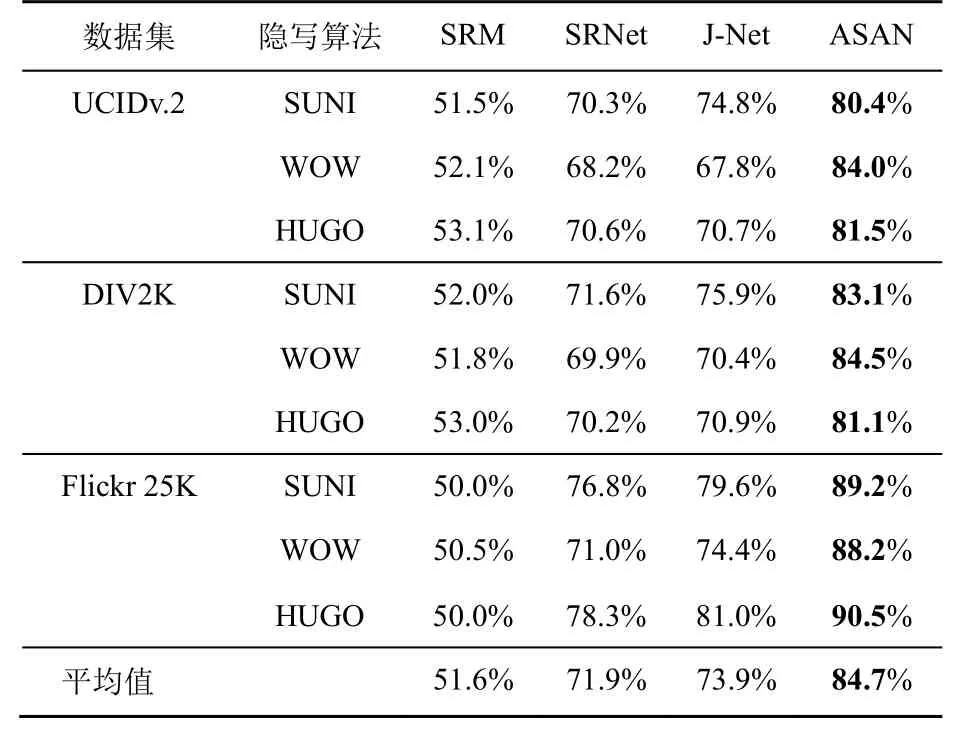
表3 数据集失配时准确率对比(嵌入率为0.2 bit/pixel)Table 3 Detection accuracy comparison in dataset mismatch(0.2 bit/pixel)
3.3 隐写算法失配实验
隐写算法失配实验将已知隐写算法(用来训练SRM和SRNet模型的算法)进行嵌入得到的500个图像对作为源领域数据,将其他隐写算法进行嵌入得到的500个图像对作为目标领域数据。实验数据集为BOSSbase1.01。在隐写算法失配时,SRM仍受失配影响,其检测准确率下降,但下降幅度低于数据集失配。可见相比隐写算法失配,SRM可能对数据集之间的不一致更为敏感。而对于SRNet,大部分隐写算法失配情况下模型的准确率会下降,准确率上升的特例出现在测试算法为S-UNIWARD时。
表4和表5分别给出了嵌入率为0.4 bit/pixel和0.2 bit/pixel时隐写算法失配的实验结果。从实验结果可以看出本文提出的ASAN方法可以有效地减轻隐写算法失配对基于深度学习的隐写分析器的影响。嵌入率为0.4 bit/pixel时,本文方法将隐写分析器的准确率提高4.7%~10.2%,平均提高7.2%;嵌入率为0.2 bit/pixel时,本文方法将隐写分析器的准确率提高2.5%~11.2%,平均提高6.8%,检测准确率均高于SRM、SRNet、J-Net。

表4 隐写算法失配时准确率对比(嵌入率为0.4 bit/pixel)Table 4 Detection accuracy comparison in steganographic algorithm mismatch (0.4 bit/pixel)
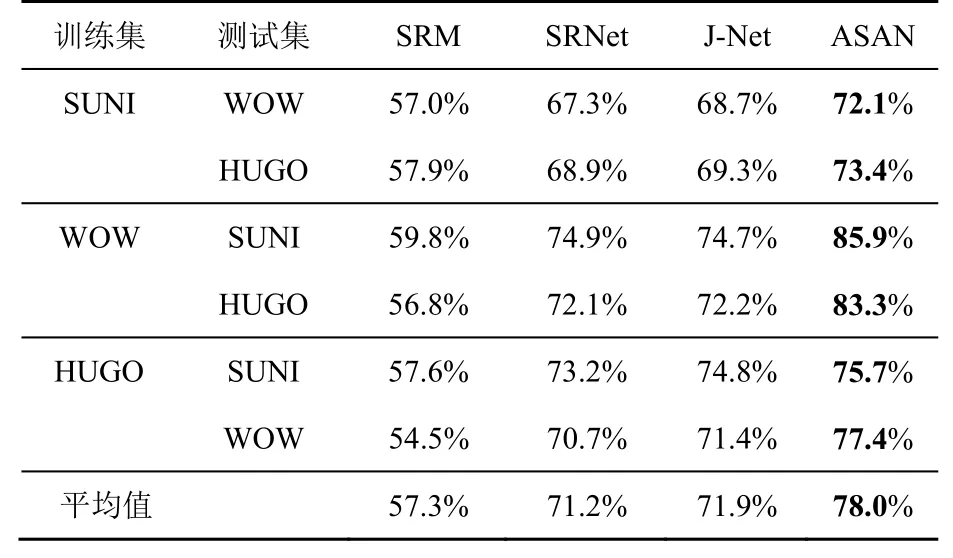
表5 隐写算法失配时准确率对比(嵌入率为0.2 bit/pixel)Table 5 Detection accuracy comparison in steganographic algorithm mismatch (0.2 bit/pixel)
3.4 t-SNE可视化
为了进一步评估ASAN的性能,本文使用t-SNE降维技术[39]对数据集失配时网络学习到的特征分布进行可视化,如图2所示。来自源领域的样本用黄色数值表示,来自目标领域的样本用蓝色数值表示,两个领域各1 000个样本点。数值0代表载体图像,数值1代表载密图像。同时为了更直观地表示,本文将载体图像用更浅的黄色或蓝色表示。该部分实验将数据集从BOSSbase1.01迁移至UCIDv.2,检测S-UNIWARD算法的实验结果,嵌入率为0.4 bit/pixel。
图2(a)为进行领域自适应之前SRNet提取的特征分布图,可以观察到,在源领域(黄色)上,载体图像特征(浅黄色的0)和载密图像特征(深黄色的1)之间存在聚类现象,很少有样本混淆到另一个类别的特征分布中,此时模型的检测准确率较高。然而,在目标领域(蓝色)上,由于载体源失配问题的发生,特征的分布发生变化,模型检测准确率降低。图2(b)和图2(c)分别为采用J-Net[19]和本文方法ASAN进行领域自适应之后的特征分布图。可以看到本文提出的方法可以更好地将源领域和目标领域进行对齐,扩大类间距离,减小类内距离,从而提升模型的准确率。结合t-SNE特征分布图进行分析,载体源失配会导致预训练隐写分析模型提取的特征分布发生变化,从而使检测准确率下降。通过充分利用待测图像的信息,J-Net和ASAN可以将源领域数据和目标领域数据的特征分布进行对齐以提升检测准确率。而J-Net全局地将特征分布进行了对齐,虽然对齐之后全局分布大体相似但具体到两个类别中,分类器不能充分描述分类边界。ASAN方法通过结合子领域自适应和对抗学习两种策略,局部地对齐属于同一类别的相关子领域,同时使源领域和目标领域的特征更加相似,特征分布更紧密,达到了更好的分类效果。

图2 t-SNE对比Figure2 Comparison result of t-SNE
3.5 消融实验
消融实验探究了子领域自适应和对抗学习对最终分类效果的不同影响。选取的载体源失配场景为数据集失配,实验设置与3.2节一样,表6与表7分别为嵌入率为0.4 bit/pixel和0.2 bit/pixel时的消融实验结果。表中ADV列表示只采用对抗学习,DSAN列表示只采用子领域自适应,而ASAN列则表示同时采用这两种策略进行领域自适应的结果。由表6和表7中实验结果可以看出子领域自适应和对抗学习两种方法都可以提升模型的准确率,二者效果接近,而将二者结合起来可以更好地进行领域自适应,从而提升模型的准确率。
为了更直观地观察这种差异,本实验采用UCIDv.2数据集,检测S-UNIWARD算法时的准确率曲线如图3所示。其中图3(a)是嵌入率为0.4 bit/pixel时的准确率曲线,图3(b)是嵌入率为0.2 bit/pixel时的准确率曲线。可以观察到,在训练过程中ASAN的提升高于其他两种方法,这种优势在嵌入率为0.4 bit/pixel时更为明显。
4 结束语
为了减轻载体源失配问题对基于深度学习的隐写分析模型的负面影响,本文提出了对抗子领域自适应网络ASAN,从学习域无关特征和减小子领域特征分布差异这两个角度,将子领域自适应和对抗学习这两种领域自适应方法结合,提高了隐写分析模型在载体源失配情况下的准确率。通过在多个公开数据集以及多种嵌入率上进行了大量的实验,结果证明本文所提出的方法可以在数据集失配以及隐写算法失配时都提供较好的检测性能。在未来的工作中,将继续研究JPEG域的失配隐写分析问题,进一步提升基于深度学习的隐写分析方法的实际应用价值。
猜你喜欢
电机与控制应用(2022年4期)2022-06-27 06:29:22
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
雷达学报(2018年3期)2018-07-18 02:41:26
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
电源技术(2015年5期)2015-08-22 11:18:12
