
网络舆情话题漂移路径研究*
2022-06-23 14:01朱恒民杨欣谊
情报杂志 2022年6期
朱恒民 钱 莉 杨欣谊 魏 静
(1.南京邮电大学管理学院 南京 210003;2.江苏高校哲学社会科学重点研究基地—信息产业融合创新与应急管理研究中心 南京 210003;3.南京大学信息管理学院 南京 210023)
0 引 言
随着时间的推进、网民的持续关注和热烈讨论,网络舆情的态势也是在不断地变化着。与传统媒体的“就事论事”不同,网络传播者泛化以及网络本身具有的虚拟性、匿名性、发散性、渗透性和随意性等特点,使得网络舆情在发展过程中可能朝任何一个方向发展,路径不确定并经常进行转换,这导致原有的舆情可以衍生出多个与之相关的话题,本文称此过程为话题漂移[1]。由于漂移话题与原有舆情话题在内容上产生了较大的偏移,如何有效地探测和跟踪舆情发展过程中的漂移话题,是舆情演化分析的关键问题。
不同于话题演化中通过计算话题内容的相似性来描述话题的演化路径,话题漂移后的新话题与原话题的内容相似度较低,因此话题漂移路径的追踪更具有挑战性。本文以“新冠肺炎”疫情为例,基于LDA(Latent Dirichlet Allocation)模型抽取出疫情发展中的话题,并观察特征词在话题漂移过程中的微观特征,进而提出一种话题漂移路径追踪分析方法,以期细粒度地揭示舆情事件发展中话题之间的漂移过程。
1 文献综述
话题漂移区别于话题演化,但话题漂移研究起源于话题演化研究。为了描述话题的演化路径,一些学者提出了解决方法。Gao等提出了一种新的在线加权条件随机场正则化相关话题模型(OCCTM),该模型利用语义相关性捕捉来自短文本的主要话题和相关子话题的演化路径[2]。通过度量相邻时间段间的主题相似性,陈翔等人揭示了主题间的演化关系,并进一步识别出主题的演化路径[3]。吴菲菲等人将文本挖掘中的主题模型与专利引文相结合,提出了一种利用语义相似度构建的有向有权网络来识别技术多主题演化路径的方法[4]。范少萍等人设计了基于统计与语义相结合的关键关联计算方法,进而识别出主题在时间片上的演化路径[5]。显然,识别话题演化路径研究的常见方法是通过度量相邻时间片中的话题相似性。
关于话题漂移的研究,陈伟等在LDA与隐马尔可夫链(HMM)相结合的基础上,对船用柴油机技术领域的主题演化趋势进行了定量预测,分析了不同时期主题的转移概率及演化规律,描绘了主题演化路径并对该方法的准确性和有效性进行了验证[6]。关鹏等结合专家经验进行语义演化分析,以判断相邻阶段哪些主题是新生的,哪些主题间产生了融合、分裂以及继承等演化模式,并由此绘制主题演化图谱[7]。不同于科技文献,网络文本中的词汇语义更为丰富复杂,这给网络文本话题漂移研究中带来了挑战,一些学者提出了一些思路。黄微等提出并构建了网络舆情衍进指数,用以描述网络舆情演化过程中衍生出新话题的现象[8]。Li等人针对短文本语义稀疏问题,通过引入维基知识库对模型语义进行扩展,结果表明改进过的主题漂移检测方法能够更有效跟踪短文本流中的主题漂移[9]。
特征词在话题演化中的重要作用引起了学者的关注。例如,李慧等人将特征词热度加入到微博热点话题模型演化模型中,可以发现微博热点事件子话题的演化规律[10]。黄微等人结合词权重分析话题漂移情况,提出网络热点事件话题漂移指数构建过程,并绘制话题漂移指数变动曲线用以体现网络热点事件发生话题漂移的时间节点[11]。Yang等人指出特征词呈现出长度短、信号弱、速度快等特点,并在此基础上提出了一种同时监测作者写作风格的动态性和学习作者的兴趣的主题漂移模型(TDM)[12]。
综上所述,区别于话题演化中通过话题内容相似性来构建话题的演化路径,话题漂移所产生的新话题往往呈现出与原话题内容不同的特点,因此话题演化路径的分析方法并不适用于话题漂移研究。其次,特征词在话题漂移中的作用引起了学者的关注,如何基于特征词的微观视角描绘话题漂移过程尚需要进一步探索。
2 话题漂移过程中的词特征分析
话题由一系列特征词构成,话题在漂移过程中首先表现为特征词的变化。话题漂移过程中特征词的变化特征是什么?能否从词的视角来揭示话题漂移的微观过程?针对上述问题,本文选取2020年初爆发的新型冠状病毒疫情事件,以前期1月份的微博数据为研究对象,对疫情事件中话题的漂移过程进行分析。
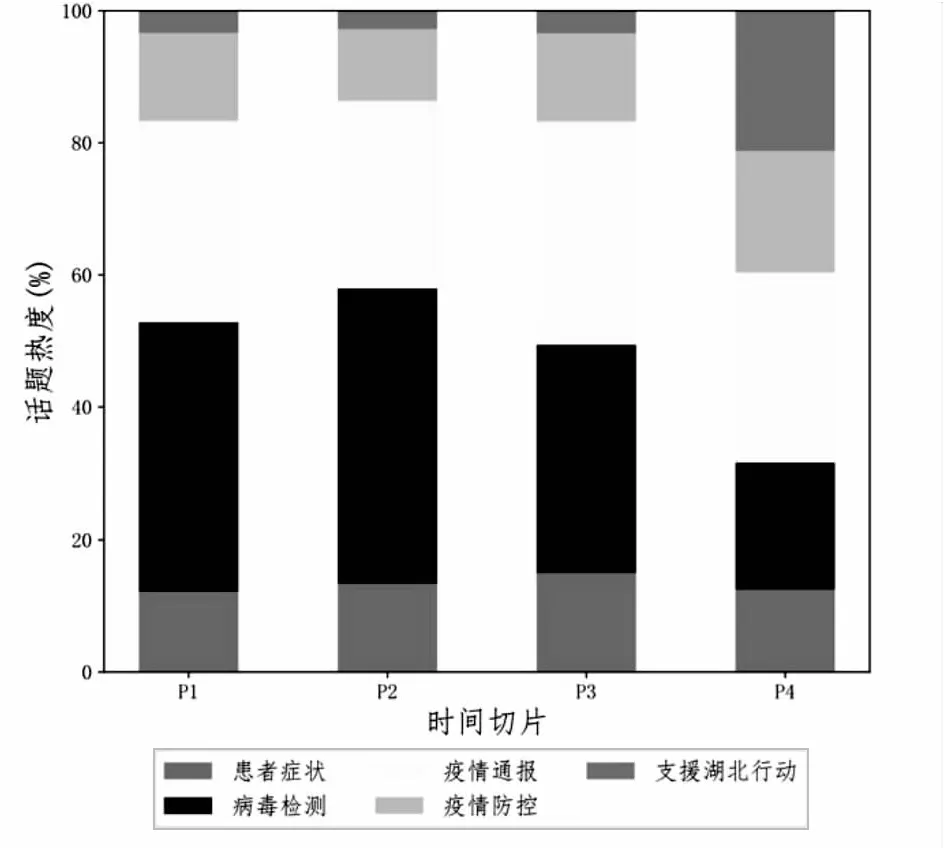
图1 2020年1月“新冠”疫情话题热度占比
以2020年1月份每一周为一个时间切片,基于LDA模型抽取出每个时间切片内发布微博所覆盖的话题,统计出隶属具体话题的微博数量所占的比例,作为该话题的热度,如图1所示。从中可看出,一些话题的热度随着时间的推移发生着明显的变化。例如,“病毒检测”话题热度逐渐降低,而“支援湖北行动”热度逐渐增加。这是因为疫情最初在武汉大规模爆发,检测试剂供不应求,引起网民广泛关注。随着时间的推移,人们普遍更加关注疫情防控期间医疗物资等问题,各地纷纷对湖北疫情伸出援助之手。话题热度随着时间的演进出现起伏变化,说明话题之间可能发生了漂移。
基于上述话题热度分析结果,本文选取“病毒检测”和“支援湖北行动”两个话题,对其特征词进行分析。基于LDA模型提取的话题可表示为一系列特征词及其对话题的贡献。将两个话题中的特征词分别用气泡表示,气泡的大小表示特征词对话题的贡献,气泡的颜色区分两个不同的话题,如图2所示。黑色表示“病毒检测”话题,灰色表示“支援湖北行动”话题,中间区域为两个话题共有的特征词。结果显示,这两个话题尽管内容差异较大,但仍然包含一些相同的特征词,且这些共有特征词对不同话题的贡献大小存在着差异。
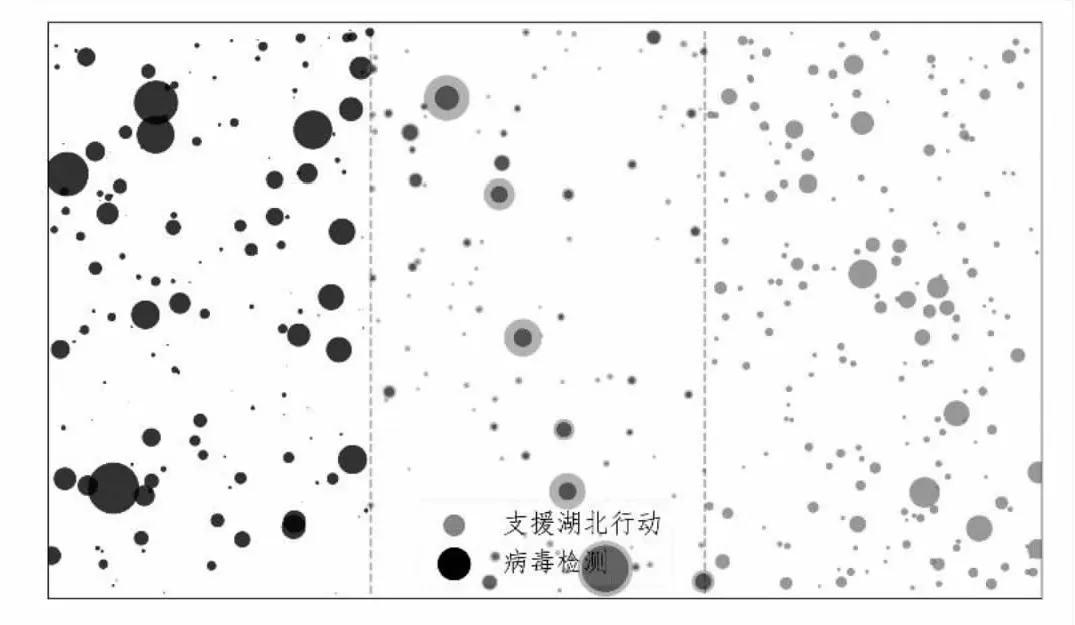
图2 特征词对话题贡献对比
不同话题包含多个共同特征词。如果我们定义特征词隶属到各话题的词频作为该特征词的热度(计算方法详见3.3节),则可以观察话题漂移过程中共有特征词在不同话题上热度随时间的变化差异。本文对比分析了话题“病毒检测”和“支援武汉行动”中共有特征词的热度变化,并绘制折线图,如图3所示。结果显示,共有特征词在话题“病毒检测”上的热度随着时间逐渐减小,在话题“支援湖北行动”上的热度逐渐增大。结合前面的分析可知,话题“病毒检测”向话题“支援湖北行动”漂移。
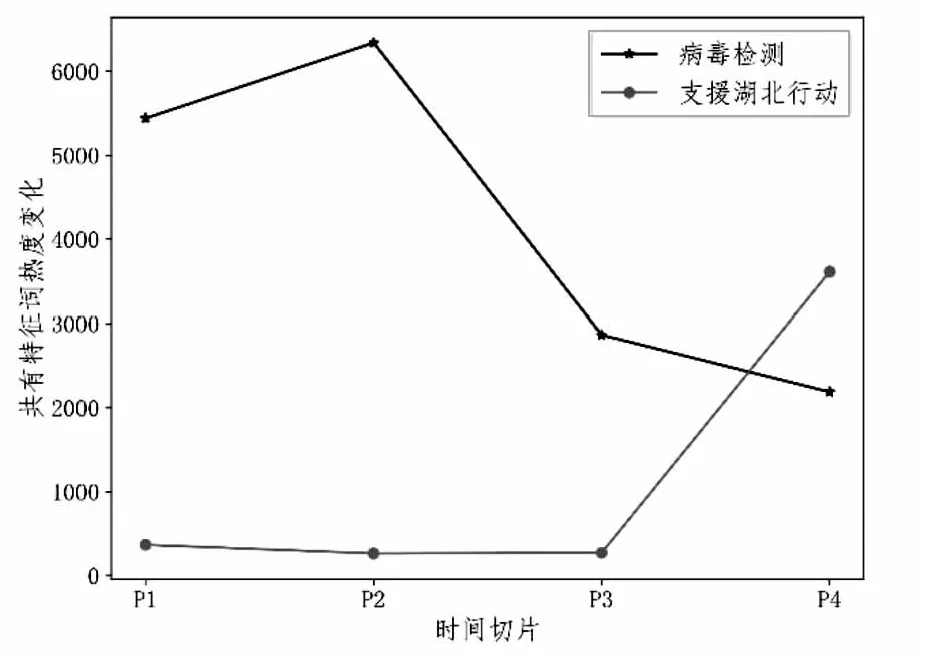
图3 共有特征词在不同话题上的热度变化对比
综上所述,话题热度变化是话题漂移的指征之一;发生漂移的两个话题之间包含了一些相同特征词,但同一特征词对不同话题的贡献存在着差异;在话题发生漂移的过程中,共有特征词在不同话题上的热度呈现出不同的变化趋势。因此,以话题中的特征词为视角,可以描述出话题漂移的微观过程。
3 话题漂移研究方法框架
本文话题漂移的研究方法框架如图4所示,包括特征词提取和筛选、基于LDA的话题识别和话题漂移路径识别及可视化三部分。
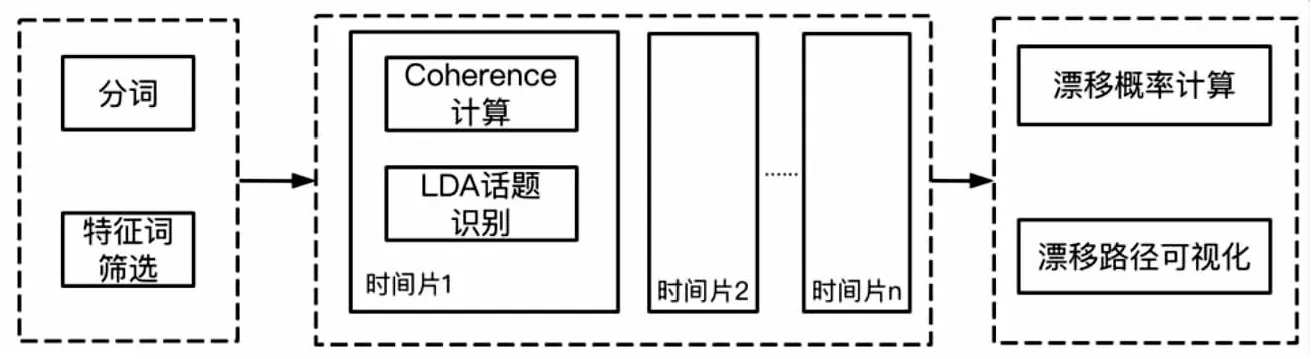
图4 话题漂移路径研究方法框架
3.1 特征词提取和筛选
话题中的特征词,是指用户生成内容中能够反映主题内容、具有明确语义的词汇。由于互联网的开放性,普通用户在发表自己观点时用词较为口语化,也存在表情符号、图片以及网络用语等不规范形式。为了提取网络文本中的话题特征词,本文首先采用结巴工具分词,根据词性对特征词进行筛选,将其限定为名词、名动词、名形词、人名、地名、机构团体和专用名词等承载较多语义的词汇,去除代词、拟声词、副词等词性以及各种网络用语及符号。在词性筛选的基础上,采用TF-IDF进一步提升特征词筛选质量,其能够在无需人工参与的情况下兼顾词频和重要性,过滤掉一些常见词,保留能提供更多信息的重要词[13]。
3.2 基于LDA的话题识别
目前研究者进行话题识别和演化分析,需要划分时间片以明确话题演化的时间维度。本文采用按照固定时间片的方法,对不同时间片中的文档信息分别运行LDA模型,得到不同时间片内覆盖的话题及其包含的特征词。
LDA话题模型发挥降维作用的关键在于对文本潜在话题数量的准确设定,但 LDA 方法自身并不能生成最佳的话题数量。Blei提出使用困惑度(Perplexity)作为确定话题数量的标准,但容易导致话题间相似度过大[14]。Teh等提出层次狄利克雷过程(Hierarchical Dirichlet Processes),其使用非参数模型自动训练得到话题数,但该方法运算效率较低,针对大规模文本分析时很难保证迭代精度[15]。考虑到模型的泛化能力以及话题抽取效果,本文采用话题Coherence数值指标计算各时间片中最佳话题数,在Coherence值趋于稳定时,相应的话题数量最优[16]。
3.3 话题漂移关系识别
互联网舆情所具有的衍生性和动态性,使舆情呈现出复杂的演化特征。话题漂移过程中衍生出的新话题与原话题在内容上具有较大偏差,这种情况下追踪话题间的漂移路径是具有挑战性的。从本文第二节分析结果可知,可以从特征词角度描述话题漂移过程。
首先,本文定义了共有特征词在话题下的热度。基于LDA模型构建话题-特征词矩阵与文档-话题矩阵,即话题由一系列特征词所构成,而文档是隶属到不同话题下的。特征词的热度可通过在文档中出现的词频来度量。令话题ti和tj中共有的特征词集合为SV={sv1,sv2,…,svn},n表示两个话题中共有特征词的数量。特征词svl在话题ti下的热度可定义为:
(1)
其中,freq(svl,dock)表示共有特征词svl在文档dock中出现的词频,weight(dock,ti)表示文档dock隶属到话题ti的权重,m表示文档集大小,即文档的数量。
其次,本文定义了话题之间的漂移概率。给定两个话题ti和tj,并假设前者出现的时间早于后者,则话题ti向话题tj漂移的概率可定义为:
(2)
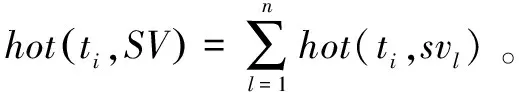
4 实证分析
4.1 数据采集与预处理
实证数据来源于新浪微博。首先设置关键词(“新冠”“肺炎”和“疫情”)和时间段等检索条件,然后通过编写网络爬虫程序实现自动化批量采集。数据集包含300 034条微博,时间跨度为2019年12月31日至2020年4月24 日。
对实验数据进行预处理:对每一条微博利用正则表达式去除非文字符号;采用百度停用词表和哈尔滨工业大学停用词表去除文本中部分代词和语气助词等;利用结巴分词工具分词,定义需要保留的词性为:名形词、名词、人名、地名、机构团体、专用名词和名动词;去除单字;保留TF-IDF值排名前80%的词;对于检索关键词,我们予以去除,因为“新冠”“肺炎”“疫情”此类高频关键词几乎在每篇微博中都出现,不利于区分话题。
4.2 基于LDA的话题识别
实验将数据集划分为4个时间片,每个时间片为4周。采用Coherence指标确定各时间片的最优话题数量,利用Python中的LDA库计算得到话题信息,导出每个话题的特征词。这些话题之间边界清晰,划分效果较为理想。本文对话题进行了编号和命名,根据每个话题下的前20个特征词的语义基本可以归纳出该话题的内容,如表1所示。由于篇幅的限制,这里仅列出每个话题的前8个特征词。

表1 话题特征词及命名
4.3 话题漂移路径识别及可视化
话题间的漂移关系描述了从一个话题衍生出另一个话题的可能性,它反映了疫情事件发展过程中相关话题的来龙去脉。根据公式(2)计算相邻时间片下话题之间的漂移概率,结果如表2所示。将概率值高于0.5的话题判定为话题之间具有漂移关系,多个时间切片之间的漂移关系形成了话题漂移路径,如图5所示,其中,连边粗细表示话题之间的漂移概率。
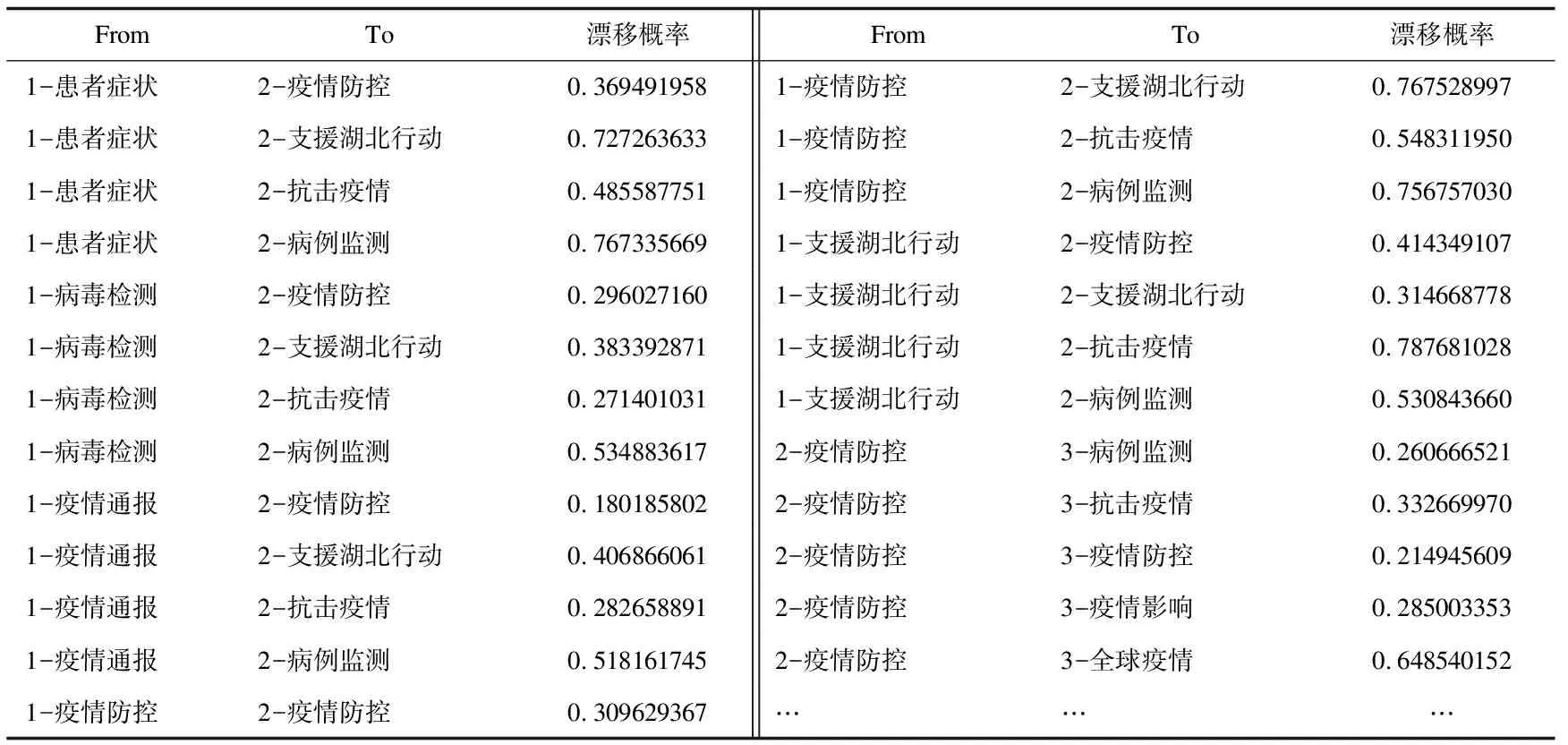
表2 话题间的漂移概率(部分)
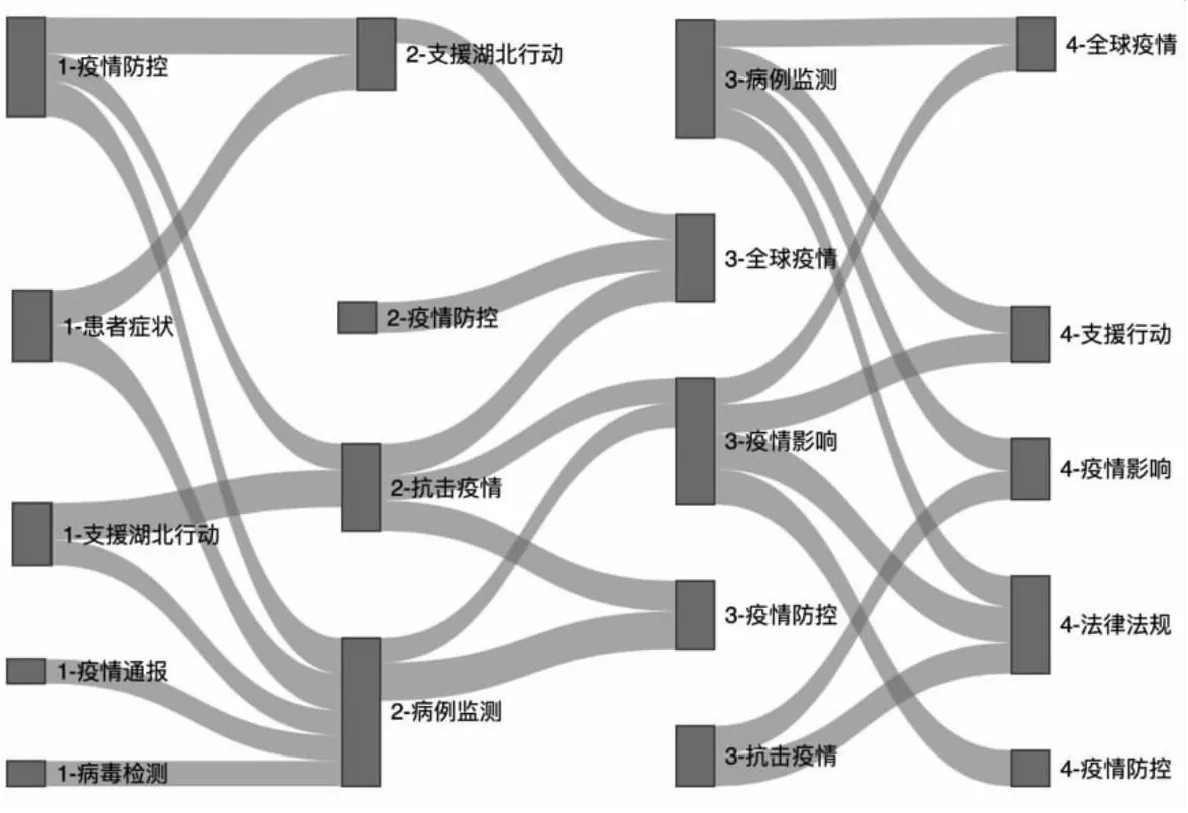
图5 疫情事件中话题漂移路径图
从研究结果可以看出,新冠疫情期间,微博上网民议题的变化反映了疫情事件的发展过程。从新冠病毒初显端倪、专家组展开病毒调查,到疫情爆发,各界开展全面抗疫,再到国内疫情逐渐得到控制,而国际疫情局势却愈发严峻,我国的防控重点也逐渐从国内疫情防控转变为境外疫情输入防控和对国际疫情的医疗援助。图5中疫情话题的漂移路径描绘出话题之间的来龙去脉,便于我们更好地掌握疫情事件的整个发展过程。具体分析如下:
P1至P2时间段处于疫情的初期,“疫情防控”以及“支援湖北行动”向“抗击疫情”漂移。其原因是武汉出现了不明原因的感染者,人们对疫情的预防和疫情发展都给予了更多的关注,但随着大量感染者的持续增加,各界为抗击疫情做准备,比如国家相关政策的出台,社会各界的有效配合,以及各大医疗队的驰援。此外,多个话题均向“病例监测”漂移,在此期间,由于疫情发展迅速,人们更多关心病例病况、活动轨迹、年龄以及居住地等信息等。这是由于面对重大突发性公共事件,恐慌情绪在全社会迅速蔓延,公众需要获取更多的病例信息来满足安全需求。
P2至P3时间段中,疫情逐步扩展到全世界,因此人们的关注点扩大到“全球疫情”的讨论。其中“疫情防控”以及“抗击疫情”均向“全球疫情”漂移,国内出现了多例境外输入病例,接着其他地区如英美等国纷纷发现了感染者,人们逐渐开始关注国外的疫情。此外,“抗击疫情”和“病例监测”向话题“疫情影响”漂移,这是由于随着社会各界的有效举措和人们的积极配合,疫情在国内的发展得到及时控制,人们的生活也逐渐恢复,整体经济也呈现复苏趋势。
P3至P4时间段中,“病例监测”“抗击疫情”向“法律法规”漂移。这一时期,在全球疫情蔓延阶段,境外输入病例超过本土确诊病例,移民管理局发布在华外国人应知法律法规,对于隐瞒出境史或者入境不如实申报健康状况将追求刑责。另外,中国各地开展抗击疫情应急攻关,全国各级财政已下达疫情补助资金,对红十字会有关领导和干部在抗击疫情期间接收和分配捐赠款物工作中存在的失职问题进行了严肃调查。此外,“病例监测”以及“疫情影响”向“支援行动”漂移,国内疫情整体出现衰退迹象,我国转向国际疫情的援助。
4.4 与基线方法对比分析
正如文献综述中所指出的,话题演化中专门检测话题漂移的已有工作非常少,话题演化路径或演化图谱分析的工作相对较多,且目前常见方法是通过度量相邻时间片中话题之间的相似性来描绘话题演化路径或演化图谱。考虑到话题演化路径可以在一定程度上反映话题在时序上的漂移状态,因此本文将话题演化路径分析作为基线(Baseline)方法,同本文提出的话题漂移路径方法进行对比实验。
在话题演化路径中,相邻时间片内话题之间相似性一般采用两个话题分别对应的词向量之间的余弦相似度来度量[4,7],其值介于0到1之间,值越大说明话题之间的语义越接近。本实验中采用每个词对话题的贡献度构成话题的词向量。为了清晰地呈现话题之间的演化路径,实验选取相似度阈值为0.4,即过滤掉相邻时间片内话题相似度较低的演化关系,得到话题演化路径图,如图6所示。

图6 基于相似性计算的话题演化路径图
从图6中可以看出,话题演化路径可以发现一些话题之间的漂移关系。例如, P1至P2时间片中“疫情防控”向“抗击疫情”漂移、P2至P3时间片中“抗击疫情”向“全球疫情”漂移以及P3至P4时间片中“疫情影响”向“法律法规”漂移等,这些话题之间的漂移关系在图5中同样被呈现出来。但是,基线方法检测出的演化关系反映了前后话题之间语义上的一致性,如P2至P3时间片的“病例监测”以及P1至P4时间片的“疫情防控”等。需要说明的是,图6中有名称相同的话题之间没有演化关系,因为前后话题之间的内涵发生了变化。例如,P3 中的“疫情影响”主要指国内复工复产,而P4中的“疫情影响”则出现了更多关于疫情对国际形势影响的微博,在语义上两者的相似度不高,因此未被识别出来。
由此可见,当相邻时间片内两个发生漂移的话题在语义上具有一定的相似度时,基线方法可以识别出这类话题间的漂移关系。但是,当发生漂移的两话题语义跨度较大时,如P2时间片中的“抗击疫情”和P3中的“疫情影响”,以及P3时间片中的“病例监测”和P4中的“法律法规”漂移等,本文提出的漂移路径方法则可以检测出这类话题之间的漂移,而基线方法则不可以。由于相当一部分漂移话题与原有舆情话题在内容上产生了较大的偏移,甚至是衍生出了新话题,因此,本文提出的方法在话题漂移路径追踪中更具有优势。
5 结语
区别于话题演化中通过话题内容相似性来构建话题的演化路径,话题漂移所产生的新话题往往呈现出与原话题内容不同的特点。本文通过观察特征词在漂移过程中的微观特征,进而提出一种话题漂移路径分析方法。对舆情事件“新冠肺炎”进行实证分析,通过LDA话题模型对各时间片文档信息进行话题抽取,结合词热度计算话题漂移概率,进而描绘出话题之间的来龙去脉,更好地帮助我们掌握疫情事件发展的整个过程,也为舆情话题的监控和预警提供了新的思路。对比实验验证了方法的有效性。
此外,从词的视角研究话题漂移也为新话题预测提供了新的思路。因为,当一个新的话题出现时,特征词首先发生变化,未来我们将探索这个方向。
猜你喜欢
音乐天地(音乐创作版)(2022年1期)2022-04-26
计算机系统应用(2021年9期)2021-10-11
人大建设(2020年5期)2020-09-25
快乐作文(1.2年级)(2020年8期)2020-09-10
37°女人(2020年5期)2020-05-11
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
