
基于特征选择和TrAdaBoost的跨项目缺陷预测方法
2022-06-21 07:10李莉石可欣任振康
计算机应用 2022年5期
李莉,石可欣,任振康
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)(∗通信作者电子邮箱lli@nefu.edu.cn)
基于特征选择和TrAdaBoost的跨项目缺陷预测方法
李莉*,石可欣,任振康
(东北林业大学 信息与计算机工程学院,哈尔滨 150040)(∗通信作者电子邮箱lli@nefu.edu.cn)
跨项目软件缺陷预测可以解决预测项目中训练数据较少的问题,然而源项目和目标项目通常会有较大的数据分布差异,这降低了预测性能。针对该问题,提出了一种基于特征选择和TrAdaBoost的跨项目缺陷预测方法(CPDP-FSTr)。首先,在特征选择阶段,采用核主成分分析法(KPCA)删除源项目中的冗余数据;然后,根据源项目和目标项目的属性特征分布,按距离选出与目标项目分布最接近的候选源项目数据;最后,在实例迁移阶段,通过采用评估因子改进的TrAdaBoost方法,在源项目中找出与目标项目中少量有标签实例分布相近的实例,并建立缺陷预测模型。以F1作为评价指标,与基于特征聚类和TrAdaBoost的跨项目软件缺陷预测(FeCTrA)方法以及基于多核集成学习的跨项目软件缺陷预测(CMKEL)方法相比,CPDP-FSTr的预测性能在AEEEM数据集上分别提高了5.84%、105.42%,在NASA数据集上分别提高了5.25%、85.97%,且其两过程特征选择优于单一特征选择过程。实验结果表明,当源项目特征选择比例和目标项目有类标实例比例分别为60%、20%时,所提CPDP-FSTr能取得较好的预测性能。
跨项目缺陷预测;特征选择;核主成分分析;实例迁移;TrAdaBoost
0 引言
由于软件开发人员开发经验的匮乏、对需求的误解或软件开发过程的不规范等一系列问题,导致了软件缺陷的产生。软件缺陷如果不立即修正,可能会导致巨大的人力、物力以及经济损失。在整个软件项目开发周期内,只有尽早发现软件缺陷,因软件缺陷带来的风险和修复风险的代价才能越小。软件缺陷预测(Software Defect Prediction, SDP)[1-2]可以帮助软件开发人员尽早发现项目中存在的缺陷。目前,大部分研究工作聚焦于项目内软件缺陷预测(Within-Project Defect Prediction, WPDP)[3],就是采用项目内的历史数据作为训练数据,对新版本进行建模预测。但是,对于新启动的项目来说,没有足够多的历史数据来构建模型进行预测。跨项目缺陷预测(Cross-Project Defect Prediction, CPDP)[4]因此产生,即利用其他项目(即源项目)中的数据构建软件缺陷预测模型,对当前项目(即目标项目)进行缺陷预测。然而,源项目和目标项目间通常有较大的数据分布差异,这会导致预测模型很难得到较好的预测性能。因此,CPDP中的关键问题也就是如何缩小源项目和目标项目之间的数据分布差异。
针对该问题,本文提出了一种两阶段的基于特征选择和TrAdaBoost的跨项目缺陷预测方法(Cross-Project Defect Prediction method based on Feature Selection and TrAdaboost, CPDP-FSTr)。该方法包括两阶段:在特征选择阶段,通过核主成分分析(Kernel Principal Component Analysis, KPCA)方法删除源项目中冗余和无关特征,再根据筛选后的源项目属性特征分布选择与目标项目属性特征分布最接近的特征;在实例迁移阶段,采用TrAdaBoost方法,从特征选择后的源项目中选择与少量有标签目标项目实例相似的实例,构建软件缺陷预测模型。
1 相关工作
1.1 跨项目缺陷预测
跨项目缺陷预测基于其他项目(源项目)中的标记数据来预测当前项目(目标项目)是否存在软件缺陷。源项目和目标项目之间的数据差异性,会导致构建模型无法取得较好的预测性能[5],因此,设计合理的缩小源项目和目标项目间的数据差异的方式仍然是跨项目缺陷预测中亟待解决的问题。针对该问题,大部分研究人员将机器学习应用于CPDP领域[6],其中通过特征选择(feature selection)方法[7]和迁移学习(transfer learning)方法[8]来设计解决方案被广泛应用。Zimmermann等[9]从项目的上下文角度出发,共提出了40种不同的项目上下文因素来计算项目间的相似性,以此选择候选源项目,主要是通过实证研究中考虑的622对CPDP结果与其相应项目间的相似性来构建决策树,完成候选源项目的选择。He等[10]通过度量元的数据分布特征选择与目标项目相匹配的源项目,考虑了16种不同的分布特征,其中众数、中位数、均值和调和均值等特征可以描述属性取值的集中趋势,异众比率、四分位差、方差和标准差等可以体现属性取值的离散程度,而偏态和峰度可以描述属性取值的分布形状。Turhan等[11]从目标项目出发,提出了Burak过滤法,首先计算目标项目与源项目中实例的欧氏距离,再对欧氏距离进行排序,选择与目标项目中每个实例最近的个源项目实例添加到候选训练集中。而Peters等[12]认为源项目中有助于CPDP的数据更多,因此提出了Peters过滤法,首先从源项目实例中选出与其距离最近的一个目标项目实例,对于选中的目标项目实例,再从源数据集中选出与其距离最近的一个实例。一些研究人员[13-14]将源项目和目标项目数据同时进行数据标准化,比如min-max标准化方法和z-score标准化方法。这些方法可以使不同项目的特征取值处于同一个取值区间,同时与原取值分布特征一致。黄琳等[15]通过将不同特性的核函数进行组合,使数据在新的特征空间得到更好的表达,再结合集成学习,提出了基于多核集成学习的跨项目软件缺陷预测(Cross-project software defect prediction based on Multiple Kernel Ensemble Learning, CMKEL)方法,进一步提升了软件缺陷预测的精度。然而,CMKEL方法中代价敏感系数的引入对实验结果有很大的影响,且整体的预测性能不佳。
1.2 特征选择
特征选择在软件缺陷预测领域有着重要的应用,是从原始特征集合中选择最有价值信息从而降低特征空间维度的过程,其目的在于去除原始数据中的冗余数据和无关数据,生成价值较高的特征子集。
特征选择方法主要包括过滤式、嵌入式和包裹式。过滤式按照发散性或相关性等指标对特征进行评分;嵌入式通过机器学习算法和模型进行训练确定特征优劣;包裹式则根据目标函数完成特征的选择。以上三种方法都只选择原始特征的一个子集,但这些子集可能无法准确表示原始数据本质的特征结构。特征转换技术的出现解决了这个问题,可以在一定程度上抽取出更具代表性的特征,其中具有代表性的方法有主成分分析法(Principal Component Analysis, PCA)和线性判别法(Linear Discriminant Analysis, LDA)。刘芳等[16]提出了基于主成分分析和优化支持向量机(Principal Component Analysis and Improved Support Vector Machine, PCA-ISVM)的软件缺陷预测方法,利用主成分分析消除数据冗余信息,结合粒子群算法完成软件缺陷预测,一定程度上提高了软件缺陷预测的效率。
1.3 迁移学习
迁移学习已被广泛应用于各个行业,其核心是找到源领域和目标领域之间的相似性,实现知识的跨领域迁移。迁移学习解决了机器学习在实际场景中模型训练数据和测试数据处于不同特征空间且具有分布不同的问题。因此,迁移学习常用于跨领域之间的知识传递,跨项目软件缺陷预测正是其中一个重要应用。
迁移学习根据学习方法可以划分为基于实例的迁移学习、基于特征的迁移学习和基于参数的迁移学习。根据特征空间是否一致可划分为同构迁移学习和异构迁移学习。
目前研究人员主要关注基于实例的迁移学习和基于特征的迁移学习。邱少健[17]提出了基于核均值匹配和多簇权重分析(Kernel Mean Matching and Multiple-Cluster Weights, KMM-MCW)的跨项目软件缺陷预测方法,将源项目划分为多个簇,通过核均值匹配(Kernel Mean Matching, KMM)算法调整簇中实例权重,继而完成实例的迁移。倪超等[18]借助聚类分析和实例迁移方法,提出了基于特征聚类和TrAdaBoost的跨项目软件缺陷预测(cross-project software defect prediction using Feature Clustering and TrAdaBoost, FeCTrA)方法,该方法可以在一定程度上缩小源项目和目标项目间的数据差异,提升缺陷预测的性能,但在聚类分析过程中,若初始簇中心挑选不理想,则软件缺陷预测的性能就会相应地下降。
本文提出了基于特征选择和TrAdaBoost的跨项目缺陷预测方法(CPDP-FSTr)。该方法通过特征选择和实例迁移两阶段,利用核主成分分析法和基于距离的属性特征分布的特征选择(feature selection based on Distance Attribute Feature Distribution, DAFD)技术,对源数据进行筛选,并增加评估因子,提升TrAdaBoost方法对错分的有缺陷样本的关注度。然后将筛选后的源项目实例和部分有标签目标实例注入改进后的TrAdaBoost方法,最终构建软件缺陷预测模型。
2 本文方法
假设源项目和目标项目具有相同的特征集合,基于该假设本文提出了一种基于特征选择和TrAdaBoost的跨项目缺陷预测方法(CPDP-FSTr),将其与只考虑DAFD特征选择过程的FSTr-D方法和只考虑KPCA特征选择过程的FSTr-KP方法分别进行预测性能的对比。
2.1 研究动机
跨项目缺陷预测主要通过源项目中的有标签实例构建训练模型,以解决目标项目有标签实例少、不足以支撑缺陷预测的问题。源项目和目标项目具有数据分布差异,通过改进的TrAdaBoost方法,从实例角度在源项目中找到与目标项目相似的实例来训练数据集,解决训练数据集不足的问题。除此之外,在实际的源项目数据中,存在着部分冗余数据和无用数据,同时数据通常不是线性的,因此需要选择有效的特征选择方法,实现对源项目特征的筛选。从源项目角度考虑,选择能够反映缺陷数据内在结构的最优特征,并采用KPCA方法进行特征选择。根据如图1所示的实验结果可知,只考虑KPCA方法特征选择过程的FSTr-KP得到的预测性能不佳,主要是由于跨项目缺陷预测存在数据分布差异。

图1 特征选择过程的实验结果(KPCA)Fig. 1 Experimental results of feature selection process (KPCA)
从目标项目角度来说,源项目和目标项目之间存在分布差异,因此选择与目标项目更为相似的源项目特征,从而辅助目标项目构建有效的缺陷预测模型。因此,提出了基于距离的属性特征分布的特征选择(DAFD)技术。根据如图2所示的实验结果可知,只考虑DAFD特征选择过程的FSTr-D方法在部分项目中性能优于只考虑KPCA特征选择过程的FSTr-KP方法,但整体预测性能仍欠佳,主要原因是源项目中存在冗余数据影响预测性能。
基于以上分析,拟考虑结合源项目和目标项目两个角度,采用KPCA和DAFD结合的两过程特征选择方法CPDP-FSTr,既避免源项目冗余数据对预测性能的负面影响,同时一定程度上缩小了数据间的分布差异。根据如图3所示的实验结果可知,两过程特征选择方法提高了预测性能,且表现良好。
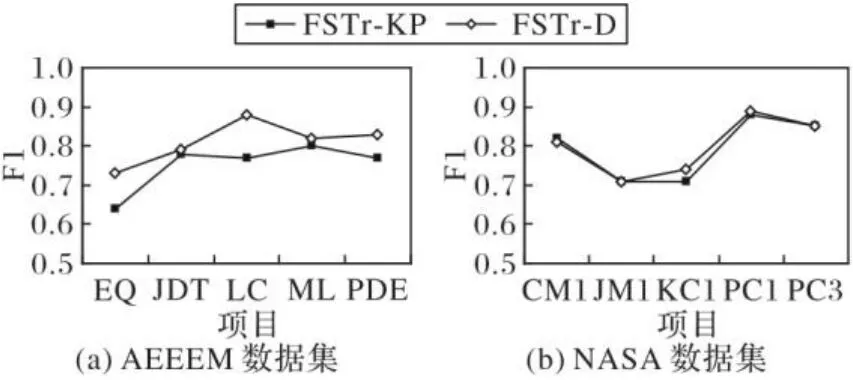
图2 特征选择过程的实验结果(DAFD)Fig. 2 Experimental results of feature selection process (DAFD)
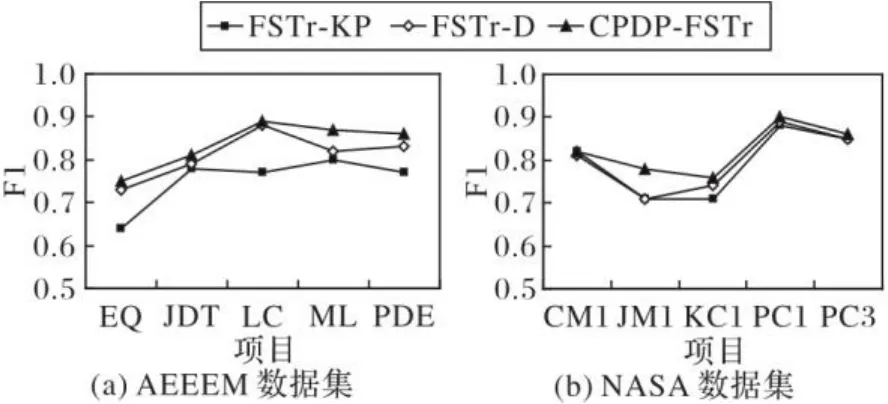
图3 特征选择过程的实验结果(两过程)Fig. 3 Experimental results of feature selection process (two-process)
根据以上分析及过程性实验可知,由于跨项目软件缺陷预测存在的数据分布差异以及源项目中冗余数据所带来的负面影响,单一阶段特征选择方法的预测性能不佳,而采用KPCA和DAFD两过程结合的特征选择方法一定程度上解决了以上问题,因此采用KPCA和DAFD两过程结合作为特征选择阶段的特征选择方法。
2.2 方法流程
CPDP-FSTr方法的流程如图4所示。该方法包括特征选择和实例迁移两个阶段,具体的流程如下:
1)在特征选择阶段,包括两个过程。首先,CPDP-FSTr通过核主成分分析法删除源项目数据中的无用数据和冗余数据。其次,从筛选后的源数据属性分布特征集合中选择与目标项目相近的特征形成候选训练数据集。
2)在实例迁移阶段,将目标项目中少量有标签的实例加入候选训练数据集内,采用经评估因子改进后的TrAdaBoost方法,通过不断迭代,得到若干个基分类器,然后集成得到强分类器,最终得到跨项目缺陷预测模型。本文源项目特征选择比例和目标项目中有标签的实例比例分别为60%、20%。
2.3 特征选择阶段
源项目中通常会存在部分无关数据和冗余数据,这些数据都会一定程度上影响缺陷预测模型的预测性能;同时,由于源项目和目标项目数据分布不一致,源项目中与目标项目相关性较低的特征也会影响到缺陷预测模型的性能。因此,特征选择阶段包括两部分:第一部分,移除源项目中的类标签,对其余特征采用基于KPCA的特征选择技术,筛选出无用特征和冗余特征;第二部分,提取源项目和目标项目的属性分布特征,选择与目标项目最相近的源项目特征。

图4 CPDP-FSTr流程Fig. 4 Flow chart of CPDP-FSTr
2.3.1 基于核主成分分析的特征选择技术KPCA
PCA技术是最经典的线性特征转换技术,当数据是线性可分且服从高斯分布时,PCA的特征选择效果较好。但在跨项目软件缺陷预测领域,由于缺陷数据在线性子空间中不能进行划分,因此PCA提取的特征代表性欠佳,导致预测结果不理想。KPCA技术是对PCA技术的改进[19],可以更好地处理非线性数据,选择有代表性的特征,同时删除数据中的无关特征和冗余特征。KPCA技术使用一个非线性映射函数将低维特征空间中的数据映射到高维特征空间中,再找到其线性子空间进行降维,从而达到特征选择的目的。现有研究表明,KPCA的性能优于PCA。
将KPCA方法应用于跨项目缺陷预测领域,通常考虑Linear线性核函数或径向基高斯核函数(Radial Basis Function, RBF)。由于本文研究涉及数据集特征数较小,样本数正常,故采用RBF径向基高斯核函数进行特征选择。
协方差矩阵的特征方程可以表示为:
协方差的特征方程可以表示为:
2.3.2 基于距离的属性特征分布的特征选择技术DAFD
基于选择分布特征与目标数据最相似的候选数据的基本原理,使用特征向量的欧氏距离来确定这些最相似的候选向量。对欧氏距离进行升序排序,选择前r项作为候选训练数据集。
本文采用的属性分布特征是均值(mean)、标准差(std)、偏度(skew)和峰度(kurt)这四个。均值可以体现数据分布集中趋势,标准差体现数据的离散程度,偏度和峰度可以体现数据的分布形态。在选取相似的源项目特征之前先对源项目和目标项目数据的所有属性取值进行数据预处理,采用最大最小(min_max)标准化进行数据归一化,使所有分布特征的特征值归一化到区间[0,1]。这样既可以消除不同度量大小对DAFD方法的不良影响,同时也可以使属性的取值分布接近正态分布。首先,使用欧氏距离公式计算源项目和目标项目之间所有属性分布特征向量的距离,来判断两个项目间的数据分布的相似性。然后对计算得出的距离进行升序排序,选择距离最小的前r个特征。
算法1中给出了特征选择阶段的详细描述。
算法1 特征选择。
6) 计算降维后的矩阵:
2.4 实例迁移阶段
CPDP-FSTr方法选择TrAdaBoost方法来进行实例迁移。TrAdaBoost是对集成学习算法AdaBoost的改进,采用了两套权重调整机制,对源项目和目标项目的权重调整机制相反。源项目采取的权重调整机制是增加与目标项目相关的样本权重,减小与目标项目无关的样本权重,从而筛选出与目标项目更相关的样本。而目标项目则是增加错误分类的样本权重,减小正确分类的样本权重,以此找到更难分类的样本。以上权重调整机制不断迭代,最后用加权投票的方式将每一轮迭代产生的基分类器加权求和形成一个强分类器。
然而由于数据存在类不平衡问题,当类不平衡问题极其严重时,有缺陷样本被错分对整体的错误率影响较小,而预测结果则会偏向于多数类。设置评估因子EF改进TrAdaBoost方法,使得预测结果更加关注错分的有缺陷样本。评估因子EF以F‑measure为基础。
其中:EF由T和TN计算,T表示有缺陷的实例被预测为有缺陷,TN表示不含有缺陷的实例被预测为无缺陷。本文设置,更加关注有缺陷实例被错分的情况;那么,设置目标实例权重调整因子为:
算法2给出了实例迁移阶段的详细描述。
算法2 实例迁移。
8) 更新实例权重:
9)迭代结束;
10)输出假设:
3 实验设置及结果分析
3.1 数据集
在本文方法的实验研究中,采用了公开的软件缺陷数据集:AEEEM数据集和NASA数据集。表1~2分别给出了AEEEM数据集和NASA数据集中项目的统计信息。
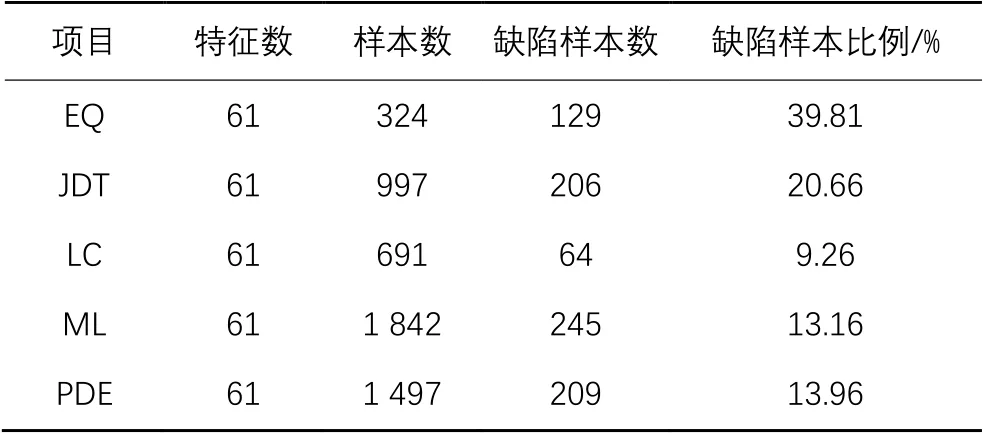
表1 AEEEM数据集的统计信息Tab. 1 Statistical information of AEEEM dataset
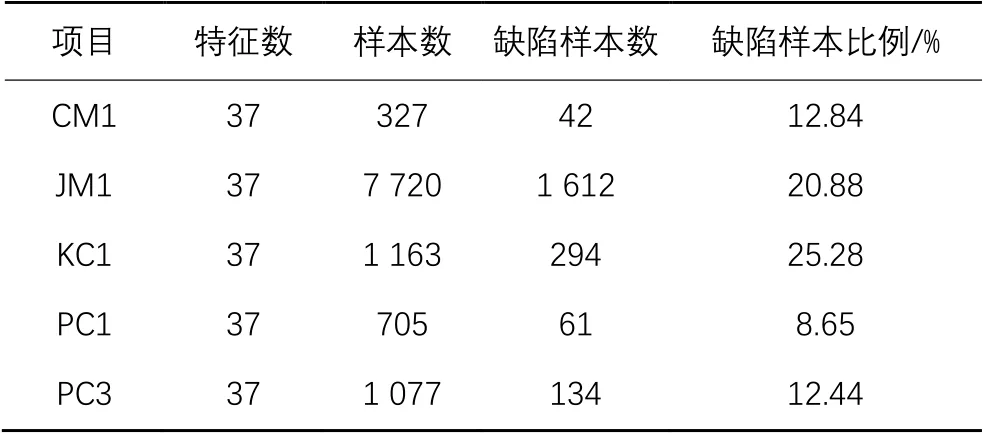
表2 NASA数据集的统计信息Tab. 2 Statistical information of NASA dataset
3.2 评价指标
软件缺陷预测考虑的是目标项目中是否存在缺陷的一个二分类问题。对于目标项目的任一实例进行缺陷预测都涉及到四种实际情况:若有缺陷的实例被预测为有缺陷,则记为TP(True Positive);若无缺陷的实例被预测为有缺陷,则记为FP(False Positive);若无缺陷的实例被预测为无缺陷,则记为TN(True Negative);若有缺陷的实例被预测为无缺陷,则记为FN(False Negative)。根据以上四种实际情况,可以定义精确度()、召回率()以及F1度量(F1-measure)。
其中,精确度指在所有被预测为有缺陷的实例中,真正有缺陷的实例比例。
召回率指在所有真正有缺陷的实例中,被正确预测为有缺陷的实例比例。
F1度量可以综合考虑精确度和召回率两个指标,在类不平衡问题中能够更好地对预测性能进行评价。故本文使用F1作为评价方法性能的评价指标。
3.3 研究问题
为了验证CPDP-FSTr方法的有效性和预测性能,两过程特征选择的有效性以及CPDP-FSTr方法的相关参数设定,本文主要关注以下四个问题。
问题1 CPDP-FSTr方法与现有的优秀的跨项目缺陷预测方法的预测性能对比。如今,在跨项目缺陷预测领域,研究人员已经提出了很多优秀算法,本文考虑基于特征迁移和实例迁移的跨项目缺陷预测方法FeCTrA,基于多核集成学习的跨项目软件缺陷预测(CMKEL)方法,以及未改进TrAdaBoost的CPDP-FSTr方法CPDP-FSNTr。
问题2 CPDP-FSTr方法的特征选择阶段包括两个特征选择过程。不同的特征选择过程可以选择出不同的特征,对最终的预测性能也可能不同。本文根据源项目、目标项目以及跨项目缺陷预测特点进行特征选择过程的过程性探究实验。研究中只考虑KPCA和DFAD的单一选择过程和包含两者的两过程特征选择的性能表现,验证了CPDP-FSTr方法中两过程特征选择的合理性和有效性。
问题3 目标项目中有类标的实例比例对CPDP-FSTr方法预测性能的影响。由于目标项目中的类标信息需要由专业人员标记得出,需要消耗大量的人力和物力,因此,CPDP问题需要少量的标注实例得出较好的预测结果。本文考虑20%以下的有标签实例比例,分析其对CPDP-FSTr方法的影响。
问题4 在特征选择阶段,源项目中的特征选择比例对CPDP-FSTr方法预测性能的影响。CPDP-FSTr方法基于属性分布特征通过距离选出与目标特征相似的源项目特征。因此,本文考虑10%~100%、步长为10%的特征选择比例,分析其对CPDP-FSTr方法产生的影响。
3.4 实验方法及参数设置
CPDP-FSTr方法主要包括特征选择和实例迁移两部分。在特征选择阶段,源项目的特征选择比例设置为,其中表示为源项目的特征数。在实例迁移阶段,选择目标项目中20%的实例放入候选训练数据集。
在实验的过程中,选择一个项目作为源项目,另一个项目作为目标项目,进行一对一的跨项目缺陷预测。所有结果采用10次跨项目5折交叉验证的平均值。跨项目5折交叉验证是指:使用源项目中所有的有标签数据和目标项目中的1折(即20%)的有标签数据作为最终的训练集,对目标项目中未标记的4折(即80%)数据进行预测。
3.5 结果分析
3.5.1 针对问题一的结果分析
本文选择AEEEM和NASA数据集,对CPDP-FSTr方法的预测性能和有效性进行实验研究,使用决策树作为基分类器,特征选择比例为60%,有标签的目标项目实例选择比例为20%,并将该方法与其他三种方法进行对比。采用F1作为评价指标,结果如表3~4所示。
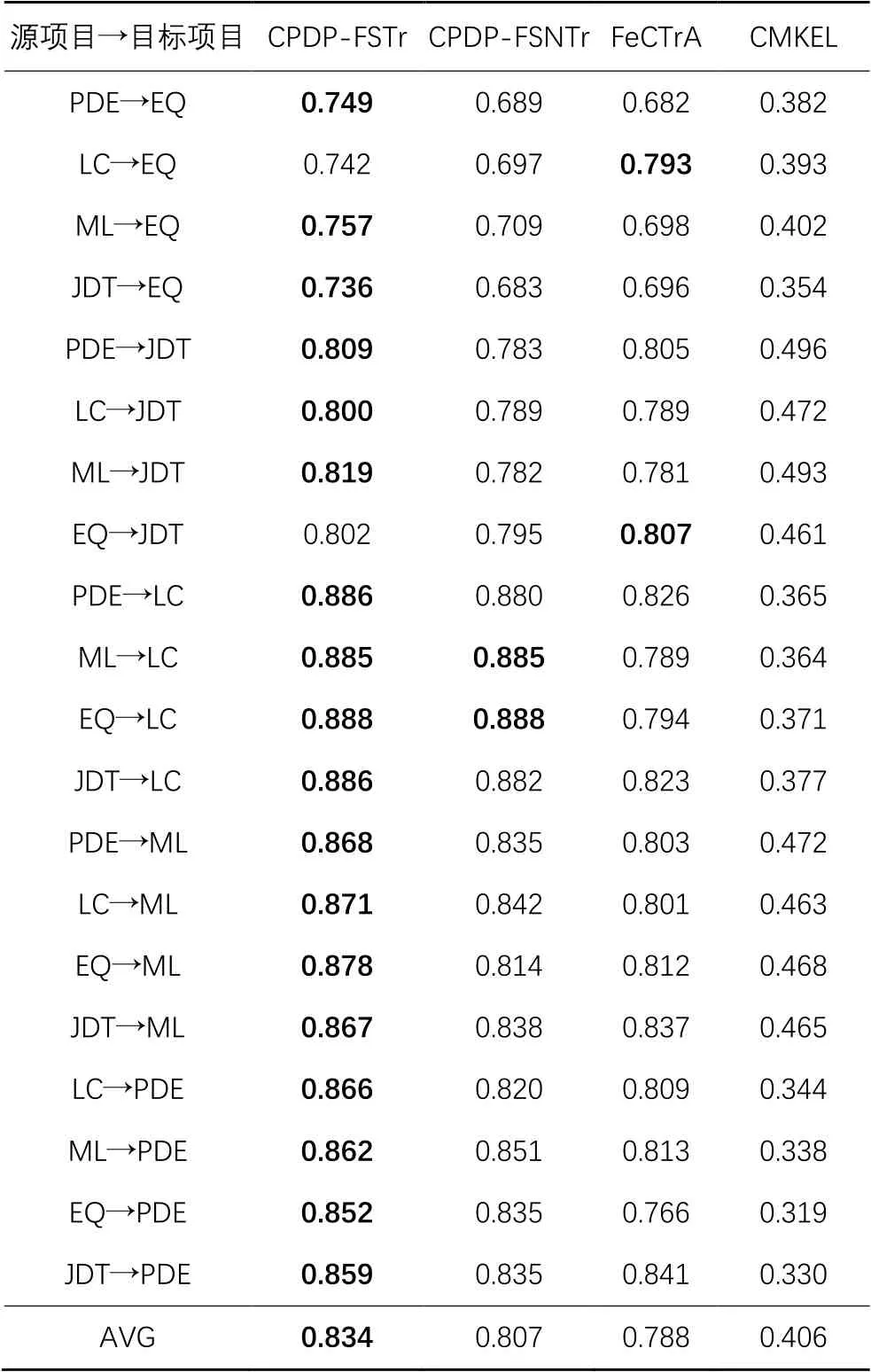
表3 不同算法预测性能的结果对比(AEEEM数据集)Tab. 3 Result comparison of prediction performance of different algorithms (AEEEM dataset)
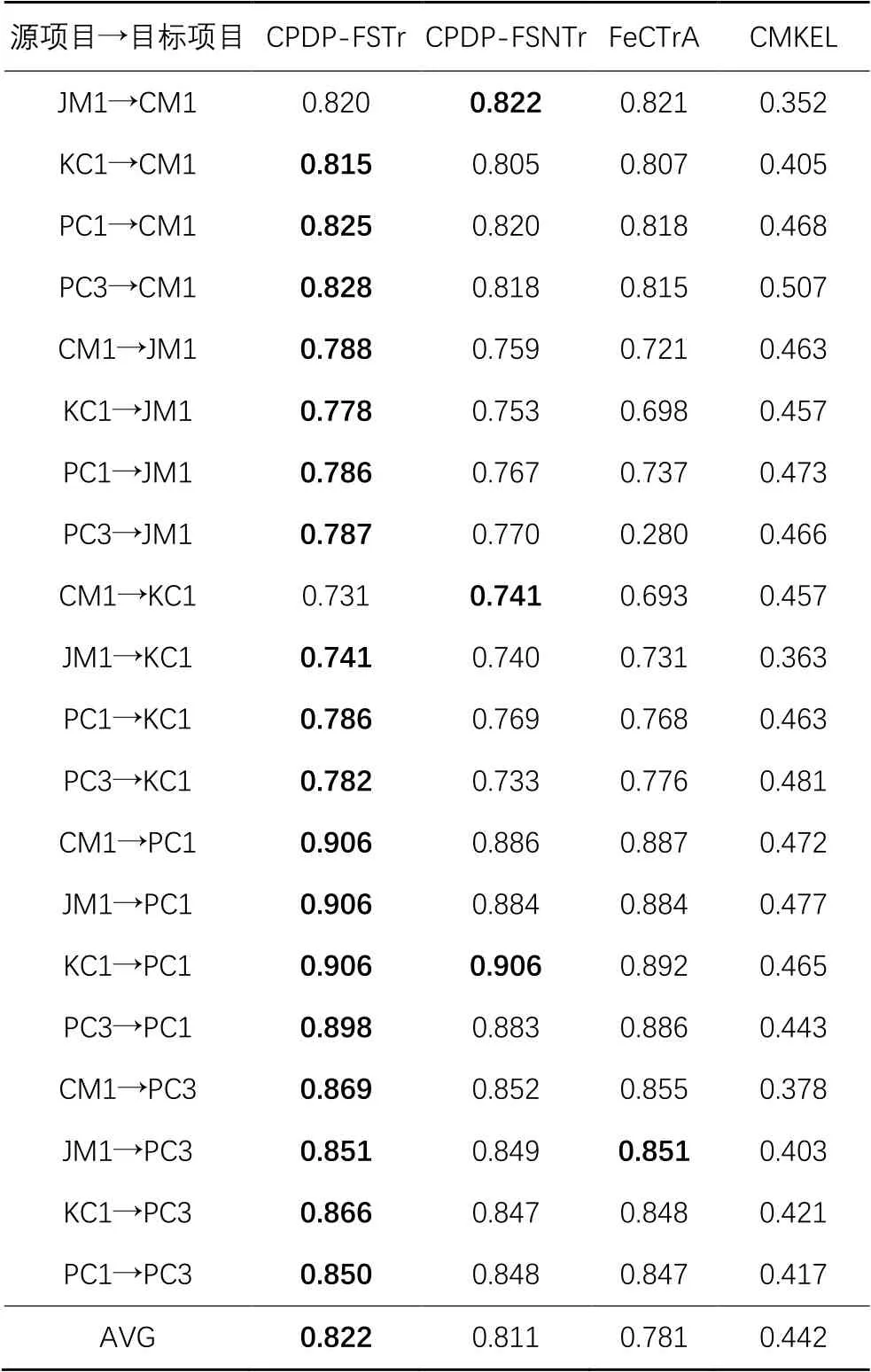
表4 不同算法的预测性能结果对比(NASA数据集)Tab. 4 Result comparison of prediction performance of different algorithms (NASA dataset)
在表3~4中,第一列表示跨项目缺陷预测各方法的应用场景,如:PDE→EQ表示源项目为PDE,目标项目为EQ。其余各列表示在不同场景下不同算法的F1指标,即其预测性能。AVG表示每一种方法的整体平均预测性能,每一行的最大值进行了加粗表示。
根据表3~4的实验结果可以看出,CPDP-FSTr方法的预测性能明显优于其他三种对比方法,其大部分场景下的预测性能都表现较好,可以取得更好的效果。在AEEEM数据集中,从平均预测性能来看,CPDP-FSTr与CPDP-FSNTr、FeCTrA和CMKEL相比分别提高了3.34%、5.84%和105.42%。例如PDE→ML,CPDP-FSTr方法的F1值为0.868,相较于CPDP-FSNTr(0.835)、FeCTrA(0.803)以及CMKEL(0.472),其预测性能分别提高了3.95%、3.99%和76.9%。从表3可以看出,CPDP-FSTr在目标项目为EQ时,F1取得最大值的情况较少,其原因可能是EQ的缺陷样本比例较高,且EQ的样本数较少,导致可以放入训练集的有类标的目标项目数据较少。NASA数据集中目标项目为CM1时,情况与EQ相似,且NASA数据集中,从平均预测性能来看,CPDP-FSTr与CPDP-FSNTr、FeCTrA和CMKEL相比分别提高了1.36%、5.25%和85.97%。
另外在整个CDPD-FSTr方法中,随着对TrAdaBoost方法的改进,平均预测性能得到了提升。在AEEEM数据集中,其平均预测性能由0.807提升到了0.834。而在NASA数据集中,其平均预测性能由0.811提升到了0.822。
因此,在跨项目缺陷预测中,相较于其他三种方法,本文提出的CPDP-FSTr方法的预测性能表现更好。
3.5.2 针对问题2的结果分析
本阶段实验选择特征选择比例为60%,有标签的目标项目实例选择比例为20%。同时将两过程特征选择的CPDP-FSTr方法与只考虑KPCA方法特征选择过程的FSTr-KP、只考虑DAFD特征选择过程的FSTr-D方法所得到的预测性能分别进行对比。不同特征选择过程的实验结果如表5~6所示。

表5 特征选择过程的实验结果(AEEEM数据集)Tab. 5 Experimental results of feature selection process (AEEEM dataset)
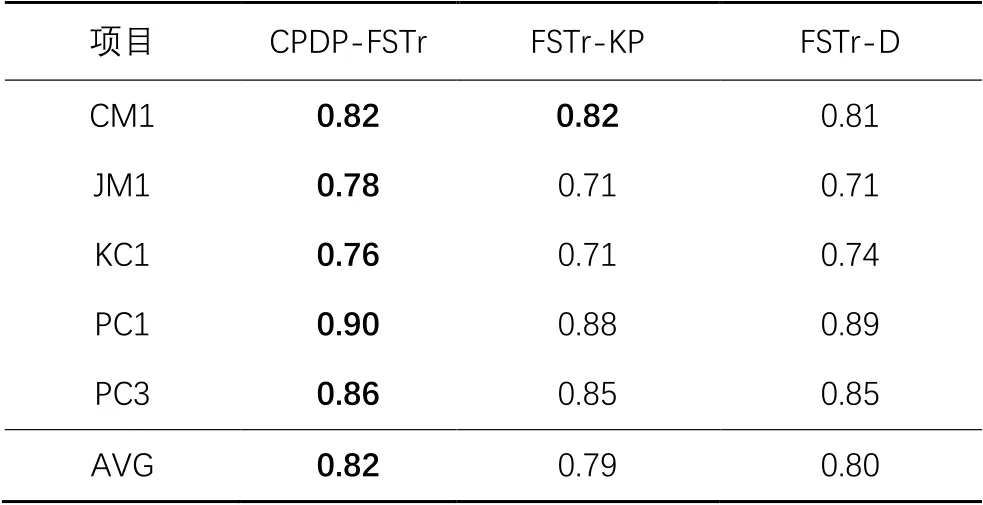
表6 特征选择过程的实验结果(NASA数据集)Tab. 6 Experimental results of feature selection process (NASA dataset)
在表5~6中,第一列表示跨项目缺陷预测中的目标项目,AVG表示每一种特征选择过程的整体平均性能,每一行的最大值进行了加粗表示。
表5~6的实验结果可以验证2.1节采用两过程特征选择方法的合理性,在实验涉及的所有项目中,含两过程特征选择的CPDP-FSTr的平均性能均优于单一特征选择过程的FSTr-KP和FSTr-D方法。在AEEEM数据集中,CPDP-FSTr相较FSTr-KP和FSTr-D在平均预测性能上分别提高了12%和3.7%。在NASA数据集中,CPDP-FSTr相较FSTr-KP和FSTr-D在平均预测性能上分别提高了3.8%和2.5%。综上,实验结果表明,CPDP-FDTr方法考虑到了源项目角度的特征选择问题以及目标项目角度的数据分布差异问题,上述两个问题一定程度上的解决使得特征选择的有效性得到了提升。
综上,实验验证了CPDP-FSTr方法中两过程特征选择的性能优于单一特征选择过程,具有其合理性和有效性。
3.5.3 针对问题3的结果分析
本文设置5%、10%以及20%三种有类标实例比例进行实验研究,以此分析目标项目中有类标实例比例对于CPDP-FSTr方法性能的影响。由于标注实例需要耗费人力和物力,所以把比例控制在20%以下有助于减少开销,且同时更有效地帮助模型进行更加准确的预测。此外,对于5%、10%以及20%的比例,分别采用跨项目的20折、10折和5折交叉验证。有类标实例比例对于CPDP-FSTr方法性能的影响如图5~6所示。
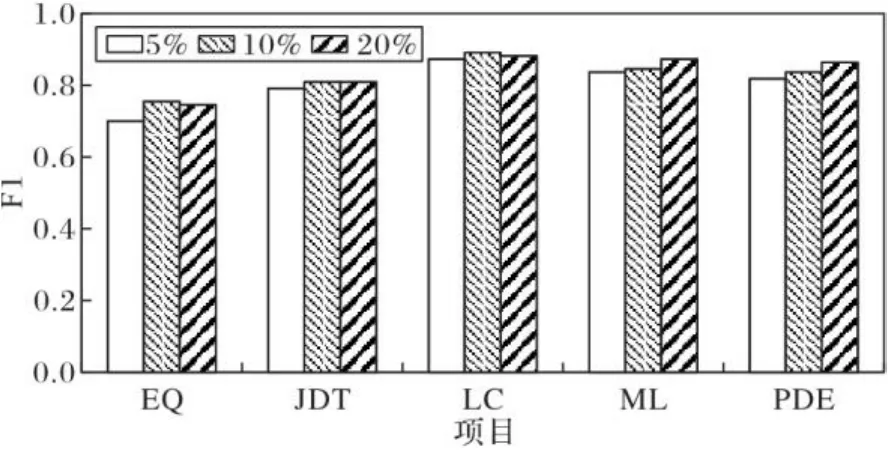
图5 目标项目有类标实例比例对性能的影响(AEEEM数据集)Fig. 5 Influence of target project labeled instance proportion on performance (AEEEM dataset)

图6 目标项目有类标实例比例对性能的影响(NASA数据集)Fig. 6 Influence of target project labeled instance proportion on performance (NASA dataset)
在图5~6中,横轴代表不同的目标项目,纵轴代表对应的F1值。可以看出,在LC、ML和PDE这三个项目中,随着目标项目有类标实例比例的增加,CPDP-FSTr方法的预测性能也随之提升,主要是由于这三个项目中包含的样本数较多,分别为691、1 842、1 497,随着目标项目中有标签实例比例的增加,可用的实例信息越多,得到的预测结果就越好。对于项目JDT来说,当有类标实例比例为10%时,F1值最大,当比例增加到20%时,预测性能反而下降,其可能的原因是JDT的缺陷样本比例较高,或数据质量不好。对于项目EQ来说,当比例从5%上升到20%时,F1处于不稳定的状态,其可能的原因是EQ项目中的样本太少,只有324个,随着比例的增加,可用的信息增加得很少,因此有类标实例比例对其性能的影响不大。
由图6可以看出,整体而言,CPDP-FSTr的预测性能随着目标项目有类标实例比例的增大而不断提升。在CM1项目上,目标项目有类标实例比例从10%增加到20%,其性能变化幅度较小,可能是由于CM1项目中仅包含327个实例,比例的变化不会增加太多可用信息。在JM1、KC1、PC1和PC3上,CPDP-FSTr的预测性能均随着有类别实例比例增加而提高,主要是由于这四个项目中包含的实例数较多,随着有类标实例比例的增加,增加的可用信息也更多,预测性能也就越来越好。
因此,在CPDP-FSTr方法中的特征选择阶段,有类标的实例比例选定为20%比较合理。特征选择阶段采用的方法更适用于实例个数较多的数据集,预测性能更优。
3.5.4 针对问题4的结果分析
为了研究CPDP-FSTr方法中的特征选择阶段,源项目中的特征选择比例对于该方法性能的影响,本文将特征选择比例设定为10%~100%、步长为10%。特征选择比例对CPDP-FSTr方法性能的影响如图7~8所示。
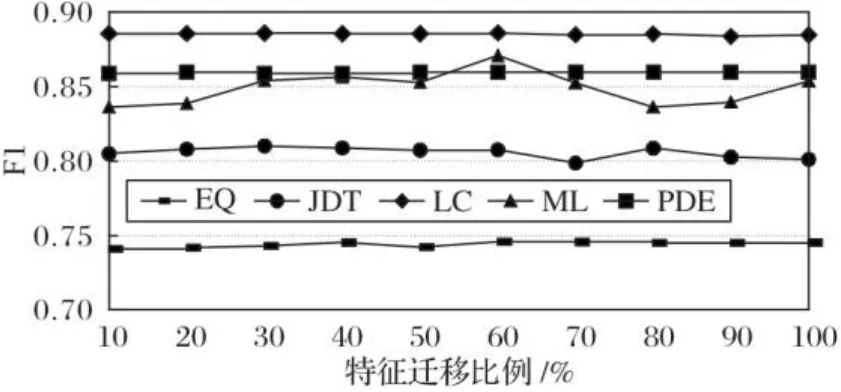
图7 特征选择比例对性能的影响(AEEEM数据集)Fig. 7 Influence of feature selection proportion on performance (AEEEM dataset)
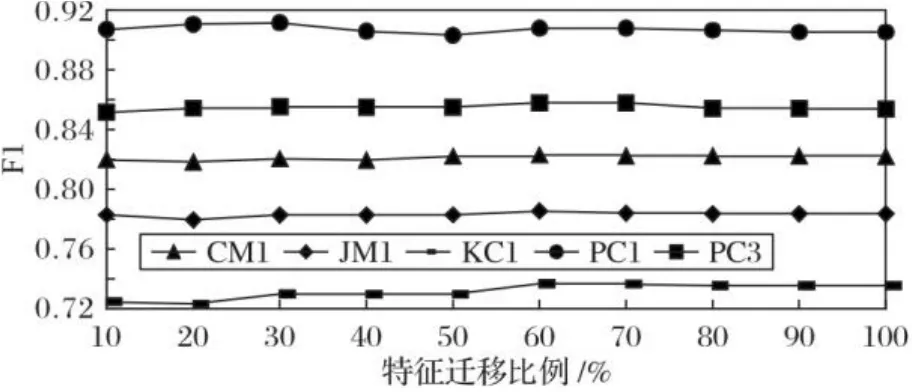
图8 特征选择比例对性能的影响(NASA数据集)Fig. 8 Influence of feature selection proportion on performance (NASA dataset)
在图7~8中,横坐标代表不同的特征迁移比例,纵坐标代表对应的F1值。由图7可以发现,当特征迁移比例从10%上升到100%的过程中,EQ、LC和PDE整体处于较为稳定的状态,随着特征迁移比例的增加,F1分别在0.74、0.89和0.86上下浮动。在EQ项目和LC项目中,当迁移的特征比例为60%时,CPDP-FSTr方法取得的预测性能最高。在JDT项目中,当迁移比例为10%~60%时,预测性能较为平稳,迁移比例为70%时预测性能最差,迁移比例为80%时到达峰值,之后性能不断下降。在ML项目中,当迁移比例为60%时,取得最优效果,随着迁移比例继续提高,预测性能大幅下降,到80%时开始回升。
由图8可以看出,随着特征迁移比例从10%上升到100%,CM1、JM1、KC1、PC1和PC3这五个项目均处于较为平稳的状态。其中,CM1、JM1在特征迁移比例为60%时,预测性能最佳;KC1、PC1和PC3这三个项目在特征迁移比例为60%和70%时,均取得最优预测性能。当特征迁移比例继续提升时,性能均有小幅度下降。
因此,在CPDP-FSTr方法的特征选择阶段,源项目中的特征选择比例设置为60%时,能取得较好的预测结果。
4 结语
本文提出了一种基于特征选择和TrAdaBoost的跨项目缺陷预测方法,一定程度上缩小了跨项目缺陷预测中源项目和目标项目间的数据分布差异,且通过采用KPCA方法和基于距离的属性特征分布,找出了与目标项目最相近的源项目特征,同时增加了评估因子改进TrAdaBoost技术,以保证更关注错分的有缺陷样本,继而进行实例迁移,构建跨项目缺陷预测模型。实验结果表明,该方法可以有效应用于跨项目缺陷预测中,且预测性能明显优于基准实验,提高了软件缺陷预测的性能。
在接下来的研究工作中,将进一步探讨:1)不同基分类器对于CPDP-FSTr方法预测性能的影响,如支持向量机、逻辑回归、朴素贝叶斯等;2)优化特征选择策略,进一步提高CPDP-FSTr方法的有效性和预测性能。本文方法对于数据量较少的数据(如EQ项目样本数为324)的预测性能可进一步提高,因此需要对特征选择策略进一步优化。在下一阶段研究中,可以选择中位数、离散系数等构建属性分布特征向量,选择适用于不同数据量数据集的属性分布特征组合。同时,也可以考虑通过信息熵、基尼指数来判断源项目和目标项目之间的分布相似性,进一步提高本文方法的特征选择的有效性。
[1] 宫丽娜,姜淑娟,姜丽.软件缺陷预测技术研究进展[J].软件学报,2019,30(10):3090-3114.(GONG L N, JIANG S J,JIANG L. Research progress of software defect prediction [J]. Journal of Software, 2019, 30(10): 3090-3114.)
[2] HALL T, BEECHAM S, BOWES D, et al. A systematic literature review on fault prediction performance in software engineering [J]. IEEE Transactions on Software Engineering, 2012, 38(6): 1276-1304.
[3] GONG L N, JIANG S J, BO L L, et al. A novel class-imbalance learning approach for both within-project and cross-project defect prediction [J]. IEEE Transactions on Reliability, 2020, 69(1): 40-54.
[4] 陈翔,王莉萍,顾庆,等.跨项目软件缺陷预测方法研究综述[J].计算机学报,2018,41(1):254-274.(CHEN X, WANG L P, GU Q, et al. A survey on cross-project software defect prediction methods [J]. Chinese Journal of Computers, 2018, 41(1): 254-274.)
[5] YUAN Z D, CHEN X, CUI Z Q, et al. ALTRA: cross-project software defect prediction via active learning and TrAdaBoost [J]. IEEE Access, 2020, 8:30037-30049.
[6] PRABHA C L, SHIVAKUMAR N. Software defect prediction using machine learning techniques [C]// Proceedings of the 2020 4th International Conference on Trends in Electronics and Informatics. Piscataway: IEEE, 2020:728-733.
[7] SAIFUDIN A, TRISETYARSO A, SUPARTA W, et al. Feature selection in cross-project software defect prediction [J]. Journal of Physics: Conference Series, 2019, 1569(2): Article No.022001.
[8] 吴琦.基于迁移学习的跨项目软件缺陷预测[D].长春:吉林大学,2018:12-13.(WU Q. Cross-project defect prediction based on transfer learning [D]. Changchun: Jilin University,2018: 12-13.)
[9] ZIMMERMANN R, NAGAPPAN N, GALL H, et al. Cross-project defect prediction: a large scale experiment on data vs. domain vs. process [C]// Proceeding of the 2009 7th Joint Meeting of the European Software Engineering Conference and the ACM SIGSOFT Symposium on the Foundations of Software Engineering. New York: ACM, 2009: 91-100.
[10] HE Z M, SHU F D, YANG Y, et al. An investigation on the feasibility of cross-project defect prediction [J]. Automated Software Engineering, 2012, 19(2): 167-199.
[11] TURHAN B. On the dataset shift problem in software engineering prediction models [J]. Empirical Software Engineering, 2012, 17(1/2): 62-74.
[12] PETERS F, MENZIES T, MARCUS A. Better cross company defect prediction [C]// Proceedings of the 2013 10th Working Conference on Mining Software Repositories. Piscataway:IEEE, 2013: 409-418.
[13] NAM J, PAM S J, KIM S. Transfer defect learning [C]// Proceedings of the 2013 35th International Conference on Software Engineering, Piscataway: IEEE, 2013: 382-391.
[14] PANICHELLA A, OLIVETO R, DE LUCIA A. Cross-project defect prediction models: L’Union fait la force [C]// Proceedings of the 2014 Software Evolution Week — IEEE Conference on Software Maintenance, Reengineering, and Reverse Engineering. Piscataway: IEEE, 2014: 164-173.
[15] 黄琳,荆晓远,董西伟.基于多核集成学习的跨项目软件缺陷预测[J].计算机技术与发展,2019,29(6):27-31.(HUANG L, JING X Y,DONG X W, Cross-project software defect prediction based on multiple kernel ensemble learning [J]. Computer Technology and Development, 2019, 29(6): 27-31.)
[16] 刘芳,高兴,周冰,等.基于PCA-ISVM的软件缺陷预测模型[J].计算机仿真,2014,31(3):397-401.(LIU F, GAO X, ZHOU B, et al. Software defect prediction model based on PCA-ISVM [J]. Computer Simulation, 2014, 31(3): 397-401.)
[17] 邱少健.基于迁移学习的跨项目软件缺陷预测关键技术研究[D].广州:华南理工大学,2019:40-60.(QIU S J. Research on cross-project software defect prediction by transfer learning [D]. Guangzhou: South China University of Technology, 2019: 40-60.)
[18] 倪超,陈翔,刘望舒,等.基于特征迁移和实例迁移的跨项目缺陷预测方法[J].软件学报,2019,30(5):1308-1329.(NI C, CHEN X, LIU W S, et al. Cross-project defect prediction method based on feature transfer and instance transfer [J]. Journal of Software, 2019, 30(5): 1308-1329.)
[19] SCHÖLKOPF B, SMOLA A, MÜLLER K R. Kernel principal component analysis [C]// Proceedings of the 1997 International Conference on Artificial Neural Networks, LNCS 1327. Berlin: Springer, 1997: 583-588.
Cross-project defect prediction method based on feature selection and TrAdaBoost
LI Li*, SHI Kexin,REN Zhenkang
(College of Information and Computer Engineering,Northeast Forestry University,Harbin Heilongjiang150040,China)
Cross-project software defect prediction can solve the problem of few training data in prediction projects. However, the source project and the target project usually have the large distribution difference, which reduces the prediction performance. In order to solve the problem,a new Cross-Project Defect Prediction method based on Feature Selection and TrAdaBoost (CPDP-FSTr) was proposed. Firstly, in the feature selection stage, Kernel Principal Component Analysis (KPCA) was used to delete redundant data in the source project. Then, according to the attribute feature distribution of the source project and the target project, the candidate source project data closest to the target project distribution were selected according to the distance. Finally, in the instance transfer stage, the TrAdaBoost method improved by the evaluation factor was used to find out the instances in the source project which were similar to the distribution of a few labeled instances in the target project, and establish a defect prediction model. Using F1 as the evaluation index, compared with the methods such as cross-project software defect prediction using Feature Clustering and TrAdaBoost (FeCTrA), Cross-project software defect prediction based on Multiple Kernel Ensemble Learning (CMKEL), the proposed CPDP-FSTr had the prediction performance improved by 5.84% and 105.42% respectively on AEEEM dataset,enhanced by 5.25% and 85.97% respectively on NASA dataset, and its two-process feature selection is better than the single feature selection process. Experimental results show that the proposed CPDP-FSTr can achieve better prediction performance when the source project feature selection proportion and the target project labeled instance proportion are 60% and 20% respectively.
cross-project defect prediction; feature selection; Kernel Principal Component Analysis (KPCA); instance transfer; TrAdaBoost
TP311.5
A
1001-9081(2022)05-1554-09
10.11772/j.issn.1001-9081.2021050867
2021⁃05⁃25;
2022⁃01⁃24;
2022⁃02⁃18。
李莉(1977—),女,河南孟州人,副教授,博士,CCF会员,主要研究方向:先进软件工程、区块链、群智能优化、大型分布式计算; 石可欣(1997—),女,山东聊城人,硕士研究生,主要研究方向:软件缺陷预测; 任振康(1996—),男,山东青岛人,硕士研究生,主要研究方向:软件缺陷预测。
LI Li, born in 1977, Ph. D., associate professor. Her research interests include advanced software engineering, blockchain, swarm intelligence optimization, large-scale distributed computing.
SHI Kexin,born in 1997, M. S. candidate. Her research interests include software defect prediction.
REN Zhenkang, born in 1996, M. S. candidate. His research interests include software defect prediction.
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
金点子生意(2014年4期)2014-04-10
中学生英语高效课堂探究(2008年9期)2008-11-17
