
基于全局与局部标签关系的多标签图像分类方法
2022-06-21 06:39任炜白鹤翔
计算机应用 2022年5期
任炜,白鹤翔
(山西大学 计算机与信息技术学院,太原 030006)(∗通信作者电子邮箱2783800599@qq.com)
基于全局与局部标签关系的多标签图像分类方法
任炜*,白鹤翔
(山西大学 计算机与信息技术学院,太原 030006)(∗通信作者电子邮箱2783800599@qq.com)
针对多标签图像分类任务中存在的难以对标签间的相互作用建模和全局标签关系固化的问题,结合自注意力机制和知识蒸馏(KD)方法,提出了一种基于全局与局部标签关系的多标签图像分类方法(ML-GLLR)。首先,局部标签关系(LLR)模型使用卷积神经网络(CNN)、语义模块和双层自注意力(DLSA)模块对局部标签关系建模;然后,利用KD方法使LLR学习全局标签关系。在公开数据集MSCOCO2014和VOC2007上进行实验,LLR相较于基于图卷积神经网络多标签图像分类(ML-GCN)方法,在平均精度均值(mAP)上分别提高了0.8个百分点和0.6个百分点,ML-GLLR相较于LLR在mAP上分别进一步提高了0.2个百分点和1.3个百分点。实验结果表明,所提ML-GLLR不仅能对标签间的相互关系进行建模,也能避免全局标签关系固化的问题。
图像分类;自注意力机制;深度学习;知识蒸馏;多标签分类
0 引言
如何对不同标签之间存在的关系进行建模一直以来就是多标签分类尤其是多标签图像分类中的一个重要问题。以卷积神经网络(Convolutional Neural Network, CNN)[1-4]为例,在一些大型单标签图像数据集(例如ImageNet[5])上精度已能够达到90%以上[6]。然而,由于CNN独立对待目标,将多标签问题转化为一组二分类问题来预测每个目标是否存在,忽视了标签之间的依赖关系,因此很多相关研究发现其对多标签图像,例如数据集MSCOCO(MicroSoft Common Objects in COntext)2014[7]的分类精度通常仅有80%左右[2,8]。因此,对标签关系进行建模是提高多标签图像分类精度的关键。
基于循环神经网络(Recurrent Neural Network, RNN)的模型是目前多标签图像分类中最具代表性的一类方法[9-11]。Wang等[9]提出了使用RNN模型来对标签关系进行建模的卷积神经网络-循环神经网络(CNN-RNN)模型。这一模型使用CNN和RNN的联合嵌入空间来表征图像与语义结构。CNN-RNN模型保留了交叉标签相关性,提高了多标签分类精度。然而,在CNN-RNN训练时需要根据训练数据中各标签边缘概率来定义标签顺序。这种预定义的标签预测顺序可能错误地对标签依赖关系进行建模。例如,根据标签频率可能得到{餐桌,花,叉子},然而从语义的角度上,由于“餐桌”与“叉子”有更强的依赖关系,所以正确顺序应为{餐桌,叉子,花}。为了解决这一问题,Yazici等[11]提出了基于视觉注意力的长短期记忆(Long Short-Term Memory, LSTM)深度学习框架,通过引入视觉注意力模型来自动地学习标签顺序。然而这一模型仍然难以完全避免RNN模型自身的缺陷,即以序列方式逐个预测标签,同标签之间关系的双向性相矛盾,从而导致RNN模型无法完整地对标签之间关系进行建模。
此外,CNN-RNN模型仅关注每张图像自身的标签相关性,即局部标签关系(Local Label Relationship, LLR),忽略了整个数据集上的全局标签关系。为解决这一问题,Chen等[12]提出了基于图卷积网络(Graph Convolutional Network, GCN)的多标签图像分类(Multi-Label image classification based on GCN, ML-GCN)模型。这一模型在整个训练集上统计全局标签关系,利用GCN在全局标签关系的指导下建立多个标签之间的共现概率,进而在一定程度上提高多标签图像的分类精度。
图1是ML-GCN在多标签图像数据集VOC2007(PASCAL VOC challenge 2007)[13]上统计出的全局标签相关矩阵。在数据集的图像中与“人”这一标签具有较高共现概率的标签有很多,如“自行车”“马”和“摩托”。当图像中存在“人”“桌子”时,“椅子”可能存在被遮盖的情况从而导致漏标;但在全局标签关系中,因为“桌子”与“椅子”有较高的共现率,所以“椅子”会被标注出来。

图 1 VOC2007上的标签关系矩阵(未填写部分为0)Fig. 1 Label relation matrix on VOC2007 (0 for unfilled part)
虽然ML-GCN能够考虑全局标签的相关性,但由于该方法过度依赖标签共现概率,容易导致弱关系情况下缺标签和强关系情况下多标记的问题。
为解决上述两个多标签分类问题,本文提出了基于全局与局部标签关系的多标签图像分类方法(Multiple Label image classification method based on Global and Local Label Relationship, ML-GLLR)。该方法利用双层自注意力(Dual Layer Self-Attention, DLSA)来探索局部标签之间相互作用的关系;同时,用知识蒸馏(Knowledge Distillation, KD)对全局与局部的标签关系进行建模,并在两个公共数据集MSCOCO2014和VOC2007上进行了实验。
1 ML‑GLLR
ML-GLLR的框架如图2所示。该框架由两部分组成,分别为LLR模型和KD方法,其中LLR细分为传统分类器、语义模块、DLSA模块。首先,利用CNN提取图像特征,得到特征,为特征图的个数,、分别表示特征图的长和宽;接着,语义模块将按不同类别注意的区域在空间维度上加权求和得到标签特征,为总类别数,表示标签特征的维度;然后,经过DLSA以及DLSA分类器得到标签分布,与由经过传统分类器得到的标签分布进行加权平均操作,得到局部标签分布;最后,分别与真实标签分布和ML-GCN得到的全局标签分布进行知识蒸馏。

图2 ML-GLLR整体框架Fig. 2 Overall framework of ML-GLLR
1.1 语义模块
语义模块的目的是在预测期间聚焦和描述感兴趣的图像区域;同时,还可以将CNN模型得到的特征转化为标签特征,有利于DLSA模型计算标签关系。受文献[11,14]启发,使用用于图像字幕生成的软注意力的机制,将特征图表示成相应的标签特征,本文的语义模块也使用同样的机制。具体地,有:
不难发现,语义模块能充分利用注意力机制来粗略定位标签对应的区域,并根据注意力权重得到标签特征,隐式地利用了标签共现信息。在实验部分会展示和说明语义模块在多标签图像上的可视化结果及其作用。
1.2 DLSA模块
张小川等[15]利用自注意力机制学习文本序列内部的词依赖关系,提升了文本分类的精度。受此启发,本文利用DLSA机制对标签之间的依赖关系进行建模。DLSA模块由两个自注意力模块与标签关系矩阵组成。具体地,双层注意力模块分为三步。
第二步 使用C维的全连接层将映射并通过函数得到结果:
1.3 知识蒸馏与传统分类器
高钦泉等[16]针对目前用于超分辨率图像重建的深度学习网络模型结构深且计算复杂度高的问题,使用KD方法将知识从教师网络转移到学生网络,最后在不改变学生网络的网络结构及参数量的前提下提升学生网络的重建效果;邓棋等[17]通过KD方法,将训练好的“知识”提取到AlexNet模型中,从而实现了在减少系统资源占用的同时,提高准确率的效果。受此启发,本文将利用KD使DLSA在保留局部标签关系知识的同时学习ML-GCN的全局标签关系知识。
在1.2节中,DLSA的输出结果还无法进行知识蒸馏,需DLSA分类器与传统分类器结合。传统分类器分为两步:首先,对进行全局平均池化;然后,利用全连接层进行分类。传统分类器的标签分布计算式为:
KD方法是以ML-GCN作为教师模型,以LLR作为学生模型,计算式为:
2 实验与结果分析
2.1 评价指标
为了与现有方法进行公平比较,本文沿用文献[12,18]的评价指标,具体如下。
1)在类别上的准确率(CP)、召回率(CR)、F1分数(CF1);在总体上的准确率(OP)、召回率(OR)、F1分数(OF1),以及为每幅图像分配得分前3名的标签,即Top-3。
2)每个类别的平均精度(Average Precision, AP)。首先,遍历的索引(是从高到低的排序函数,是第类别的预测得分),每次遍历需要判断索引位置的真实标签是否存在,若存在则使用和统计数量(是第类别的真实标签),然后,按照式(12)计算;若不存在则只在统计数量。遍历结束后,第类别的准确率如式(13)所示。
3)所有类别的平均精度均值(mean Average Precision,mAP)。mAP是基于排序的度量,具体地:
2.2 实验设置
本文以深度残差网络为基线方法。首先,选用101层的残差网络(101-layer deep Residual network, Res-101)[3]提取特征;然后,经过池化、全连接层和函数来进行多标签图像分类。Res-101也是LLR的主干网络。在上述的训练过程中,数据预处理为:对输入图像进行随机裁剪并调整大小为长宽448的图像,然后随机水平翻转。优化器选择随机梯度下降(Stochastic Gradient Descent, SGD)法,其中学习率初始化为0.05,动量为0.9。特别地,本文方法LLR中主干网络Res-101的参数学习率初始化为0.005,其余参数为0.05。所有参数的学习率在训练至第20轮与第30轮时以0.1的倍率进行变化,一共训练40轮。批处理大小为16,损失函数使用二元交叉熵函数。ML-GCN以文献[12]的方式进行训练。训练方法完成后,使用训练好的LLR模型和ML-GCN模型,以式(9)为损失函数进行知识蒸馏。使用SGD为优化器,主干网络Res-101的参数学习率初始化为0.000 5,其余参数为0.005,动量为0.9。所有参数的学习率在训练至第5轮时以0.1的倍率变化,一共训练10轮。
2.3 数据集
本文实验使用MSCOCO2014[7]和VOC2007[13]这两个公共多标签图像数据集。数据集具体信息如下:
1)MSCOCO2014数据集包含12 218张图像,其中,训练集有82 081张图像,验证集有40 137张图像,共有80个类别,平均每张图像大约有2.9个标签。因此,MSCOCO2014常用于多标签图像分类。
2)VOC2007数据集包含9 963张图像,共有20个类别,它被分为训练集、验证集、测试集。本文将训练集和验证集合并为训练集。所以,训练集有5 011张图像,验证集有4 952张图像。
2.4 对比结果分析
将本文方法(ML-GLLR)分别与CNN-RNN、空间正则化网络(Spatial Regularization Network, SRN)[8]、Res-101、基于多特征过滤和融合(Multi-Evidence filtering and fusion,Multi-Evidence)[19]的分类方法、基于视觉注意的CNN-LSTM(CNN-LSTM based on visual Attention, CNN-LSTM-Att)[11]、ML-GCN[12]以及语义特定图表示学习(Semantic-Specific Graph Representation Learning, SSGRL)[18]在MSCOCO2014数据集上进行对比实验,其结果评估如表1所示。ALL下的6个指标是将分类结果按照阈值为0.5划分,高于0.5则标记为1,低于0.5则标记为0,然后使用式(10)~(11)计算;Top-3下的6个指标是直接将分类结果最高的3个标签标记为1,其余为0,然后再使用式(10)~(11)计算。
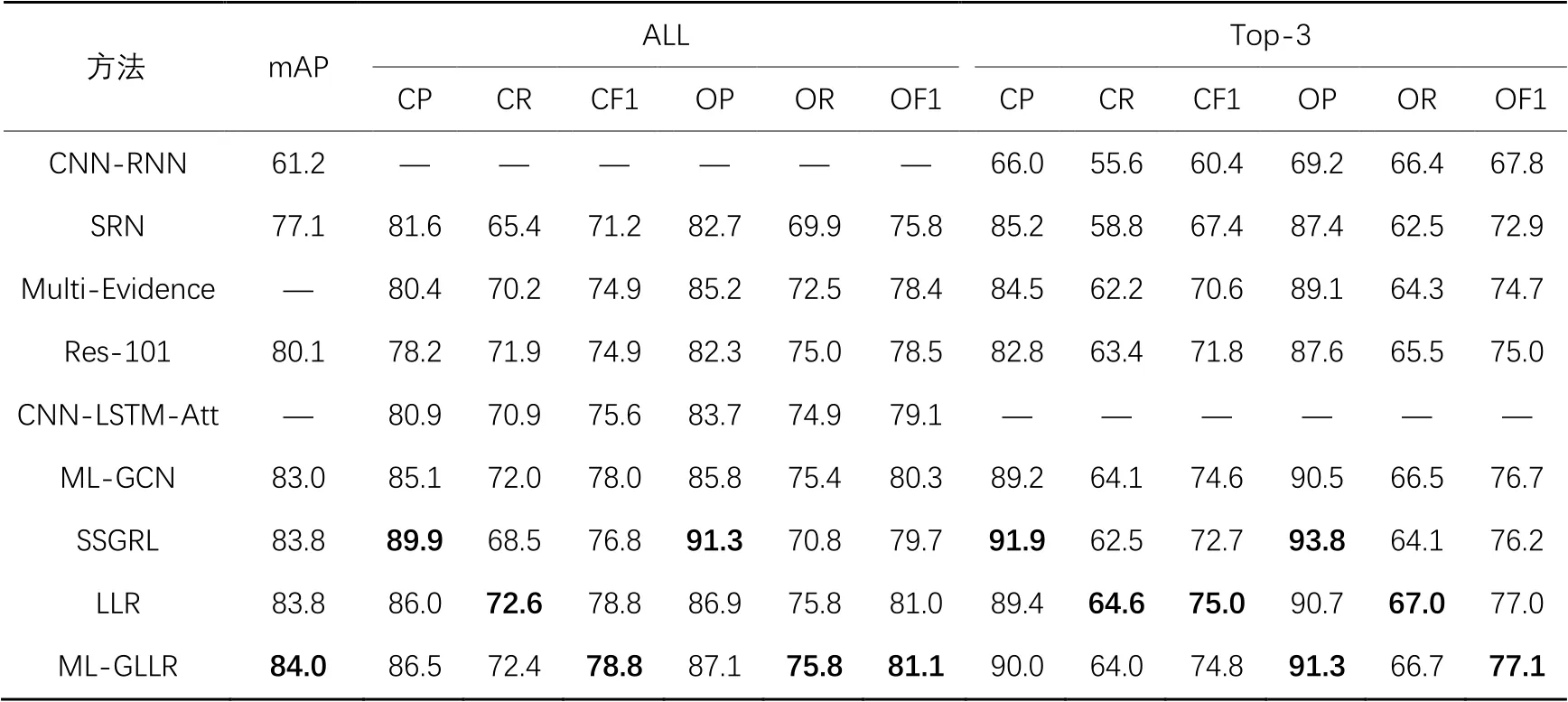
表1 不同方法在MSCOCO2014数据集上的评价指标对比 单位: %Tab. 1 Evaluation index comparison of different methods on MSCOCO2014 dataset unit: %
在MSCOCO2014数据集上,LLR相较于基线Res-101、ML-GCN模型,mAP分别提升了3.7、0.8个百分点,与SSGRL模型持平,都达到了83.8%;LLR相较于CNN-LSTM-Att、ML-GCN、SSGRL,OF1分别提升了1.9、0.7、1.3个百分点,CF1分别提高了3.2、0.8、2.0个百分点。当进行知识蒸馏后,考虑全局与局部标签关系的ML-GLLR模型,其mAP可以达到84.0%,比其他方法更优。
将本文方法(ML-GLLR)分别与CNN-RNN、区域潜在语义相关性(Regional Latent Semantic Dependencies, RLSD)[20]、VGG(Visual Geometry Group)[2]、HCP(Hypothesis CNN Pooling)[21]、Res-101、ML-GCN和SSGRL在VOC2007数据集上进行对比实验,其结果评估如表2所示。
与Res-101、ML-GCN相比,LLR的mAP分别提升了2.7、0.6个百分点。当充分考虑全局与局部标签关系时,与ML-GCN、SSGRL、LLR相比,文本ML-GLLR的mAP分别提升了1.9、0.9、1.3个百分点。
对于各类AP,如“沙发”,ML-GCN的AP只有84.3%,而LLR达到了88.4%。通过KD方法,对ML-GCN全局标签关系进行学习,LLR在局部标签关系与全局标签关系之间达到了一定的平衡,“沙发”类别的AP达到90.7%,类似的类别还有“植物”和“桌子”等。所以,实验结果可以表明,利用KD结合全局与局部标签关系在多标签图像分类中是有效的。
2.5 网络消融分析
本文所提ML-GLLR包含三个消融因素:语义模块、DLSA模块、KD模块。为了验证ML-GLLR的有效性,在数据集MSCOCO2014和VOC2007上,采用如下的方式进行消融实验:1)采用Res-101和维的全连接层(分类器)结合的网络结构作为基准网络;2)在LLR的基础上,去除DLSA模块,保留语义模块;3)在LLR的基础上,使用两个全连接层替代语义模块,保留DLSA模块;4)LLR,只考虑局部标签关系的方法;5)ML-GLLR,结合全局与局部标签关系的方法。表3给出了上述五种方法的预测精度。其中,T-OF1和T-CF1表示Top-3下的OF1和CF1指标;A-OF1和A-CF1表示ALL下的OF1和CF1指标。

表2 不同方法在VOC2007数据集上各标签的结果对比 单位: %Tab. 2 Comparison of results in various labels on VOC2007 dataset with different methods unit: %
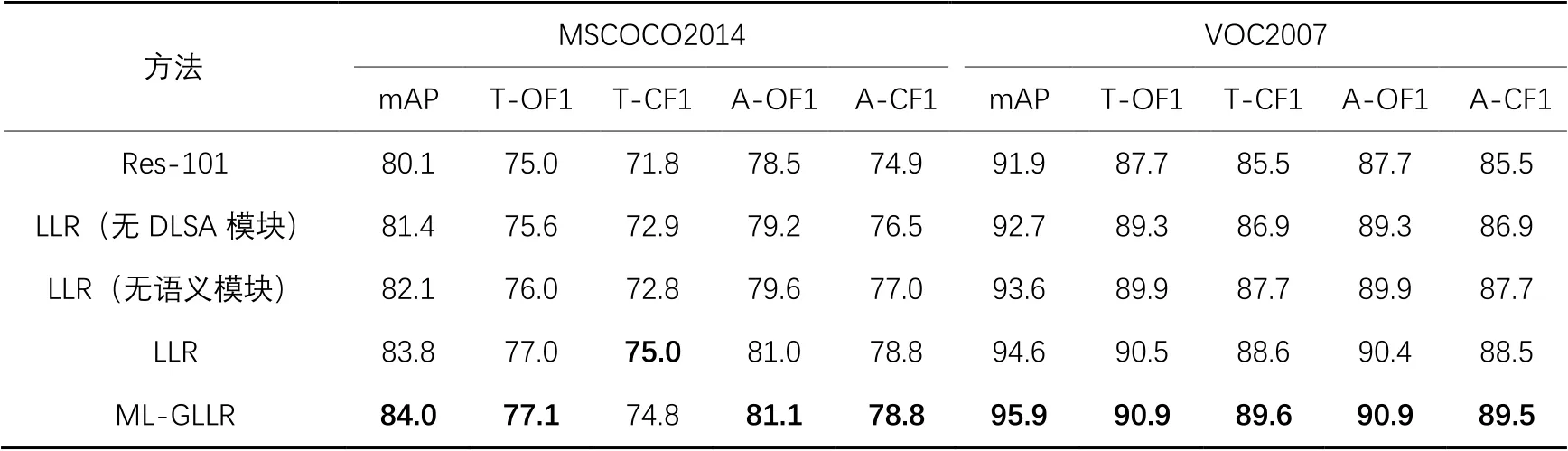
表3 消融实验结果 单位: %Tab. 3 Ablation experimental results unit: %
2.5.1 语义模块的作用
语义模块可以使CNN模型得到的特征图按权重进行加权求和,该权重表示各个标签在图像中所注意的区域。图3(a)、(e)是MSCOCO2014的测试集样本COCO_val_476534和COCO_val_473994,图3(b)、(c)、(d)和(f)、(g)、(h)分别展示了图3(a)、(e)在语义模块中注意到的区域(高亮区域)。对于2个样本的所有真实标签(猫、遥控器、沙发、人、狗、飞碟),LLR都预测正确。图3(a)中,“遥控器”“猫”“沙发”能分别与图中较亮的区域一一对应,这些区域都有着较高的权重,标签特征就是以这些权重对CNN特征图在空间维度上加权求和得到的。

图3 语义模块可视化Fig. 3 Semantic module visualization
由表3可知,当LLR去除语义模块后,LLR的mAP在MSCOCO2014数据集上从83.8%下降到82.1%,在VOC2007数据集上从94.6%下降到93.6%,表明了语义模块对后续标签关系学习的有效性。
2.5.2 DLSA模块与KD模块的作用
DLSA模块用于探索局部标签关系。由表1、2可知,在两个数据集上,含DLSA模块的LLR和ML-GLLR各项分类指标都优于ML-GCN和CNN-LSTM-Att:与CNN-LSTM-Att相比,LLR可以充分考虑标签之间的相互作用关系;与ML-GCN相比,DLSA模块从局部上考虑标签相关性。图4中,斜体下划线为模型预测结果中缺失的标签,斜体下划线加粗为多余标签。在图4(a)中,“猫”“植物”与其他标签的共现率都很低,因此有这两个标签时,ML-GCN会忽略“瓶子”。在图4(b)中,“人”和“电视机”都与“沙发”有较高的共现率,从而导致ML-GCN标记了不存在的“沙发”。但DLSA模块在图4(a)中标记出了“瓶子”,在图4(b)中没有标记“沙发”,所以,DLSA模块在一定程度上防止了漏标和多标记的问题。

图4 多标签图像分类中ML-GCN与ML-GLLR比较Fig. 4 Comparison of ML-GCN and ML-GLLR in multi-label image classification
此外,由表3可知,当LLR无DLSA模块时,在MSCOCO2014数据集上mAP只能达到81.4%,在VOC2007上mAP只能达到92.7%,验证了DLSA模块的有效性。
事实上,无论是从局部上还是从全局上考虑标签关系,它们都存在一定的局限性。例如,图5是VOC2007中的两个样本图像在ML-GCN、LLR和ML-GLLR中的分类结果。LLR只能识别出图5(a)中的“椅子”“植物”以及图5(b)中的“人”“牛”,这是因为LLR相较于ML-GCN更依赖CNN提取的特征,更重要的是缺乏全局标签关系上的考虑。
图6是图5的图像在不同模型下的标签关系矩阵(由式(5)得到)。经过知识蒸馏后,在图6(a)、(c)中,当存在“椅子”“植物”时,这两个标签与“沙发”的共现率从59.3%、60.1%变化至66.6%、66.3%;在图6(b)、(d)中,当存在“牛”“人”时,与“马”的共现率从64.5%、57.7%变化至64%、61.8%。这使得LLR在图5(a)中识别出“沙发”,在图5(b)中识别出“马”。

图5 多标签图像分类中ML-GCN、LLR与ML-GLLR比较Fig. 5 Comparison of ML-GCN, LLR and ML-GLLR in multi-label image classification

图6 LLR经过知识蒸馏后标签关系的变化Fig. 6 Change of LLR label relationships after knowledge distillation
同样在图1中也可以发现“椅子”“植物”都与“沙发”的共现率高,“人”“牛”都与“马”的共现率高。这表明LLR通过知识蒸馏学习到了全局标签关系,验证了基于知识蒸馏来实现全局与局部关系信息的结合是有效的。
此外,经过知识蒸馏后的LLR在不少类别之间的共现率发生显著变化。图7、8分别是VOC_val_0986图像中类别“人”与其他类别、类别“牛”与其他类别在LLR和ML-GLLR上的共现率。
不难发现,虽然在图7中“人”与其他类别在经过知识蒸馏后共现率都有提高,但在图9中很多类别却不会被标记。这是因为,式(8)中局部标签分布与传统分类器的标签分布相关,而传统分类器是对图像内容的基本分类,正如图9中的LLR在各个类别的得分,除了类别“马”处于被发现的临界值外,其他类别得分都很低,所以即使提升了共现率也无法标记。KD的目的是使LLR学习全局标签关系(如图1中的标签关系),所以图7中“人”与其他类别的共现率经过KD后都有提升的趋势,而图8中“牛”与其他类别的共现率变化却很难发现规律。这是因为图6中标签关系都是LLR根据每一个样本的特征计算出来的,不是固化的全局标签关系。虽然LLR通过知识蒸馏处理全局标签关系,但它不会完全地拟合全局标签关系,一定程度上也需要考虑样本自身标签关系的内部联系,避免出现强标记的问题。

图7 VOC_val_0986中类别“人”与其他类别的共现率Fig. 7 Co-occurrence rate of category “people” and other categories in VOC_val_0986

图8 VOC_val_0986中类别“牛”与其他类别的共现率Fig. 8 Co-occurrence rate of category “cattle” and other categories in VOC_val_0986

图9 VOC_val_0986中各个类别在LLR和ML-GLLR模型的得分Fig. 9 Scores of each category of VOC_val_0986 in LLR and ML-GLLR models
本文方法的不足之处是语义模块。CNN得到的特征在经过语义模块表示为各个类别特征后,一些类别可能会包含其他类别的信息,如图3(h)除飞碟区域有很高的注意程度外,对人的区域也有少量的注意程度,这表明语义模块得到的特征向量不能十分准确地表达各个类别信息,这可能会对标签关系的判断造成一定的干扰。所以,对于该问题还需进一步的研究。
3 结语
标签关系的挖掘是多标签图像分类的关键问题之一,本文提出了基于全局与局部标签关系的多标签图像分类方法(ML-GLLR)。该方法利用DLSA对样本内部的标签关系即局部上的标签关系进行建模,又通过知识蒸馏充分考虑全局上与局部上的标签关系。在两个公共数据集MSCOCO2014和VOC2007上的实验结果表明,所提方法的性能优于其他对比方法。但本文所提方法也存在一些问题:首先,不是端到端的训练方法,需要进行多次训练,导致实用性差;语义模块对图像中各类的注意区域存在重合问题,可能会影响最后的判断。所以,如何将模型构建成端到端的训练方法以及消除各类别的注意区域重合问题是接下来的研究重点。
[1] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]// Proceedings of the 2012 25th International Conference on Neural Information Processing Systems. Red Hook: Curran Associates Inc., 2012: 1097-1105.
[2] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. [2021-03-15]. https://arxiv.org/pdf/1409.1556.pdf
[3] HE K M, ZHANG X Y, REN S Q, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2016: 770-778.
[4] 刘尚旺,郜翔.基于深度模型迁移的细粒度图像分类方法[J].计算机应用,2018,38(8):2198-2204.(LIU S W, GAO X. Fine-grained image classification method based on deep model transfer [J]. Journal of Computer Applications, 2018, 38(8): 2198-2204.)
[5] DENG J, DONG W, SOCHER R, et al. ImageNet: a large-scale hierarchical image database [C]// Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2009: 248-255.
[6] PHAM H, DAI Z H, XIE Q Z, et al. Meta pseudo labels [C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021:11552-11563.
[7] LIN T Y, MAIRE M, BELONGIE S, et al. Microsoft COCO: common objects in context [C]// Proceedings of the 2014 European Conference on Computer Vision, LNCS 8693. Cham: Springer, 2014: 740-755.
[8] ZHU F, LI H S, OUYANG W L, et al. Learning spatial regularization with image-level supervisions for multi-label image classification [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE,2017: 2027-2036.
[9] WANG J, YANG Y, MAO J H, et al. CNN-RNN: a unified framework for multi-label image classification [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE, 2016: 2285-2294.
[10] CHEN S F, CHEN Y C, YEH C K, et al. Order-free RNN with visual attention for multi-label classification [C]// Proceedings of the 2018 32nd AAAI Conference on Artificial Intelligence. Palo Alto: AAAI Press, 2018: 6714-6721.
[11] YAZICI V O,GONZALEZ-GARCIA A, RAMISA A, et al. Orderless recurrent models for multi-label classification [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020:13437-13446.
[12] CHEN Z M, WEI X S, WANG P, et al. Multi-label image recognition with graph convolutional networks [C]// Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2019: 5172-5181.
[13] EVERINGHAM M, GOOL VAN L, WILLIAMS C K I, et al. The PASCAL Visual Object Classes (VOC) challenge [J]. International Journal of Computer Vision, 2010, 88(2):303-338.
[14] XU K, BA J L, KIROS R, et al. Show, attend and tell: neural image caption generation with visual attention [C]// Proceedings of the 2015 32nd International Conference on Machine Learning. New York: JMLR.org,2015: 2048-2057.
[15] 张小川,戴旭尧,刘璐,等.融合多头自注意力机制的中文短文本分类模型[J].计算机应用,2020,40(12):3485-3489.(ZHANG X C, DAI X Y,LIU L, et al. Chinese short text classification model with multi-head self-attention mechanism [J]. Journal of Computer Applications, 2020, 40(12): 3485-3489.)
[16] 高钦泉,赵岩,李根,等.基于知识蒸馏的超分辨率卷积神经网络压缩方法[J].计算机应用,2019,39(10):2802-2808.(GAO Q Q, ZHAO Y, LI G, et al. Compression method of super-resolution convolutional neural network based on knowledge distillation [J]. Journal of Computer Applications, 2019, 39(10): 2802-2808.)
[17] 邓棋,雷印杰,田锋.用于肺炎图像分类的优化卷积神经网络方法[J].计算机应用,2020,40(1):71-76.(DENG Q, LEI Y J,TIAN F. Optimized convolutional neural network method for classification of pneumonia images [J]. Journal of Computer Applications, 2020,40(1): 71-76.)
[18] CHEN T S, XU M X, HUI X L, et al. Learning semantic-specific graph representation for multi-label image recognition [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019:522-531.
[19] GE W F, YANG S B, YU Y Z. Multi-evidence filtering and fusion for multi-label classification, object detection and semantic segmentation based on weakly supervised learning [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 1277-1286.
[20] ZHANG J J, WU Q, SHEN C H, et al. Multilabel image classification with regional latent semantic dependencies [J]. IEEE Transactions on Multimedia, 2018, 20(10): 2801-2813.
[21] WEI Y C, XIA W, LIN M, et al. HCP:a flexible CNN framework for multi-label image classification [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016,38(9): 1901-1907.
Multi-label image classification method based on global and local label relationship
REN Wei*, BAI Hexiang
(School of Computer and Information Technology,Shanxi University,Taiyuan Shanxi030006,China)
Considering the difficulty of modeling the interaction between labels and solidification of global label relationship in multi-label image classification tasks, a new Multiple-Label image classification method based on Global and Local Label Relationship (ML-GLLR) was proposed by combining self-attention mechanism and Knowledge Distillation (KD) method. Firstly,Convolutional Neural Network (CNN), semantic module and Dual Layer Self-Attention (DLSA) module were used by the Local Label Relationship (LLR) model to model local label relationship. Then, the KD method was used to make LLR learn global label relationship. The experimental results on the public datasets of MicroSoft Common Objects in COntext (MSCOCO) 2014 and PASCAL VOC challenge 2007 (VOC2007) show that,LLR improves the mean Average Precision (mAP) by 0.8 percentage points and 0.6 percentage points compared with Multiple Label classification based on Graph Convolutional Network (ML-GCN) respectively, and the proposed ML-GLLR increases the mAP by 0.2 percentage points and 1.3 percentage points compared with LLR. Experimental results show that, the proposed ML-GLLR can not only model the interaction between labels, but also avoid the problem of global label relationship solidification.
image classification; self-attention mechanism; deep learning; knowledge distillation; multi-label classification
TP391.4
A
1001-9081(2022)05-1383-08
10.11772/j.issn.1001-9081.2021071240
2021⁃07⁃16;
2021⁃08⁃31;
2021⁃09⁃14。
国家自然科学基金资助项目(41871286)。
任炜(1996—),男,山西襄汾人,硕士研究生,主要研究方向:深度学习、计算机视觉; 白鹤翔(1980—),男,山西榆次人,副教授,博士,主要研究方向:机器学习、数据挖掘。
This work is partially supported by National Natural Science Foundation of China (41871286).
REN Wei, born in 1996,M. S. candidate. His research interests include deep learning, computer vision.
BAI Hexiang, born in 1980,Ph. D., associate professor. His research interests include machine learning, data mining.
猜你喜欢
中国医院院长(2022年13期)2022-08-15
少儿画王(3-6岁)(2020年4期)2020-09-13
金桥(2018年4期)2018-09-26
东方教育(2018年20期)2018-08-22
感悟(2016年8期)2016-05-14
长江学术(2015年1期)2015-02-27
当代贵州(2014年13期)2014-09-21
微型计算机(2009年4期)2009-12-23
