
人机结合校对模式在图书校对中的应用研究
2022-06-20 03:39梁晓
中国传媒科技 2022年6期
梁 晓
(河南文艺出版社,河南 郑州 450016)
导语
随着时代的发展,信息技术不断升级,其可以借助计算机实现对校对工作经验的系统分析和整理,通过挖掘其中存在的内在规律,实现对校对重点以及校对内容的快速累积,这种技术的出现也颠覆了传统校对模式。[1-3]对出版社而言,这种智能化的校对方法在极大程度上提高了校对的效率。但是值得关注的是,计算机实现较多地是建立在对学科基础知识了解和掌握的基础之上的。[4-5]通过深度学习校对的资料,实现对校对信息的更新,单纯地依靠计算机完成校对工作并不能达到预期的校对标准。除此之外,随着校对工作要求的改变,一些校对规则也在不断发生着变化,机器学习的计算机校对是无法通过自主方式实现更新的,此时就需求人为对校对规则进行修改。由此不难看出,人工校对仍然是校对工作中不可或缺的重要组成部分。[6-7]
为此,本文提出了关于人机结合校对模式在图书校对中的应用研究,利用计算机强大的学习能力以及人工对校对问题判定的可靠性,实现可靠的校对。本文通过试验测试对设计方法的有效性进行了验证。通过本文的研究,以期为现代校对工作的开展提供帮助。
1.基于人机结合的图书校对模式设计
1.1 校对问题分解处理
利用人机结合的方式开展图书校对工作之前,考虑到校对涉及语句逻辑、字词正误、专业术语使用等多项内容。为此,本文首先对校对工作进行分解,将复杂多样的校对任务分解为多个单一的任务。对于问题的分解,本文对分解函数进行了一定的调整,利用静态分解策略实现对其的优化。将每一个校对任务作为变量,以每个变量为目标,建立与之对应的子种群,其中,每个子种群中包含所属校对任务中的所有校对信息。[8]其具体的分解方式为

其中,Xi表示分解后的一个种群,b表示校对任务自身的属性,p表示校对任务的重要性,q表示校对任务的目标属性。Sim(*)表示分解参考指标的相似性。但是需要注意的是,对任务进行分解时,要将分解粒度控制在合理范围内,一旦分解粒度过大,可能会导致最终的校对结果中漏检问题较为严重;而当分解粒度过小时,可能会出现相同问题重复校对的问题,影响最终的校对效率。为此,本文设置分解粒度大小为0.50。以此为基础,即可以得到i个独立的校对任务。[9]
以此为基础,将复杂的校对工作分解为多个简单的独立任务,为后续的工作提供更加简单的计算环境。
1.2 任务间协作机制的构建
首先,对各子群体中的子问题耦合性进行统一,将各个子问题作为独立的优化问题,此时对其的求解方式可以表示为

其中,λ表示各子群体中子问题的关联系数,f表示校对资源所占的比例,表示子群中的独立个子问题,分别表示子问题自身的属性、重要性以及对λ应校对目标的属性。通过这样的方式,就可以得到优化后的校对任务。而在实际校对工作中,许多问题不仅仅是以单纯的竞争关系存在的,又包含协同关系。因此,本文基于协同进化算法,对优化后的子任务种群的全局平衡状态进行设置。[10]假设在子种群中的个体对校对工作其余所有任务的适应度评价为a,通过逐个分析,即可得到所有子种群中选择合作个体,并组成一个完整解。

其中,ai表示xi子种群中个体对其余校对任务的适应度评价结果。通过这样的方式,构建出一个包含协作机制的校对任务体系,为后续的校对工作提供执行依据。
1.3 校对信息更新
通过上文不难看出,以计算机为基础的校对主要是以知识储备为基础开展的,而要确保计算机的校对效果,对每个任务子群的信息库进行及时有效的更新是极为重要的环节。[11]为此本文将经过校对后的文本信息以修订模式重新输入到计算机中,利用机器学习对其修改的内容进行深度学习,并与原有的信息库进行比对。当信息库中原有的校正信息在输入文本中未体现,或原信息库中没有的信息在输入文本中有体现时,则将其作为待判定问题二次数次输出,通过人工确认的方式对其修改的准确性进行最终确认。[12]计算机采集到最终的校对结果后,将该类信息作为校对信息库的备用补充。当再次出现该类问题时,以差异化的标注形式对其进行标记,同样通过人工确认的方式对其进行判定。当该类问题的判定结果相同次数达到信息库修改的目标值时,则做出对应的添加或删除处理。其具体的实现流程如图1所示。
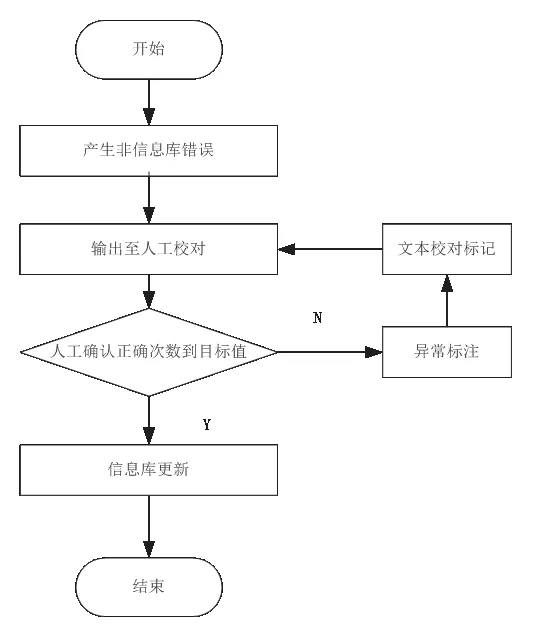
图1 计算机校对信息库更新流程
按照图1所示的方式,确保计算机对校对内容的判定能够按照校对要求的变化而做出调整,确保校对的可靠性。
1.4 基于人机结合的校对
首先,将待校对的资料信息输入到计算机系统中,分别以上文建立的校对任务体系中的单一任务为目标,对文本信息进行匹配,当完成所有任务的执行后,对匹配度达到判定要求的问题,直接通过计算机对其进行修改及标注。在此过程中,匹配的方式为

其中,Wi表)示待校对文本信息。
对判定标准的设置,由于不同文本类型的校对重点存在一定差异,因此结合实际情况,本文将单一校验任务的匹配度结果与整体校验任务的匹配度结果的比值作为判定标准,以此为基础,对判定标准的设置值如表1所示。
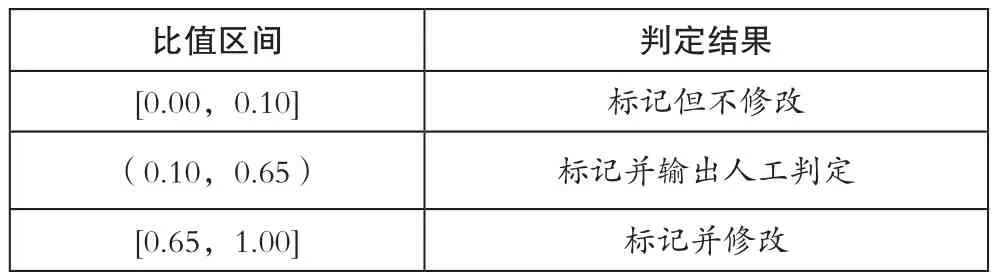
表1 校对判定标准
按照表1 的标准,将取值区间为[0.65,1.00]的校对内容直接利用计算机进行修改。通过这样的方式即可通过计算机完成对文本65%校对问题的修改;将取值区间为[0.00,0.10]的校对内容做简单标记,并进行单独处理;对无法确认是否存在问题,或者无法明确修改后信息的问题,通过人工校对的方式对其进行判断。最终将校对后的文本再次以标记的形式输入到计算机中,作为机器学习的目标,为信息库的更新提供数据基础。
2.应用测试
2.1 测试环境设计
由于本文设计的校对方法是以人机结合为基础实现的,因此需要计算机设备的支持,在测试过程中,本文采用的数据库服务器型号为Sqlserver 2019,对应的应用服务器搭载的操作系统版本为Windows Server 2020,服务器端的具体运行环境为6.0GHZ,CPU大小为1G,系统运行的网络环境为TCP/IP 。
2.2 测试目的设计
为了全方位测试本文设计的人机结合校对模式的应用效果,本文首先在测试图书馆内部用专网软硬件网络环境下搭建了具体的测试环境,通过构建一个完整且真实的测试环境,为测试结果的可靠性提供保障。在此基础上分别在社会学科、自然学科、实验学科、计算机学科、建筑学科以及设计学科抽选测试数据,以此为基础实施具体的测试任务。根据测试计划,本文在对校对资料类别和种类进行选择时,尽可能以多样化为目标,以此为基础,形成了最终的测试用文档数据。考虑到需校对结果的统计需要采集完整的未校对的错误信息,因此本文进行此次测试的主要目标是判断人机结合校对是否都能够满足图书馆在资料校对业务方面提出的要求。按照现阶段普遍使用的标准,本文将对校对准确率达到 90%以上作为合格标准的正确率。
2.3 测试范围设计
本文的测试工作范围包括资料的共享性、字词句一致性错误、专业术语使用错误、资料内容引用错误4项,为便于统计,分别记为①②③④。以此为基础,测试中选用的实验数据具体设置如表2所示。
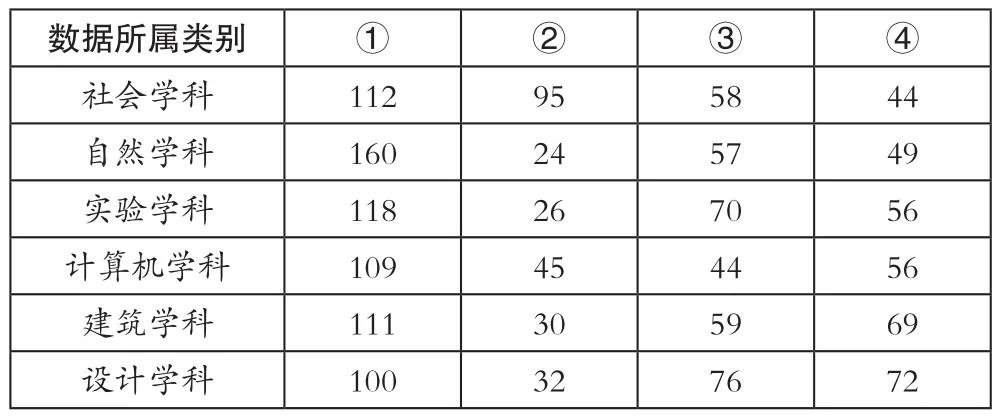
表2 实验数据准备
2.4 测试结果
在上述基础上,利用文献单一计算机校对和单一人工校对的方法作为对照组,分别对测试数据进行校对,并统计了3种方法的校对结果,其中未检出的文本作为数据如表3所示。
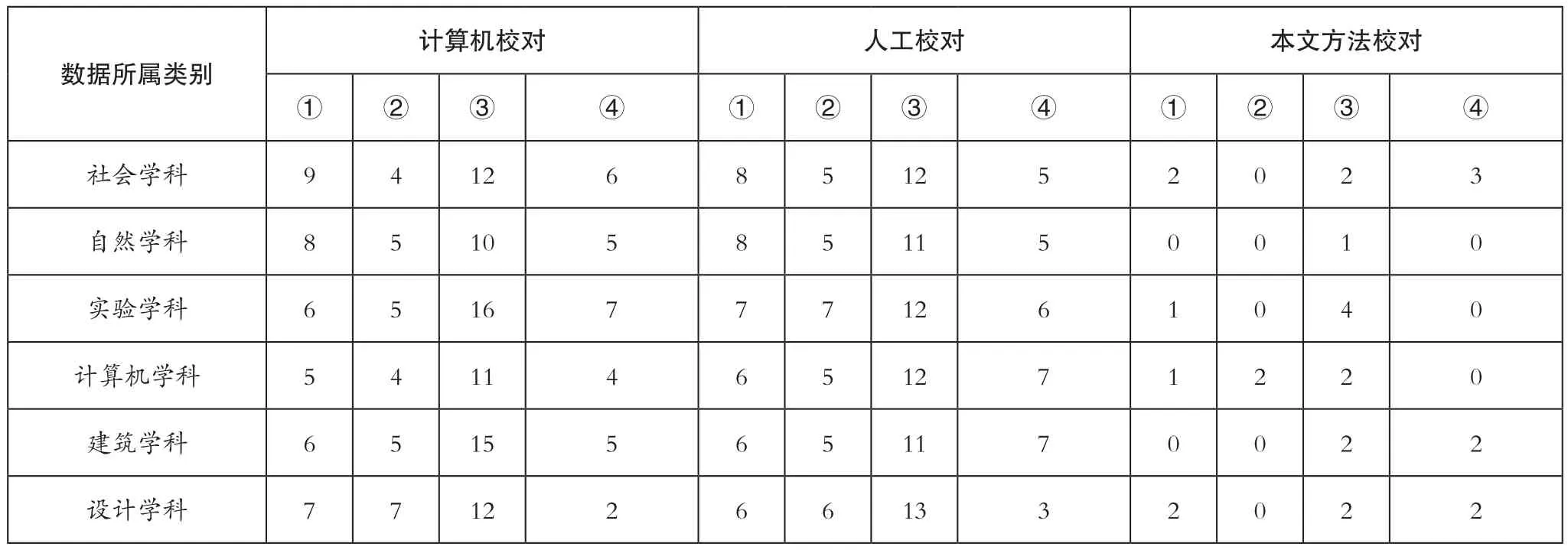
表3 校对结果统计表
通过对比表3数据不难看出,单一计算机校对和人工校对对资料业务逻辑错误和专业术语使用规范错误的漏检率相对较高,相比之下,本文方法对6种错误的漏检个数始终低于5个。特别是对字词句一致性错误的校对,其检出率达到了100%。整体测试结果中,检出率最低的内容为实验学科中在专业术语使用规范上存在的错误,但其检出率也达到了94.29%,远高于校对准确率 90.00%的合格要求。表明本文设计的校对方法可以实现对资料中错误的准确识别。
结语
图书出版后,其产生影响的范围是巨大的,且产生的影响是不可逆转的。因此,无论是从学术研究的角度,还是从出版需求的角度,在出版前对资料进行有效的校对是十分重要的环节之一。一方面,考虑出版刊物对时间的要求,另一方面,考虑出版社对校对效率的要求,如何实现高效准确的校对成为出版行业关注的重点问题。本文就人机结合技术在图书校对中的应用展开研究,实现对错误的有效检出。通过本文的研究,也希望为相关工作的开展提供有价值的参考,实现快速、准确的资料校对。
猜你喜欢
今日农业(2022年15期)2022-09-20
青少年科技博览(中学版)(2022年6期)2022-08-31
南都周刊(2021年3期)2021-04-22
湖南电力(2021年1期)2021-04-13
新生代(2018年16期)2018-11-13
中学生物学(2018年8期)2018-03-01
电脑知识与技术(2016年31期)2017-02-27
海外星云(2016年7期)2016-12-01
太空探索(2016年5期)2016-07-12
中学生物学(2008年6期)2008-08-29
