
基于3 类属性预测颈动脉斑块的随机森林方法研究
2022-06-18 07:17:16李建敦蒋坷宏蒋伏松郑西川
医疗卫生装备 2022年5期
李建敦,蒋 鹏,李 桃,陈 霆,蒋坷宏,蒋伏松*,郑西川,魏 丽
(1.上海电机学院电子信息学院,上海 201306;2.上海交通大学附属第六人民医院计算机中心,上海 200233;3.上海交通大学附属第六人民医院内分泌代谢科,上海 200233)
0 引言
颈动脉斑块(carotid plaque,CP),特别是易损斑块(vulnerable plaque,VP),是典型的糖尿病并发症,也是心血管疾病的重要根源之一,每年在世界范围内约造成1 770 万人死亡(约占所有病因的30%)[1]。因此,对于医院的内分泌代谢科来讲,CP 的早期诊断至关重要。临床上,B 超成像以其非侵入性和较高精度而被广泛采用,是事实上的黄金标准。考虑到经验丰富的B 超医师(也包括超声系统)数量有限,无法满足日益增多的疑似CP 的检测需求,获得准确的诊断结果仍然费时费力,因此这一黄金标准的大规模推广存在明显局限性,急需简单且高效的辅助诊断方法。临床研究显示,许多常规体检指标与CP密切相关,如年龄、性别、高血压、吸烟、肥胖、血糖、高密度脂蛋白(HDL)、低密度脂蛋白(LDL)、高同型半胱氨酸(Hcy)、血脂(LP)等[1-3]。相关研究同时表明,糖尿病和非酒精性脂肪肝(non-alcoholic fatty liver disease,NAFLD)可作为2 个独立指标来预测健康人群中的CP[4-5]。此外,作为血糖状态的一个指标,糖化血红蛋白(HbA1c)被证明与无糖尿病人群中的CP有关[6]。本文以上海交通大学附属第六人民医院的脱敏数据集为基础,开展内分泌状态与CP 相关性的实例研究,目的是利用尽可能少的常规体检指标和糖尿病相关指标来建立一个CP 的辅助预测模型。
1 数据集
本文基于2012—2018 年上海交通大学附属第六人民医院5 993 例糖尿病患者的脱敏数据开展案例研究。根据已有的研究成果[1-2,4-6],聚焦其中的10个属性来训练分类判别模型,包括性别、年龄、糖尿病病程、甘油三酯(TG)、LDL、HDL、总胆固醇(TC)、空腹血糖(FPG)、HbA1c、空腹胰岛素(FINS)。表1 从均值±标准差、最小值、最大值几个方面统计描述了其中的9 个属性(不包括性别)。

表1 数据集的9 个属性的基本数据
目前,世界卫生组织公布的糖尿病诊断标准有FPG≥7.0 mmol/L 和HbA1c≥6.5%,而CP 则以B 型超声作为金标准。在预处理方面,首先将年龄(18~78岁)离散化为7 个等宽(宽度为10 a)的数据段,然后使用最小-最大算法(min-max 算法)对其余属性进行归一化。此外,根据诊断结果对这些病例数据进行平衡,以避免标签比例对模型精度造成影响。
2 建模与预测
在传统机器学习模型如线性回归、逻辑回归、支持向量机、决策树等[1,7]的基础上,本研究采用更多的监督模型来拟合5 993 例脱敏数据,即将性别、年龄等10 个属性作为特征、5 993 个病例作为监督数据输入至单一规则、随机森林(random forest,RF)[8]等17个不同的机器学习模型中,并以CP 的分类预测为目标来训练参数(如图1 所示)。其中,17 个模型皆由Weka(v3.8)软件构建[9],结果经十折交叉验证得出。结果显示,不同模型在CP 预测上的性能差异明显,其中自助聚合(bootstrap aggregating,Bagging)[10]和RF 2 个模型在F1 值、AUC、查全率、查准率方面均优于其他模型,而RF 模型优势最明显(查准率为0.808,查全率为0.806,F1 值为0.805,AUC 为0.897)。

图1 多种监督模型的性能比较
作为一种集成学习模型,Bagging 模型可综合利用多个单分类器的判别结果,具体包括3 个步骤。
第1 步:采用有放回抽样的方式建立m 个子集。
第2 步:应用决策树模型为每个子集训练1 个分类器。
第3 步:在CP 预测中,给定病例的预测结果由各个分类器投票产生,规则是少数服从多数,即选择多数分类器得出的结果作为最终的预测结果。
RF 也是一个集成学习模型[11],因性能高、可用性好,在多个应用领域广受欢迎。一般来说,训练1个RF 模型需要4 个步骤,其中的阈值可根据已有的研究和经验来设定。
第1 步:采用有放回抽样的方式抽样n 次(n 为训练集规模)。

第3 步:循环执行前2 步k(k=10)次。
第4 步:基于投票法来汇总所有决策树的预测结果。规则是少数服从多数,即选择多数分类器得出的结果作为最终的预测结果。
Bagging 和RF 2 个模型在性能上优于其他模型的原因主要有:(1)较完整地维护了属性间不完全独立的事实。相比之下,基于独立性假设的其他机器学习模型未能遵从这一事实,导致性能较差,如朴素贝叶斯模型。(2)都属于集成学习模型,其有效利用了多个弱分类器协同决策的优势,因此性能较高。RF模型性能卓越的原因主要在于节点处的最优分割加入了随机化,即从全部属性中随机选取d 个属性,分别按照它们的属性值将病例分类,计算并比较划分之后的信息增益,最后选择得到最大信息增益的属性,从而确定当前节点的最优分割。同时,考虑到RF模型优良的并行性,本文拟采用RF 模型对病例数据进行拟合,以实现CP 的预测和临床预检。
3 特征选择
根据在RF 模型中各属性(10 个)对CP 预测的贡献度进行排序。理论上,一个属性的重要性可通过其在所有决策树上的平均不纯度减少值来量化,也可通过变量重要性度量(variable importance measures,VIM)来完成,即通过GI 来量化[12]。决策树i 上节点m的GI 为
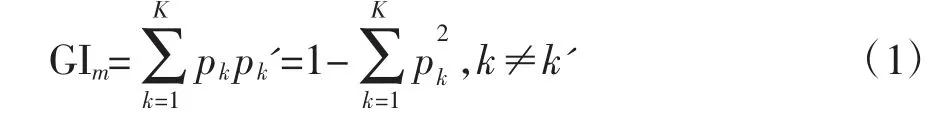
式中,K 为总类数;pk为节点m 上第k 个类的份额。实际上,GIm可通过节点m 中源于不同类别的2 个样本的概率来计算。基于此,属性j 对节点m 的重要性可用公式(2)来度量:

式中,GIx和GIy是从节点m 派生出来的节点对应的GI。此外,可以累计属性j 占主角的所有树和节点来计算VIMj。在算法实现上,使用Python(v3.6)软件和Sklearn 模块[13]来实现属性重要性排序,结果如图2所示。
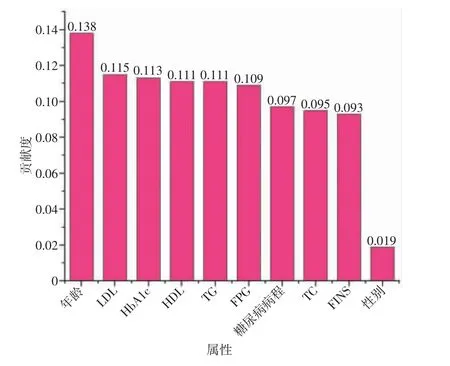
图2 属性重要性排序
根据排序持续压缩属性集,以找到一个最佳的属性子集,从而从5 993 例糖尿病患者中发现CP。压缩属性集的具体步骤是:首先删除重要性最低的性别特征,将剩余特征及对应数据输入至RF 分类器进行训练与验证;然后删除FINS 属性再进行分类预测,直到基于单一属性完成实验,结果如图3 所示。鉴于0.75 通常被认为是计算机辅助诊断的经验阈值,可以得出如下结论:年龄、LDL 和HbA1c 3 个属性构成的属性子集能够以较高的精度识别CP。根据上述3 个属性对预测结果的影响程度进行重要性排序,结果为:年龄>LDL>HbA1c。
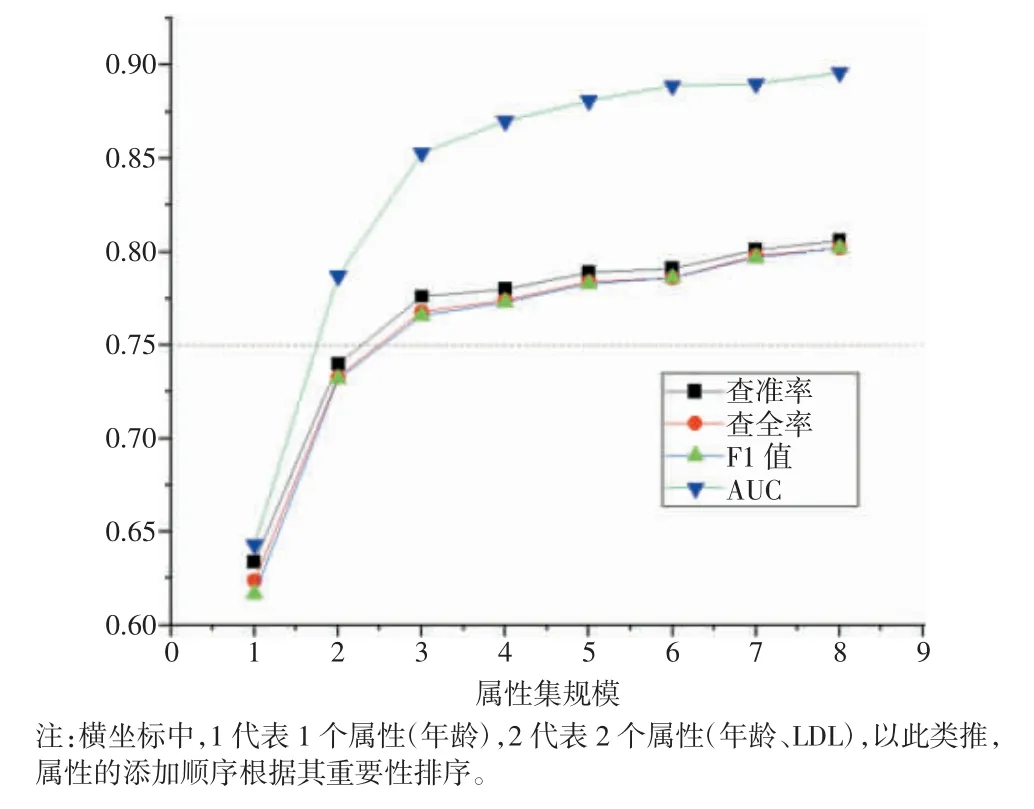
图3 基于不同属性子集的预测结果
由于FPG 和HbA1c 高度相关,同时LDL 和HDL也具有强关联性,因此本研究进行了更多的实验来评估不同属性集之间的性能差异。实验中的属性子集有4 类,分别为S1(年龄、LDL、HbA1c)、S2(年龄、FPG、LDL)、S3(年龄、HDL、HbA1c)和S4(年龄、HDL、FPG)。从性能比较结果(如图4 所示)中可以观察到4 条曲线是平缓的,其中查准率、查全率和F1 值保持在0.75~0.78 之间,而AUC=0.855±0.003。由此可以得出结论,LDL 和HDL 在预测CP 中效能相当,而HbA1c 和FPG 基本可以互换。
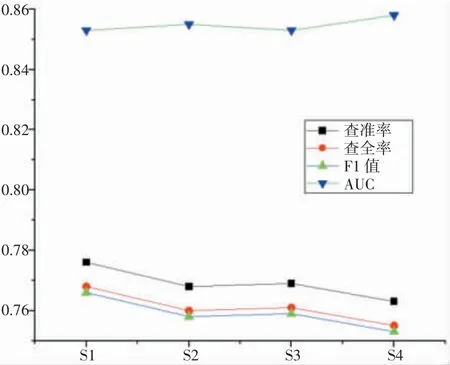
图4 不同属性集的性能比较
与已有研究[1-2]相呼应,本研究的实验结果也表明年龄是CP 诊断中最重要的独立指标。另外,本研究也表明,HbA1c 和FPG 不但能有效识别健康人群中的CP[4-5],而且对鉴别糖尿病患者中的CP 也具有显著效果。与Chen 等[11]研究不同,本研究未发现男性和女性在CP 诊断中有明显差异。
4 结语
本研究以上海交通大学附属第六人民医院提供的脱敏数据集为基础,构建了多个分类预测模型,其中,RF 模型可以充分利用内分泌的常规属性来预测CP。实验结果表明,HbA1c、LDL 和年龄3 类属性在预测中发挥了关键作用,仅由它们训练完成的模型已获得不错的预测效果;同时也说明基于常规体检指标训练而成的机器学习模型具有简单、高效、成本低和准确率高等特点,理论上能够作为诊断CP 的辅助方法。本文提出的RF 方法有助于辅助内分泌代谢科医师在超声诊断前对CP 的疑似病例进行预诊断,以节省患者时间,减少不必要的医疗资源浪费。本研究的局限性包括:未考虑CP 的演化或严重程度;数据均来自同一家医院,因此训练而成的预测模型的一般适用性有待进一步考证。鉴于深度学习在辅助诊断方面的良好可用性[14-15],本研究未来拟在大规模扩充现有数据集的基础上,探索深层神经网络模型的适用性,以进一步提高CP 的预测精度。
猜你喜欢
小猕猴智力画刊(2022年9期)2022-11-04 02:31:54
机械工业标准化与质量(2022年6期)2022-08-12 02:07:42
国际眼科杂志(2021年9期)2021-09-15 03:24:42
装备制造技术(2020年2期)2020-12-14 03:09:16
电子测试(2018年1期)2018-04-18 11:52:35
汉语世界(The World of Chinese)(2017年1期)2017-09-28 07:13:12
小学生作文选刊·低年级版(2017年2期)2017-03-06 21:19:40
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
小学生导刊(低年级)(2016年8期)2016-09-24 23:56:40
