
融合通用题目表征学习的神经知识追踪方法研究
2022-06-17 09:09沈双宏黄振亚陈恩红王士进
中文信息学报 2022年4期
魏 思,沈双宏,黄振亚,刘 淇,陈恩红,3,苏 喻,王士进
(1. 认知智能国家重点实验室(科大讯飞),安徽 合肥 230088;2. 中国科学技术大学 计算机科学与技术学院 大数据分析与应用安徽省重点实验室,安徽 合肥 230027;3. 中国科学技术大学 大数据学院,安徽 合肥 230027)
0 引言
在线学习系统(Online Learning Systems,OLS),包括智能辅导系统(Intelligent Tutoring Systems,ITS)和大规模在线开放课程(Massive Online Open Courses,MOOC),能够为学生提供智能教育服务[1-3]。例如,自适应地向学生推荐个性化的学习资源和学习路径,以提高他们的学习效率和体验[4-5]。知识追踪(Knowledge Tracing,KT)旨在监测学生在学习中的动态知识状态[6],是提供这些智能服务中最基础和必要的研究任务之一。近年来,随着在线教育的迅速发展,越来越多的研究开始关注到这个新兴的研究方向[7-20]。
具体来说,知识追踪问题的定义如下: 在一个智能在线学习系统中,假设学生集合是={s1,s2,…,sI},包含I个不同的学生;题目集合是={e1,e2,…,eJ},包含J个不同的题目;知识点集合是={kc1,kc2,…,kcM},包含M个不同的知识点。每个题目都与特定的知识点关联,学生通过在不同的题目上进行练习达到对相应知识点的掌握。这里学生的学习交互序列可表示为X=(e1,a1),(e2,a2),…,(et,at),其中,et表示t时刻学生回答的题目,at是对应的答案标签(1代表正确答案,0代表错误答案),T表示学习交互序列的长度。基于学生的学习交互序列,知识追踪是评估学生在学习过程中不断演变的知识状态并进一步预测他们未来表现的任务。这里的知识状态指的是学生在具体知识点上的掌握程度。为了方便理解,本文在图1中给出了一个知识追踪的具体示例: 在学生的练习过程中,知识追踪模型不断估计学生知识状态并给出反映学生知识掌握程度变化的雷达图。在该示例中,雷达图的每一维对应学生在对应知识点上的掌握情况。通过雷达图面积的变化可以看出,学生在练习后获得了较好的知识增长。
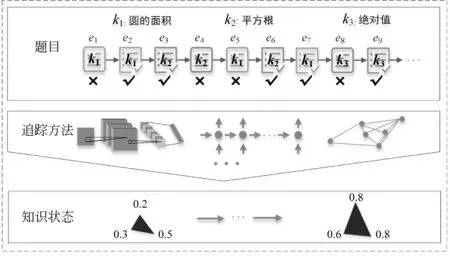
图1 知识追踪过程示例
针对知识追踪的现有工作中,研究重点主要集中在两个方向: 探索更好的追踪方法或寻求更恰当的题目表征方式。如表1所示,本文对现有的知识追踪模型进行了系统的分类,从表中可以看出研究不同的追踪方法更受关注。一些最新的技术,尤其是基于深度学习(deep learning, DL)的方法,已经成功应用于知识追踪任务。与此同时,针对题目表征的研究相对较少。然而,在追踪方法上的诸多研究给知识追踪任务带来的性能提升实际上并不如在题目表征上的研究。例如,目前表现最优的采用基于自注意力机制的编码器-解码器架构的 AKT模型在知识追踪中取得了很好的表现[16]。根据AKT原文的实验结果,其主要的表现收益来自基于Rasch模型[21]的题目表征,而不是基于单调自注意力机制的追踪方法。
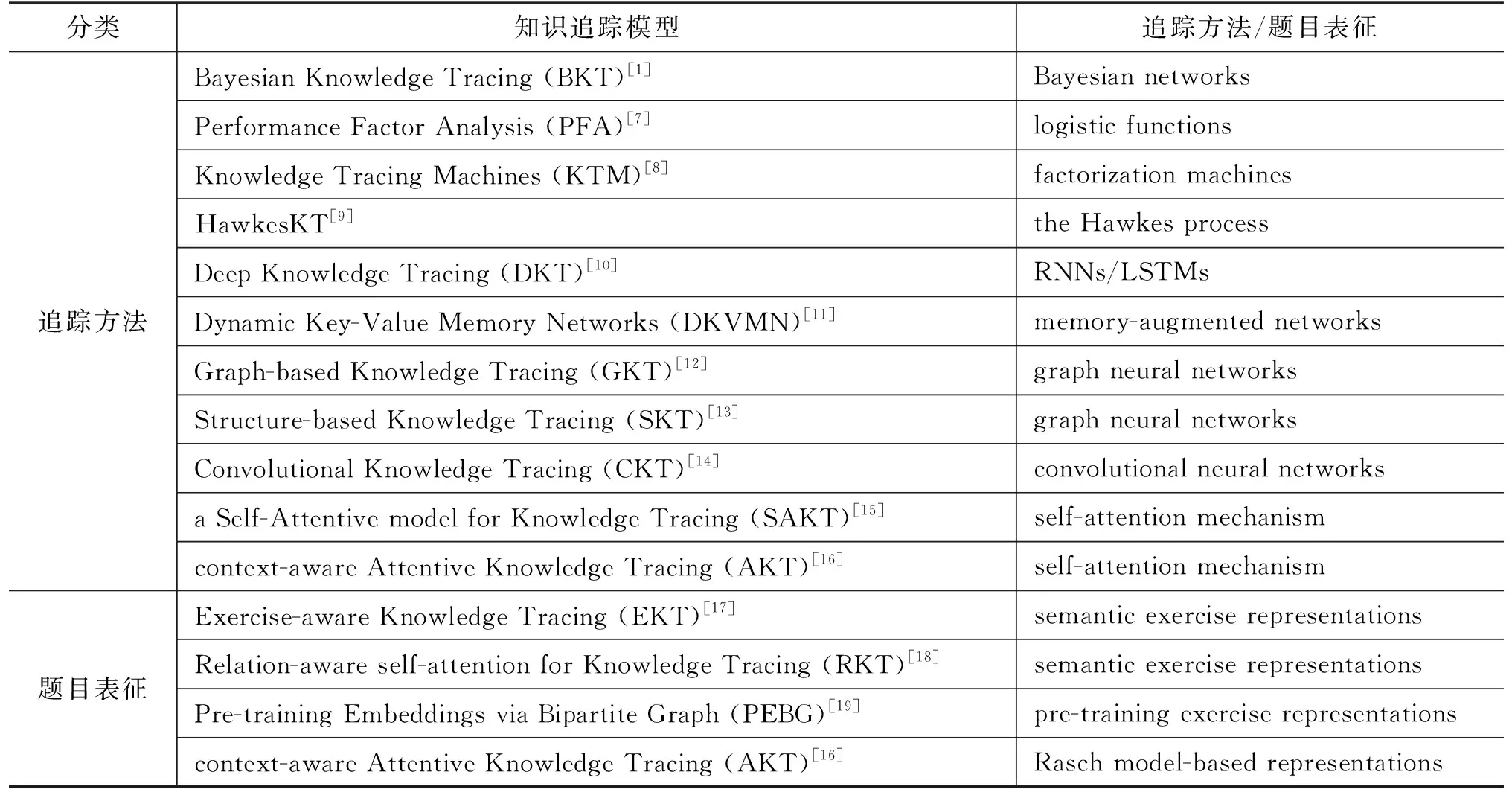
表1 知识追踪模型分类结果
此外,在现有大多数知识追踪模型中,题目往往仅由其含有的知识点表示,在这样的情况下,它们假设具有相同知识点的题目是相同的。例如,图2中题目e4和e6具有相同的知识点——“平方根”,所以它们被认为是同一道题。然而,这样简单的假设在现实情况中是不合理的。因为具有相同知识点的题目之间,不同的题目难度等独特特征被忽略了,而题目难度等特征在学生学习场景中是十分重要的。具体来说,在对图1中学生的知识状态进行建模时,能答对题目e4的学生显然比只能答对题目e6的学生在“平方根”知识点上具有更好的掌握水平。此外,答错题目e4和e6代表的含义也不相同: 答错题目e6可以表明学生掌握得很差,而答错题目e4只能说明掌握得不够好。为了完善知识追踪中的题目表征,Liu等人[17]提出利用题目的文本去预训练得到独特的题目表征;Liu等人[19]同样提出一种预训练题目表征的方法,该方法通过构建题目-知识点关系、题目相似关系、知识点相似关系、题目难度二分图,利用神经网络预训练得到题目表征。此外,Ghosh等人[16]将心理测量学中的Rasch模型[21]引入到题目表征中。上述方法虽然取得了一定的效果,但是它们都往往需要先获取题目文本等额外资源,并且经过复杂的预训练过程去获取题目表征,然后再将这些题目表征应用到知识追踪任务中,这限制了其进一步的发展和实际的应用场景。

图2 题目示例
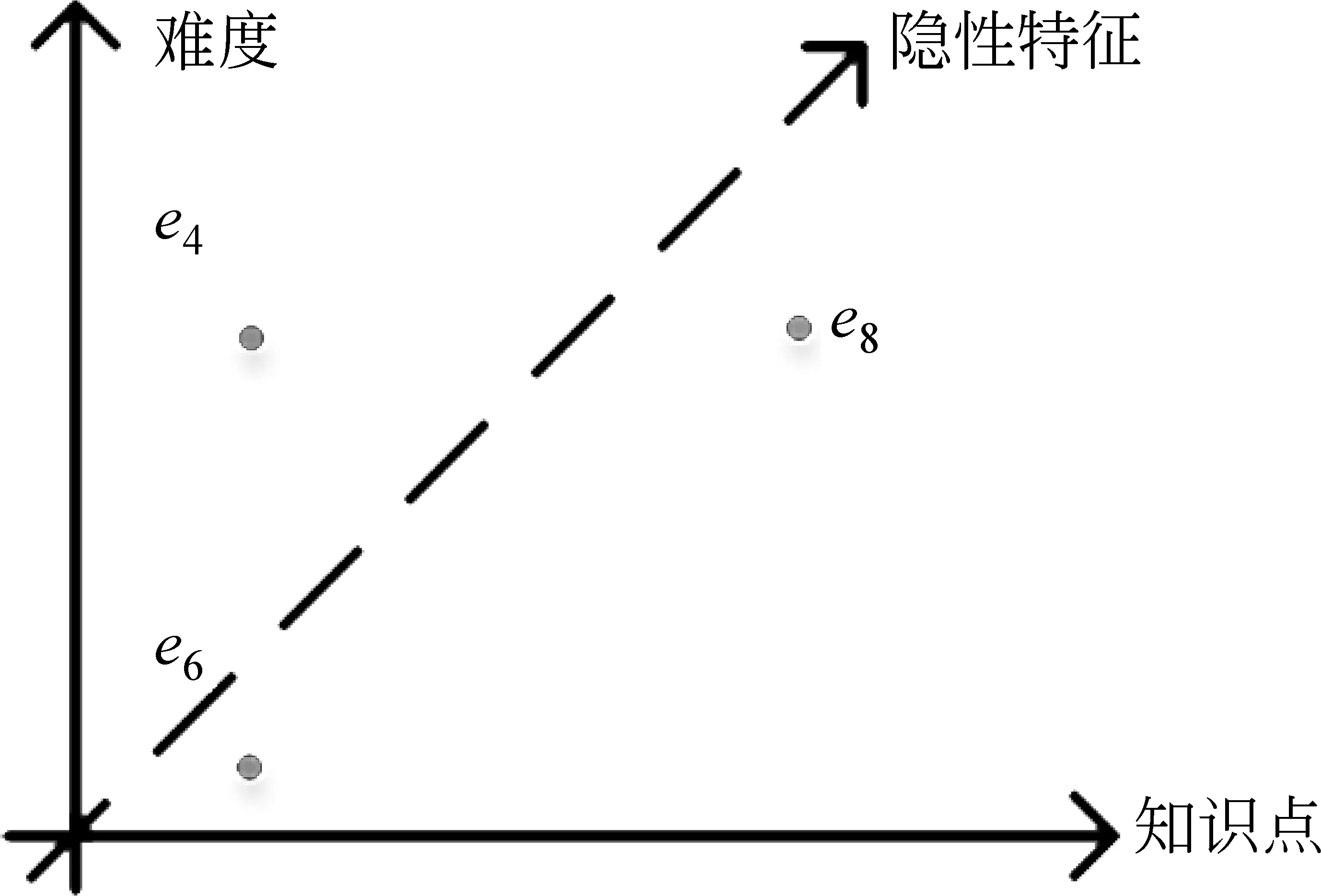
图3 题目特征维度及其关系
鉴于题目表征对知识追踪任务的重要意义和影响,针对目前知识追踪任务中题目表征存在的问题,本文首先提出了一种通用题目表征方法。如图3所示,题目具有多种特征维度,通过知识点和难度等预定义的显性特征就可以辨别绝大多数不同的题目,但考虑到少部分具有相同知识点和难度的题目也可能不一样,本文用题目独有隐性特征来区分这类题目。因此,本文进一步利用知识点、难度等显性特征和题目独有隐性特征来构建通用题目表征以综合表示题目。然后,为了学习到有意义的题目表征,本文提出将题目表征学习融入知识追踪过程中,并设计了一种融合通用题目表征学习的神经知识追踪框架(Neural Knowledge Tracing Framework,NKTF),在进行知识追踪的同时学习精确有效的题目表征,不需要额外的文本资源并省去了复杂的题目表征预训练过程。该框架包含三个主要模块: ①学习交互表征模块; ②追踪方法模块; ③表现预测模块。具体来说,学习交互表征模块包含本文设计的通用题目表征以及学生相应的答案表征。追踪方法模块可以由任意一种现有的知识追踪模型来完成,本文应用了三种常用的基于深度学习的方法,分别是深度知识追踪中的LSTM[10]、卷积知识追踪中的CNN[14]和基于注意力知识追踪中的self-attention[15]。表现预测模块用于预测学生未来的表现,本文通过学生的知识状态与待回答题目的内积对建模学生运用知识回答题目的过程,学生的表现也可以通过内积结果来预测。最后,本文在三个真实数据集上进行了实验,实验结果表明,通过将题目表征学习融入知识追踪任务中,NKTF可以同时促进题目表征学习和知识追踪的效果,在自动学到有意义的题目表征的同时也能较大程度地提高基线知识追踪模型的性能,使它们能够超过目前最优的模型。
1 相关工作
1.1 追踪方法驱动的知识追踪模型
追踪方法驱动的知识追踪模型代表寻求不同 的方法来建模学生知识状态演变的一类知识追踪模型。贝叶斯知识追踪(Bayesian knowledge tracing,BKT)是第一个被提出的知识追踪模型[1],它是隐马尔可夫模型的一个特例。随后,一些其他模型,比如表现因子分析(Performance Factor Analysis,PFA)[7],采用逻辑函数来估计学生掌握知识点的概率。用在推荐系统中对用户和项目进行编码的因子分解机(Factorization Machines,FM)也被成功应用在知识追踪任务中对学生和题目进行建模[8]。HawkesKT利用Hawkes过程对知识追踪过程中的时序交叉效应进行自适应建模[9]。近年来,深度学习的进步推动了基于神经网络的知识追踪模型的发展。神经网络强大的非线性和特征提取能力使其非常适合对复杂的学习过程进行建模。具体地,深度知识追踪(DKT)首先将深度学习引入知识追踪任务中[10],它利用RNN及其变种LSTM对学生的知识状态进行建模。然后,动态键值记忆网络模型(DKVMN)使用记忆网络来存储潜在的知识点并更新学生的知识掌握程度[11]。基于图神经网络的知识追踪(Graph-based Knowledge Tracing,GKT)提出使用GNN对知识点中自然存在的图结构进行建模[12]。同样,基于知识结构的知识追踪(SKT)也使用GNN来捕获知识追踪过程中知识点之间的影响力传播[13]。卷积知识追踪(CKT)应用CNN来模拟学生的个性化学习率[14]。基于注意力的知识追踪(SAKT)将Transformer中的self-attention引入到知识追踪[15]。情境感知的注意力知识追踪(AKT)结合了具有单调假设的自注意力机制[16],并提出一种编码器-解码器架构对学生知识能力进行建模。
1.2 题目表征驱动的知识追踪模型
相较于追踪方法驱动的知识追踪模型,题目表征驱动的知识追踪模型旨在更好地表征知识追踪中的题目。题目感知的知识追踪(EKT)有效利用题目文本内容来提高知识追踪的表现[17]。EKT定义了一个Bi-LSTM 架构来自动地从文本内容中学习题目的语义表征,然后将这些表征输入到 LSTM 层以捕获学生的动态知识状态。同样,关系感知的知识追踪(RKT)利用题目的上下文信息来增强自注意力机制[18]。RKT定义了题目相关系数并从文本内容中捕获题目之间的关系信息。基于二分图的预训练表征(PEBG)提出了一种获得预训练题目表征的方法[19]。它将题目-知识点关系、题目相似关系、知识点相似关系、题目难度一起表示为二分图,并利用基于内积的神经网络将它们融合以获得预训练的题目表征。此外,AKT 还提出利用心理测量学中的Rasch模型来构建题目和知识点的表征[16]。题目表征驱动的知识追踪模型通常需要复杂的预训练方法和题目文本等额外资源,这限制了它们的进一步发展。
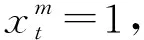
总的来说,追踪方法驱动的知识追踪模型受到了更多研究人员的关注。然而,从现有研究的结果来看,题目表征驱动的知识追踪模型更能有效地提升知识追踪的效果。例如,基于Rasch模型的题目和知识点表征可以使AKT获得最大的收益。PEBG中的预训练题目表征也很好地提高了基线知识追踪模型的表现。本文提出一种通用题目表征方法,并将题目表征学习融入到知识追踪过程中,在实验部分可以看到,本文方法不仅提升了知识追踪的效果,而且学到了精确有效的题目表征。
2 模型与方法
本文提出了融合通用题目表征学习的神经知识追踪框架NKTF,模型框架如图4所示。本节首先介绍学习交互表征模块,然后介绍追踪方法模块,最后介绍表现预测模块。

图4 NKTF模型框架图
2.1 学习交互表征模块
学习交互由题目和答案组成。基于知识点的学习交互表征无法区分具有相同知识点的题目,除了知识点之外,题目还有难度等其他特征。完整的题目表征应当能精确有效地区分每一道题目。为了得到这样的题目表征,本文用知识点、难度等显性特征,以及题目独有的隐性特征来综合表征题目。具体地,题目的知识点可以由专家标注得到,首先随机初始化一个嵌入矩阵K∈M×dk,其中dk是向量的维度。对于知识点kcm,本文分配一个特定的向量对其进行表征。对于题目难度,本文采用经典测试理论[22]中基于统计的难度计算方式,如式(1)所示。
(1)
其中,Si是回答了题目et的学生集合,ai==1表示答案正确,常量Cd是预定义的难度级别数目。同样地,随机初始化一个嵌入矩阵D∈Cd×Cd,用于表示题目难度,其中Cd是向量的维度。对于难度级别为c的题目,其难度向量为dc∈dk。因此,对于题目et,其知识点和难度向量分别为ket和det。然后,本文可以通过ket和det的组合得到题目表征的显性特征首先连接ket和det,然后输入层感知器(multi-layer perceptron,MLP),如式(2)所示。
(2)
其中,W1∈(dk+dd)×d1是权重矩阵,b1∈d1是偏差项。经过组合后,将包含其知识点和题目难度的深度混合特征。综合考虑知识点和题目难度可以更好地推断学生的知识状态: 对较难练习的正确答案表明知识掌握程度较高,对较简单练习的错误答案表明知识掌握程度较低。然而,难度和知识点等显示特征只能在二维空间中表达每个题目,无法区分更高维空间中题目的差异。因此,本文在难度和知识点的基础上,为每一个题目添加一个独有的隐性特征d2,其中,d2是向量的维度。最后,题目et的表征可以通过式(3)得到。
(3)
其中,“⊕”是连接运算,W2∈(d1+d2)×dh是权重矩阵,b2∈dh是偏差项,dh是向量的维度。因此,本文提出的通用题目表征包含了知识点、难度以及题目独有特征等综合信息,可以准确区分每一道题目。在知识追踪过程中,NKTF将同时自动学习题目表征。
得到题目表征后,本文将题目表征和答案表征融合得到学习交互表征。在这里,答案表征也来自随机初始化的矩阵A∈2×da;这里2表示答案的正确或错误两种类别,da是向量的维度。学习交互(et,at)如式(4)所示。
(4)
其中,W3∈(d1+d2+da)×dx是权重矩阵,b3∈dx是偏差项,dx是向量的维度。经过训练,本文可以获得精确有效的学习交互表征。
2.2 追踪方法模块
本文的研究重点是知识追踪中的题目表征学习,为了验证本文提出的通用题目表征学习的有效性,在追踪方法模块,本文将上述学习交互表征作为输入,选择现有的三种常用知识追踪模型来实现追踪方法模块,分别是DKT中的LSTM、CKT中的CNN和SAKT中的self-attention。以 DKT中的LSTM为例,本文提出的学习交互表征xi,将作为LSTM的输入,学生知识状态的具体计算如式(5)所示。
(5)
其中,Wi,Wf,Wo,Wc∈(dx+dh)×dh是权重矩阵,bi,bi,bo,bc∈dh是偏差项。类似地,本文将LSTM中的隐藏状态hi∈dh视为学生的知识状态。
2.3 表现预测模块
在表现预测模块中,和传统知识追踪模型不同的是,本文输出知识状态向量的长度并不等于知识点的数量。与通过索引进行预测的方式不同的是,NKTF利用知识状态向量和待回答题目的表征的内积来模拟学生的回答过程。然后,通过sigmoid函数将内积结果转换为估计学生回答正确的概率,如式(6)所示。
yt +1=σ(et +1·hi)
(6)
为了训练NKTF中的所有参数和随机初始化的表征向量,本文选择预测答案y和实际答案a之间的交叉熵对数损失作为目标函数,使用Adam优化器[23]在mini-batches上优化,如式(7)所示。
(7)
3 实验
3.1 数据集
为了验证本文提出的融合通用题目表征学习的神经知识追踪框架的有效性,本文选取了三个真实数据集进行实验,这三个数据集的具体介绍如下:
●ASSIST2012(1)https://sites.google.com/site/assistmentsdata/home/2012-13- school-data-with-affect该数据集中的数据收集自在线辅导系统——ASSISTments[24]。数据是从技能构建者题目集中收集的,学生需要在这些题目集中进行类似的练习以获得知识。在这个数据集中,本文过滤了没有相关知识点的学习交互记录。过滤后共有2 711 813条学习交互记录,29 018名学生,53 091个题目,265个知识点,平均学习交互序列长度约为93。该数据集拥有最多数量的题目。
●ASSISTchall(2)https://sites.google.com/view/assistmentsdatamining/dataset该数据集来自于2017 年ASSISTments教育数据挖掘竞赛,跟踪了学生2004—2007年间在ASSISTments学习平台中的使用记录。这个数据集中共有942 816 条学习交互记录,1 709名学生,3 162个题目,102个知识点,平均学习交互序列长度约为552。该数据集具有最长的平均学习交互序列。
●NeurIPS_EDU2020(3)https://eedi.com/projects/neurips-education-challenge该数据集发表于NeurIPS 2020教育挑战赛,该挑战赛提供了来自教育平台Eedi[25]的学生用户两个学年的数学练习数据。这个数据集共有15 867 850条学习交互记录,118 971个学生,27 613个题目,1 125个知识点,平均答题交互序列长度约为133。该数据集拥有最多的答题交互序列。本文去掉了该数据集中部分学习交互时间信息重复的记录。
3.2 实验设置
本文首先按照答题的时间顺序对学生的所有学习交互记录进行排序。然后,根据数据集的平均学习交互序列长度将所有输入序列设置为固定长度: ASSIST2012为100、NeurIPS_EDU2020为200、ASSISTchall为500。对于比固定长度更长的序列,本文将它们切分成几个子序列。对于短于固定长度的序列,使用零向量将它们填充到固定长度。本文使用均匀分布[26]随机初始化模型训练中的所有参数。对于所有数据集和模型,本文都进行了标准的5折交叉验证。所有的超参数都是在训练集上学习的,在验证集上表现最好的模型被用来评估测试集。本文共划分了100个不同的难度等级(Cd=100)。为方便起见,在本文的NKTF 实现中,参数dh、de、da、dk、dd、d1、d2、d3都设置成100。
本文将3个基于NKTF的知识追踪模型与5个基线进行比较,为了公平比较,所有方法都经过调整以获得最佳性能。模型具体介绍如下:
(1) 基于动态记忆网络的DKVMN[11];
(2) 基于LSTM实现的DKT[10];
(3) 基于DKT的改进DKT+[27],加入了正则化项解决DKT预测的问题;
(4) 基于自注意力机制的SAKT[15];
(5) 基于CNN的CKT[14];
(6) 具有单调注意机制和基于Rasch模型题目表征的AKT[16];
(7) 基于DKT的NKTF_DKT;
(8) 基于SAKT的NKTF_SAKT;
(9) 基于CKT的NKTF_CKT;
上述所有模型都在带有两个2.30 GHz Intel(R) Xeon(R) Gold 5218 CPU资源和一个TeslaV100-SXM2-32GB GPU资源的Linux服务器上进行训练。本文公开了NKTF 的源代码(4)https://github.com/bigdata-ustc/EduKTM/tree/main/EduKTM/NKTF。
3.3 学生表现预测
为了评估NKTF的有效性,本文将3个基于NKTF的模型与所有基线模型学生表现预测任务上进行比较,并在表2中列出了5折交叉实验在测试集上的平均结果,其中基线模型的结果来源于本文基于基线模型开源代码复现的实验结果(5)AKT原文在ASSISTchall数据集中AUC为0.770 2,本文复现结果为0.764 3。原文在ASSISTchall数据集中AUC约为0.723,本文复现结果为0.722 1。这些复现差异主要源于数据预处理方式不同,不会影响本文提出方法的有效性。。为了提供可靠的评估结果,本文在所有实验中都采用了四项评估指标: 均方根误差 (RMSE)、ROC曲线下面积 (AUC)、准确度 (ACC) 和皮尔逊相关系数的平方 (r2),其中在计算准确度时将阈值设置为0.5。从表2中可以观察到几个重要的实验结果。首先,受益于本文提出的通用题目表征学习,基线知识追踪方法的效果得到了显著的改进,并且击败了现有最优的方法。其次,基线模型中不同的追踪方法在性能上只有很小的差异,DKT中的LSTM略微优于其他方法。此外,本文注意到基于自注意力机制的知识追踪模型,如SAKT和AKT,不擅长处理ASSISTchall数据集中的较长学习交互序列,其原因是这些模型对学习交互中关键的序列信息不敏感。
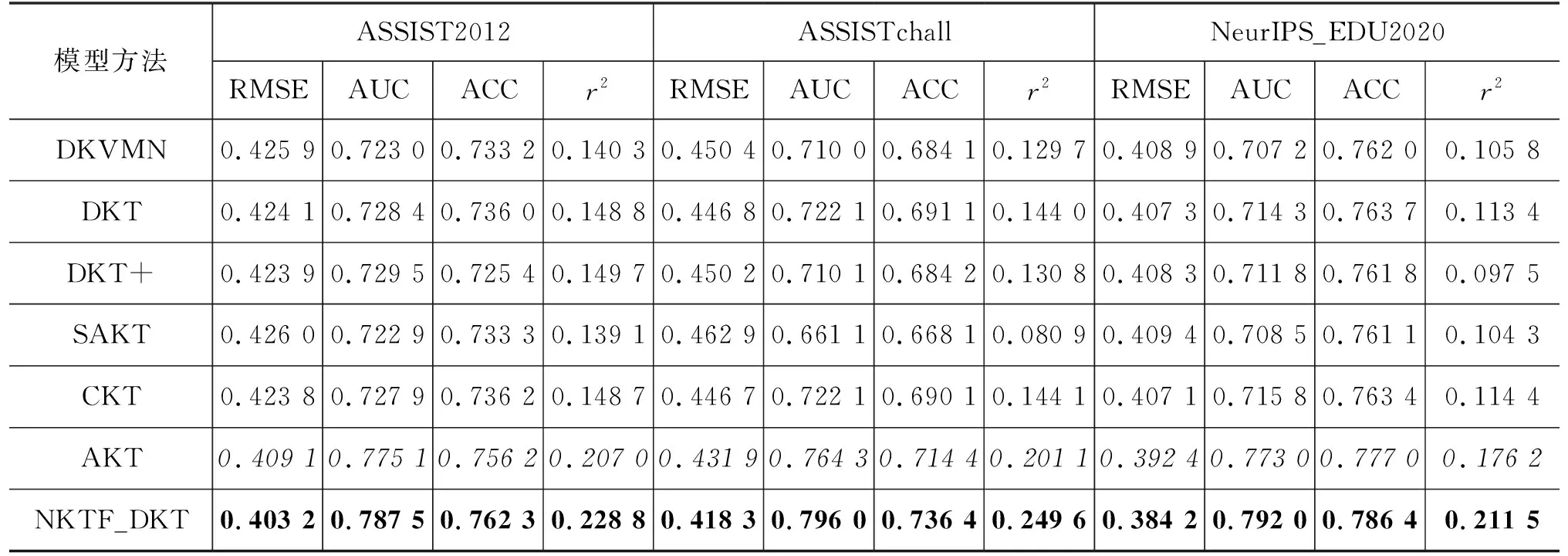
表2 学生表现预测结果比较

续表
3.4 题目表征的可解释性
本节进行了更多的实验来展示NKTF在知识追踪过程中学习到的通用题目表征的可解释性。具体来说,本文首先随机在数据集NeurIPS_EDU2020上选择八个具有不同知识点和难度的题目。如图5所示,本文计算并可视化了这些题目之间的余弦相似度相关权重。从图3中可以看到,经过足够的训练,NKTF学习到的题目表征,反映出了不同题目的知识点、难度和个体特征。图3清楚地表明,具有相同知识点的题目或难度更接近的题目之间的相关权重往往更高。然后,本文首先随机选择50个不同的知识点和10个不同的难度,在数据集ASSISTchall 上构建500个不同的题目。然后利用T-SNE方法[28]将这些题目的表征向量投影到二维空间,并使用K-means聚类将它们分成10个类别,如图6所示。可以看到,聚类结果显示出很好的可解释性, NKTF学到的题目表征向量可以清楚地分为10个类别不同的难度级别。
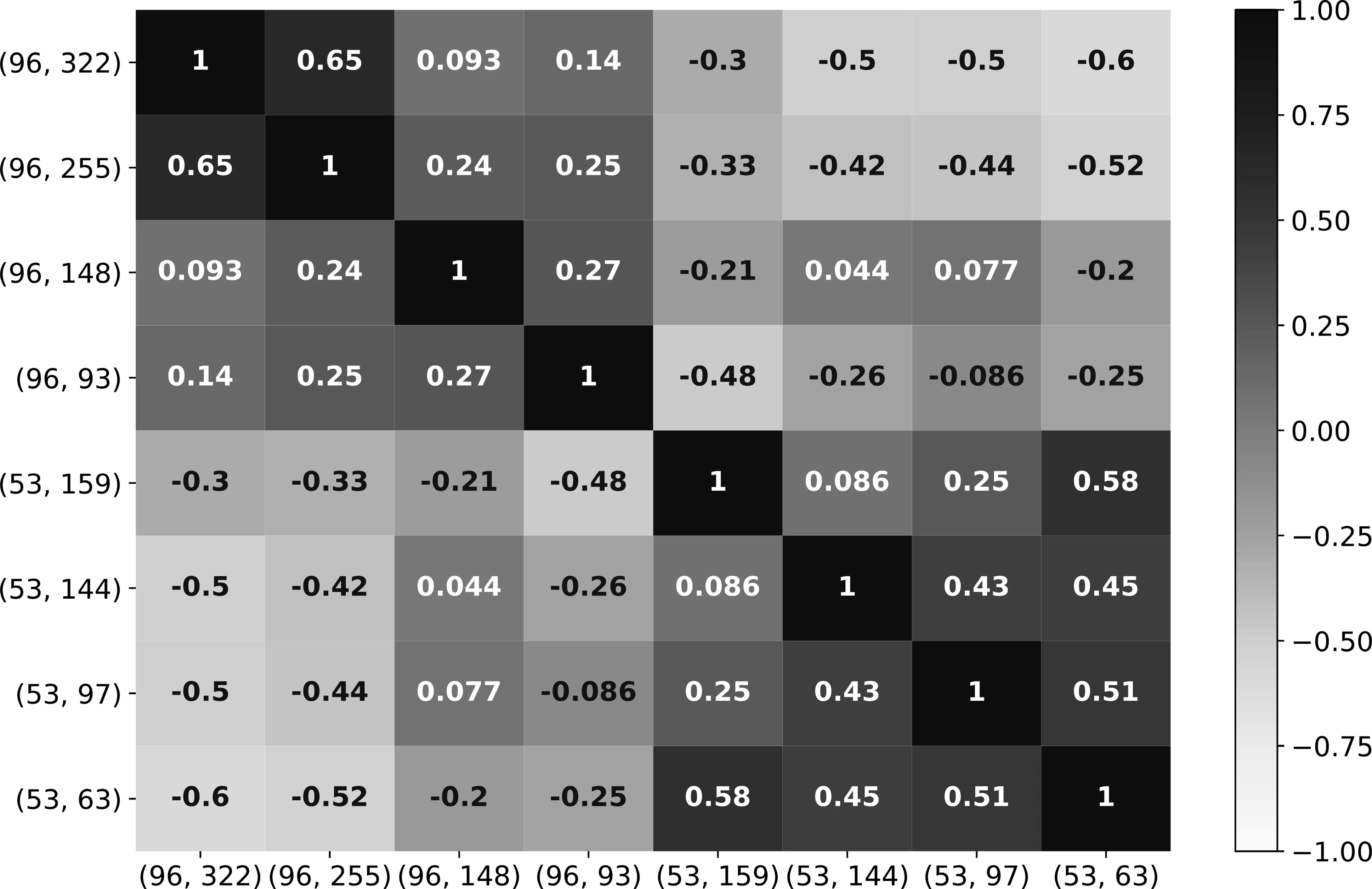
图5 数据集NeurIPS_EDU2020上不同知识点和难度的题目之间的相关权重可视化标签(i,j)表示题目的知识点为i,难度为j,其中较大的j表示更难的题目
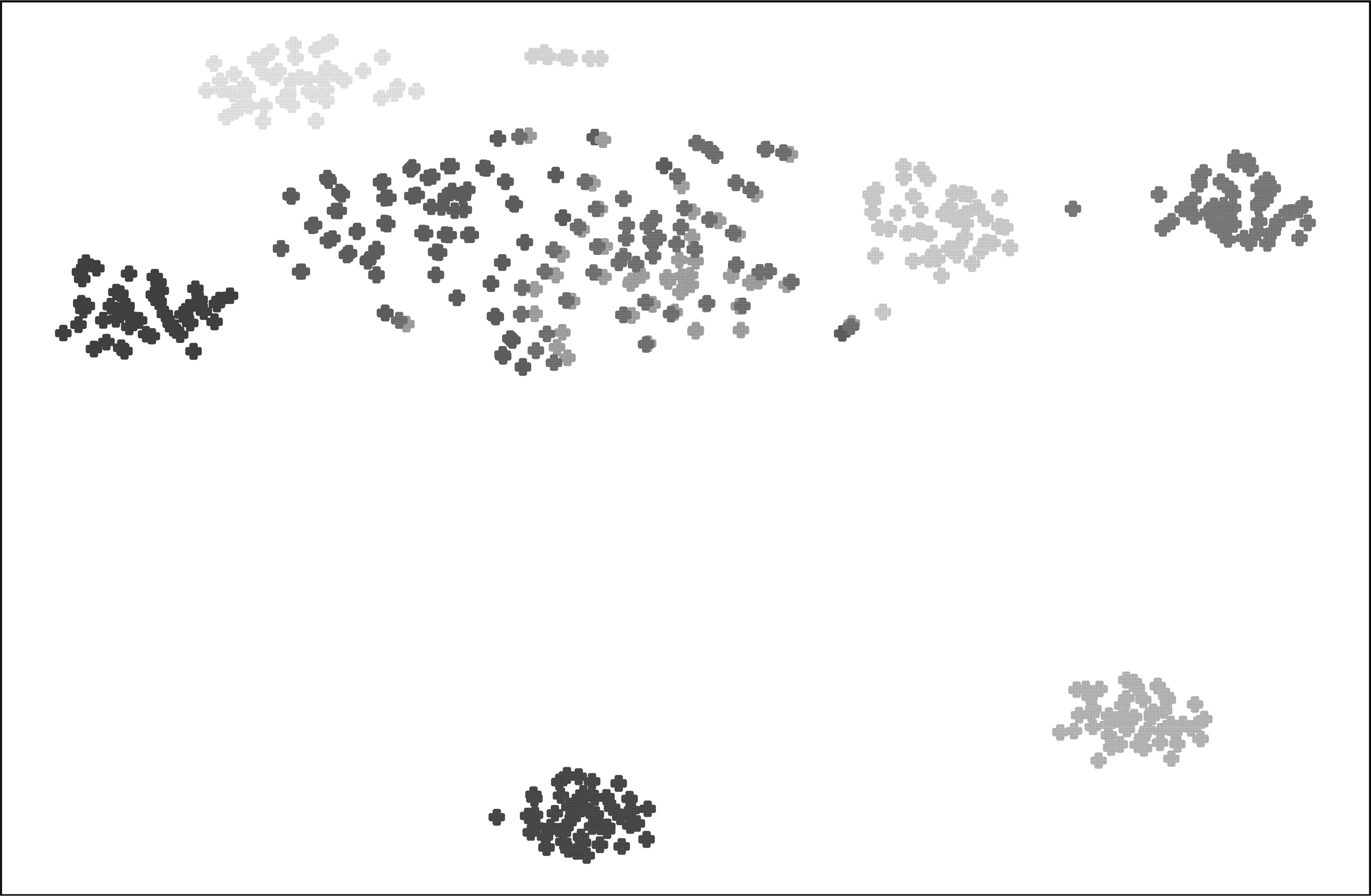
图6 数据集ASSISTchall上500个题目表征向量的聚类结果这些题目由50个不同的知识点和 10个不同的难度级别组成
3.5 消融实验
为了进一步验证本文提出的包含知识点、难度等显性特征和题目独有隐性特征的通用题目表征的有效性,本文进一步在表现最好的NKTF_DKT模型上进行了消融实验。实验在ASSIST2012和ASSISTchall两个数据集上进行,实验结果如表3所示。从表中可以看出,当训练数据足够的时候,NKTF可以在知识追踪的过程中同时学习到有意义的显性特征和隐性特性,在ASSISTchall上使用两种特征可以得到最好的表现。当题目数量太多或者训练数据不足的时候,NKTF无法学到有效的隐性特征,在ASSIST2012数据集上,单独使用显性特征可以得到最佳表现,加入隐性特征反而使得预测的准确率略微下降。因此,在实际运用中,应当根据数据集的具体情况决定题目表征是否需要包含隐性特征。
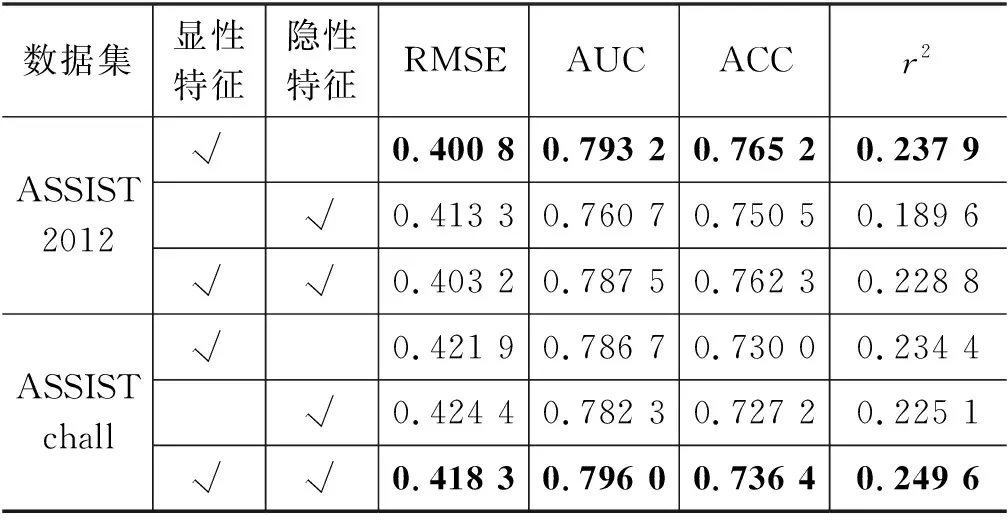
表3 NKTF_DKT消融实验结果对比
3.6 知识追踪过程可视化
在图7中,本文给出了数据集ASSIST2012里一个学生具体的知识追踪过程。在该学生回答18个不同题目的过程中,本文使用NKTF_DKT追踪了他/她不断演变的知识状态。从这个案例中,可以更好地理解本文提出的题目表征在知识追踪过程中发挥的重要作用。例如,学生在知识点为49: 实数排序、难度为0.25的练习中得到了正确答案,但未能正确回答具有相同知识点但难度更大 (0.55) 的题目。同样,他/她在知识点为45: 正小数排序、难度为0.38的题目中得到了错误的答案,但仍能够正确回答具有相同知识点但更简单(难度值为0.13)题目。通过兼顾题目的知识点和难度,本文可以更加准确快速地评估学生的知识熟练程度。

图7 ASSIST2012数据集上学生在具有不同难度级别的五个知识点上知识状态的追踪过程其中难度值已归一化到0到1之间,数值越大代表难度越大
4 总结与展望
本文梳理了目前知识追踪领域追踪方法驱动和题目表征驱动的两类模型,发现了题目表征驱动的知识追踪模型事实上更能有效地提升知识追踪的效果。针对目前知识追踪中简单的基于知识点的题目表征以及复杂的基于预训练的题目表征中存在的问题,本文提出了一种通用的题目表征方法,利用知识点、难度等显性特征和题目独有的隐性特征来完整地表示题目,并且将题目表征学习融入知识追踪过程,构建了融合通用题目表征学习的神经知识追踪框架。实验证明,本文方法可以在知识追踪过程中自动学习到精确有效的题目表征,并且大幅度提高了基线知识追踪模型在学生表现预测任务上的性能,超过了当前最优的结果。
在未来的工作中,我们将继续探究更好地结合题目表征学习和知识追踪任务,例如,针对性地构建多任务学习框架更好地完成题目表征学习和知识追踪。此外,可以尝试将学习到的题目表征运用在题目属性标注、质量预测等任务上。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
新世纪智能(数学备考)(2021年9期)2021-11-24
小哥白尼(军事科学)(2021年7期)2021-11-20
小哥白尼(军事科学)(2021年6期)2021-11-02
小哥白尼(军事科学)(2021年2期)2021-10-12
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
文苑(2020年7期)2020-08-12
中学生数理化·八年级数学人教版(2019年11期)2019-09-10
非公有制企业党建(2016年9期)2016-05-25
高中生学习·高三版(2016年9期)2016-05-14
