
基于BERT的强化语境与语义信息的对话幽默识别模型
2022-06-17 09:09蒋玉茹张禹尧
中文信息学报 2022年4期
徐 洋,蒋玉茹,2,张禹尧
(1. 北京信息科技大学 智能信息处理研究所,北京 100101;2. 国家经济安全预警工程北京实验室,北京 100044)
0 概述
幽默是人际交往中一种重要的交流形式,在生活中随处可见。幽默一词是由“humor”音译而来[1]。Cruthirds[2]将幽默定义为“在个人、群体或组织中产生积极情绪和认知的有趣交流。”随着人工智能的发展,幽默计算[3]近些年来已成为自然语言处理领域的新兴热点之一,主要研究如何基于自然语言处理技术理解和识别包含幽默的文本表达,挖掘幽默表达中潜在的语义内涵,构建面向幽默表达的计算模型,这有助于赋予计算机更深层次的人类认知。采用深度学习的方法对幽默进行识别的研究成果在智能问答、情感陪护等领域也有广阔的应用前景。
根据幽默所处场景的不同,幽默一般表现为两种形式[4],一种是注重语言模态和语言浅层属性的单句幽默,另一种是依赖于语言所处上下文环境的语境幽默。单句幽默识别中所采用的特征往往比较简单,例如,表达中是否存在谐音、叠字、歧义等现象;而有关语境的幽默识别通常需要一定的上下文推理,与语义、语用、逻辑和常识有关。相较于单句幽默,有关语境幽默的识别具有更大的难度和挑战性。
幽默有多种类型[4],主要可分为为笑话(joke),俏皮话(one-liner)和对话幽默。对话幽默与简短的笑话和俏皮话形式的幽默不同,在对话中的幽默包含更多的上下文信息,单句幽默和语境幽默交替出现,而且语境幽默中的上下文跨度范围更广,这使得在对话中进行幽默识别更加困难。因此本文提出了强化语境与语义信息的对话幽默识别模型,对情景喜剧中的幽默进行识别,并在CCL2020评测任务中提供的中文语料《我爱我家》上进行实验,综合评分相较于仅使用中文BERT[5]的对比模型提升了2.4%。
本文组织结构如下: 第1节阐述幽默识别的相关工作;第2节介绍本文所构建的基于BERT的强化语境与语义信息的对话幽默识别模型;第3节描述本文的实验设置;第4节展示结果并对实验结果进行分析;第5节对实验中的典型案例进行分析;第6节对本文进行总结。
1 相关工作
幽默计算的初衷是让机器懂得幽默,2016年林鸿飞等[3]首次对幽默的可计算性进行了系统性的概述,提到幽默的识别与幽默的生成都属于幽默计算的范畴。
Mihalcea等[6]首次将幽默识别定义为二分类任务,并构建了一个笑话语料库,结合反语、特定俚语等幽默特征进行幽默识别。在此语料的基础上,Yang等[7]融入歧义、不协调等幽默特征继续进行幽默识别。Chen等[8]使用卷积神经网络CNN(Convolutional Neural Networks)进行幽默识别。Baziotis等[9]在SemEval-2017 Task6幽默评测任务中提出基于注意力机制[10]和长短期记忆网络LSTM(Long Short-Term Memory)的幽默识别模型,在识别两句话哪个更幽默的任务中取得当时最好成绩。Fan等[11]提出了PACGA网络学习幽默的语音结构和语义表示用于幽默的识别,并使用注意力机制来增强模型对幽默识别的能力。
杨勇等[12]在俏皮话形式的短文本幽默识别方向展开工作,他们独辟蹊径地从文本的语言学特征出发,引入了语音特征、字形特征和词的语义特征,结合双向门控循环单元GRU(Gate Recurrent Unit)和层次注意力网络,提出的PFSHAN模型在英文数据集中能够对俏皮话形式的幽默进行有效识别。Annamoradnejad等[13]创建了短文本幽默识别数据集ColBERT,并在Google提出的英文BERT[14]模型的基础上提出了改进的模型对幽默进行识别,最终在该数据集上取得了很好的效果。
在对话幽默识别任务中,Bertero等[15]率先利用基于神经网络的深度学习方法进行尝试,在《生活大爆炸》语料库(1)https://en.wikipedia.org/wiki/The_Big_Bang中首先使用CNN对每句话语进行编码,并捕捉低层级话语特征,其次将所有话语向量依次输入LSTM网络进一步捕捉对话文本中的高层级对话特征,结合这两种特征的CNN-LSTM模型在对话幽默识别任务上取得了不错的效果。这种层次化的对话文本编码方式在低层级对单个话语中的字符序列进行编码,在高层级对整个对话中的话语序列进行编码。相较于直接使用整个对话的字符序列对对话进行编码而言,层次化的对话编码方式能够有效的保留对话的结构信息。Majumder等[16]提出的DialogueRNN模型也是使用了类似的编码方式对对话文本进行编码,同样也取得了不错的效果。
由于幽默的表现形式不限于文本,近些年来使用声觉和视觉信息的多模态方法也开始应用于幽默识别中。相较于单一模态特征,多模态特征的相互融合能够让模型学习到更好的特征表示[17]。Yang等[18]通过语音、文本和视觉特征进行幽默识别。Bertero等[19]也使用情景喜剧中的声觉和文本特征来增强模型幽默识别的能力。
2018年以来,中文信息学会举办的中国计算语言学大会(CCL)中都会发布与幽默计算相关的评测任务,吸引了国内众多高校和企业参加。评测任务从识别幽默的类型到识别幽默的强度,再从单句幽默的识别到多轮对话中幽默的识别,极大程度上推动了幽默计算的发展。本团队曾参与CCL2020发布的评测任务三(2)http://cips-cl.org/static/CCL2020/humorcomputation.html——情景喜剧笑点识别,并获得了第四名的成绩。团队在比赛结束后对提交的最终模型做出了改进,形成了本文的模型。
2 模型结构
本文结合对话结构特征提出基于BERT的强化语境与语义信息的对话幽默识别模型,参考文献[15]采用的对话编码方式,使用层次化表示的编码方法对输入的对话文本进行编码,这样既可以对完整的对话内容进行编码,同时也保留了原本的对话结构。此模型通过学习对话语料中更深层次的幽默特征,进而提升机器幽默识别的能力。模型的整体结构如图1所示,自底向上由三部分构成,分别为BERT语义编码层,对话层级信息提取层和分类器层。

图1 基于BERT的强化语境与语义信息对话幽默识别模型图
2.1 BERT语义编码层
BERT语义编码层是通过预训练语言模型BERT对发言人及话语信息进行编码,提取对话中的基本语义信息。
与传统的单句幽默识别任务不同,在对话中,除了对话文本以外,发言人的信息也至关重要,因此本文将其也作为信息输入的一部分,将一段对话表示为X={(S1,T1),(S2,T2),…,(SN,TN)},S表示发言人,T表示发言人所说话语,N为该对话所包含的话语个数,其中,Xi=(Si,Ti),i∈(1,N)表示对话中第i句发言人信息及其话语信息。
经过BERT语义编码层后得到的编码结果表示为一段对话中各个话语的独立编码,记为Hi∈RL×h,其中,L为每句话语的最大长度,h为预训练模型隐藏层维度,所有输出结果共同拼接构成一段对话的表示结果,记为Hseq∈RN×L×h。如式(1)、式(2)所示。
Hi=BERT(Xi)
(1)
Hseq=[H1;H2,…;HN]
(2)
BERT在预训练的过程中[CLS] 标志放在句子的首位,使用[CLS]位置的表征向量表示当前话语的基本语义信息。因此本文将Hi中[CLS]位置的向量表示为Hi_cls∈Rh,所有输出结果共同拼接构成一段对话的表示结果,记为Hcls∈RN×h。
2.2 对话层级信息提取层
对话层级信息提取层的设计是本文的工作重点。为了让模型学习到更深层次的对话幽默特征,更充分地进行幽默识别,本文基于对话的结构特点,将此层级更细致地分为语义信息提取模块和语境信息提取模块。
语义信息提取模块对单句话语进行编码,提取话语深层次的语义信息,语境信息提取模块对一段对话进行编码,获取更完整的语境信息。
2.2.1 语义信息提取模块
语义信息提取模块采用两种方式对单独的话语信息进行编码,分别以Hi_cls和Hi作为输入,提取并强化不同层次的语义信息。二者编码过后的输出分别为Ui_cls和Ui。
本文将Hi_cls输入进全连接层(LINEAR),输出结果表示为Ui_cls∈Rn,其中n表示分类标签数。如式(3)所示。
Ui_cls=Wk×Hi_cls+bk
(3)
其中,Wk和bk为可学习的参数。
本文将Hi输入进BiLSTM中进行编码,能够从整体上对单句话语进行语义特征提取,输出结果记为Ui_b∈RL×h,如式(4)所示。
Ui_b=BiLSTM(Hi)
(4)
紧接着使用多头自注意力机制对Ui_b进行再编码,从每句话语中学习到不同字的重要程度后给每个字分配不同的注意力权重,再通过加权操作得到对话信息更全面的向量表示Ui_a∈RL×h,如式(5)所示。
Ui_a=Attention(Ui_b)
(5)
最后将Ui_a取[CLS]位置的向量表示Ui_acls∈Rh输入进全连接层(LINEAR)中,得到Ui∈Rn,如式(6)所示。
Ui=WV×Ui_acls+bV
(6)
其中,WV和bV为可学习的参数。
2.2.2 语境信息提取模块
语境信息提取模块的输入为Hcls。由于此时各个话语之间的信息仍是独立的,因此采用BiLSTM将对话中的话语信息有效地结合起来,将Hcls通过BiLSTM进行编码,获取包含上下文信息的话语表示,结果记为Db∈RN×h,如式(7)所示。
Db=BiLSTM(Hcls)
(7)
然后利用CNN来学习对话中的局部语境信息。将Db与Hcls相加输入进CNN,接着通过激活函数f(=ReLU)进行非线性变换,得到局部语境信息编码结果Dl∈RN×h,如式(8)所示。
Dl=ReLU(CNN(Hcls+Db))
(8)
接下来为了更充分地获取全局语境信息,可以通过注意力机制赋予不同话语权重来计算在一段对话中当前话语的重要程度。将Db与Hcls相加求和之后经过注意力机制编码,得到全局语境信息编码结果Dg∈RN×h,如式(9)所示。
Dg=Attention(Hcls+Db)
(9)
最后将上述各编码结果相加,送入全连接层(LINEAR),得到结果Do∈RN×n,如式(10)、式(11)所示。
其中,WQ和bQ为可学习的参数。
2.3 分类器层
在分类器层,将在对话层级信息提取层中语义信息提取模块提取出的单句语义信息编码结果进行拼接,获得完整的对话语义信息编码Ucls∈RN×n和Useq∈RN×n,再与语境信息的输出结果Do相加求和得到F,并使用softmax函数进行概率化,得到最后的分类预测结果Predict。如式(12)~式(15)所示。
3 实验设置
3.1 数据集
本文所采用的数据集来源于CCL2020评测任务三情景喜剧笑点识别(3)https://github.com/DUTIR-Emotion-Group/CCL2020-Humor-Computation,其公开的数据集涉及两种语言,英文数据来自情景喜剧《老友记》,中文数据来自情景喜剧《我爱我家》。本文实验基于中文语料进行,数据集规模如表1所示。任务根据场景变化将情景剧的对话结构分为对话和话语两个层级,从表2可以看出,其中每一段对话包含若干个有序出现的话语。每个话语存在幽默标签,标签0表示非幽默,标签1表示幽默。

表1 数据集规模

表2 数据集示例
3.2 评价指标
3.2.1 话语级评价指标
话语级的幽默识别任务可视为二分类任务,模型需要预测出每个话语中的幽默标签(幽默或非幽默),因此在该层级采用F1值进行评价,计算如式(16)所示,其中,P表示精确率(Precision),R表示召回率(Recall)。
(16)
3.2.2 对话级评价指标
在对话层级,每段对话的长短(包含的话语个数)不同,而本文期望模型对于不同长度的对话中的幽默标签都能进行有效的预测,因此在此层级使用准确率(Accuracy)进行评价。即首先计算每段对话的准确率,再对所有对话计算均值得到该级别评价指标。如式(17)、式(18)所示。
(17)
(18)
其中,Acci表示第i段对话上的平均准确率,Accavg表示所有对话上的准确率。
3.2.3 最终得分
模型的整体效果由F1和Accavg综合决定,使用Score表示,如式(19)所示。
Score=F1+Accavg
(19)
3.3 参数设置
本文使用BERT作为预训练模型,版本为Chinese_wwm_ext(4)https://github.com/ymcui/Chinese-BERT-wwm,隐藏层维度为768,丢弃率设置为0.15。BiLSTM中的隐藏层维度设置为384,丢弃率设置为0.15。CNN中卷积核设置为3,丢弃率设置为0.3。注意力部分使用多头自注意力机制,头数设置为8,丢弃率设置为0.1。最大话语长度设置为64,批量大小为1,梯度累加步数为5,优化器为Adam,学习率设置为3e-5,损失函数使用交叉熵,由于数据集中样本不均衡,因此在损失函数中对正负样本的损失设置了不同的权重,正例权重设为2.0,负例权重设为1.0,以减轻数据不均衡的影响。同时为了消除语料划分对模型性能造成的影响,实验采用k折交叉验证的方法进行评估,k取值为5。在对话层级信息提取层选取的隐藏层为模型的最后2层输出结果。
4 实验结果与分析
本文基于3.1节的数据集,采用五折交叉验证的方式进行实验,验证本文所提方法的有效性。为了与前人相关工作进行对比,本文复现了文献[12]与文献[15]的工作,实验结果如表3所示。
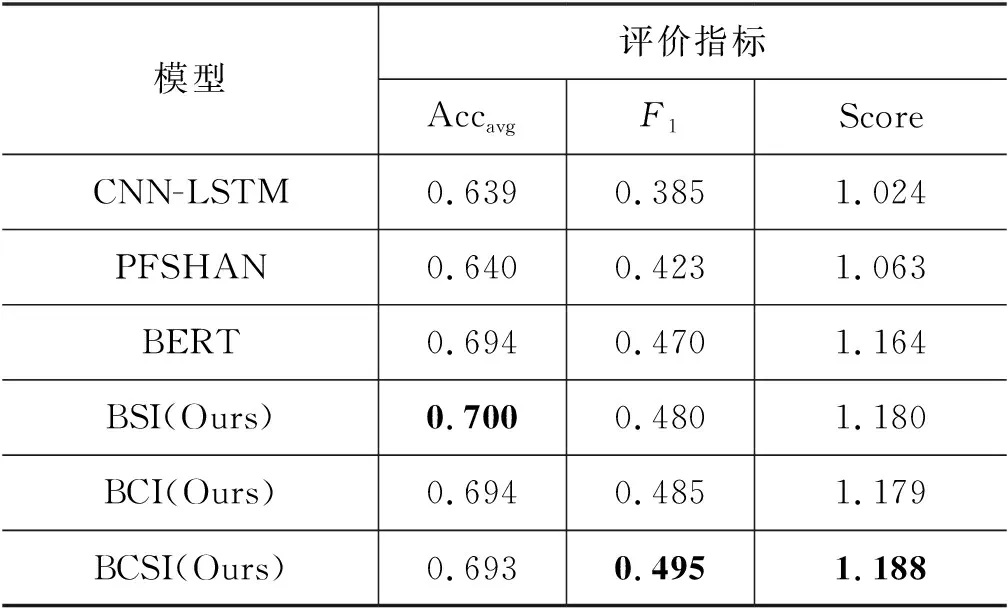
表3 不同模型的幽默识别实验结果
(1) CNN-LSTM[15]
CNN-LSTM是关于对话幽默识别的先进研究成果。本文复现了文献[15]中所提出的模型,但未加入Tirgram特征、发言人语速特征、反义词特征及词情感分数特征。
(2) PFSHAN[12]
PFSHAN是单句幽默识别先进研究成果。本文复现了文献[12]中所提出的模型,但是在特征方面未使用语音特征以及歧义词等级向量特征。
本文所提出的方法为:
(1) BERT
本文采用BERT模型进行对话幽默识别,将每句话语输入进BERT进行编码,得到每句话语的基本表示后取BERT输出中[CLS]位置的编码结果送入分类器进行分类。
(2) BSI(Ours)
本文所提出的模型BSI(BERT_based model with enhanced Semantic Information),包含BERT语义编码层、对话层级信息提取层中的强化语义信息部分和分类器层。
(3) BCI(Ours)
本文所提出的模型BCI(BERT_based model with enhanced Contextual Information),包含BERT语义编码层,对话层级信息提取层中的强化语境信息部分和分类器层。
(4) BCSI(Ours)
本文所提出的模型BCSI(BERT_based model with enhanced Contextual and Semantic Information),包含BERT语义编码层、对话层级信息提取层和分类器层。
首先从表3可以看出,相较于PFSHAN模型和仅使用了预训练词向量的CNN-LSTM模型而言,不论在单句幽默识别中还是在对话幽默识别中使用了BERT的模型整体效果要优于以上两种模型,这说明预训练语言模型提取对话中幽默特征能力更强。
其次相较于仅使用BERT的幽默识别模型而言,本文所提出的模型从语境与语义信息两方面强化对话中的幽默特征,在对话层级信息提取层中语境信息提取模块与语义信息提取模块都做出了一定的贡献。
BSI模型主要用于强化对话中的语义特征,相较于BERT模型准确率从69.4%提升至70%,F1值从47%提升至48%。这表明经过语义信息提取层后,模型学到了更多对话语义级别的特征,这些特征帮助模型提高了对话幽默识别的能力。
BCI模型主要用于强化对话中的语境特征,相较于BERT模型F1值从47%提升至48.5%,准确率保持不变,这也可以表明经过BCI模型后所提取的语境信息对于对话识别幽默能力也具有提升作用。
最后,从整体上来看,融合语境与语义信息的BCSI模型相较于BSI模型与BCI模型,在综合评价指标上分数分别提高了0.8%和0.9%,F1值分别提升了1.5%和1%,这表明结合语境与语义信息的BCSI模型对于对话中的幽默识别能力更强,也可以证明本文提出方法的有效性。
5 典型案例分析
为了进一步分析实验结果,本文随机选取了实验数据中的4段对话,共118句话语,并标注了每条话语的幽默表现形式。
模型整体的分析结果如表4所示,表头中第一列表示人工标注的话语幽默类型结果,“BERT”表示仅使用BERT模型所预测的结果,“BCSI”表示本文所提出模型的预测结果。经统计共38句笑点句,幽默占比32.2%,其中单句幽默占比13.6%,语境幽默占比18.6%。相较于BERT模型在这两类幽默的预测结果,本文所提出的BCSI模型准确率更高,这再次说明了本文所提出模型的有效性。

表4 不同模型幽默识别能力分析
具体案例如表4、表5所示。表4为单句幽默的具体案例,表5为语境幽默的具体案例。表头中“真实标签”表示语料库中标注的幽默标签,“BERT”表示仅使用BERT模型所预测的结果,“BCSI”表示本文所提出模型的预测结果。
在表5中,第1句由王总所说的话语引用了俗语,用自嘲的口吻说出来自己团队的战斗力不够强,属于单句幽默。第3句由大个儿所说的话语使用了“哎呀妈呀”这样的口头禅,并将话语内容转折起到了幽默的效果。
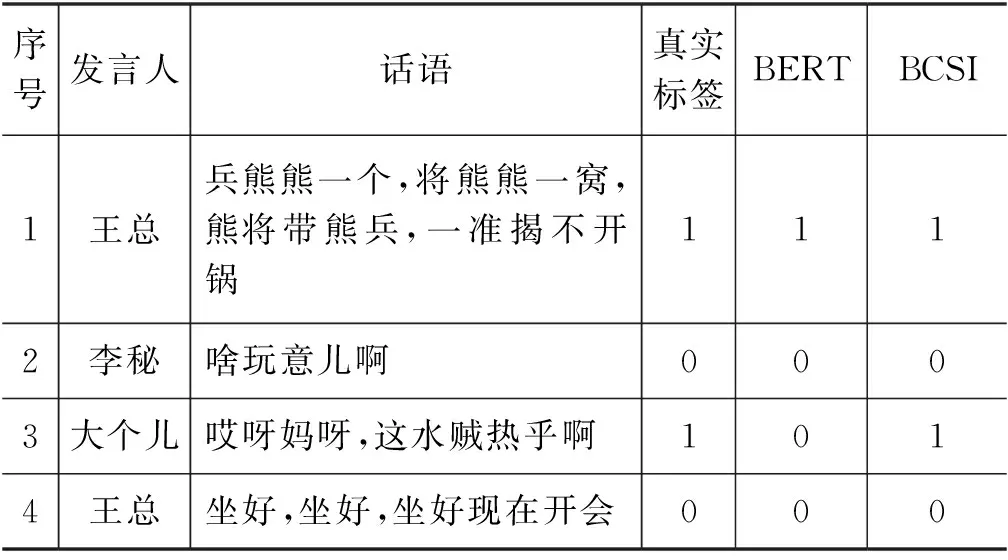
表5 单句幽默识别案例
在表6中,第3句由傅明所说的话语承接上文李大妈的话进而回复,略带无奈的表达引起了笑点。
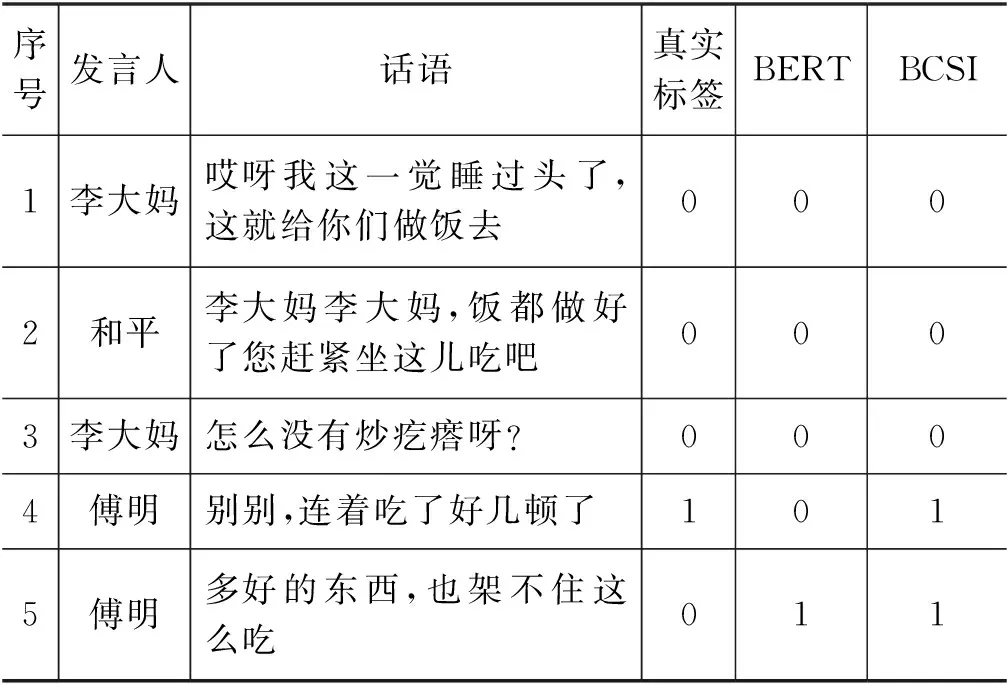
表6 语境幽默识别案例
从这两个案例中进一步可以看出,本文所提出的强化语境和语义信息的幽默识别模型BCSI相较于BERT基线模型而言,在单句幽默和语境幽默的识别上的性能更好。
6 总结与展望
对于对话幽默识别任务,本文结合对话结构特征提取对话幽默特征,提出了基于BERT的强化语境与语义信息的对话幽默识别模型。模型首先使用BERT对发言人信息及话语信息进行编码,其次分别使用句级别的BiLSTM、CNN和Attention机制强化语境信息,使用词级别的BiLSTM和Attention机制强化语义信息。实验结果表明,相较于对比模型,本文提出的模型在幽默识别方面有了一定的效果提升,但仍然存在一些不足。首先没有利用上对话参与者的人际关系信息,当不同发言人进行沟通时由于角色关系的差异可能会导致幽默表达方式的不同,如何引入角色关系提升幽默识别的性能是本文下一步工作的重点。其次本文未充分利用相关工作中所提及的用于识别幽默的语言学特征,这些特征能否提升本文模型的性能也值得进一步尝试。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年13期)2022-05-10
航天工业管理(2020年9期)2020-12-28
军事运筹与系统工程(2020年1期)2020-09-11
廉政瞭望(2019年5期)2019-06-10
长江学术(2016年4期)2016-03-11
时代英语·高二(2015年2期)2015-05-18
时代英语·高二(2015年1期)2015-03-16
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
