
针对重用掩码AES 算法的随机明文碰撞攻击
2022-06-16 05:24:34赵秉宇王柳生张美玲
计算机工程 2022年6期
赵秉宇,王柳生,张美玲,2,郑 东,2
(1.西安邮电大学 网络空间安全学院,西安 710121;2.西安邮电大学 无线网络安全技术国家工程实验室,西安 710121)
0 概述
密码算法在加密设备上进行实现,加密设备在执行算法的过程中不可避免地会泄露不同形式的物理信息,例如能量消耗、电磁辐射、声音等,这些信息统称为侧信道信息。侧信道攻击是密码学研究的热点方向,自从KOCHER 在1996 年提出计时攻击思想以来[1],研究人员提出了大量侧信道攻击方法,例如差分能量分析攻击[2]、碰撞攻击[3]、相关能量分析攻击[4]、模板攻击[5]等。随着侧信道攻击方法的出现,与其相关的能量迹定位方法[6]和侧信道信息泄露评估方法[7-8]也陆续被提出。侧信道分析攻击能够从物理信道泄露的能量消耗等物理信息中获取密码设备运算时与密钥相关的中间值信息,并且能够分段恢复较长的密钥,对加密设备造成了很大的安全威胁。
碰撞攻击是侧信道攻击中的一种,关注的是加密设备在加密或解密过程中算法中间值是否存在碰撞,即是否出现相同的中间值,可以从泄露能量中有效地提取密钥相关信息。2003 年,SCHRAMM 等[3]提出针对数据加密标准(Data Encryption Standard,DES)的侧信道碰撞攻击。2004 年,SCHRAMM 等[9]又提出针对高级加密标准(Advanced Encryption Standard,AES)的列混合变换输入字节的碰撞检测攻击方法。2007 年,BOGDANOV[10]提出针对AES的线性碰撞攻击,该方法改进了SCHRAMM 等提出的针对AES 的碰撞检测攻击。在实际应用中,为了抵抗侧信道攻击[11-12],加密设备[13-14]一般会采取一系列的对策,掩码技术[15-16]就是其中一种。2010 年,MORADI 等[17]提出一种能够识别使用掩码技术的AES 算法S 盒间碰撞的方法。2011 年,CLAVIER等[18]利用重用掩码的特点,建立不同的S 盒间带掩码数据的碰撞关系。2012 年,BOGDANOV 等[19]提出一种将DPA 和侧信道碰撞攻击相结合的攻击方法,大幅提高了碰撞攻击效率。2019 年,NIU 等[20]提出一种能抵抗3 种典型掩码方案的碰撞攻击思路,利用掩码和被掩码数据处理方式相同的特点,选择AES 的列混合变换作为攻击点并实现了很好的攻击效果;DING 等[21]提出自适应选择明文碰撞攻击,通过建立能量迹欧氏距离与中间值汉明距离的联系,用能量迹泄露的距离信息减小密钥候选值空间;ZHENG 等[22]提出基于假设检测的侧信道碰撞攻击,利用假设检测方法确定一个合理的碰撞阈值,该方法提高了碰撞检测的成功率。
文献[18]提出的改进型相关性碰撞攻击需要预先确定1 个碰撞阈值,通过比较2 段能量迹之间的相关系数和碰撞阈值之间的大小关系来确定是否发生碰撞,阈值的准确性会影响碰撞检测的成功率,进而影响攻击的成功率。该攻击方法只能利用能量迹中发生碰撞的信息,未发生碰撞的信息会被忽略。文献[21]提出的自适应选择明文碰撞攻击在攻击之前需要攻击者拥有一个和目标设备相同的设备用于建立攻击模板,实施复杂且具有一定的局限性。由以上分析可知:文献[18,21]中提出的方法都需要控制每次加密的明文,在攻击者不能操作和目标设备相同的设备并且只能获得一定数量的随机明文和对应能量迹的情况下,这2 种方法均会失效。
本文基于重用掩码AES 算法任意2 个S 盒之间输入的汉明距离和欧式距离之间的关系[21],提出一种高效的随机明文碰撞攻击方法。该方法无需预先确定碰撞阈值及建立攻击模板,即可有效利用能量迹中未发生碰撞的信息。此外,该方法属于随机明文攻击方法,因此当攻击者不能对目标设备进行操作时也可实施攻击。
1 相关工作
1.1 汉明重量模型
汉明重量模型[5]是指设备泄露的能量与被处理数据的汉明重量相关,计算公式如下:

其中:q表示能量迹采样点的序号;tq表示对数据x进行处理时在采样点q处泄露的能量消耗值;sq表示采样点q处的系数;rq表示对应能量迹在采样点q处的噪声,并且服从正态分布;HW(x)表示求x的汉明重量。
1.2 重用掩码方案
重用掩码方案在AES 算法加密的每一轮中仅产生2 个随机掩码值,在同一轮中16 个S 盒的输入用同一掩码,16 个S 盒的输出用同一掩码,也就是在一轮中只需要预计算1个新的S 盒置换表S′。新的S 盒置换表与普通的置换表之间的关系为S′(xi⊕mask1)=S(xi)⊕mask2,其中,i∈[1,16],mask1是S 盒的输入掩码,mask2是S 盒的输出掩码,重用掩码方案的框图如图1 所示。

图1 重用掩码方案框图Fig.1 Block diagram of reused mask scheme
1.3 汉明距离和欧式距离
汉明距离是指使用重用掩码的AES 算法同一轮加密中2 个S 盒的输入之间的汉明距离。如图2 所示,2 个不同的S 盒的输入分别为x1⊕mask1和x2⊕mask1,那么它们之间的汉明距离就是x1=p1⊕k1和x2=p2⊕k2之间的汉明距离,即HD(x1,x2),其中HD(x1,x2)表示求x1和x2之间的汉明距离。
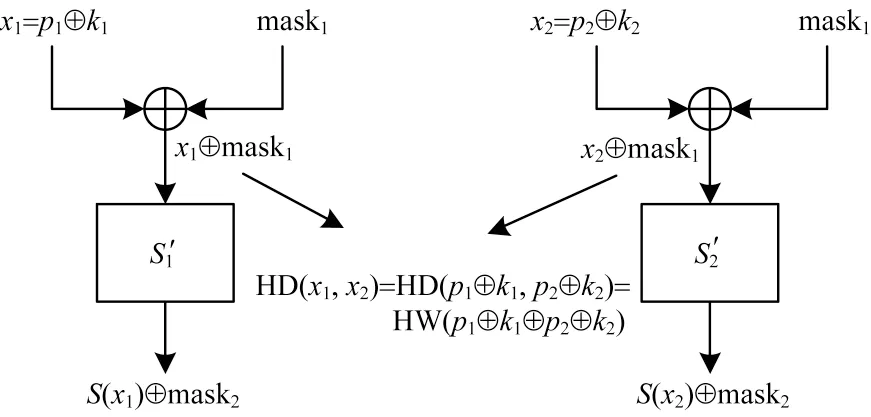
图2 汉明距离示意图Fig.2 Schematic diagram of Hamming distance
欧氏距离计算以前2个S盒为例,对1个明文加密,采集其对应的能量迹,将能量迹中对应于图2 中处理数据x1⊕mask1和x2⊕mask1的2 段能量迹分别截取出来并对齐,然后根据式(2)计算欧氏距离ED(x1,x2)。
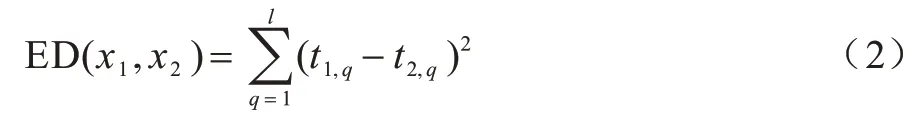
其中:ti,q是第i个S 盒所对应的能量迹中的第q个采样点的采样值,l是第i个S 盒所对应的能量迹中的采样点的个数。通过式(2)可以看出,欧氏距离本质上就是采用最小二乘法计算同一轮加密中2 段能量迹之间的累积距离。
在本文中,如果没有特殊说明,则汉明距离均指使用重用掩码的AES 算法同一轮加密中2 个不同S盒的输入之间的汉明距离,欧氏距离均指同一轮加密中2 个不同S 盒的输入位置所对应2 段能量迹间的累积距离。
1.4 汉明距离和欧式距离之间的关系
对同一Δhd下的N个明文进行加密,分别求每个Δhd对应的欧氏距离的均值,计算公式如下:
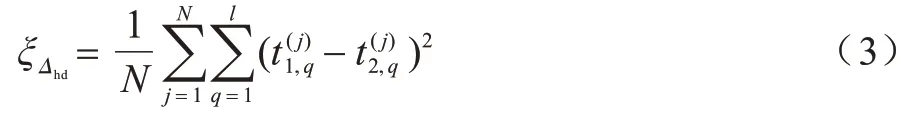

其中:sq是汉明重量模型中的系数;σ2是加密设备的噪声方差,该值对所有的采样点都是近似相等的。
由此可见,欧氏距离的均值和汉明距离之间满足线性关系。
2 攻击原理
2.1 欧式距离归类
使用猜测的汉明距离将欧氏距离进行归类,通过某个明文分别与256 个密钥异或值求得256 个猜测的汉明距离,利用这256 个猜测的汉明距离分别与该明文对应的欧氏距离进行归类。
假设某个随机明文的前2 个字节分别为p1=143、p2=59,其对应欧氏距离为ED(p1,p2)。如表1 所示,通过p1和p2以及猜测的密钥异或值Δ求得汉明距离HD,然后将HD 和Δ分别作为行号和列号对欧氏距离进行归类。对于明文p1和p2,通过Δ=0,1,…,255 分别可以求得汉明距离HD=4,5,…,4,假设第i行第j列位置处原来的累积欧氏距离为edi,j,则这次加密后对2 个S 盒之间的欧氏距离归类的结果如表1 所示,其中灰色位置为欧氏距离归类时的位置。从表1 可以看出,每个位置所存放的是累积欧氏距离,也就是在已经确定一个欧氏距离的位置之后,需要将该欧氏距离与这个位置原来的值相加,得到该位置处新的累积值。

表1 明文字节p1和p2对应欧氏距离归类后的结果Table 1 Results of Euclidean distance classification of plaintext bytes p1 and p2
2.2 归类结果分析
为方便归类结果的分析,使用式(5)来描述式(4)中汉明距离和欧式距离均值之间的线性关系。

其中:x表示实际的汉明距离;y表示x对应的欧氏距离的均值;a=和b=2σ2l是2 个常系数。由式(5)可以得到表2 中的欧氏距离的均值和实际汉明距离的关系。

表2 汉明距离和欧氏距离均值的对应关系Table 2 Relationship between Hamming distance and the mean of Euclidean distance
2 个明文字节的异或值是1 个8 bit 数据,对于1 个8 bit 的数据,共有28个可能值,这256 个值出现的概率相等且均为1/256。考虑所有256 个值,根据表2 描述的关系进行欧氏距离归类,令d表示猜测密钥异或值和正确密钥异或值之间的汉明距离。在归类后,首先计算表1 中每个位置累计欧氏距离的均值,然后计算表1 中第1 列数据与后面256 列数据的均值之间的相关系数ρ,得到表3 所示的结果。
通过式(6)计算2 个长度为n的向量X和Y之间的相关系数:
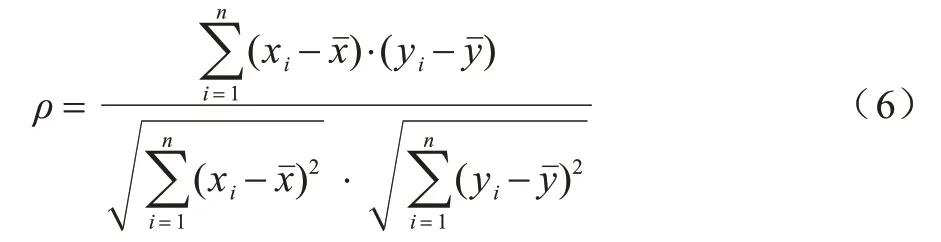
其中:xi和yi分别表示向量X和Y的第i个元素;分别表示向量X和Y中所有元素的均值。
从表3 中可以看出,在理论情况下,只有d=4 时的相关系数为0,其他情况下相关系数为1 或−1。表3 中的结果是理论情况下的相关系数,本文在实验仿真中发现,通过上述归类法处理数据后,不同的d会造成归类时欧氏距离分布的不均匀,从而影响欧氏距离的均值的准确性,最终影响相关系数的求取。相比于直接归类分析,将随机明文分成多组后归类可以得到更好的分析结果,分组归类的原理如图3 所示,首先将明文分成N组进行欧氏距离归类,然后将归类结果拼接在一起,最后求矩阵A中每个位置的均值,计算V和求均值后的A中每一列的相关系数。
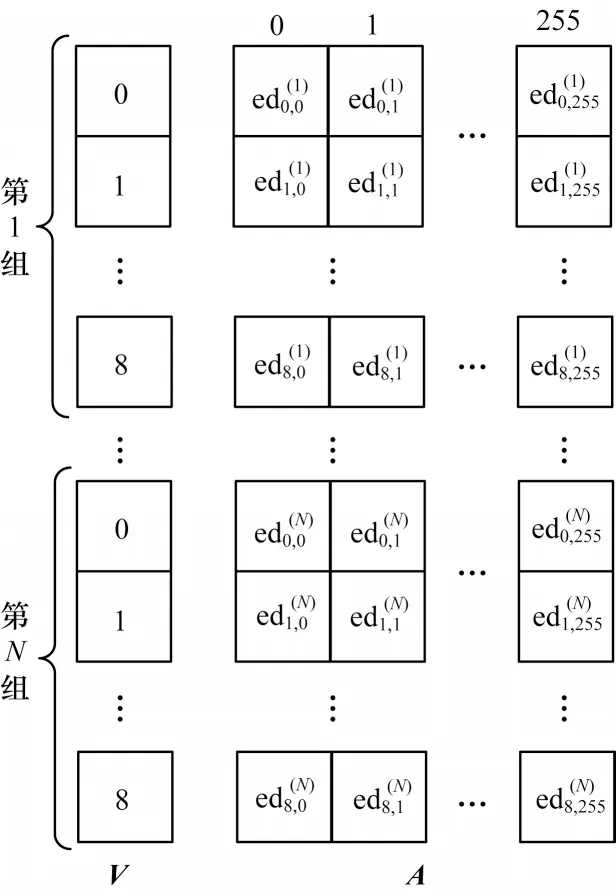
图3 欧氏距离的分组归类Fig.3 Grouping and classification of Euclidean distance
为验证在实际情况下由于d的不同对相关系数的影响,在噪声标准差σ=0.002 9 的情况下,加密10 组随机明文,每组包含50 000 个明文,设置密钥异或值Δ=85,通过仿真实验归类分析后进行排名。
表4 给出了排名前8 的猜测密钥异或值,可以看出这些值对应的d都很小。图4 给出了所有猜测密钥异或值对应求得的相关系数,可以看出:排名前93 个密钥异或值对应相关系数接近于1 且递减,对应于d为0、1、2、3 的情况;从排名93 开始相关系数突然变小,排名93 到164 对应于d为4 的情况,相关系数接近于0;排名164 到256 的相关系数接近于−1,对应于d为5、6、7、8的情况。图5 给出了这256 个排序后的密钥异或值所对应的d,可以看出:排名前10 的密钥异或值所对应的d比较小,为0、1、2;当d=3 时所对应的猜测密钥异或值位于排名36到93;93后为d≥4 所对应的猜测密钥异或值。
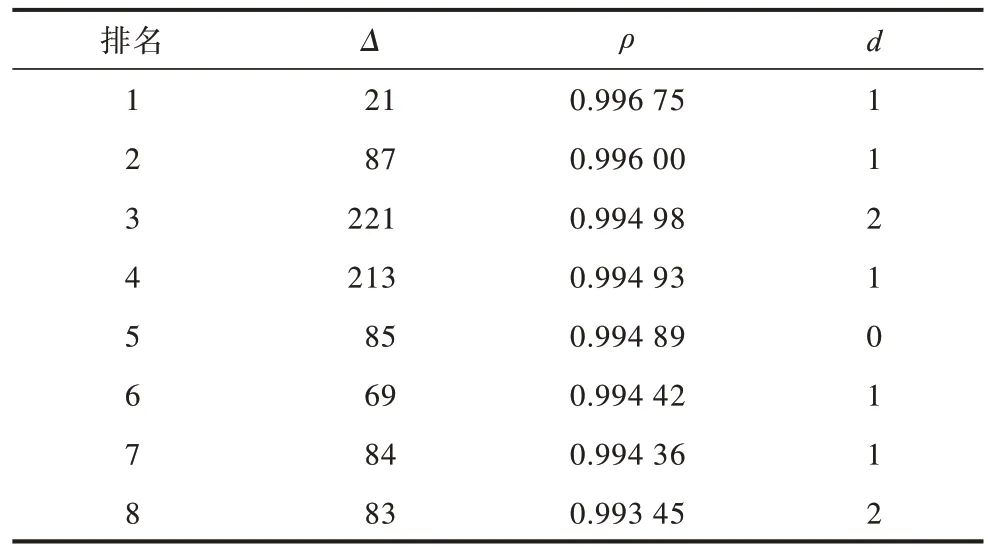
表4 排名前8 的猜测密钥异或值所对应的相关系数Table 4 Correlation coefficients corresponding to the top 8 guessed key XOR value
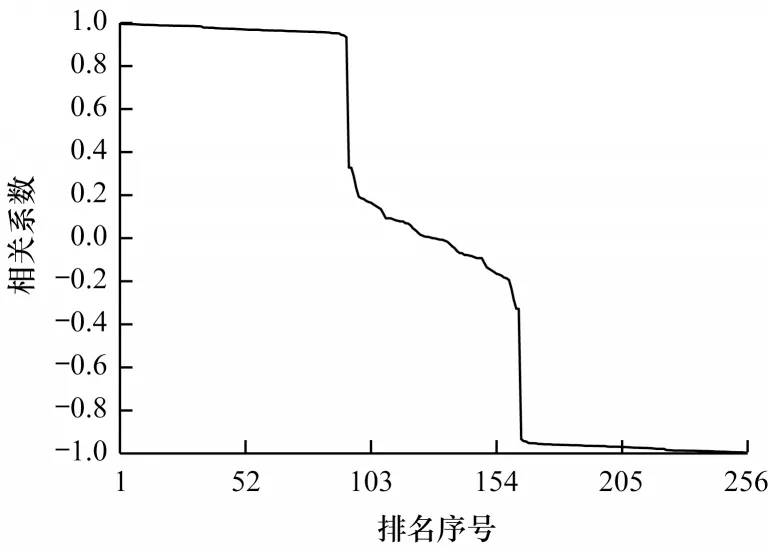
图4 归类分析后不同排名对应的相关系数Fig.4 Correlation coefficients corresponding to different rankings after classification analysis
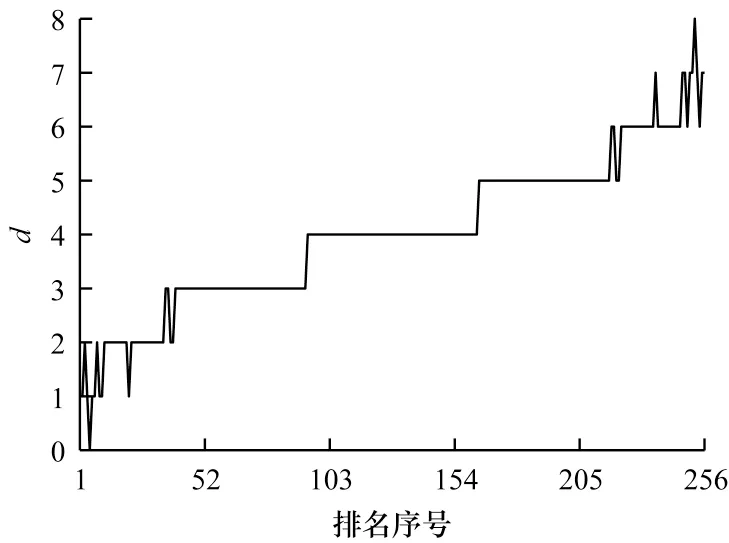
图5 归类分析后不同排名对应的d 值Fig.5 d values corresponding to different rankings after classification analysis
以上结果验证了在实际情况中,d的不同会对相关系数造成影响,且根据相关系数对猜测密钥异或值排序后的前10 个值所对应的d比较小,正确的密钥异或值排名会比较靠前。基于以上结论,可以首先通过归类分析法将正确密钥异或值所在范围缩小,然后本文攻击方法利用排名靠前的密钥异或值所对应的d比较小的特点提出投票法,从中进一步得到正确异或值。
3 攻击方法设计
3.1 实验平台介绍
采用ChipWhisperer[23]平台作为实验平台,所有实验均使用该平台采集的能量迹,然后用MATLAB对能量迹进行分析。ChipWhisperer 是一个开源平台,用于对硬件设备的安全性进行研究。如图6 所示,该平台包含主控板(左)和目标板(右)2 个模块。主控板用于采集和传输能量消耗,同时用来实现PC和实验板的数据传输以及密码算法的下载。目标板实现对数据的加密。该平台对于研究人员而言具有低成本、易操作的优点。

图6 ChipWhisperer 实验平台示意图Fig.6 Schematic diagram of the ChipWhisperer experimental platform
实验板主要有2 个对应的开源软件配合使用,分别是Capture 和Analyzer,前者用于加载加密算法、控制明密文以及捕获能量迹,后者提供了一些分析能量迹的脚本。图7 给出了Capture 软件能量迹采集示意图。
图7 Capture 软件能量迹采集示意图Fig.7 Schematic diagram of Capture software energy trace acquisition
不同的实验设备所对应的能量迹具有不同的噪声标准差,本文使用的平台噪声标准差σ为0.002 9,通过在能量迹上加入噪声来合理增加标准差。
3.2 攻击流程
本文方法的攻击过程包括线上能量迹采集阶段和线下数据分析阶段,具体攻击流程如下:
步骤1加密M个随机明文,采集对应的M条能量迹,并记录这M个随机明文。
步骤2将M个明文和M条能量迹分成N组,每组包含M/N个明文和M/N条能量迹。
步骤3将每条能量迹中对应于处理16 个S 盒输入的部分截取出来并对齐。
步骤4对每条能量迹求第1 个S 盒和第2 个S盒之间的欧氏距离,然后进行归类,并将归类后的矩阵拼接,得到如图3 所示的结果。
步骤5求矩阵A中每个位置的均值,计算向量V和求均值后的矩阵A中每一列的相关系数,根据相关系数将猜测密钥异或值进行降序排序。
步骤6用投票法将排序后排名前n的密钥异或值进行投票,筛选出票数最少的密钥异或值,该值是前2 个密钥字节k1和k2的异或值Δ1,2=k1⊕k2。
步骤7重复步骤4 到步骤6,对第1 个S 盒和另外14 个S 盒进行归类分析,最终得到如等式(7)所示的第1 个密钥字节和其他15 个密钥字节之间的线性关系,从而将密钥空间从2128缩小到28。

步骤8遍历第1 个密钥字节,从剩下的候选密钥中得到正确密钥。
3.3 针对前2 个S 盒的攻击
为验证本文方法的可行性,将对使用重用掩码方法的AES-128 算法进行攻击,攻击的目标点是第1 轮加密中前2 个S 盒的输入位置。在对采集的能量迹进行统计分析之前,需要将每条能量迹所对应16 个S 盒操作部分截取出来,如图8所示。由于第1轮中的16个S 盒操作的实现方式相同且依次执行,因此通过方差检测可以清晰地区分出16个S盒操作在能量迹中的位置。在确定16 个S 盒的位置后,对区间内的点进行攻击尝试,最终找到合适的8 个采样点。不失一般性,在噪声标准差σ为0.002 9 的情况下,设置前2 个密钥字节分别为k1=43、k2=126,共加密30 组随机明文,每组包含100 个猜测密钥异或值,选择排名1 到排名8 的猜测密钥异或值作为投票对象。
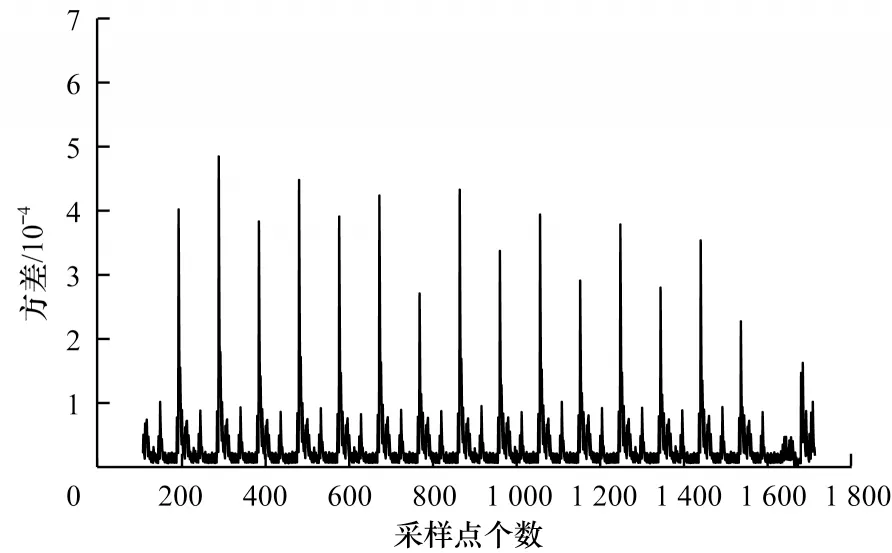
图8 AES 加密的第1 轮方差检测结果Fig.8 Results of the first round variance test of AES encryption
表5 给出了实施欧氏距离归类分析并根据相关系数排序后排名1 到排名8 的结果,可以看出这8 个猜测密钥异或值Δ与正确密钥异或值的距离d均较小,并且距离为0 时的正确密钥异或值也包含在其中。在密钥异或值候选空间被缩小后,用投票法筛选出正确密钥异或值。从第1 个值93 开始分别与另外7 个值求汉明距离,对于每个值将求得的7 个汉明距离相加作为该值的投票结果。因为排名靠前的猜测密钥异或值与正确密钥异或值的距离均很小,所以通过投票后得到的投票值最小的猜测密钥异或值就是正确密钥异或值。如图9 所示,对前8 个猜测密钥异或值分别进行投票,然后统计总票数。从图9 可看出,正确密钥异或值的票数是9,在前8 个猜测密钥异或值中最小。
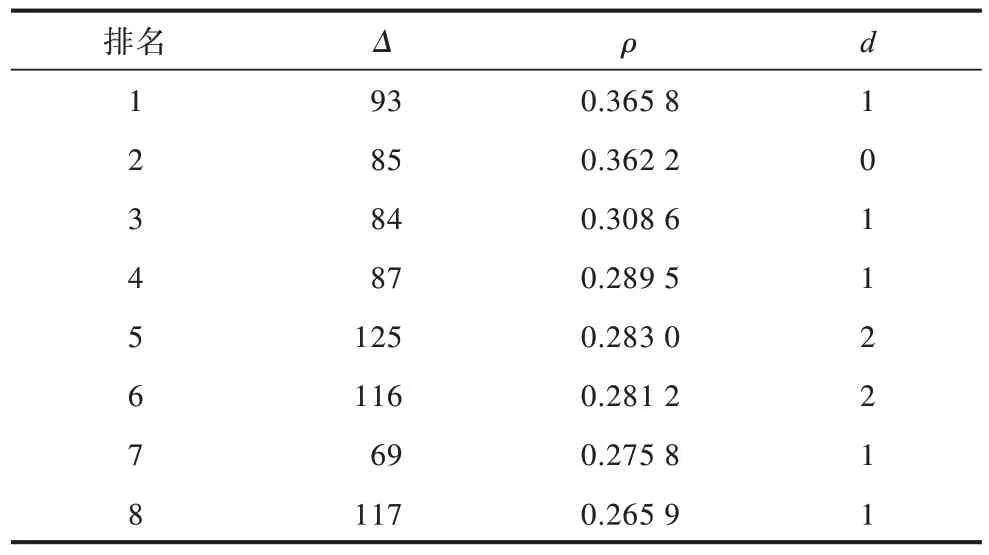
表5 前2 个S 盒归类分析排序后的结果Table 5 Results of classification analysis and sorting of the first two S-boxes

图9 排名前8 的猜测密钥异或值投票结果Fig.9 Results of the voting for the top 8 guessed key XOR value
3.4 攻击成功率统计与对比
为分析本文方法的效率,实验针对重用掩码AES-128 算法加密的第1 轮实施大量攻击后,统计成功率随着加密次数的变化曲线。在实际攻击中,控制明文分组为30,通过改变每个分组中随机明文的个数来统计成功率。为与其他方法进行对比,在相同的实验环境下实施另外3 种攻击方法并统计其成功率。
图10、图11 分别给出了本文方法与文献[18,21]方法在不同的噪声环境下的攻击成功率对比。文献[18]中提出针对重用掩码AES 算法的改进型相关性碰撞攻击(Improved Collision-Correlation Attack,ICCA),该攻击方法的成功率曲线对应图10、图11中的ICCA方法。文献[21]提出自适应选择明文碰撞攻击,使用最小二乘法(Least Square Method,LSM)和中心矩积法(Central Moment Product,CMP)这2 种方法来计算2 段能量迹的差,并利用自修正(Self-Correction,SC)错误机制,大幅提升了成功率,该攻击方法的成功率曲线对应图10、图11 中的SC_LSM 和SC_CMP 方法。
从图10、图11 可以看出:在噪声标准差σ为0.002 9 时,若要达到95%的成功率,则本文方法需要约1 600 条能量迹,其他3 种方法中成功率最高的SC_CMP 方法也需要约1 600 条能量迹;在噪声标准差σ为0.006 时,若要达到95%的成功率,则本文方法需要约4 000 条能量迹,其他3 种方法中成功率最高的SC_CMP 方法需要约5 000 条能量迹。

图10 针对重用掩码方案的攻击成功率对比(σ=0.002 9)Fig.10 Comparison of attack success rate for reused mask scheme(σ=0.002 9)
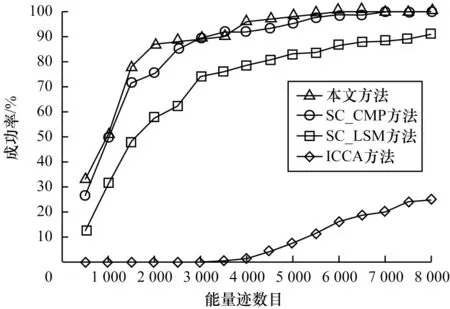
图11 针对重用掩码方案的攻击成功率对比(σ=0.006)Fig.11 Comparison of attack success rate for reused mask scheme(σ=0.006)
由此可见,本文方法相比于SC_CMP 方法,成功率的优势并不明显,但相比于其他3 种方法,除了不需要预先确定碰撞阈值及预先计算攻击模板外,最大的优势在于明文的随机性。当不允许攻击者操作与目标设备相同的设备且只可获得一定数量的随机明文和其对应能量迹时,其他3 种方法就无法实施攻击,因为文献[18,21]方法需要对选择明文进行加密,在攻击过程中需要对明文进行一定的控制,本文方法只需要获得一定数量的随机明文和其对应能量迹就可实施攻击,不需要攻击者主动控制明文,所以不会受到此因素的影响。
表6 从无需碰撞阈值、无需攻击模板、攻击过程简单、对重用掩码方案具有高效性、可利用未发生碰撞的信息、攻击者能够不操作目标设备等6个方面对本文方法和文献[18,21-22]方法进行对比,其中,√表示具备该性能优势,×表示不具备该性能优势。由表6可以看出,本文方法相比于已有方法具有一定的优势。
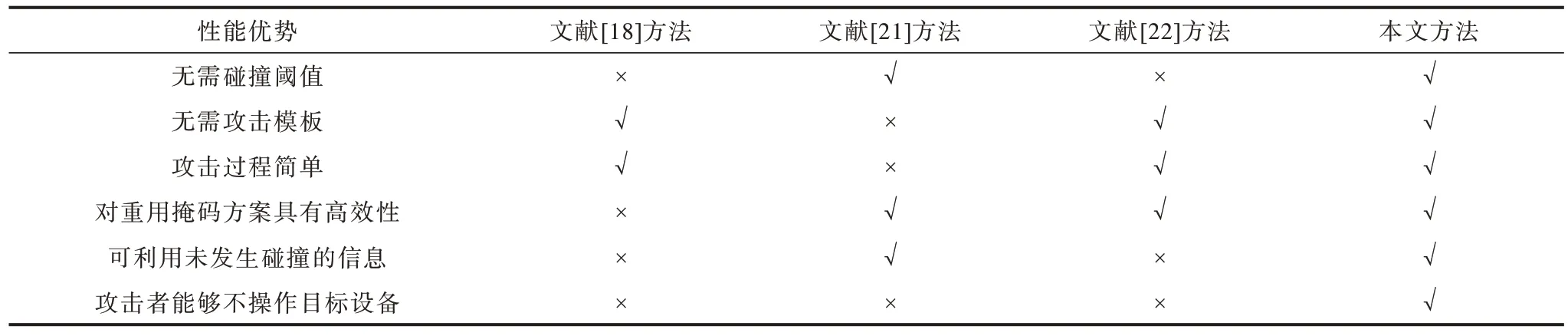
表6 4 种攻击方法的性能对比Table 6 Performance comparison of four attack methods
4 结束语
本文针对使用重用掩码技术的AES 算法,提出一种高效的随机明文碰撞攻击方法。利用能量迹中未发生碰撞的信息,采用重用掩码AES 算法S 盒输入的汉明距离和欧式距离的关系,从256 个密钥异或值中找出正确的密钥异或值。实验结果表明,与改进型相关性碰撞攻击、自适应选择明文碰撞攻击和基于假设检测的侧信道碰撞攻击方法相比,本文方法无需建立攻击模板及计算碰撞阈值,并且加密的是随机明文,实施简单。由于笔者通过分析发现采用多组明文进行实验可有效减少所需的明文总数,因此在后续工作中将研究明文组数对所需明文总数和成功率的具体影响,从而寻找到最优的明文组数。
猜你喜欢
通信学报(2019年5期)2019-06-11 03:05:56
通信技术(2018年3期)2018-03-21 00:56:37
中国铁路文艺(2016年6期)2016-05-14 08:13:13
星星·散文诗(2015年35期)2015-10-27 21:00:08
浙江大学学报(工学版)(2015年4期)2015-03-01 01:17:53
电子设计工程(2015年20期)2015-01-29 02:58:24
应用数学与计算数学学报(2014年4期)2014-09-26 12:16:00
自然资源遥感(2014年3期)2014-02-27 11:56:33
探索地理(2013年5期)2014-01-09 06:40:44
上海理工大学学报(2012年1期)2012-03-20 13:54:12
