
面向中小型企业的废水排放水质监测模型研究
2022-06-14 14:08薛梦瑶马金萍杜子龙
湖北农业科学 2022年10期
俞 武,薛梦瑶,何 斌,马金萍,杜子龙
(1.宁夏西干渠管理处,银川 750021;2.河海大学商学院,江苏 常州 213022;3.常州市大数据挖掘与知识管理重点实验室,江苏 常州 213022;4.常州兰陵自动化设备有限公司,江苏 常州 213002)
随着中国社会生产力、科学技术的发展以及产业结构向工业等领域调整,中国城镇化步伐不断加快,但一系列的环境问题也随之而来,其中水污染问题尤其突出。针对水资源保护问题,中国采取了一系列科学的法律手段,先后出台了多项规范和排污标准,包括《中华人民共和国水法》《中华人民共和国水污染防治法》《中华人民共和国环境保护法》等,以规范化和法制化手段合理利用水资源,不断完善中国水资源法律制度体系。
水污染会影响各类环境资源、破坏生态平衡,还会降低工业和农业生产质量,甚至危害人类生活和身体健康。纵观近年来的水污染现象,突发水污染事件占比较大,其中绝大多数是由于企业违规排放废水或工厂事故泄露所引起,而一些环保设备差、装备水平低的中小型工业企业最容易出现事故。因此,在国务院于2015 年印发的《水污染防治行动计划》中,第一点就强调了对工业污染的防治工作,尤其是对小型工业企业的排查,对小型企业的污水治理工作提出了更高的要求。但是污水监测的全套设备包括其运行维护费用每年高达50 万~60 万元,导致很多小型企业因无法承担该项费用而排放不达标废水,对人类安全造成极大的威胁。因此,寻找适合中小型企业污水水质等级监测的方法已刻不容缓。本研究基于某市河道水质数据,分析容易监测的水质指标与水质等级之间的关系,以决策树算法构建的水质等级监测模型对企业污水排放进行监控,有效替代传统采购价高、运行成本高的设备,减少费用压力,可以为企业、政府等相关部门提供方便、科学的排放废水监测体系,为中小型企业污水排放前的监测提供理论参考。
1 研究现状
1.1 水质等级监测研究现状
在水质等级监测研究中,主要以多种算法为基础,构建水质评价模型,并根据实践中的突出问题加以改进。张颖等[1]以流域的三大监测断面点为研究对象,采用灰色模型对水质的各个参考值进行预测,利用模糊神经网络方法构建水质预测模型,综合把握水质变化,达到了预警效果。高学平等[2]关注季节变化对水质指标权重的影响,以层次分析法创造性地提出时域权重矩阵,并将此与实测权重相结合,得到综合评价权重,设计改进的模糊综合评价法提高水质评价的准确度。肖金球等[3]针对水质监测系统在太湖应用中存在的数据和等级评价不准确的问题,提出一种改进型GA-BP 的神经网络,基于此可以辨识复杂的水质模型,以此消除干扰因素带来的误差。闫佰忠等[4]以地下水水质评价为对象,基于安阳市8 个监测点的数据,以随机森林设计水质评价模型,并与神经网络模型相比较,结果显示该方法的准确性与稳定性更高。张莹等[5]在大数据背景下聚焦于海洋水质评价,以机器学习算法为基础,以40 万站点和13 个水质指标信息为样本,构建海洋多水质指标信息的综合评价模型。
1.2 水污染溯源研究现状
随着中国城镇化不断发展,水污染现象逐年增加,水污染溯源研究被广大学者所重视,尤其是针对企业污水溯源的研究。Boano 等[6]针对任意分布源的水污染溯源和多个独立点源的水污染溯源,采用地质统计法对水污染事件进行回溯。Wei 等[7]利用AM 算法和正向模型的不确定性特征对水污染事件过程进行反演,针对水中污染物特征判断整个污染过程,在反演过程中寻求最终结果。李欣欣等[8]利用改进的AFSA 算法对构建的污染物时空溯源模型和排放总量模型进行求解,确定污染物排放量、排放位置和时间3 个参数,借助GIS 技术进行污染源企业排查清单的确定。王忠慧等[9]利用耦合的概率密度分析方法优化水力学模型,并采用BAS 算法进行求解,实现污染物源项信息的确定,有效减少计算量并提高了精准度。孙策等[10]利用贝叶斯和蒙特卡洛相结合的方法,基于已知污染源信息,利用函数求得污染源的概率密度,将溯源问题转化为求概率密度的抽样问题,使结果更有效快速地接近目标。吕清等[11]以南方某市S 河的一次水质异常事件为例,对水纹识别技术在水污染溯源中的实际应用进行验证,根据水纹峰变化推断入侵过程,比对水体水纹与污染源水纹,最终实现溯源。
1.3 决策树算法应用研究现状
决策树算法以其速度快、精确度高等特点,已被学者们应用到各行各业的研究中。Chandra[12]将决策树创造性应用于地质学领域,用以确定发生滑坡的概率,选用地质构造、坡度等9 个主要因素进行分析,生成滑坡敏感性图,结果表明该图可以用于中等规模和区域的规划中。Arlita 等[13]在运输领域,采用决策树方法开发选择模型,以确定最佳货物运输方案,为公司业务发展提供合理计划。杨泉[14]将决策树算法应用到汉语短语关系分类上,建立7 个分类特征,在自建库中生成决策树,以投票给出最终结果,并采用1 020 条数据进行测试,正确率高达94.8%。刘晓娜等[15]主要将其应用到解决橡胶林地的遥感识别,以Landsat MSS/TM/ETM 数据和MODIS-NDVI 数据为基础,利用决策树方法构建简单快捷的橡胶林地分类方式,提取所需地区的橡胶林地,有助于生态保护和土地合理开发利用。程华等[16]利用C4.5 决策树方法解决港航班延误预测问题,构建预测模型,并以中国某大型机场数据为例,进行大量试验验证其正确率。王焱[17]在对国内外行人检测的研究现状进行分析后,创造性地提出将梯度提升决策树算法应用于行人检测中,并与区域建议网络相结合,设计出可以用于检测不同尺度行人的检测算法。
2 数据来源与研究方法
2.1 数据来源
本研究水质数据来源为某市20 条河流的监测数据,时间跨度为2018 年1 月至2020 年8 月,数据中包含了纬度、地区、水质等级、高锰酸盐指数、氨氮、总磷、pH、水温、溶解氧、浊度、电导率、总氮、数据时间等属性。对排放废水历史水质数据进行分类和关联分析,探究其中容易监测的水质指标与水质等级之间的关系,经过筛选后,选择特征属性以构建水质等级分类模型。
2.2 研究方法
在构建水质等级分类模型时主要采用决策树算法对水质进行分类。决策树算法是为了解决ID3 算法忽略对叶子数目的研究而提出的一种改进算法,是通过一系列规则对数据进行分类的方法,其基本原理是通过归纳学习训练集的规律生成相应的决策树,用所生成的决策树规律对新的数据进行分类。该算法具有速度快、准确性高、可处理连续字段和种类字段等优点[18]。
决策树主要表现为树形结构,包括一个根节点、若干个内部节点和若干个叶子节点,其中每个内部节点代表一种属性测试,每个叶子节点代表一种决策结果。节点之间通过分支进行联系,每个分支代表一种测试输出。同时决策树也代表了对象值与其属性之间的映射关系,其中对象用节点表示,每个从根节点到叶子节点之间所有的路径代表对象值,而每个分支则代表可能的属性值。具体的决策树结构如图1 所示。
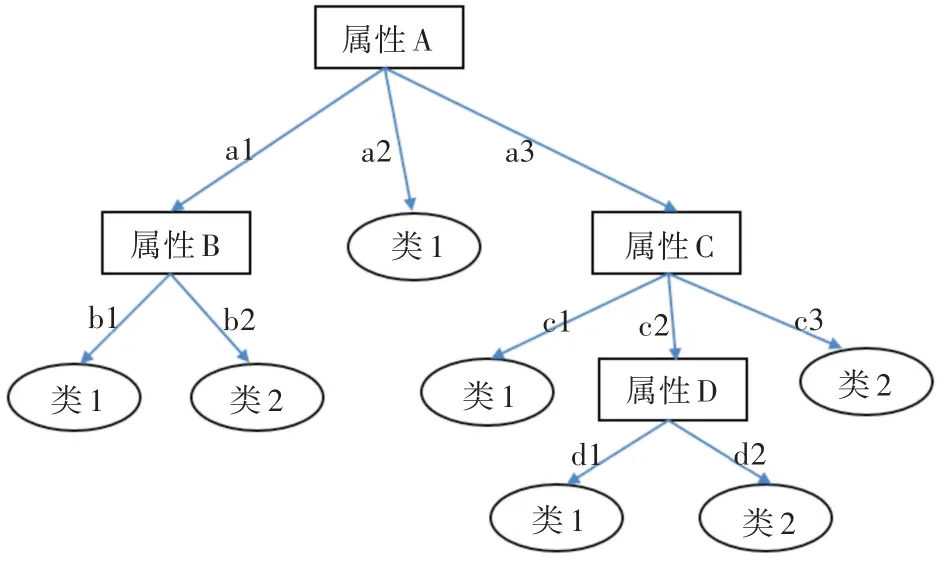
图1 决策树结构
一棵决策树生成的过程也就是决策树的学习过程,主要分为特征选择,决策树生成和决策树剪枝3个步骤。首先进行特征选择,从训练数据样本中选择特征作为节点分叉标准,其中特征的选择具有不同的选择标准,评估标准不同最终的决策树算法也不同;接着进行决策树的生成,根据之前选择的特征标准,对训练数据采用从上至下的递归法生成子节点,直至分叉结束;最后是决策树修剪过程,由于决策树易因过拟合现象而导致分类有误,因此在决策树生成后要进行树枝的修剪过程,通过减小树的结构达到解决过拟合的问题。
3 基于决策树算法的水质等级分类模型构建
3.1 水质等级监测模型的属性选择
决策树中含有多个特征属性,但只有一些特征属性对分类起到关键作用,影响水质类别的所有特征对其分类具有不同的敏感程度,特征的选择对模型的准确度和效率具有直接影响。传统的水质等级评价会选择pH、溶解氧、高锰酸盐指数、氨氮等30多种评价指标作为特征属性,但很多中小型企业由于资金原因无法购置和运行全套的水质评价仪器,使工厂排放的废水未经过等级评价便排放到河道中,导致污染物超标,劣Ⅴ类水增加。因此,在对水质等级与各因素之间的影响程度以及各种组合结果的对比后,最终选择温度和总磷作为最终的特征属性。其中总磷是指水中所有形态磷的总量,是反映水体质量和污染程度的重要指标。在水体中,磷一般以磷酸盐和有机磷的形式存在,绝大多数来源于企业污水中磷的使用。磷是水中最主要的影响元素,是促进水中生物和微生物生长的关键因素,若磷过于富集,则会导致水体质量下降。对中小型企业排放废水中总磷的监测和分析,可以辨别水质的污染程度,了解水质的富营养化状况,因此总磷是水质分析中的必测项目,是评价水质的重要因素,选择磷作为特征属性具有一定的理论和实际支撑。
测定总磷含量的国家标准是钼酸铵分光光度法(GB 11893-89)。该方法的主要原理是,首先在保持中性的水环境下,用过硫酸钾或者硫酸-高氯酸对水样进行消解操作,使水样中所有形态的磷转化为正磷酸盐,接着在酸性介质中,让消解的正硝酸盐与钼酸铵发生反应,从而保持在锑盐存在的条件下将生成的磷钼杂多酸立即用抗坏血酸还原生成蓝色的络合物,最后在700 nm 条件下进行吸光度测定。
3.2 水质等级监测模型的建立
水质等级的分类模型是指从已知的水质数据中利用决策树分类算法,将水质类别分类中的规律提取出来的过程,其中已知类别的数据称为样本数据,可以分为训练集和测试集两部分。在建立水质等级分类模型过程中,首先根据需求和数据特点选择决策树算法作为分类模型;接着将训练集数据作为算法输入值,总结归纳分类标准后输出相应的分类模型;最后利用测试集数据验证分类模型的准确性和有效性,使用构建的分类模型将测试数据进行分类,完成后与实际分类情况比对,统计最终的准确率,若准确率达到要求的标准,则认为该模型可作为水质分类模型,否则需要重新构建,其具体的流程如图2所示。
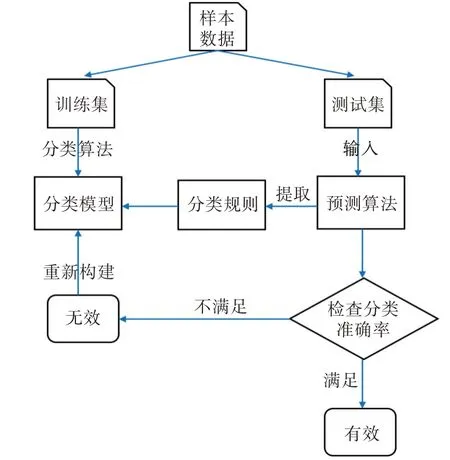
图2 分类模型构建流程
4 面向中小型企业的废水排放水质监测模型构建
面向中小型企业的废水排放水质监测模型是基于水质等级分类模型建立的。对企业而言,定期对废水进行取样,测定废水的温度以及其中的总磷含量,将数据输入构建的基于决策树算法的水质等级分类模型中,输出相应的水质类别,判断是否符合排放标准,若符合记录数据后可以要求进行排放程序,若不符合则需要进行再次处理,重复此过程直至废水达到排放标准。而对政府相关部门而言,在进行废水排放水质抽查时,首先将监测到的数据输入基于水质等级分类的模型中,判断企业排放的废水是否符合标准,是否对水体造成了污染,若初步监测符合标准则记录在册,若结果不符合,水质的类别低于Ⅲ类水质或当地标准,则将样水送至相关机构,采用专业设备进行监测后,再次判断是否符合标准,一旦发现不符合则根据相关政策对企业进行罚款、教育等。该模型有效降低了中小型企业和政府对废水排放水质的监测费用,有效防止企业偷排超标废水的行为,减少水体污染现象。其具体模型如图3 所示。
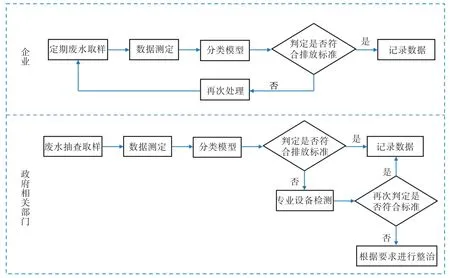
图3 中小型企业的废水水质监测模型
在构建决策树的过程中,需要找出最佳节点和最佳分支方法,衡量这个“最佳”的指标叫作“不纯度”。通常来说,“不纯度”越低,决策树的拟合效果越好。参数Criterion 是用来决定“不纯度”的计算方法。在sklearn 库中提供了entropy(信息熵)和Gini Impurity(基尼系数)2 种计算方法。使用的决策树算法在分支方法上的核心大多是围绕在对某个“不纯度”相关指标的最优化上。“不纯度”是基于节点来计算的,树中的每个节点都会有一个“不纯度”。信息熵相较于对“不纯度”的处理更加敏感,当使用信息熵作为指标时,决策树的生长会更加“精细”,对于高维数据、噪音很多的数据,信息熵容易发生过拟合现象,而基尼系数在这种情况下的效果要优于信息熵,本研究选择基尼系数计算“不纯度”。
在构建模型时可以对特征标签重要性进行可视化,结果发现总磷的重要性为0.960 20,水温的重要性为0.039 78,可见总磷相较于温度,对水质等级的影响更大,也更直接。同时为了方便构建决策树模型,将Ⅰ类、Ⅱ类、Ⅲ类、Ⅳ类、Ⅴ类、劣Ⅴ类6 个水质等级分别用数字1、2、3、4、5、6 替代。最终生成决策树的部分结构如图4 所示。
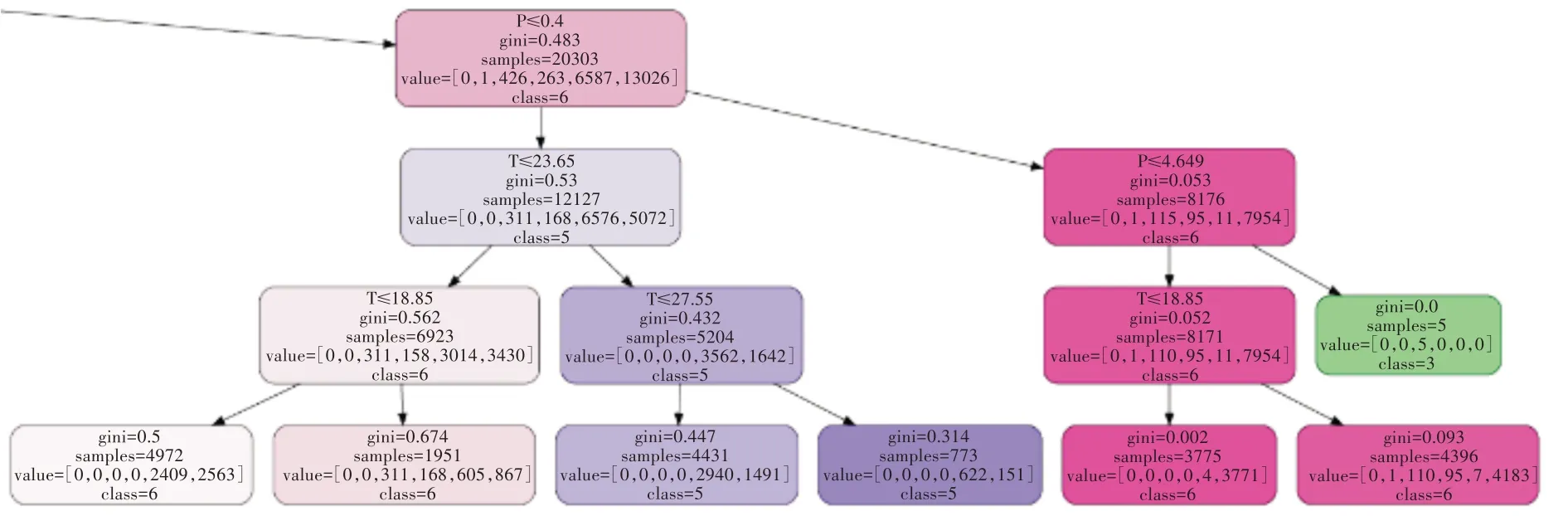
图4 决策树分类模型部分结构
图4中每个方格代表一个节点。在最上面的节点中,P≤0.4 代表下面分支的判断条件,即总磷含量小于等于0.4 mg/L,左分支为True,右分支为False;gini 是“不纯度”的指标,gini 值越小,分类效果越好;samples 代表当前节点对应的样本数量,values 代表训练集数据中不同标签值对应的样本数量,如values=[0,1,426,263,6 587,13 026]代表Ⅰ类、Ⅱ类、Ⅲ类、Ⅳ类、Ⅴ类、劣Ⅴ类的样本数量分别为0、1、426、263、6 587、13 026 个;class 代表当前节点的标签预测值,如class=6 代表当前节点的预测值为劣Ⅴ类水。
5 应用测试与分析
对决策树进行评估时最常用的标准是预测正确率。训练集共有50 206 条数据,使用决策树对水质等级进行预测,预测正确数据为39 443 条,正确率为78.56%;模型的训练集得分低于测试集,为72.87%。表1、表2 为模型预测情况的评价指标统计。
在计算评估指标时,样本被分为4 类,分别为TP(True positives)、FP(False positives)、FN(False negatives)、TN(True negatives)。TP 是指将正类判定为正类,FP 是指将负类判定为正类,FN 是指将正类判定为负类,TN 是指将负类判定为负类。其中精确度的计算公式为TP/(TP+FP),召回率的计算公式为TP/(TP+FN),加权调和平均值的计算公式为2TP/(2TP+FP+FN)。以Ⅲ类水为例,正类数据指Ⅲ类的数据,负类数据指除Ⅲ类之外其他等级的数据。当水质等级预测全部正确时,Ⅲ类水对应的样本数量应为17 149 个。在实际使用决策树模型进行预测时,预测出属于Ⅲ类水的数据共19 458条,其中的正确判定为15 022条,则TP为15 022条,FP 则为4 436条,FN 为2 127 条,TN 为30 748 条,精确度为15 022/(15 022+4 436),即77.20%;召回率为15 022/(15 022+2 127),即87.59%;加权调和平均值2×15 022/(2×15 022+4 436+2 127),即82.07%(表1)。
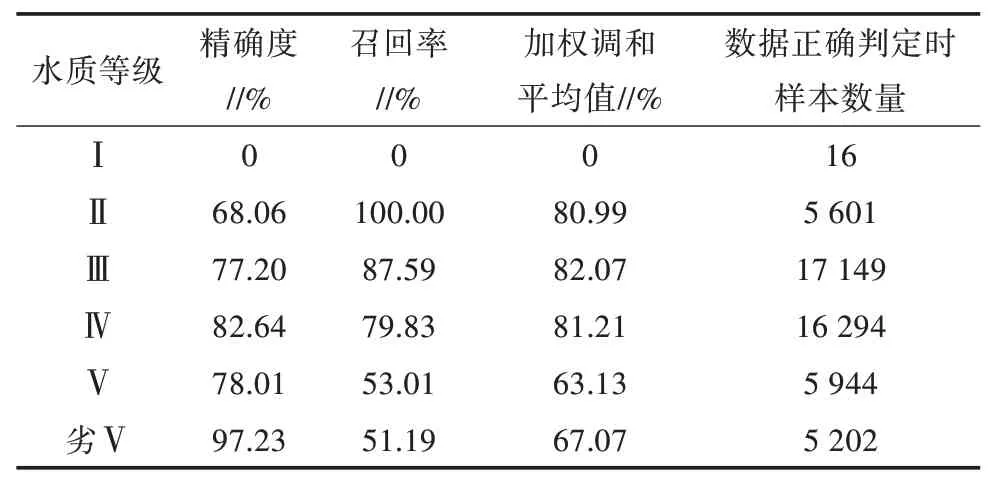
表1 各水质等级模型预测情况统计
如表2 所示,accuracy 指所有数据水质等级预测的正确率,即50 206 条数据,使用决策树正确预测了其中的39 443 条数据,accuracy 为78.56%。macro avg 是宏平均,即对每个类别的精确度、召回率和加权调和平均值求算术平均值。weighted avg 是加权平均值,它是对macro avg 的一种改进,在计算时考虑了每个类别样本数量在总样本中的占比,以消除样本数量差异所带来的影响。可以看出,macro avg值和weighted avg 值存在一定差距,主要是因为实验数据集中在III类与IV 类,在消除样本数量差异的影响之后,精确度、召回率和加权调和平均值的加权平均值都维持在80%左右。
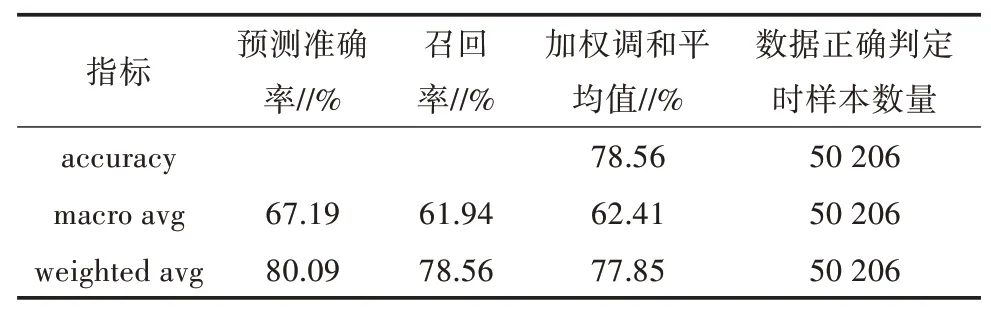
表2 训练集数据模型预测情况评估
6 小结
随着中国城镇化步伐不断加快以及环境保护和水污染防治行动的不断深入,大型企业已经建成完善的废水监测和处理体系,而由于废水监测设备昂贵、运行成本高,是中小企业完善废水监测体系面临的主要问题。因此,构建符合中小型企业的废水排放水质监测模型显得尤为重要和紧迫。针对这种现象,本研究采用决策树算法,将水质数据划分为训练集与测试集,通过构建水质等级分类模型预测水质等级,测试集验证的水质等级正确率为78.56%,证明了该方法的可行性,可用于对中小型企业的废水水质进行初步分级,减少监测费用,同时对水质进行监控,以便在水质异常时采集水样进行深入监测,并及时采取治理措施,形成针对中小型企业的废水监测体系,减少水污染现象。
猜你喜欢
环境(2023年5期)2023-06-30
云南化工(2021年6期)2021-12-21
成都信息工程大学学报(2019年3期)2019-09-25
当代水产(2019年1期)2019-05-16
电子制作(2018年16期)2018-09-26
资源节约与环保(2018年1期)2018-02-08
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
环境科技(2015年6期)2015-11-08
郑州大学学报(医学版)(2015年1期)2015-02-27
河南科技(2014年23期)2014-02-27
