
基于并行卷积核的Attention U-Net虚拟试衣方法研究
2022-06-11 11:32舒幸哲
软件工程 2022年6期
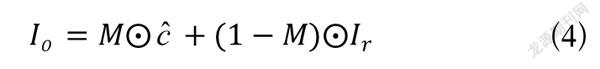


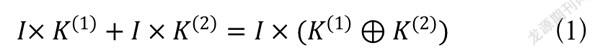
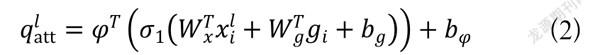
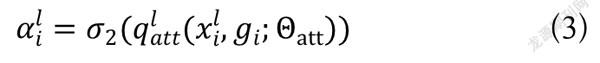
摘 要:针对虚拟试衣中特征提取不足、人物肢体被衣服遮挡的问题,在基于图像特征保留的虚拟试衣方法基础上,提出基于并行卷积核的Attention U-Net虚拟试衣方法。该方法采用并行卷积核代替原有的3×3卷积核来提取特征,并在U-Net网络中融入注意力机制形成新的Attention U-Net图像合成器,通过不断调整网络学习参数,将模型放在数据集VITON Dataset上进行虚拟试衣实验。实验结果表明,与原方法相比,该方法能提取出更多的细节纹理,在结构相似性上提升了15.6%,虚拟试衣效果更好。
关键词:虚拟试衣;特征提取;并行卷积核;注意力机制;结构相似性
中图分类号:TP391.41 文献标识码:A
Research on Attention U-Net Virtual Try-On Method
based on Parallel Convolution Kernel
SHU Xingzhe
Abstract: Virtual try-on has problem of insufficient feature extraction in and people's limbs being covered by clothes. On the basis of the virtual try-on method with image feature retention, this paper proposes an Attention U-Net virtual try-on
method based on parallel convolution kernel. In this method, parallel convolution kernel is used to replace the original 3×3 convolution kernel to extract features, and the attention mechanism is integrated into the u-net network to form a new Attention U-Net image synthesizer. By constantly adjusting the network learning parameters, the model is placed on the data set VITON (Virtual Try-On Network) Dataset for virtual fitting experiment. Experimental results show that compared with the original method, the proposed method can extract more detailed textures, improve the structural similarity by 15.6%, and the virtual fitting effect is better.
Keywords: virtual try-on; feature extraction; parallel convolution kernel; attention mechanism; structural similarity
1 引言(Introduction)
隨着网络的快速发展,虚拟试衣被应用于越来越多的领域。虚拟试衣的目标是用一件服装来代替模特身上原有的服装,合成新的虚拟试衣图像[1]。目前已有的虚拟试衣技术,如基于图像特征保留的虚拟试衣网络(Toward Characteristic-Preserving Image-based Virtual Try-On Network, CP-VTON)的测试结果中存在衣服不够清晰、人体肢体被衣服遮挡的问题。通过改进,可以使虚拟试衣结果更接近现实,给用户带来更真实的虚拟试衣体验[2]。
一项成熟的虚拟试衣技术需使模特换衣后的身体姿势[3]及服装关键特征得到良好保留。本文基于CP-VTON虚拟试衣方法,在特征提取阶段引入并行卷积核,同时融入注意力机制,生成Attention U-Net图像合成器用于将变形后的衣服图像和模特图像进行融合,生成虚拟试衣结果。实验结果表明,本文改进后的网络结构不仅可以改善肢体被衣服遮挡的问题,同时也能得到更逼真、细节更丰富的虚拟试衣效果[4]。
2 相关工作(Related work)
在CP-VTON虚拟试衣实验中,由于使用的人物数据集LIP不够干净,存在视觉不佳、有噪声的人物图片,导致第一步中服装基于人体变形模块的训练效果不是很理想[5],存在人体肢体被衣服遮挡的情况。为了改进这一缺陷,本文基于端到端的训练方式进行了改善。一个理想的虚拟试衣结果中,不仅要把指定服装形状转换成模特的体态形状,而且要保留衣服的关键特征。CP-VTON虚拟试衣方法通过形状上下文匹配算法处理空间变形,但由于CP-VTON虚拟试衣方法采用了由粗到细的策略,无法良好地保留服装细节,并且人物肢体会被衣服遮挡,这会对虚拟试衣效果产生一定的影响。本文研究的关键问题是:其一,如何在虚拟试衣结果中保留更多的特征细节,并且使得人物肢体被遮挡的情况得到改善;其二,U-Net网络编解码器结构偏于简单,参数较少,网络模型深度不足,所以在U-Net网络结构中融入有效的网络模型,形成新的编解码器对于提高网络模型分割精度十分关键。
2.1 并行卷积核
本文基于CP-VTON虚拟试衣方法进行改进,目的是在虚拟试衣图像中良好的保留衣服特征细节以及模特形态。本文首先训练CP-VTON网络并进行测试,得到第一次虚拟试衣实验结果。在融入并行卷积核后重新训练,测试后得到第二次实验结果。最后在U-Net网络中融入注意力机制形成Attention U-Net图像生成器,再次训练网络,测试后得到第三次实验结果。最终将三次实验结果进行对比。
本文在特征提取阶段用一维非对称卷积核替代了CP-VTON网络中的3×3方形卷积核,构造出的非对称卷积网络可以获得更高的训练精度[6]。由于卷积操作的可叠加性,依靠并行卷积核来提高卷积神经网络的性能是可行的。并行卷积核分支在输出后的求和公式如下:
(1)
式(1)中,作为输入图传进网络,和是具有兼容尺寸的卷积核,代表在卷积过程的对应位置进行求和操作。式(1)左边首先将通过卷积核进行卷积操作,然后将再次通过卷积核进行卷积操作,两者结果进行相加。式(1)右边和卷积核逐点相加后,再将进行卷积操作,等式两边结果是一致的。从式(1)中可知,并行卷积核在卷积神经网络中的使用并不会增加额外的计算量。
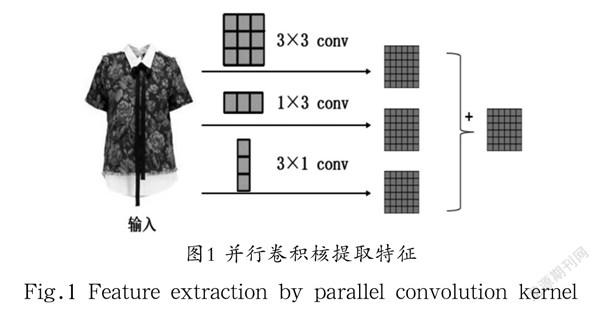
大量的实验已证明,并行卷积核网络的特征提取能力更强[7],并且在融入卷积神经网络结构后能有效提高网络模型的性能,这依赖于横向卷积和纵向卷积可以提升网络对图像翻转的鲁棒性。使用并行卷积核提取特征的过程如图1所示。
CP-VTON原有网络在特征提取阶段使用了3×3卷积核,本文将3×3卷积核拆分成三个并行的3×3、1×3、3×1卷积核进行训练,最终将这三个卷积层的计算结果进行融合作为卷积层的输出。
2.2 Attention U-Net结构
注意力机制是在计算资源一定的情况下,把有限的计算资源更多地调整分配给相对重要的任务,使得计算机能合理规划并且处理大量信息的一种模型。U-Net网络提取的低层特征中存在较多的冗余信息,注意力机制的融入可以抑制网络模型学习无关任务,达到抑制冗余信息被激活的目的,同时提高模型学习重要特征的能力。
在虚拟试衣领域,衣服和人物是全局最需要重点关注的区域,本文引入了注意力机制,可以对衣服和人物部分投入更多的注意力资源,聚焦于更多的细节信息,降低了对其他信息的关注,使得人物和衣服的特征更清晰地展示出来,提高了虚拟试衣任务的效率和准确性。
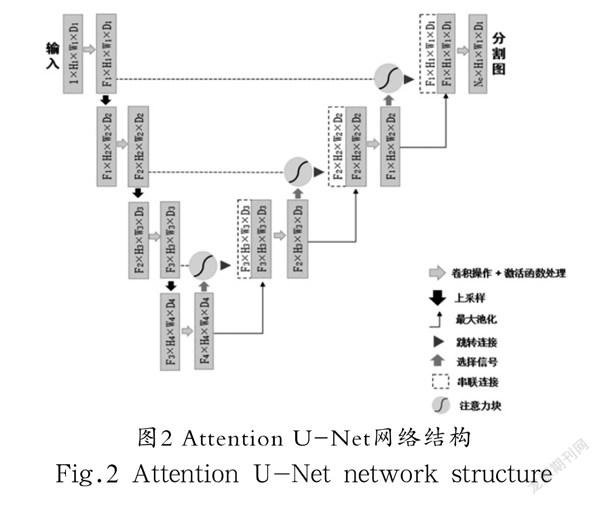
本文引入注意力机制的具体操作为加入注意力块。注意力块是一种可以自动学习的模型,它可以区分目标的外形和尺寸,并且可以有效地被整合进标准的卷积神经网络模型中[8]。注意力块融入卷积神经网络模型后的原理为:注意力权重与特征图相乘,让不相关的区域值变小,从而抑制不相关元素,而相應目标区域的值会变大。本文采用的注意力块结构连接在U-Net网络模型每个跳跃连接阶段的末端,使其形成Attention U-Net网络结构。Attention U-Net整体网络结构如图2所示。
在本文提出的Attention U-Net图形合成器中,输入图片的尺寸为256×192,在经过一次卷积和最大池化处理后,图片大小减半为128×96。经过三次卷积块和最大池化的组合后,在网络最底部得到大小为32×24的特征图,随后解码器通过上采样将特征图的大小恢复为256×192。
本文g定义是U-Net网络中解码部分的矩阵,xl是编码部分的矩阵,则本文注意力块的执行步骤为:
步骤一:对g进行1×1卷积操作后,尺寸变为1×254×64×64;
步骤二:对xl进行1×1卷积操作后,尺寸变为1×255×64×64;
步骤三:将步骤一和步骤二的结果相加,突出特征;
步骤四:对步骤三的结果进行ReLU激活函数处理;
步骤五:对步骤四的结果进行卷积操作,从256通道降为1通道,尺寸变为1×1×64×64;
步骤六:对步骤五的结果进行Sigmoid激活函数处理,得到注意力权重值;
步骤七:将步骤六的结果与xl相乘,把注意力权重赋到高阶特征中。
注意力块执行步骤整体公式如下:
(2)
(3)
式(2)和式(3)中,表示ReLU激活函数,表示Sigmoid激活函数,、、表示卷积操作,、表示对应卷积操作的偏置项。
3 实验(Experiment)
3.1 实验数据
本文实验采用CP-VTON虚拟试衣方法所带的数据集VITON Dataset。该数据集包含19,000 个图像对,每个图像对都包含一张女性模特图像和一张该模特身上的服装图像。为保证人体图像的多样性,该数据集中的人物图像包括模特正面照、侧身照和背身照。在移除视觉不佳、存在明显噪声的图像对之后,还剩下16,253 对干净的图像,这些图像被进一步分成14,221 对训练集和2,032 对验证集,再将验证集中的图像重新排列为不成对的图像对作为测试集。所有输入图像的像素都被调整到256×192,输出图像具有相同的分辨率。
3.2 实验网络结构
本文参考CP-VTON网络结构,使用深度可分离卷积以及注意力机制模块搭建构造卷积神经网络,网络的第一层使用并行卷积核提取选定衣服和人物的特征。实验整体的网络结构由两个模块组成:
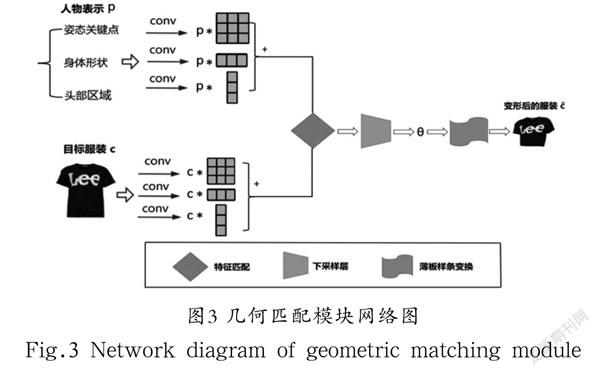
(1)几何匹配模块:结合人体特征和衣服图片,将衣服根据人体形态进行TPS薄板样条变换,生成变形后的衣服图片。
(2)试穿模块:综合人体特征和变形后的衣服图片,用图片生成器进行图片融合,生成虚拟试衣最终效果图。
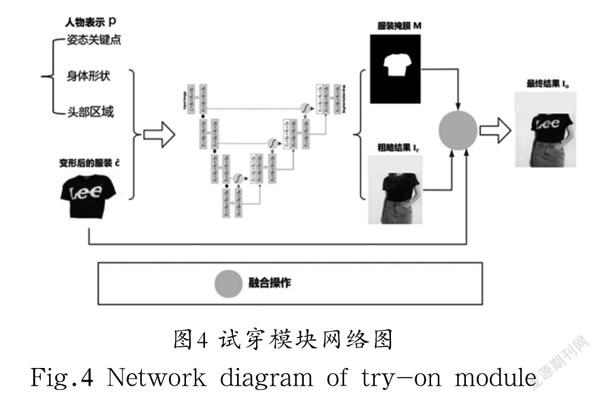
人物表示作为网络的输入之一,需要包含尽可能多的人物关键信息。包含三个部分:(1)多通道的姿态热度图,各通道分别代表人体姿势及形态的关键点;(2)单通道二值掩码特征图,用以表示身体形状,白色表示人体除脸和头部外的身体区域,黑色表示其他区域;(3)人体头部区域的RGB图像。
本文网络中的几何匹配模块参考CP-VTON网络进行改进,由四部分组成:
(1)特征提取网络:它是融入并行卷积核后的特征提取网络。将CP-VTON网络中卷积核为3×3的卷积层替换成三个3×3、1×3、3×1的卷积层,三个卷积层的stride都为2,输出被融合后作为原有卷积层的输出,在训练阶段强化了网络的特征提取能力。
(2)匹配层:将和的两个高维特征组合成单个张量,作为回归网络的输入。
(3)回归网络:根据匹配层输出来预测空间变换参数。该部分包含两个stride为2的卷积层、两个stride为1的卷积层、一个全连接的输出层。
(4)TPS薄板样条变换模块:根据第三部分所预测的转换参数,进行TPS薄板样条变换,生成变形后的衣服。
几何匹配模块使用L1范数损失函数进行训练,其网络流程图如图3所示。
几何匹配模块的输入是人物表示和选定衣服图片。网络提取完和的高级特征后,在匹配层将它们组合到一起。几何匹配模块的输出是选定衣服根据人体形态变形后的衣服。
本文网络中的试穿模块参考CP-VTON网络进行改进,输入是给定的人物表示与几何匹配模块的结果,输出是最终的虚拟试衣结果,试穿模块的网络流程图如图4所示。
在试穿模块中,人物表示与变形后的衣服作为输入传到Attention U-Net图像合成器中,经过编码和解码操作得到粗糙的合成图像,并得到衣服的合成掩膜,然后使用将和融合在一起,得到最终的虚拟试衣结果,具体实现方法参考以下公式:
(4)
式中,为element-wise矩阵乘法,表示相对应的元素逐个相乘。
4 实验结果(Experimental results)
4.1 直观对比
本文实验采用CP-VTON虚拟试衣方法所带的数据集VITON Dataset。本文将虚拟试衣结果与CP-VTON虚拟试衣结果进行视觉直观对比,其中Result 1为CP-VTON虚拟试衣结果,Result 2为本文实验得到的最终虚拟试衣结果,对比结果如图5所示。
图5中,第一列为所选模特,第二列为选定衣服。从虚拟试衣对比图中可以看出,本文方法相较于CP-VTON虚拟试衣方法,细节还原度更精细,面料感官更逼真,对人体肢体被衣服遮挡的情况也有了一定的改善。
4.2 SSIM结构相似性
除了在视觉效果上进行比较,还需要用有效的实验数据对比来评价实验的好坏。为了使虚拟试衣结果与模特原服装一致,从而进一步进行结构相似性的定量比较,本文使用模特身上的衣服作为选定换衣图片重新进行实验。本文采用了SSIM指标来衡量虚拟试衣效果的好坏。SSIM(Structural Similarity)即结构相似性,它从亮度、对比度、结构三个方面作为两幅图像的度量指标,其最大值为1,最小值为0,数值越高表明两幅图像在相似度上越接近[9]。本文实验中的SSIM值越高,表明虚拟试衣结果质量越好。虚拟试衣结果对比图如图6所示。
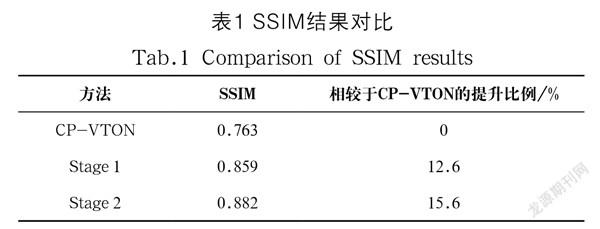
图6中,图片下方的数字为虚拟试衣结果与原图的SSIM值,其中第一列为所选模特,第二列为选定衣服,CP-VTON Results为CP-VTON网络模型训练后得到的测试结果,Stage 1 Results为在CP-VTON网络中融入并行卷积核后训练得到的测试结果,Stage 2 Results为进一步融入Attention注意力机制形成Attention U-Net图像合成器后训练得到的测试结果,三次实验的训练集以及测试集保持一致。从图6中最右侧选取的放大细节可以看出,本文方法在人物和衣服的特征提取上有了一定提升。同一数据集下,2,032 张测试图与原图的SSIM平均值结果如表1所示。
从表1中可以计算出,在SSIM数据上,Stage 1相较于CP-VTON虚拟试衣方法提升了12.6%,而Stage 2相较于Stage 1进一步提升了2.7%。实验结果对比表明,本文方法的效果相比于CP-VTON有了明显提升,并且融入两个点后的虚拟试衣效果也好于一个点。
综上,本文方法在保留衣服的关键特征和身体部位信息方面表现得更好,同时在量化指标上体现了在虚拟试衣技术上的进步。
5 结论(Conclusion)
本文提出了一种使用并行卷积核提取特征,以及在U-Net网络中融入注意力机制,用新的图像合成器合成虚拟试衣图像的方法。用并行卷积核代替原有的卷积核,可以使衣服和人像的特征提取网络训练到更高的精度,形成更逼真、细节更丰富的虚拟试衣图像。在网络模型中融入注意力机制,可以在衣服和人像中提取出更多的细节信息,提升虚拟试衣效果。实验结果表明,相比于CP-VTON虚拟试衣方法,本文方法在视觉质量、定量分析方面有了一定的提升,较好地解决了虚拟试衣服装细节保留不够、肢体被衣服遮挡的问题。
后续工作中,我们将继续优化虚拟试衣网络模型,扩大虚拟试衣图像样本库,寻求进一步提升虚拟试衣效果的方法。
参考文献(References)
[1] 张淑芳,王沁宇.基于生成对抗网络的虚拟试穿方法[J].天津大学学报(自然科学与工程技术版),2021,54(9):925-933.
[2] LEE W. Development of a virtual fit analysis method for an ergonomic design of pilot oxygen mask[J]. Applied Sciences, 2021, 11(12):5332.
[3] 陳华丽,吴世刚.基于虚拟现实技术的中国近代旗袍变迁的研究[J].辽宁丝绸,2021(2):35-36.
[4] 徐俊,普园媛,徐丹,等.基于款式变换和局部渲染相结合的虚拟试衣研究[J].太原理工大学学报,2021,52(1):98-104.
[5] 王成伟.形状可调的三次三角样条插值曲线及其在服装造型中的应用[J].北京服装学院学报(自然科学版),2020,40(4):
30-34.
[6] 袁帅,王康,单义,等.基于多分支并行空洞卷积的多尺度目标检测算法[J].计算机辅助设计与图形学学报,2021,33(6):
864-872.
[7] 欧阳羲同.横向反卷积在超声检测中的应用[J].东南大学学报,1989,19(2):89-94.
[8] 梁斌,刘全,徐进,等.基于多注意力卷积神经网络的特定目标情感分析[J].计算机研究与发展,2017,54(8):1724-1735.
[9] 杨达,狄岚,赵树志,等.基于结构相似性与模板校正的织物瑕疵检测方法[J].智能系统学报,2020,15(3):475-483.
作者简介:
舒幸哲(1997-),男,硕士生.研究领域:图像处理.
猜你喜欢
电子制作(2019年15期)2019-08-27
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
电子制作(2018年19期)2018-11-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
中国生物医学工程学报(2017年6期)2017-02-10
广西科技大学学报(2016年1期)2016-06-22
