
基于深度极限学习机的煮糖制炼自适应控制研究
2022-06-10 07:51:28陆冠成蒙艳玫余双双
甘蔗糖业 2022年1期
陆冠成,蒙艳玫,余双双,董 振
(广西大学机械工程学院,广西南宁 530004)
0 引言
煮糖过程是一个存在传热传质、复杂相变和非线性慢时变的过程,包含多种因素的相互影响和相互作用,难以直接通过机理建模来构建控制系统模型。目前,国内也有高校和研究机构以过饱和度为控制目标研究煮糖自动化技术,通过调节煮糖过程的运行参数来实现过程的自动控制,但煮糖过程关键工艺参数监控的长期稳定性尚需进一步研究[1]。
煮糖过程是一个包含高粘度的气相流、液相流和固相流的复杂过程,是一个多因素复杂耦合的系统。煮糖过程有流动场、温度场、浓度场、真空度场、外力场和杂质场等相互作用,煮糖过程的运行参数和糖膏物性对这些场均有影响,直接制约了煮糖生产的质量、产量和能耗[2]。因此,在煮糖过程中如何协同优化这些因素是提高产品质量、提高生产效率和降低能耗的关键。
机器学习算法能够在不透彻了解过程机理的情况下,通过对过程数据进行学习与建模,挖掘过程输入与输出之间存在的隐含关系,并以其逼近实际过程。虽然前馈神经网络已经得到了充分的研究和广泛使用,但是由于其基于采用梯度下降求解,容易导致求解过程陷入极小点而达不到预期效果。极限学习机是Huang等人提出的一种采用类似于单隐含层神经网络的结构,但有别于神经网络的全新机器学习方法[3]。基于最小二乘法辨识输出权值向量,对目标具备较好的全局逼近能力;不需要频繁调整网络参数,避免了多次迭代调整网络参数带来的计算复杂度,提高了网络模型的学习效率,减少了模型训练时间。
为了解决存在耦合方式多变、糖膏物性不确定与高度非线性等复杂因素的煮糖制炼自适应控制难题,本文以煮糖制炼过程离散状态控制转移为核心,基于深度极限学习机研究了煮糖制炼过程关键参数的递推自适应控制,运用极限学习机自编码器抽取煮糖制炼过程关键参数特征研究了煮糖制炼关键参数粗差数据的剔除与脉动数据的滤波。
1 极限学习机的原理
极限学习机是Huang等人提出的一种全新的机器学习方法。它是一种采用类似于单隐含层神经网络的结构,但有别于神经网络的机器学习方法[3]。在极限学习机中,输入层与隐含层的连接权值及隐含层的阈值均是随机生成的,并在学习过程中不再需要调整。极限学习机可以被看作一个参数线性化模型,其求解过程可归结为求解线性系统[4-5]。与传统单隐含层神经网络相比,极限学习机具有学习速度快、需要调整的参数少和泛化性能好等优点[6]。从极限学习机的理论上分析,即使隐含层节点数是随机设置的,其仍能保持单层前馈神经网络的通用逼近能力。极限学习机由输入层、隐含层和输出层三层构成,其网络结构如图1所示。
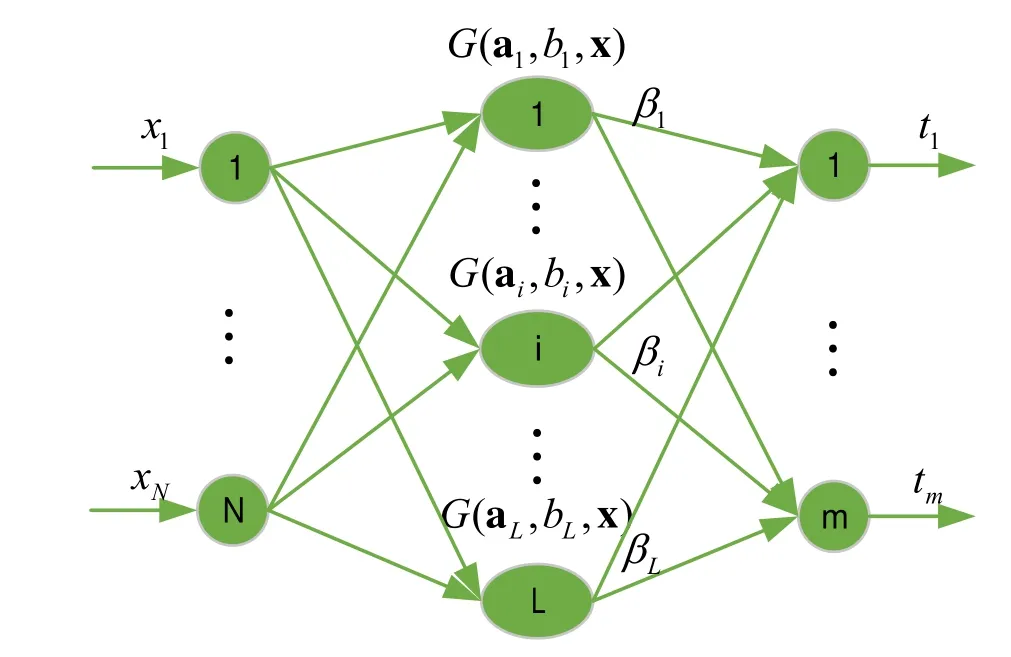
图1 极限学习机网络结构图
极限学习机的输出函数可由式(1)表示。
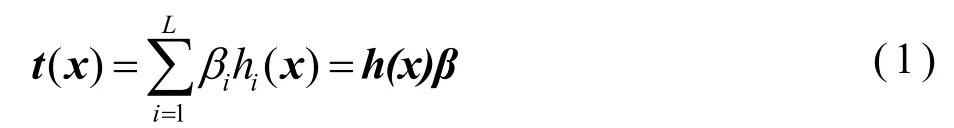
在式(1)中,β=[1,2,...,L]T为隐含层到输出层之间的权重向量,h(x)=[h1(x),h2(x),...,hL(x)]是极限学习机的非线性特征映射。极限学习机隐含层节点的映射函数表达式并不唯一,在实际应用中hi(x)通常可由如下公式表示。
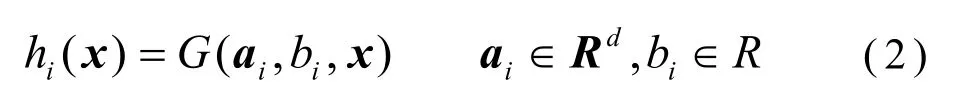
其中,ai表示第i个隐含层节点的权重向量,bi表示第i个隐含层节点的偏置量,G(a,b,x)表示隐含层激活函数。当一个待解决问题存在多变量映射关系时,极限学习机可以使用如下矩阵形式表述。

在极限学习机的矩阵形式中,T表示样本目标矩阵,H表示隐含层输出矩阵。根据极限学习机原理,极限学习机成功应用于解决实际问题的关键在于参数ai,bi和βi的求取。在极限学习机中,输入权值ai和隐含层偏置bi是随机确定的,那么隐含层的输出矩阵H一经确定后就不会再改变了。因此,极限学习机的关键在于输出权重向量的求取。极限学习机的输出权重向量β可由最小二乘法辨识,其辨识目标式子如下所示。
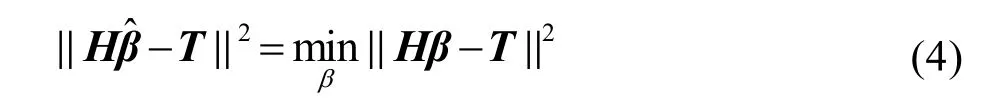
2 基于深度极限学习机的煮糖制炼过程关键参数特征变换方法
由于受到实际工况的影响,煮糖制炼过程传感器数据容易导致一些参数测量结果出现不确定性。基于工人经验设置的煮糖制炼过程工艺目标,因工人经验知识不同以及工况变化影响,容易导致一些工艺指标与现场工况不匹配。煮糖制炼过程气动阀门受到工厂供气量的影响容易导致阀门开度不到位。煮糖制炼过程蒸汽供应的波动容易导致对流跟随波动,最终导致煮糖制炼控制器脉动输出。因煮糖制炼过程是一个慢时变过程,煮糖制炼控制器脉动输出极有可能导致伪晶的出现以及导致煮炼时间变长[1,7]。因此,煮糖制炼过程关键参数粗差数据的剔除以及脉动数据的滤波提高煮糖制炼自动控制效果的关键所在。粗差数据的剔除与脉动数据的滤波理论上可以根据统计学原理实现,然而这需要大量的数据,增加了计算复杂度,导致这类处理难以适应在线控制。极限学习机的自编码为解决此类问题提供了一条新途径。
极限学习机的自编码是一种无监督的学习算法,常用于实现数据降维或者特征提取,是深度学习中数据特征抽取的主要手段。极限学习机自编码器的网络结构由输入层、隐含层和输出层构成。它主要包含编码器和解码器2个部分,其结构的特别之处在于输入层和输出层节点数相同。极限学习机自编码器的构成如图2所示。
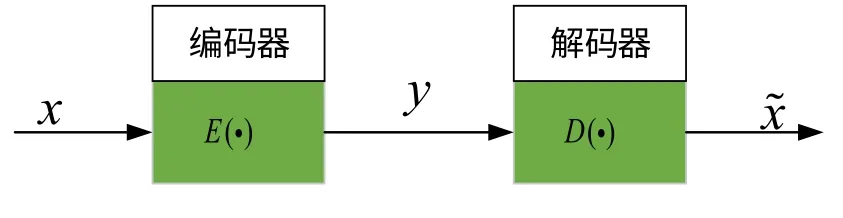
图2 极限学习机自编码器的构成
其中,x为自编码器的原始输入数据,为自编码器的输出, ()E·是编码函数, ()D·是解码函数,y是x的特征空间。极限学习机自编码器的编码与解码过程可由以下式子表示。

基于极限学习机自编码器原理,煮糖制炼过程关键参数的特征抽取以现场传感器的数据和基于工人经验的工艺指标作为自编码器的原始输入数据x,通过自编码器的编码函数 ()E·将其编码为y,然后再通过解码函数 ()D·将y解码为,其目的是为了让尽量复现x,亦即次要数据被剔除后所获得数据特征尽可能逼近原始数据x。基于极限学习机自编码器抽取关键参数特征的主要目的在于经过迭代计算与复现输入数据,让编码后的y具有表征x的价值属性,从而实现粗差数据的剔除与脉动数据的滤波。基于极限学习机抽取煮糖制炼过程关键参数特征的网络结构如图3所示。
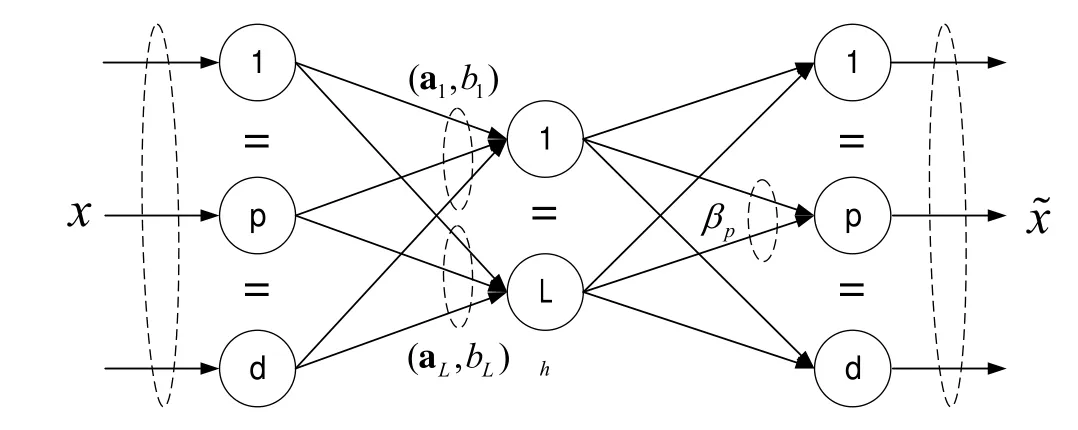
图3 煮糖制炼过程关键参数特征抽取的网络结构图
3 基于深度极限学习机的煮糖制炼递推自适应控制
煮糖制炼过程是一个包含各种因素相互影响与相互作用的高度非线性且机理复杂的过程,难以直接通过机理建模解决煮糖制炼自动控制问题。煮糖制炼过程的各组件单元通过物理场共享发生关联,各场输入输出受场间耦合变量的约束,前一场输出结果被作为输入加载入下一场引起该场输出结果的不断变化,各个影响因素之间耦合关系极其复杂。煮糖制炼过程体系内场与外场的约束关系,过程关键参数与糖膏物性对各个物理场的影响,关键参数与糖膏物性对煮糖制炼过程传热、传质和相变的影响表征了煮糖制炼过程各能量传递单元关键参数的变化规律与各影响因素存在重要的协同作用[8-9]。机器学习算法能够在不透彻了解过程机理的情况下,通过对过程数据进行学习与建模,挖掘过程输入与输出之间存在的隐含关系,并以其逼近实际过程。
基于最小二乘法辨识输出权值向量极限学习机是挖掘过程输入与输出之间存在隐含关系的重要学习方法之一。然而,与神经网络、支持向量机与强化学习算法等类似,在面对高维数据时其仍存在模型精度和稳定性下降的问题。深度极限学习机是一种具有多隐含层网络结构的极限学习机,是解决高维数据映射问题的全新方法[10]。深度极限学习机的网络结构如图4所示。深度极限学习机的隐含层之间的关系可下式表示。
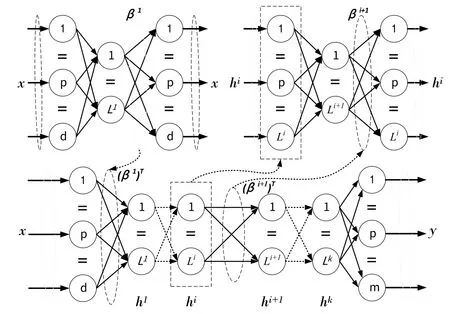
图4 深度极限学习机网络结构
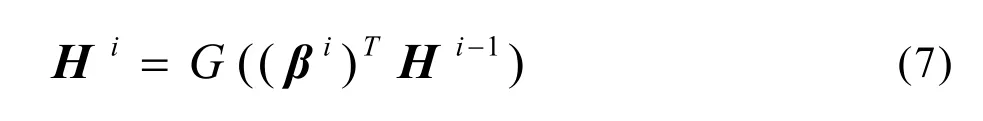
其中,Hi表示深度极限学习机的第i层隐含层输出,Hi-1表示深度极限学习机的第(i-1)层隐含层的输出,()G·为深度极限学习机的隐含层的激活函数,βi表示深度极限学习机的第i层的输出权值,深度极限学习机的最后一个隐含层和输出层之间的连接输出由正则化最小二乘法计算[11]。深度极限学习机不但具备极限学习机具有的网络模型学习效率高与对目标全局逼近能力强的优点,还能解决高维度问题,为揭示存在高维度映射的数据间隐含关系提供了一种新方法[10]。
煮糖制炼过程既有传热又有传质和相变,是一个包含各种因素的相互影响和相互作用且机理复杂的过程,导致难以直接通过机理建模来反映其过程控制内部机理。煮糖制炼过程真空度对糖膏沸点与糖膏流动性具有明显影响;浓度场与温度场通过流动场相互作用;杂质场促进母液的结晶速度与晶体颗粒的成长速度,对浓度场具有显著影响;其它煮糖制炼影响因素均有相互耦合作用。影响煮糖制炼各因素的耦合关系如图5所示。
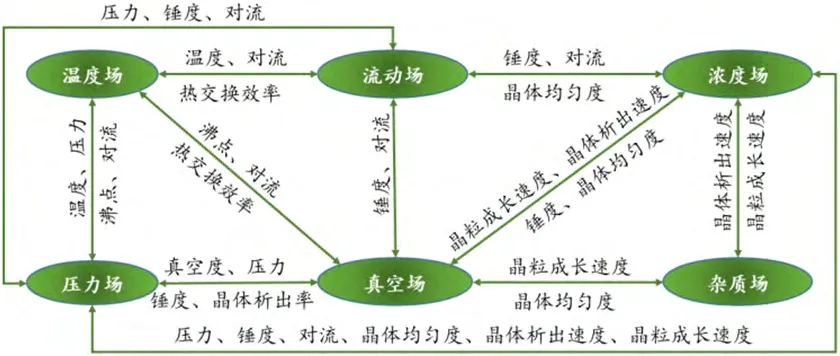
图5 影响煮糖制炼各因素的耦合关系
煮糖制炼过程的各组件单元通过物理场共享发生关联,各场输入输出受场间耦合变量的约束,前一场输出结果被作为输入加载入下一场引起该场输出结果的不断变化,各个影响因素之间耦合关系极其复杂基于传统PID控制或者单一数据驱动控制方法的煮糖制炼自动控制由于对耦合过程过多简化,导致成品糖质量严重下降。由于实际煮糖制炼过程是一个存在高维度非线性映射关系的过程,神经网络与极限学习机等因高维度与迭代计算量的限制,实际上难以解决煮糖制炼自适应控制问题。深度极限学习机不但具备极限学习机的优点,而且具备处理高维度映射问题的能力。因此,本文以煮糖制炼过程离散状态控制转移为核心,基于深度极限学习机构建煮糖制炼过程关键参数的递推自适应控制模型,实现煮糖制炼过程深度递推自适应控制方法,解决存在控制时变性强、耦合方式多变、糖膏物性不确定与高度非线性等复杂因素的煮糖制炼自适应控制难题。
基于深度极限学习机的煮糖制炼过程深自适应控制过程如图6所示,其工作原理是在控制周期到达时,以煮糖罐糖膏当前温度、煮糖罐糖膏当前锤 度、煮糖罐当前蒸汽压力、煮糖罐糖膏当前立方数、煮糖罐糖膏当前结晶状态特征、稀释箱糖膏当前温度、稀释箱糖膏当前锤度、稀释箱当前物料特征、煮糖罐糖膏当前锤度与目标锤度的偏差、煮糖罐糖膏当前立方数与目标立方数的偏差、煮糖罐糖膏当前结晶状态特征与目标结晶状态特征的偏差等全局协同优化下一个控制周期的蒸汽阀门开口度、入料阀门开口度、热水阀的开口度和稀释箱各个物料阀门开口度等过程控制量,将全局协同优化后的各个过程控制量施加于煮糖制炼,如此循环往复,不断学习过程数据、更新参数以及优化调整各个过程控制量,直至煮糖制炼各个分量满足工艺指标。
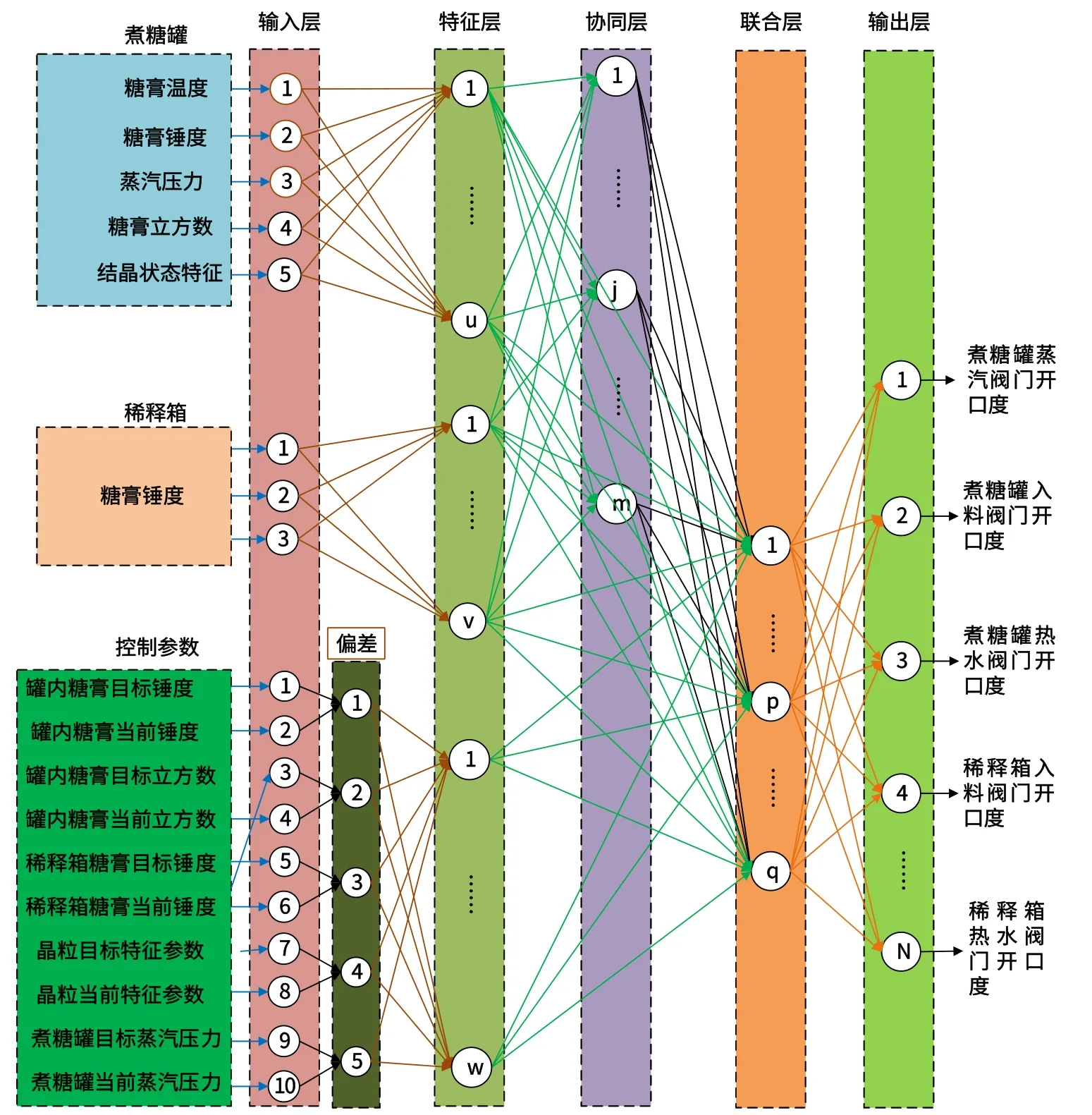
图6 基于深度极限学习机的煮糖制炼递推自适应控制过
4 实验结果
锤度与液位的控制是煮糖制炼过程实施自动控制的关键因素之一。机器学习方法在工业在线控制上的应用,除了考虑隐含规律的挖掘能力之外,还考虑在线控制的计算复杂、误差边界控制与泛化能力等因素。为了验证深度极限学习机的误差边界控制与泛化能力,本文以实验室煮糖制炼装置的历史数据作为基础数据,分别运用前馈神经网络与深度极限学习机对锤度与液位数据进行训练,并使用交叉验证法统计2种方法的均方根误差(RMSE)。图8是本文采集历史数据所用的实验设备。2种方法训练的均方根误差曲线分别如图9和图10所示。从均方根误差曲线上看,深度极限学习机的效果优于前馈神经网络。

图7 实验室实验装置
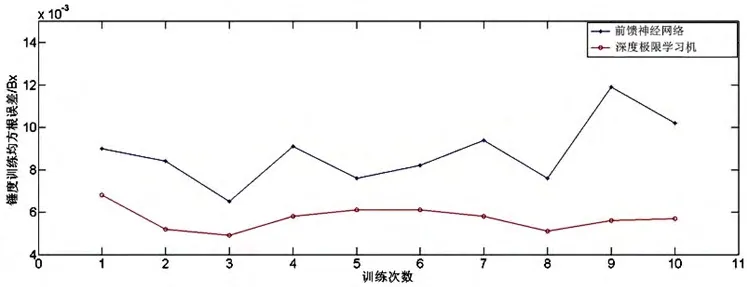
图8 锤度训练均方根误差值曲线
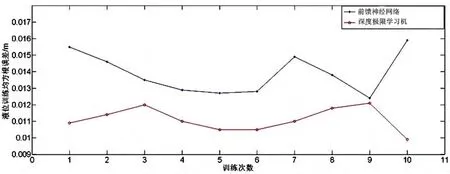
图9 液位训练均方根误差值曲线
为了验证本文所提出方法的有效性及其放在工业上应用的可行性,本文运用WPF编写了一款煮糖制炼过程自动控制软件终端,并将其部署于广西某制糖企业的煮糖制炼工段。该软件终端现场运行截图见图10,实时控制曲线见图11。从实时控制曲线可以看出,当工艺目标改变时,它能够较好地协调各个阀门的控制量;能够使制炼关键参数跟随工艺目标;能够平稳地控制目标锤度与目标立方数。
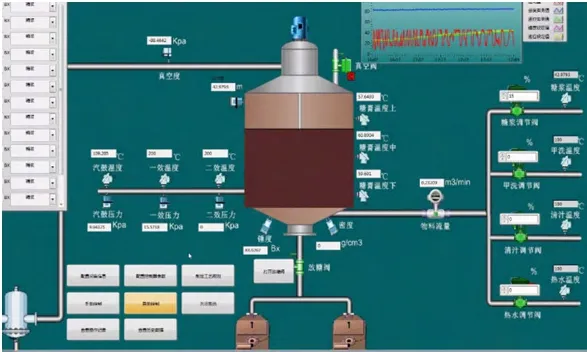
图10 现场运行截图
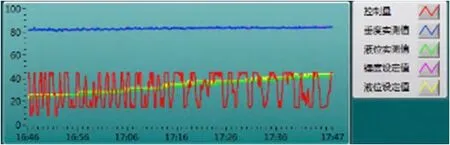
图11 实时控制曲线
本文在同一个煮糖设备上分别记录30罐次的自动控制煮糖和人工煮糖的煮糖时间与成品糖色值。图12为自动控制煮糖方法和人工煮糖方法的煮糖时间对比,结果表明本文自动控制方法的实际煮糖时间稍微优于人工煮糖时间。图13为自动控制煮糖方法和人工煮糖方法的糖色值对比,结果表明自动控制方法煮糖的效果优于人工煮糖。
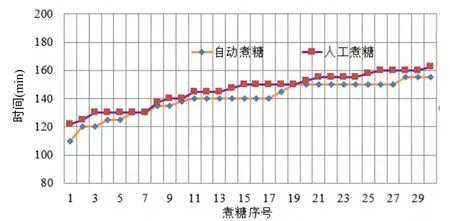
图12 时间对比图
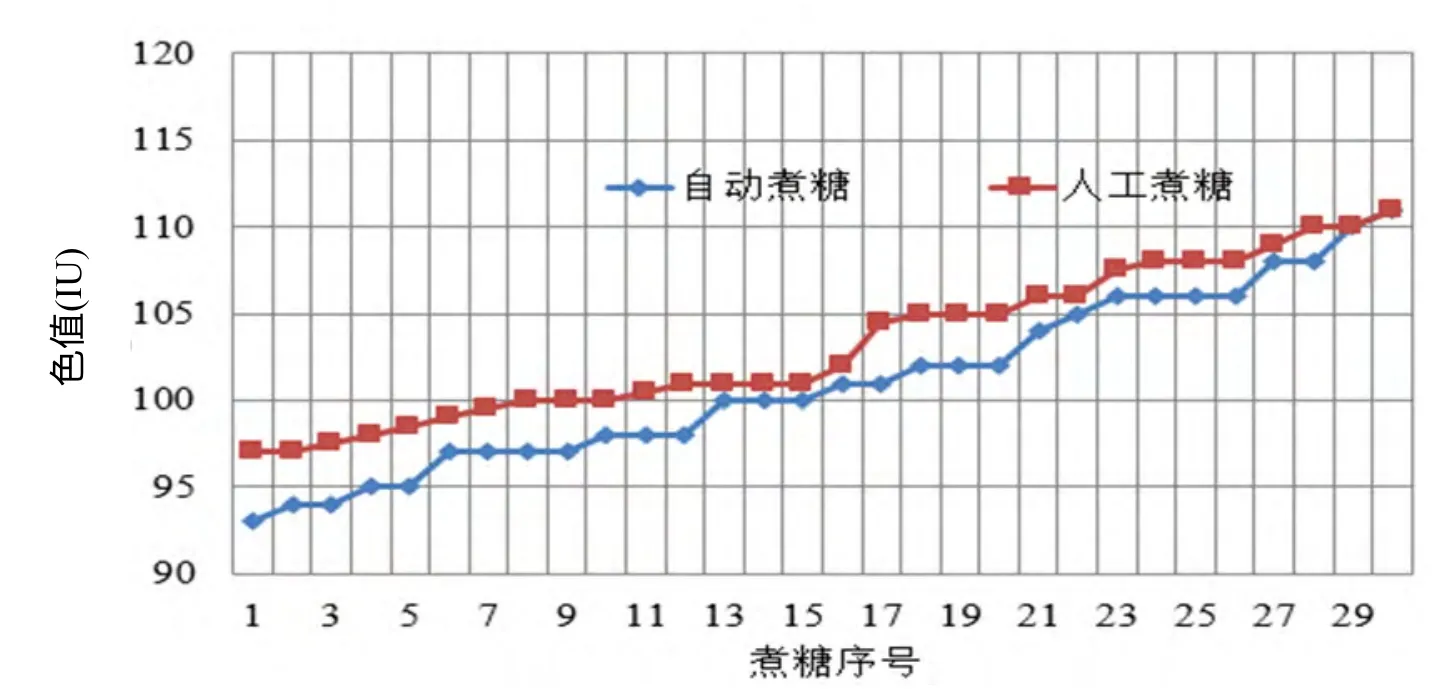
图13 色值对比图
5 结语
煮糖制炼许多内在规律难以了解或者过于复杂,导致难以获取过程控制定量知识。煮糖制炼过程机理复杂,存在非线性慢时变,难以直接通过机理建立受控系统的数学模型,控制难度极大。虽然可以对煮糖制炼过程约束条件进行简化后建立受控系统的数学模型,但是由于对受控系统进行诸多简化,导致基于数学模型的煮糖控制器在实际应用中往往受未建模动态及鲁棒性的影响,未能及时适应物料变化和现场约束条件的变化,严重影响了煮糖质量和煮糖效率。
为了解决复杂因素影响的煮糖制炼自适应控制难题,本文以煮糖制炼过程离散状态控制转移为核心,基于深度极限学习机构建煮糖制炼过程关键参数的递推自适应控制模型,并基于极限学习机自编码器抽取煮糖制炼过程关键参数特征,提出了一种基于深度极限学习机的煮糖制炼自适应控制方法。实验结果表明,与人工煮糖相比,本文所提出方法不但缩短了煮糖制炼时间,而且有效地降低了成品糖的色值,为煮糖制炼过程实现多因素协同与自适应控制提供了一种新途径。
猜你喜欢
测控技术(2018年10期)2018-11-25 09:35:26
电子测试(2018年15期)2018-09-26 06:01:04
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
自动化学报(2018年2期)2018-04-12 05:46:21
制造技术与机床(2017年4期)2017-06-22 11:17:32
电子设计工程(2017年20期)2017-02-10 03:39:29
自动化学报(2016年8期)2016-04-16 03:38:51
西北工业大学学报(2015年1期)2016-01-19 03:29:56
电子器件(2015年5期)2015-12-29 08:42:24
哈尔滨师范大学自然科学学报(2015年6期)2015-04-23 08:20:35
