
一种面向多云资源和多云服务的监控告警方法
2022-06-10 07:13:38王骏翔
上海船舶运输科学研究所学报 2022年2期
王骏翔
(中远海运科技股份有限公司, 上海 200135)
0 引 言
近年来,在产业转型过程中,我国各行业企业纷纷利用云计算和人工智能等新兴技术提升自身的生产效率、创新能力和资源利用率,促进发展模式变革,为实现数字化转型奠定了坚实基础。当前,我国各行业企业的信息技术(Information Technology,IT)基础架构向云迁移已成为主流趋势,各行业的业务系统上云率不断提升,而随着数字化转型需求的增加,云计算在数字化转型和智能化升级过程中将得到更广泛的应用。数字化转型的前提是对企业资源进行优化,而云计算以其强大的弹性和高可拓展性,不仅能实现IT资源优化,而且能实现规模效应最大化。随着云计算技术的不断发展,诸多企业纷纷围绕其软件和硬件基础环境的交付特点,建设或使用满足自身需求的云计算平台或公有云服务。企业级应用的云资源服务也已从传统的云资源向容器云、微服务和各种PaaS服务演变。
本文结合实际工程案例,利用开源的云计算技术和监控分析技术,提出一种适用于大型集团型企业的云计算多云资源和云服务性能监控系统的技术。对技术方案的建设需求、技术理论和实现方式进行详细阐述。以某大型集团型企业为例,介绍其在多云资源和多云服务环境下的新一代监控告警方式的技术变革。
1 多云资源监控的需求与价值
1.1 多云服务资源的演变及其特征
近年来,越来越多的企业开始将自己的核心生产业务系统向云迁移。在上云应用过程中,对云计算资源的多元化服务需求随着云计算技术的演变发生着质的变化。
传统信息系统的底座是操作系统(如Windows、Linux和Docker等),上层由用于支撑业务运作的各种中间件构成(数据库有Mysql和Oracle;应用服务有apache、tomcat、redis和kafka等)。随着云计算技术的不断发展,传统硬件架构已转化为云化架构,既有虚拟化环境,又有容器环境,以及各种微服务和PaaS服务等;同时,随着公有云、行业云和专有云的不断衍生,出现了企业多云和混合架构的巨变。
图1为多云服务的演变示图。

图1 多云服务的演变示图
未来,数字经济将促使我国云计算产业得到快速发展。从技术层面来看,新技术和新应用将给云计算市场带来新的活力,使用好用于支撑业务系统的各种多云服务逐渐成为企业数字化转型进程中必不可少的重要环节。
1.2 多云资源和多云服务的监控需求
对于已完成云基础资源纳管和交付的“上云”企业而言,随着云计算技术的不断发展和业务形态的不断变化,企业多云环境、跨云架构和容器微服务等云服务的形态逐渐显露,并迅速得到应用和发展。
云计算将各类异构的、动态的资源分布于整体的云计算服务中,形成巨大的异构云资源池,用户可依照按需使用的原则获取服务。云服务所提供服务的质量依赖于云计算整体服务架构和资源的稳定性,可通过对云计算服务中的传统云主机、容器云资源和多云服务资源进行实时监控,为上层整体的云服务体系持续赋能,以提供高效、稳定、健壮的云运行环境。
1.2.1 传统云主机资源的监控需求
传统云主机虚拟化技术是云计算服务的基础,云主机的性能和稳定性直接影响着整体云服务的效率和用户体验,对云主机运行的稳定性和性能进行监控显得尤为重要。通过对云主机进行监控,获取资源实时监控数据,并对性能历史数据进行分析,既可有效地对云主机资源进行动态的配置调整,又能根据云主机占用宿主机资源的情况对云主机进行动态迁移。因此,云主机的资源监控在云计算服务中占据着非常重要的位置。
1.2.2 容器云资源的监控需求
随着云计算技术的不断发展,微服务和容器技术已成为企业广泛应用的新型云技术,对容器云资源的稳定性和性能监控的需求变得日趋迫切。相较于传统云主机,容器环境是运算资源随机池化的,存在着1个节点上运行着随机调配的多个容器的情况,很难通过传统监控手段区分每个容器的资源占用情况和负载情况。除了需对容器的性能指标进行实时监控以外,还需对整个容器群集系统的各组件和运算节点的性能、流量、用户行为模式和应用程序性能等传统因素进行监控,保证容器基础设施稳定、高效运行。
1.2.3 多云服务资源的监控需求
当前,通过利用云计算技术和自动服务编排技术等,能实现基于云资源的灵活配置,由此衍生出的诸多aPaaS云服务已成为企业快速交付业务的基础。针对这些aPaaS云服务(例如Nginx、HAProxy、JVM、MQ、Kafka、Oracle、MySQL和Redis等),实时掌握和了解相应云服务的健壮性和性能指标是支撑上层云业务的关键。通过对多云服务资源监控指标进行采集,既能在性能调优时满足实时性能分析的需求,又能在日后通过历史数据回溯业务故障点时提供有效的手段,搭配云主机和容器等监控数据,更可全方位地支撑和保障整体云服务的状态。
1.3 多云资源和多云服务监控技术对企业发展的作用
应对不断新增的云计算服务,通过有效的手段对传统云主机服务、容器云服务和多云服务等云资源进行实时、精准的监控数据采集和性能分析,不仅是保障企业上层各业务系统稳定运行的基石,而且是将传统被动式运维转化为主动防护和监管的有效措施。
对于大型集团型企业而言,通过构建数据中心级别的统一多云监控体系,可在满足多元化业务发展需求的同时,建立稳定、高效的开放式监控平台,辐射所有云应用资源和上云系统。各上云企业和系统在此基础上,只需关注自身的产品服务能力,无需单独构建多云监控系统,达到企业数字化转型和降本增效的目标。
2 多云资源和云服务性能监控技术方案设计
2.1 总体方案设计
在设计该技术方案时,重点关注企业级大型数据中心多云资源和多云服务的性能监控场景,主要提升多种云资源在性能监控数据采集、数据汇总清洗、分析展示和异常告警等方面的灵活性和可扩展性。在多云资源的监控方案中,采用基于开源的Prometheus技术实现上述功能。
Prometheus 是一套开源的系统监控报警框架。采用TSDB(Time Series Database)时序列数据库为监控指标和键值建立多维度数据模型。通过HTTP协议,周期性地抓取被监控组件的状态,受监控的组件根据其组件类型提供对应的HTTP接口,即可进行对接。Prometheus架构拓扑图见图2。

图2 Prometheus架构拓扑图
Prometheus的技术特点主要有:
1) 采用TSDB(Time Series Database)时序列数据库的多维度数据模型;
2) 可利用各种维度灵活的PromQL查询语言;
3) 不依赖分布式存储,单个服务器节点是自主的;

图3 Prometheus技术方法的实施步骤
4) 通过基于HTTP的Pull方式采集时序数据;
5) 可通过中间网关(Pushgateway)进行时序列数据推送;
6) 通过服务发现或静态配置发现目标服务对象;
7) 支持多种多样的图表和界面展示,比如Grafana等。
Prometheus技术方法的实施步骤见图3。在该技术方法中,利用云计算平台中的自动化能力部署监控采集器,对多云资源和多云服务中的可用性和性能指标进行监控;通过确定云可用性和性能监控指标及键值确定监控侧策略和阈值;通过监控采集器监控对应的组件;通过多维度建模及云计算平台下的分权管控和联动进行数据分析;针对不同云资源展示对应的监控数据和分析结果;通过采用底层性能采集服务的群集,统一性能监控数据的告警。此外,提供相应的告警系统,有效提升多种云资源在性能监控数据采集、数据汇总清洗、分析展示和异常告警等方面的灵活性和可扩展性。
2.2 云资源和云服务的监控数据采集设计
在采集性能监控数据时,主要利用Prometheus Exporters实现该功能。Exporters是Prometheus监控中的重要组成部分,负责对数据指标进行采集。开源社区官方给出的插件有node_exporter、blackbox_exporter、mysqld_exporter和snmp_exporter等,第三方的插件有redis_exporter和cadvisor等。
在该技术方案中,针对云主机、数据库和容器部分的监控采集采用的主要插件及其用途见表1。

表1 针对云主机、数据库和容器部分的监控采集采用的主要插件及其用途
Prometheus server会定期从Exporters组件中拉取metrics监控性能指标。
2.3 云资源和云服务监控数据分析和展示设计
在分析和展示云资源性能监控数据时,结合数据中心多云资源监控分析和展示的场景,利用开源的Grafana技术实现该功能。
在Prometheus体系中,通过PromQL和其他API(Application Programming Interface)方式可视化地展示收集的数据,除了其本身提供的Promdash和丰富的模板引擎以外,还提供HTTP API查询方式,满足使用者的调度需求。
在该技术方法中,采用的Grafana是一个开源的跨平台度量分析和可视化 + 告警工具,提供强大且优雅的方式创建、共享和浏览数据。支持可自定义的分析展现视图,Dashboard中可显示不同种类的metric数据源中的数据。Grafana支持热插拔控制面板和可扩展的数据源,与该技术方案中的Prometheus无缝融合。图4为Prometheus+Grafana工作原理图。

图4 Prometheus+Grafana工作原理图
2.4 云资源和云服务监控告警设计
监控告警是数据中心监控系统中的重要组成部分,在Prometheus监控系统中,采集与告警机制相应分离。Prometheus server在本地存储收集到的metrics,并运行已定义好的告警规则(alert.rules),通过一定的规则清理和整理数据,并将得到的结果存储到新的时间序列中。当告警规则触发之后,会将告警信息转发到独立的组件Alertmanager中,经Alertmanager处理之后,通过电子邮件、PaperDuty和HipChat发送给通知者。Prometheus Alertmanager工作机制图见图5。
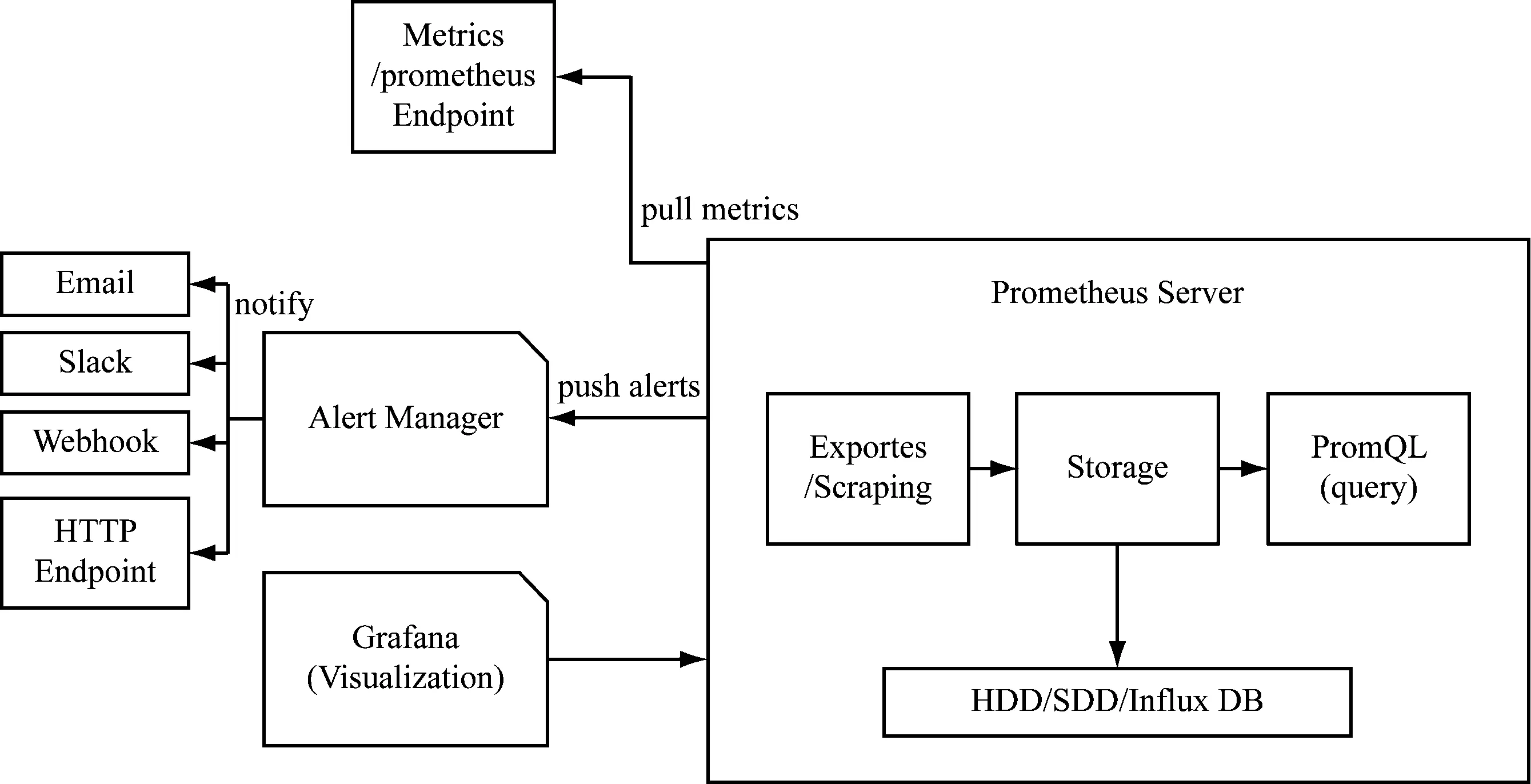
图5 Prometheus Alertmanager工作机制图
3 多云资源和多云服务监控技术的实现及应用
在该技术方法中,利用自主可控的开源产品,通过实时采集多云资源和多云服务的监控数据,精准地提供直观、实时、高效、友好的可视化资源展示界面,对来自于不同云区域、不同云基础平台和不同种类的云应用服务的IT管理及性能数据进行统一存储、分析和展现,帮助上云企业和云运营服务商轻松掌控全局,高效应对突发事件,把握整体云资源状态。
3.1 开源的Prometheus和Grafana群集部署
通过基于Kubernetes的微服务方式部署构建开源的Prometheus和Grafana群集,以下是Prometheus部署配置的部分YAML信息。Prometheus各组件模块状态见图6。
kind: Deployment
metadata:
name: prometheus
namespace: kube-prometheus
spec:
containers:
- image: 10.xx.xx.xx:8082/prometheus
name: prometheus
imagePullPolicy: IfNotPresent
command:
- "/bin/prometheus"
args:
- '--config.file=/etc/config/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=30d'
ports:
- containerPort: 9090
name: http
…
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-prometheus
spec:
type: NodePort
ports:
- name: http
port: 9090
protocol: TCP
targetPort: 9090
nodePort: 30089
…

图6 Prometheus各组件模块状态
以下是Grafana部署配置的部分YAML信息。
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-prometheus
spec:
spec:
containers:
- name: grafana
image: 10.xx.xx.xx:8082/grafana
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
protocol: TCP
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-prometheus
spec:
type: NodePort
ports:
- port : 80
targetPort: 3000
nodePort: 30030
selector:
app: grafana
3.2 Prometheus Alert监控告警的实现
通过在Prometheus群集环境中部署启用Alertmanager模块,实现对告警功能的环境部署。以下是Alertmanager模块部署配置的部分YAML信息。图7为Prometheus Alertmanager规则配置状态。
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-rules
namespace: kube-prometheus
data:
general.rules: |
groups:
- name: general.rules
rules:
- alert: InstanceDown
expr: up == 0
for: 1 m
labels:
severity: error
…
node.rules: |
groups:
- name: node.rules
rules:
- alert: NodeFilesystemUsage
expr: |
100 - (node_filesystem_free{fstype=~"ext4|xfs"} /
node_filesystem_size{fstype=~"ext4|xfs"} * 100) > 80
for: 1 m
…
pod.rules: |
groups:
- name: pod.rules
rules:
- alert: PodCPUUsage
expr: |
sum(rate(container_cpu_usage_seconds_total{image!=""}[1 m]) * 100) by (pod_name, namespace) > 80
for: 5 m
labels:
severity: warning
…
3.3 Grafana监控数据分析展示的实现
Prometheus提供了标准的API Restful接口,可通过http[s]://IP:PORT/metrics获取所有监控对象的采集数据。
在Grafana设计和展示过程中,通过编写和配置PromQL语言,实现对相关监控对象和指标的细颗粒度的分析。图8为Grafana性能分析PromQL分析。
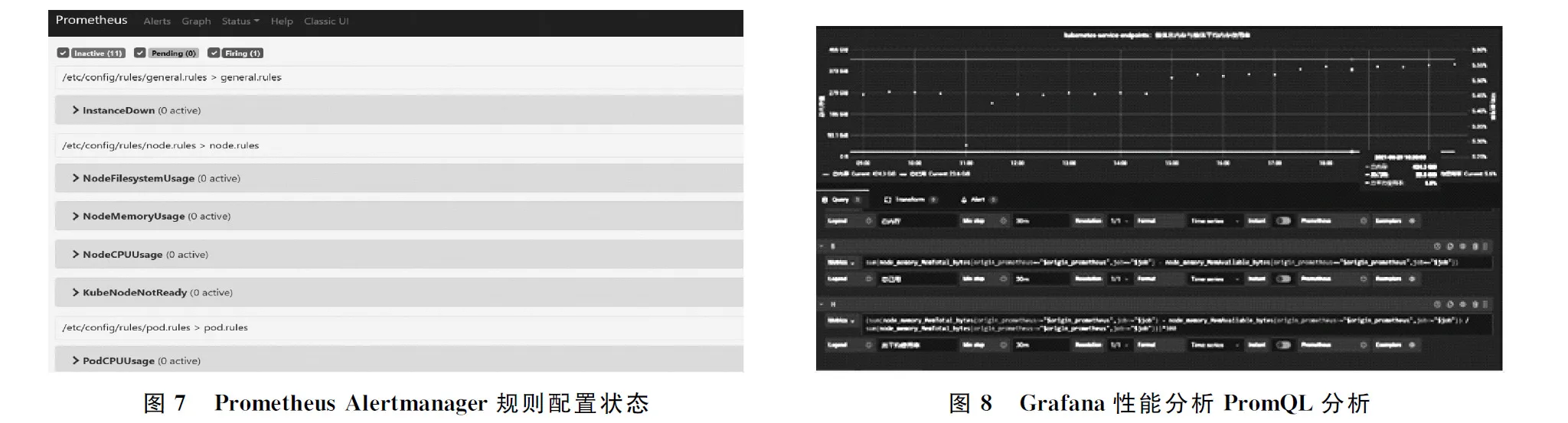
3.4 多云资源和多云服务监控及告警的应用效果
通过利用该技术方法,对云原生技术和企业自主研发的云计算服务平台进行无缝衔接,有效实现大型集团型企业在多云资源和多云服务方面的体系建设和灵活运用。
3.4.1 传统云主机的性能监控效果
对于传统云主机的性能监控,其数据采集和分析展现效果见图9。

图9 传统云主机的性能监控分析效果图
3.4.2 容器云资源的性能监控效果
对于Kubernetes容器云资源的性能监控,其数据采集和分析展现效果见图10。

图10 Kubernetes容器云资源的性能监控分析效果图
3.4.3 多云服务资源的性能监控效果
在多云服务资源监控方面,实现了对各种多云服务(如elasicsearch/minio/rockermq/mysql)的性能监控,数据采集及分析展现效果见图11。
从以上性能指标和展示效果中可看出,多种云资源和云服务的性能监控数据能得到有效的采集和分析展示,在灵活支持和兼容异构多云资源与云服务的情况下,不仅提升了监管效率,而且保证了整个云服务体系的稳定、可靠运营。
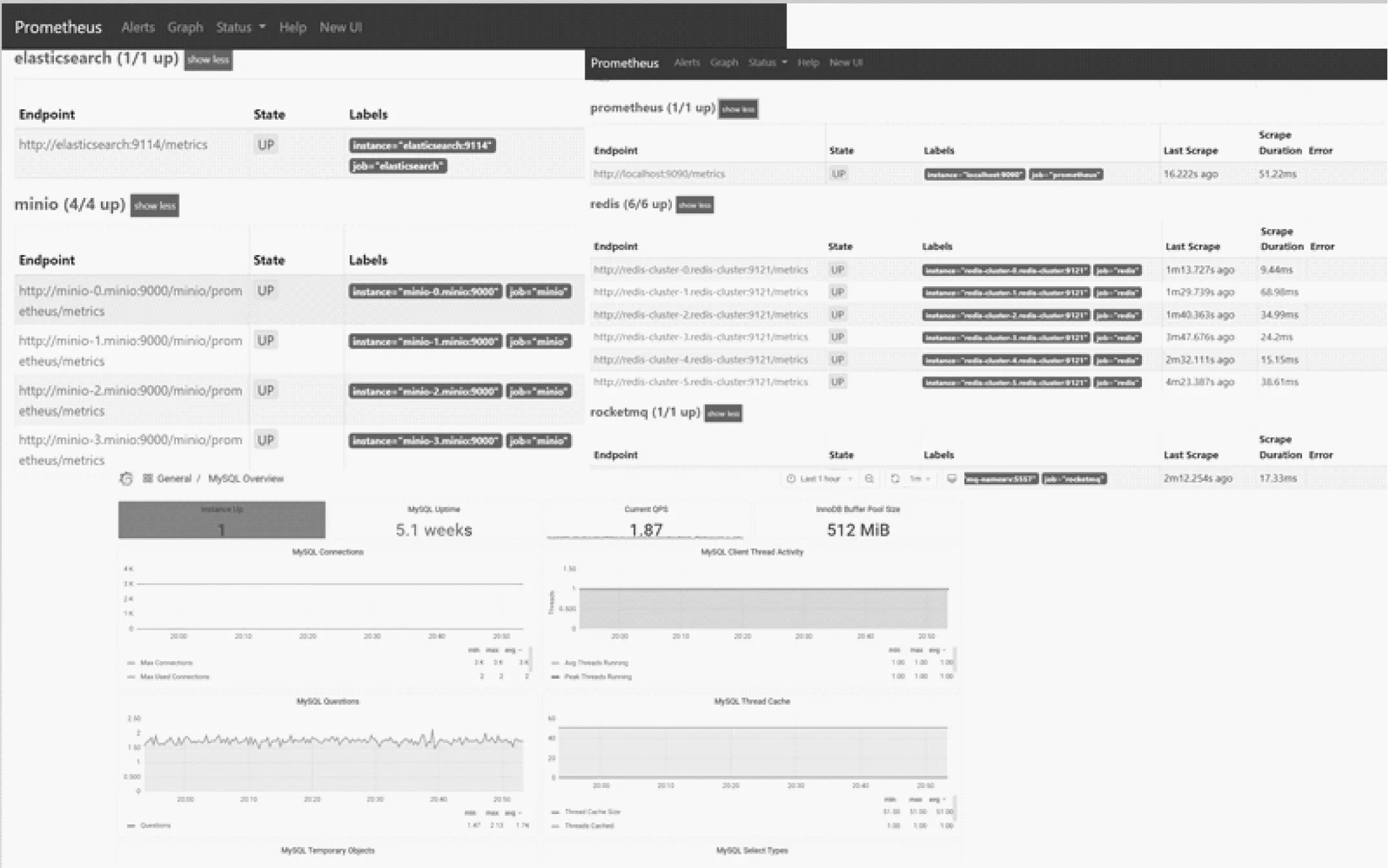
图11 云服务性能监控图分析效果图
4 结 语
当前,很多企业都面临着IaaS和PaaS等云计算服务监控方面的压力,尤其是多云环境下的异种云资源和云服务的统一监控和告警能力。为此,在企业云业务的基础上,构建一个适用于大型集团型企业多云资源和多云服务的性能监控系统尤为重要,不仅能保障云业务高效、稳定开展,而且能提升整体的云运维和服务能力。
猜你喜欢
阅读(快乐英语中年级)(2022年11期)2022-05-30 10:48:04
疯狂英语·新读写(2021年10期)2021-12-07 02:41:30
作文周刊·小学一年级版(2020年20期)2020-09-02 07:17:56
读者·校园版(2019年24期)2019-12-10 06:44:03
新世纪智能(英语备考)(2019年4期)2019-06-26 00:49:04
铁道通信信号(2019年11期)2019-05-21 03:06:06
作文评点报·低幼版(2018年2期)2018-02-09 16:18:14
中国公共安全(2017年8期)2017-10-13 08:12:17
小学生作文·小学低年级适用(2016年4期)2017-01-16 11:00:53
小朋友·聪明学堂(2015年8期)2015-11-30 23:53:53
