
面向社交网络的谣言检测方法研究
2022-05-30 01:07:38钟南江陈轩弘
计算机与网络 2022年13期
钟南江 陈轩弘
摘要:网络谣言已成为近年来威胁社会稳定的一大重要因素,基于社交网络传播的谣言具有变化形式快、扩散速度快和影响层面广等特点,对公安民警的谣言治理水平提出了新的要求。基于机器学习和深度学习的自动化谣言检测方法是当前谣言治理的突破点。对中文微博谣言数据集进行了预处理,采用One-hot,TF-IDF,Doc2Vec将文本向量化,基于逻辑回归、神经网络算法构建相应模型,在谣言数据集上进行了实验性能评估与对比分析。结果显示,基于Doc2Vec和神经网络的谣言检测模型在谣言数据集上的准确率最高。
关键词:社交网络;神经网络;谣言检测
中图分类号:TP391文献标志码:A文章编号:1008-1739(2022)13-57-7

0引言
当前,社交网络中充斥着网络谣言,尤其是在微博等网络自媒体较多的社交网络中,谣言的转发达到了惊人的数量。目前,对于谣言的发现和检测大多通过人工搜索、接受举报等方式,这种方法效率低且具有一定的滞后性,难以对谣言的形成和发展进行有效的预防和封堵。在公安实践中,谣言治理已成为当前工作的一大痛点、难点,如何及时有效地对谣言进行发现、处理是当下需要关注的一个重要问题。本文通过研究分析自然语言处理的前沿算法,提出高效的谣言检测模型,可以为公安实战提供有力支撑。
最常见的方法是将谣言检测问题归结为一个二元分类问题。然而在实际情况中,将所有新闻分为2类(真实新闻或谣言)是困难的,因为某些情况下,谣言中也掺杂了部分的真实新闻。为了解决这个问题,一种常见的做法是增加一个额外的分类。增加分类的方法主要有2种:一种是对既不完全真实也不完全虚假的新闻分成一个单独的类别;另一种是设置2个以上的真实度。后者的分类模式更加接近人类的判断方式。
现有的谣言检测方法[1-2]中常用的分类模型是支持向量机(SVM)和朴素贝叶斯模型(NBC)。逻辑回归(LR)和决策树、随机森林算法(RFC)也被使用。这些算法提取了评论中的文本内容、用户属性、信息传播和时间特性的分类特征,进行特征归一化后使用分类模型进行谣言检测。
目前,随着GPU等计算水平的提高,基于深度学习模型[4-9]在自然语言处理任务中表现优异,并逐渐成为NLP的主流方向。在斯坦福著名的机器阅读理解竞赛中,基于深度学习的模型在SQuAD2.0数据集中的表现已经超过人类水平。
本文研究的是对社交网络中存在的大量中文新闻文本数据进行挖掘和研究,并分析多种自然语言处理模型在谣言检测任务上的性能,比较模型性能以及模型优缺点。最后选取合适的模型应用于社交网络中的谣言检测。
1数据获取与预处理
目前,中文文本的谣言集中出现在微博和微信两大互联网平台上。其中,微信平台由于其相对隐私性,谣言的文本数据较难获取;微博平台有专门的辟谣账号,谣言的文本数据获取难度相对较低。因此,本文采用微博数据进行谣言检测的训练数据,数据来自DataFountain数据科学竞赛网站中的疫情期间互联网虚假新闻检测竞赛的训练数据集(www. datafountain.cn/competitions/422/datasets)。
该数据集中有49 910个样本,共有9个标签,分别为:id(新闻id)、content(新闻的文本内容)、picture_lists(新闻图片id)、comment_2(新闻的至多2条评论)、comment_all(新闻的所有评论)、category(新闻所属领域)、ncw_ label(是否需要进行真值判断)、fake_ label(取值為{0,1},0表示非虚假新闻,1表示虚假新闻)、real_ label(取值为{0,1},0表示非真实新闻,1表示真实新闻)。使用Python的collections库中的Counter函数对标签ncw_ label进行统计,得到{0∶33806,1∶16104},根据标签说明,选取ncw_ label取值为0的33 806个数据作为训练样本。本文基于谣言文本进行分类建模,因此,选取数据集的content和fake_label标签作为本文建模分析的数据。再使用Counter函数对标签fake_ label进行统计,得到{0∶16965,1∶16841},表明,在33 806个数据中,有16 965个真实新闻,16 841个虚假新闻。
实践表明,中文文本中的标点对中文语义的理解影响不大,反而会成为数据的噪声,影响模型的精度。因此,先将中文文本数据中的标点和数字去除,仅留出中文文本。接着,对中文文本进行分词处理。中文文本的分词是基于现有的中文语料,对架设的分词模型进行训练,从而使分词模型获得符合一般中文表达习惯的中文文本切分能力。本文选用pkuseg分词工具包,该分词工具包内专门根据微博语料构建了网络领域模型,分词效果相比同类工具较好。
2特征工程
目前,绝大部分算法工具无法直接对输入的中文信息进行处理,只能在数值上进行运算。因此,需要通过一定的方法将中文的文本数据转换为算法可读的数值化数据,这个转换的过程可称为特征工程,或特征提取。
特征提取的过程也是训练文本表示的过程,是用一组数值向量来表示一个词汇、一个句子、一个段落,从而将文本数据转换为向量化、结构化的数据,以便下游任务使用。文本转化为数值向量后,可以直接对文本映射的向量空间中的点进行数据挖掘和分析。当前,主流的词汇向量化表示方法有2种类型:一种是离散化的文本表示;另一种是分布式的文本表示。
2.1基于离散化的文本表示
One-hot编码是对文本进行编码最简单的方法,是一种离散化的词汇表示方法。One-hot方法首先根据目标文本创建一个大小为的词典,为文本所含的独立的词汇个数,之后将每个词汇映射成长度为的向量,单词在词典的第个位置则将向量的第位标记为1,该向量的其余位置标记为0。

2.2基于分布式的文本表示
由于离散化的文本表示方法无法形成对文本语义的表示,因此引入分布式的文本表示方法。在分布式的文本表示方法中,数值向量是稠密的,一般情况下,词汇在向量的每个维度上都有非0的取值。
2.2.1 Word2vec
当理解一个陌生词汇的意思时,通常会通过它周围的词语的意思对它的意思进行预测。同样的,我们也可以通过一个词来预测其上下文中相关的词。Word2Vec[10]正是借助这一理念构建的词向量模型,其模型结构图如图1所示。

可以看到,Word2Vec主要由3个模块构成:词汇表构建器、上下文环境构建器和参数学习器。词汇表构建器用于接收原始的文本数据,并根据给定的文本语料构建词汇表。上下文环境构建器使用词汇表构建器的输出结果,以及上下文环境窗口的词作为输入,然后产生输出。参数学习器为一个3层的神经网络,输入层神经元的个数和训练的词汇表大小一致,隐层神经元的数量就是最后得到的词向量维度大小,输出层的神经元数量和输入层相同。
Word2Vec中有2个算法:连续词袋(CBOW)算法和跳跃语法(Skip-gram)算法。算法模型如图2所示。

在CBOW算法中,目标词的上下文环境由其周边多个词来表示,而Skip-gram算法则反过来利用目标词预测上下文的词。
2.2.2 Doc2Vec
Doc2Vec[3]由Quoc Le和Thomas Mikolov于2014年提出。他们基于Word2Vec进行了改进,并且使得文档向量的大小不受文档词汇个数的影响,并且在较大的文本数据中,拥有比Word2Vec更好的文本语义捕捉能力。
Doc2Vec的训练方式与Word2Vec大体相同,但在Doc2Vec中,增加了一个句向量来表示文段的意思,每次训练时,Doc2Vec都会设置滑动窗口并截取窗口大小数量的词与句向量共同进行训练,此时的句向量可以看作一个一直参与训练的词向量,因此,每次训练句向量都能捕获到训练词表达的语义,该向量对文段主旨的表达会越来越准确,并最终作为整个文段的向量表示。
3模型建立
3.1逻辑回归

3.2神经网络
神经网络可以理解为一个能拟合任意函数的黑匣子,每个神经网络都有输入层\输出层\隐藏层,每个层之间根据任务的需要,也会设置若干个节点。输入层和输出层各有一个,可以理解为函数中的自变量和应变量,而隐藏层可以有多個,类似于函数中的系数,在神经网络中,隐藏层是不可见的,层与层之间都有特定的链接方式。以全连接神经网络为例,本层的单个神经元接收上一层所有神经元的传入,输入维度是上一层的节点个数,同时,神经元的输入又与下一层的所有神经元相连接。如图3所示是一个4层的神经网络结构图,第1层为输入层,有12个神经元;第2、3层为隐层,分别有8个和2个神经元;第4层为输出层,有1个神经元。

本文采用5层的全连接神经网络进行模型的训练,其中第1层为输入层,接收传入的句向量,句向量维度为64维,第2~4为隐藏层,神经元个数分别为32,16,8;第5层为输出层,输出一个一维的结果。
4实验分析
4.1评价指标
本文将33 806个样本数据分成训练数据和测试数据,训练数据共27 044条,占到总样本数的80%,测试数据共6 762条,占到总样本数的百分之20%。在句向量维度上选择64维的向量作为模型的输入。模型性能评估采用准确率(Accuracy)、精确度(Precision)、召回率(Recall)和F1 Score作为评价指标。模型在对训练数据拟合后,对测试数据进行预测,并选取模型输出值大于0.5的数据作为预测的正例。根据预测结果生成混淆矩阵,混淆矩阵如表1所示。

其中,TP代表将正例预测为正例数;FN代表将正例预测为反例数;FP代表将反例预测为正例数;TN代表将反例预测为反例数。

從实验结果来看,使用Doc2Vec作为文本表示方法,使用神经网络作为分类模型在各个指标上都优于其他组合,说明这2种方法组合有更好的谣言识别能力。
4.3模型性能对比
为了对比模型的收敛性和训练效率,进行了模型性能对比实验。
One-hot和TF-IDF文本表示方式由于其实现方法类似,因此在模型性能上表现相似。图4是One-hot+逻辑回归模型迭代训练200次的损失和准确率变化图。图5是TF-IDF+逻辑回归模型迭代训练200次的损失和准确率变化图。其中,蓝色部分为损失值,点表示样本在训练集上的损失,线表示样本在测试集上的损失;红色部分为精确度,点表示样本在训练集上的损失,线表示样本在测试集上的损失。

从图4和图5中可以看出,One-hot和TF-IDF算法处理的样本数据都在进行逻辑回归迭代50次后趋于收敛,模型精度保持在80%,训练效率没有明显的区别。
图6和图7是使用One-hot和TF-IDF进行文本表示后,使用神经网络进行谣言检测的性能图,可以看到模型识别准确率较逻辑回归有较大的提升。但其在迭代200次后仍然还未收敛,模型损失函数值(蓝色曲线)仍然呈现下降的趋势,这是由于神经网络的模型更复杂,参数更多,模型训练需要花费更多的时间和迭代次数。

图8和图9为使用Doc2Vec作为文本表示方法,分别使用逻辑回归和神经网络作为分类器,模型准确率和损失值的变化趋势图。可以看到,当Doc2Vec通过全连接神经网络进行训练时,模型效果提升较大。但是逻辑回归在模型迭代至200次时测试集准确率已经趋于平缓,而神经网络在迭代800次时才逐渐趋于平缓,说明逻辑回归消耗的计算资源更少,模型更加高效。
再将图4、图5、图8进行对比,可以看到,使用Doc2Vec比One-hot和TF-IDF两种表示方法需要迭代更多的次数模型才会收敛。

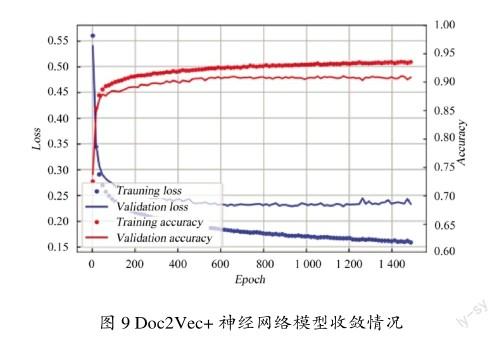
通过模型性能比较试验可以得出以下结论:逻辑回归模型的收敛速度比神经网络更快,但准确率比神经网络低;使用离散型文本表示方法One-hot和TF-IDF比使用分布式文本表示Doc2Vec模型的速度更快,但准确率更低。因此模型的选择应考虑实际的使用需要,如果对准确率要求不高且计算能力有限时,使用离散化的文本表示与逻辑回归结合的模型能够满足其要求;若算力充足并且对准确率有较高的要求,则建议使用分布式文本表示方法与神经网络结合的模型进行分类。
4.4神经网络结构对比
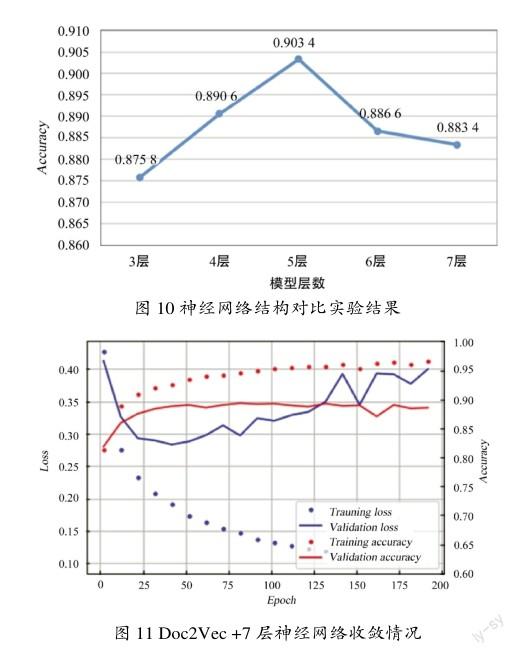
为了选择合适的模型结构,构造了不同的神经网络结构,并对它们的识别准确率进行比较。分别构建了3层(64×18×1)、4层(64×32×16×1)、5层(64×32×16×8×1)、6层(64×32×16×8×4×1)、7层(64×40×30×20×10×5×1)的神经网络,括号中为每一层的神经元数量。选择Doc2Vec作为文本表示方法,实验结果如图10所示,可以看到,5层的神经网络识别准确率最高。3层~5层,随着模型层数的增加,识别准确率越来越高。但当模型层数增加到6层之后,模型的准确率有较大幅度的下滑,这是由于模型出现了过拟合。
为了验证模型的确出现了过拟合,将7层神经网络的收敛情况通过图11展示出来,其中红色虚线为训练集准确率变化趋势,红色实线为测试集准确率变化趋势,在迭代100次后训练集准确率仍然在不断提高,但测试集准确率开始下滑;蓝色虚线为训练集损失,蓝色实线为测试集损失,他们之间的变化趋势有着非常明显的区别,在训练迭代25次后测试集损失有明显的上升,并且出现了较大幅度的波动,但训练集损失仍然在不断下降。以上均为过拟合的表现。
因此,在该数据集上,最终选择5层(64×32×16×8×1)神经网络作为本文的模型结构。
5结束语
本文从特征提取和模型搭建2个角度分析了谣言文本检测算法,并对相关算法模型进行了介绍说明,在最后对各个算法模型的组合进行了实验分析,比较了他们在准确率、精确度、召回率和F1 Score指标的表现。
未来,谣言检测任务还能够在以下方面进行提升与改进:样本数量可以进行扩充,本次实验仅使用了新浪微博上的文本,下一步还可以加入其他社交网络的谣言文本和常规语料,以提高模型的泛化能力;模型复杂度还需进一步提升,目前自然语言处理领域已有如Bert,Transformer等更高效的模型,下一步可以将这些模型应用到谣言检测任务中;样本类型可以进一步丰富,大量谣言在发布其文本的同时,还会发布一些吸引人眼球的图片,下一步可以融合自然语言处理和计算机视觉的模型,对谣言文本和图片进行综合分析检测。
参考文献
[1] KE W,SONG Y,ZHU K Q.False Rumors Detection on Sina Weibo by Propagation Structures[C]// IEEE International Conference on Data Engineering.Seoul:IEEE,2015:651-662.
[2]段大高,蓋新新,韩忠明,等.基于梯度提升决策树的微博虚假消息检测[J].计算机应用,2018,38(2):410-414.
[3] Le Q V, Mikolov T. Distributed Representations of Sentences and Documents[C]//International Conference on Machine Learning.Toronto:JMLR,2014:1188-1196.
[4] JING M,WEI G,MITRA P, et al. Detecting Rumors from Microblogs with Recurrent Neural Networks[C]//25th International Joint Conference on Artificial Intelligence.New York,2016:3818-3824.
[5] MA J, GAO W, WONG K F. Rumor Detection on Twitter with Tree-structured Recursive Neural Networks[C]// 56th Annual Meeting of the Association for Computational Linguistics.Melbourne:ACL,2018:1980-1989.
[6] YU F, LIU Q, WU S, et al. A Convolutional Approach for Misinformation Identification[C]// 26th International Joint Conference on Artificial Intelligence.Melbourne:IJCAI.2017: 3901-3907.
[7] YU F, LIU Q, WU S, et al. Attention-based Convolutional Approach for Misinformation Identification from Massive and Noisy Microblog Posts[J]. Computers&Security,2019, 83: 106-121.
[8]冯茹嘉,张海军,潘伟民.基于情感分析和Transformer模型的微博谣言检测[J].计算机与现代化, 2021(10):1-7.
[9]段大高,王长生,韩忠明,等.基于微博评论的虚假消息检测模型[J].计算机仿真, 2016,33(1):386-390.
[10] MIKOLOV T, CHEN K, CORRADO G, et al. Efficient Estimation of Word Representations in Vector Space[J/OL].[2022-03-15]. https://arxiv.org/abs/1301.3781.
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
电脑知识与技术(2016年24期)2016-11-14 00:32:08
企业导报(2016年20期)2016-11-05 18:53:13
戏剧之家(2016年19期)2016-10-31 19:44:28
新闻前哨(2016年10期)2016-10-31 17:46:44
重型机械(2016年1期)2016-03-01 03:42:04
大连工业大学学报(2015年4期)2015-12-11 04:06:52
海军航空大学学报(2015年4期)2015-02-27 13:45:47
电测与仪表(2014年20期)2014-04-04 11:58:02
电测与仪表(2014年2期)2014-04-04 09:04:04
