
基于多尺度注意力网络的电工着装不规范检测
2022-05-30 10:48毛峰凌永标郭尹江志强耿浩任佳锐
电脑知识与技术 2022年21期
毛峰 凌永标 郭尹 江志强 耿浩 任佳锐

摘要:针对电力安全施工中施工人员着装不规范问题,笔者采用智能视觉计算中的目标检测技术,对施工人员是否佩戴安全帽以及穿着工作服是否规范的情况进行自动检测,提出一种基于多尺度注意力网络(MAR-CNN)的着装不规范检测方法。该方法针对安全帽及着装等目标大小不一的多尺度特性,在Faster R-CNN网络的基础上,结合了特征金字塔(FPN)思想,设计了多尺度注意力(MA)网络模块。此外,该注意力机制可以有效抑制背景特征,增强检测对象的特征,有效缓解施工现场背景复杂带来的错检漏检现象。在电网施工现场数据集上的实验结果表明笔者所提方法具有有效性。
关键词:目标检测;着装检测;电力安全;多尺度网络;注意力机制
中图分类号:TP381 文献标识码:A
文章编号:1009-3044(2022)21-0004-04
开放科学(资源服务)标识码(OSID):
电力建设施工具有工人多、工作内容繁多和危险系数大等特点,因此为了保障现场人员的人身安全及预防危险,佩戴安全帽及安全着装显得尤为重要。然而,存在有小部分施工人员防范意识薄弱,经常不戴安全帽或未规范着装进入施工现场,更有甚者在施工过程中摘除安全帽和脱掉工作服,给电力施工建设带来危险。电网安全施工监管急需对施工全过程中工人不规范着装进行自动化检测和报警的解决方案。
随着人工智能深度学习的发展,计算机视觉的研究广泛应用于智能视频监控、机器人导航、工业检测、智慧医疗等诸多领域,通过相关技术的应用可以有效减少对人力资源的消耗,具有重要的现实意义。目标检测正是计算机视觉的一个热门方向。笔者利用目标检测技术对施工现场工人的一些不规范着装进行全程自动化地检测,可以有效地提升智能电网现场作业安全管控的能力。
为了实现电力施工人员着装不规范的自动化检测,笔者收集并标注了一批电力施工现场的工人规范着装与不规范着装的数据集。图1展示了一对电力施工人员着装规范与不规范的示例。笔者标注施工人员安全帽正常佩戴和未佩戴、工作服穿戴规范和不规范这几种典型类别,其中“aqm”表示安全帽正常佩戴,“aqmqs”表示安全帽未佩戴,“gzf”表示工作服穿戴规范,“gzfyc”表示工作服穿戴不规范。
笔者提出一种基于多尺度注意力网络(MAR-CNN)的着装不规范检测方法。该方法针对安全帽及着装等目标大小不一的多尺度特性,在Faster R-CNN网络的基础上,结合了特征金字塔(FPN)思想,设计了多尺度注意力(MA)网络模块。此外,该注意力机制可以有效抑制背景特征,增强检测对象的特征,有效缓解施工现场背景复杂带来的错检漏检现象。
1 相关工作
1.1 经典的目标检测网络
目标检测是计算机视觉中的一个重要任务,近年来得到了广泛的研究。目前,基于深度学习的目标检测框架主要分为两大类:一类是两阶段目标检测算法,这类算法以区域卷积神经网络R-CNN[1]为代表;另一类是单阶段目标檢测算法,以SSD[4]等为代表,从回归的角度出发,研究目标检测问题。而两阶段目标算法是一种将目标检测统一为区域建议加分类器的框架,即将检测任务分为回归任务和分类任务。一般来说,两阶段目标算法在许多公共基准数据集上可以获得更好的检测性能。
Ross Girshick等人将候选区域[5]与CNN结合起来,提出一种目标检测算法R-CNN[1]。R-CNN利用了Selective Search[6] 获得候选区域,之后对候选区域的大小进行处理后,进行特征提取,再使用分类器判别是否属于特定的类别。对于选定的候选框,使用回归器进一步调整边界位置。而Fast R-CNN[2]将R-CNN的多个步骤整合在一起,对于候选区域的提取仍然使用的是Selective Search算法。Faster R-CNN[3]主要是通过使用RPN网络代替Selective Search算法,RPN网络通过在特征图上做滑窗操作,使用预定义好尺度的锚框映射到原图,得到候选区域,实现端到端的目标检测。Cascade R-CNN[7]提出一种multi-stage的网络,利用前一个阶段的输出进行下一阶段的训练,阶段越往后使用更高的IoU阈值,保证样本数量的情况下产生更高质量的检测框。
1.2 多尺度网络
目标大小尺度不一的问题一直是目标检测的主要难点之一。多尺度图像金字塔是一种常用的改进方案[8]。在图像金字塔策略的基础上,SNIP[9]提出一种尺度归一化方法。但是,他们的推理速度较慢。另外一些方法利用不同空间分辨率的多层次特征来缓解尺度变化,或者直接根据骨干网络提出的金字塔特征层次结构作为检测器进行预测[7,12]。ION[10]连接不同层的特征,以生成更好的特征图进行预测。为了弥补底层特征中语义的缺失,FPN网络[11]提出一种自上而下地融合多尺度特征的路径,以在高层特征中整合强语义信息。PANet[15]在FPN上增加了一个额外的自底向上的路径聚合网络;STDL[12]提出一个利用跨尺度特性的尺度转换模块;M2det[13]提出一个U形模块来融合多尺度特征。
1.3 注意力网络模块
注意力网络模块的核心思想是基于原有的数据找到其之间的关联性,根据重要程度不同赋予不同的权重。自注意力机制是注意力机制的改进,其减少了对外部信息的依赖,更擅长捕捉数据或特征的内部相关性,能够有效提高模型训练的并行性和效率。SENet[14]通过显式建模通道之间的相互依赖性自适应地重新校准通道的特征响应,可以利用小的计算代价获取大的性能提升。Huet等人[15]提出一种应用自注意力机制的目标关系模块,对一组目标以及它们之间的关系进行建模,提高对象的识别能力。DANet[16]通过融合并行的通道注意力模块和位置注意力模块的结果来捕获丰富的上下文相关性,自适应地将局部特征与其全局相关性相结合。SANet[17]通过池化层实现多尺度特征聚合,同时生成软全局注意掩码,增强像素级密集预测的目标。
针对电力施工现场存在的场景复杂导致的尺度变化多样性等问题,笔者结合了特征金字塔(FPN)思想,设计了多尺度注意力(MA)网络模块,提出了一个多尺度注意力网络。
2 多尺度注意力网络(MAR-CNN)
本文基于对目标检测网络和区域建议生成网络共享全图像卷积特征的Faster R-CNN网络结构进行设计。为了对一张既具有高分辨率又具有较强语义信息的特征图进行预测,网络结合了在以特征金字塔为基础结构对每一层级的特征图分别进行预测的FPN结构。针对电力施工场景中,随着施工规模、地点的不同,目标尺度丰富以及背景复杂这一现象,本文设计出一个多尺度注意力(MA)模块。
2.1 多尺度注意力(MA)模块
为了缓解目标尺度变化较大带来的障碍,笔者参考了现有的一些多尺度信息融合的方式,并在融合中增加通道注意力,詳细结构如图2所示。
受相互学习思想[18]的启发,Pang等人[19]提出了一种聚合交互策略(AIM),以更好地利用多层次特征,避免因分辨率差异较大而对特征融合造成干扰。单级特征只能表征尺度特定的信息。在自上而下的路径中,浅层特征的细节表现能力由于深层特征的不断积累而减弱。受上述思想启发,本文融合相邻层的特征,因为它们的抽象程度更接近,同时获得了丰富的尺度信息。如图2所示,可分为三种融合方式。第一种,将来自ResNet网络第一层的特征与第二层的特征进行融合,首先将高低层特征分别采样到对方分辨率大小,再分别进行融合,然后将融合过后的特征再次进行融合(此时融合后特征分辨率与低层特征分辨率相同),再增加一条残差连接,将特征与低层特征融合。第二种,融合方式同第一种,只是此时选取ResNet网络三层相邻特征进行融合,最终特征大小分辨率与中间层特征相同。第三种,同前两种方式,选取ResNet网络第三层的特征与第四层的特征进行融合,最终特征大小分辨率与高层特征相同。
另外,由于电力施工场景背景较为复杂,常施工于城市街道、乡村街道、农田等各种不同场景下,为了抑制这种背景带来的不利影响,笔者在尺度信息融合过程中,使用了Squeeze-and-Attention模块(SA)[17]。SA模块扩展于SE模块[14]并引入了通道注意力机制,通过通道之间的相关性把重要的特征增强,不重要的特征减弱,从而让提取的特征指向性更强,对网络性能带来了一定的性能提升。
2.2 基于多尺度注意力的目标检测网络
MAR-CNN目标检测网络的整体结构见图3,主干网络选取ResNet101网络,将主干网络后四层获取到的特征送入多尺度注意力模块,经过MA模块后得到特征:[Cii∈1,2,3,4]。
再结合带有top-down结构和横向连接的FPN[11]结构设计,以此融合具有高分辨率的低层特征和具有丰富语义信息的高层特征。此时,笔者得到特征[Pii∈1,2,3,4],再使用RPN网络进行预测。RPN网络实际分为2条分支,一个分支通过softmax分类用来判断anchors是否为需要检测的物体,另一分支用于计算对于anchors的边界框回归的偏移量,以获得精确的proposals。而最后的proposal层则负责综合前景anchors和与其对应边界框回归的偏移量获取最后的proposals,同时剔除太小和超出边界的 proposals。RPN 提高了区域建议质量,从而提高了整体目标检测精度。另外,图3中Res_layer [ii∈1,2,3,4]表示的是不同的ResNet层,FC为全连接层。
3 实验
3.1 实验环境
实验代码基于PyTorch深度框架。在训练阶段,采用数据增强技术来避免过拟合问题。笔者的网络在Tesla P100-PCIE-16GB上训练了20个epoch。经实验证明,20个epoch已经可以使模型收敛。骨干网络参数(ResNet-101)使用ImageNet数据集上预先训练的相应模型进行初始化。笔者使用动量SGD优化器,其权重衰减为0.0001,初始学习速率为0.02,动量为0.9。
3.2 数据集
本文实验所使用的数据来源于真实电力施工场景。笔者针对电力施工人员工作服穿戴、安全帽佩戴情况,共实地收集了5431张图片,并从中划分4888张图片作为训练集,其余作为验证集。数据共包括4类对象,表1列举出笔者制作的数据集的具体检测对象分布情况,其中数量表示的是每一类检测目标的标注框数量而非图片数量。每一张图片中可能包含多个标注框。笔者的数据集存在的挑战主要是由真实场景中施工现场的多样性带来了目标对象的尺度变化较大,另在街道中施工时,行人及旁观者也将被进行检测,这对笔者的检测效果带来了一定的挑战。
3.3 对比实验
3.3.1 与其他现有方法对比
将MAR-CNN方法与其他的方法在真实施工场景数据集上进行比较,笔者将Faster R-CNN[3]、SSD[4]、Cascade R-CNN[7]、GFL[20]、ATSS[21]5种目标检测方法以及MAR-CNN方法的实验结果展示在表2中。从表中数据,可以说明笔者方法的有效性。在真实施工场景的数据集上,笔者的方法针对施工人员佩戴安全帽和穿戴工作服的检测结果具有一定的可靠性,从而更大程度地对施工人员的人身安全进行保护。
为了更好地说明,笔者绘制了实验过程中的loss变化图,以及各类方法的mAP结果图,如图4和图5。图4中,横坐标为训练迭代次数。如图5所示,本文方法的收敛速度与效果是图中最好的,横坐标表示为训练epoch次数。从各个数据对比中可以看出,本文方法与其他方法相比较,达到了最优的性能。
3.3.2 模块有效性对比实验
MAR-CNN是基于Faster R-CNN[3]网络结构,结合FPN[11]思想,并使用了带有通道注意力的信息融合模块。
笔者首先讨论MAR-CNN对比带有FPN[11]思想的Faster R-CNN[3]网络的效果。如表3所示,从检测结果可以看出,MAR-CNN方法的检测精度更高一些。其中AP0.5表示在训练和测试中使用的阈值。AP0.5是指当检测框与标注框重叠的交并比超过0.5即认为检测到目标时的平均精度,AP0.75表示阈值为0.75。
同时,笔者对不同尺度目标的检测精度进行了分析,如表4所示。表4中选用的IoU为0.5,目标的标注面积小于322为小目标,用APs来表示;目标的标注面积介于322和962之间的称为中等目标,用APm来表示;目标的标注面积大于962的称为大目标,用APl来表示。如表4所示,笔者的方法在三种尺度的目标上检测精度均高于带有FPN[11]思想的Faster R-CNN[3]网络的检测精度,这也从侧面说明了本文所提的MA模塊的有效性。
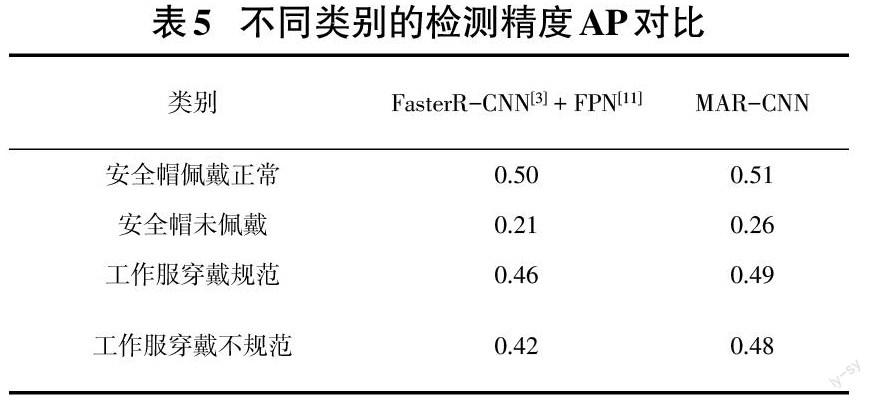
其次,笔者对不同的检测类别结果也做了分析,并将结果展示于表5中,此时检测框与标注框重叠的交并比的阈值设定为0.7。从表5中,笔者可以发现,安全帽未佩戴的检测精度整体较低,这是因为未佩戴的情况大多为施工现场的非工作人员以及极少部分的工作人员,导致安全帽未佩戴的情况更加丰富,其中一个表现就是尺度变化更丰富。相对于带有FPN[11]思想的Faster R-CNN[3]网络,笔者的方法在这个类别上的检测效果也可以达到小幅度的提升,从而说明本文方法的有效性。
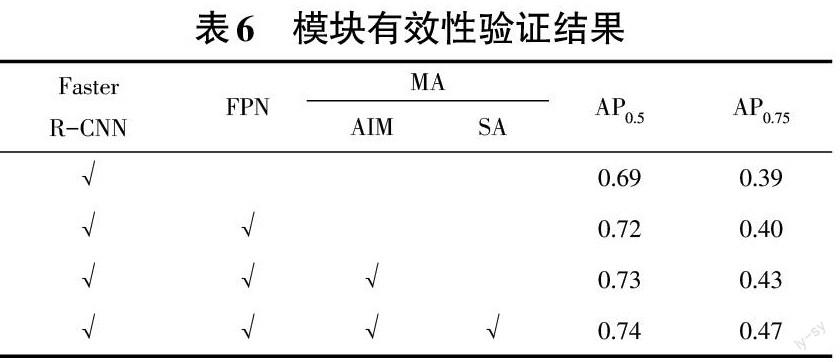
为了更直接地说明笔者所提方法中各模块的有效性,针对网络中有无FPN思想、有无聚合交互策略(AIM)以及有无通道注意力机制做了对比实验,并将实验结果展示在表6中。另外,笔者选择SE模块作为注意力机制替换SA时,AP0.75仅有0.42,AP0.5仅为0.71。从而更加直观地说明多尺度注意力(MA)模块的有效性。
4 结论
为了进一步提升电力施工现场的安全性,保障现场人员的人身安全,笔者设计出一种多尺度信息融合目标检测算法MAR-CNN,对电力施工人员着装不规范的典型情况进行自动检测。为了得出更可靠的结果,笔者收集了真实场景的施工现场图片,制作出一个电网施工人员着装数据集,并在这个数据集上验证了笔者方法的有效性。
参考文献:
[1] Girshick R,Donahue J,Darrell T,et al.Rich feature hierarchies for accurate object detection and semantic segmentation[C]//2014 IEEE Conference on Computer Vision and Pattern Recognition.June 23-28,2014,Columbus,OH,USA.IEEE,2014:580-587.
[2] Girshick R.Fast R-CNN[C]//2015 IEEE International Conference on Computer Vision.December 7-13,2015,Santiago,Chile.IEEE,2015:1440-1448.
[3] Ren S Q,He K M,Girshick R,et al.Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[4] Liu W,Anguelov D,Erhan D,et al.SSD:single shot MultiBox detector[M]//Computer Vision – ECCV 2016.Cham:Springer International Publishing,2016:21-37.
[5] Hosang J,Benenson R,Dollár P,et al.What makes for effective detection proposals?[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2016,38(4):814-830.
[6] Uijlings J R R,Sande K,Gevers T,et al.Selective search for object recognition[J].International Journal of Computer Vision,2013,104(2):154-171.
[7] Cai Z W,Vasconcelos N.Cascade R-CNN:delving into high quality object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:6154-6162.
[8] Liu S,Qi L,Qin H F,et al.Path aggregation network for instance segmentation[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:8759-8768.
[9] Singh B,Davis L S.An analysis of scale invariance in object detection - SNIP[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:3578-3587.
[10] Bell S,Zitnick C L,Bala K,et al.Inside-outside net:detecting objects in context with skip pooling and recurrent neural networks[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition.June 27-30,2016,Las Vegas,NV,USA.IEEE,2016:2874-2883.
[11] Lin T Y,Dollár P,Girshick R,et al.Feature pyramid networks for object detection[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.July 21-26,2017,Honolulu,HI,USA.IEEE,2017:936-944.
[12] Zhou P,Ni B B,Geng C,et al.Scale-transferrable object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:528-537.
[13] Zhao Q J,Sheng T,Wang Y T,et al.M2Det:a single-shot object detector based on multi-level feature pyramid network[J].Proceedings of the AAAI Conference on Artificial Intelligence,2019,33:9259-9266.
[14] Hu J,Shen L,Sun G.Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:7132-7141.
[15] Hu H,Gu J Y,Zhang Z,et al.Relation networks for object detection[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.June 18-23,2018,Salt Lake City,UT,USA.IEEE,2018:3588-3597.
[16] Fu J,Liu J,Tian H J,et al.Dual attention network for scene segmentation[C]//2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 15-20,2019,Long Beach,CA,USA.IEEE,2019:3141-3149.
(下轉第14页)
(上接第7页)
[17] Zhong Z L,Lin Z Q,Bidart R,et al.Squeeze-and-attention networks for semantic segmentation[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020:13062-13071.
[18] Ying Zhang, Tao Xiang, Timothy M Hospedales, et al. Deep mutual learning. In CVPR, pages 4320–4328, 2018.
[19] Pang Y W,Zhao X Q,Zhang L H,et al.Multi-scale interactive network for salient object detection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020:9410-9419.
[20] Xiang Li, Wenhai Wang, Lijun Wu,et al. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv preprint arXiv:2006.04388, 2020.
[21] Zhang S F,Chi C,Yao Y Q,et al.Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).June 13-19,2020,Seattle,WA,USA.IEEE,2020:9756-9765.
【通联编辑:唐一东】
猜你喜欢
现代电子技术(2018年8期)2018-04-13
智能计算机与应用(2017年5期)2017-11-08
山东工业技术(2016年23期)2016-12-23
科学与财富(2016年28期)2016-10-14
科学与财富(2016年28期)2016-10-14
