
语音识别技术在慕课学习平台的应用探究
2022-05-30 12:21季莉
电脑知识与技术 2022年22期
季莉
摘要:慕课学习平台的建设与应用正蓬勃发展,目前海量的视频学习资源只能按照学校名称或课程名称去搜索,学习者很难精准快速定位到具体知识技能点的讲课视频。基于语音识别技术来解决慕课学习中的痛点问题,帮助学习者快速精准搜索到目标视频,从而获得更好的学习体验,进一步提升教育资源的价值,是人工智能技术在慕课平台的创新应用。
关键词:语音识别;慕课平台;人工智能
中图分类号:G43 文献标识码:A
文章编号:1009-3044(2022)22-0058-02
人工智能的热潮席卷全球,也正深度影响着教育行业。2018年,教育部发布了《高等学校人工智能创新行动计划》,从高等教育领域推动落实人工智能发展;2019年2月,《中国教育现代化2035》发布,提出新一代智能技术要融合传统教学,统筹建设一体化智能化教学、管理与服务平台,打造智能化校园,推动和促进人才培养模式改革。
同时期,我国的在线课程建设与应用正蓬勃发展,学习平台不断涌现、课程数量不断增加、学习者规模越来越大。截至2020年3月,我国共2.3万余门慕课上线,学习人次达3.8亿,超过1亿人次获得慕课学分[1]。学术上关于慕课的研究成果丰富、热点多元,研究多集中在混合教学模式、高等教育影响、信息素养教育、商业模式、困境与对策、可视化分析等角度[2],而关于人工智能技术在慕课应用的论文,却明显数量较少,研究不足。本文从语音识别技术的角度,探索提升慕课深度应用的新途径。
1 慕课学习资源精准搜索的困境
慕课突破传统教育的时空界限,聚集海量名师名课,共享优质教学资源,极大地丰富了学习者的选择性。目前慕课的学习平台资源的搜索方式,基本按照学校名称、专业名称或者具体课程名称,则能得到精准的回应,这种搜索方式适合学习者系统地学习一门课程;但是如果学习者想从海量视频资源中迅速找到某个具体知识技能点,则往往无法得到精准的回应,甚至没有返回结果,而现实中,无论是复习考試或者是求职工作,确实存在着大量的学习者急需要快速搜索到精准讲解视频的需求。
如何从繁杂的视频数据库中检索出人们感兴趣的视频,一直是信息时代的难题。传统的依靠手工标注的基于文本的视频检索,已经无力应对如今海量的数据;近年来,基于内容的视频检索也应运而生,但该技术依据的是颜色、大小、形状、纹理等视频的底层特征[3];随着深度学习技术的发展,视频检索往高层特征的深度学习发展,可以解决依据一段视频在海量数据库中检索出相似视频的需求[4]。然而,上述解决方案都无法解决本文提到的问题。
2 语音识别技术在慕课学习平台的应用方案
语音识别是利用机器设备接收和理解人类语言的交叉学科应用技术,涉及语言学、计算机科学、心理学和信号处理等众多领域,是实现人机交互的关键性技术[5]。近年来由于人工智能方向上的进步,语音识别取得了突破性的发展,在智能家居、声控语音拨号系统、医药卫生、教育培训等各个领域进入实用化阶段[6-7]。本文研究和关注基于语音识别技术来解决慕课学习中的痛点问题,帮助学习者既能快速精准搜索到目标视频,而背后又无须耗费大量人力做支持,从而获得更好的用户体验,进一步提升平台的价值。
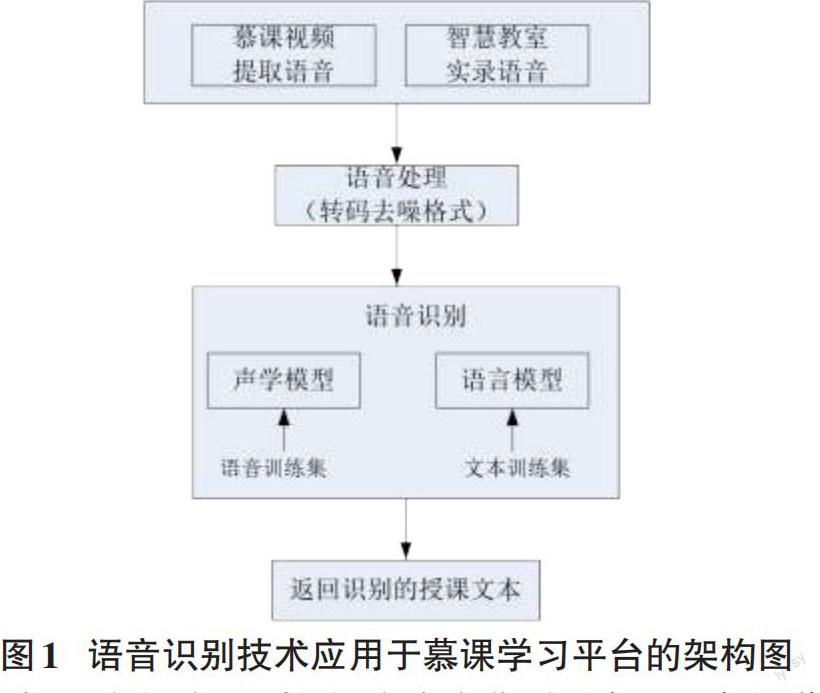
在慕课学习平台中增加语音识别功能,不更改原慕课平台的主体,以节省开发成本、降低风险。应用方案架构图如图1所示,具体流程包括:
首先,进行语音识别的语音来自慕课平台上现存的讲课视频以及智慧教室形成的上课实录语音流,其中视频文件需要抽取语音流,形成语音库;
然后,语音识别前需要对语音做一定的处理,包括降噪、设置比如采样率及声道等参数、转换文件压缩格式等,否则会影响语音识别率。语音识别引擎有两大模块:声学模型和语言模型。声学模型就是用语音训练集来进行训练学习语音;语言模型就是通过对文本训练集的反复训练和迭加优化,来刻画文本和文本之间的概率权重。这两个模块合起来执行就能得到识别结果。
最后,识别的授课语音形成文档返回。而关于文档的搜索技术则已经非常成熟,这样,学习者就解决了如何从浩如烟海的慕课视频,快速搜索定位到具体知识技能点课件的难题。
3 关键问题及拟采取的解决措施
3.1 抽取慕课视频中的语音流数据
慕课平台的老师讲课视频多采用MP4(mp4,m4a,m4v,f4v,f4a,m4b,m4r,f4b,mov)或者WMV (wmv, wma, asf*)等格式,常用的音频格式则有MP3、WMA、AAC等格式,具体要讲视频抽取转换成哪种音频格式取决于下一步语音识别模块中支持的格式。
MoviePy是一个用于视频编辑的Python库,可以实现切割、拼接、标题插入、视频合成、视频处理和自定义效果的创造。安装Moviepy库,运用VideoFileClip函数读取MP4视频,然后提取音频并输出,即可以实现从教师的讲课视频中抽取语音流数据的功能。
3.2 使用语音识别模型识别语音流数据
使用语音模型识别语音流数据,该系统通常由语音信号预处理、语音特征提取、声学模型、语言模型和语音搜索解码算法构成[8],最终目标是将一段语音信号转换为输出的文本文字。语音识别模块技术要求较高,可以借助第三方云AI。目前公开的云AI有微软的Azure Machine Learning或IBM的IBM Bluemix、亚马逊网站服务的Amazon Machine Learing等海外公司产品,以及百度AI、腾讯AI等国内产品。比如在百度AI注册后建立应用并记录对应的API_KEY和SECRET_KEY,作为调用API(Application Programming Interface,简称API) 的身份凭识。根据音频url、音频格式、语言id以及采样率等参数创建音频转写任务。创建成功后,音频会开始进行语音转写任务,再通过查询结果接口进行结果查询,获得识别结果。
首先是创建账号及应用,获取AppID、API Key、Secret Key,并通过请求鉴权接口换取 token,主要代码如下。
grant_type = "client_credentials"
client_id = "API Key"
client_secret = "Secret Key" # 创建应用所获取的API Key、Secret Key
url='https://openapi.baidu.com/oauth/2.0/token?grant_type=client_credentials&client_id={}&client_secret={}'.format(client_id, client_secret)
res = requests.post(url)
token = json.loads(res.text)["access_token"]
print(token) # 獲取token
然后是音频文件转码,需要将抽取到的音频转成符合语音识别模块输入要求格式的音频。百度语音支持pcm、wav、amr、m4a格式,音频参数为单声道、16000的采样率以及16bits编码。最后是创建识别请求,通过POST方式提交音频,返回识别结果。
headers = {'Content-Type': 'application/json'} # 固定头部
url = "https://vop.baidu.com/server_api"
data = {
"format":"pcm",
"rate": 16000,
"dev_pid": 1537,
"speech": speech,
"cuid": CUID,
"len": size,
"channel": 1,
"token": token,
} # 语音数据JSON格式参数
req = requests.post(url, json.dumps(data), headers) # 通过post方式提交音频
result = json.loads(req.text)
return result["result"][0][:-1] # 返回识别结果
4 测试与结论
邀请14位老师,其中男性7位,女性7位,年龄为26~60岁,口齿清晰,发音流利。通过佩戴收音耳麦在授课环境下录音,语音信号以16bit量化的16KHZ采样,形成语音文件。
为简化测试,将每堂课的授课录音选取约5分钟作为测试语音。授课老师整理各自的授课实录形成人工文本文件。语音文件和人工文本文件一一对应,以便后续作比对处理。创建应用,将测试语音文件上传,调用接口进行测试。譬如选择某段中国文化课堂测试语音,时长为5分10秒,大小为54M,字数为1188个,测试的识别结果与人工文本比对后发现75个错字,错字率为6.31%。同样的方法,将所有学科的授课测试语音做识别比对,得出以下结论:首先,授课语音识别错字率在6.21%~8.13%区间内,识别效果可以满足后续对某个具体知识技能点的文本搜索;其次,专业领域的课程语音识别效果略低于通识课程语音,原因主要是核心词汇的识别率,某些生冷的专业词汇不收录在语音模型词库中;最后,授课老师的一些发音习惯,如吞音、音量过小或过大都会影响识别效果。
后续进一步提高慕课课堂语音识别正确率的有效途径是对专业领域的语言模型实施迭代优化,获得对应领域的训练文本,动态更新词典,反复改进初始语言模型,直到达到满意的阈值为止。
参考文献:
[1] 韩筠.在线课程推动高等教育教学创新[J].教育研究,2020,41(8):22-26.
[2] 黄斌,吴成龙.MOOC的研究现状、热点领域与发展建议——基于CNKI期刊论文的可视化分析[J].成人教育,2021,41(7):20-26.
[3] Megrhi S,Souidene W,Beghdadi A.Spatio-temporal salient feature extraction for perceptual content based video retrieval[C]//2013 Colour and Visual Computing Symposium (CVCS).Gjovik,Norway.IEEE,2013:1-7.
[4] 胡志军,徐勇.基于内容的视频检索综述[J].计算机科学,2020,47(1):117-123.
[5] 程风,翟超,吕志,等.基于语音识别技术的智能家居主控设计[J].工业控制计算机,2018,31(5):29-31.
[6] 戴礼荣,张仕良,黄智颖.基于深度学习的语音识别技术现状与展望[J].数据采集与处理,2017,32(2):221-231.
[7] Xiong W,Wu L,Alleva F,et al.The microsoft 2017 conversational speech recognition system[C]//2018 IEEE International Conference on Acoustics,Speech and Signal Processing.Calgary,AB,Canada.IEEE,2018:5934-5938.
[8] 梁静.基于深度学习的语音识别研究[D].北京:北京邮电大学,2014.
【通联编辑:唐一东】
猜你喜欢
西安航空学院学报(2022年2期)2022-07-04
IT经理世界(2018年20期)2018-10-24
中国新通信(2016年21期)2017-01-06
现代电子技术(2015年11期)2015-07-28
