
融合注意力机制改进残差网络的表情识别方法
2022-05-30 04:29姜丽莉黄承宁
计算机技术与发展 2022年5期
姜丽莉,黄承宁
(南京工业大学浦江学院 计算机与通信工程学院,江苏 南京 211200)
0 引 言
2016年何恺明博士等人[1]在CVPR大会中提出残差学习方法,并以此为基础提出名为残差网络 (Residual Network,ResNet)的神经网络模型,其核心思想在于通过恒等映射解决深层次网络在训练中出现的梯度弥散问题导致的退化问题,增强了网络对复杂特征提取模式的学习能力与计算性能。
根据通用近似定理[2],一个足够宽的神经网络足以逼近任意有限维向量空间上的连续紧致函数,并由2017年Zhou Lu等人[3]以及2018年Boris Hanin等人[4]给出相应证明。而宽神经网络存在参数量巨大的问题,在2015年Ronen Eldan等人[5]对深层神经网络进行研究之后,发现拥有同样数量神经元的深神经网络相比宽神经网络具备更强的特征学习能力与更少的参数量。可以看出,足够深的神经网络模型在理论上也应具备极强的拟合能力[6],但在实践中发现深层神经网络却可能出现梯度弥散与梯度爆炸问题[7],这将致使训练误差增大。
在对这一问题的研究分析中,Mark Sandler博士等人在CVPR大会中提出,因为引入了如ReLU等激活函数,使得神经网络在计算中存在不可逆的信息损失,这导致了深层次网络训练中容易出现梯度弥散问题,并由此提出,可以通过去除低维度ReLU使得网络模型的内部结构具备足够的信息保存能力以避免此问题的出现[8]。而何恺明博士等人所提出的残差学习则考虑了另一种解决方法,通过将恒等映射引入神经网络之中,使得网络模型的内部结构具备足够的信息保存能力以解决上述问题[1]。
该文设计了一个基于注意力机制的改进残差网络。对表情样本利用多个带有SE模块的特征层进行特征提取,利用注意力机制增强关键特征通道,在ResNet-50的基础上减少了计算量并提高了识别准确率。
1 残差网络
1.1 残差学习
残差学习的核心思想在于让神经网络拟合恒等映射H(x)=x,同时在其网络模型内,引入短路机制与恒等映射[9],以此设计了标准残差单元,其具体内部结构如图1所示。

图1 标准残差单元的内部结构
令xn为第n层残差单元的输入,则其最终输出yn如式(1)所示:
yn=F(xn,Wn)+xn
(1)
其中,Wn是第n层残差单元的权重,目标函数F为神经网络需要学习的残差函数,由于恒等映射的存在,残差函数F即输出与输入的残差yn-xn。
以上文的标准残差单元为例,其内部结构存在一个ReLU线性整流门以及两层权重w1和w2,则其残差函数F的定义表达式如式(2)所示:
F(xn,wn):=ReLU(xn·w1)·w2
(2)
由式(1)及式(2)可以得出,ResNet中浅层残差单元Rl到深层残差单元Rh的学习特征的表达式如式(3) 所示:

(3)
由式(3),依据链式法则求一阶偏导数,可以求得深层残差单元Rh到浅层残差单元Rl的梯度传播中的梯度∇F(xl)的表达式如式(4)所示:

(4)
对式(3)及式(4)进行分析可以得到,由于恒等映射将浅层残差单元的输入直接传播到深层残差单元,可以保证当一个深度为h层的神经网络所拟合的残差已经足够小时,网络深度的继续增加不会导致过多的信息损失,即当浅层网络已经拟合数据后,网络深度的增加不会大幅影响模型对数据的训练误差。由此可以得出,通过引入恒等映射这种短路机制,可以有效缓解因深层次网络的信息损失导致的梯度弥散问题。
1.2 ResNet网络结构
ResNet神经网络是由多层卷积层层叠组成的残差神经网络,在考虑性能等因素之后,深层次ResNet网络的内部结构中选用了瓶颈(Bottleneck)残差单元[1]。瓶颈残差单元是对残差学习单元的改进,将标准残差单元中原有的一个3×3卷积核拆分为两个1×1卷积核,分别用于对特征图的提升维度与降低维度操作,可以对稀疏的输入信息进行压缩,从而减少网络的参数数量及计算量,提升神经网络的训练速度与特征提取能力。瓶颈残差单元的内部结构如图2所示。

图2 瓶颈残差单元的内部结构
ResNet神经网络依据其内部结构中卷积层数量的不同,分别具有不同实现模型,如由18层卷积层组成的ResNet-18模型、由34层卷积层组成的ResNet-34模型等,具体内部结构如图3所示。
在ResNet的特征层中,选用一个3×3卷积核步长为2的池化层对输入信息进行下采样,可以使输入数据降维,进而减少参数数量。而在不同的实现模型中,特征层的具体实现也存在差异。ResNet-18与ResNet-34等浅层神经网络使用1.1节中所提及的标准残差单元作为特征层的残差单元,而ResNet-50、ResNet-101以及ResNet-151等深层神经网络则选用上文所提及的瓶颈残差单元。各ResNet模型的特征层的具体结构如表1所示。

图3 ResNet的内部结构

表1 ResNet各模型的特征层结构、参数量及计算量
由表1可以得出,ResNet-50模型可以兼具模型的特征学习能力以及计算性能,因此选为文中表情识别方法的特征提取器以及baseline。
2 ResNet-50模型的改进
2.1 激活函数与改进
激活函数是在神经网络的线性代数求解中引入非线性因素,使得神经网络具有拟合非线性函数的能力[10]。神经网络中常用sigmoid函数、tanh函数以及ReLU函数作为激活函数[11],现进行分析如下:
2.1.1 sigmoid(σ)
sigmoid函数亦称为logistic函数与逻辑回归函数,其定义表达式及导数表达式如式(5)所示:

(5)
通过对式(5)及其函数图像与导数图像进行分析,结论如下:sigmoid函数具有平滑性质,易于求导;sigmoid函数的输出并不是零中心化,即其输出均值不为0,这会导致输出存在方差偏移现象,影响网络训练中梯度下降的收敛性;当sigmoid函数的输入值非常大或非常小时出现饱和,其导数趋于0,使得神经网络容易出现梯度弥散问题,这导致网络参数的更新速度以指数衰减的形式减慢。
2.1.2 tanh
tanh函数即正切双曲函数,其定义表达式及导数表达式如式(6)所示:

tanh'(x)=1-tanh2(x)
(6)
通过对式(6)及其函数图像与导数图像进行分析,结论如下:tanh函数的输出为零中心化,这使得使用tanh函数作为激活函数可以避免输出的方差偏移现象的出现;tanh函数同样存在因饱和导致梯度弥散的问题,进而使得网络参数的更新速度减慢。
2.1.3 ReLU
ReLU函数即线性整流函数,其定义表达式及导数表达式如式(7)所示:

(7)
通过对式(7)及其函数图像与导数图像的分析,结论如下:ReLU函数具有单侧抑制的性质,即在x=(-∞,0)区间中神经元的激活被抑制,这使得神经网络中的神经元具有稀疏激活性,可以较好地提高模型的学习能力与泛化性能;ReLU函数在x=(-∞,0)区间上其导数为1,这使得神经网络不会出现梯度爆炸问题;但ReLU函数一样存在因其输出非零中心化,进而出现输出的方差偏移问题,将导致网络收敛速度变慢;同时存在因在x=(-∞,0)区间上y=0导致的神经元不被激活的问题,进而出现神经元死亡问题。
2.1.4 Swish
为利用结合上述激活函数的优点并解决其缺点,如神经元死亡等问题,谷歌大脑实验组的Prajit Ramachandran等人提出了Swish指数线性函数[12],其定义表达式及导数表达式如式(8)所示:
Swish(x):=x·σ(x)
(8)
通过对式(8)及其函数图像与导数图像进行分析,结论如下:Swish激活函数具有下确界、非单调、平滑等性质,在x=(0,∞)区间上的导数趋近于1,具有ReLU函数所具备的优势;同时Swish激活函数的输出接近零中心化,可以加速神经网络的收敛;Swish激活函数在x=(-∞,0)区间上的输出不为0,解决了神经元死亡问题;同时Swish具有下确界,这使其对负数噪声具有较高的健壮性。
据此考虑,该文利用Swish激活函数替代模型中的ReLU激活函数,并在后文中验证其性能。
2.2 注意力机制与SE模块
注意力机制是在神经网络的内部结构中对人类视觉注意力机制进行的仿生[13],其基本思想是通过分配权重的方式,使神经网络关注于重要信息,并抑制非重要信息,减少数据噪声,可实现让神经网络对关键特征进行针对性学习,减少计算量,增强特征表达能力并提高信噪比,进而提高模型的泛化能力。
Squeeze-and-Excitation (SE)模块是2018年由Momenta的胡杰等人于CVPR大会上提出的通道注意力模块[14],其核心思想在于通过在神经网络的内部结构中增加一个子网络,用于自动学习每一个输出通道的权重与关联性,再对输出通道按照对应权重进行加权,增强重要的信息通道。在SE模块的内部结构中,按照其计算需求将模块内部划分为Squeeze、Excitation以及Reweight三个子模块,其具体结构如图4所示。
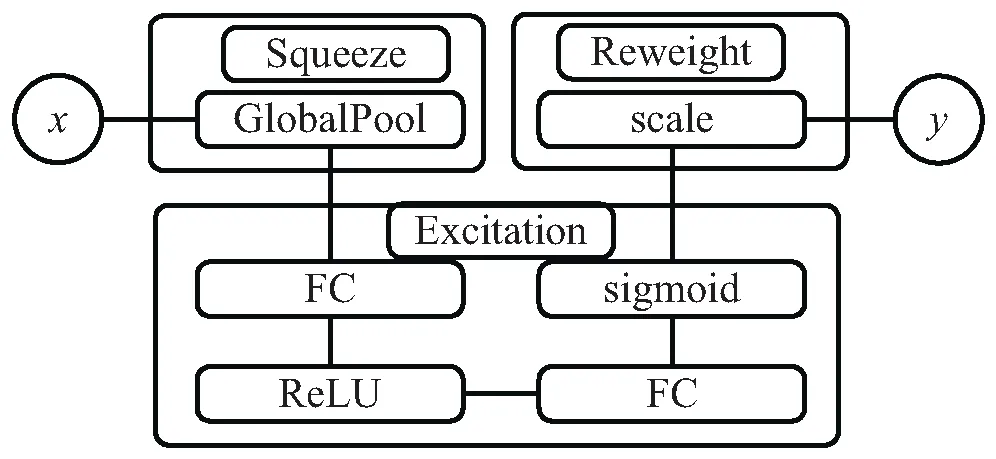
图4 SE模块的内部结构
Squeeze部分设计为通过一个全局池化层,按照空间维度将H×W×C的特征通道通过全局池化,压缩为一个1×1×C的实数数列特征,每个特征通道所对应的实数z表征着该特征通道上注意力权重,用于增强关键特征通道并抑制非关键特征通道。对特征通道c的Squeeze操作的定义表达式如式(9)所示:
(9)
Excitation部分设计为每个特征通道学习对应权重,以学习特征通道之间的相关性。其内部通过两个全连接层,对z分别进行提升维度和降低维度操作,可以限制模型的复杂度并辅助泛化。最后通过sigmoid函数门进行归一化获得介于区间(0,1)中的权重s。对实数z的Excitation操作的定义表达式如式(10)所示:
s=Fexcitation(z,W):=σ(ReLU(zW1)W2)
(10)
Reweight部分是将上述操作中得到的通道权重s进行scale操作以点乘方式对先前的特征通道c进行逐一加权操作,进而得到最终的输出y。对通道权重s与特征通道c的scale操作的计算表达式如式(11)所示:
y=Fscale(c,s):=cs
(11)
SE模块可以通过短路方式直接接入ResNet-50模型的残差单元内部结构之中,组成SE-ResNet-50神经网络[14],可以提高ResNet-50模型对特征通道信息之间复杂的相关性的拟合能力。其具体实现方式如图5 所示。

图5 SE-ResNet-50的残差单元结构
据此考虑,该文利用Swish激活函数替代模型中的ReLU激活函数,并在后文中验证其性能。
3 验证方式与结果分析
3.1 训练策略
训练神经网络所使用的训练工作站的具体软硬件环境参数如下:CPU:AMD Zen R7 1700 3.75 GHz,硬盘:三星SSD sm961 256 GB,内存:芝奇 DDR4 Trident Z 3200 C15 32 GB,GPU型号:技嘉 AORUS GeForce GTX 1080 Ti,操作系统:Windows 10 专业版。CPU与GPU性能在时间容许范围内支持较大的迭代代数,硬盘容量与显存容量支持较大的训练数据集以及数据增广方式,并支持较大的训练批量,以此设置模型的训练超参数,并选用Adam优化器对模型进行优化。训练超参数如表2所示。

表2 模型训练的超参数
3.2 数据集与数据增强
该文所采用的数据集为中科院和北京大学的联合实验室提供的CAS-PEAL-R1数据集[15],该数据集中的表情部分包含了由377名不同年龄、性别组成的表演者的一共1 885张照片,包含5种表情数据,如闭眼、皱眉、张嘴、微笑、惊讶等常见表情,足以满足课堂评估的专注度分析中所需的表情类别。
文中神经网络训练所用的表情数据选用CAS-PEAL-R1数据集中的闭眼、皱眉、微笑、惊讶等四种一共1 508张图片,通过随机裁剪与左右翻转等预处理方式对数据集进行数据增强,最终得到12 064张图片数据,其中四种表情各3 016张图片数据。对数据集依照留出法以6∶2∶2的比例随机划分为训练集、验证集以及测试集,即训练集中包含7 238张训练图片,验证集中包含2 413张验证图片,测试集中包含2 413张测试图片。
3.3 验证方法与结果
该文选用交叉熵损失函数度量真实样本分布与预测样本分布的差异,监督所提出模型的训练。交叉熵损失函数的定义表达式如式(12)所示:

(12)
其中,p(x)是表情样本x的真实分布,q(x)是文中模型对表情样本x的预测分布。
在经过1 000代迭代之后,模型在训练集上的损失均趋于0,训练集上的正确率趋于99.9%,测试集上的正确率趋于94.1%。可见,所设计的基于改进残差网络的表情识别方法具有较好的识别性能。
该文利用混淆矩阵评估模型对表情类别在识别过程中的混淆程度。混淆矩阵的各行分别代表相应表情类别的真实情况,而各列分别代表识别模型对相应表情类别的预测情况,矩阵中任意元素xij表征着第i类的数据被模型识别为第j类的百分比,即矩阵的反对角线上的数值越高,模型的识别混淆程度越低,反之非反对角线上的数值越高,模型的识别混淆程度越高。在试验之后,对文中模型的表情识别结果绘制混淆矩阵,结果如表3所示。
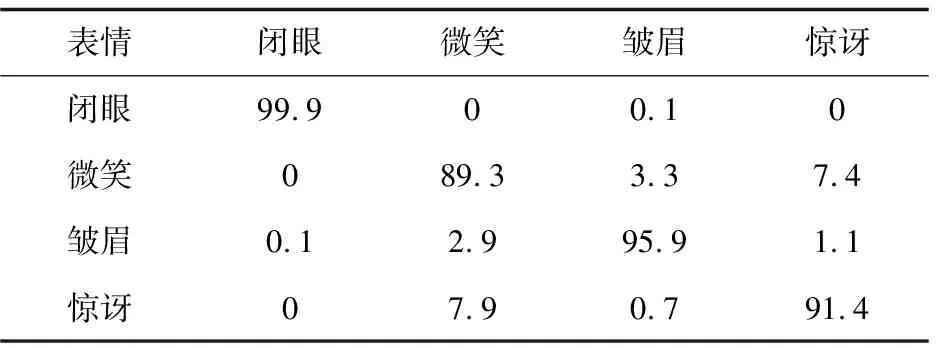
表3 表情识别的混淆矩阵 %
从表3分析可知,模型对闭眼的识别混淆程度最低,准确率为99.9%;模型对微笑的识别混淆程度最高,准确率仅为89.3%;并从中可以得到模型将微笑混淆为惊讶与皱眉的程度略高,说明该识别模型对微笑的识别方法尚有待改进。综合可见,设计的模型对人脸表情类型的识别效果具有较低的混淆程度。
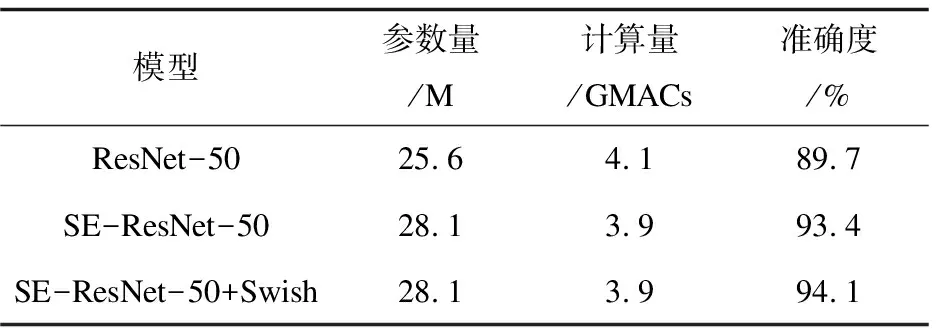
表4 文中模型与baseline的对比
表4是文中模型(SE-ResNet-50+Swish)与ResNet-50以及SE-ResNet-50进行比较的汇总结果。分析可知,SE-ResNet-50在ResNet-50的基础上引入SE模块之后,虽然增加了网络层数,但凭借引入注意力机制的方式反而减少了计算量,与此同时参数数量没有显著增多,对表情识别的准确率有明显提高;SE-ResNet-50 +Swish相比于SE-ResNet-50的参数数量与计算量等无显著增多,但准确率有稍微提升。可见,该文在表情识别方法中对残差网络的改进有可取之处。
4 结束语
设计了一个基于注意力机制的改进残差网络。对表情样本利用多个带有SE模块的特征层进行特征提取,利用注意力机制增强关键特征通道,在ResNet-50的基础上减少了计算量并提高了识别准确率。下一步将针对多姿态表情识别进行进一步研究,增强网络对不同环境下的特征学习能力。
猜你喜欢
心理学报(2022年9期)2022-09-06
舰船科学技术(2022年11期)2022-07-15
中国教育信息化·高教职教(2022年4期)2022-05-13
心理学报(2022年4期)2022-04-12
煤气与热力(2022年2期)2022-03-09
舰船科学技术(2021年12期)2021-03-29
软件(2017年6期)2017-09-23
南水北调与水利科技(2017年1期)2017-02-27
科技视界(2016年1期)2016-03-30
科技经济市场(2014年2期)2014-06-20
