
一种融合用户动态偏好和注意力机制的跨领域推荐方法
2022-05-27 01:06:56钱忠胜俞情媛李端明孙志旺
小型微型计算机系统 2022年6期
钱忠胜,涂 宇,俞情媛,李端明,孙志旺
(江西财经大学 信息管理学院,南昌 330013)
1 引 言
随着大数据时代的到来,各种各样软件产生了大量的信息,这些海量信息使人们的日常生活变得更加丰富.但是,这个过程中也出现了一些不可避免的问题,例如信息泛滥和信息迷航.在此环境下,为了让每个用户能够获取自己想要的信息,针对不同用户的个性化推荐技术应运而生.当前,相关研究人员将个性化推荐技术应用于各个领域的资源推荐,除了电影、音乐、体育之外,还包括了电子商务、基于位置的服务、医疗等领域.
传统推荐算法大都关注用户的显性偏好.随着电商系统的发展壮大,越来越多的用户参与其中,但大部分用户只对一小部分商品有需求,也只会对部分商品进行评分,进而导致评分矩阵变得十分稀疏.因此,仅分析用户的评分只能得到关于用户的片面信息.主题模型是一种统计模型,主要挖掘潜在特征,并发现其中的抽象主题.通过主题模型提取各个项目评论的主题分布,并结合用户对项目的评分,可获取用户的偏好分布信息,大大减少了数据的稀疏性.
一般来说,无论是一小段话还是一整篇文章,总会有一个中心思想,那些与中心思想关联度较高的词出现的频率通常高于其它词.例如,在一篇介绍地区风景的文章中,“高楼”、“瀑布”、“树木”等词出现的评论会相对较高,与之不相关或者相关度较低的词出现的次数明显减少.潜在狄利克雷分布(LDA)是一个3层贝叶斯概率模型,总体分为3部分,分别是词、主题、文档.LDA以若干个主题来表达将所有文本中的特征,不同文本隶属于某个主题的程度以概率的方式呈现.
大部分用户的历史记录中存在着一系列项目,但是这些内容不一定能完全表达用户的兴趣.如果用户在过去很长的一段时间都喜欢听轻音乐,而最近却听了一首摇滚乐,这并不能代表用户喜欢此类歌曲,可能这段时间这种类型的歌曲比较受欢迎,故不能将它们视为同等重要.当一个项目具有许多主题时(如音乐的歌手、作曲者、类型、时间等),用户往往会更倾向于其中的某个或多个.
基于注意力的模型是一种流行的深度学习方法,已成功应用于问答、神经机器翻译和语音识别等领域.基于注意力的模型有助于选择最相关的信息,而不是使用所有可用的信息.
一般来说,注意力机制对模型的学习效果能带来明显的提升.更重要的是,所获得的中间注意力分数可为预测提供富有成效的解释.例如,在问答中,注意力可显示生成的答案与相应上下文的相关性.
目前,大多数推荐技术都为单领域的,即仅利用用户在单一领域的兴趣对用户进行推荐,而多领域相结合的推荐技术较少.通过单领域推荐能获取的信息十分有限,往往只有用户的一部分记录,难以全面了解用户,进而使得推荐效果变得不可靠,准确度降低.跨领域推荐[1-5]技术能综合考虑用户在不同领域的偏好信息,相对于单领域推荐冷启动问题有了明显的改善.不仅如此,跨领域推荐系统还能通过分析用户在不同领域的偏好,使得推荐结果更具有多样化的特点.
跨领域推荐可就不同侧面,分为不同的场景.根据领域间的交叉关系,可划分为用户部分重叠、用户完全重叠、用户完全不重叠、项目部分重叠、项目完全重叠、项目完全不重叠.用户/项目完全重叠的情况较为少见,若用户/项目完全不重叠,则难以实现跨领域推荐,而用户/项目部分重叠的情况较为常见.为了便于实现跨领域推荐,本文选取的应用场景为领域间部分用户重叠.
人工神经网络模拟人的思维,将所有接收到的信息并行处理,然后按一定的方式转换,得到最终的结果.BP神经除了基础的前馈传到以外,还包含了反向传播机制,在较强的拟合能力基础上,增加了泛化能力和容错能力,能够很好地解决分类与回归问题.将BP神经网络应用于跨领域推荐,能够发现不同领域用户偏好的对应关系,充当了领域间的桥梁.
基于以上讨论,本文提出了基于用户动态偏好和注意力机制的跨领域推荐方法.项目的评论信息包含了项目本身的相关特征,LDA主题模型能够提取这些信息,将项目的评论信息转换为项目的主题分布.将评分、时间以及项目主题分布三者结合,并引入注意力机制,得到用户动态偏好.接着,使用BP神经网络发掘不同领域间用户偏好的映射关系,将用户在源领域的偏好映射到目标领域,并与用户的目标领域偏好结合.最后,利用用户的偏好相似度来预测其对项目的评分.
论文的余下部分安排如下:第2节介绍了相关工作,描述了跨领域推荐的相关技术,以及LDA主题模型在推荐系统中的应用.第3节详细描述了本文采用的相关算法,3.1节介绍了基于主题模型的用户动态偏好提取过程,3.2节介绍了基于BP神经网络的跨领域兴趣映射过程,3.3节对整体模型进行整合,给出最终的推荐框架.第4节展开实验设计与结果分析.第5节对全文进行总结,给出存在的不足及进一步的研究.
2 相关工作
无论是在社交网站还是电商系统中,用户的评论信息往往远多于用户的评分信息,能更好地反应用户对商品的喜好程度以及观点.主题模型能够处理项目的文本信息,统计每个项目相关文本中的词语,根据统计的结果来判断哪些词汇可以作为主题,以及作为主题的概率.
张航等[6]提出了negLDA模型,在LDA模型的基础上,结合用户对项目的负面与正面评分,对用户的偏好进行综合评价,进而使得用户对项目的评分预测效果更佳.董晨露等[7]提出了TTCF模型,在User-CF算法的基础上,加入了评论信息与艾宾浩斯遗忘曲线,同时计算用户的整体相似度,进而利用相似用户来进行评分预测.彭敏等[8]提出了SACF模型,利用LDA主题模型挖掘用户评论信息中的偏好分布,再结合情感分析技术预测用户在项目属性面上的评分.最后,结合用户在属性面上的评分与总体评分,计算不同用户之间的相似度,使用协同过滤的方法预测用户对未评分物品的评分值.高娜等[9]提出了嵌入LDA主题模型的协同过滤推荐算法,通过LDA主题模型对标签信息进行处理,提取用户与项目的主题分布,最后结合用户评分与主题分布计算用户的相似度.张斌等[10]提出了TSM/Forc推荐方法,通过LDA主题模型将用户与项目的标签信息关联起来,再利用一个模型从整体上对这些文本信息进行融合分析.
近年来,深度学习算法的性能越来越好,能够很好地提取深层特征,已被广泛使用.注意力机制是一种深度学习研究模式,能使无用信息的影响最小化.
谢恩宁等[11]提出了DeepCF-A模型,在已有的DNN基础上结合注意力机制,提高了隐式数据中潜在特征的提取效率,进而使推荐性能有了很大改善.罗洋等[12]提出了一种融合注意力LSTM的推荐算法,基于已有的用户评分及其它相关信息,通过自编码器提取用户的隐向量.然后结合LSTM与注意力机制将项目的辅助信息转换为项目的隐向量.最后,将用户与项目的隐向量结合预测评分.赵赟等[13]提出了一种基于注意力机制与文本信息的用户关系抽取方法,通过分析任意两个用户的评论信息来判断两者是否存在好友关系,若两者之间具有好友关系,则将两者信息进行拼接,输入包含LSTM层和注意力层的网络中.苑威威等[14]提出了一种基于自注意力机制的混合推荐算法,结合多重自注意力机制与DNN处理降维后的数据获取用户的潜在偏好,进而得到用户潜在偏好相似性与项目相似性.最后,结合两种相似性对用户进行项目推荐.
Yuan等[15]提出了ACA-GRU模型,在循环神经网络的基础上引入上下文信息,以区分评分序列中每个项目重要性,进而预测用户的动态偏好.Chen等[16]提出了DeepUCF+a模型,在传统的UserCF基础上,使用深度神经网络与注意力机制来区分每一个物品的被购买记录中不同用户的重要性,使算法性能更佳.
上述研究均为基于单领域的推荐算法,当用户在该领域数据稀疏时,便无法给予精准的个性化预测.故引入跨领域推荐,结合用户在其它领域的偏好与用户在目标领域的偏好,得到用户的综合偏好,为稀疏用户提供更好的推荐结果.跨领域推荐系统中的常用技术包括:基于标签的推荐、迁移学习、协同过滤等.通过对源领域知识的学习来填充目标领域中的缺失信息,最终完成对用户的推荐.
王俊等[17]提出了TRBT模型,在矩阵分解的基础上结合了不同领域的评分模式,并通过聚类算法构造邻接图,最后将评分模式、邻接图结合预测用户对未评分项目的评分.Xu等[18]提出了CULS模型,引入信任关系,用户之间若相互信任,则他们具有相似的偏好,再通过修改随机漫步中的转移矩阵进行推荐,将领域间相似的用户突出显示.Taneja等[19]提出了提出了一种智能的基于跨领域的推荐方法,该方法通过张量分解技术更好地捕捉领域间的用户因素和项目因素之间的交互,提高了预测的精准度.Jiang等[20]提出了HRW模型,引入了基于图的推荐算法,与其他项目领域相连接.通过这种创新的表达方式,来自辅助领域的有用知识可以通过社交领域转移到目标领域.
李林峰等[21]提出了SKP模型,处理用户在源领域和目标领域的评分信息,得到领域间的知识模型以及目标领域的知识模型,最后结合两者使推荐结果更准确.葛梦凡等[22]提出了ITTCF模型,将用户标签和用户评分结合进行跨领域推荐,解决了传统跨领域推荐算法通常只将评分信息从源领域迁移到目标领域,而其它信息均未能发挥作用的弊端.高升等[23]提出了一种基于潜在因子的跨领域推荐算法,将不同领域的潜在因子聚类,得到跨领域共性特征;再将目标领域的潜在因子单独聚类,得到单领域的个性特征;最后,将两者加权求和,用于缓解目标领域的数据稀疏性.Kumar等[24]提出了一种基于语义聚类的跨领域推荐算法,引入了跨越多个领域的公共语义空间的概念,使用不同领域的语义聚类词汇的主题建模.
上述跨领域推荐算法都存在一定的不足,有的未考虑用户的评论信息,有的未考虑时间因素给评分信息或评论信息带来的影响,导致挖掘用户偏好不够全面.本文将用户的评分、评论信息用于构建动态偏好,再与BP神经网络相结合,应用于跨领域推荐系统中,能够更加全面地发掘用户的偏好,弥补单领域推荐数据稀疏性的不足,并使得偏好的时效性更强.
3 融合用户动态偏好和注意力的跨领域推荐策略
由于单领域数据的稀疏性,使得推荐的准确度降低,若能将多个领域的数据结合可大大提高推荐结果的可靠性.本文的跨领域场景为源领域与目标领域的部分用户重叠,学习这些共同用户在不同领域间偏好的映射关系进而预测其他用户的偏好.
首先利用LDA主题模型[25]提取项目评论中的主题,得到各个项目的主题分布.再结合用户对项目的评分,得到用户的偏好向量.由于用户的偏好具有时效性,故将时间因子引入用户偏好向量的构建过程.虽然用户在不同领域的偏好分布不尽相同,但其中也有着一定的对应关系,通过BP神经网络拟合用户在源领域与目标领域的映射关系.最后,通过用户综合偏好的相似度进行评分预测.本节所用的符号说明如表1所示.
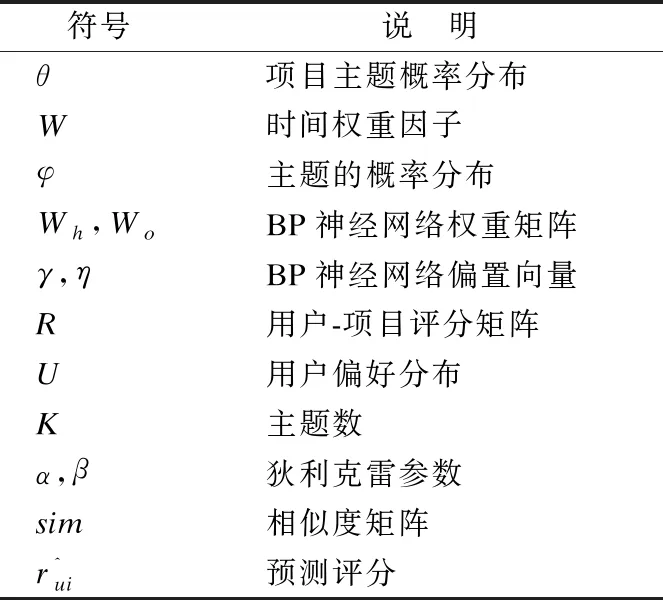
表1 相关符号说明
3.1 基于主题模型的用户动态偏好提取方法
现实中的各种项目有着丰富的信息,包含用户的评分、评论等.大部分用户的评分意愿都不强,留下的信息也较少,故难以准确地表达用户喜好.而用户对项目的评论信息则包含了项目的某些特征以及用户的隐式偏好,使用LDA主题模型处理项目的评论信息,得到项目的主题分布.
3.1.1 基于LDA的项目主题提取
LDA是一种较为常用的主题概率模型,采用词袋模型进行文本向量化,即在一篇文档中仅考虑一个词汇是否出现.它是一个文档生成的过程,分为词汇层、主题层、文档层3个部分,是一种无监督的机器学习方法.文档中的每一个词有一定概率属于某个主题,而每一个主题也会有一定概率包含某个词语.其中每一篇文档可由向量θd=(Pd,1,Pd,2,…,Pd,k)表示,Pd,k表示主题k在文档d中出现的概率;每一个主题可以由ψk=(Pk,1,Pk,2,…,Pk,n),Pk,n表示词汇n在主题k中出现的概率.
LDA模型由包含每个主题的概率分布ψk、每个文档的主题概率分布θd,以及每个词汇的主题分配序列Zdj组成.在本文中,每一个文档的内容即为每一个项目所有的评论信息,故文档层为所有项目的评论信息,各个参数可通过吉布斯采样获取,目标似然函数如式(1)所示.
(1)
其中,θZdj表示特定主题的产生概率,φZdj,Wdj表示词汇Wdj属于该主题的概率,LDA经典模型如图1所示.
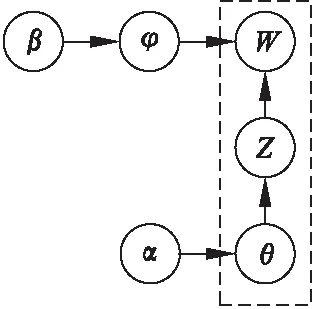
图1 LDA主题模型经典结构图
LDA模型的输入为项目的评论信息,而这些信息中通常包含大量无意义或与用户兴趣无关的词,在文本的预处理阶段需将这些词剔除,防止模型性能受到影响.
3.1.2 用户动态偏好提取算法
经研究表明[26],大部分用户更倾向于描述其喜欢的项目特征,而非不喜欢的项目特征,故本文将评论分布作为用户偏好分布的近似.
一般地,用户对项目的偏好程度通常会随时间的推移以一定的方式变化.在互联网领域中,用户不同时期的偏好对当前偏好的影响程度不尽相同,通常近期偏好对当前偏好的影响程度高于很久之前的偏好.因此,在计算用户当前偏好时,距离当前时间越近的偏好所占的权重应越高.
受文献[7]的用户偏好提取思想的启发,在完成对项目主题分布的提取后,将其与评分、时间因子、注意力权重结合,得到用户的偏好向量,具体过程如式(2)-式(7)所示:
(2)
Query=θquery_index
(3)
(4)
(5)
(6)
(7)
其中tmax表示用户u最近一次评分时间戳的数值;tmin表示用户u最早一次评分时间戳的数值;tui表示用户u对项目i评分的时间戳;Attentioni表示用户偏好的注意力权重;Wui表示用户综合权重,综合考虑了注意力权重与时间权重因子;rmax表示用户u对项目评分的最大值,rui表示用户u对项目i的评分.其过程如算法1所示.
算法1.基于主题模型的用户动态偏好提取算法
输入:主题数K,狄利克雷参数α、β,用户评分记录R,商品评论记录I
输出:用户偏好分布向量U
Begin
1.θ←LDA(α,β,I);
//提取项目主题分布
//结合评分、时间因子、注意力权重计算偏好权重
//(见式(2)-式(6))
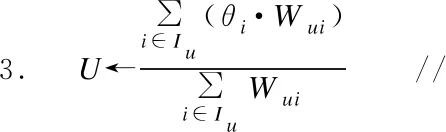
End
在算法1中,步骤1为使用LDA主题模型提取项目评论的主题分布的过程,步骤2和步骤3为项目主题分布与用户评分信息、时间因子、注意力权重结合的过程.通过这两个步骤,完成了对用户偏好分布的提取.
3.2 基于BP神经网络的用户偏好跨领域映射算法
在不同的领域之间,用户的偏好亦存在一定的对应关系.例如,喜欢看喜剧片的用户大都偏向于想看幽默搞笑类的书籍,而喜欢看恐怖片的用户一般想看灵异恐怖类的书籍.这里通过BP神经网络完成用户在不同领域间的兴趣映射,利用3.1节中求得的重叠用户在源领域和目标领域的偏好,构建跨领域映射网络.
设Tus为用户在源领域的偏好向量,Tut为用户在目标领域的偏好向量,将Tus作为输入,Tut作为输出,使用BP神经网络学习Tus和Tut之间的映射关系,如式(8)-式(12)所示.
1)输入层到隐藏层
b=Wh×x
(8)
2)经过隐藏层的激活函数
h=g(b-γ)
(9)
3)隐藏层到输出层
β=Wo×h
(10)
4)经过输出层的激活函数
pre_y=g(β-η)
(11)
5)损失函数
(12)
在式(9)和式(11)中,g(x)=relu(x),具体模型结构如图2所示.
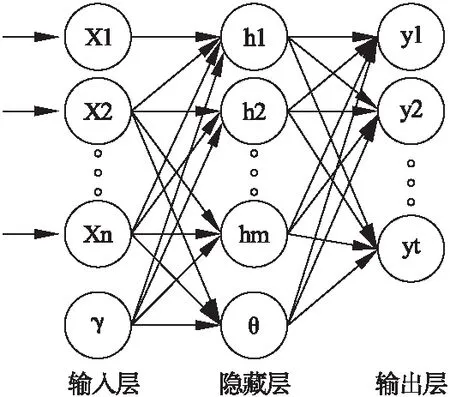
图2 BP神经网络结构图
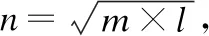
算法2.基于BP神经网络的用户偏好跨领域映射算法
输入:重叠用户在源领域和目标领域的偏好向量,学习率
输出:训练完成的BP神经网络
Begin
1. initialize(v,w,γ,θ);//初始化参数
2.Foriin range(N) //N为数据集大小
3.b←Wh×x; //见式(8)
4.h←g(b-γ); //见式(9)
5.β←Wo×h; //见式(10)
6.pre_y←g(β-θ); //见式(11)
//损失函数极小化,见式(12)
EndFor
End
在算法2的步骤1中,将包括权重矩阵和偏置向量在内的各个参数赋予一个初值;步骤2-步骤6为映射过程,即拟合输入与输出的过程.在将用户源领域的偏好向量映射到目标领域后,以一定的方式与用户在目标领域的偏好向量加权求和,得到用户的综合偏好,该过程在下一节详细描述.
3.3 融合用户动态偏好和注意力的跨领域推荐框架
在前两个小节(3.1-3.2节)的基础上,下面从整体上描述跨领域推荐的过程.在将用户源领域的偏好向量映射到目标领域后,需要以一定的方式与用户目标领域的偏好向量加权求和.
将推荐系统的范围由单领域扩展为多领域能有效减少数据量不足带来的影响.若用户在目标领域的数据是稀疏的,则通过少量的信息难以准确地发掘其偏好.此时,将用户在源领域的偏好与其在目标领域的偏好结合,可减少数据稀疏的影响,我们给出融合用户动态偏好和注意力的跨领域推荐策略(Cross-Domain Recommendation Strategy Fusing Users′ Dynamic Preferences and Attention Mechanism,CDRS_FUDPAM),其整体框架如图3所示.
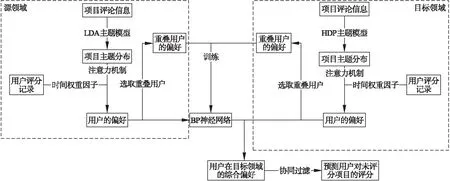
图3 CDRS_FUDPAM跨领域推荐模型的整体框架
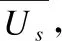
(13)
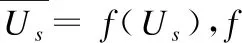
在得到用户综合偏好向量后,用余弦相似度计算用户的偏好相似度.用户m和用户n的偏好相似度如式(14)所示:
(14)
其中,Um表示用户m的偏好向量,Un表示用户n的偏好向量.
在完成对用户之间相似度的计算后,对每个用户的相似用户列表按相似度从大到小排序,选取前K个用户,通过他们的评分来预测用户对未评分项目的评分,如式(15)和式(16)所示:
(15)
(16)
其中Nu表示用户u的相似用户列表,rvi表示用户v对项目i的评分,sim(u,v)表示用户u和用户v的相似度.
融合用户动态偏好和注意力的跨领域推荐过程如算法3所示.
算法3.融合用户动态偏好和注意力的跨领域推荐算法
输入:源领域用户评分记录{Rus},目标领域用户评分记录{Rut},源领域用户-项目评论{Is},目标领域用户-项目评论{It}
输出:用户在目标领域对未评分项目的预测评分
Begin
1.Us←T_LDA(Is,Rus);
//结合注意力机制、评分、时间因子计算源领域
//用户偏好向量(见算法1)
2.Ut←T_LDA(It,Rut);
//结合注意力机制、评分、时间因子计算目标领域
//用户偏好向量(见算法1)
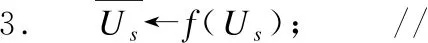
//计算用户的综合偏好向量(见式(13))
//计算用户之间的相似度(见式(14))
End
在算法3中,其中步骤1和步骤2为算法1中用户动态偏好的提取过程,综合考虑了注意力机制、评分、时间因子;步骤3为跨领域映射过程,将用户源领域偏好映射到目标领域;步骤4和步骤5为最终的推荐过程,将映射后源领域偏好与目标领域偏好结合,得到用户的综合偏好,再通过综合偏好来计算相似度,进而预测用户对未评分项目的评分.
4 实验设计与分析
本节首先介绍了实验环境以及实验使用的数据集,然后选取了几种典型的评价指标以及相关的对比算法,最后给出面向用户动态偏好和注意力的跨领域推荐方法与其它方法的对比实验结果,并进行了详细的分析.
4.1 实验环境与数据集
4.1.1 实验环境
本文的实验环境为Win10 64位操作系统,内存为32G,处理器为AMD Ryzen 7 3700X 8-Core Process,使用的编程软件为Pycharm,编程语言为Python,详情如表2所示.

表2 实验环境
4.1.2 实验数据集
为了体现相关因素对实验结果的影响,本文使用亚马逊影视评分评论数据集及其音乐评分评论数据集进行实验,简称Video和Music.作为世界上影响力较大的购物平台之一,亚马逊拥有海量的数据,其中包括了图书、音乐、食品等商品的销售记录、评分记录以及关联商品,用户可以在亚马逊网上搜索所需的资源,并对其进行评分以及标注.另外,用户还可以通过邮件发现感兴趣的好友.因此,可用亚马逊的数据集进行跨领域推荐研究.实验数据集包含了用户ID、项目的ID、用户对项目的评分以及评论、用户评论项目的时间,删除部分异常数据后,基本统计信息如表3所示.

表3 Amazon数据集的样本信息
该数据集为Amazon数据集的两个子数据集,由于样本数量足够多,故可用于验证跨领域推荐模型的性能.虽然整体的样本数很多,但大部分用户只对少数项目打过分,数据极为稀疏,如表4所示.
从表4可看出,两个领域的评分数据都极其稀疏,无论是Video领域还是Music领域.如果仅仅通过评分信息来得出推荐结果,现有的模型都难以得到满意的结果.本文通过LDA模型处理评论信息,同时结合评分信息,并引入辅助领域的数据来缓解目标领域的数据稀疏性问题.项目的评论信息如表5所示.
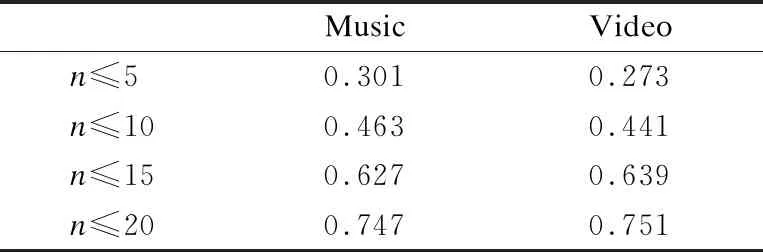
表4 项目评分统计信息
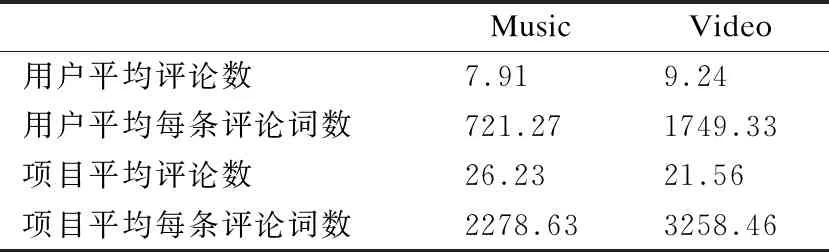
表5 项目评论统计信息
从表5可看出,用户对项目的评论信息十分丰富,无论是评论的数量还是每条评论的内容都足够多,能较好地缓解数据稀疏性带来的影响.
4.2 评价指标与参数设置
4.2.1 评价指标
平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Squared Error,RMSE)是目前推荐系统中较为常见的两个评价指标,用于衡量预测评分和真实评分之间的误差,而困惑度(Perplexity)可用来衡量概率分布与目标文本的匹配程度.故本文使用MAE和RMSE来对比不同算法的性能,用困惑度来选择合适的主题数,进而设置其它参数.
1)平均绝对误差(MAE)
由于本文的目标是预测用户对未浏览过的项目的评分,而MAE是评分误差的平均绝对值,故MAE可作为本文中评分预测的评价指标.MAE的计算如式(17)所示:
(17)
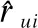
2)均方根误差(RMSE)
除了MAE以外,RMSE也是一种用于衡量预测评分预测的准确性的指标,反应预测评分与真实评分的标准差.RMSE的计算如式(18)所示:
(18)
3)困惑度(Perplexity)
评价主题模型中主题数的选取是否合理的指标,该值与模型的质量呈负相关,即Perplexity越小,主题概率模型的质量越高.Perplexity计算如式(19)所示:
(19)
其中,P(ri)为第i个项目的全部评论信息的生成概率,Ni为第i个项目的全部评论信息的总词数.
4.2.2 参数设置
在实验过程中,相关参数的设置尤为重要,取值合适的参数能让算法性能明显提升.本文选择Music作为源领域,Video作为目标领域,同时将评分以及评论数量都少于5的用户剔除,并将所有数据集中的80%和其它20%的数据分别作为训练集与测试集.本文的参数共有3部分,分别是LDA相关参数,跨领域系数λ,近邻数N.研究表明[27],当近邻数在30~60之间,推荐效果较好,故本文将近邻数设置为其中值45.
1)LDA相关参数
LDA的参数的选择决定了项目主题的提取效果,其中包括超参数α、β和主题数K.根据历史经验,将α取值为50/K,β取值为0.01,主题数K设置13个值做对比实验,分别为6,11,16,21,26,31,36,41,46,51,56,61,66.观察源领域和目标领域中Perplexity值随主题数K的变化趋势,如图4所示.
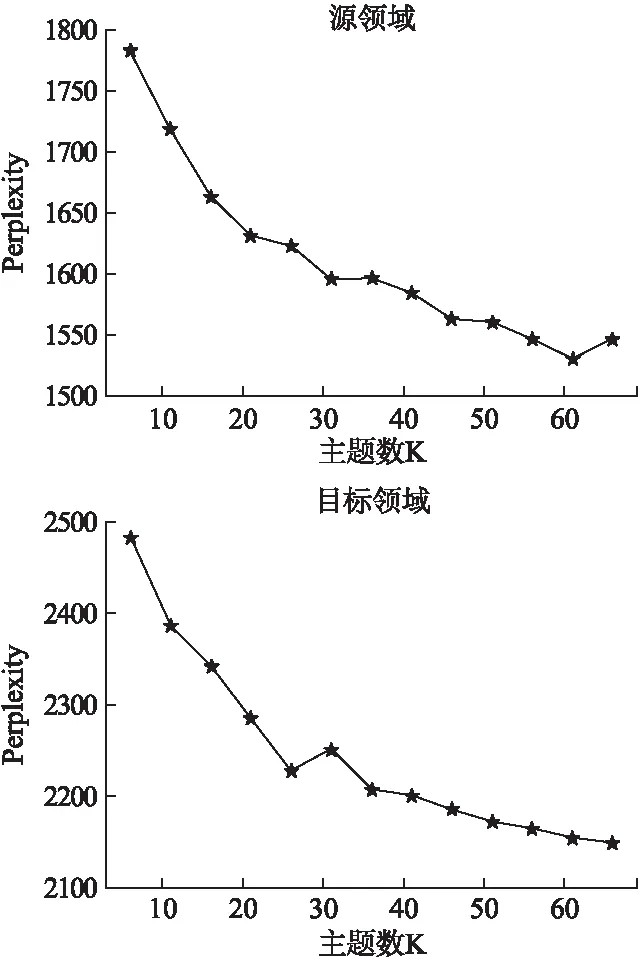
图4 源领域与目标领域LDA主题数对Perplexity值的影响
从图4可看出,在源领域中,Perplexity值与主题数Ks呈负相关.初始时刻,曲线的下降速率很快.约在Ks=21时下降速率逐渐变缓,说明增加主题数的效果已不明显.此后虽然随着主题数K的增大,Perplexity值总体减小,但是过拟合的风险越来越大,因此Ks=21为最佳主题数,此时的模型性能最好,故选取Ks=21作为源领域LDA的主题数.与源领域类似,在Kt=26时,主题模型对文本的预测能力最佳,故选取Kt=26作为目标领域LDA的主题数.接下来,在Ks=21,Kt=26的条件下设置后续参数.
2)跨领域系数
用户的偏好包括从源领域映射而来的和用户在目标领域的,将这两部分偏好进行加权求和,得到用户的综合偏好.在Ks=21,Kt=26的条件下,观察目标领域中MAE值随跨领域系数的变化趋势,如图5所示.
图5 跨领域系数对MAE值的影响
从图5中可以看出,随着跨领域系数的增大,MAE呈现波浪式变化.刚开始,MAE值随着跨领域系数的增大而减小,当跨领域系数达到临界时,MAE最小.随后,随着跨领域系数的增大,MAE值反而大幅度增大,说明目标领域所占的比例应大于源领域,当两者所占比例为7:3时,推荐效果最好,故本文的跨领域系数取值为0.3.
4.3 对比算法
本文提出的CDRS_FUDPAM算法结合用户评分、评论以及辅助领域信息,主要解决了以下两个问题.
问题1.用户评分与评论相结合的方式能否降低数据稀疏性对推荐结果的影响.
系统中大部分用户的活跃度都不高,往往只对少数感兴趣的项目评分,这导致评分矩阵的稀疏度非常高,进而很难从这有限的信息中充分提取用户偏好.而评论信息包含了项目的某些特征以及用户的偏好,信息丰富度远高于评分矩阵.通过LDA模型处理项目评论信息,再结合用户的评分信息可得到用户的偏好分布,进而降低数据稀疏带来的影响.
问题2.相比单领域的推荐算法,跨领域推荐算法能否提高评分预测的精度.
在单领域推荐系统中,不同用户的数据分布差异很大,有些用户十分活跃,评分评论数很多,但大多数用户只有很少的历史记录.历史记录丰富的用户通常预测的准确度较高,而历史记录稀少的用户的偏好通常难以被准确捕获.在跨领域推荐中,由于辅助领域的引入,原本缺少的信息在一定程度上得到弥补,进而提高预测的准确性.
为了实现上述目标,我们将CDRS_FUDPAM与4个目前性能较好的模型进行对比,分别是LFM、SVD++、HFT和USRMF.
1)LFM:经典推荐算法,通过矩阵分解预测用户对未评分项目的评分.
2)SVD++:LFM使用了SVD矩阵分解来求预测评分,而SVD++在LFM的基础上加入了隐性特征,使得算法性能得到进一步提高.
3)HFT[28]:将用户对项目的评分与评论信息结合,并融入LDA主题模型,提取用户更多的隐式偏好,使得推荐性能得到进一步提升.
4)USRMF[29]:使用LDA主题模型提取项目特征分布,结合用户评分得到用户的偏好分布与项目的隐特征,然后根据用户偏好与项目的隐特征得到其近邻用户与项目,同时结合矩阵分解模型使得算法性能进一步改善.
5)CDRS_FUDPAM:本文提出的模型CDRS_FUDPAM,在使用LDA主题模型提取评论信息并结合评分信息、时间因子与注意力机制的基础上,增加辅助领域信息,以降低单领域数据稀疏性的影响.
如表6所示,LFM和SVD++仅仅依赖评分信息,而HFT和USRMF同时使用了评分和评论信息.最后一个是本文使用的CDRS_FUDPAM,除了评分与评论信息,还加入了不同领域的信息,能够更全面地发掘用户的偏好.
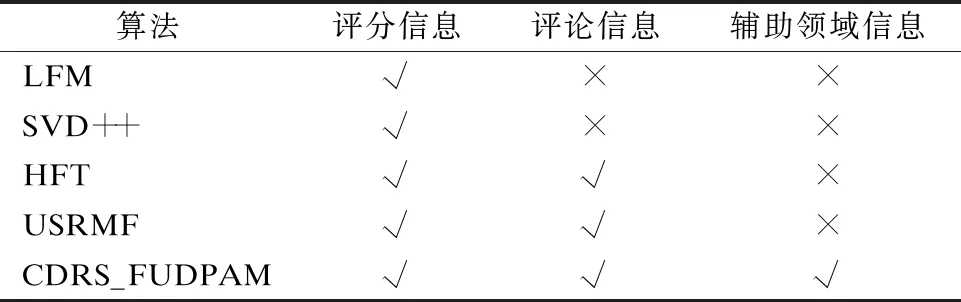
表6 不同模型特点对比
4.4 评分预测分析与讨论
4.4.1 评分预测对比
通常,模型的性能受多个因素限制,本文通过隐因子数来对比各个模型的性能差异,隐因子数过少,所获取的信息太少,造成模型欠拟合问题;隐因子数过多,容易过拟合.故分别设定隐因子数为6,11,16,21,…,66,观察各模型性能随隐因子数的变化趋势.对于主题模型(HFT、USRMF和CDRS_FUDPAM),隐因子数和主题数相等,其中CDRS_FUDPAM的隐因子数为目标领域的主题数.对于矩阵分解模型(LFM和SVD++),隐因子数等于用户或商品的隐向量长度.各模型MAE和RMSE值随隐因子数的变化趋势分别如图6和图7所示.
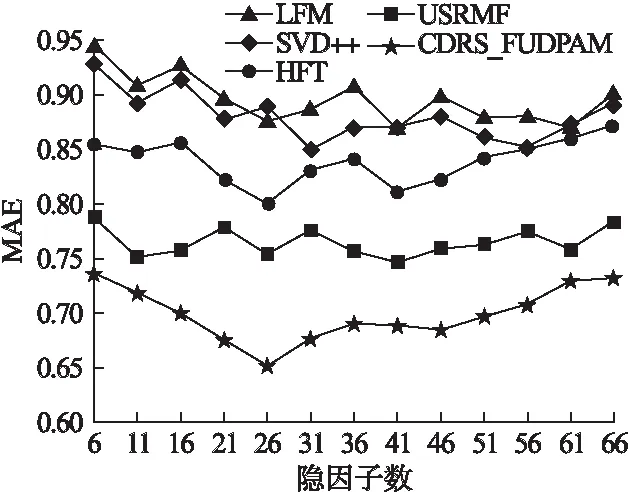
图6 隐因子数对MAE值的影响
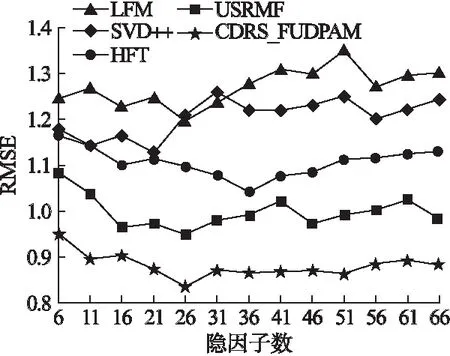
图7 隐因子数对RMSE值的影响
图6中,X轴为隐因子数,Y轴为MAE值.图中的各个曲线变化趋势表明,MAE值一开始与隐因子数呈负相关,当达到最小值后,继续增大隐因子数,MAE值的变化趋势与之前相反.这说明若要充分提取模型的特征就需要足够的隐因子数,隐因子数过少便无法实现.此时,通过增加隐因子数可以更充分地提取模型的特征.当隐因子数超过临界点后,继续增加隐因子数无法改善模型的性能.
图7中,X轴为隐因子数,Y轴为RMSE值.与MAE值随隐因子数的变化趋势类似,RMSE值一开始随着隐因子数的增加而减小,当达到最小值后,继续增大隐因子数,RMSE值非但不减小反而呈增大趋势.这说明隐因子数过少时,增加隐因子数可以更充分地提取模型的特征.当隐因子数超过临界点后,继续增加隐因子数无法改善模型的性能.
4.4.2 实验讨论
本文共选取了4种不同的典型算法与提出的CDRS_FUDPAM算法做对比,并对相应的结果进行分析.从图6中可看出,MAE值和RMSE值随着隐因子数的增加,均呈下降趋势.当隐因子数超过临界值时,继续增加隐因子数,模型的性能没有得到改善,反而越来越差,说明此时模型逐渐趋于过拟合状态.而CDRS_FUDPAM算法的整体性能均优于其它算法,说明辅助领域信息的引入能够有效改善数据稀疏带来的影响.
综上所述,LFM和SVD++算法仅利用了数据集中的评分信息,但评分信息通常由于数据的稀疏性和评分的随意性而难以完全反映用户的偏好,故这两种算法的MAE值和RMSE值偏高.而HFT和 USRMF在上面基础上添加了评论信息,使用LDA发掘项目的隐特征,算法性能较前两种算法有明显提升.而本文提出的CDRS_FUDPAM算法加入了辅助领域信息,同时结合注意力机制,使得推荐的准确性与时效性得到进一步提升.
5 总结与下一步工作
本文给出了一种基于用户动态偏好和注意力的跨领域推荐方法,尝试解决冷启动、数据稀疏性以及偏好时效性等传统推荐算法的问题.此方法将LDA提取的项目主题分布与用户的评分信息结合,得到用户动态偏好,同时引入时间权重因子与注意力机制使得用户的偏好更有时效性.最后,将源领域和目标领域的用户偏好进行加权融合,使得推荐的准确度进一步增强,推荐结果也更加丰富.
论文的主要贡献如下:
1)通过LDA模型将项目的评论信息转换为项目的主题分布,再结合用户对项目的评分,得到用户的动态偏好.由于同时利用了评分和评论,使得评分数据稀疏性带来的影响明显减小.
2)引入时间影响因子与注意力机制,将用户每个时刻的偏好与时间因子权重、注意力权重结合,使得对用户整体偏好的估计更为准确.
3)利用BP神经网络来获取源领域与目标领域之间用户偏好的映射关系,并将此映射关系应用于所有用户的偏好,将其从源领域映射到目标领域,再结合目标领域单独的推荐结果,使得最终推荐结果更加准确.
本文也存在一定的不足,对于冷启动用户和项目而言,推荐的准确性仍有待提高.另外,用户与项目的很多隐式特征并未充分利用.热门程度较高的项目往往具有较高的评分,而热门程度较低项目的评分往往具有随机性.接下来的工作将逐步加入用户的社交网络、用户的标签、资源的热门程度等影响因子,提取更多的隐式特征用以改善模型的效果.
猜你喜欢
数学物理学报(2021年4期)2021-08-30 08:27:50
中等数学(2020年1期)2020-08-24 07:57:42
文化创新比较研究(2020年14期)2020-01-02 19:25:56
文化创新比较研究(2020年8期)2020-01-02 04:45:23
成都信息工程大学学报(2019年4期)2019-11-04 00:56:02
青年生活(2019年23期)2019-09-10 12:55:43
阅读与作文(英语初中版)(2019年8期)2019-08-27 03:59:25
小学生学习指导(低年级)(2018年11期)2018-12-03 05:05:00
现代防御技术(2016年1期)2016-06-01 12:13:27
中共南宁市委党校学报(2015年4期)2015-02-28 11:48:10
