
多物理耦合计算中动态输运问题高效蒙特卡罗模拟方法*
2022-05-26 09:18上官丹骅闫威华魏军侠高志明陈艺冰姬志成
物理学报 2022年9期
上官丹骅 闫威华 魏军侠 高志明 陈艺冰 姬志成
(北京应用物理与计算数学研究所,北京 100094)
多物理耦合计算在众多领域都有重要应用.如果其包含粒子输运过程,用蒙特卡罗方法模拟粒子输运常占据大部分的计算时间,因此多物理耦合计算中动态输运问题的高效蒙特卡罗模拟方法意义重大,其不可避免地依赖于大规模并行.基于动态输运问题的特点,本文提出了两种新方法:一是针对输运燃耗耦合计算的新型计数规约算法;二是动态输运计算样本数自适应算法.两种算法都能在保持计算结果基本不变的前提下使计算时间大幅减少,从而提高了效率.
1 引言
在定量讨论各种核系统(如反应堆等)的动态行为时,中子的时-空及能量分布是很关键的.中子与原子核反应导致核能释放,从而导致介质温度、密度和运动速度等物理量发生变化;反过来,因为中子与核的反应依赖于二者之间的相对运动能量,从而介质中原子核热运动和流体运动将影响中子的输运过程.基于物理上的考虑,可以用Maxwell分布来描述核的热运动.在对核的密度分布函数作为权重求平均以后,中子输运方程中的系数将只依赖于中子与流体运动之间的相对速度.基于相空间中子数守恒原理,可得考虑流体宏观运动的中子输运方程[1]:

其中V=v−u是相对速度,v是中子速度,u是流体速度,N(r,V,t)drdV是t时刻r处体积元 dr内相对速度V处 dV范围内的中子可几数,Σ′f′V ′N′=Σ(r,V′)f(r,V′→V)V′N(r,V′,t),Σ(r,V)是宏观总截面,是一个中子在单位距离内与i类核经受某一由x标志的特定反应的概率,表示r处速度为V′的中子与i类核发生x类反应产生速度为V的中子的概率,q(r,V,t)drdV表示r处 dr体积元内产生的速度为V处 dV范围内的中子数.严格来说,由于宏观截面依赖于中子通量,所以上述方程中宏观截面是随时间变化的.所以,输运方程其实是一个非线性的微分-积分方程.由于流体运动的时间尺度较中子运动的时间尺度长,所以可选一个时间间隔,其相对于中子输运相当长,而对于流体运动来说相当短,从而在该间隔内可以忽略核数密度改变的影响.在时间间隔末通过解线性输运方程得到中子角通量以后,就可以利用所得中子角通量、流体力学方程组和燃耗方程组求解新的物质密度和核数密度.这样就把非线性输运方程转化为多时间步的线性输运问题,形成了多物理耦合计算(本文仅考虑流体力学、输运和燃耗的多物理耦合计算).
随着科学技术的发展,特别是并行计算能力的飞跃,粒子输运问题的建模(包括几何建模、物理建模等)越来越逼近真实情况,以前由于计算能力不足而不得不采取的各种近似逐渐被替换,这就给蒙特卡罗粒子输运模拟带来了巨大的挑战.以反应堆pin-by-pin 模型蒙特卡罗粒子输运模拟领域著名的Kord-Smith 挑战[2]为例,由于其高达百万以上栅元,几十亿数量级的计数规模的设置,使得蒙特卡罗模拟面临存不下、算不快和算不准的难题.对于多物理耦合计算中的动态蒙特卡罗粒子输运模拟而言,其面临挑战的难度相较Kord-Smith 挑战而言只高不低.这主要是由动态输运问题高达千万以上网格的几何建模、由于极端反应条件造成的数十万以上的计算步、由于输运与燃耗耦合而必须求解的大量网格计数所造成的,而且动态输运问题由于时间累积效应,定态输运蒙特卡罗模拟所常用的许多技巧并不能直接应用,需要根据动态问题的特点设计新的算法.
在公开发表的文献中,反应堆大型pin-bypin 模型的高效蒙特卡罗模拟方法呈现出蓬勃发展的趋势.区域分解[3,4]和数据分解[5,6]方法的提出主要是为了解决存不下的问题;为了解决算不快的问题,提出了若干高效样本数并行算法;为了解决全局计数算不准的问题,除了加大样本并高效并行以外,还提出了UFS (uniform fission site method)[7,8]和UTD (uniform tally density method)[9,10]等算法(这些算法都属于偏倚算法).表1 列出了常见的大型反应堆pin-by-pin 模型的蒙特卡罗模拟方法对于存不下、算不快和算不准这3 个难点各自的优缺点分析.其中“√”表示左边的算法对上面难点的解决有促进作用,“×”表示表示左边的算法对上面难点的解决有阻碍作用,“—”表示没有影响.框内的语句表示的是促进或阻碍作用最本质的原因.这些研究对于动态输运问题的高效蒙特卡罗模拟也具有重要的借鉴作用.
从表1 可以看出,各种算法在解决一个问题的同时常引入新的问题.对于本文关注的动态输运问题,由于其不同的特点,上述算法可以借鉴但不能照搬.鉴于动态输运蒙特卡罗模拟极大的计算量,设计高效算法的一个基本思路就是在基本不改变大样本直接模拟结果的基础上尽可能减少计算时间.为此,本文开展了针对输运燃耗耦合计算的计数规约优化算法和针对样本并行的样本数自适应算法研究.这些研究是在北京应用物理与计算数学研究所自主开发的极端条件下三维多物理多介质问题数值模拟软件JUPITER (jointed numerical simulation software for multi-physics and multimaterials problems under extreme conditions)上进行的,此平台对模型采取三维非结构网格建模,在此基础上进行多物理耦合计算.其中的蒙特卡罗粒子输运模拟模块(以下简称为JUPITERMC 程序)以区域分解加样本并行为基本架构,可支持数千万三维非结构多面体网格、数百亿样本的中子输运及燃耗耦合计算,具备数万处理器核的高效并行计算能力.

表1 常见算法优缺点比较Table 1.Relative merits of common algorithms.
本文第2 节介绍了一种基于输运燃耗耦合计算模式的计数规约新算法;第3 节基于蒙特卡罗模拟分批计算提出了一种样本数自适应算法;第4 节的数值结果表明两种算法都可以在基本不改变计算结果的前提下大幅减少计算时间,从而提高了效率;最后是总结.
2 计数规约优化算法
2.1 输运燃耗耦合计算模式
对于大规模动态输运蒙特卡罗模拟问题,为解决存不下的难题,JUPITER-MC 程序采取了区域分解加样本并行的二级并行模式.整个模型进行网格分片,每个进程只存储单个网格片(包含若干非结构网格)并分配若干样本粒子,一旦粒子逃逸出该网格片,就将粒子属性信息发送给相应的其他进程(其存储的是逃逸粒子所应到达的网格片).在输运燃耗耦合计算时,燃耗方程求解的是网格片上所有网格内所有核素新的核数密度.由于燃耗方程的输入是网格片上所有网格的多种微观反应率等计数,存储同一网格片的不同进程需要将这些计数进行规约平均并全局广播,以此保证求解同一网格片的不同进程上的燃耗计算输入是一致的,由此可以保证求解同一网格片的不同进程的燃耗计算的输出(即新的核数密度)是一致的(并不需要规约平均).
2.2 计数规约新算法
由2.1 节所述,同一网格片上所有网格的微观反应率需要规约平均并全局广播,而燃耗计算所得核数密度自然保持一致,并不需要费时的规约平均操作.但是,若网格片所含网格数目较多,或者存储同一网格片的进程数较多,需要规约平均并全局广播的微观反应率数据本身就是网格数目的多倍,由此导致并行通信的时间是不可忽略的(同一进程上,网格片所含网格数相对于样本数越多,计数规约所占的时间比例越高).仔细分析输运燃耗耦合模式,可以发现燃耗计算的输出数据几乎必然远少于输入数据.因此,本文提出了一种计数规约的新算法,即燃耗计算只利用本地的微观反应率数据进行计算,所以其输入端不需要费时的通信,而输出端(即新的核数密度)由于不同进程不再能保持一致,所以将存储同一网格片的不同进程的燃耗输出端按相应进程数进行规约平均并全局广播.虽然此种算法只是将费时的通信从燃耗输入端转移到输出端,但由于通信的数据量可以大幅减少,预期可以从总体上减少通信时间.值得注意的是,这种算法从原理上就不能保证串并行严格一致,但在样本数趋于无穷时,串并行结果是趋于一致且与原算法的结果是趋于一致的.
3 样本数自适应算法
3.1 研究基础
对于动态输运问题蒙特卡罗模拟进行样本数自适应研究,起源于三个方面的研究基础,即香农熵概念引入定态临界计算以指示裂变源分布的收敛、临界计算全局计数算法的研究和临界计算全局计数问题的样本数自适应算法研究.
3.1.1 香农熵
对于定态输运临界计算问题,理论上只有当裂变源分布已经收敛时才能进行各种计数,否则结果是包含系统性误差的.当迭代计算进行时,可以利用信息论中香农熵的概念对裂变源分布是否收敛进行后验检验.假设系统包含N个栅元,在某一步迭代计算后产生了M个裂变点,每个栅元包含Mi(i=1,2,···,N)个裂变点,则裂变源分布对应的香农熵H为
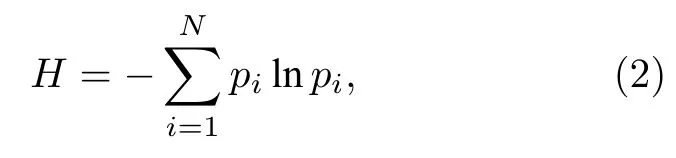
其中pi=Mi/M.每一迭代步将产生一个熵值,当计算完成时,若判断出K步以后熵序列已经收敛而开启计数的迭代步号大于等于k,则认为所得计数没有系统性误差.当然,也存在一些基于熵概念对裂变源分布是否收敛的实时诊断方法研究[11−13].
3.1.2 临界计算全局计数算法
在定态临界计算时常常伴随着全局计数的求解,由于全局计数问题目标众多且核系统各部分之间反应性的不均匀,全局计数问题单靠增加样本数是低效的.为此,基于对裂变次级中子数进行不同标准的偏倚,产生了UFS 和UTD 等算法,这些算法以若干全局计数整体效率指标进行衡量,都大幅提高了计算效率.
3.1.3 临界计算全局计数问题的样本数自适应算法
由于定态临界计算时何时启动全局计数是凭经验设置的,且每步样本数是固定不变的,所以可能存在过早启动全局计数(即裂变源分布还未收敛就启动全局计数)和冗余计算(即全局计数结果已经满足要求还在计算)的问题.文献[14]提出了一种临界计算全局计数问题的样本数自适应算法,其基于对香农熵序列的一种实时收敛性诊断方法和对一种全局计数精度指标的实时监测,可以保证在更合理的地方启动全局计数并且节省不必要的计算.
3.2 样本数自适应算法
在国际著名的定态蒙特卡罗粒子输运模拟软件MCNP 中,存在根据某一计数的相对误差变化进行样本数自适应调整的方法.但这一方法并不适合动态输运蒙特卡罗模拟.因为动态计算中反馈给其他物理过程的全局反馈量很难确定哪一个重要,无法根据某个计数结果的相对误差进行样本数自适应调整.基于定态输运临界计算和动态多步输运计算的类比,即定态临界计算的裂变源中子对应于动态输运计算上一步传递给本步的未死亡粒子(称之为时间源粒子),定态临界计算的全局计数对应于多物理耦合计算中动态输运反馈给其他物理过程的全局反馈量,可以设计动态输运蒙特卡罗模拟的一种样本数自适应算法,详述如下.
3.2.1 基本思路
由于JUPITER-MC 程序是样本数分批计算,每批计算都会形成时间源中子和全局反馈量计数.时间源中子形成的时间源分布和全局反馈量计数对于整个多物理耦合计算来说是最重要的两个因素.所以,一旦某批次计算完成,根据某种判断标准表明时间源分布已经抽样充分且全局反馈量计数已经整体收敛,则可以提前结束本步的计算,不再进行剩余批次的计算.这是多物理耦合计算中动态输运蒙特卡罗模拟样本数自适应算法的基本思想.
3.2.2 基本工具
上述基本思路的实现需要3 个基本工具.一是根据什么定量指标表明时间源分布已经抽样充分;二是根据什么定量指标表明全局反馈量计数已经充分收敛;三是如何根据批次的增加实时判断上述两个指标已经收敛.前两个工具的实现离不开香农熵概念的推广.第3 个工具则是一种熵值序列的实时收敛性诊断方法.
由于时间源中子是时间源分布的抽样,对于某一固定的相空间网格(这里仅考虑空间和能量组成的相空间),假设共包含N个网格(Si,i=1,2,···,N)、G个能群(gi,i=1,2,···,G)和M个时间源中子,令pij(i=1,2,···,N;j=1,2,···,G)是包含在相空间网格Si×gj中的时间源中子数除以总时间源中子数再除以Vi(Vi是相应网格的体积),则

Hs是一个指示时间源中子是否已经足够代表时间源分布的类香农熵指标.基于同样的考虑和全局反馈量都是通量与某响应函数的积分的事实,可设计指示全局反馈量计数是否整体收敛充分的类香农熵指标如下:
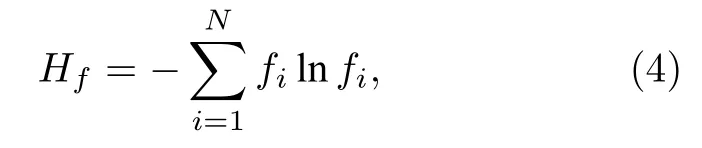
其中fi是第i个网格上的体通量除以总通量.注意到上述两个指标是第一次提出用以指示时间源中子是否充分和全局反馈量计数是否整体收敛,虽然指示全局反馈量计数是否整体收敛的指标不止一个.
对于分批计算,每完成一批计算就会得到新的熵值Hs和Hf.可以设计熵值序列的实时收敛性诊断方法如下:对每一种熵值序列,在第n批计算完成后可构造随机振荡指标Kn,其定义为[15]
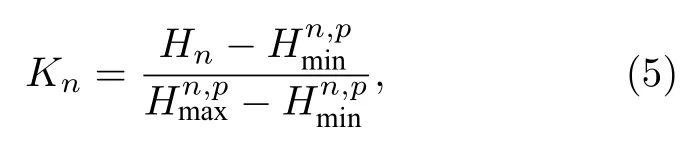

则可认为对应熵值序列已经收敛(p,m,ε固定为20,50,0.1).
4 数值结果及讨论
如引言中所述,本文只关注力学、输运和燃耗的多物理耦合计算问题,因此本节将给出若干此类模型的计算结果.必须指出的是,同样的方法是可以应用到其他多物理耦合计算过程的.
4.1 计数规约优化算法结果
考虑一个包含141 万非结构六面体网格的模型,该模型包含5 种介质,其中有含裂变物质的材料.对其进行多介质ALE (arbitrary Lagrange-Euler)力学、中子输运和燃耗的耦合计算.其中蒙特卡罗粒子输运模拟采取每步1600 万样本,160 核并行,不进行区域分解(经物理分析,此样本数对于本模型是足够的).由于计数规约优化算法在减少燃耗输入端规约数据的同时增加了燃耗输出端的规约数据,所以比较计数规约时间和燃耗计算时间之和(包含燃耗输出端的规约时间)是合理的.
如图1 所示,计数规约时间和燃耗计算时间之和减少了大约30%.表2 是该模型一个完整的计算结果,其中把原程序对总释放能量的计算结果取为标准1.从表2 可以看出,总释放能量只有约1%的变化,而总计算时间减少了约15%.可见,计数规约优化算法可以在基本保持原结果不变的前提下实现计算时间的减少,从而提高了效率.

图1 新旧方法计数与燃耗计算时间之和的对比Fig.1.Comparison of the total time of tally reduce and burnup calculation by using old and new methods.

表2 对于一个包含141 万非结构六面体网格的模型,全过程计算结果与计算时间比较Table 2. Comparison of the results and calculation time for the whole simulation for the model including 1.41 million unstructured hexahedral meshes.
4.2 样本数自适应算法结果
首先考虑一个包含550 万非结构六面体网格的模型,含7 种不同的轻重介质,其中包含裂变材料.对其进行定态迭代计算求解中子时间增殖常数:
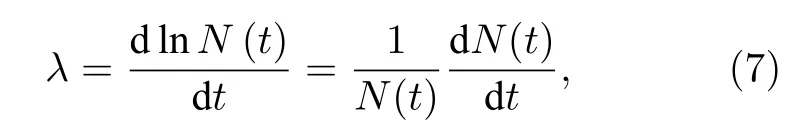
其中N(t)是t时刻系统中的中子数.蒙特卡罗模拟迭代100 步,每步3200 万样本,64 核并行.表3是其计算结果及时间.可见,最终的λ只变化了0.5%,而计算时间减少了约57%.

表3 对于一个包含550 万非结构六面体网格的模型,定态迭代计算结果与计算时间比较Table 3. Comparison of the λ and calculation time for the iteration calculation for the model including 5.50 million unstructured hexahedral meshes.
其次考虑一个包含2233 万非结构六面体网格的模型,同样含7 种不同的轻重介质,其中包含裂变材料.对其进行多介质ALE 力学、中子输运和燃耗的耦合计算.蒙特卡罗模拟每步1.6 亿样本,8000 核并行,区域分解为250 个网格片(注意,由于此模型足够精细,若不进行区域分解,大型机的内存仍然不够).表4 是其计算结果及计算时间.其中,原程序的总释放能量取为标准1.可见,最终的总释放能量只变化了0.4%,而计算时间减少了约39%.

表4 对于一个包含2233 万非结构六面体网格的模型,全过程计算结果与计算时间比较Table 4. Comparison of the results and calculation time for the whole simulation for the model including 22.33 million unstructured hexahedral meshes.
从上面两个模型的计算结果可以明显看出,样本数自适应算法可以在基本保持原结果不变的前提下实现计算时间的大幅减少,从而提高了整体计算效率.
5 结论
基于多物理耦合计算中动态输运问题的特点,本文在香农熵概念的启发下通过设计新的指标和利用一种实时熵值序列诊断方法,实现了对动态输运蒙特卡罗模拟的样本数进行自适应调节的方法,避免了过多的冗余计算.同时,基于对多物理耦合计算中输运燃耗耦合模式的分析,提出了一种新的MPI 环境下的计数规约算法,可以在保持结果统计等价的前提下减少必须规约的数据量,从而减少时间.经若干大型模型的检验,两种算法都能在保持计算结果基本不变的前提下使计算时间大幅减少,从而提高了效率.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
核安全(2022年3期)2022-06-29
北方民族大学学报(2021年5期)2021-11-27
宇航计测技术(2019年3期)2019-10-29
表面工程与再制造(2019年3期)2019-09-18
现代计算机(2019年19期)2019-08-12
北京航空航天大学学报(2018年10期)2018-10-30
金桥(2018年4期)2018-09-26
科学与财富(2016年34期)2017-03-23
