
直播网站在线弹幕情感分析
2022-05-26 08:56陈朝明
软件导刊 2022年5期
陈朝明
(中南民族大学计算机科学学院,湖北武汉 430027)
0 引言
近年来,随着在线影音平台的兴起,网络直播成为一种影像娱乐的流行模式。直播与其他各种传统影视的最大区别在于,观众能随时通过弹幕文本和视频主播之间进行实时交互,主播也同样可以根据其受众的直播需求进行实时反馈——通过弹幕及时地调整自己的直播节目动态内容并更好地通过直播取悦其受众,以获得更多关注。其中,演出或主持直播的主角一般称之为“主播”或是“实况主”。弹幕则指一种用户观看直播的评论方式。这些评论文本从屏幕上呈现一闪而过的视觉效果,看上去如高速飞行的子弹一般,因而人们将其称之为弹幕[1]。
在对文本的情感分析中,传统方法大多是基于对情感知识的认知构建一个情感词典,然后以这些情感词典为主要工具进行分类。国内外研究者在情感分析的研究和应用上已取得突破性进展,但对于弹幕文本情感分析的深入研究却较少。最早提出情感分析字典的whissell[2],他们先招募了148 名受试者,首先使用5 个附加单词,其中包括描述一个数学术语、物理科学术语、电视技术术语、报纸技术术语和生物学等术语,然后与其他情感词典频次度最高的情感字词互相匹。Kim 等[3]利用同义词、近义词的关系,将一批人工标注的初始种子情感词作为基础,将与种子词同义词语的情感倾向设置为相同,与种子词反义相反则设置为对应的情感极性。上文提出的情感词典都比较基础,即只对使用最为广泛的词如“漂亮”“好”“不行”等进行了收集整理。基础情感词典锁覆盖的文本有限,无法结合语境、语义分析,在情感分类性能上存在不足。有一些年份比较久远的情感词典应用到具有新含义情感词的语料中时,由于受到语境迁移影响从而导致分类效果较差。
在文档和句子层次上,目前研究主要集中在基于机器学习的情感分类方法上。这种方法将预先标记数据的情感极性作为训练数据[4]。根据训练数据,对情感分类模型进行训练,优化分类精度,然后对文本进行情感极性分类。谢铁等[5]利用深度递归神经网络算法获取句子语义信息,并引入汉语“情感训练树图数据库”作为训练数据,找到词语中的情感信息;Appel 等[6]提出一种结构混合式的句子级情感分析方法,在已有情感词典的基础上,利用自然语言处理技术对情感词典进行增强,并利用模糊集估计句子的语义方向、极性和强度,为情感计算提供了基础。这两种方法都忽略了句子间的依存关系;Abbasi 等[7]提出一种基于语言学规则的多文本语义特征选取方法,该选取方法不但考虑了语义信息,还利用语法特征之间的相互关系,可以有效去除文本中的杂质、无关信息和其他冗余的语义特征;党蕾等[8]首先分析不同语法之间的相关性,然后根据语法结构提取距离因子,并对否定模式匹配后的句子极性算法进行改进,最后提高了句子级情感分析的准确性。在分析相关基础知识和语义特征的基础上,Shi 等[9]提出基于随机条件的情感信息联合识别模型,并给出一个关于词语情感强度的计算公式。他们提出的模型对于弹幕这样的短文本评论语言适用性较差。
尽管国内外研究者对传统文本的情感分析进行了大量深入研究,已取得较为成熟的成果[10],但对弹幕情感的研究与分析并不多。并且,由于弹幕独特的在线实时、语言简略与互联网化特征,现有方法难以直接用于弹幕情感分析。因此,采用新的方法对直播弹幕的情感进行分析具有非常重要的实际意义与应用价值[11]。
已有研究中尚没有对弹幕的特征进行研究,也缺乏对弹幕领域情感词典的完善。针对该问题,本文做了如下工作:提出一个基于改进SVM 算法的情感分析模型;在收集处理直播网站在线弹幕文本后构建一个弹幕文本语料库,结合现有情感词典构建一个弹幕专属情感词典,在对优化模型进行实验后实现分类性能提高;考虑了弹幕中能表达情感的各项特征[12]。
1 情感分析流程
情感强度评价是对情感极性的判断,将判断结果细分为强、中、弱等不同程度。文本情感分析一般过程如下:①从互联网上收集和整理原始语料库数据,首先对数据进行清理,去除非文本数据,然后对文本进行预处理[13];②根据不同的算法,对预处理后的文本数据进行情感极性判断和情感强度评价;③将情感分析过程的结果应用到事物评价、企业经营、政府监管等相关领域,实现研究的意义和价值[14]。
弹幕情感分析流程如图1 所示,首先从直播平台收集和整理原始语料库数据,对原始弹幕数据进行清理,去除非文本数据形成弹幕语料库[15],然后对文本进行预处理。通过对语料进行特征提取,构建弹幕情感词典[16]。
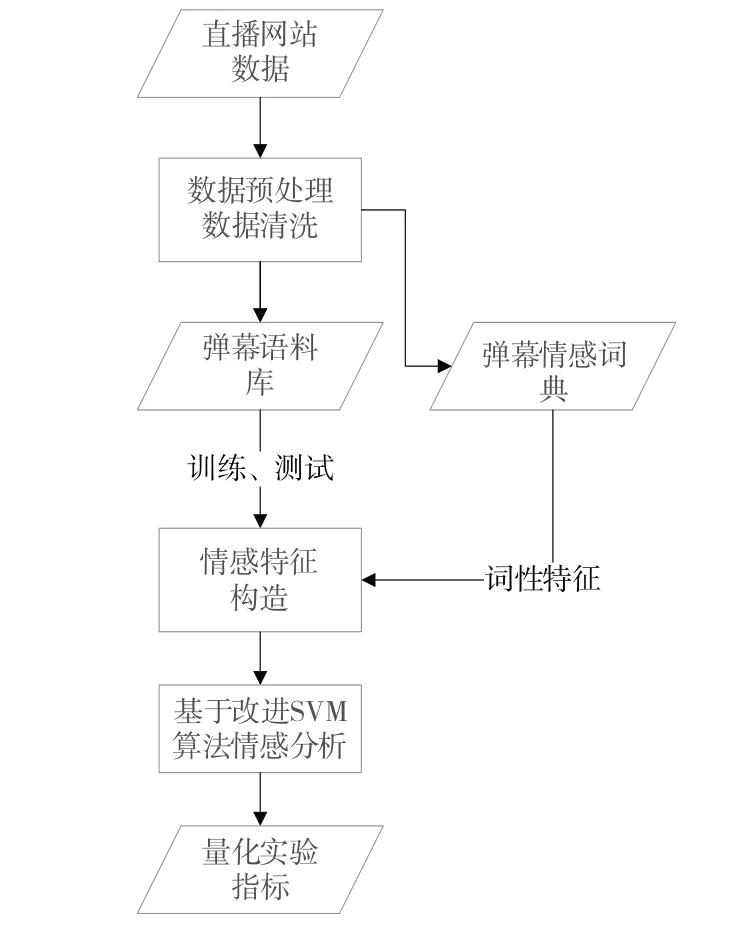
Fig.1 Flow of bullet screen sentiment analysis图1 弹幕情感分析流程
2 弹幕数据情感分析模型
2.1 系统模型
如图2 所示,系统模型由语料库、特征工程、分类器组成。首先,原始数据由直播网站后台获取,分别经过分词、停用词进行处理,将其进行人工分类后组成的语料库;然后,通过特征工程提取每个W特征,转化为,其中x为W提取的各项特征,y为W的分类结果(包含正向和负向);再经过本文改进的分类器进行分类得到S{W1,W2,...,Wn},通过输出数据优化分类器使分类器得到更好的性能评价指标P。因此,该模型的核心问题可以描述为:

2.2 数据预处理
本文选取虎牙直播网站的弹幕数据作为本文的语料数据来源。通过虎牙直播网站开放接口,使用Python 接收后台数据,并将所需直播间的弹幕文本保存在本地中。本文以虎牙的官方直播间——《英雄联盟赛事》(https://www.huya.com/lpl)为主要数据获取对象。经过一段时间的实时弹幕获取,累计得到61万条文本。
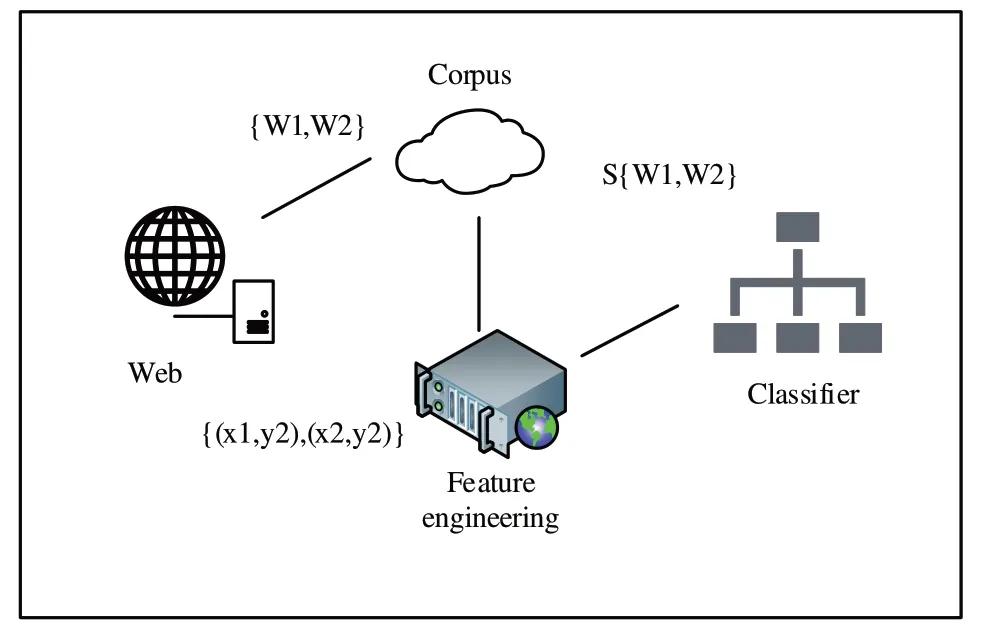
Fig.2 System model图2 系统模型
由于弹幕的口语化严重,弹幕文本往往包含大量与情感表达无关的文字。为了保证后续情感分析结果的有效性,需要进行严格的文本预处理操作,以保证文本数据的标准化。对弹幕文本的预处理包括以下几个步骤:过滤无意义文本、情感极性标注、文本分词和去除停止词[17]。
在对弹幕文本进行分词处理后,出现了大量的无意义词。这些词在各种汉语文本中都很丰富,但并不参与文本意义的表达,这些词被称为停止词。停止词指在语篇中频繁出现但对语义研究毫无意义的词,如“和”“德”“在”“然后”,以及一些使用过于频繁的词,如“我”“就”“啊”“把”。此外,作为网络文本,弹幕还包含一些英文、数字、表情符号和特殊符号。弹幕的口语化现象严重,因此去除停止词也是文本预处理的一个重要步骤。本文将收集所有的停止词,形成停止词列表。分词后匹配停止词列表,过滤文本,避免分词后过多干扰。使用for 循环遍历seg_str,通过if 语句判断该词是否存在于停止词列表中,将该词后面的停止词移到seg 列表的内容中[18]。
2.3 情感特征构造
在考虑特征构造时,本文选取几种常见的情感特征。通过组合这些特征得到最优分类效果。其中,词向量化是最基础的工作,标记了每个词在训练文档中的空间特征,在后文的实验中称为word 特征[19];情感词典则依据情感词进行分类,在实验中称为pos(词性)特征;依存句法分析则通过综合算法判断句子的情感特性,叫作dep(句法)特征。
针对直播弹幕情感词典缺乏的不足,为了构造一个弹幕领域性词典,本文在大连理工信息检索研究室情感词汇本体(Dalian University of Technology Sentiment Ontology,DUTSO)的基础上,通过增加弹幕专属情感词的方式,构建新的情感分析词典。获取新的情感词首先要将文本数据进行预处理,目前的预处理工作一般包含数据清洗、停用词处理、分词、词性标注、词频统计等。情感词汇如表1所示。
在评论语言中,情感词和评价目标词之间通常存在某种修饰关系,这种修饰关系可以通过依存分析找到。依存分析通过分析词与词之间的依存关系,揭示句子的句法结构。在依存句法理论中,句法结构实质上包含了词与词之间的依存(修饰)关系。依存关系可以分为不同的类型以表达句子中两个词之间的特定句法关系,并且用于连接主导词和从属词。采用依存句法描述句子的好处在于不需要理解单词本身的意思,而是通过所承载的语法关系表达单词,而且其数量远远少于单词数量[20]。同时,一个句子中的核心动词是支配其他成分的中心成分,它不受自身支配,并作为句子的根节点,这样的词在依存关系中被记录为“根”。当然,非正式不完整句子中可能没有动词。此时,形容词或名词也可能成为根节点。并且,依赖于根节点,其他组件之间也存在依赖关系。除词汇本身特征外,还需组合的情感特征如表2所示。

Table 1 Emotional vocabulary表1 情感词汇
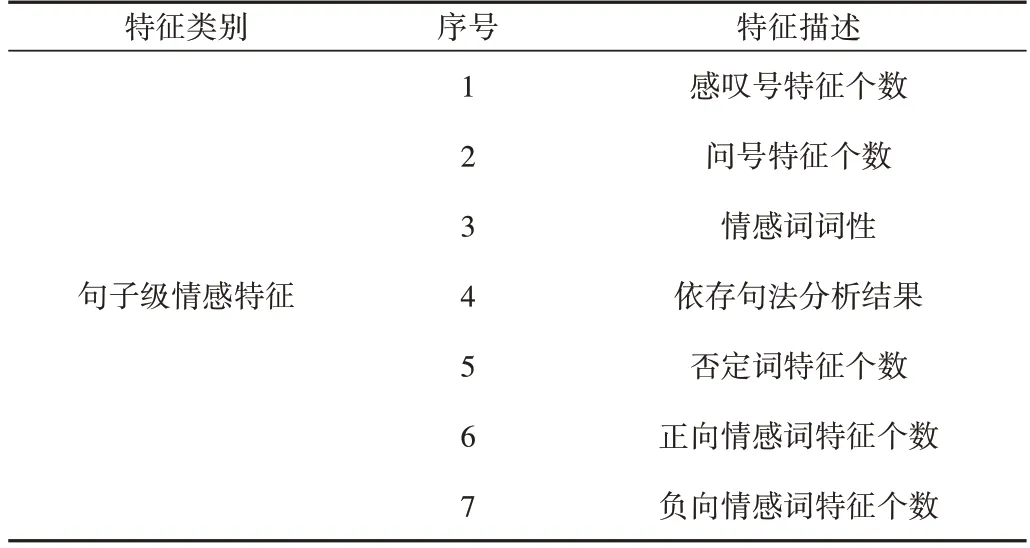
Table 2 Emotional characteristics explanation表2 情感特征示意表
基于依存语法的方法是利用依赖语法分析提取文本的主干,然后利用其他分类方法对其进行分类。该方法提取的主文本大多包含明显的情感词和情感对象,文本中没有明显情感词的部分往往被忽略,但这些被忽略的部分也可能表达情感。因此,从提高文本预期利用率的角度出发,考虑了其他部分的影响:利用句法依存关系提取评论句中的短语,并在此基础上进行分句[21],提取出可能表达意见的句子部分,并利用训练好的监督分类模型识别意见类别类别。
2.4 基于改进SVM 算法的情感分类
弹幕文本经过特征提取,得到了一个高维空间的向量矩阵,这些数据的分类依赖于有效的分类器。在对比多个机器学习方法后,本文选取支持向量机(Support Vector Machine,SVM)算法构建情感分类的分类器[22]。SVM 算法在面向本文所提弹幕语料库这种数据量不大的样本时仍然有效。其分类准确率高、泛化能力强。假设弹幕文本训练资料为:
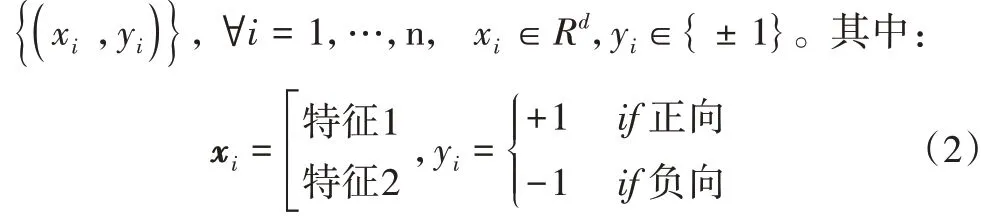
样本空间中任一个样本点到超平面(ω,b)的距离可写为:
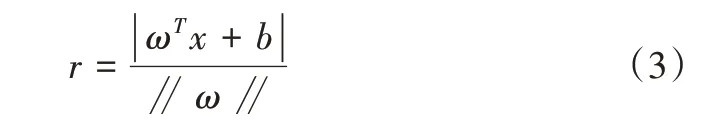
SVM 的优化目标是使r最大。正向分类满足wTx+b>=1,负向分类满足wTx+b<=-1。将这两类可整理如下:
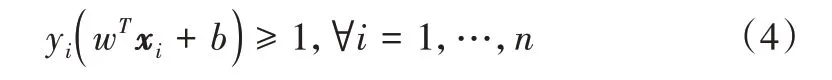
分类问题即满足上式条件的优化问题,总结为:
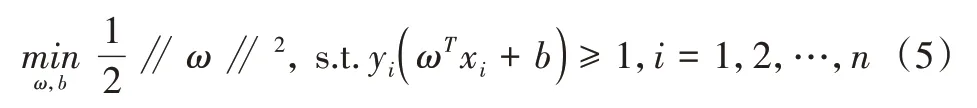
将情感分类模型转化为无限制经验损失最小化问题,考虑到误差问题引入Hinge Loss,l(ω,(x,y))。最小化问题的定义函数如下:
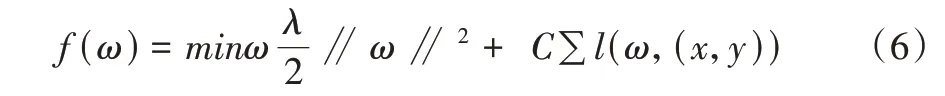
其中,l(ω,(x,y))如下:
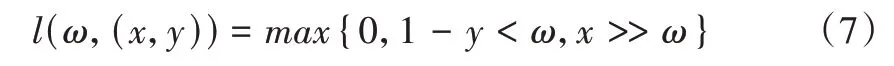
使用随机梯度下降求解目标函数。
为了平衡泛化与学习,提高内核函数的自适应性,引入分类处理因子与梯度下降因子对SVM 进行算法改进[23]。用Smooth Loss 替换Hinge Loss,即将式l(ω,(x,y))转化为,将问题进一步转化为超平面下的无约束平滑优化问题。
随机选取超平面空间下的一个训练样本it,其中i为某一情感特征,a为样本活跃度即迭代次数。将式(8)转化为式(9)。
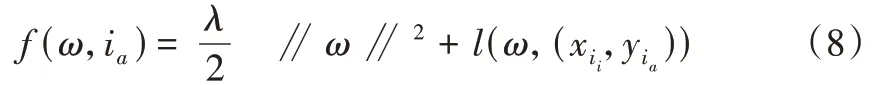
进行子梯度求解,如下:

可以看到,引入了分类处理因子与梯度下降因子后,可以得到一个降低了泛化误差的预测器。本文将通过实验对改进SVM 后的情感分类模型进行效果验证。
3 实验
3.1 实验环境
为了验证本文方法的有效性,采用Pycharm 工具在Windows 平台实现本文提出的弹幕情感分析算法。实验环境如表3所示。

Table 3 Experimental environment表3 实验环境
实验所使用的语料库为本文获取的虎牙后台弹幕数据,这些经过上述处理步骤,即过滤无意义文本、情感极性标注、文本分词和去除停止词。原始弹幕总共有61 万条,经过第一步处理还有11 万条,再从11 万条弹幕中随机抽取1 万条进行标注,其中有明确情感倾向的数据形成数据集DTDS,部分数据如图3 所示。其中,有1 250 个正向语料和1 250个负向语料,共计2 500条语料。
Fig.3 Processed corpus图3 处理后的语料
3.2 不同模型实验比较
为了比较模型好坏,实验中加入最大熵、未改进的SVM 算法和朴素贝叶斯算法作为比较,这3 种算法均为SKlearn 工具包提供的基本分类算法。本实验的评价标准为准确率、召回率和F1值[24]。
实验设置了5 组分组实验,其中每组由250 个正向语料和250 个负向语料,4 组增量实验各组分别由150 对、300对、450 对和600 对正负语料构成。4 种算法实验结果如表4所示。
通过对比可以看出,本文提出的改进SVM 分类器模型比未改进模型的评价指标(精确率、召回率、F1 值)分别高3.8%、2.3%与1.1%,而传统SVM 又比朴素贝叶斯算法和最大熵算法模型高3.7%、5.3%与4.5%和5.7%、5%、5.4%。这充分表明,通过增加弹幕词典及改进特征组合,能有效提升在线弹幕情感分析的准确性和有效性[25]。
3.3 特征组合对性能的影响
在机器学习分类器的训练算法确定为SVM 后,接下来需要选择一定的特征组合方法,并对组合的特征进行筛选。本文将弹幕文本特征分成单词(word)、词性(pos)与句法(dep),按照word、word+pos、word+dep、word+pos +dep 4 种特征组合进行实验,分析精确率、召回率与F1 值。不同特征组合的性能如图4所示。
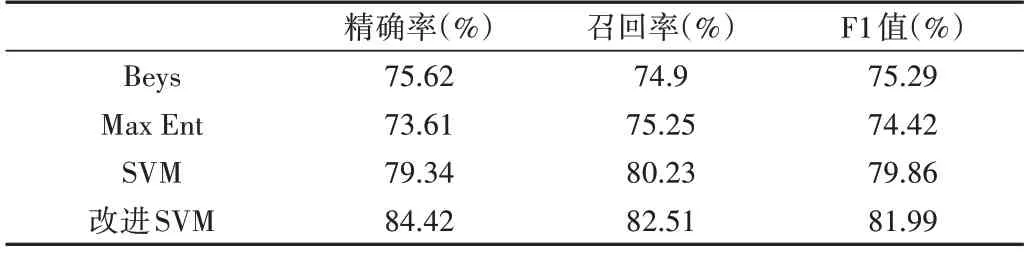
Table 4 Comparison of experimental results of each method表4 各方法实验结果比较

Fig.4 Experimental results of different feature combinations in improved SVM algorithm图4 不同特征组合在改进SVM算法下的实验结果
从图4 可以看出,加入了特征组合后,实验效果均比单一word 特征性能更优。仅考虑word 特征时,精确率、召回率与F1 值分别为61.47%、65.26% 与67.13%,通过增加词性(pos),精确率与召回率分别提升到66.97%、73.41%。这充分说明特征项的增加对模型性能有显著影响,尤其是在弹幕文本中,由于文本短以及口语化,词性与文本情感具有明显相关性。
word+dep 的特征组合性能要优于word+pos 的特征组合,精确率、召回率与F1值分别提升到70.85%、71.47%、77.93%,这表明了句子特征对于弹幕文本的有效性。其主要原因在于,弹幕具有文本短及表达简洁的特征,仅从词性与单词的角度分析还不够。而将3 组特征进行全部结合的word+pos+dep 效果最好。word+pos+dep 在评价指标(精确率、召回率、F1 值)上与word+pos 相比分别高4.2%、0.2%、30.9%,与word+dep 特征组合的性能相比高0.4%、2.2%与9%,其中word 特征,也即直接将语料转化为词向量的性能时最差,这一结果意味着短语类别分类更依赖于词和词之间的依存句法关系,这也验证了本文基于改进SVM 算法融合4项情感特征的情感分析模型的有效性。
4 结语
情感分析作为近年来自然语言处理的热点之一,在热点分析、舆情监测和自动答疑等方面具有广阔的应用前景。弹幕作为一种新兴的应用,具有篇幅短、用词口语化、网络词语和符号较多等特点,给传统情感分析方法带来了挑战。本文着眼于弹幕文本情感分析,对直播弹幕与情感分析相关技术进行了深入分析,同时分析出用户对直播内容的喜好程度,提高弹幕情感分析准确性。
本文针对弹幕语料库缺乏、语言简略及互联网化特征,构建了弹幕专属情感词典;针对直播弹幕语言的特性,提出了一种基于改进SVM 的情感分析模型。通过引入分类处理因子与梯度下降因子,降低了预测器的泛化误差。在此基础上,提出了词向量、情感词、否定词和标点符号等多种融合特征的方法。通过实验优化调整模型参数,得到适合直播弹幕的特征组合,提高了分类准确度[27]。实验结果表明,本文提出的方法在精确率、F1 值及召回率性能上更优。同时,本文研究也存在一些不足:本文只使用了虎牙直播的弹幕文本作为实验数据,由于直播内容的多样性,可能不能完全说明本文情感分析模型的稳定性和鲁棒性。并且,本文提出的情感分析模型基于情感分类中的二分类方法,通过分类结果计算单位时间的情感。在实际应用中,情感具有多样复杂的特征,对弹幕文本进行更加细分的多分类情感分析是下一步研究方向。
猜你喜欢
汉语世界(2021年2期)2021-04-13
小学科学(学生版)(2020年10期)2020-10-28
小哥白尼(野生动物)(2019年3期)2019-07-01
疯狂英语(双语世界)(2017年3期)2018-01-19
疯狂英语(双语世界)(2017年1期)2017-07-01
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
当代修辞学(2013年4期)2013-01-23
