
面向课后服务科普聊天系统的设计与实现
2022-05-25 01:53:48吴中其陈隽淇马启伟林芷泳黄贝苗
大科技 2022年20期
吴中其,陈隽淇,马启伟,林芷泳,黄贝苗
(华南师范大学软件学院,广东 佛山 528225)
0 引言
2021 年,中共中央办公厅国务院印发《关于进一步减轻义务教育阶段学生作业负担和校外培训负担的意见》[1]。该政策结合了校外减负及校内减负两个方面,能够切实地进行减负工作。但与此同时,如何引导中小学生开展探究性学习活动成为当下需要考虑的重要问题。
本文围绕本系统对系统的功能设计、深度学习模型、前端架构设计、数据库设计与后端架构设计这五个方面进行阐述。使用Qt 设计前端界面,选用GPT-2 模型作为本系统对话模型,采用了Python Flask 框架构建后端系统进行本系统的设计。
1 系统模块设计
科普聊天系统主要分为登录/注册、科普聊天、班级学习排名、班级学习情况统计和收藏夹5 个模块。
(1)登录/注册:为满足系统需要记录用户的学习情况并为其提供个性化服务,用户访问本系统都需要在该模块进行登录。若用户没有账户,需在该模块进行注册。
(2)科普聊天:用户可以通过语音输入或者文字输入的方式与系统进行对话。在对话过程中,系统将通过对用户输入的内容进行分抽取,结合数据集中的科普背景知识生成流程的回答,通过多轮的对话让用户在无形中学习新知识。
(3)班级学习排名统计:该模块以用户在科普聊天模块中所累计的积分为主,用户的学习时长为辅,对每个用户进行学习情况排名,以激励用户的学习热情。
(4)学习情况统计:该模块统计用户当日的学习情况并实时展现给用户,同时还将展现同组内其他用户的当日学习情况,通过横纵对比更加深刻的了解自己的学习情况。
(5)收藏夹:当用户在和系统对话的过程中,如果用户觉得系统科普的内容自己还未掌握或者科普内容值得再次查看即可直接右键点击对话内容选择收藏该对话,并在收藏界面进行查看,同时用户还可以将不再需要的内容取消收藏。
2 深度学习模型与数据集
2.1 GPT-2 模型介绍
GPT-2 模型[2]由多层单向Transformer 的解码器部分构成,本质上是自回归模型。GPT-2 凭借其稳定、优异的性能吸引了业界的关注。GPT-2 在文本生成上有着惊艳的表现,其生成的文本在上下文连贯性和情感表达上都超过了人们的预期。使用GPT-2 作为我们系统的对话模型具有合理性。
2.2 KdConv 数据集介绍
数据集方面,本文选取了Zhou 等学者[3]在知识驱动的中文多轮对话数据集KdConv 一文中构建的数据集。由于KdConv 数据集结构与GPT-2 模型的所需的输入有所不同,因此本文提取了该数据集中的有效数据,并进行了适应性修改。
经训练后,模型具备了在流畅应答的前提下进行科普的能力,可以满足大多数场合中的对话需求。
3 聊天系统的实现
3.1 前端架构设计
QT 具有良好的跨平台特性,能够支持Microsoft Windows95/98、Microsoft Windows NT、Linux、Solaris、SunOS 等众多操作系统。除此之外,Qt 具有良好的封装机制,具有良好的可重用性,能为开发人员提供遍历。基于上述理由,本文使用Qt 技术来实现系统的前端模块。
本项目使用组件化开发,减少代码冗余,将整个前端项目分成页面逻辑层、数据请求层和路由转发层。页面逻辑层负责进行响应,接收用户提供的文本数据;数据请求层负责接收并向后端发送文本数据,获取请求结果;路由转发层则负责进行页面跳转,以及在每次跳转时验证用户信息,阻止无权限访问。用户使用软件流程图如图1 所示。
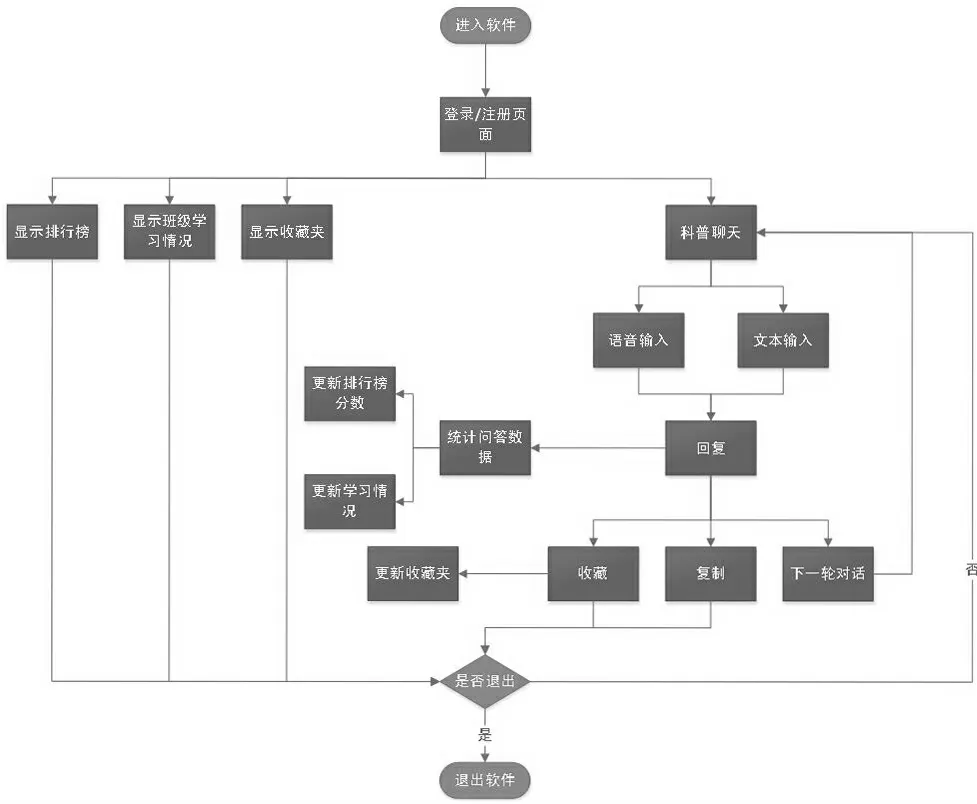
图1 用户使用软件流程
3.1.1 登录/注册模块设计
(1)注册过程。注册模块通过前端获取用户注册信息,对信息加密后传输到系统的后台服务器中。服务器进行数据合法性验证后,通过查询数据库数据判断用户的注册信息是否重复,若不重复则动态生成SQL 语句将用户信息插入数据库表中,注册模块工作流程如图2 所示。
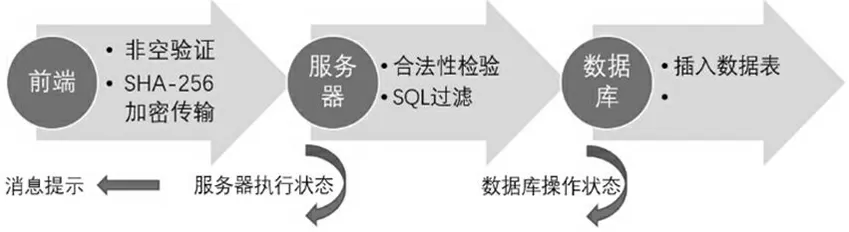
图2 用户注册模块工作流程
(2)登录过程。注册模块通过前端获取用户登录信息,并将其输入信息上传至后台服务器。服务器进行数据合法性验证后,通过查询数据库数据判断用户的账户信息是否存在,及登录口令是否正确,若存在且正确,根据用户名签发token,默认状态下有效期为3h,超过3h 后token 失效,需要重新登录。图3 为用户登录模块工作流程。
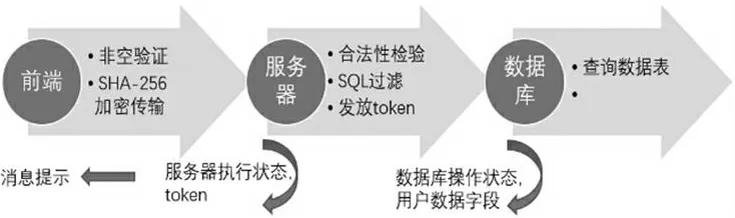
图3 用户登录模块工作流程
3.1.2 语音模块设计
语音模块使用Python Pyaudio 工具库进行基本功能的实现,并根据程序需求封装为utils/audioManager 模块。该模块内实现了申请音源输入设备、申请音源输出设备、写音频文件及读音频文件。其中utils/audioManager.recording 方法实现了自动录音,可根据读取音频流的能量大小,动态判断语音输入是否结束。
3.1.3 对话模块设计
采用GPT-2 模型实现我们的对话系统模块,以这种方法构建对话系统,则可以在生成高信息量同时又不失流利的回复。对话模块可视化页面如图4 所示。
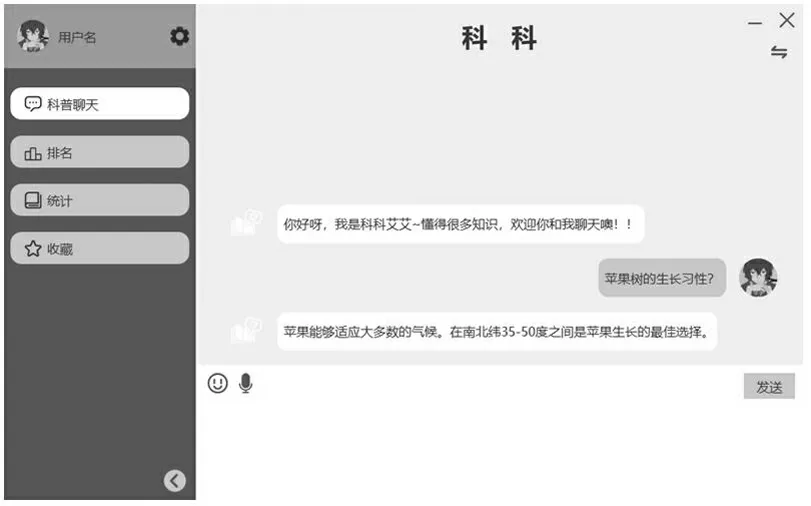
图4 用户聊天界面
用户可以通过在输入框中打字与机器人聊天。如果语句中出现好的知识点,可以点击语句进行收藏,收藏后的语句将会存储在收藏模块中。此外,每次对话都将会累计得分,并将得分的变化存储在班级学习情况中。如果使用教师账号进行登录,还能够查看班级学习排名。
3.2 数据库设计
本文采用MySQL 关系型数据库对系统的进行设计。在该系统的数据库中,本文以学生、教师对象是系统的主体,在数据库中以用户名作为唯一标识符,并通过用户名与对话、组(班级)以及收藏进行对应。对话设计为弱实体,依赖于学生实体而存在,属性包括了一句对话输入、一句对话输出以及对话发生的时间等。科普聊天系统数据库的E-R 图如图5 所示。整个系统实体的数据冗余程度在可接受的范围内,基本兼顾了查询效率和存储性能。
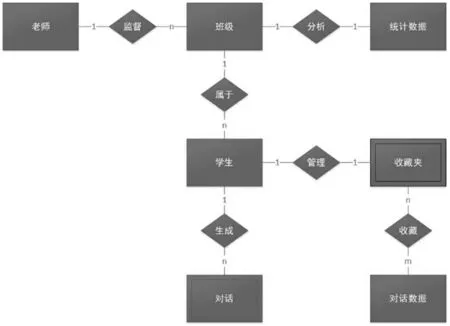
图5 科普聊天系统数据库的E-R 图
3.3 后端架构设计
在后端框架中,本系统可以分为四个部分:数据传输层,数据处理层,数据库接口层和安全层。其中,数据传输层负责获取和提交前端数据;数据处理层负责请求数据库数据以及对数据进行处理;数据库接口层实现对数据库的访问接口;安全层负责验证用户合法性以及拦截恶意请求等功能。
系统的实现采用了Python Flask 框架,同时配合使用Flask 中的SQLAlchemy 扩展进行ORM 映射,将数据库表映射为Python 中的实体。
安全层中实现了用户的Token 验证模块。前端获取服务时需要带上Token,本模块会验证Token 是否过期。对于合法发放Token 并且Token 有效的请求,后端才会响应。
4 结语
国家“双减”政策的全面推行,对中小学校教育教学质量和服务水平的要求进一步提高,填补课后服务需求缺口成为学校的一项重要工作。本文设计了能够为中小学生提供优质的、富有趣味的科普知识资源的系统,填补中小学校在课后服务资源方面的需求和缺口。我们在后续将会继续改进该系统,让本系统在更大程度上更加能贴合个性化发展需求,进而促进个人的全面发展。
猜你喜欢
学生天地(2020年23期)2020-06-01 02:13:30
意林(2017年9期)2017-06-06 10:26:12
少年文艺·开心阅读作文(2017年4期)2017-04-07 22:07:42
财经(2017年2期)2017-03-10 14:35:35
发明与创新(2016年38期)2016-08-22 03:02:58
发明与创新(2016年34期)2016-08-22 03:01:02
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
杭州科技(2014年1期)2014-02-27 15:26:30
