
基于观测点机制的异常点检测算法
2022-05-20 03:11:14于万国何玉林覃荟霖
深圳大学学报(理工版) 2022年3期
于万国,何玉林,覃荟霖
1)河北民族师范学院数学与计算机科学学院,河北承德 067055;2)深圳大学计算机与软件学院,广东深圳 518060;3)人工智能与数字经济广东省实验室(深圳),广东深圳 518107
异常点检测亦称为离群点检测,是数据挖掘领域的重要研究分支之一[1-2],可被视为一种无监督机器学习方法,其主要任务是利用统计分析或机器学习的方法从群体集合中找出与大多数数据存在明显不同的数据(亦称为异常点或离群点).迄今尚无被学术界或者工业界广泛接受的关于异常点的明确定义,人们仅能根据具体的应用,基于行业知识的积累对本行业的异常点给出特定的形式化描述,如黑客入侵[3]、银行欺诈[4]、仪器故障[5]和灾害预警[6]等都与异常点检测有密切关系.
如何平衡计算复杂度与检测精度之间的矛盾是异常点检测领域的关键问题,现有的异常点检测算法可归结为4类:①基于统计的异常点检测.此类算法通常基于给定的数据集构建一个统计模型,再计算样本点符合该模型的概率,并将概率值偏低的样本点标记为异常点,如基于先验统计模型[7]、基于直方图[8]、基于混合模型[9]的异常点检测算法等.②基于聚类的异常点检测.此类算法先对给定的数据集进行聚类,再对样本量明显较少的类簇进行进一步分析,例如计算类内紧凑度和类间分离度,进而确定其是否为异常点簇.代表性的工作包括基于k-means 聚类[10]、基于 DBSCAN 聚类[11]和基于层次聚类[12]的异常点检测算法等.③基于距离的异常点检测.若一个样本点距离数据集中其他样本点都很远,则该样本点会被认为是异常点.此类算法的重点在于设计样本点之间的距离度量,如基于k-近邻[13]、基于全局k-近邻[14]和基于k-近邻图[15]的异常点检测算法等.④基于密度的异常点检测.该类算法认为正常点所处的类簇密度要高于异常点所处的类簇密度,那些具有低密度值的样本点通常会被标记为异常点.密度度量的设计是该类算法研究的重点.代表性工作包括基于局部异常因子的异常点检测(local outlier factor-based outlier detection,LOFOD)[16]、基于局部相关积分的异常点检测[17]和基于局部异常概率的异常点检测[18]等.以上算法针对不同的应用场景已取得了良好的实际表现,然而它们都没能很好地解决计算复杂度与检测精度之间的矛盾,即基于统计的异常点检测算法计算复杂度一般相对较低,但检测精度不高;另外3种算法虽然识别精度相对较高,但计算复杂度普遍较高.
本研究提出一种基于观测点机制的异常点检测(observation-point mechanism-based outlier detection,OPOD)算法,是随机化学习(randomization-based learning)策略在异常点检测领域中一种新应用,通过在原始的数据空间随机放置观测点,再利用观测点来辨别原始数据集中的正常点和异常点.OPOD算法主要包括4个关键步骤:①在原始数据对应的空间中生成若干随机观测点;②对于给定的观测点,估计其与所有样本点距离值的概率密度函数;③计算观测点与样本点之间距离值出现的概率;④融合所有观测点对样本点观测的出现概率以完成对异常点的检测.基于PyCharm平台生成仿真数据集,对OPOD算法的可行性、合理性和有效性进行实验验证,包括OPOD算法通过观测点对原始空间多维样本点向一维距离空间的转化、OPOD 算法随观测点数量增加的收敛性,以及与基于近邻的异常点检测(nearest neighbor-based outlier detection,NNOD)算法和基于局部异常因子的异常点检测(local outlier factor-based outlier detection,LOFOD)算法的性能对比.实验结果表明,OPOD 算法具备异常点检测能力,且能够收敛,同时在观测点选取合适的条件下,具有比NNOD 和LOFOD 算法更低的时间复杂度和更好的异常点检测效果.
1 两种经典的异常点检测算法
1.1 NNOD算法
对于任意给定的属于数据集D的样本点x,令kNN(x)表示其对应的k近邻集合,则样本点x的异常度可被定义为

其中,d(x,y)为样本点x和样本点y之间的距离.在给定阈值δ> 0 条件下,当O(x) >δ时,认为样本点x为异常点.由式(1)可见,NNOD算法是基于样本点x与其k近邻的平均距离来判断该样本点是否为异常点:平均距离越小,表明样本点x的密度越大(即周围有邻居),x是异常点的几率就越小;反之,样本点x的密度越小(周围无邻居),x是异常点的几率就越大.NNOD算法的异常点检测结果易受k值的影响.
1.2 LOFOD算法
在LOFOD 算法中,每个样本点对应一个局部异常因子(local outlier factor,LOF),计算式为

其中,LRD(x)和LRD(y)分别为样本点x和y的局部可达密度(local reachability density,LRD),

其中,dreach(x,y)为样本点x到y的可达距离,

其中,dk(y)为样本点y与其第k近邻之间的距离;d(x,y)为样本点x与y的距离.为解决 NNOD 算法对近邻个数敏感的缺陷,LOFOD 算法不仅考虑了样本点x的密度,还考虑了x的近邻点的密度.当LOF(x)<1 且越接近1 时,样本点x越有可能是正常点;当LOF(x)>1 时,LOF(x)的值越大,样本点x越有可能是异常点.
综上可见,NNOD 算法和LOFOD 算法都是从数据集样本点的近邻入手确定样本点异常情况.由于两种算法都要扫描数据集中的每个样本点来确定近邻,因此,它们时间复杂度都为O(N2L).其中,N为数据集的规模;L为数据集的维度.
2 基于观测点的异常点检测算法
本研究提出一种基于观测点的异常点检测算法.假设现有包含N个L维样本点的数据集D={xn|xn=(xn1,xn2,…,xnL),xnl∈ R,n= 1,2,…,N;l=1,2,…,L},D中含有若干异常点,则OPOD 算法检测步骤如下.
1)生成随机观测点.在数据集D对应的样本空间中随机生成M个观测点p1,p2,…,pM,其中,第m(m= 1,2,…,M) 个 观 测 点pm=(pm1,pm2,…,pmL,),l= 1,2,…,L.观测点数值的选取 应 满 足其 中 ,分别为数据集D的第l维数据的最小值和最大值.
2)估计观测点与样本点之间距离的概率密度函数.依次计算观测点pm与样本点xn之间的距离值,得到距离集合Sm={sm1,sm2,…,smN},再利用核密度估计器确定Sm的概率密度函数[18],即
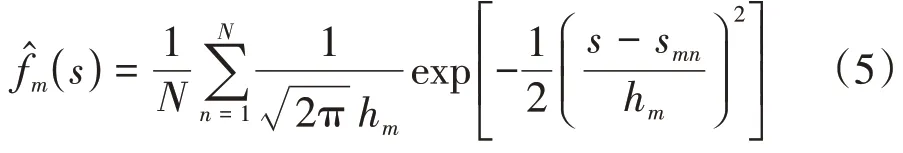
其中,hm为窗口宽度,hm>0.简便起见,本研究选用拇指规则[19-20]确定窗口宽度,即令hm=其中,σm为Sm的标准差.
3)计算观测点与样本点之间距离的概率值,即基于估计的概率密度函数计算Sm中距离值出现的概率.对于给定的极小值Δs>0,对应出现smn值的概率值为

4)识别异常点.对于给定的观测点pm,由式(6)得到其观察到的数据集D中样本点xn出现的概率给 定 阈 值ξ> 0,若则认为样本点xn为pm观测到的异常点 , 并 令xn相 对pm的 异 常 度tmn= 1; 若则认为xn为pm观测到的正常点,并令tmn= 0.如此类推,可得到全部观测点对应数据集D的异常点判别矩阵T=(tmn)M×N.若

则将xn标记为异常点.其中,为向上取整操作.
对OPOD算法中的关键步骤和参数选取做以下解释.
对于L维数据集,在使用M个观测点从N个样本点中进行异常点检测时,计算观测点与样本点之间的距离的时间复杂度为O(MNL).对于基于近邻和区域密度的异常点检测算法NNOD 和LOFOD 而言,执行算法往往需要计算数据集中两样本之间的距离,时间复杂度为O(N2L).因此,当M≪N时,OPOD算法的计算速度将比NNOD和LOFOD算法快得多.
在进行观测点与样本点之间距离的概率密度函数估计时,使用拇指规则确定核密度估计器的窗口宽度参数,主要原因是拇指规则在计算窗口宽度参数时不依赖迭代的参数优化过程,而是以解析解的形式直接给出窗口宽度,可节省计算时间.
在进行异常点识别时,采用式(8)对ξ>0进行选取.

g(s)是均值为μm,标准差为σm的正态分布函数,μm为样本集合Sm的均值,s∈Sm.
3 实验验证与结果分析
实验所用计算机硬件环境为Intel CPU i5-8300H,主频为2.3 GHz,内存容量为8 Gbyte,硬盘容量为1 Tbyte;软件环境为 Python 3.7.6,Anaconda3,64 bits Window 10操作系统.
3.1 OPOD算法的可行性验证
基于PyCharm 平台,在给定数据的规模和维度条件下,采用sklearn.datasets 的make_blobs 函数 (https://scikit-learn. org/stable/modules/generated/sklearn. datasets. make_blobs. html#sklearn. datasets.make_blobs)生成2维仿真数据集.其中,仿真数据集1共有500个样本点,仿真数据集2共有1 000个样本点,二者都含7 个异常点,如图1.数据集中的数据点类别各异且具有各向同性高斯分布,同时有少量数据的类被标注为异常点.这些仿真数据集均已上传至百度网盘(https://pan.baidu.com/s/12IQMPM30G9YW5YXft-Zt-g,提取码:jd3d).

图1 采用sklearn.datasets的make_blobs函数生成2维仿真数据集Fig.1 (Color online)Two dimensional synthetic data sets generated with make_blobs function in sklearn.datasets
使用观测点机制进行异常点检测是通过将多维空间的数据点转换成1 维空间的距离点,在1 维空间中估计距离值的概率分布,进而判断原始数据中哪些样本点为异常点.图2 为使用OPOD 算法对仿真数据集1 和2 进行异常单检测的结果.由图2 可见,异常点对应的距离值均在概率密度函数的长尾部分,概率值较小,通过对多观测点的融合能够轻易地将它们检测出来.实验结果表明,样本点在多维原始空间的分布情况可反映到1维距离空间的观测点,样本分布密集区域对应的概率密度函数值较大,而样本稀疏区域对应的概率密度值相对较小.

图2 观测点与样本点之间观测距离的概率分布Fig.2 (Color online)Probability distributions of observation distances between observation points and data points
3.2 OPOD算法的合理性验证
分别测试不同规模和不同维度的数据集对OPOD 算法性能的影响.其中,算法的表现使用异常点召回率(R)衡量,即被正确检测的异常点个数与全部异常点个数的比值.
首先分析数据集规模与OPOD算法中观测点数量之间的关系.设L= 40,正常点的个数以步长100 从1 000 增至4 000,共得到31 个仿真数据集.异常点数量与正常点数量的比例保持在1∶100.图3 给出了在不同规模数据集上,随着观测点数量(M)的增加,OPOD算法的收敛性示意.

图3 OPOD算法对不同规模数据集异常点检测的收敛性(L = 40)Fig.3 Convergence of OPOD algorithm for outlier detection under different size data sets(L = 40)
图4 显示随着数据集规模的增加,OPOD 算法所需观测点数量逐渐增加直至收敛.这表明对于给定维度的数据集,所需观测点数量并非随着数据集规模的增大无限增大,而是有上限的.

图4 数据规模对OPOD算法观测点个数的影响Fig.4 Impact of data size on number of observation points in OPOD algorithm
为考察数据集维度与OPOD算法观测点之间的关系,设置N= 1 010.其中,正常点数个为1 000,异常点个数为10,数据维度以步长1 从1 增至60,得到60 个仿真数据集.图5 分别给出了数据维度L= 30、40、50和60 时,随观测点数量的增加OPOD算法的收敛性.图6 给出了随着数据集维度的增加,OPOD 算法所需观测点数量需求情况.由图6可见,随着数据集维度的增加,OPOD 算法所需观测点数量总体呈减少趋势,表明算法具有处理高维数据异常点检测问题的潜能,且数据维度越高,所需观测点数量越少.该结果与“维数灾”相对应,即数据维度越高,数据分布越稀疏,因此只需要较少观测点就能够观测到数据分布的基本情况.

图5 OPOD算法对不同维度数据集异常点检测的收敛性(N = 1 010)Fig.5 Convergence of OPOD algorithm for different data dimensions(N = 1 010)

图6 数据维度对OPOD算法观测点个数的影响Fig.6 Impact of data dimension on number of observation points in OPOD algorithm
以上结果表明,OPOD 算法性随着观测点数量的增加呈收敛趋势,且随着数据规模的增加,观测点数量逐渐增加;同时,随着数据维度的增加,观测点数量逐渐减少.
3.3 OPOD算法的有效性验证
为验证OPOD 算法的有效性,本研究对OPOD算法与两种经典的基于局部异常因子(local outlier factor,LOF)的异常点检测算法 NNOD 和LOFOD 算法进行仿真实验,并对比它们的运行时间、异常点召回率和误检率.其中,误检率为错误检测的异常点个数与检测出的异常点个数的比值.NNOD算法和LOFOD 算法中,近邻的确定和LOF 的计算分别采用PyOD 工具库(https://pyod.readthedocs.io/en/latest/)中 的 pyod.models.knn 和 pyod.models.lof 代 码实现.
图 7 和图 8 对比了 NNOD、LOFOD 和 OPOD 算法对不同规模、不同维度的仿真数据集2进行检测时的运行时间.结果发现,无论是对于不同规模的数据集,还是不同维度的数据集,OPOD 算法的运行时间最少,表明该算法的计算复杂度低.
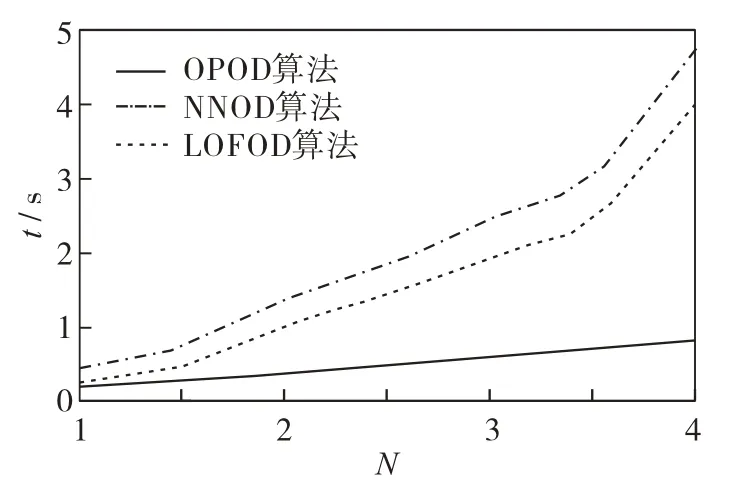
图7 NNOD、LOFOD和OPOD算法对不同规模数据集进行异常点检测的时间对比Fig.7 Time comparison among NNOD,LOFOD and OPOD algorithms for different data sizes
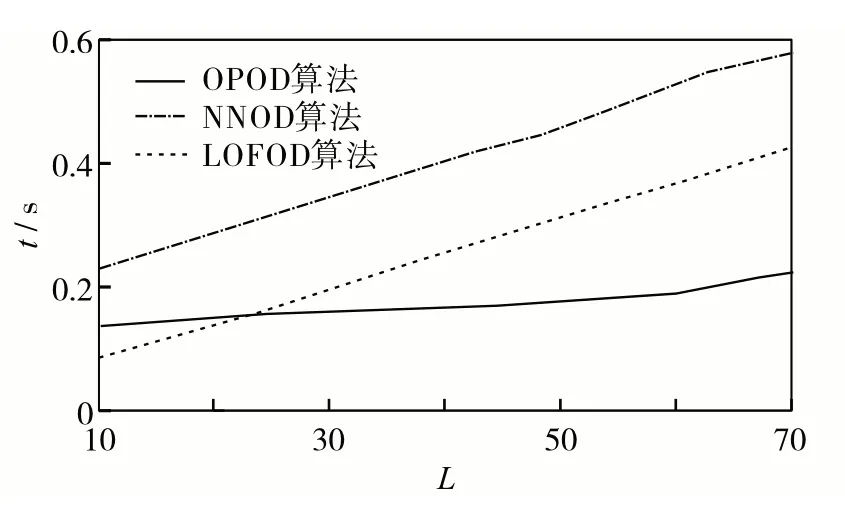
图8 NNOD、LOFOD和OPOD算法对不同维度数据集进行异常点检测的时间对比Fig.8 Time comparison among NNOD,LOFOD and OPOD algorithms for different data dimensions
选用4个标准UCI数据集(https://archive.ics.uci.edu/ml/datasets.php),固定某一个类为正常类,再从其余类中每次随机挑选10 个样本作为异常点,重复30次,正常点和异常点的选择情况见表1.表2和表3分别对比了OPOD算法和NNOD算法,以及OPOD算法和LOFOD算法的异常点召回率、误检率和运行时间.从中可见,OPOD 算法以较低的时间复杂度获得了较高的召回率和较低的误检率,表明OPOD算法的有效性.

表1 OPOD、NNOD和LOFOD算法使用的数据集Table 1 The data sets used in comparison among OPOD,NNOD and LOFOD algorithms

表2 OPOD和NNOD算法的召回率、误检率和运行时间Table 2 The recall (R), false detection rate (F) and run time (t) of OPOD and NNOD algorithms

表3 OPOD和LOFOD算法的召回率、误检率和运行时间Table 3 The recall (R), false detection rate (F) and run time (t) of OPOD and LOFOD algorithms
OPOD 算法取得良好异常点检测表现的原因是,该算法通过观测点将多维的原始数据转化成一维的距离数据,在某种程度上可以将观测点机制看作是一种特征提取[21]机制,恰当的异常点选取能够保证一维的距离分布正确反映出原始数据分布情况.之后在低维空间使用基于统计的异常点检测算法比在高维空间构建统计模型具有更低的计算复杂度,且比统计模型具有更好的适用性.
结 语
提出一种基于观测点机制的异常点检测算法OPOD,通过对不同维度、不同规模的仿真数据集进行测试,获得比基于近邻和局部异常因子的异常点检测算法更低的计算复杂度和更高的异常点检测精度.OPOD 算法通过在原始数据空间中随机放置观测点,并将多维的原始数据转换为一维的距离数据,再估计一维距离数据的概率密度函数,进而计算距离值的概率值,从总观测点的角度检测出异常点数据.下一步可结合生成模型理论对观测点的选取机制进行优化,并考虑在随机样本划分[22]框架下设计出用于大数据异常点检测的OPOD 算法.同时,仍需进一步对OPOD算法的收敛性、观测点数量的选取,以及最优观测点的确定等方面进行理论分析和验证.
猜你喜欢
广西民族大学学报(自然科学版)(2022年1期)2022-05-18 05:18:06
智能城市(2021年3期)2021-04-12 04:40:50
绿色科技(2019年12期)2019-07-15 11:13:02
中国惯性技术学报(2019年6期)2019-03-04 09:50:10
当代旅游(2018年8期)2018-02-19 08:04:22
中央民族大学学报(自然科学版)(2017年2期)2017-06-11 07:14:54
水利科技与经济(2016年10期)2016-04-26 08:39:58
火控雷达技术(2016年3期)2016-02-06 02:30:28
山东建筑大学学报(2015年4期)2015-05-11 09:05:22
浙江理工大学学报(自然科学版)(2015年10期)2015-03-01 02:54:43
