
基于LightGBM算法的高致病性传染病的传播趋势预测研究
2022-05-20 10:13:10周伟鸿朱思霖
物联网技术 2022年5期
周伟鸿,朱思霖
(厦门大学嘉庚学院,福建 漳州 363105)
0 引 言
传染病(Contagious Diseases)的有效防治是全人类面临的共同挑战。通过大数据,特别是数据的时空关联特性,精准预测传染病的传播趋势和速度,将有助于人类社会控制传染病,进而保障社会公共卫生安全。本文以2020 IKCEST第二届“一带一路”国际大数据竞赛暨第六届百度&西安交通大学大数据竞赛为依托,针对赛题所构造的若干虚拟城市,构建传染病群体传播预测模型。根据该地区传染病的历史每日新增感染人数、城市间迁徙指数、网格人流量指数、网格关联强度和天气等数据,预测群体未来一段时间每日新增感染人数。高致病性传染病的传播趋势的精准预测,在一定层面上不但可以为疫情防控决策和效果评价提供参考,而且对疫情防控具有一定的应用价值和社会价值。
1 任务分析
1.1 任务说明
2020 IKCEST赛题共涉及11个虚拟城市的90天的传染病感染情况,每个城市有若干重点区域。初赛要求针对所提供的5个城市,利用每个城市各区域前45天的样本数据进行训练,预测每个城市各区域后30天每天的新增感染人数。复赛要求针对包含初赛城市在内的11个城市,利用每个城市各区域前60天的样本数据进行训练,预测每个城市各区域后30天每天的新增感染人数。本文以初赛为例,对高致病性传染病的传播趋势预测方案进行说明。
1.2 方案设计
2020 IKCEST赛题中,所给数据均为多维度的时间序列数据,而传统时间序列模型,如ARIMA模型只能通过新增感染人数本身预测新增感染人数,无法关联迁移指数等其他维度的特征,故在方案设计中选用具有高效解释性的机器学习模型—LightGBM模型进行预测。在数据呈现方面,感染人数变化幅度及波动较大,并且统计的特征均为时间序列数据,缺乏固定特征,感染人数难以与单项特征相关,故而需要针对训练数据特点进行特征工程。针对赛题特点及数据特点,本文提出的高致病性传染病的传播趋势预测流程如图1所示。
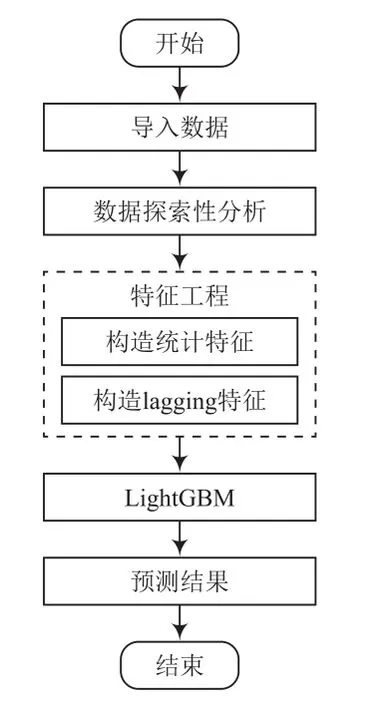
图1 方案流程
2 数据分析
2.1 数据探索性分析
在本实验中,须通过5个城市前45天的感染人数对后15天的感染人数进行预测。竞赛数据训练集共包括5个城市,每个城市目录下包含6个文件,其中infection包含各区域每天新增感染人数数据,migration包含城市间迁徙指数数据,density包含网格人流量指数数据,transfer包含网格关联强度数据,grid_attr包含网格归属区域数据,weather包含天气数据。复赛新增6个城市,训练集的城市数量从5增加到11;训练集的时间窗口从45天增加到60天;其他不变。具体文件信息见表1所列。

表1 竞赛训练数据信息
2.2 特征工程
赛题数据主要包括各个城市每天的新增感染人数、迁徙城市以及指数、人流量指数、人口迁移强度、天气数据。对数据进行分析后,初步得出结论:数据规模大,数据量约为4 GB;数据间经纬度对应有大量缺失;分析的数据为历史时间序列数据,缺乏固定特征与联系。
根据数据特点及分析结论,构建了基于统计特征和lagging特征的特征工程。即对数据表格根据日期进行拼接,以日期分组构造人流量指数、天气数据等统计特征,通过新增感染人数的历史数据构造lagging特征,具体说明如下。
2.2.1 构造统计特征
通过日期、区域进行划分,统计感染人数的统计特征,比如新增感染人数的均值、方差、最大值、最小值、偏差、峰度、四分位数等特征以及迁移指数等特征的平均值、中值。
2.2.2 构造lagging特征
lagging特征是时间序列分析中与时间相关的滞后特征,比如可用第一天的新增感染人数作为第二天的一个lagging特征。本文采用长时间序列的lagging,即利用前45天数据预测第一天(即第46天),然后用前46天的数据预测第2天(即第47天),以此类推,lagging特征的具体构造方法如图2所示。采用长时间序列的lagging特征,让模型更好地抓住历史感染特征的同时,可以较准确地完成第天的感染人数预测或未来感染人数的预测。
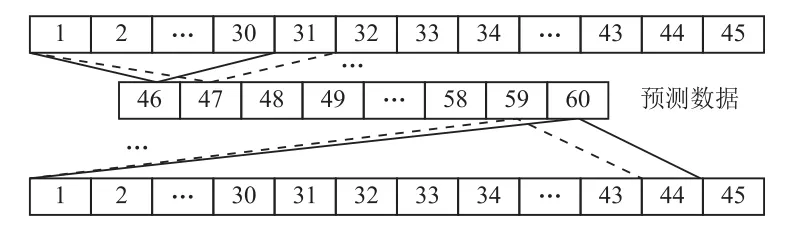
图2 lagging特征构造示意图
3 LightGBM模型
LightGBM模型是由微软亚洲研究院提出的一种决策树分布式梯度提升算法GBDT的框架,因其具有高训练效率、低内存使用,可处理大规模数据,支持直接使用类别特征等优势而被广泛应用。LightGBM模型包含的4种改进算法及其优势如图3所示。
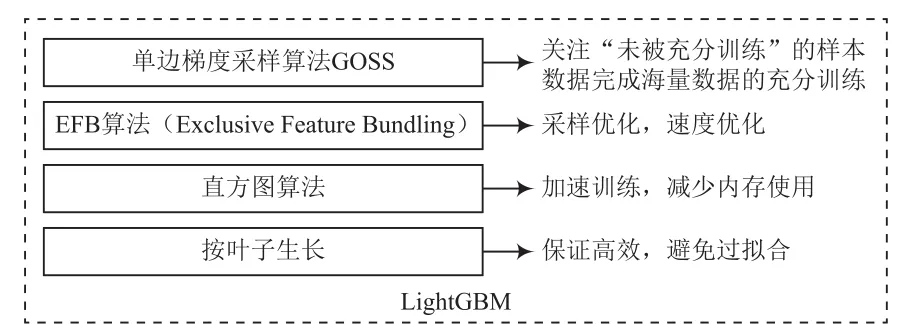
图3 LightGBM模型包含的4种改进算法及其优势
赛题所给数据的数量大、差异性大,应用LightGBM模型时,单边梯度采样算法GOSS(Gradient-based One-Side Sampling, GOSS)并未直接对样本进行训练,而是根据梯度对训练集数据的特征进行排序,通过预设比例,保留梯度大的样本,对梯度小的样本随机保留,同时放大小梯度样本带来的信息增益,从而避免数据分布的改变。通过GOSS算法处理,能够使模型训练时关注“未被充分训练”的样本数据,从而完成海量数据的充分训练。另外,对于训练数据具有标签跨度大、异常值多的特点,利用直方图算法,将大规模的数据放在了直方图中,使得特征占用内存更小,加速了模型的训练。对于样本的特征维度很高、样本空间稀疏的特点,LightGBM模型采用EFB(Exclusive Feature Bundling, EFB)算法进行特征优化,通过稀疏特征的合并、互斥特征的绑定等方式进一步优化了模型的训练速度。最后,通过按叶子生长leaf-wise算法防止了数据过拟合。综上可知,对于解决高致病性传染病的传播趋势预测问题,LightGBM模型具有迭代速度快、可解释性强等特点。
4 模型参数和实验结果
4.1 模型参数
机器学习中,不同的参数模型会对训练效果产生不同的影响,本方案中使用的LightGBM模型的超参数具体含义及设置见表2所列。在树模型中,当遇到过拟合时,可以首先考虑降低树的深度(max_depth参数)的值,而数的叶子数量(num_leaves)的取值最好为2max_depth,其中max_depth为树的最大深度,超过此值也容易导致模型过拟合;此外,为了平衡模型误差以及模型复杂度,也可采用正则化参数,即Lambda参数。在遇到过拟合的情况时,也可引入bagging_fraction参数。
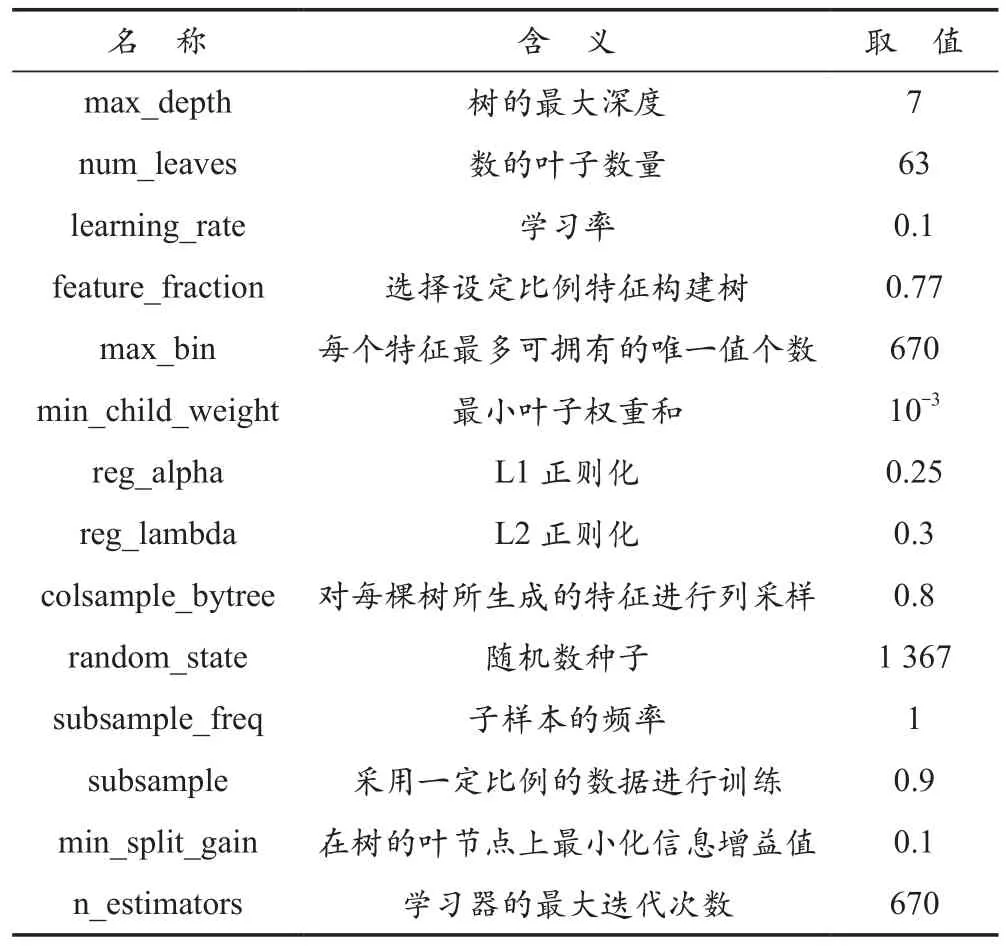
表2 LightGBM模型的超参数含义及设置
4.2 评估标准
为了评估预测效果、衡量观测值与真值之间的误差,本文采用回归评价指标均方根误差(Root Mean Square Error,RMSE)对预测结果进行评估,原理是计算观测值和真值间偏差的平方和与观测次数比值的平方根,如式(1)所示。
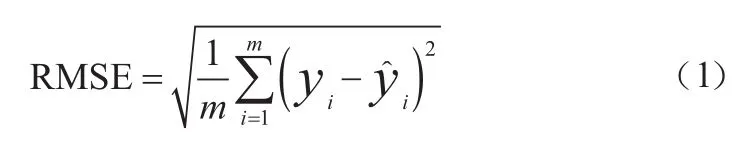
4.3 实验结果
在预测过程中,随着时间的推移,新增感染人数的变化幅度越来越大,数据的波动性越来越强,在统计特征上表现为感染人数的方差越来越大,数据的稳定性较差。本文通过对新增感染人数取对数变换来降低异方差性及共线性的影响,数据的形态特征更接近于正态分布。为了使数据与初始状态保持一致且具有可解释性,在经过LightGBM模型预测后,对预测结果进行指数变换,从而得到最终的新增感染人数的预测结果。本文选取了A、B、C、D、E 共5个城市的若干区域绘制了新增感染人数预测图,如图4所示。从图中可以看出,不同城市的新增感染人数的走势有各自的特点,本方案对于A、B城市的新增感染人数有较好的预测效果,对于C、D城市预测偏差较大。对5个城市的总体预测结果,即5个城市不同区域的新增感染人数的预测值与真实值的均方根误差RMSE,见表3所列。
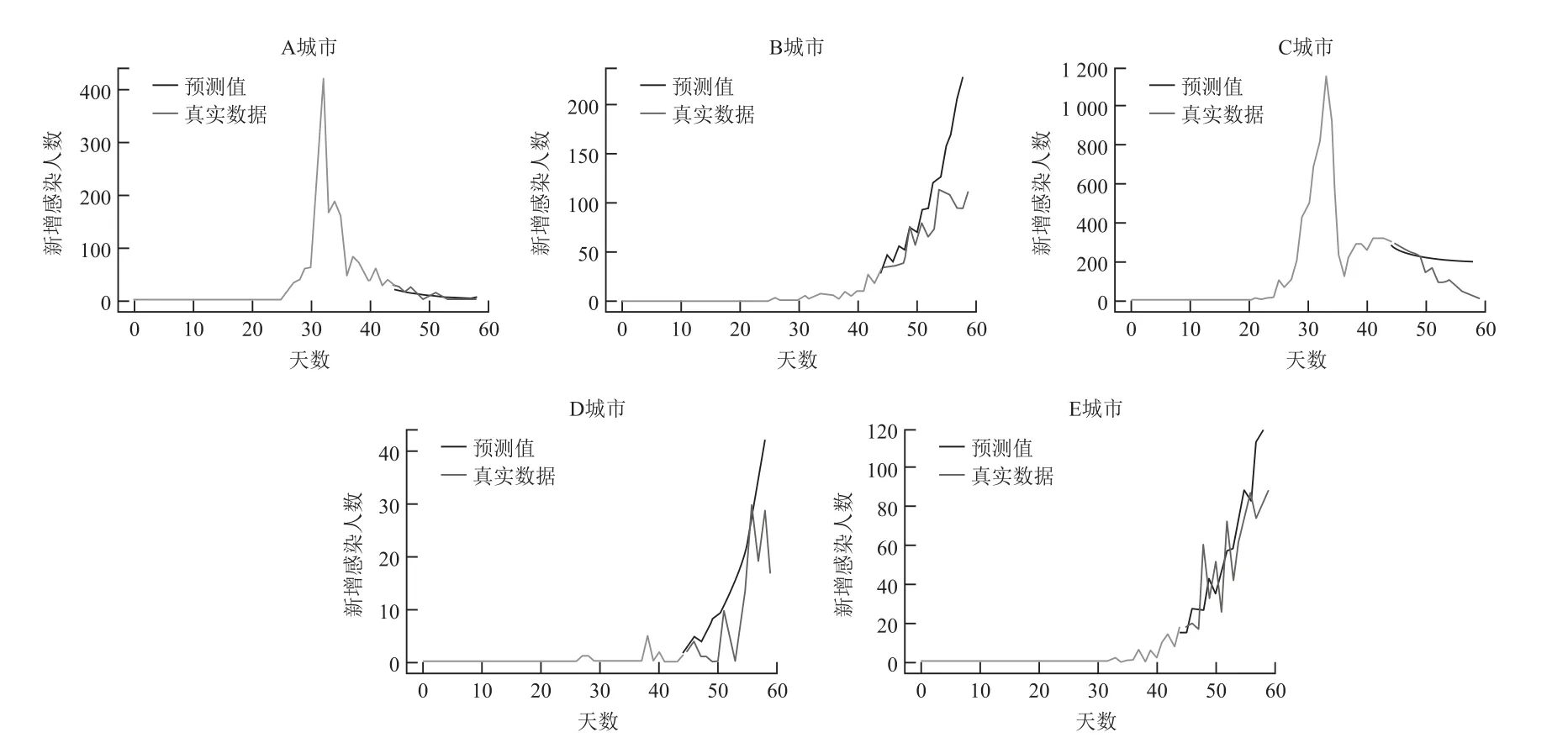
图4 5个城市的新增感染人数预测结果

表3 5个城市新增感染人数真实值与预测值均方根误差
5 结 语
高致病性传染病的传播给人类的生存带来威胁,根据疾病传播特点进行及时干预和有效防控具有重要意义。本文提出一种基于LightGBM模型的高致病性传染病的传播趋势预测方案。在方案中,根据感染人数的数据特点,从统计和时序两个方面构造了多类统计特征和lagging特征的特征工程,并利用LightGBM模型对新增感染人数进行了预测,取得了较好的预测结果,具有较低的RMSE。后续对于本实验的优化方面,将主要从以下两个方向进行:
(1)多角度的特征工程。例如可考虑多阶的统计特征,进一步挖掘人流量指数的潜在特征;还可以根据数据中给出的区域经纬度,构建区域图,挖掘邻近区域间新增感染人数的具体情况。
(2)融合多种模型。比如可以尝试LSTM的多输入单输出模型,该方法在序列建模问题上有一定优势;还可以以城市为粒度进行考虑,使用SEIR(Susceptible Exposed Infected Removed)模型进行预测,最后通过模型的集成进一步提高准确率。
猜你喜欢
黄河之声(2022年10期)2022-09-27 13:59:46
传染病信息(2022年3期)2022-07-15 08:25:08
肝博士(2022年3期)2022-06-30 02:48:50
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25 13:08:00
今日农业(2021年8期)2021-07-28 05:56:08
基层中医药(2020年3期)2020-02-13 02:48:50
中学生数理化·八年级物理人教版(2017年11期)2017-04-18 11:22:51
湖南畜牧兽医(2016年3期)2016-06-05 08:37:56
兽医导刊(2016年12期)2016-05-17 03:51:42
